文章目录
- 第1关:字符串操作方法
- 第2关:Pandas的日期与时间工具
- 第3关:Pandas时间序列的高级应用
第1关:字符串操作方法
任务描述
本关任务:读取step1/bournemouth_venues.csv文件,获取Venue Name列,通过向量化字符串操作得到清洗后的数据。
相关知识
为了完成本关任务,你需要掌握:1.pandas字符串方法;2. 基本正则表达式。
字符串方法
如果你对Python字符串方法十分了解,那么下面的知识对你来说如瓮中捉鳖,几乎所有的Python内置的字符串方法都被复制到Pandas的向量化字符串方法中。
下面列举为Pandas字符串方法借鉴Python字符串方法的内容:
它们的作用与Python字符串的基本一致,但是需要注意这些方法的返回值不同。举两个例子:
样例1:
monte = pd.Series([‘Graham Chapman’, ‘John Cleese’, ‘Terry Gilliam’, ‘Eric Idle’, ‘Terry Jones’, ‘Michael Palin’])
monte.str.lower() # 返回字符串
输出:
0 graham chapman
1 john cleese
2 terry gilliam
3 eric idle
4 terry jones
5 michael palin
dtype: object
样例2:
monte.str.split() # 返回列表
输出:
0 [Graham, Chapman]
1 [John, Cleese]
2 [Terry, Gilliam]
3 [Eric, Idle]
4 [Terry, Jones]
5 [Michael, Palin]
dtype: object
pandas中还有一些自带的字符串方法,如下图所示:
其中get_dummies()方法有点难以理解,给大家举个例子:假设有一个包含了某种编码信息的数据集,如 A= 出生在美国、B= 出生在英国、C= 喜欢奶酪、D= 喜欢午餐肉:
full_monte = pd.DataFrame({
‘name’: monte,
‘info’: [‘B|C|D’, ‘B|D’, ‘A|C’, ‘B|D’, ‘B|C’, ‘B|C|D’]})
print(full_monte)
输出:
info name
0 B|C|D Graham Chapman
1 B|D John Cleese
2 A|C Terry Gilliam
3 B|D Eric Idle
4 B|C Terry Jones
5 B|C|D Michael Palin
get_dummies()方法可以让你快速将这些指标变量分割成一个独热编码的DataFrame(每个元素都是0或1):
full_monte[‘info’].str.get_dummies(‘|’)
输出:
A B C D
0 0 1 1 1
1 0 1 0 1
2 1 0 1 0
3 0 1 0 1
4 0 1 1 0
5 0 1 1 1
正则表达式方法
还有一些支持正则表达式的方法可以用来处理每个字符串元素。如下图所示:
众所周知,正则表达式“无所不能”,我们可以利用正则实现一些独特的操作,例如提取每个人的first name:
monte.str.ext\fract(‘([A-Za-z]+)’)
输出:
0 Graham
1 John
2 Terry
3 Eric
4 Terry
5 Michael
dtype: object
或者找出所有开头和结尾都是辅音字符的名字:
monte.str.findall(r'^[^AEIOU].*[^aeiou]$')
输出:
0 [Graham Chapman]
1 []
2 [Terry Gilliam]
3 []
4 [Terry Jones]
5 [Michael Palin]
dtype: object
如果你想深入了解这些方法的作用,请参考Pandas官方文档
编程要求
本关的编程任务是补全右侧上部代码编辑区内的相应代码,要求实现如下功能:
读取step1/bournemouth_venues.csv文件,文件说明如下:
列名 说明
Venue Name 场地名
Venue Category 场地类别
Venue Latitude 场地经度
Venue Longitude 场地纬度
以空格切分每个场地名并获取每个切分后列表的最后一个元素作为一个Series;
将所有单词为P开头的值替换为空,并删除所有为空的行;
找出所有值不含字母的行并删除;
返回清洗后的结果;
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
无测试输入
预期输出:
0 Roast
1 DelMarco
2 Gardens
3 Gardens
4 Square
5 Stable
6 Starbucks
7 Co.
8 Gardens
9 Sandwich
10 Kitchen
11 Gym
12 Coffee
13 Bournemouth
14 Manger
15 Cucumber
16 Guys
17 Club
18 Beach
19 Odeon
20 Gelateria
21 Valerie
22 Greek
23 Slope)
24 Starbucks
26 Nero
28 Tealith
29 NEO
30 Bay
31 Aces
...
