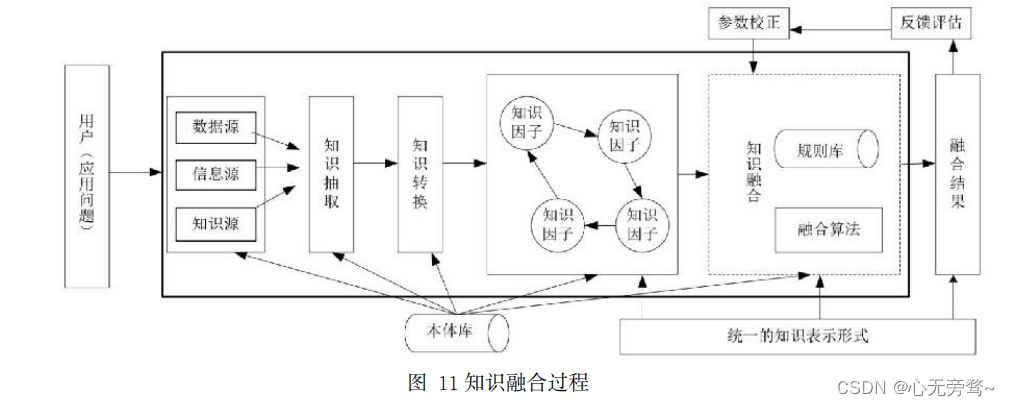
本章内容
- k-近邻分类算法
- 从文本文件中解析数据
前言
众所周知,电影可以按照题材分类,然而题材本身是如何定义的?由谁来判定某部电影属于哪个题材?也就是说同一题材的电影具有哪些公共特征?这些都是在进行电影分类时必须要考虑的问题。没有哪个电影人会说自己制作的电影和以前的某部电影类似,但我们确实知道每部电影在风格上的确有可能会和同题材的电影相近。那么动作片具有哪些共有特征,使得动作片之间非常类似,而与爱情片存在着明显的差别呢?动作片中也会存在接吻镜头,爱情片中也会存在打斗场景,我们不能单纯依靠是否存在打斗或者亲吻来判断影片的类型。但是爱情片中的亲吻镜头更多,动作片中的打斗场景也更频繁,基于此类场景在某部电影中出现的次数可以用来进行电影分类。本章第—节基于电影中出现的亲吻、打斗出现的次数,使用k-近邻算法构造程序,自动划分电影的题材类型。我们首先使用电影分类讲解k-近邻算法的基本概念,然后学习如何在其他系统上使用k-近邻算法。
本章介绍第一个机器学习算法:k-近邻算法,它非常有效而且易于掌握。首先,我们将探讨k-近邻算法的基本理论,以及如何使用距离测量的方法分类物品;其次我们将使用Python从文本文件中导人并解析数据。
1 k-近邻算法概述
简单地说,k-近邻算法采用测量不同特征值之间的距离方法进行分类。
优点:精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用数据范围:数值型和标称型。
k-近邻算法(kNN)的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一条数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类标签,作为新数据的分类。
现在我们回到前面电影分类的例子,使用k-近邻算法分类爱情片和动作片。有人曾经统计过很多电影的打斗镜头和接吻镜头,图2-1显示了6部电影的打斗和接吻镜头数。假如有一部未看过的电影,如何确定它是爱情片还是动作片呢?我们可以使用kNN来解决这个问题。

首先我们需要知道这个未知电影存在多少个打斗镜头和接吻镜头,图2-1中问号位置是该未知电影出现的镜头数图形化展示,具体数字参见表2-1。

即使不知道未知电影属于哪种类型,我们也可以通过某种方法计算出来。首先计算未知电影与样本集中其他电影的距离,如表2-2所示。此处暂时不要关心如何计算得到这些距离值,使用Python实现电影分类应用时,会提供具体的计算方法。
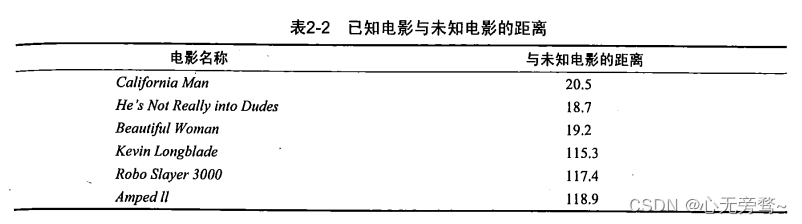
现在我们得到了样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到k个距离最近的电影。假定k=3,则三个最靠近的电影依次是He 's Not Really into Dudes、Beautiful Woman和California Man。k-近邻算法按照距离最近的三部电影的类型,决定未知电影的类型,而这三部电影全是爱情片,因此我们判定未知电影是爱情片。
本章主要讲解如何在实际环境中应用k-近邻算法,同时涉及如何使用Python工具和相关的机器学习术语。按照开发机器学习应用的通用步骤,我们使用Python语言开发k-近邻算法的简单应用,以检验算法使用的正确性。
k-近邻算法的一半流程:
(1)收集数据:可以使用任何方法。
(2)准备数据:距离计算所需要的数值,最好是结构化的数据格式。
(3)分析数据:可以使用任何方法。
(4)训练算法:此步骤不适用与k-近邻算法。
(5)测试算法:计算错误率。
(6)使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
