1. 非类型模板参数
模板参数分类类型形参与非类型形参。
类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。
非类型形参,就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
//#define N 100
template<class T,size_t N=10>//非类型模板参数
//这里N还可以给缺省值,模板参数和函数参数是十分相似的
class array
{
private:
T _a[N];
};
int main()
{
array<int>a0;
array<int,100>a1;
array<double,1000>a2;
return 0;
}
//非类型模板参数只能用于整形
//非类型模板参数表达是常量,传也得常量
//这里的 array<int,10> a1;
// int a1[10];
//看起来没有区别,只是表达形式的不同,都没有初始化
//两个真正的区别是关于越界的检查,数组是对于越界进行抽查,但是array<int,10>这种
//一定会被查到,对于数组正常的写法来说,是首元素的地址进行加访问的,是指针的解引用,array<int,10>是
//函数调用
2. 模板的特化
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结 果,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板
struct date
{
date(int year,int month,int day)
:_year(year)
,_month(month)
,_day(day)
{}
bool operator>(const date &d)const
{
if ((_year > d._year) || (_year == d._year && _month > d._month) ||
(_year == d._year && _month == d._month && _day > d._day))
{
return true;
}
else
{
return false;
}
}
int _year;
int _month;
int _day;
};
template<class T>
bool Greater(T left, T right)
{
return left > right;
}
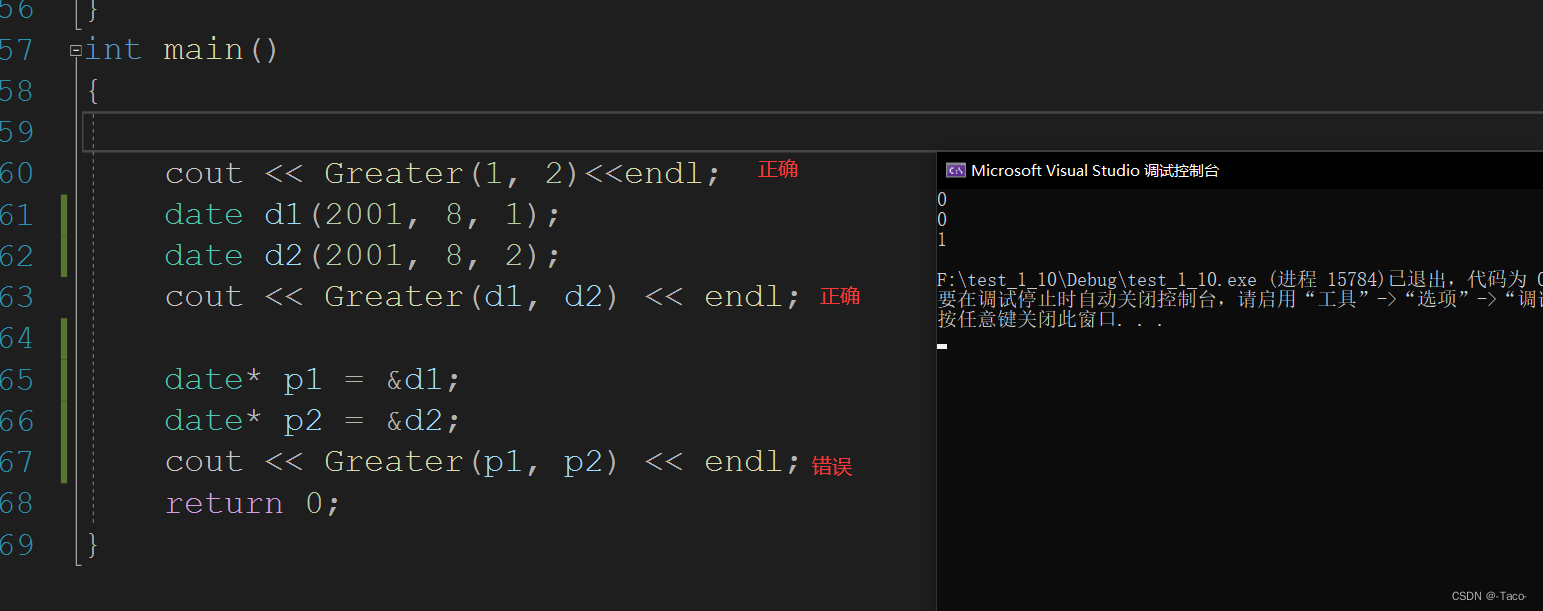
int main()
{
cout << Greater(1, 2)<<endl;
date d1(2001, 8, 1);
date d2(2001, 8, 2);
cout << Greater(d1, d2) << endl;
date* p1 = &d1;
