文献:Fast Adaptive Task Offloading in Edge Computing based on Meta Reinforcement Learning
基于深度强化学习DRL的方法,样本效率很低,需要充分的再培训来学习新环境的更新策略,对新环境的适应性很弱。
基于元强化学习的任务卸载方法,可以通过少量的梯度更新和样本快速适应新环境。
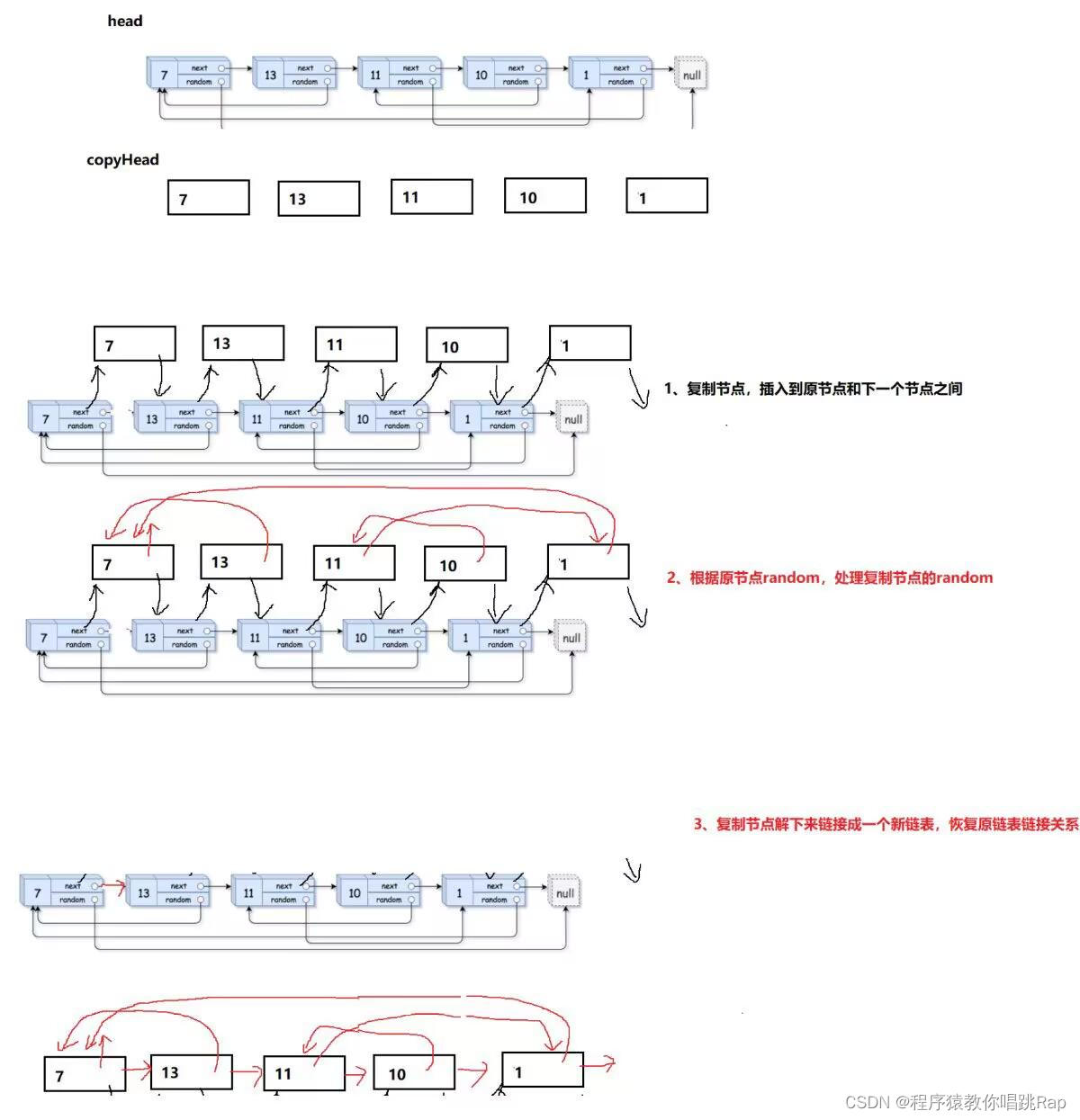
将移动应用程序建模为有向无环图(DAG),并通过自定义序列到序列(seq2seq)神经网络来卸载策略。提出了一种将一阶近似和裁剪的替代目标相结合的方法,训练seq2seq网络。
一、介绍
启发式算法严重依赖于MEC系统的专家知识或精确数学模型,用户设备系统环境发生改变时需要改变相应的数学模型。特定的启发式/近似算法很难完全适应MEC应用程序和架构日益复杂而产生的动态MEC场景。
深度强化学习(DRL)将强化学习(RL)与深度神经网络(DNN)相结合,可以学习通过试错来解决复杂问题,而无需对环境进行精确建模。对于意外扰动或不可见的情况(如应用程序、任务数或数据速率的变化)的适应性较弱。
元学习通过利用一系列学习任务中的先前经验来显著加快新任务的学习。
元强化学习(MRL)旨在通过建立以前的经验,在与环境的少量交互中学习新任务的策略。
MRL进行两个学习“循环”,一个“外循环”,它使用其在许多任务上下文中的经验来逐步调整元策略的参数,元策略控制“内循环”的操作。基于元策略,“内部循环”可以通过少量梯度更新快速适应新任务。
MRL好处:可以基于新移动用户的本地数据和元策略快速学习新移动用户特定的策略。提高学习新任务的训练效率,并使卸载算法更适应动态MEC环境。
一阶MRL算法与序列到序列(seq2seq)神经网络相结合。所提出的方法学习所有用户设备UE的元卸载策略,并基于元策略和本地数据快速获得每个UE的有效策略。
二、背景
- 多址边缘计算
任务卸载的目标是找到将应用程序划分为两组计算任务的最佳策略,其中一组在UE上执行,另一组卸载到MEC主机,从而使总运行成本最小化。 - 强化学习
强化学习考虑从环境中学习,以使累积的回报最大化。 - 元强化学习
MRL通过元学习增强了传统的RL方法,元学习旨在学习一种学习算法,该算法可以快速找到从任务分布中提取的学习任务的策略。
基于一阶MRL实现MRLCO,因为它的计算成本低、性能好,并且在与seq2seq神经网络结合时易于实现。
