前言
系列专栏:机器学习:高级应用与实践【项目实战100+】【2024】✨︎
在本专栏中不仅包含一些适合初学者的最新机器学习项目,每个项目都处理一组不同的问题,包括监督和无监督学习、分类、回归和聚类,而且涉及创建深度学习模型、处理非结构化数据以及指导复杂的模型,如卷积神经网络、门控循环单元、大型语言模型和强化学习模型
在当今社会,几乎每个人都有一部手机,他们的手机都会定期收到通信(短信/电子邮件)。但重要的一点是,收到的大多数信息都是垃圾信息,只有少数是必要的通信。骗子制造欺诈性短信,骗取你的个人信息,如密码、账号或社会保险号。如果他们掌握了这些信息,就有可能访问您的电子邮件、银行或其他账户。
在本文中,我们将使用 Tensorflow 开发各种深度学习模型,用于垃圾短信检测,并分析不同模型的性能指标。
我们将使用短信垃圾邮件检测数据集,该数据集包含短信文本和相应的标签(垃圾短信或垃圾邮件)。
目录
- 1. 相关库和数据集
- 1.1 相关库介绍
- 1.2 数据集介绍
- 2. 探索性数据分析
- 2.1 每句话的平均字数
- 2.2 语料库中独特词的总数
- 3. 模型建立
- 3.1 数据准备(拆分为训练集和测试集)
- 3.2 构建模型
- 3.2.1 构建模型(多项式朴素贝叶斯)
- 3.2.2 创建自定义文本矢量化和嵌入层:
- 3.2.3 双向 LSTM(Bidirectional LSTM)
- 3.3 评估模型性能
1. 相关库和数据集
1.1 相关库介绍
Python 库使我们能够非常轻松地处理数据并使用一行代码执行典型和复杂的任务。
Pandas– 该库有助于以 2D 数组格式加载数据框,并具有多种功能,可一次性执行分析任务。Numpy– Numpy 数组速度非常快,可以在很短的时间内执行大型计算。Matplotlib/Seaborn– 此库用于绘制可视化效果,用于展现数据之间的相互关系。Keras– 是一个由Python编写的开源人工神经网络库,可以作为Tensorflow的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
1.2 数据集介绍
垃圾短信集是为垃圾短信研究而收集的一套带标记的短信。它包含一组 5,574 条英文短信,并对垃圾邮件进行标记,原始数据集可在此处找到。
①使用 pandas 函数 .read_csv() 加载数据集
# Reading the data
df = pd.read_csv("spam.csv",encoding='latin-1')
df.head()

我们可以看到,数据集中包含三列未命名的空值列。因此,我们放弃这些列,并将列 v1 和 v2 分别重命名为 label 和 Text。由于目标变量是字符串形式,我们将使用 pandas 函数 .map() 对其进行数字编码。
df = df.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis= 1)
df = df.rename(columns={'v1':'label','v2':'Text'})
df['label_enc'] = df['label'].map({'ham':0,'spam':1})
df.head()
经过上述数据预处理后的输出结果:

②让我们将 Ham 和 Spam 数据的分布情况可视化。
sns.set_theme()
sns.countplot(x=df['label'], palette=["#C2C4E2","#EED4E5"], hue=df['label'], legend=False)
plt.show()
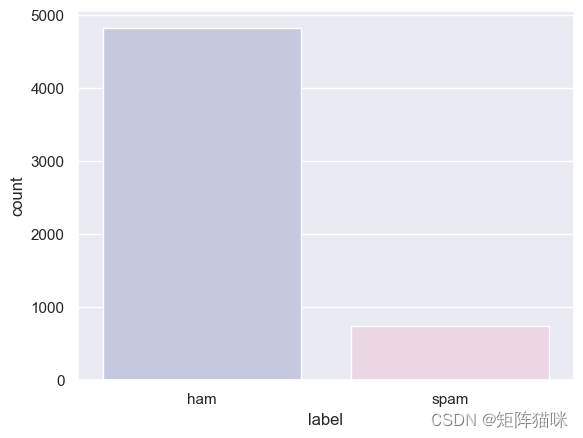
有价值的数据相对高于垃圾数据,这是很自然的。由于我们将在深度学习模型中使用嵌入式,因此无需平衡数据。
2. 探索性数据分析
2.1 每句话的平均字数
现在,让我们找出 SMS 数据中所有句子的平均单词数。
# Find average number of tokens in all sentences
avg_words_len=round(sum([len(i.split()) for i in df['Text']])/len(df['Text']))
print(avg_words_len)
15
2.2 语料库中独特词的总数
现在,让我们来计算语料库中独特词的总数
# Finding Total no of unique words in corpus
s = set()
for sent in df['Text']:
for word in sent.split():
s.add(word)
total_words_length=len(s)
print(total_words_length)
15585
3. 模型建立
3.1 数据准备(拆分为训练集和测试集)
现在,使用 train_test_split() 函数将数据分成训练和测试两部分。
# Splitting data for Training and testing
from sklearn.model_selection import train_test_split