date* p2 = &d2;
cout << Greater(p1, p2) << endl;
return 0;
} 


处理方法同上:
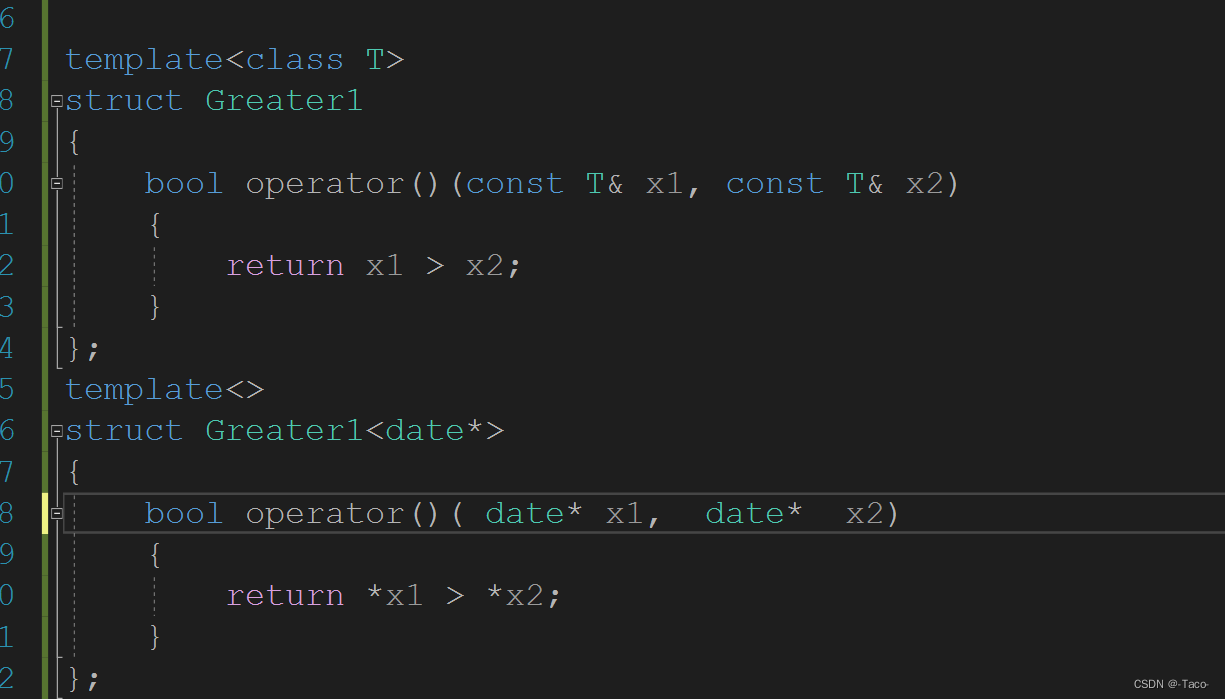

以及在优先级队列中存储的时候也会出现特化的情况
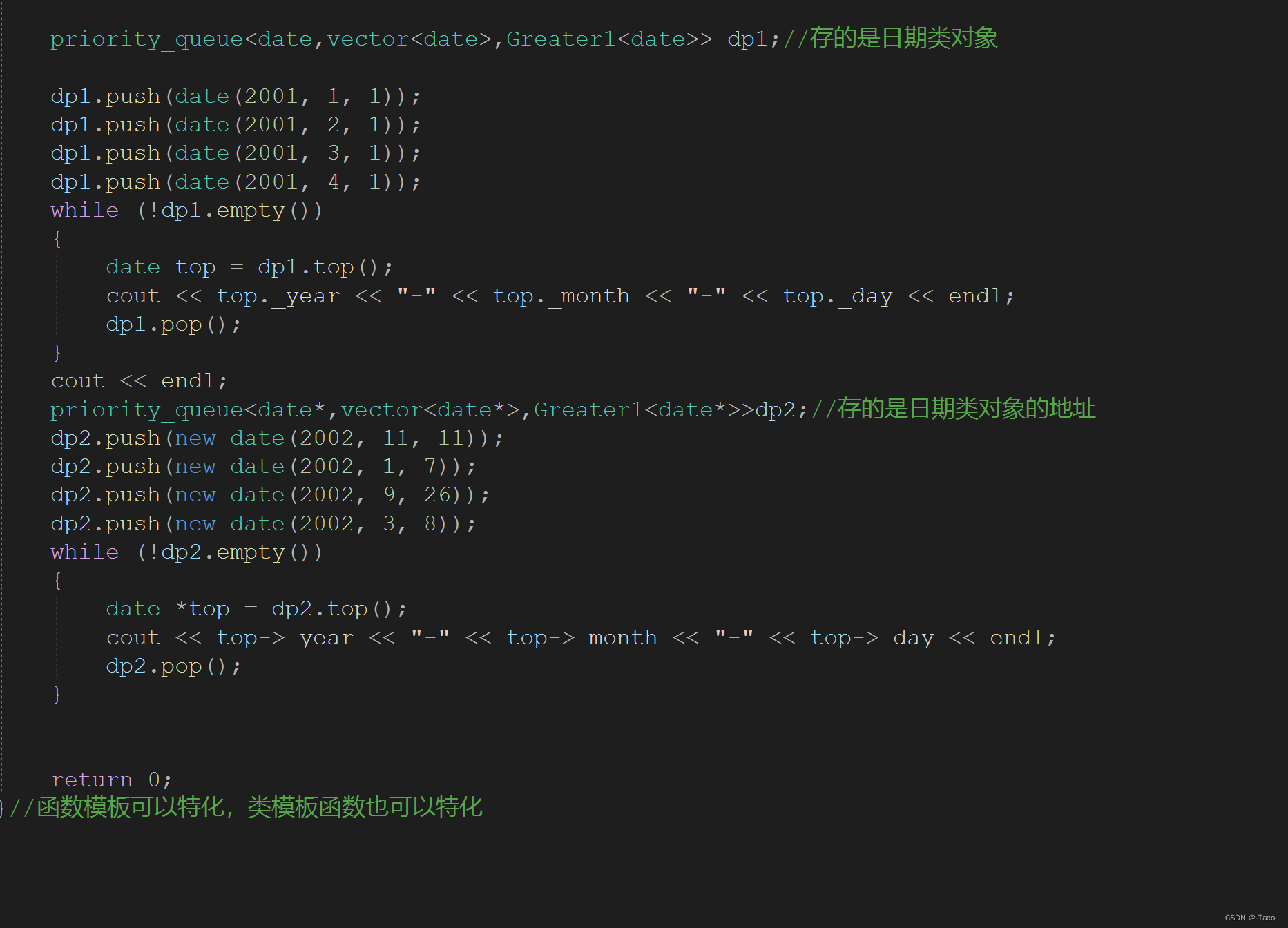
如果第二个priority_queue不使用特化,则date*这种情况会出现各种的结果不会按照我们输入的大堆排法;
函数模板的特化步骤:
1. 必须要先有一个基础的函数模板
2. 关键字template后面接一对空的尖括号<>
3. 函数名后跟一对尖括号,尖括号中指定需要特化的类型
4. 函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
类模板特化
全特化
全特化即是将模板参数列表中所有的参数都确定化。
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
template<>
class Data<int, char>
{
public:
Data() { cout << "Data<int, char>" << endl; }
private:
int _d1;
char _d2;
};
void TestVector()
{
Data<int, int> d1;
Data<int, char> d2;