67 Co.
69 Garden
70 Brasserie
71 Restaurant
72 Gardens
73 Atlantico
74 Hotel
75 DYMK
76 Winchester
77 Subway
78 Circus
79 Bar
80 Triangle
81 Rojo
82 KFC
83 Hotel
84 Cliff
85 Xchange
86 Express
87 (Harvester)
88 Zag
89 (BMH)
90 Bournemouth
91 Coffee
92 Inn
93 Stop
94 Chineside
96 Hotel
97 Hotel
98 Chine
Name: Venue Name, Length: 90, dtype: object
开始你的任务吧,祝你成功!
示例代码如下:
import pandas as pd
def demo():
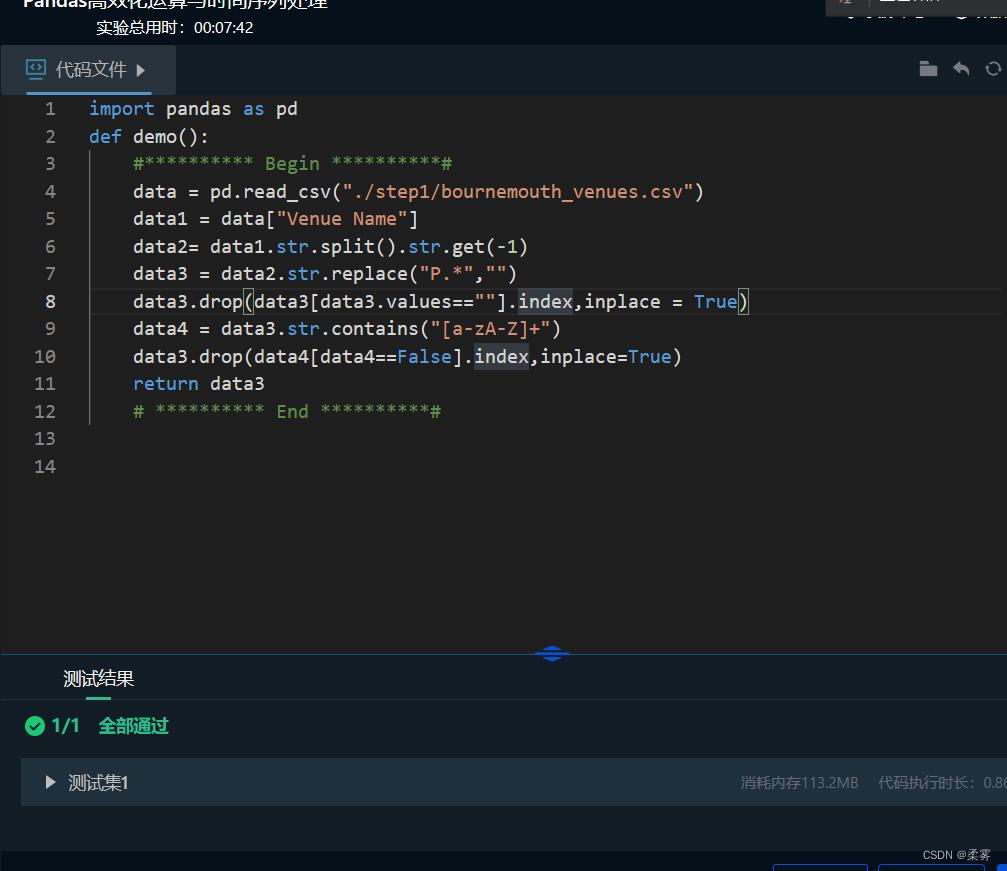
#********** Begin **********#
data = pd.read_csv("./step1/bournemouth_venues.csv")
data1 = data["Venue Name"]
data2= data1.str.split().str.get(-1)
data3 = data2.str.replace("P.*","")
data3.drop(data3[data3.values==""].index,inplace = True)
data4 = data3.str.contains("[a-zA-Z]+")
data3.drop(data4[data4==False].index,inplace=True)
return data3
# ********** End **********#
第2关:Pandas的日期与时间工具
任务描述
本关任务:根据预期输出,创建三种不同索引的数据结构。
相关知识
Pandas是为金融模型而创建的,所以拥有一些功能非常强大的日期、时间、带时间索引数据的处理工具。
本关卡介绍的日期与时间数据主要包含三类:
时间戳:表示某个具体的时间点;(例如2015年7月4日上午 7 点)
时间间隔与周期:期表示开始时间点与结束时间点之间的时间长度,例如2015年(指的是2015年1月1日至2015年12月31日这段时间间隔)。周期通常是指一种特殊形式的时间间隔,每个间隔长度相同,彼此之间不会重叠;(例如,以24小时为周期构成每一天)
时间增量或持续时间:表示精确的时间长度。(例如,某程序运行持续时间22.56秒)
Python 的日期与时间工具
原生Python中也有处理日期与时间的工具,它与Pandas中处理时间的工具有着千丝万缕的联系。
Python的日期与时间功能都在标准库的datetime模块和第三方库dateutil模块。
如果你处理的时间数据量比较大,那么速度就会比较慢,这时就需要使用到NumPy中已经被编码的日期类型数组了。
NumPy中的datetime64类型
Python原生日期格式的性能弱点促使NumPy团队为NumPy增加了自己的时间序列类型。datetime64类型将日期编码为64位整数,这样可以让日期数组非常紧凑(节省内存)。
In[3]:import numpy as np
date = np.array(‘2015-07-04’, dtype=np.datetime64)
date
Out[3]:array(datetime.date(2015, 7, 4), dtype=‘datetime64[D]’)
有了这个日期格式,即可以进行快速的向量化运算:
In[4]:date + np.arange(12) #由于date是datetime类型,所以向量化运算也是datetime类型的运算
Out[4]:
array([‘2015-07-04’, ‘2015-07-05’, ‘2015-07-06’, ‘2015-07-07’, ‘2015-07-08’, ‘2015-07-09’, ‘2015-07-10’, ‘2015-07-11’, ‘2015-07-12’, ‘2015-07-13’, ‘2015-07-14’, ‘2015-07-15’], dtype=‘datetime64[D]’)
由于datetime64对象是64位精度,所以可编码的时间范围可以是基本单元的 264倍。datetime64可以在时间精度与最大时间跨度之间达成了一种平衡,也就是说,NumPy会自动判断输入时间所需要使用的时间单位。
In[5]: np.datetime64(‘2015-07-04’) # 天为单位
Out[5]: numpy.datetime64(‘2015-07-04’)
