AWS Managed Apache Flink (以下以 MAF 代指)是 AWS 提供的一款 Serverless 的 Flink 服务。
1. 问题
大家在使用 MAF 的时候,可能遇到最大的一个问题就是 MAF 的依赖管理,很多时候在 Flink 上运行的代码,托管到 MAF 上之后发现有很多依赖问题需要解决,大体上感觉就是 MAF 一定需要一个纯洁的环境,纯洁的 Flink 代码包。
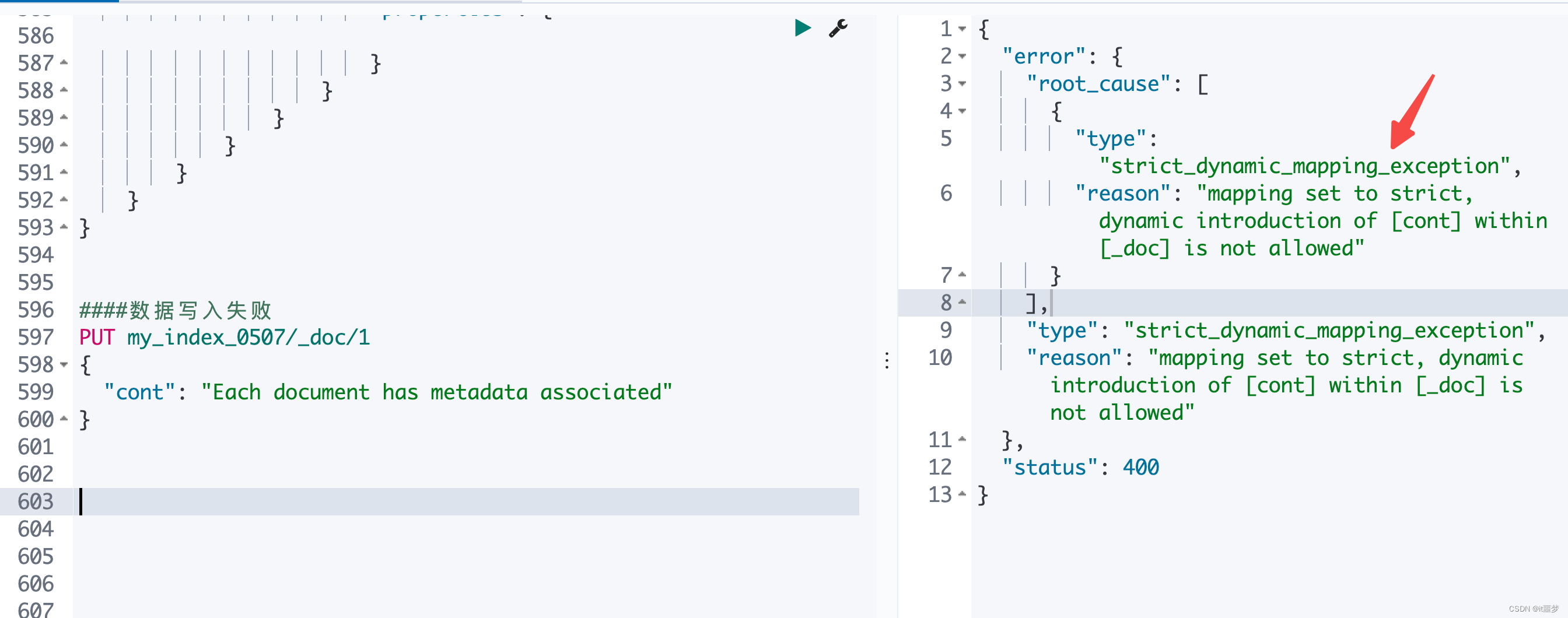
而我们在使用 MAF 向 Iceberg 表写入数据时候更是如此。在使用 MAF 向 Iceberg 写入数据时,使用 Glue Data Catalog,会遇到如下报错:
Caused by: java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configuration
at org.apache.iceberg.flink.FlinkCatalogFactory.clusterHadoopConf(FlinkCatalogFactory.java:211)
at org.apache.iceberg.flink.FlinkCatalogFactory.createCatalog(FlinkCatalogFactory.java:139)
at org.apache.flink.table.factories.FactoryUtil.createCatalog(FactoryUtil.java:406)
at org.apache.flink.table.api.internal.TableEnvironmentImpl.createCatalog(TableEnvironmentImpl.java:1356)
at org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:1111)
at org.apache.flink.table.api.internal.TableEnvironmentImpl.executeSql(TableEnvironmentImpl.java:701)
分析上面的错误,发现是在执行 Craete catalog 的时候,调用了 clusterHadoopConf 方法。我们在继续分析源码,在Iceberg 的源码 FlinkCatalogFactory 中,找到报错的代码位置,如下:
public static Configuration clusterHadoopConf() {
return HadoopUtils.getHadoopConfiguration(GlobalConfiguration.loadConfiguration());
}
而 HadoopUtils 这个类是来自于 org.apache.flink.runtime.util.HadoopUtils,我怀疑可能是 MAF 的环境是依赖于 EKS,因此镜像中并没有包含和 hadoop 相关的依赖,导致这里方法加载默认配置的时候,找不到 org/apache/hadoop/conf/Configuration 类,但是当我尝试在 maven 中加入 hadoop-client 依赖后,仍然存在这个问题。
2. 解决方案
通过上面的分析,我们知道了问题是出在了 org.apache.flink.runtime.util.HadoopUtils这个类,查找了很多资料,终于在 github 的 issue 中发现也有人遇到过这样的问题【#3044】,并且给出了一个绕行的方法,就是在自己的代码工程中重写 org.apache.flink.runtime.util.HadoopUtils这个类,不得不承认这是一个高明的方法。
