1.1. SparkSQL介绍
SparkSQL,就是Spark生态体系中的构建在SparkCore基础之上的一个基于SQL的计算模块。SparkSQL的前身不叫SparkSQL,而是叫做Shark。最开始的时候底层代码优化、SQL的解析、执行引擎等等完全基于Hive,总是Shark的执行速度要比Hive高出一个数量级,但是Hive的发展制约了Shark。因此在15年中旬的时候,Shark的负责人将Shark项目结束掉,重新独立出来的一个项目,就是SparkSQL。Spark SQL不再依赖Hive,做了独立的发展,逐渐的形成两条相互独立的业务:SparkSQL和Hive-On-Spark。在SparkSQL发展过程中,同时也吸收了Shark有些特点:基于内存的列存储、动态字节码优化技术。
SparkSQL是用于结构化数据处理的Spark模块,与基本的Spark RDD API不同,SparkSQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。在内部,SparkSQL使用这些额外的信息来执行额外的优化。有几种与SparkSQL交互的方法,包括SQL和Dataset API。计算结果时,将使用相同的执行引擎,这与用于表示计算的API/语言无关。这种统一意味着开发人员可以轻松的在不同的API之间来回切换,基于API的切换提供了表示给定转换的最自然的方式。
SparkSQL的发展历史:
- 2014年:SparkSQL 1.0版本正式发布。
- 2015年:SparkSQL 1.3版本正式发布,新增了DataFrame编程模型,也是目前使用到的编程模型。
- 2016年:SparkSQL 1.6版本正式发布,新增了Dataset编程模型,提供了强类型支持,也就是在RDD的每行数据添加了类型约束。适用于Java、Scala。
- 2016年:SparkSQL 2.0版本正式发布。
- 2019年:SparkSQL 3.0版本正式发布,性能得到大幅提升。
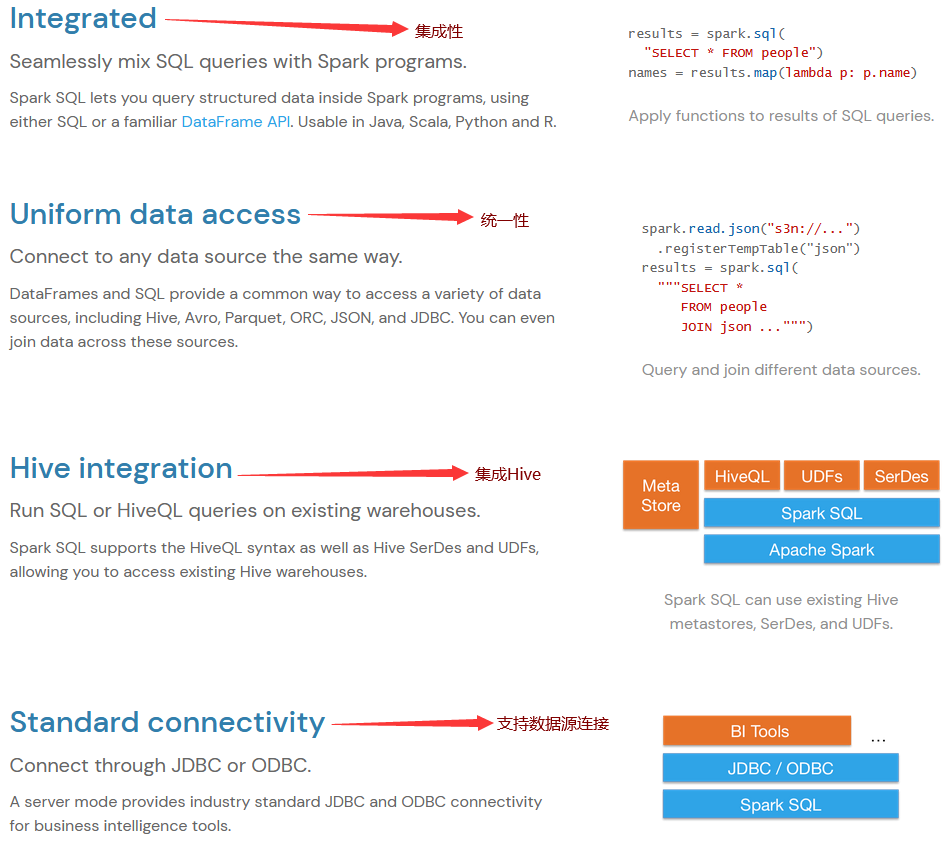
1.2. SparkSQL的特点
1.3. 总结
SparkSQL就是Spark生态体系中用于处理结构化数据的一个模块。
- 结构化数据是什么?
- 存储在关系型数据库中的数据,就是结构化数据.
- 半结构化数据是什么?
- 类似xml、json等的格式的数据被称之为半结构化数据.
- 非结构化数据是什么?
- 音频、视频、图片等为非结构化数据.
换句话说,SparkSQL处理的就是二维表数据。
![[淘宝销量]—采集分析—实例参考▶](https://img-blog.csdnimg.cn/direct/978115f9407f4f8a9c4a1601e2967c9d.gif)









![[华为OD] B卷 树状结构查询 200](https://img-blog.csdnimg.cn/direct/2b90720440444b5d82451cf5898ea1d3.png)