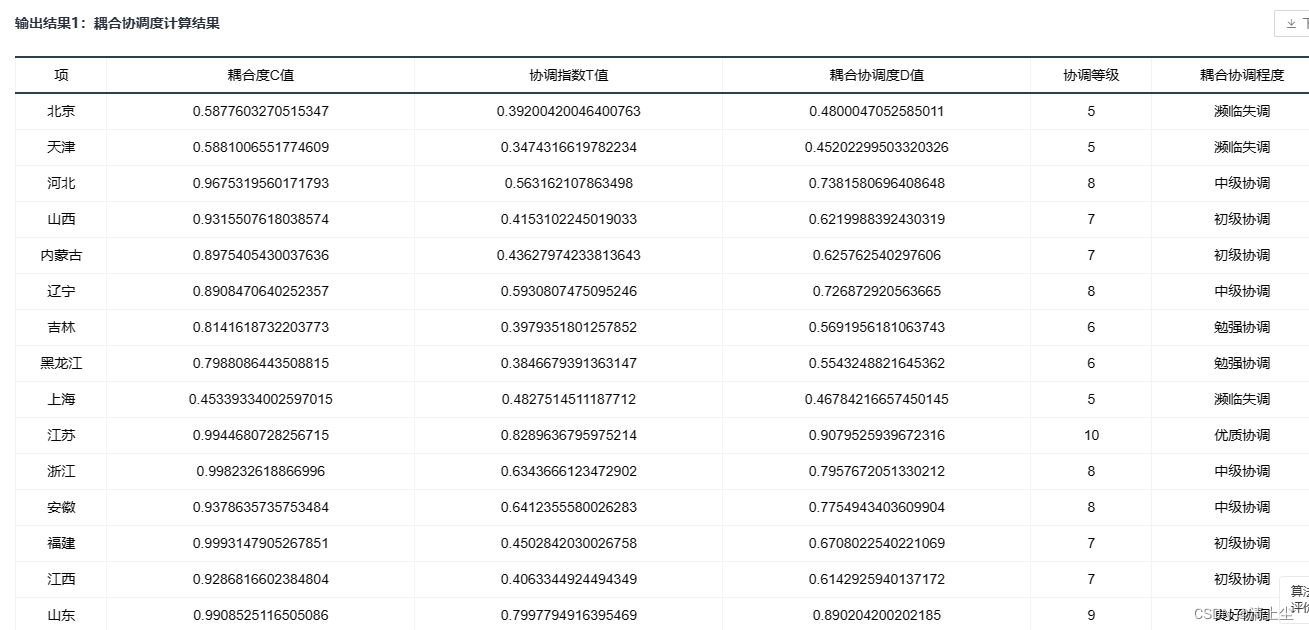
Apache Flume 中的事务处理是指 Flume Agent 在处理事件流时的一种机制,用于确保数据的可靠传输和处理。

1. 事务概述:
Flume中的事务是指一组事件的传输和处理,这些事件在传输过程中要么全部成功完成,要么全部失败,不存在部分成功部分失败的情况。- 事务通常由
Source产生,经过Channel存储,最终由Sink消费。事务性机制确保了事件从 Source 到 Sink 的可靠传输。
2. 事务处理工作流程:
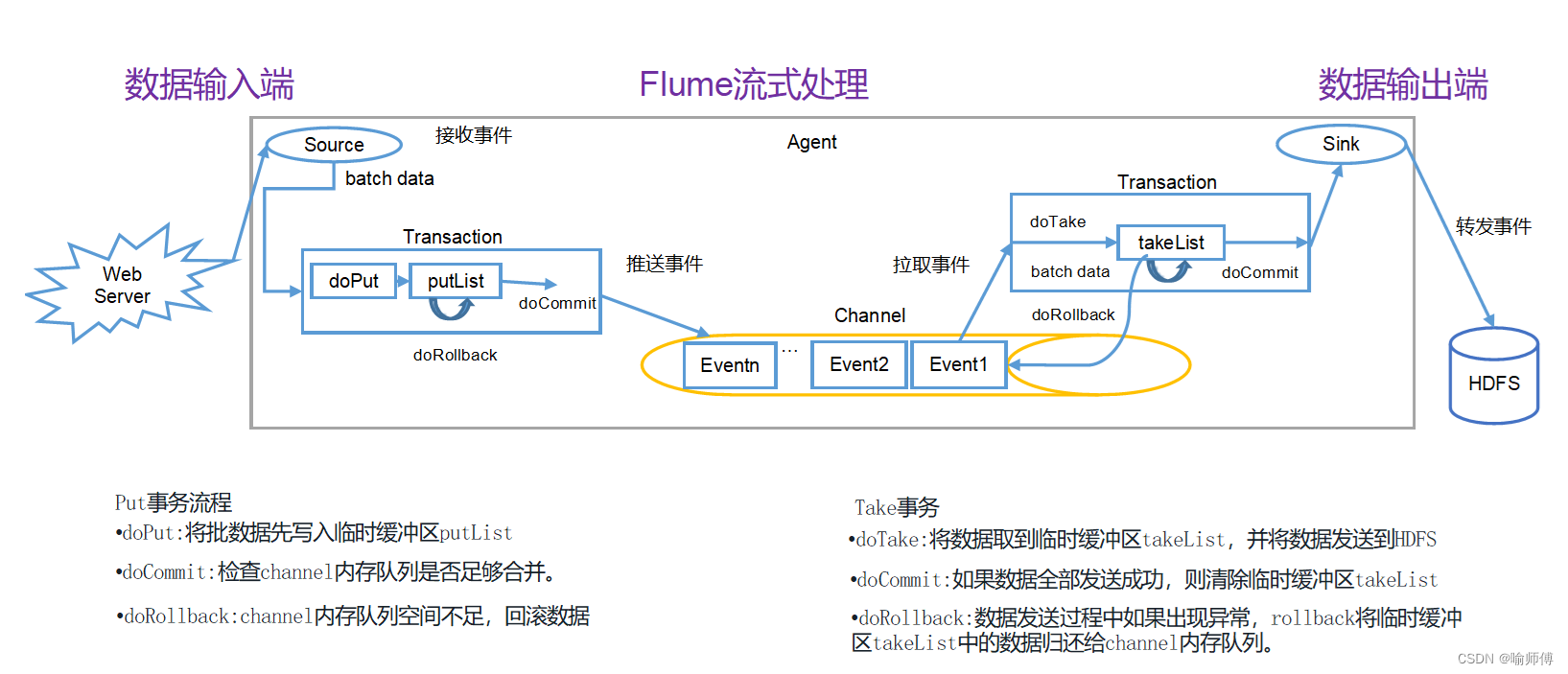
数据输入端(Source):
- 接收事件(Receiving Events):Source 接收到批数据作为事件输入。
- Transaction(事务):在处理事件时,Source 会启动一个事务。
- doPut:将批数据先写入临时缓冲区 putList。
- doCommit:检查 channel 内存队列是否有足够的空间来合并数据。
- doRollback:如果 channel 内存队列空间不足,则回滚数据。
- 回滚过程:
- 如果在写入数据到临时缓冲区 putList 时发生异常,Flume 会进行回滚操作。
- 回滚操作包括将未成功写入的数据从临时缓冲区移除,并将其放回到输入队列中,以确保不会丢失任何数据。
- 这样做可以确保在下次事务处理时重新尝试写入失败的数据。
数据传输端(Channel):
- Event1, Event2:事件被传输到 Channel 中,即一个事件队列。
- doTake:将数据取到临时缓冲区 takeList,并将数据发送到下游的 Sink(如 HDFS)。
- batch data:数据在 Channel 中进行批量处理。
- doRollback:如果发送过程中出现异常,将临时缓冲区 takeList 中的数据归还给 Channel 内存队列。
- 回滚过程:
- 如果在将数据从 Channel 中取出进行处理时出现异常,Flume 会进行回滚操作。
