# 安装和加载需要的包
install.packages("readxl")
install.packages("forecast")
install.packages("ggplot2")
library(readxl)
library(forecast)
library(ggplot2)
# 数据加载和预处理
data <- read_excel("全年数据.xlsx")
colnames(data) <- c("year", "CO2_Emissions")
# 转换year列为日期类型
data$year <- as.Date(as.character(data$year), format="%Y")
# 时间序列图绘制
ggplot(data, aes(x = year, y = CO2_Emissions)) +
geom_line() +
labs(title = "中国工业碳排放量 (年)",
x = "年份",
y = "二氧化碳排放量") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5))全国碳排放量

这张图表展示了中国碳排放的时间序列数据,横轴标记为“年份”,时间范围从2005年开始一直到2020年结束。纵轴标记为“碳排放”,表示中国每年的碳排放量。从这个图表中,可以观察到以下趋势和特点:碳排放的显著增长:从2005年开始,中国的碳排放量呈现出明显的增长趋势。这可能与中国在这些年中快速发展和工业化过程中的能源需求增加有关。
人口增长趋势:与碳排放趋势相似,中国的人口数量也在这个时期稳步增长。人口增长可能是碳排放增长的一个主要因素,因为更多的人口需要更多的能源和资源。碳排放的高峰:在图表上可以看到,碳排放量在2014年左右达到了一个高峰。这可能是由于中国政府采取了一些政策措施来减少碳排放,或者与工业结构的变化有关。