}
int main()
{
TestVector();
return 0;
}如果是偏特化的话:
偏特化:
偏特化:任何针对模版参数进一步进行条件限制设计的特化版本。比如对于以下模板类:
偏特化有以下两种表现方式:
部分特化 将模板参数类表中的一部分参数特化
template<class T1>
class Data<T1, int>
{
public:
Data()
{
cout << "Data<T1,int>" << endl;
}
private:
T1 _d1;
int _d2;
};
有了这个Data<T1,int>之后,如果Data<int,int>也走的是这个部分特化,这里可以特化各种带引用的,带指针的各种类型,但是其实本质都一样,走的是更加匹配的那一个。
typename跟class在模板的使用的时候,功能是一样的template<class T>和template<typename T>
但是typename比class还多一个用处,就是在为实现的类比如自己实现的vector的时候,如果想分离编译,想把函数写在类外,假设我们在lrx的命名空间里去实现,如果分离编译,写insert的话,肯定先写lrx::vector<T>::iterator lrx::vector<T>::insert(lrx::vector<T>::iterator pos,const T&x);这里会报错,在这之前要加上typename,
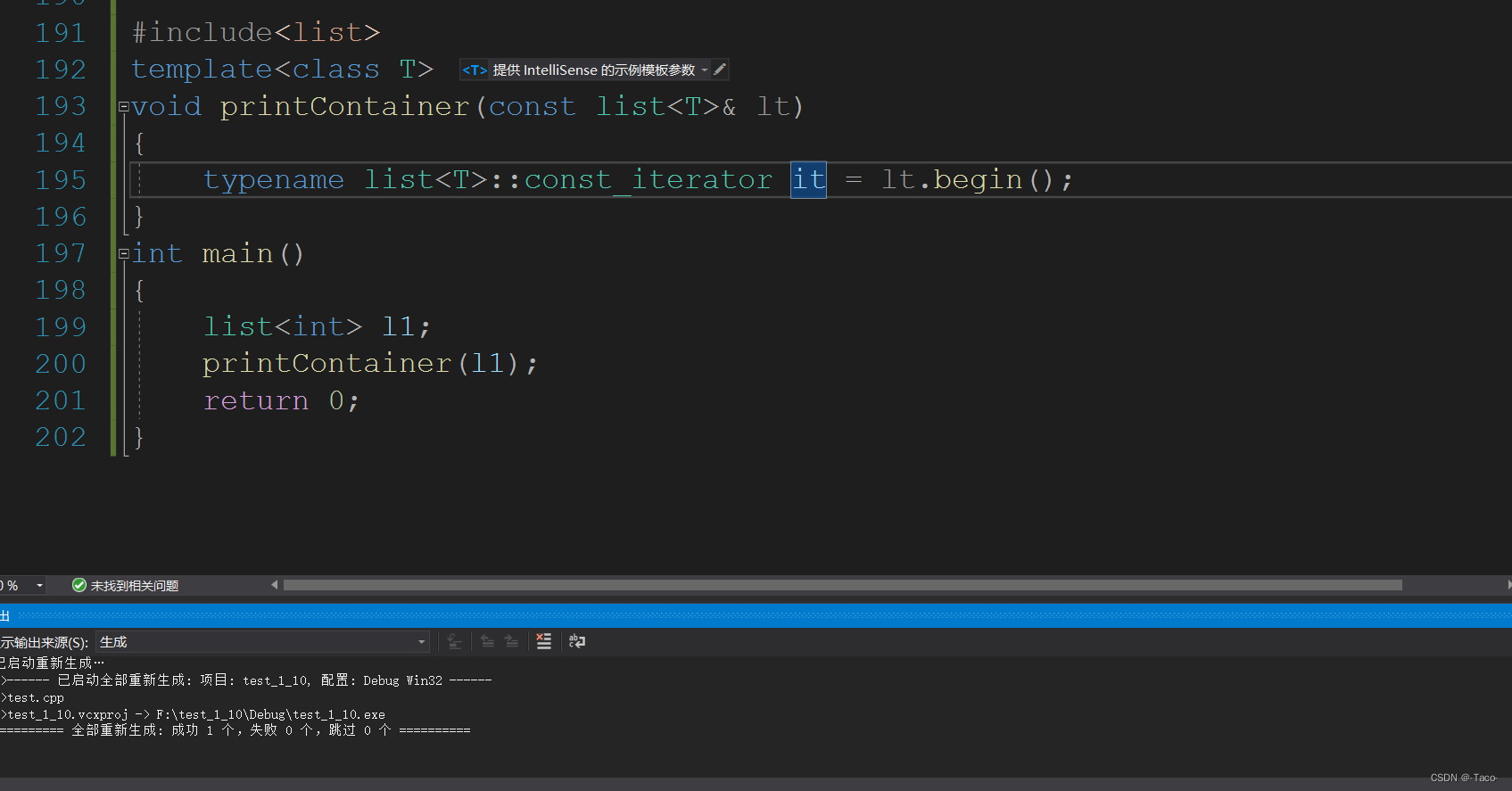
typename lrx::vector<T>::iteratorlrx::vector<T>::insert(typename lrx::vector<T>::iterator pos,const T&x); typename 是告诉编译器前面是一个类型,在还没有实例化的模板的情况下,要使用typename告诉编译器有这是一个类型。因为编译器这里无法区分这是类型还是变量,变量的话,静态的指定类域就可以访问,静态的也可以类似如此访问,静态的就可以这样访问就是变量访问,所以加一个typename告诉编译器这是未实现的类型。
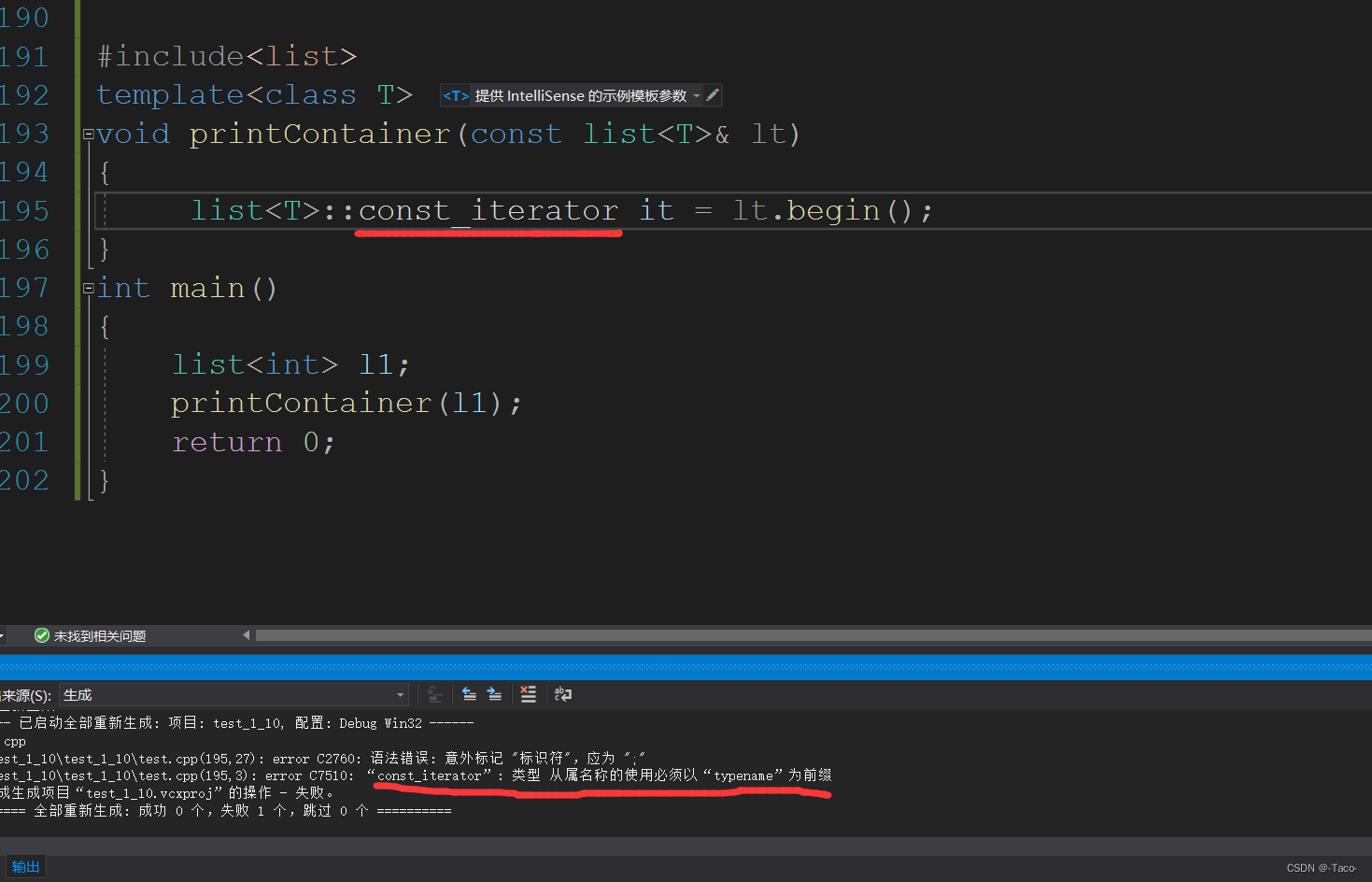
就比如这种情况下,编译器就无法得知,这个const迭代器到底是变量还是类型,所以要在前面加上typename。
3 模板分离编译
3.1 什么是分离编译 一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链 接起来形成单一的可执行文件的过程称为分离编译模式。
// a.h
template<class T>
T Add(const T& left, const T& right);
// a.cpp
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
