[干货]
本文爬取淘宝的搜索结果,包含标题、价格、原价、店铺、月销量字段。将结果保存成csv格式,并作简单分析。以手机为例。【淘宝销量】
用到的python库:selenium、urllib、pyquery、pandas。
1.爬取页面分析
1.1 获取URL
打开淘宝,在搜索框中输入“手机”并按回车键,会看到关于手机的搜索结果:
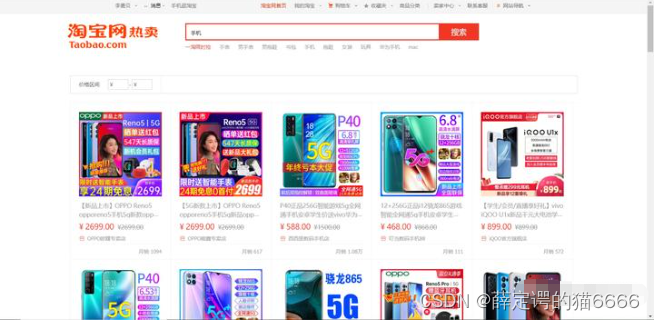
拉到页面最下面,只有上一页、下一页、首页三个按钮,看不到搜索结果总共有多少页。按F12打开开发者工具,然后刷新页面,可以在网络监听中找到页面的URL:

其中,keyword参数即我们搜索的关键词“手机”,pnum代表页数(从0开始)。我们试着把其中不必要的参数去掉,构造URL:
1.2获取页面元素
现在我们已经得到了URL,接下来尝试获取所需字段所在页面元素中的位置。点击开发者工具中的Elements、接着点击左边的箭头符号按钮,将鼠标定位在手机展示结果页面,可以看到手机信息所在的位置:
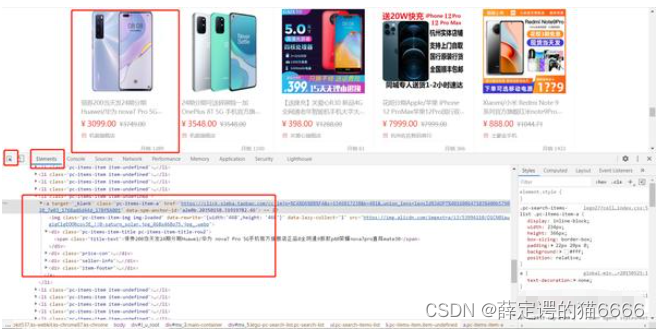
每个手机信息保存在class=pc-items-item item-undefined的li标签中,依次按上述点击标题、价格等字段,可以得到每个元素的具体位置。那么,我们可以通过改变URL里的页数参数,获取该页的网页源代码,然后使用pyquery库获取我们想要的元素。
2.爬虫代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import urllib.parse
from pyquery import PyQuery as pq
import pandas as pd
def scratch_page(driver, url, page):
"""获取网页源代码"""
wait = WebDriverWait(driver, 10)
retry_num = 0
while retry_num < 3: # 如果打开页面失败,则最多重复三次
try:
driver.get(url % (urllib.parse.quote(keyword), page))
# 等待页面加载完成
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '.pc-search-page-item-after'), '下一页'))
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.pc-search-items-list li')))
retry_num = 3
except:
retry_num += 1
return driver
def goods(html):
"""获取单页的所有商品"""
# 解析网页源代码
doc = pq(html)
# 抓取字段:标题、价格、原价、店铺名、月销量
items = doc('.pc-search-items-list').children('li')
for item in items.items():
title = item.find('.title-text').text() # 标题
discount_price = item.find('.coupon-price-afterCoupon').text() # 价格
original_price = item.find('.coupon-price-old').text() # 原价
shop = item.find('.seller-name').text() # 店铺
monthly_sales = item.find('.sell-info').text() # 月销量
yield [title, discount_price, original_price, shop, monthly_sales]
def main(keyword, total_pages):
url = 'https://uland.taobao.com/sem/tbsearch?keyword=%s&pnum=%d'
chrome_options = Options()
chrome_options.add_argument('--headless') # 设置无头chrome
driver = webdriver.Chrome(options=chrome_options)
goods_list = pd.DataFrame(columns=['category', 'title', 'discount', 'original_price', 'shop', 'monthly_sales'])
# 按页爬取
for page in range(total_pages + 1):
print('正在抓取第%d页...' % (page + 1))
driver = scratch_page(driver, url, page)
html = driver.page_source
items = goods(html)
for item in items:
item.insert(0, keyword)
goods_list.loc[len(goods_list)] = item
# 将结果保存到csv中
goods_list.to_csv('淘宝商品_%s.csv' % keyword, index=False, encoding='utf-8-sig')
driver.close()
print('\n抓取完成')
return
if __name__ == '__main__':
keyword = '手机'
total_pages = 16 # 每页60
main(keyword, total_pages)3.爬取结果
爬下来的原始数据总共有1000条,结果中包含了手机壳、蓝牙耳机等非手机数据,需要做进一步数据清洗。

4.数据清洗和可视化
4.1数据清洗
1.首先将月销量处理成数字:将"月销 "替换成"",字段值含"万"的调整成数值型并乘以10000。
2.店铺名含特殊字符,从第二位开始截取作为店铺名。
3.将原价中的"¥"替换成"",并将该字符转换成数值型。
4.将标题中含'手机壳|眼镜|洗手机|sim|蓝牙|播放器|飞行器|发动机|数据恢复|换屏|手表|手环|维修|电视|家用|自信|监控|音响|热水器|打印机|扳手|通用|电脑|手链|音箱|监测仪|男|定位|服装|神器|基因|吉它|话筒|女|大疆|头戴|洗碗机'这些字符的记录剔除掉。
5.将以上步骤处理后的结果去重。
经过数据清洗,总共得到337条有效数据。










![[华为OD] B卷 树状结构查询 200](https://img-blog.csdnimg.cn/direct/2b90720440444b5d82451cf5898ea1d3.png)
![[C/C++] -- DFS搜索迷宫路径](https://img-blog.csdnimg.cn/direct/07288dddba6346efb3fc57bf2ce7dddf.png)