小幅下降或趋于平稳:在高峰之后,碳排放量在2015年左右出现了一些小幅下降或趋于平稳的迹象。这可能是由于能源效率改进、可再生能源使用增加等因素的影响。增长趋势恢复:然而,随着时间的推移,碳排放的增长趋势似乎又恢复。尽管增长速度可能有所放缓,但仍然是一个值得关注的趋势。
总的来说,这张图表提供了关于中国碳排放和人口增长之间关系的见解。它强调了减少碳排放和可持续发展的重要性,以应对气候变化和环境挑战。这也可能促使政府和社会采取更多的措施来降低碳排放并推动可持续发展。
接下来使用模型自动定阶:
Series: data$CO2_Emissions
ARIMA(2,1,0) with drift
Coefficients:
ar1 ar2 drift
1.1907 -0.5293 432.6742
s.e. 0.1882 0.1856 109.8183
sigma^2 = 31708: log likelihood = -124.58
AIC=257.17 AICc=260.02 BIC=260.94
指定的ARIMA模型是(2,1,0)附带漂移项。表示该模型是一个包含两个自回归项(AR)、一次差分(I - 积分)和零个滑动平均项(MA)的ARIMA模型。
其中:ar1 和 ar2 是第一和第二自回归项的系数。ar1的系数是1.1907,标准误为0.1882;ar2的系数是-0.5293,标准误为0.1856。这些系数表明了前一时期(或前几时期)的数据对当前值的影响。漂移(drift)系数是432.6742,标准误为109.8183,表明有一个正向的线性趋势,即CO2排放量随时间呈上升趋势。sigma^2:模型的方差为31708,这是残差的方差,也就是模型未能解释的变动部分。对数似然值(log likelihood):是-124.58,用于衡量模型拟合数据的好坏。AIC(赤池信息准则):是257.17,AICc(校正后的赤池信息准则)是260.02,BIC(贝叶斯信息准则)是260.94。这些准则越低表明模型越好,通常用于比较不同模型的拟合优度。