X, y = np.asanyarray(df['Text']), np.asanyarray(df['label_enc'])
new_df = pd.DataFrame({'Text': X, 'label': y})
X_train, X_test,\
y_train, y_test = train_test_split(
new_df['Text'], new_df['label'], test_size=0.2, random_state=42)
X_train.shape, y_train.shape, X_test.shape, y_test.shape
((4457,), (4457,), (1115,), (1115,))
3.2 构建模型
3.2.1 构建模型(多项式朴素贝叶斯)
首先,我们将建立一个基线模型,然后尝试使用深度学习模型(嵌入、LSTM 等)击败基线模型的性能。
在这里,我们将选择 MultinomialNB(),当特征是离散的,如单词的字数或 tf-idf 向量时,它在文本分类中表现出色。tf-idf 是一种度量方法,它能显示出一个词在文档中的重要性或相关性。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
from sklearn.metrics import classification_report,accuracy_score
tfidf_vec = TfidfVectorizer().fit(X_train)
X_train_vec,X_test_vec = tfidf_vec.transform(X_train),tfidf_vec.transform(X_test)
baseline_model = MultinomialNB()
baseline_model.fit(X_train_vec,y_train)
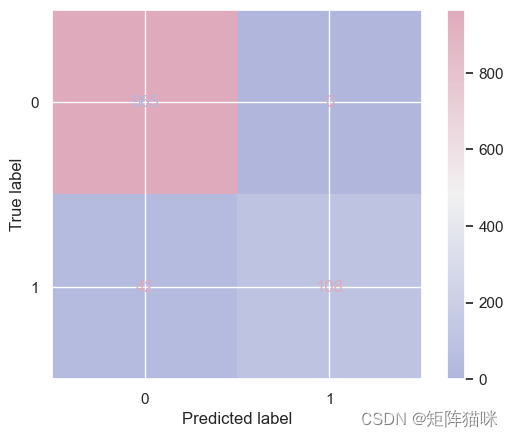
nb_accuracy = accuracy_score(y_test, baseline_model.predict(X_test_vec))
metrics.ConfusionMatrixDisplay.from_estimator(baseline_model,
X_test_vec, y_test,
cmap=sns.diverging_palette(260,-10,s=50, l=75, n=5, as_cmap=True))
print(f'{baseline_model.__class__.__name__} : ')
print('Validation Accuracy : ', nb_accuracy)
print(classification_report(y_test, baseline_model.predict(X_test_vec)))
MultinomialNB :
Validation Accuracy : 0.9623318385650225
precision recall f1-score support
0 0.96 1.00 0.98 965
1 1.00 0.72 0.84 150
accuracy 0.96 1115
macro avg 0.98 0.86 0.91 1115
weighted avg 0.96 0.96 0.96 1115
3.2.2 创建自定义文本矢量化和嵌入层:
文本矢量化是将文本转换为数字表示的过程。例如 词袋频率、二进制词频等;
词嵌入是对文本的一种学习表示,在这种表示中,具有相关含义的词具有相似的表示。每个单词都被分配到一个单一的向量中,而向量值的学习过程就像神经网络一样。
现在,我们将使用 TensorFlow 创建一个自定义文本矢量化层。
from tensorflow.keras.layers import TextVectorization
MAXTOKENS=total_words_length
OUTPUTLEN=avg_words_len
text_vec = TextVectorization(
max_tokens=MAXTOKENS,
standardize='lower_and_strip_punctuation',
output_mode='int',
output_sequence_length=OUTPUTLEN
)
text_vec.adapt(X_train)
- MAXTOKENS 是之前找到的词汇量的最大值。
- OUTPUTLEN 是句子的填充长度,与句子长度无关。
现在让我们创建一个嵌入层
embedding_layer = layers.Embedding(
input_dim=MAXTOKENS,
output_dim=128,
embeddings_initializer='uniform'
)
- input_dim 是词汇量的大小
- output_dim 是嵌入层的维度,即嵌入单词的向量的大小
- input_length 是输入序列的长度