1.1 准备: 使用python导入数据
import numpy as np
import operator
def createDataSet():
group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
在上面的代码中,我们导入了两个模块,第一个是科学计算包Numpy,第二个是运算符模块。k-近邻算法执行排序操作的时候会用到operator运算符模块提供的函数,后面我们将进一步介绍。
打开python编译器,本文用pycharm进行编译示范。用group和labels变量接收createDataset()函数的两个返回值并输出。
group, labels = createDataSet()
print(group)
print(labels)
# 输出如下:
[[1. 1.1]
[1. 1. ]
[0. 0. ]
[0. 0.1]]
['A', 'A', 'B', 'B']
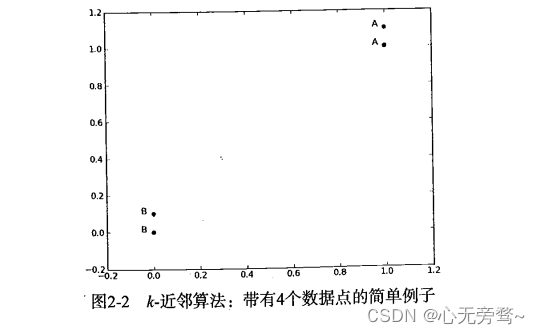
group输出的结果里面有4组数据,每组数据有两个我们已知的属性或者特征值。上面的group矩阵每行包含一个不同的数据,我们可以把它想象为某个日志文件中不同的测量点或者入口。由于人脑的限制,我们通常只能可视化处理三维以下的事务。因此为了简单地实现数据可视化,对于每个数据点我们通常只使用两个特征。
向量label包含了每个数据点的标签信息,label包含的元素个数等于group矩阵行数。这里我们将数据点(1,1.1)定义为类A,数据点(0,0.1)定义为类B。为了说明方便,例子中的数值是任意选择的,并没有给出轴标签,图2-2是带有类标签信息的四个数据点。
现在我们已经知道Python如何解析数据,如何加载数据,以及kNN算法的工作原理,接下来我们将使用这些方法完成分类任务。
1.2 从文本文件中解析数据
这里首先给出k-近邻算法的伪代码和实际的python代码,然后详细地解释每行代码的含义。其伪代码如下:
对未知类别属性的数据集中的每个点依次执行以下操作:
(1)计算已知类别数据集中的点与当前未知类别数据集中点之间的距离。
(2)按照距离递增次序排序。
(3)选取与当前点距离最小的k个点。
(4)确定前k个点所在类别的出现频率,按从小到大的排列返回索引列表。
(5)返回前k个点出现频率最高的类别作为当前点的预测分类。
python函数classify0()如程序清单2-1所示

classify0()函数有4个输人参数:用于分类的输人向量是inX,输入的训练样本集为dataSet,标签向量为labels,最后的参数k表示用于选择最近邻居的数目,其中标签向量的元素数目和矩阵dataset的行数相同。
程序清单2-1使用欧氏距离公式,计算两个向量点xA和xB之间的距离①:
d
=
(
x
A
0
−
x
B
0
)
2
+
(
x
A
1
−
x
B
1
)
2
d= \sqrt{(xA_0-xB_0)^2+(xA_1-xB_1)^2}
d=(xA0−xB0)2+(xA1−xB1)2
例如,点(0, 0)与(1,2)之间的距离计算为:
(
1
−
0
)
2
+
(
2
−
0
)
2
\sqrt{(1-0)^2+(2-0)^2}
(1−0)2+(2−0)2
如果数据集存在4个特征值,则点(1,0,0,1)与(7,6,9,4)之间的距离计算为:
(
7
−
1
)
2
+
(
6
−
0
)
2
+
(
9
−
1
)
2
+
(
4
−
1
)
2
\sqrt{(7-1)^2+(6-0)^2+(9-1)^2+(4-1)^2}
(7−1)2+(6−0)2+(9−1)2+(4−1)2