# 预测模型
model <- auto.arima(data$CO2_Emissions)
model
forecast_data <- forecast(model, h = 5) # 预测未来5年
# 预测结果可视化
plot(forecast_data, main = "碳排放预测")
# 模型检验
checkresiduals(model)# 预测未来5年的
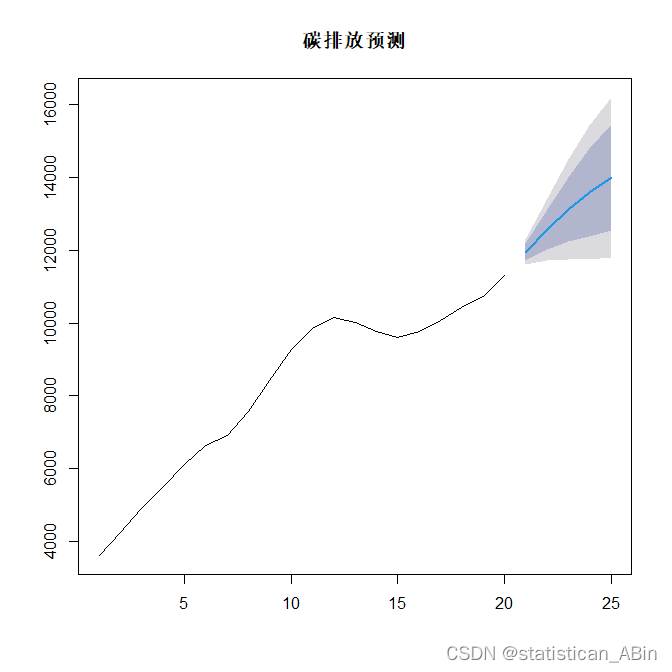 从预测趋势的角度来看,模型显示中国的碳排放量将继续增长。然而,随着时间的推移,置信区间变得越来越宽,这意味着我们对未来的预测变得越来越不确定。这种不确定性可以由多种因素造成
从预测趋势的角度来看,模型显示中国的碳排放量将继续增长。然而,随着时间的推移,置信区间变得越来越宽,这意味着我们对未来的预测变得越来越不确定。这种不确定性可以由多种因素造成
省碳排放量
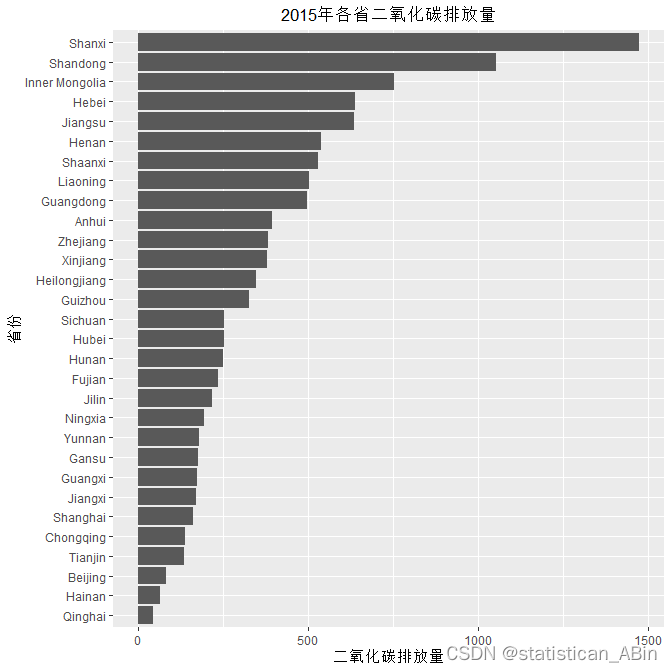 这张图提供了关于2015年中国各省一氧化碳排放量的重要信息。一氧化碳是一种对人类健康和环境具有潜在危害的气体,因此对其排放量的监测和理解至关重要。
这张图提供了关于2015年中国各省一氧化碳排放量的重要信息。一氧化碳是一种对人类健康和环境具有潜在危害的气体,因此对其排放量的监测和理解至关重要。
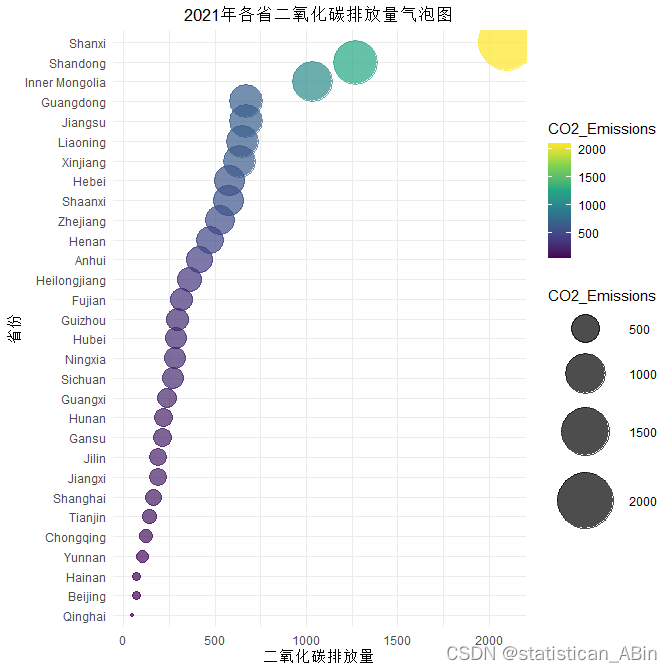 图是中国各省2021年二氧化碳排放量的泡泡图(气泡图)。这种图通常用于显示三个维度的数据:X轴代表一维,Y轴代表第二维,而气泡的大小代表第三维。在这张图中:X轴表示二氧化碳排放量。Y轴是中国的省份,以纵向形式列出。气泡的大小代表排放量的相对大小。
