性能优化思维
整体思维
- 木桶效应:系统的性能符合木桶效应(一个木桶能装多少水,取决于木桶中最短的那块木板),所以性能优化需要从多个方面去考虑,如架构优化、业务优化、前端优化、中间件调优、网关优化、JVM优化、数据库优化、代码优化、容器/硬件优化等;
- 优化分类:
- 架构优化:从系统整体架构考虑,如:读写分离、集群部署、引入缓存/搜索/消息中间件、中台架构、分库分表等;
- 参数优化:从系统组件方面考虑,如:JVM、服务器、数据库、中间件、网关、容器等组件的参数调整;
- 代码优化:从代码方面考虑,如:代码中采用更优秀的算法思想/设计模式、SQL优化、对中间件的操作优化等;
单个服务层面
- 在程序中,业务的执行实体都是线程,所以程序的性能一般与线程挂钩;
-
CPU、内存、磁盘等硬件资源:线程最终会由CPU进行调度(时间片轮训)执行,且在线程的执行过程也必然需要对数据进行操作(绝大部分的业务本质都是对数据的CURD)最终都是与内存、磁盘打交道;
- 关联:线程越多,需要的CPU调度能力也就越强,需要的内存也越大,磁盘IO速率也会要求越快,当三者之间任意一个达到了瓶颈,程序中的线程数量也会达到极限,达到极限后,系统的性能会成抛物线式下滑,从而可能导致系统整体性能下降乃至瘫痪;
所以一般不能让CPU、内存、磁盘等资源的使用率达到95%+,最大利用率控制在80-85%左右为最佳状态。
- 关联:线程越多,需要的CPU调度能力也就越强,需要的内存也越大,磁盘IO速率也会要求越快,当三者之间任意一个达到了瓶颈,程序中的线程数量也会达到极限,达到极限后,系统的性能会成抛物线式下滑,从而可能导致系统整体性能下降乃至瘫痪;
-
- 线程工作模型:程序设计中主要存在三种线程处理模型:
BIO、NIO、AIO;可以参考;BIO阻塞IO模型:BIO是最传统的一对一处理模型,也就是一个客户端请求分配一条线程处理;NIO非阻塞IO模型:NIO的最佳实践为reactor模型;AIO异步IO模型:AIO落地实现proactor模型;
架构层面
- 优秀且合适的架构胜过多次调优:一个使用
Tomcat+MySQL部署的系统,无论如何调优都无法处理万级并发; - 架构需要符合实际业务,没有完美的架构只有最合适的架构,从现有环境及实际业务出发,选用最为合适的技术体系,这才是我们应该做的事情。如:
- 项目业务中读写参半,单节点难以承载压力,可以考虑项目集群、双主热备值等;
- 项目业务中写大于读,可以考虑引入消息中间件、DB分库、项目集群等;
- 项目业务中读大于写,可以考虑引入缓存/搜索中间件、动静分离、读写分离等;
- 架构可以进一步优化,当系统原有架构遇到性能瓶颈时,可以考虑进一步做架构优化,如:设计多级分布式缓存、缓存中间件做集群、消息中间件做集群、Java程序做集群、数据库做分库分表、搜索中间件做集群等,随着引入的技术越多,系统会越庞大,需要考虑的问题也会更加棘手,但带来的性能提升也是显著的;
预防大于解决
- 当问题在出现时再想办法解决,这是一种下下策,防范于未然才是最佳方案;
- 项目初期:在项目初期,我们应该对未来的流量压力、数据大小等进行预测,提前根据业务和设计出合适的架构,确保上线后可以承载业务的正常压力和增长;不要“卡点”设计,也不能过度设计造成性能过剩;
- 项目上线后:计划赶不上变化,项目初期的预测难免会出现偏差,一套完善的监控系统,在性能瓶颈来临前设好警报线,确保能够在真正的性能瓶颈到来之前解决问题;
性能调优的核心步骤
通常而言,性能优化的步骤可分为如下几步:
- 发现性能瓶颈:如有监控系统,那它会主动发出警报;如若没有,那出现瓶颈时应用肯定会出问题,如:无响应、响应缓慢、频繁宕机等。
- 排查瓶颈原因:排查瓶颈是由于故障问题导致的,还是真的存在性能瓶颈。
- 定位瓶颈位置:往往一个系统都会由多个层面协同工作,然后对外提供服务,当发现性能瓶颈时,应当确定瓶颈的范围,如:网络带宽瓶颈、Java应用瓶颈、数据库瓶颈等。
- 解决性能瓶颈:定位到具体的瓶颈后对症下药,从结构、配置、操作等方面出发,着手解决瓶颈问题。
Mysql性能优化
一般分为五个维度
客户端与连接层优化
调整客户端DB连接池参数和DB连接层参数;
- 客户端的连接池大小设置可以参考
PostgreSQL的计算公式:最大连接数 = (CPU核心数 x 2) + 有效磁盘数(SSD固态硬盘数量);- 为什么不限制服务端连接数:
MySQL实例一般情况下只为单个项目提供服务,应用程序的连接数做了限制,自然也就限制了服务端的连接数; - 正常来说
MySQL的最大连接数应大于客户端连接池的最大连接数,存在通过终端工具远程连接MySQL等情况,如果设置一致就很有可能导致MySQL连接数爆满; - 对于最佳连接数的计算,首先要把
