IvorySQL本身就是一个100%兼容PostgreSQL最新内核的开源数据库系统,而Neon Autoscaling Platform通常支持多种数据库和应用程序。将IvorySQL集成到该平台后,可以进一步增强与其他系统和应用程序的兼容性,同时更全面的体验IvorySQL的Oracle兼容功能带来的便利和优势,为用户提供更加灵活和多样化的选择。
在这篇文章中,我们将演示如何将 IvorySQL集成到 Neon Autoscaling Platform 的过程,引导您完成每个步骤,并提供清晰的说明和演示。
01
什么是Neon Autoscaling?
Neon的弹性伸缩功能为付费用户提供了极大的便利,该功能能够根据当前负载动态调整分配给Neon计算节点的计算资源量,无需用户进行繁琐的手动干预。
Neon Autoscaling的基本架构如下所示。有关更多详细信息,您可以参考这里。
https://docs.ivorysql.org/en/ivorysql-doc/v3.2/v3.2/8#architecture-overview
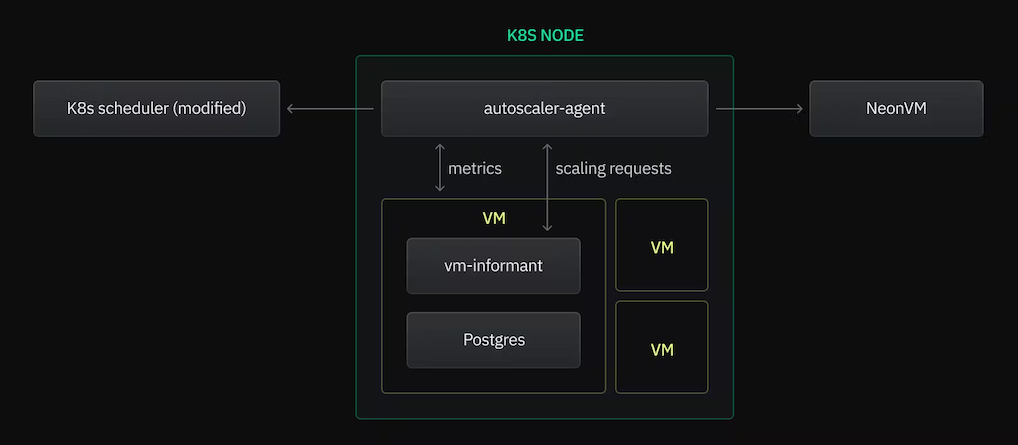
弹性缩放主要功能:
>>>实时迁移
当Kubernetes集群中的节点负载趋于饱和时,NeonVM会管理实时迁移VM的流程,确保以最小的中断(通常仅约100毫秒)将VM从一台计算机无缝转移至另一台计算机。这一实时迁移机制不仅能在节点达到容量极限前主动减少负载,还能极大地提升集群的灵活性和可靠性。
>>>内存扩展
通过使用cgroups,Postgres的内存使用情况可以实现动态调整,当需要时,它能够有效地通过Kubernetes集群中的弹性伸缩程序代理请求其他的资源,以确保数据库始终保持最佳性能。
>>>本地文件缓存
利用Postgres扩展,我们实现了本地文件缓存功能,该功能能够充分利用额外的VM内存和动态调整缓存大小来加速查询处理速度,确保在扩展事件期间实现无缝且高效的操作。
通常,Neon的垂直弹性伸缩功能可智能地管理NeonVM中基于Postgres的计算节点的性能,通过动态分配和解除vCPU与RAM资源,实现高效且灵活的资源调度。
02
将IvorySQL放入Neon Autoscaling平台
在本节中,我们将为您详细指导IvorySQL 3.2版本与Neon Autoscaling平台的集成流程。在开始之前,请运行相应的命令以获取并查看Autoscaling的源代码。
git clone https://github.com/neondatabase/autoscaling.git
cd autoscaling
git checkout v0.28.1 -b IvorySQL3.2-autoscaling
接下来,请按照以下步骤对Autoscaling平台发布tagv0.28.1进行相应的更改。
2.1 创建IvorySQL vm示例
要创建IvorySQL VM示例,需要先复制“vm-examples”目录下的“pg16-disk-test”文件夹,并将其命名为“ivy3-disk-test”,然后对“image-spec.yaml”文件进行主要修改,修改后的所有文件均可在指定位置获取。
2.2 创建IvorySQL部署文件
为了创建IvorySQL的部署文件,请复制“vm-deploy.yaml”文件并命名为“vm-deploy-ivy3.yaml”。接下来,请参照提供的示例文件,对“vm-deploy-ivy3.yaml”进行必要的修改。
2.3 将ivy3-disk-test添加到Makefile
将“ivy3-disk-test”添加到Makefile中,并合并所需的修改,以便能够通过执行“make ivy3-disk-test”命令来构建“ivy3-disk-test”镜像。
2.4 加载liboracle_parser库
要加载 “liboracle_parser” 库,请在 “postgresql.conf” 的末尾添加以下行:shared_preload_libraries = 'liboracle_parser'。
如果要跳过上述所有步骤,只需运行以下命令即可:
git clone https://github.com/HighgoSoftware/autoscaling-ivorysql.git
cd autoscaling-ivorysql
git checkout IvorySQL3.2
2.5 使用kind设置本地Kubernetes集群
使用kind设置本地Kubernetes集群。下面简要概述了使用kind设置垂直自动缩放的过程;详情请参考此处。
1)构建NeonVM Linux内核:
make kernel
2)构建docker镜像:
make docker-build
3)使用kind启动本地集群:
make kind-setup
4)部署NeonVM和Autoscaling组件:
make deploy
5)生成并加载测试VM:
make pg16-disk-test
6)启动测试VM:
kubectl apply -f vm-deploy.yaml
7)运行pgbench:
VM_NAME=postgres16-disk-test scripts/run-bench.sh
2.6 体验IvorySQL的弹性伸缩
如果您已经按照上述步骤,成功自动扩容了 “postgres16”,那么运行以下三个命令,即可体验 IvorySQL 3.2 的自动扩容功能。
make ivy3-disk-test
kubectl apply -f vm-deploy-ivy3.yaml
VM_NAME=ivorysql3-disk-test scripts/run-bench.sh
一段时间后,您应该会看到每秒事务数(tps)自动增加,如下所示。

