迷信 bbr 的人是被它的大吞吐所迷惑,我也不想再解释,但我得反过来说一下 cubic 并非那么糟。
想搞大吞吐的,看看我这个 pixie 算法:https://github.com/marywangran/pixie,就着它的思路改就是了。
cubic 属于 aimd-based 算法,以 aimd 描述全程。以下是一个参数为 1,0.5 的 aimd 过程 tcptrace 图,md 采用 prr 过程:
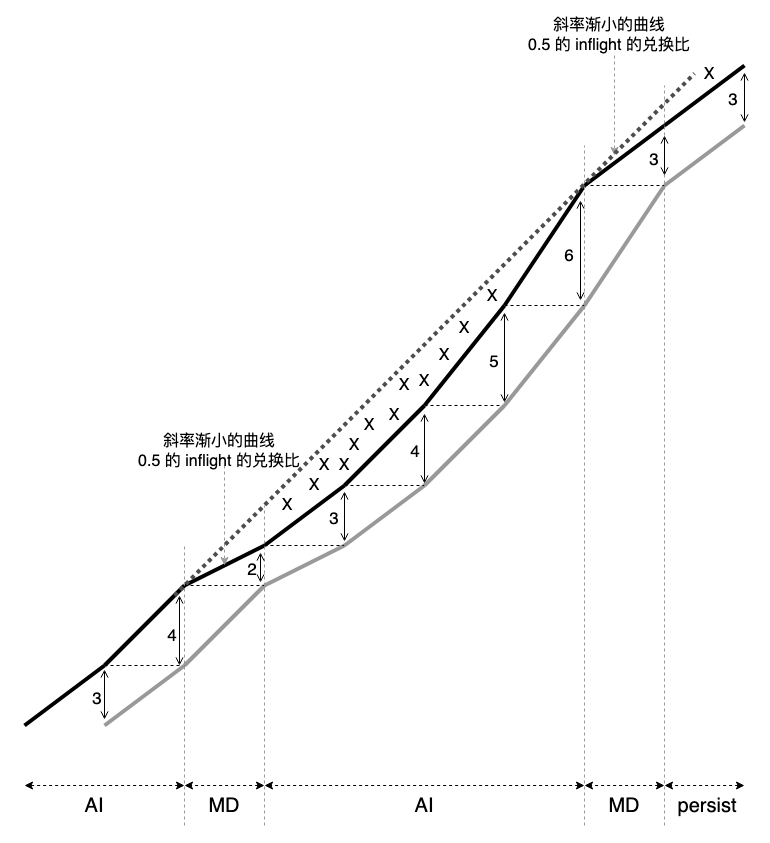
prr 降窗细节请参考:数据包守恒
简单的一个 cubic 优化请参考:cubic 与随机丢包
cubic 公平性不必说,但它吞吐低的原因也明确,图中 XXX 区域太大了。追查 XXX 太大的原因有二,rtt 越大,XXX 越宽,丢包越多, XXX 越深,越深的区域肯定越宽(长肥管道),但越宽却不一定越深(小带宽场景)。若要优化 cubic,目标也明确,减小 XXX。
rtt 无法改变,XXX 区域多由丢包决定,而丢包分为随机丢包和拥塞丢包。拥塞丢包情况下,执行 md 是 aimd 算法核心,所以不要试图通过 “不 md 降窗(换成 ad 降窗?)” 来优化吞吐,另一方面,丢包恢复后,cwnd 起点低,不要试图加速 ai 过程来优化吞吐,因为这同样破坏了 aimd 内核。 若在 aimd 框架下优化,可参考 tcp scalable 的思路。
常说的 aimd-based 算法吞吐低的原因就是 “cwnd 下降后,恢复太慢,在长肥管道尤为严重”,而似乎又什么都做不了,这是 ack 自时钟(self-clock)驱动的传输协议内在性质决定的。
但有个事可做,即隔离随机丢包。这可是个顽固难题,只有 ack 序列,信息量有限,所以不要试图折腾复杂的启发预测算法,写论文可以,实践肯定失败,要做的是引入一个非常简单的自适应机制。
相比 rfc3517 和 rate halving,tcp undo 和 prr 结合已覆盖误判,prr 让 cwnd 慢慢下降而不是一下子下降,过程中如果误判,cwnd 直接 restore。但如果随机丢包,哪怕重传一个报文,也无法 undo,任凭 cwnd 降到 ssthresh 再重新 additive increase,此时展出来的 XXX 宽度至少 2 个 rtt,rtt 越大,情况越糟。