现在,让我们使用 Tensorflow 功能应用程序接口构建并编译模型 1
input_layer = layers.Input(shape=(1,), dtype=tf.string)
vec_layer = text_vec(input_layer)
embedding_layer_model = embedding_layer(vec_layer)
x = layers.GlobalAveragePooling1D()(embedding_layer_model)
x = layers.Flatten()(x)
x = layers.Dense(32, activation='relu')(x)
output_layer = layers.Dense(1, activation='sigmoid')(x)
model_1 = keras.Model(input_layer, output_layer)
model_1.compile(optimizer='adam', loss=keras.losses.BinaryCrossentropy(
label_smoothing=0.5), metrics=['accuracy'])
模型-1概要
model_1.summary()
Model: "functional_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ input_layer (InputLayer) │ (None, 1) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ text_vectorization │ (None, 15) │ 0 │
│ (TextVectorization) │ │ │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ embedding (Embedding) │ (None, 15, 128) │ 1,994,880 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ global_average_pooling1d │ (None, 128) │ 0 │
│ (GlobalAveragePooling1D) │ │ │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ flatten (Flatten) │ (None, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense (Dense) │ (None, 32) │ 4,128 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_1 (Dense) │ (None, 1) │ 33 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 1,999,041 (7.63 MB)
Trainable params: 1,999,041 (7.63 MB)
Non-trainable params: 0 (0.00 B)
模型-1训练
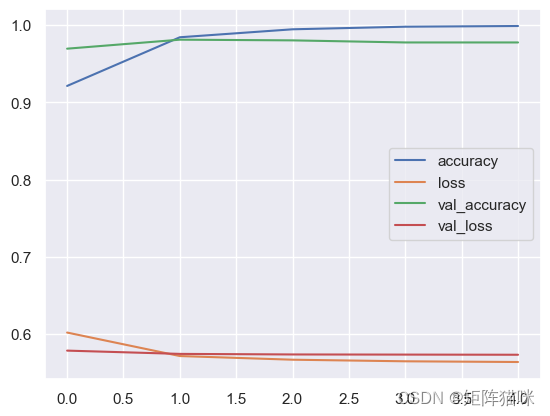
history_1 = model_1.fit(X_train, y_train, epochs=5, validation_data=(X_test, y_test))
Epoch 1/5
140/140 ━━━━━━━━━━━━━━━━━━━━ 2s 6ms/step - accuracy: 0.8605 - loss: 0.6278 - val_accuracy: 0.9695 - val_loss: 0.5784
Epoch 2/5
140/140 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step - accuracy: 0.9830 - loss: 0.5717 - val_accuracy: 0.9812 - val_loss: 0.5742
Epoch 3/5
140/140 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step - accuracy: 0.9955 - loss: 0.5659 - val_accuracy: 0.9803 - val_loss: 0.5734
Epoch 4/5
140/140 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step - accuracy: 0.9983 - loss: 0.5645 - val_accuracy: 0.9776 - val_loss: 0.5733
Epoch 5/5
140/140 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step - accuracy: 0.9992 - loss: 0.5636 - val_accuracy: 0.9776 - val_loss: 0.5731