三、问题制定
任务被卸载,执行有三个步骤。
- 用户设备通过无线信道向MEC主机发送任务。
- MEC主机运行接收到的任务。
- 任务的运行结果被返回给UE。
每个步骤的延迟与任务配置文件和MEC系统状态有关。
任务配置文件包括运行任务所需的CPU周期、发送的任务的数据大小、数据和接收的结果数据。
MEC系统状态还包含无线上行链路信道的传输速率和下行链路信道的速率。
如果任务在UE上本地运行,则在UE上只有运行延迟。任务卸载过程的端到端延迟包括本地处理、上行链路、下行链路和远程处理延迟。
资源可用时间取决于紧接在该资源上ti之前安排的任务的完成时间。如果紧接在ti之前调度的任务没有使用资源,我们将资源的完成时间设置为0。
如果任务ti被卸载到MEC主机,则ti只能在其父任务全部完成且上行链路信道可用时开始发送其数据。
如果在UE上调度ti,则ti的开始时间取决于其父任务的完成时间和UE的可用时间。
NP-hard:由于DAG拓扑结构和MEC系统状态高度动态,寻找最佳卸载计划可能极具挑战性。
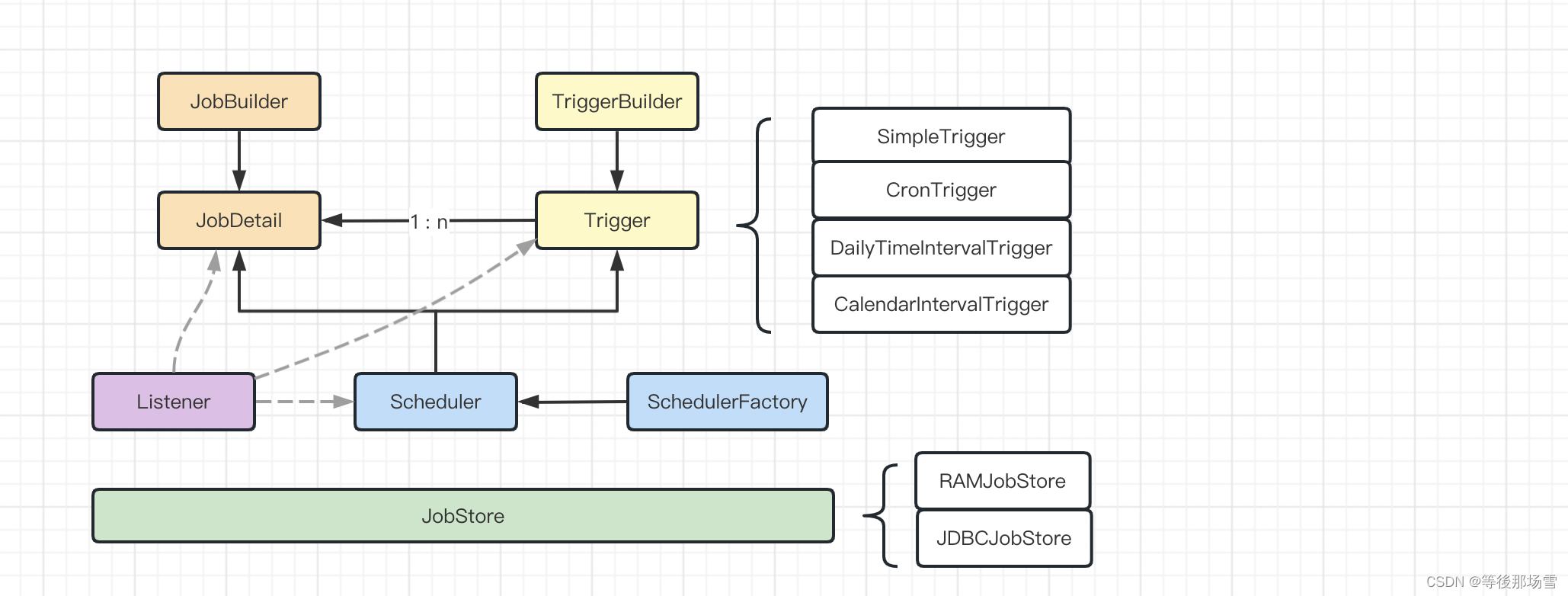
四、MRLCO:一种基于MRL的计算卸载解决方案
MRLCO授权MEC系统架构
训练过程:任务特定策略的“内循环”训练和元策略的“外循环”训练。“内环”训练在UE上进行,而“外环”训练在MEC主机上进行。
MEC主机包含MEC平台和提供计算、存储和网络资源的虚拟化基础设施。MEC平台提供交通规则控制和域名处理并提供边缘服务。MRLCO的五个关键模块(解析器、本地培训器、卸载调度器、全局培训服务和远程执行服务)。
解析器旨在将移动应用程序转换为DAG。
本地培训器负责“内环”训练,从解析器接收解析的DAG作为培训数据,并通过本地传输单元向MEC主机上传/下载策略网络的参数。
卸载调度器用于通过策略网络推断做出卸载决策。
全局训练服务用于管理“外环”训练,该训练向UE发送/从UE接收策略网络的参数,并在MEC主机中的虚拟化基础设施上部署全局训练过程。
远程执行服务负责管理从UE卸载的任务,将这些任务分配给相关联的VM,并将结果发送回UE。
MRLCO培训流程:
用户设备从MEC主机下载元策略参数;
基于元策略和本地数据在每个用户身上运行“内循环”训练,以获得任务特定策略;
用户设备将任务特定策略的参数上载到MEC主机;
MEC主机根据收集到的任务特定策略参数进行“外循环”训练,生成新的元策略。