图是中国各省2021年二氧化碳排放量的泡泡图(气泡图)。这种图通常用于显示三个维度的数据:X轴代表一维,Y轴代表第二维,而气泡的大小代表第三维。在这张图中:X轴表示二氧化碳排放量。Y轴是中国的省份,以纵向形式列出。气泡的大小代表排放量的相对大小。
区域差异分析
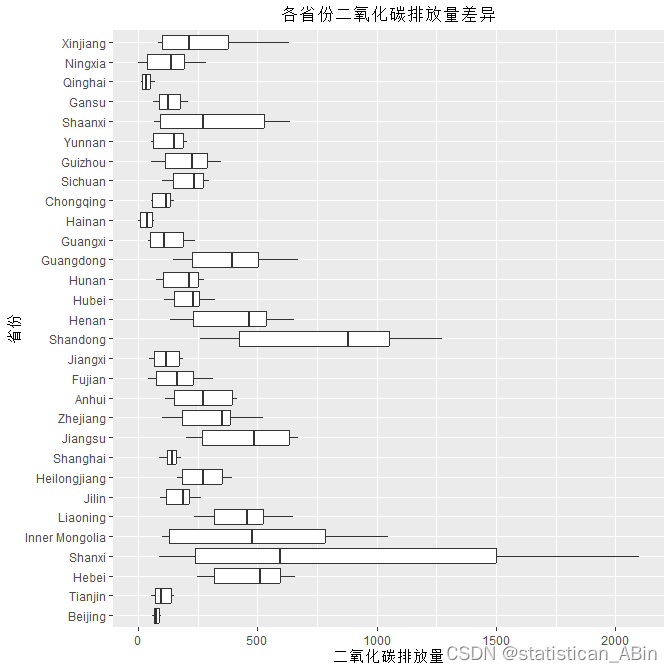
# 区域差异分析
ggplot(data_long, aes(x = Province, y = CO2_Emissions)) +
geom_boxplot() +
coord_flip() +
theme(plot.title = element_text(hjust = 0.5))+ # 确保标题居中
labs(title = "各省份二氧化碳排放量差异", x = "省份", y = "二氧化碳排放量")图可以看出,不同省份的二氧化碳排放量分布差异较大。一些省份,如北京和天津,显示出较窄的四分位数距,这意味着它们的数据点相对集中。其他一些省份,如山西和河北,四分位数距较宽,表明它们的排放量分布较为分散。
时间趋势分析:
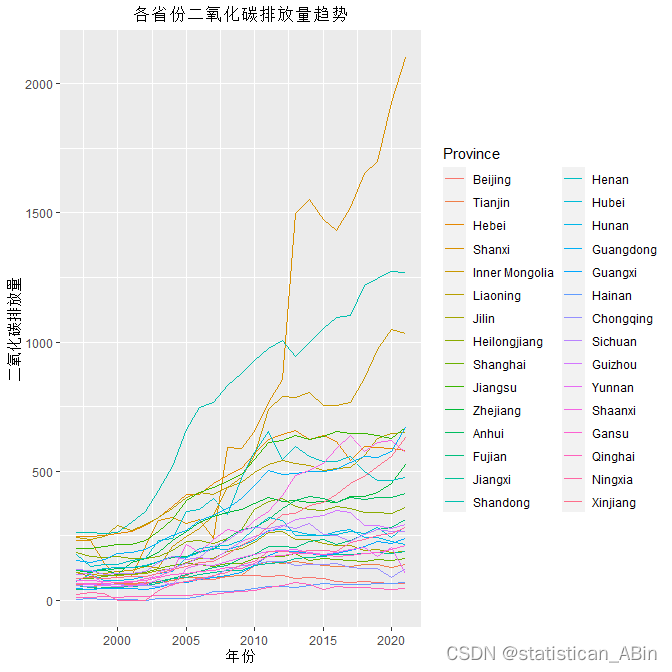
从图表中可以观察到以下几点:大部分省份的二氧化碳排放量在2000年到2020年之间呈现上升趋势。有几条折线显示出异常的急剧增长,尤其是那些在2010年后迅速上升的省份,这可能是由于快速工业化、能源消耗增加或其他因素导致的排放量增加。
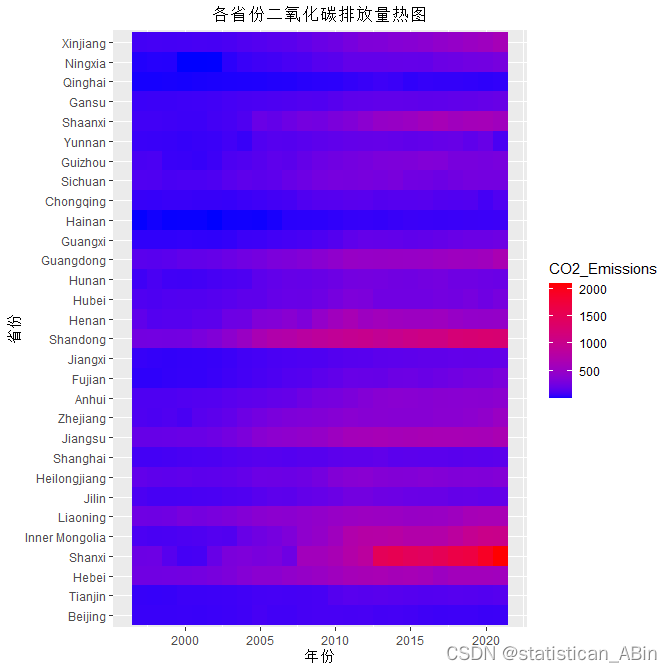
从热图上可以看出:大部分省份的二氧化碳排放量在这段时间里都有所增长,特别是在2010年之后,许多省份的排放量显著增加。某些省份,如山西、内蒙古、河北和天津的二氧化碳排放量尤其高,这些地区可能是重工业的集中地。...