// main.cpp
#include"a.h"
int main()
{
Add(1, 2);
Add(1.0, 2.0);
return 0;
}
分析:
C/C++程序运行的时候,一边要经历以下的步骤:
预处理-->编译-->汇编-->链接
编译:对程序按照语言特性进行词法语法,语义分析,检查无误之后,生成汇编代码,注意头文件不参与编译,编译器对工程中多个源文件是分离单独编译的。
链接:将多个obj文件 合并成一个,并且处理没有解决地址问题。
a.cpp和,main.cpp分别生成a.obj和main.obj
在a.cpp中,编译器没有看到对add模板函数的实例化,因此不会形成具体的加法函数,在main.obj中调用add<int>和add<double>,编译器在链接时才会找到其地址,但是这两个函数没有实例化生成具体代码,因此在链接的时候报错。
解决方法 1. 将声明和定义放到一个文件 "xxx.hpp" 里面或者xxx.h其实也是可以的。推荐使用这种。 2. 模板定义的位置显式实例化。这种方法不实用,不推荐使用。
第二种比较麻烦不推荐使用。,很容易把模板写死了。
模板总结
【优点】
1. 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
2. 增强了代码的灵活性
【缺陷】
1. 模板会导致代码膨胀问题,也会导致编译时间变长
2. 出现模板编译错误时,错误信息非常凌乱,不易定位错误