基本思想:
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个整数,把待排序文件中所有记录分成个组,所有距离为的记录分在同一组内,并对每一组内的记录进行排序。然后,取,重复上述分组和排序的工作。当gap=1时,所有记录在统一组内排好序。
希尔排序:
希尔排序分为两个步骤:
1.预排序——接近有序(gap>1)
2.插入排序(gap==1)
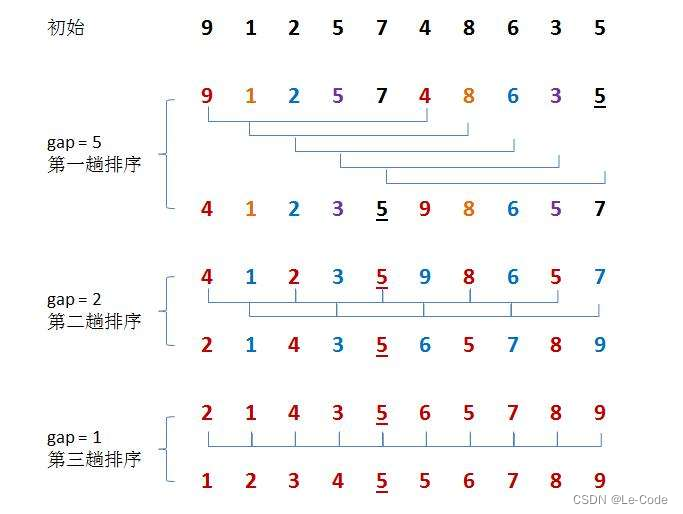
1.预排序:

比如先排红色组:

再排蓝色组:

最后排绿色组:

代码分析:
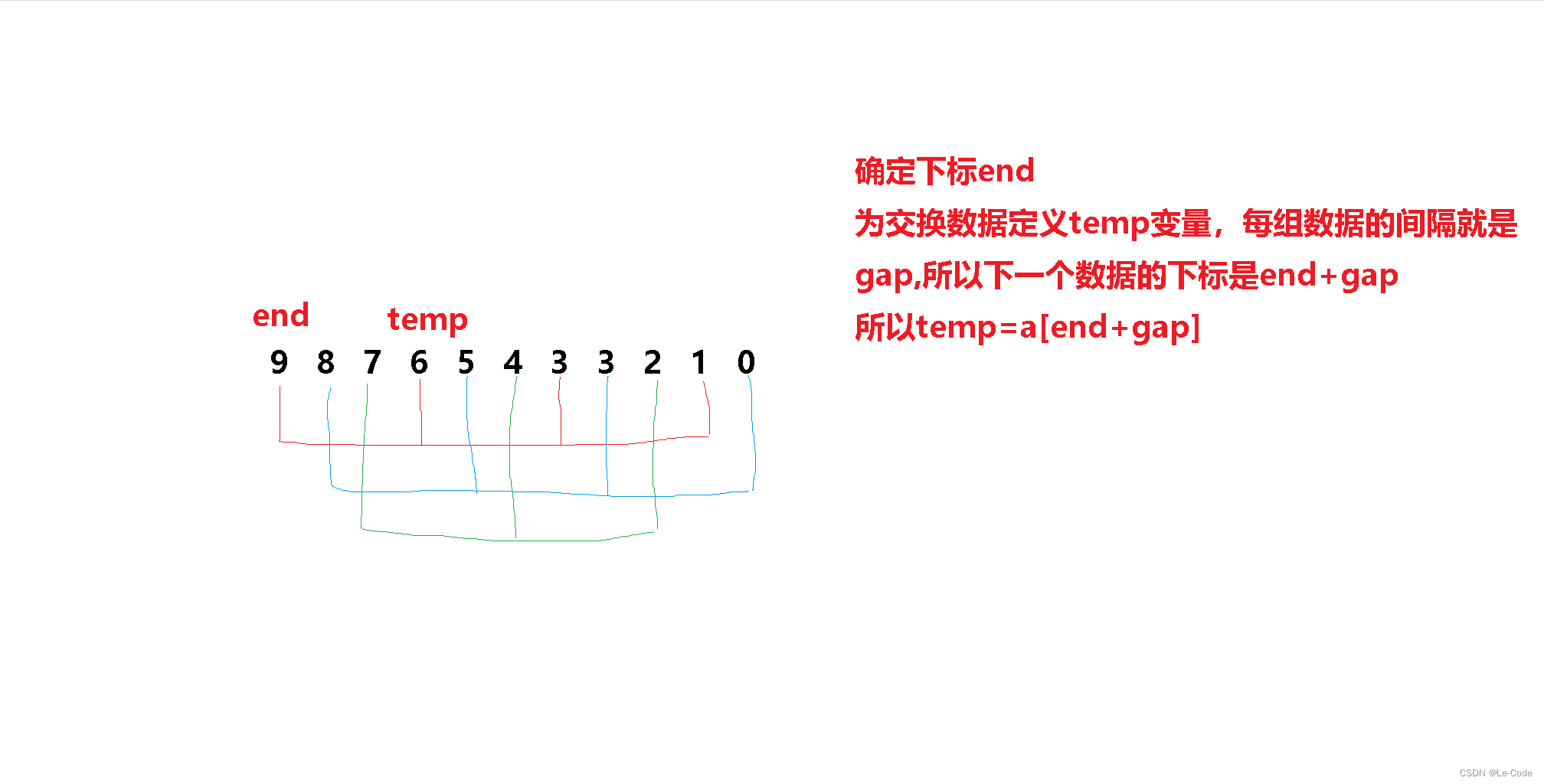
end的后一个输入往前插入:
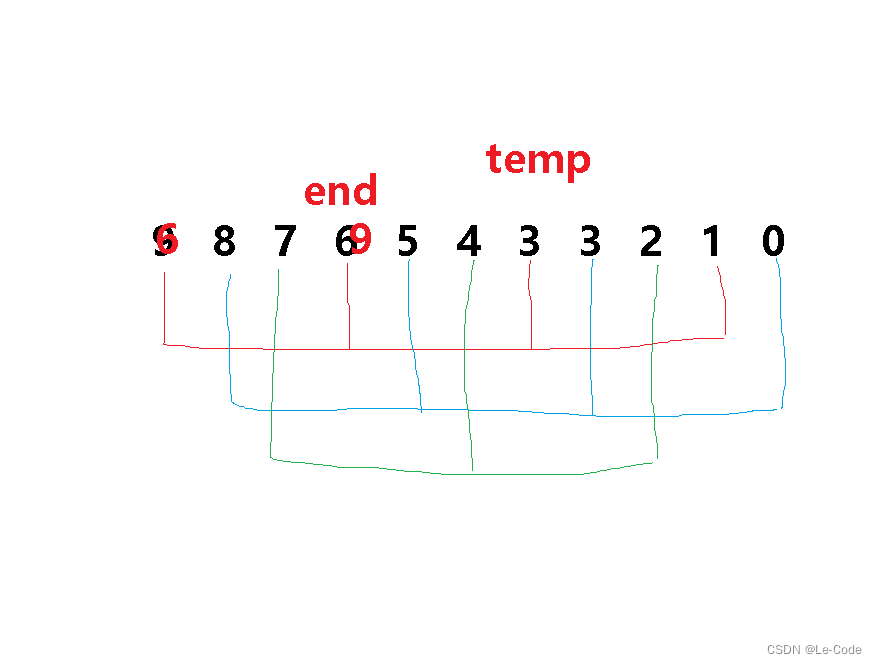
依此类推 ,完成红色组的排序
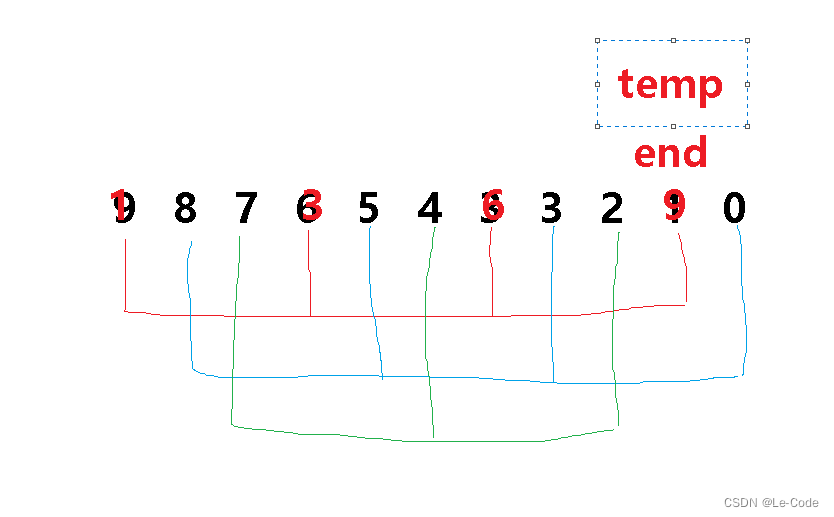
依此类推,完成所有组的预排序