- 回滚操作包括将未成功处理的数据重新放回到 Channel 内存队列中,确保不会丢失数据。
- 这样做可以确保在下次事务处理时重新尝试处理失败的数据。
数据输出端(Sink):
- Transaction(事务):在处理事件时,Sink 会启动一个事务。
- 推送事件(Pushing Events):Sink 将事件推送到下游系统(例如存储系统)。
- 拉取事件(Pulling Events):从 Channel 中拉取事件进行处理。
- doCommit:如果所有数据都发送成功,则清除临时缓冲区 takeList。
- doRollback:如果发送过程中出现异常,将临时缓冲区 takeList 中的数据归还给 Channel 内存队列。
- 回滚过程:
- 如果在将数据推送到下游系统时发生异常,Flume 会进行回滚操作。
- 回滚操作包括取消已发送但未被下游系统接收的数据,将这些数据放回到 Channel 中,确保数据不会丢失。
- 这样做可以确保在下次事务处理时重新尝试发送失败的数据。
回滚操作确保了在数据传输过程中出现异常时的数据一致性和可靠性。数据在回滚后会被重新放回到适当的位置,以便在下次处理时重新尝试。这种机制确保了数据不会因传输过程中的故障而丢失或不一致。
3. 事务性保证:
- 至少一次语义(At Least Once Semantics):Flume 保证每个事件至少会被传输和处理一次。即使在 Sink 失败时,事件仍然会留在 Channel 中等待后续的处理。
- 精确一次语义(Exactly Once Semantics):对于某些特定的 Sink,Flume 可以提供精确一次语义,确保事件只会被处理一次,不会重复。这通常需要 Sink 和 Channel 的支持。
4. 事务配置:
- 在 Flume 的配置中,可以通过设置参数来控制事务的行为,如事务的最大大小、事务的超时时间、事务的持久性等。
5. 事务的应用场景:
- Flume 的事务性机制适用于需要确保数据传输的可靠性和一致性的场景,例如日志收集、数据备份等。