CPU核数放首位考虑,紧接着是磁盘,最后是网络带宽,因为带宽会影响SQL执行时间,综合考虑后才能计算出最合适的连接数大小
- 为什么不限制服务端连接数:
- 偶发高峰类业务的连接数配置:在某些时间段或者活动开始时,流量会高于平时流量,可以将常驻连接数配成
CPU核数+1,同时缩短连接的存活时间,及时释放空闲的数据库连接; mysql最大连接数设置set max_connections = n;
Mysql参数优化:
- 设置方式:启动之后通过
set global @@xxx = xxx的方式调整,但最好还是直接修改my.ini/my.conf配置文件; InnoDB缓冲区配置:innodb_buffer_pool_size一般为内存的70%~80%;- 实例空间:当
InnoDB的缓冲区空间大于1GB时,会自动划分多个实例空间,可以在多线程并发执行时,减少并发冲突,MySQL官方的建议是每个缓冲区实例须大于1GB,通过innodb_buffer_pool_instances设置;
- 实例空间:当
- 工作线程缓冲区配置:最好根据机器内存设置为一到两倍
MB大小sort_buffer_size:排序缓冲区大小,影响group by、order by...等排序操作。max_length_for_sort_data:如果排序字段值的最大长度小于该值,则会将所有要排序的字段值载入内存排序,但如果大于该值时,则会一批一批的加载排序字段值进内存,然后一边加载一边做排序
read_buffer_size:读取缓冲区大小,影响select...查询操作的性能。join_buffer_size:联查缓冲区大小,影响join多表联查的性能。
- 调整临时表空间:
tmp_table_size、max_heap_table_size两个参数主要是限制临时表可用的内存空间,当创建的临时表空间占用超过tmp_table_size时,就会将其他新创建的临时表转到磁盘中创建;- 参数大小:可以根据
show global status like 'created_tmp%';统计信息决定Created_tmp_disk_tables / Created_tmp_tables * 100% = 120%;
- 参数大小:可以根据
- 调整空闲线程的存活时间:
- 查看数据库连接峰值:
show global status like 'Max_used_connections'; - 空闲连接的超时时间:
wait_timeout、interactive_timeout,默认八小时也就是一个连接断开后,默认也会将对应的工作线程缓存八小时后再销毁,这里我们可以手动调整成30min~1h左右,可以让无用的连接能及时释放,减少资源的占用。
- 查看数据库连接峰值:
编码层面优化:
-
编写
sql时需考虑sql是否走索引,可以参考索引使用; -
查询时尽量按需取字段,避免使用
*- 当使用
*时,解析器需要先去解析出当前要查询的表上*表示哪些字段,因此会额外增加解析成本; InnoDB会将查询的结果放入缓存中,查询的字段越多结果集也就越大占用的内存也会越大,所存储的其他数据也就越少,当其他SQL操作时,在内存中找不到数据,又会去触发磁盘IO,最终导致MySQL整体性能下降;
- 当使用
-
尽量将大事物拆分成小事物;
- 当事物较大且包含写事物时,会导致一部分数据长时间锁定,从而可能引起大量事物出现阻塞;
- 大事务也会导致日志写入时出现阻塞,这种情况下会强制触发刷盘机制,大事务的日志需要阻塞到有足够的空间时,才能继续写入日志到缓冲区,这也可能会引起线上出现阻塞,可通过
show status like 'innodb_log_waits';查看是否有大事务由于redo_log_buffer不足,而在等待写入日志。
-
尽量避免深分页的情况:
select * from test limit 100000,10在MySQL的实际执行过程中,首先会查询出100010条数据,然后丢弃掉前面的10W条数据,将最后的10条数据返回;-
解决办法:基于递增连续字段
-- 第一页 select * from test where 有序字段 >= 1 limit 10; -- 第二页 select * from test where 有序字段 >= 11 limit 10;
-
-
避免循环调用
sql,新增和更新最好采用批量操作,查询可以先将所需数据查询出来建立映射关系;
多表连接查询
-
避免三表以上的连表查询,且要以小表驱动大表,原因是:连表查询的数据量是各表数据的笛卡尔积,会随着表数据增加累乘增加;
-
关联算法:
