1、描述
有一个薪水表,salaries简况如下:
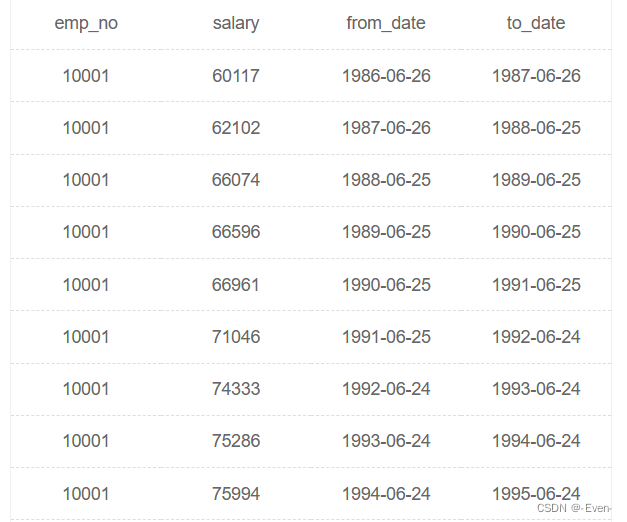
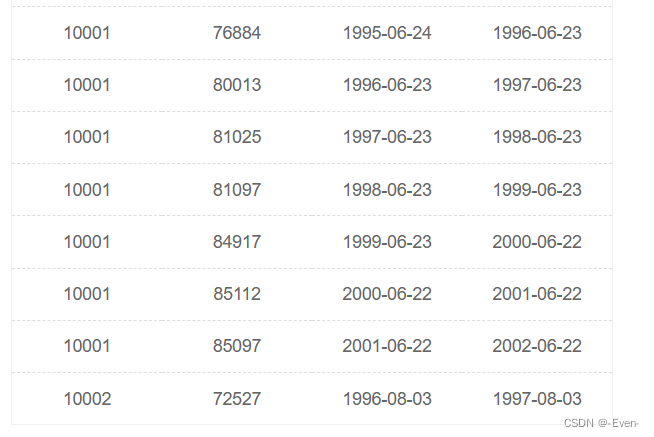
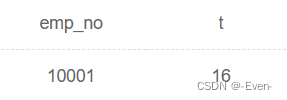
请你查找薪水记录超过15条的员工号emp_no以及其对应的记录次数t,以上例子输出如下:
2、题目建表
drop table if exists `salaries` ;
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
INSERT INTO salaries VALUES(10001,60117,'1986-06-26','1987-06-26');
INSERT INTO salaries VALUES(10001,62102,'1987-06-26','1988-06-25');
INSERT INTO salaries VALUES(10001,66074,'1988-06-25','1989-06-25');
INSERT INTO salaries VALUES(10001,66596,'1989-06-25','1990-06-25');
INSERT INTO salaries VALUES(10001,66961,'1990-06-25','1991-06-25');
INSERT INTO salaries VALUES(10001,71046,'1991-06-25','1992-06-24');
INSERT INTO salaries VALUES(10001,74333,'1992-06-24','1993-06-24');
INSERT INTO salaries VALUES(10001,75286,'1993-06-24','1994-06-24');
INSERT INTO salaries VALUES(10001,75994,'1994-06-24','1995-06-24');
INSERT INTO salaries VALUES(10001,76884,'1995-06-24','1996-06-23');
INSERT INTO salaries VALUES(10001,80013,'1996-06-23','1997-06-23');
INSERT INTO salaries VALUES(10001,81025,'1997-06-23','1998-06-23');
INSERT INTO salaries VALUES(10001,81097,'1998-06-23','1999-06-23');
INSERT INTO salaries VALUES(10001,84917,'1999-06-23','2000-06-22');
INSERT INTO salaries VALUES(10001,85112,'2000-06-22','2001-06-22');
INSERT INTO salaries VALUES(10001,85097,'2001-06-22','2002-06-22');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'1996-08-03','1997-08-03');
3、答案
- GROUP BY 和 HAVING 通常一起使用来对数据进行分组和筛选。
- GROUP BY:这个关键字用于将结果集按照一个或多个列进行分组。在每个分组中,你可以对数据执行聚合函数(如 COUNT、SUM、AVG 等),以计算每个分组的统计信息。
- HAVING:这个关键字用于在分组后的结果集中进行筛选。它类似于 WHERE 子句,但 WHERE 子句是在分组之前应用的,而 HAVING 是在分组之后应用的。HAVING 通常与聚合函数一起使用,以便根据分组后的统计信息进行筛选。
select emp_no,count(emp_no) as t
from salaries
group by emp_no
having t > 15;