pandas.apply()
遍历DataFrame的元素(一行或者一列数据)
行遍历:axis = 1 列遍历:axis = 0
基础信息
pandas的apply()方法是用来调用一个lambda函数,让函数对数据对象具有批处理的特性。
pandas支持apply()调用的对象包括——DataFrame\Series\分组对象等
DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwargs)
- func:函数或 lambda 表达式,应用于每行或者每列
- axis:表示对象遍历的限制条件
- 0 or ‘index’: 表示函数处理的是每一列
- 1 or ‘columns’: 表示函数处理的是每一行
- raw:bool 类型,默认为 False
- False ,表示把每一行或列作为 Series 传入函数中
- True,表示接受的是 ndarray 数据类型
result_type:{‘expand’, ‘reduce’, ‘broadcast’, None}, default None。These only act when
axis=1(columns)
- ‘expand’ : 列表式的结果将被转化为列。
- ‘reduce’ : 如果可能的话,返回一个 Series,而不是展开类似列表的结果。这与
expand相反。- ‘broadcast’ : 结果将被广播到
DataFrame的原始形状,原始索引和列将被保留。- func:func 的位置参数
**kwargs:要作为关键字参数传递给 func 的其他关键字参数
DataFrame与Series的区别与联系
区别:
- series,只是一个一维结构,它由index和value组成。
- dataframe,是一个二维结构,除了拥有index和value之外,还拥有column。
联系:
- dataframe由多个series组成,无论是行还是列,单独拆分出来都是一个series。
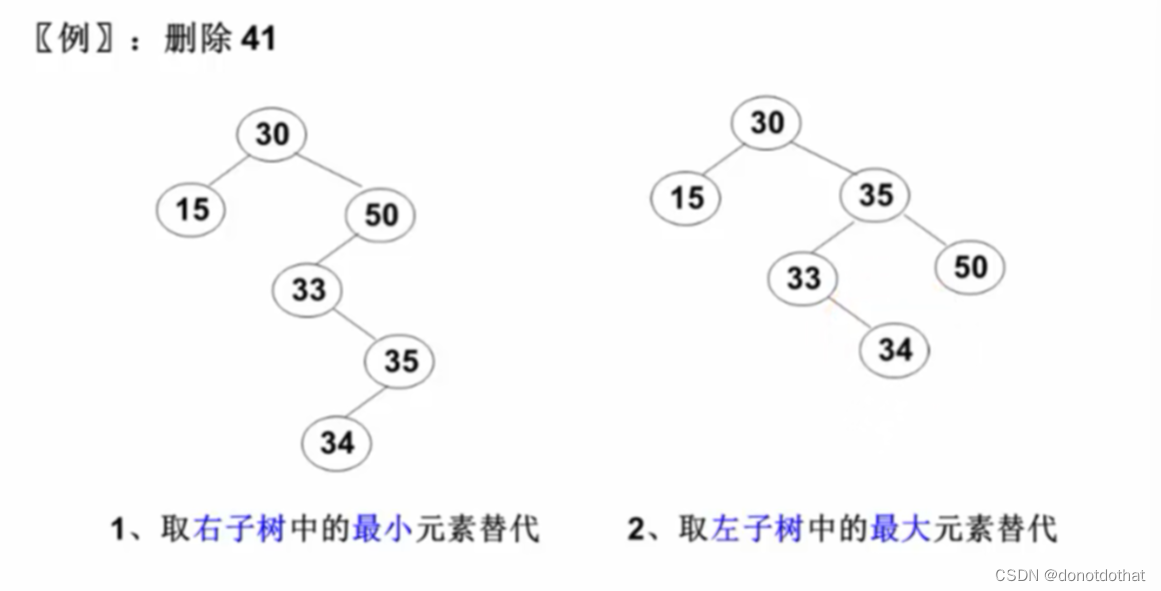
3完整的df传入函数:(lambda内,x即为df)
df=df.apply(lambda x:myneed(x,arg1),axis=1)
#可以将df['编号']传入函数:(lambda内,x即为df)
#操作对象就是df["编号"]
df=df.apply(lambda x:myneed(x['编号'],arg1),axis=1)
#也可以在df.apply()的apply函数前面的df进行增加操作对象的行或者列的限制
#对df['编号']进行apply操作:(lambda内,x即为df['编号'])
df['序号']=df['编号'].apply(lambda x:myneed(x,arg1),axis=1)自己研究的实现的案例分析
def extract_cpath(cpath_route)
if(cpath == '')
return []
return [int(s) for s in cpath.split(',')]
df["cpath_list"] = df.apply(lambda row:extract_cpath(row.cpath),axis = 1)
#这段代码的含义是:
#首先定义一个extract_cpath(cpath_route)函数,函数实现的功能是提取出cpath列的符合条件的数据
df["cpath_list"]列用来存放row(df)的cpath列中通过extract_cpath函数提取出来的数据(小贴士:通过find 命令能够查找当前目录及其子目录中所有符合特定条件的文件)大佬博客
#例如:查找当前目录及其子目录中所有以".txt"结尾的文件
find . -name "*.txt"WKT格式数据的展示
Geopandas的coords问题
问题代码:
RoadNetWork = gpd.reead_file("../data/edges.shp")
#all_matched_edges_list = [3, 4, 5, 8, 11, 13, 14, 16, 17, 18, 20, 25]
RoadNetWork.id = RoadNetWork.id.astype(int) #将RoadNetWork.id 变成整数类型
edges_matched_result =RoadNetWork[RoadNetWork.id.isin(all_matched_edges_list)]
#上述作用:判断id与all_matched_edges_list是否匹配 如果匹配 输出行所在内容 如果不匹配 返回false 该行不输出
edges_matched_result.reset_index()
print(edges_matched_result.geometry.coords)
#我上述代码错误原因:对于整个geometry应用coords的坐标属性 对象不明确
但是在apply(lambda row:len(row.geometry.coords),axis =1)里面,是逐行对geometry选定的列进行操作 这也就等价与针对于给定geometry的逐行的每个元素进行分析 对象指代明确 正确