将计算卸载过程建模为多个MDP(马尔可夫决策过程)
学习过程:在所有MDP中有效学习元策略,并基于元策略快速学习一个MDP的特定卸载策略。
MDP的状态、行动和奖励定义:
状态定义为编码DAG和部分卸载计划的组合。调度任务时,运行任务的延迟取决于任务配置文件、DAG拓扑、无线传输速率和MEC资源状态。
子任务转换为包含三个元素的嵌入:
1)嵌入当前任务索引和标准化任务配置文件的向量,
2)包含直接父任务索引的向量,
3)包含直接子任务索引的矢量。
行动:任务调度是二进制选择,0表示在用户设备执行,1表示卸载。
奖励函数定义为在为任务做出卸载决策后延迟的估计负增量。
seq2seq神经网络:编码器和解码器组成。编码器和解码器都由递归神经网络实现。编码器的输入是任务嵌入序列,解码器的输出是每个任务的卸载决策。
注意力机制允许解码器在输出生成的每个步骤关注源序列的不同部分。
在seq2seq神经网络加入注意力机制,减轻原始seq2seq神经网络导致的信息丢失问题。
长短时记忆LSTM
基于元强化学习的计算卸载MRLCO的实施
“内环”策略梯度方法是基于近端策略优化(PPO)定义目标函数,与标准策略梯度算法(VPG)相比,PPO具有更好的探索能力和训练稳定性。
五、绩效评估
MRLCO、微调DRL方法、启发式算法(基于HEFT、贪婪)对比
算法超参数
seq2seq神经网络的编码器和解码器都设置为两层动态长短期记忆(LSTM),每层具有256个隐藏单元。
仿真环境
List scheduling algorithm for heterogeneous systems by an optimistic cost table
实现一个合成DAG生成器(如图),模拟异构DAG。有四个参数控制生成的DAG拓扑和任务配置文件。任务数量;DAG的高度和宽度;DAG两个级别之间的边缘数量;任务的通信和计算成本之间的比率。

数据集分为训练数据集和测试数据集。
MRLCO首先使用算法1学习基于“训练数据集”的元策略。然后,学习的元策略被用作初始策略,以快速学习“测试数据集”的有效卸载策略。
结果分析
- 生成具有不同拓扑的DAG集,以模拟用户对移动应用程序有不同偏好的场景。
贪婪算法具有最高的延迟,而MRLCO获得最低的延迟。MRLCO可以比微调DRL方法更快地适应新任务。
基于启发式的算法使用固定策略来获得卸载计划,这不能很好地适应不同的DAG拓扑。 - 任务数对不同算法性能的影响。