MySQL8.0之前的关联算法为Nest Loop Join嵌套循环连接算法,该算法会依照驱动表的结果集作为循环基础数据,然后通过该结果集中一条条数据,作为过滤条件去下一个表中查询数据,最后合并结果得到最终数据集;-
优化器的选择逻辑:如果指定了连接条件,满足查询条件的小数据表作为驱动表。如果未指定连接条件,数据总行数少的表作为驱动表。
-
优化器不一定能够正确选择,最好在编写sql时考虑好;假设有
a(1000条数据)、b(10条数据)两张表,select * from a as t1 left join b as t2 on t1.id = t2.id;会循环1000次查询数据,而select * from b as t1 left join a as t2 on t1.id = t2.id;只需要循环十次;// 伪逻辑 for(数据 x : 驱动表){ for(数据 y : 被驱动表){ if (x == y){ // 如果符合连接条件,则记录到连接查询的结果集中..... } } }
-
-
哈希连接
(Hash Join)Mysql8.0新增,对连表时存在等值连接条件且未命中索引的情况下的连接查询优化: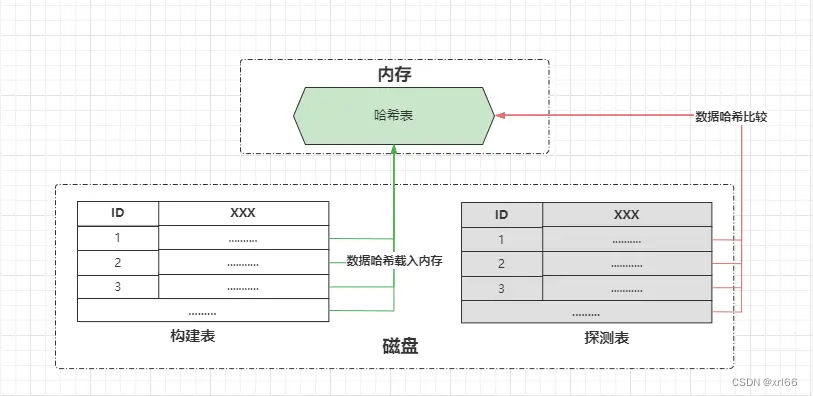
// 伪代码 // 构建阶段:将小表的每行数据,根据哈希值放入内存哈希表中 Map hashTable = new HashMap(); for(数据 x : 构建表){ hashTable.put(x); } // 探测阶段:遍历大表的每行数据与内存哈希表做连接匹配 for(数据 y : 探测表){ if (hashTable.get(y) != null){ // 如果哈希处理后能够在内存哈希表中存在, // 则表示这条数据符合连接条件,则记录到连接查询的结果集中..... } }- 分为两个阶段:
- 构建阶段:选择一张小表为构建表,然后基于连接字段做哈希处理,接着将生成的哈希值放入内存中构建出一张哈希表;
- 探测阶段:遍历大表的每一行数据,然后对连接字段做哈希处理,通过生成的哈希值与内存哈希表做比较,将符合条件的数据放入结果集;
- 相对于嵌套循环性能的提升:
- 对于大表只需要遍历一次,而嵌套循环需要遍历N次;
- 在探测阶段时,只需要先对数据做一次哈希处理,复杂度为O(1), 而循环连接为O(n);
- 存在的问题:
- 内存中的
join_buffer_size的大小可能无法完全载入哈希表;解决办法:- 分批处理:在构建阶段将构建表的数据进行拆分,在探测阶段每次载入一部分到内存中,这样会导致遍历次数增多;
- 磁盘+内存混合处理:将内存中放不下的数据放入磁盘,在探测阶段遍历大表判断时,从磁盘依次读入处理好的哈希值进行判断;
- Mysql采用的是磁盘+内存混合处理的方式;
- 内存中的
- 使用限制:
- 仅支持内连接的多表连接查询;
- 必须要去等值连接查询条件;
- 连接字段可走索引的情况下,默认依旧会采用循环连接算法;
- 默认开启,可通过
set optimizer_switch="hash_join=off";命令控制;
- 分为两个阶段:
-
反连接
(Anti Join)Mysql8.0新增,对与一些反范围查询操作的优化:- 优化场景:
NOT IN (SELECT … FROM …)NOT EXISTS (SELECT … FROM …)IN (SELECT … FROM …) IS NOT TRUEEXISTS (SELECT … FROM …) IS NOT TRUEIN (SELECT … FROM …) IS FALSEEXISTS (SELECT … FROM …) IS FALSE
- 优化场景:
Mysql结构优化:
- 表结构优化:字段数量不能过多、主键最好自增、根据业务建立中间表等;
- 字段结构优化:在保证足够使用的范围内,选择最小数据类型;尽量避免
NULL值等; - 索引结构优化:参考之前的索引使用
整体架构优化:
- 引入缓存中间件解决读压力;
- 优点:在设置合理的情况下,可以为
Mysql分担70%以上的读压力; - 缺点:系统变复杂,需要考虑缓存击穿、缓存穿透、缓存雪崩、数据一致性等问题
- 优点:在设置合理的情况下,可以为
- 引入消息中间件解决写压力;
- 优点:利用了
MQ流量削峰的能力,使请求平滑的到达数据库; - 缺点:数据库数据存在一定的延时;
- 优点:利用了
- 主从读写分离,适用于读多写少业务,提高
mysql自身抗压能力;- 优点:通过搭建集群,提高了
mysql的抗压能力; - 缺点:主节点和从节点之间存在数据不一致的情况;
- 优点:通过搭建集群,提高了
- 双主双写热备,适用于写多读少的情况;
- 需要考虑自增
ID问题;
- 需要考虑自增
- 分库分表,规避存储容量的上限+木桶效应;