代码
# 安装和加载需要的包
install.packages("readxl")
install.packages("forecast")
install.packages("ggplot2")
library(readxl)
library(forecast)
library(ggplot2)
# 数据加载和预处理
data <- read_excel("data.xlsx")
colnames(data) <- c("year", "CO2_Emissions")
# 转换year列为日期类型
data$year <- as.Date(as.character(data$year), format="%Y")
# 时间序列图绘制
ggplot(data, aes(x = year, y = CO2_Emissions)) +
geom_line() +
labs(title = "中国工业碳排放量 (年)",
x = "年份",
y = "二氧化碳排放量") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5))
# 预测模型
model <- auto.arima(data$CO2_Emissions)
model
forecast_data <- forecast(model, h = 5) # 预测未来5年
# 预测结果可视化
plot(forecast_data, main = "碳排放预测")
# 模型检验
checkresiduals(model)
###个省份数据
# 数据加载和预处理
data <- read_excel("data.xlsx")
colnames(data) <- c("Year", "Beijing", "Tianjin", "Hebei", "Shanxi", "Inner Mongolia", "Liaoning", "Jilin", "Heilongjiang", "Shanghai", "Jiangsu", "Zhejiang", "Anhui", "Fujian", "Jiangxi", "Shandong", "Henan", "Hubei", "Hunan", "Guangdong", "Guangxi", "Hainan", "Chongqing", "Sichuan", "Guizhou", "Yunnan", "Shaanxi", "Gansu", "Qinghai", "Ningxia", "Xinjiang")
data_long <- melt(data, id.vars = "Year", variable.name = "Province", value.name = "CO2_Emissions")
# 空间分布分析
# 比如分析2015年的空间分布
data_2015 <- subset(data_long, Year == 2015)
ggplot(data_2015, aes(x = reorder(Province, CO2_Emissions), y = CO2_Emissions)) +
geom_bar(stat = "identity") +
coord_flip() +
labs(title = "2015年各省二氧化碳排放量", x = "省份", y = "二氧化碳排放量") +
theme(plot.title = element_text(hjust = 0.5)) # 确保标题居中
# 筛选2021年的数据
data_2021 <- subset(data_long, Year == 2021)
# 检查2021年的数据
print(head(data_2021))
summary(data_2021$CO2_Emissions)
ggplot(data_2021, aes(x = reorder(Province, CO2_Emissions), y = CO2_Emissions, size = CO2_Emissions)) +
geom_point(aes(color = CO2_Emissions), alpha = 0.7) + # 添加颜色映射到CO2_Emissions
scale_color_viridis_c() + # 使用viridis颜色方案
scale_size_continuous(range = c(1, 20)) +
labs(title = "2021年各省二氧化碳排放量气泡图", x = "省份", y = "二氧化碳排放量") +
theme_minimal() +
coord_flip() +
theme(plot.title = element_text(hjust = 0.5)) # 确保标题居中
theme(legend.position = "bottom") # 将图例放置在底部
# 区域差异分析
ggplot(data_long, aes(x = Province, y = CO2_Emissions)) +
geom_boxplot() +
coord_flip() +
theme(plot.title = element_text(hjust = 0.5))+ # 确保标题居中
labs(title = "各省份二氧化碳排放量差异", x = "省份", y = "二氧化碳排放量")
# 时间趋势分析
ggplot(data_long, aes(x = Year, y = CO2_Emissions, group = Province, color = Province)) +
geom_line() +
theme(plot.title = element_text(hjust = 0.5))+ # 确保标题居中
labs(title = "各省份二氧化碳排放量趋势", x = "年份", y = "二氧化碳排放量")
# 转换数据为宽格式(wide format)用于热图分析
data_wide <- dcast(data_long, Year ~ Province, value.var = "CO2_Emissions")
# 检查data_wide的列名
print(colnames(data_wide))
print(head(data_wide))
# 需要将数据重新转换为长格式
data_long_for_heatmap <- melt(data_wide, id.vars = "Year", variable.name = "Province", value.name = "CO2_Emissions")
# 创建热图
ggplot(data_long_for_heatmap, aes(x = Year, y = Province, fill = CO2_Emissions)) +
geom_tile() +
scale_fill_gradient(low = "blue", high = "red") +
theme(plot.title = element_text(hjust = 0.5))+ # 确保标题居中
labs(title = "各省份二氧化碳排放量热图", x = "年份", y = "省份")
创作不易,希望大家多多点赞收藏和评论!









![[数据集][目标检测]管道焊缝质量检测数据集VOC+YOLO格式1134张2类别](https://img-blog.csdnimg.cn/direct/081289cc7bd648c4a095943bfdbf78f6.png)