2.插入排序:
当我们的gap==1的时候,我们就可以直接用我们的插入排序完成最后的排序了。数据结构——插入排序-CSDN博客
//sort.c
void ShellSort(int* a, int n)
{
//1、gap>1 预排序
//2、gap==1 直接插入排序
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;//+1可以保证最后一次一定是1
for (int i = 0; i < n - gap; i++)
{
int end = i;//完成一组数据的预排序,从第一组开始
int temp = a[end + gap];
while (end >= 0)
{
if (a[end] > temp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = temp;
}
}
}//test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "sort.h"
void TestShellSort()
{
int a[] = { 9,8,7,6,5,4,3,3,2,1,0 };
PrintArray(a, sizeof(a) / sizeof(int));
ShellSort(a, sizeof(a) / sizeof(int));
PrintArray(a, sizeof(a) / sizeof(int));
}
int main()
{
TestShellSort();
return 0;
}//sort.h
#pragma once
#include <stdio.h>
void ShellSort(int* a, int n);
void PrintArray(int* a, int n);
运行结果:

希尔排序的特性总结:
1. 希尔排序是对直接插入排序的优化。
2. 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
3. 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些书中给出的希尔排序的时间复杂度都不固定,列如:

《数据结构-用面相对象方法与C++描述》--- 殷人昆

因为快速排序的出现让希尔排序并没有人再进行进一步的优化,但是不可否认的是希尔排序是能与快速排序上同一桌吃饭的人,下面我们来做一组测试:
//test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "sort.h"
void TestOP()
{
srand(time(0));
const int N = 100000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
int begin3 = clock();
QuickSort(a3, 0, N - 1);
int end3 = clock();
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("QuickSort:%d\n", end3 - begin3);
free(a1);
free(a2);
free(a3);
}
int main()
{
TestOP();
return 0;
}//sort.c
void ShellSort(int* a, int n)
{
//1、gap>1 预排序
//2、gap==1 直接插入排序
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;//+1可以保证最后一次一定是1
for (int i = 0; i < n - gap; i++)
{
int end = i;//完成一组数据的预排序,从第一组开始
int temp = a[end + gap];
while (end >= 0)
{
if (a[end] > temp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = temp;
}
}
}
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; ++i)
{
// [0, end] 有序,插入tmp依旧有序
int end = i;
int tmp = a[i + 1];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
int PartSort(int* a, int left, int right)
{
int keyi = left;
while (left < right)
{
// 右边找小
while (left < right && a[right] >= a[keyi])
{
--right;
}
// 左边找大
while (left < right && a[left] <= a[keyi])
{
++left;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);
return left;
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
int keyi = PartSort(a, begin, end);
// [begin, keyi-1] keyi [keyi+1, end]
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}
//sort.h
#pragma once
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
void ShellSort(int* a, int n);
void PrintArray(int* a, int n);
void InsertSort(int* a, int n);
void QuickSort(int* a, int begin, int end);运行结果:

通过运行结果我们可以看到,在十万数据的当量下,希尔排序和快速排序的差别并不是很大,而我们的插入排序只能沦落到小孩那一桌去了。


PS:看到这里了,码字不易,给个一键三连鼓励一下吧!有不足或者错误之处欢迎在评论区指出!




![[淘宝销量]—采集分析—实例参考▶](https://img-blog.csdnimg.cn/direct/978115f9407f4f8a9c4a1601e2967c9d.gif)