模型-1 结果可视化
pd.DataFrame(history_1.history).plot()
3.2.3 双向 LSTM(Bidirectional LSTM)
双向 LSTM(长短期记忆)由两个 LSTM 组成,一个接受一个方向的输入,另一个接受另一个方向的输入。双向 LSTM 能有效改善网络的可访问信息,增强算法的上下文(例如,知道一个句子中紧跟在某个单词后面和前面的单词)
input_layer = layers.Input(shape=(1,), dtype=tf.string)
vec_layer = text_vec(input_layer)
embedding_layer_model = embedding_layer(vec_layer)
bi_lstm = layers.Bidirectional(layers.LSTM(
64, activation='tanh', return_sequences=True))(embedding_layer_model)
lstm = layers.Bidirectional(layers.LSTM(64))(bi_lstm)
flatten = layers.Flatten()(lstm)
dropout = layers.Dropout(.1)(flatten)
x = layers.Dense(32, activation='relu')(dropout)
output_layer = layers.Dense(1, activation='sigmoid')(x)
model_2 = keras.Model(input_layer, output_layer)
# compile the model
model_2.compile(optimizer='adam', loss=keras.losses.BinaryCrossentropy(
label_smoothing=0.5), metrics=['accuracy'])
# fit the model
history_2 = model_2.fit(X_train, y_train, epochs=5, validation_data=(X_test, y_test))
Epoch 1/5
140/140 ━━━━━━━━━━━━━━━━━━━━ 7s 17ms/step - accuracy: 0.9351 - loss: 0.5875 - val_accuracy: 0.9740 - val_loss: 0.5732
Epoch 2/5
140/140 ━━━━━━━━━━━━━━━━━━━━ 2s 12ms/step - accuracy: 0.9992 - loss: 0.5632 - val_accuracy: 0.9767 - val_loss: 0.5724
Epoch 3/5
140/140 ━━━━━━━━━━━━━━━━━━━━ 2s 12ms/step - accuracy: 0.9999 - loss: 0.5627 - val_accuracy: 0.9758 - val_loss: 0.5726
Epoch 4/5
140/140 ━━━━━━━━━━━━━━━━━━━━ 2s 12ms/step - accuracy: 1.0000 - loss: 0.5626 - val_accuracy: 0.9749 - val_loss: 0.5731
Epoch 5/5
140/140 ━━━━━━━━━━━━━━━━━━━━ 2s 12ms/step - accuracy: 1.0000 - loss: 0.5625 - val_accuracy: 0.9767 - val_loss: 0.5730
3.3 评估模型性能
baseline_model_results = evaluate_model(baseline_model, X_test_vec, y_test)
model_1_results = evaluate_model(model_1, X_test, y_test)
model_2_results = evaluate_model(model_2, X_test, y_test)
model_3_results = evaluate_model(model_3, X_test, y_test)
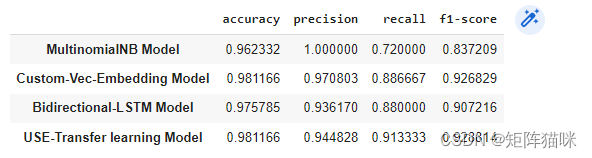
total_results = pd.DataFrame({'MultinomialNB Model':baseline_model_results,
'Custom-Vec-Embedding Model':model_1_results,
'Bidirectional-LSTM Model':model_2_results,
'USE-Transfer learning Model':model_3_results}).transpose()
total_results