重写HadoopUtils
在我们的代码工程中创建一个 package,并且添加一个名为 HadoopUtils 的 class,填入如下代码:
package org.apache.flink.runtime.util;
import org.apache.hadoop.conf.Configuration;
public class HadoopUtils {
public static Configuration getHadoopConfiguration(
org.apache.flink.configuration.Configuration flinkConfiguration) {
return new Configuration(false);
}
}
然后重新打包代码。
也可以参考 github 上的代码,链接🔗 github code
然后我们就可以编译打包代码。
3. Demo
下面我们通过一个完整的 Demo 来了解如何在 MAF 上实现 Iceberg 表的实时摄入。Demo 中会使用一个数据生成工具 Datafaker ,生成数据并且写入 MSK(kafka)中。
3.1 编译代码
获取 Demo代码,直接编译打包。
3.2 创建 MAF Application
- 将打包的 jar 上传至S3
- 进入 MAF 控制台,创建 Application,版本选择 Flink 1.18。
- 在 Application code location 部份填写在第1步上传的 jar 位置。
- MAF 会自动创建一个 IAM Role,在完成 Application 创建之后,请记得给这个 IAM Role 添加 Glue 读和写 Data Catalog 的权限,因为 Demo 代码工程会使用 Glue data catalog 作为 Iceberg catalog。
- 创建完 Application 就可以直接点击 Run 运行了。
3.3 生成数据
export MYBROKERS=<kafka-server>
export KAFKA_HOME=/home/ec2-user/environment/kafka_2.12-2.8.1
export TOPIC=datafaker_user_order_list_01
export IMPORT_ROWS=100000
#写入一条记录的间隔时间,也可以不设置
export INTERVAL=0.01
datafaker kafka $MYBROKERS $TOPIC $IMPORT_ROWS --meta dataformat_01.txt --interval $INTERVAL
这里就不详细介绍 datafaker 的使用了,如果想了解 datafaker 的参数配置可以从这个 github datafaker 获取。
3.4 在 Athena 中查询数据写入的结果
注意,如果 Athena 开启了 Reuse query results,可能会导致 count(*) 查询的不是最新的结果。

- 运维监控
4.1 Metrics
由于写入 Iceberg 表,不会在 Flink UI 看到 Records Recevied 以及 Records Send 等指标,因此如果想查看 Iceberg Sink 写入的数据量,需要进入Flink UI Sink 算子中,查看 Metrics 的 committedDataFilesRecordCount 指标。

![[Algorithm][回溯][找出所有子集的异或总和再求和][全排列 II][电话号码的字母组合][括号生成]详细讲解](https://img-blog.csdnimg.cn/direct/5eb95766e9c7483889e2c5adeadfa92c.png)