计算完所有点之间的距离后,可以对数据按照从小到大的次序排序。然后,确定前k个距离最小元素所在的主要分类2,输入k总是正整数;最后,将classCount字典分解为元组列表,然后使用程序第二行导人运算符模块的itemgetter方法,按照第二个元素的次序对元组进行排序③。·此处的排序为逆序,即按照从最大到最小次序排序,最后返回发生频率最高的元素标签。
完整代码如下:
import numpy as np
import operator
def createDataSet():
group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
group, labels = createDataSet()
print(group)
print(labels)
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
# 距离计算
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
print(sqDiffMat)
sqDistances = sqDiffMat.sum(axis=1) # 沿着1维降维,即把列全部压缩,只剩下一列,保留所有行
print(sqDistances)
distances = sqDistances**0.5
print(distances)
sortedDistIndicies = distances.argsort() # 返回数组值从小到大的索引值
print(sortedDistIndicies)
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
print(sortedDistIndicies[i])
print(voteIlabel)
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
print(classCount)
print(classCount.items())
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) # python3.x以上的版本中,iteritems()方法已经被删除,items()函数替代了它的功能,可以for循环遍历
print(sortedClassCount) # key = operator.itemgetter(1),指的是按照dict_items([('B', 2), ('A', 1)])中后一个元素进行排序,即2和1,如果是0的话就是按照B和A排序
return sortedClassCount[0][0] # reverse=True指的是降序,即按照从大到小,返回[0][0]获取最大标签出现次数的标签,也就是B
print(classify0([0, 0], group, labels, 3))
# 输出结果
# group矩阵
[[1. 1.1]
[1. 1. ]
[0. 0. ]
[0. 0.1]]
# labels标签列表
['A', 'A', 'B', 'B']
[[1. 1.21]
[1. 1. ]
[0. 0. ]
[0. 0.01]]
[2.21 2. 0. 0.01]
[1.48660687 1.41421356 0. 0.1 ]
# 从小到大的索引
[2 3 1 0]
2
B
3
B
1
A
# classCount的内容
{'B': 2, 'A': 1}
# 使用items返回字典内容为列表
dict_items([('B', 2), ('A', 1)])
# 使用itemgetter对第二个元素也就是数字2和1进行从大到小排序后的结果。
[('B', 2), ('A', 1)]
# 输出最终结果,也就是标签次数出现最多的结果B
B