MRLCO获得了最低的延迟。 - 评估不同传输速率下MRLCO的性能。
通过彻底搜索解空间来实现最优算法,以找到最优卸载计划。
MRLCO低延迟、快速适应新的学习任务。 - 不同测试数据集上所有算法的平均延迟。
MRLCO优于启发式算法,但与最佳值之间存在差距。
可能的解决方案:将seq2seq神经网络与另一种样本有效的非策略MRL方法结合。
六、相关工作
Deep reinforcement learning-based joint task offloading and bandwidth allocation for multi-user mobile edge computing 基于DRL的卸载框架,该框架联合考虑了卸载决策和资源分配。
Deep reinforcement learning-based offloading scheduling for vehicular edge computing 结合PPO和卷积神经网络的高效任务卸载方法。
Optimized computation offloading performance in virtual edge computing systems via deep reinforcement learning 基于DRL的在线卸载框架,以最大化所有UE的计算速率的加权和。
Deep reinforcement learning for vehicular edge computing: An intelligent offloading system 基于深度Q学习的方法,用于联合优化MEC中的任务卸载和资源分配。
将卸载问题假设为一个学习任务,采用了MRL方法,该方法可以有效地解决新的学习任务,只需要很少的梯度更新步骤和少量数据。
七、讨论
MRLCO优点:
学习在动态环境中快速适应和高采样效率,应用于解决MEC系统的更多决策问题;实现移动用户的高服务质量并减少网络流量。
大规模操作时,掉队的用户设备可能会因为网络连接中断或功率不足而退出,影响MRLCO训练性能。
解决这个问题的一种方法:自适应客户端选择算法,该算法可以自动过滤掉掉队者,并根据其运行状态选择可靠的客户端加入训练过程。
八、结论
MRLCO可以在少量梯度更新和样本内快速适应新的MEC环境。目标移动应用程序被建模为DAG,计算卸载过程被转换为序列预测过程,并且提出了seq2seq神经网络来有效地表示策略。通过对MRL目标采用一阶近似,以降低训练成本,并为目标添加替代剪辑,以稳定训练。