如果要缩减计算资源,可以使用以下patch命令:
kubectl patch neonvm ivorysql3-disk-test --type='json' -p='[{"op": "replace", "path": "/spec/guest/cpus/use", "value":0.25}]'
一段时间后,您应该能够观察到每秒事务数(tps)减少,如下所示。

除了使用patch命令之外,您还可以使用编辑命令 'kubectl edit neonvm ivorysql3-disk-test' 来扩展或缩减IvorySQL计算节点。只需更改“cpus”部分下的“use”值,如下所示:
spec:
enableAcceleration: true
guest:
cpus:
max: 1250m
min: 250m
use: 250m
2.7 体验 Oracle 与 IvorySQL 的兼容性
为了简化操作,避免使用复杂的Kubernetes命令,您可以选择直接登录运行IvorySQL的虚拟机。以下是登录IvorySQL VM、连接到IvorySQL数据库、检查版本以及测试Oracle兼容功能的详细步骤示例。
IVY_VM=$(kubectl get neonvm ivorysql3-disk-test -ojsonpath='{.status.podName}')
kubectl exec -it $IVY_VM -- screen /dev/pts/0
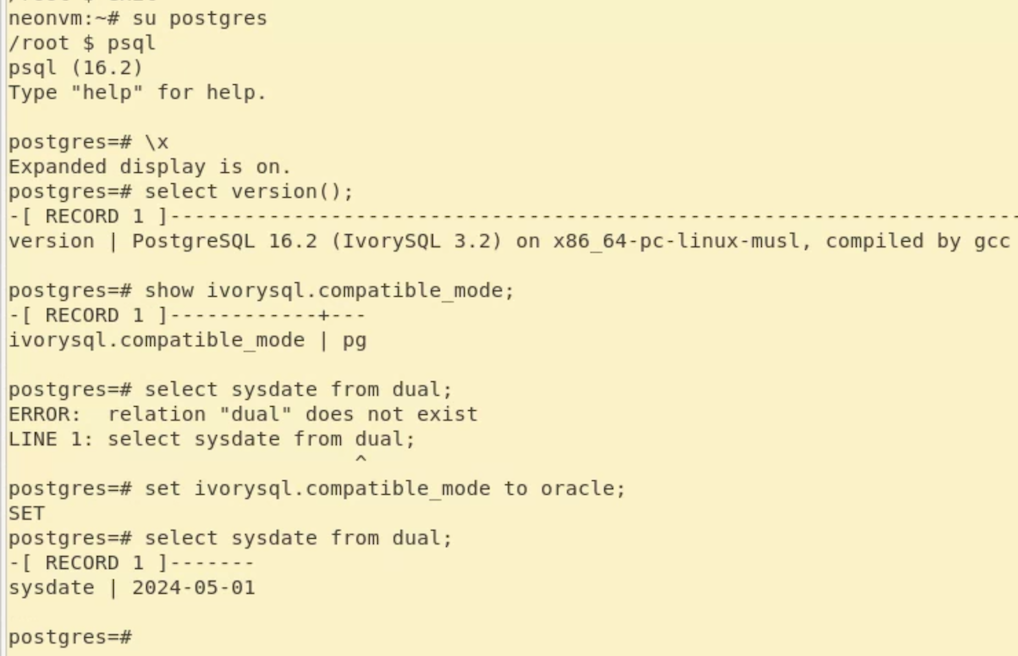
上面的屏幕截图显示IvorySQL 3.2在Neon Autoscaling Platform 上运行,并支持使用Oracle DUAL Table 的sysdate 查询。您可以参考IvorySQL开发人员指南,探索更多Oracle兼容功能。
03
总结
这篇文章提供了将IvorySQL集成到Neon垂直弹性伸缩平台的指南。通过详细的说明和演示,希望您可以了解如何将基于IvorySQL的数据库合并到Neon弹性伸缩环境中,并体验IvorySQL与Oracle的兼容功能。
04
今后工作
未来,我们正在考虑:
-
合并Postgres-16将Neon更改为IvorySQL作为无服务器分支。
-
使IvorySQL 3.0成为Neon存储库的子模块。
-
构建具有独立存储节点的IvorySQL 3.0计算节点。
当IvorySQL集成到Neon Autoscaling Platform后,最终用户将能够指定除PostgreSQL 14/15/16之外的IvorySQL计算节点,同时更全面的体验IvorySQL的Oracle兼容功能带来的便利和优势。
原文链接:
https://www.highgo.ca/2024/05/02/bringing-ivorysql-to-neon-autoscaling-platform/
![[淘宝销量]—采集分析—实例参考▶](https://img-blog.csdnimg.cn/direct/978115f9407f4f8a9c4a1601e2967c9d.gif)









![[华为OD] B卷 树状结构查询 200](https://img-blog.csdnimg.cn/direct/2b90720440444b5d82451cf5898ea1d3.png)