如果只是随机丢包,噩梦将在 prr 过程中开始,在 cwnd 达到 ssthresh 时结束,在漫长的 additive increase 中惊魂未定。
对 prr 做一番修改是高尚的,尽量截止住微弱丢包对 cwnd 的影响,但在丢包加剧时迷途知返而不是一意孤行。文章开头提到链接里 “让 cwnd 先慢后快收敛到 ssthresh” 是个主意,但还有更简单的,即 “只有在有‘足够’报文被 mark lost 时才执行 prr”。
如果只 mark lost 了一个报文,prr 只将 cwnd 拉低一点点,如果继续 mark lost,则继续 prr 降 cwnd,这样就将丢包数量和丢包频度和 prr 过程关联起来,至于 ‘足够’ 是多少,调参。
另一个高尚的修改有关 undo。采集丢包时的 srtt,若 srtt 方差 ‘足够小’,绝对值与 open 状态相比 ‘足够小’,即可直接 undo,而不是缓慢 additive increase,至于 “足够小” 是多小,调参。
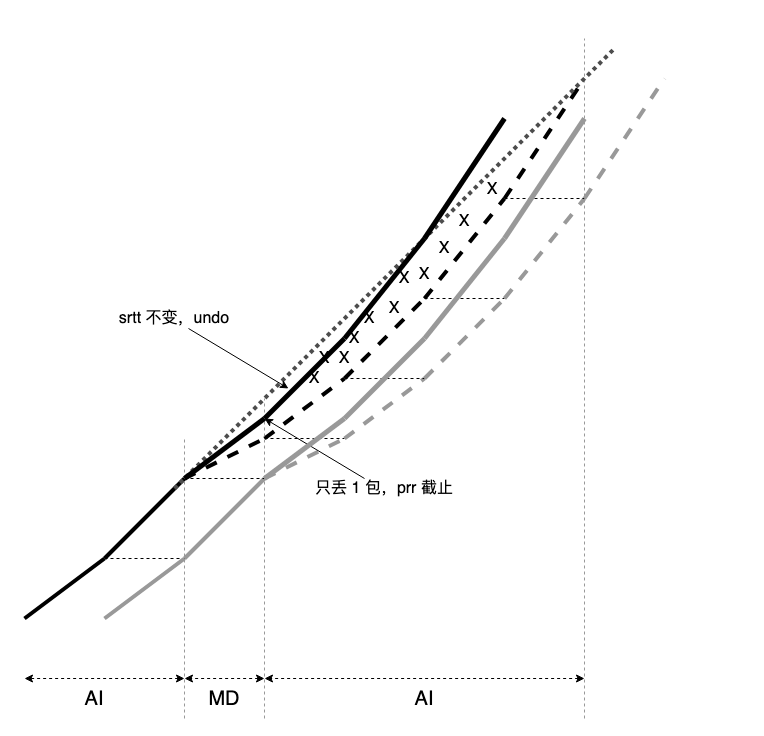
看图,虚划线是原始的,粗实线是改后的:
总结:
- 用丢包过程(数量和频度)驱动 prr 过程;
- 结合丢包时 srtt 决定恢复后是否 undo。
PS:你要把 bbr 的缺陷全克服了,它的吞吐就会变的和 cubic 差不多,最多只是 bugfix 级提升,且 bbr 已经这么做了,参考 bbr3。怎么会这样?因为 tcp ack 只带回那么些信息,信息量作用力有上限。带宽 x 的链路,必须用掉至少 a% 带宽作为代价做拥塞控制,有效吞吐最多 x - xa%,不要指望 a 能足够小,它其实是个确定数值,要做的是逼近 x - xa%,而不是 x。bbr 想多了。
但也不针对 bbr,所有 tcp 拥塞控制算法优化到极致后都存在不太高的上限,但它们的下限又足够低,所以提供了足够的岗位供我们瞎折腾,我们对此表示感谢🙏 。
如果你想提高上限,就要减小 a,但 a 是针对 tcp 的,所以,若要提高上限,必须往协议头里加东西,至于下限,无底线,有空比试比试看谁的吞吐低,但稳定。这并不是一件简单事,考 99 分很难,但不多也不少考 9 分也不容易。
浙江温州皮鞋湿,下雨进水不会胖。