In[6]: np.datetime64(‘2015-07-04 12:00’) # 分钟为单位
Out[6]: numpy.datetime64(‘2015-07-04T12:00’)
In[7]: np.datetime64(‘2015-07-04 12:59:59.50’, ‘ns’) # 手动设置时间单位
Out[7]: numpy.datetime64(‘2015-07-04T12:59:59.500000000’)
日期与时间单位格式代码表如下:
代码 含义 时间跨度(相对) 时间跨度(绝对)
Y 年(year) ±9.2e18年 [9.2e18 BC, 9.2e18 AD]
M 月(month) ±7.6e17年 [7.6e17 BC, 7.6e17 AD]
W 周(week) ±1.7e17年 [1.7e17 BC, 1.7e17 AD]
D 日(day) ±2.5e16年 [2.5e16 BC, 2.5e16 AD]
h 时(hour) ±1.0e15年 [1.0e15 BC, 1.0e15 AD]
m 分(minute) ±1.7e13年 [1.7e13 BC, 1.7e13 AD]
s 秒(second) ±2.9e12年 [2.9e9 BC, 2.9e9 AD]
ms 毫秒(millisecond) ±2.9e9年 [2.9e6 BC, 2.9e6 AD]
us 微秒(microsecond) ±2.9e6年 [290301 BC, 294241 AD]
ns 纳秒(nanosecond) ±292年 [1678 AD, 2262 AD]
ps 皮秒(picosecond) ±106天 [1969 AD, 1970 AD]
fs 飞秒(femtosecond) ±2.6小时 [1969 AD, 1970 AD]
as 原秒(attosecond) ±9.2秒 [1969 AD, 1970 AD
Pandas的日期与时间工具
Pandas中的datetime是结合了原生Python和NumPy的datetime,用来处理时间序列的基础数据类型如下:
针对时间戳数据,Pandas提供了Timestamp类型。它本质上是Python的原生datetime类型的替代品,但是在性能更好的numpy.datetime64类型的基础上创建。对应的索引数据结构是 DatetimeIndex;
针对时间周期数据,Pandas提供了Period类型。这是利用numpy.datetime64类型将固定频率的时间间隔进行编码。对应的索引数据结构是PeriodIndex;
针对时间增量或持续时间,Pandas提供了Timedelta类型。Timedelta是一种代替Python原生datetime.timedelta类型的高性能数据结构,同样是基于numpy.timedelta64类型。对应的索引数据结构是TimedeltaIndex;
最基础的日期 / 时间对象是Timestamp和DatetimeIndex。这两种对象可以直接使用,最常用的方法是pd.to_datetime()函数,。对pd.to_datetime() 传递一个日期会返回一个Timestamp类型,传递一个时间序列会返回一个DatetimeIndex类型;
DatetimeIndex类型;
In[8]:dates = pd.to_datetime([datetime(2015, 7, 3), ‘4th of July, 2015’, ‘2015-Jul-6’, ‘07-07-2015’, ‘20150708’])
dates
Out[8]:DatetimeIndex([‘2015-07-03’, ‘2015-07-04’, ‘2015-07-06’, ‘2015-07-07’, ‘2015-07-08’], dtype=‘datetime64[ns]’, freq=None)
PeriodIndex类型,任何DatetimeIndex类型都可以通过to_period()方法和一个频率代码转换成PeriodIndex类型,PeridoIndex类型可以通过to_timestamp()方法转换为DatetimeIndex类型。下面用D将数据转换成单日的时间序列:
In[10]: dates.to_period(‘D’)
Out[10]: PeriodIndex([‘2015-07-03’, ‘2015-07-04’, ‘2015-07-06’, ‘2015-07-07’, ‘2015-07-08’], dtype=‘period[D]’, freq=‘D’)
TimedeltaIndex类型,当用一个日期减去另一个日期时,返回的结果是TimedeltaIndex类型:
In[11]: dates - dates[0]
Out[11]:
TimedeltaIndex([‘0 days’, ‘1 days’, ‘3 days’, ‘4 days’, ‘5 days’], dtype=‘timedelta64[ns]’, freq=None)
为了能更简便地创建有规律的时间序列,Pandas提供了一些方法:pd.date_range()可以处理时间戳、pd.period_range()可以处理周期、pd.timedelta_range()可以处理时间间隔。
pd.date_range(),通过开始日期、结束日期和频率代码(可选的)创建一个有规律的日期序列,默认的频率是天:
In[12]:pd.date_range(‘2015-07-03’, ‘2015-07-10’)
Out[12]:DatetimeIndex([‘2015-07-03’, ‘2015-07-04’, ‘2015-07-05’, ‘2015-07-06’, ‘2015-07-07’, ‘2015-07-08’, ‘2015-07-09’, ‘2015-07-10’], dtype=‘datetime64[ns]’, freq=‘D’)
范围不一定非是开始时间和结束时间,也可以设置周期数periods来达到改目的:
In[13]:pd.date_range(‘2015-07-03’, periods=8)
Out[13]:DatetimeIndex([‘2015-07-03’, ‘2015-07-04’, ‘2015-07-05’, ‘2015-07-06’, ‘2015-07-07’, ‘2015-07-08’, ‘2015-07-09’, ‘2015-07-10’], dtype=‘datetime64[ns]’, freq=‘D’)
freq表示时间间隔,默认是D,可以通过修改它来periods参数的意义:
In[14]:pd.date_range(‘2015-07-03’, periods=8, freq=‘H’)
Out[14]:
DatetimeIndex([‘2015-07-03 00:00:00’, ‘2015-07-03 01:00:00’,
‘2015-07-03 02:00:00’, ‘2015-07-03 03:00:00’,
‘2015-07-03 04:00:00’, ‘2015-07-03 05:00:00’,
‘2015-07-03 06:00:00’, ‘2015-07-03 07:00:00’],
dtype=‘datetime64[ns]’, freq=‘H’)
pd.timedelta_range() ,如果要创建一个有规律的周期或时间间隔序列,pd.timedelta_range()可以实现该功能:
In[15]:pd.period_range(‘2015-07’, periods=8, freq=‘M’)
Out[15]:
PeriodIndex([‘2015-07’, ‘2015-08’, ‘2015-09’, ‘2015-10’, ‘2015-11’, ‘2015-12’, ‘2016-01’, ‘2016-02’], dtype=‘int64’, freq=‘M’)
也可以通过修改freq参数实现各种频率的时间间隔序列。
编程要求
请先仔细阅读右侧上部代码编辑区内给出的代码框架,根据相关知识创建时间戳、时间周期、时间增量这三种索引的数据结构。
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
2019-01-01
预期输出:
DatetimeIndex([‘2019-01-01’, ‘2019-01-02’, ‘2019-01-03’, ‘2019-01-04’,
‘2019-01-05’, ‘2019-01-06’, ‘2019-01-07’, ‘2019-01-08’,
‘2019-01-09’, ‘2019-01-10’],
dtype=‘datetime64[ns]’, freq=‘D’)
PeriodIndex([‘2019-01-01’, ‘2019-01-02’, ‘2019-01-03’, ‘2019-01-04’,
‘2019-01-05’, ‘2019-01-06’, ‘2019-01-07’, ‘2019-01-08’,
‘2019-01-09’, ‘2019-01-10’],
dtype=‘period[D]’, freq=‘D’)
TimedeltaIndex([‘01:00:00’, ‘02:00:00’, ‘03:00:00’, ‘04:00:00’, ‘05:00:00’,
‘06:00:00’, ‘07:00:00’, ‘08:00:00’, ‘09:00:00’, ‘10:00:00’],
dtype=‘timedelta64[ns]’, freq=‘H’)
开始你的任务吧,祝你成功!
示例代码如下:
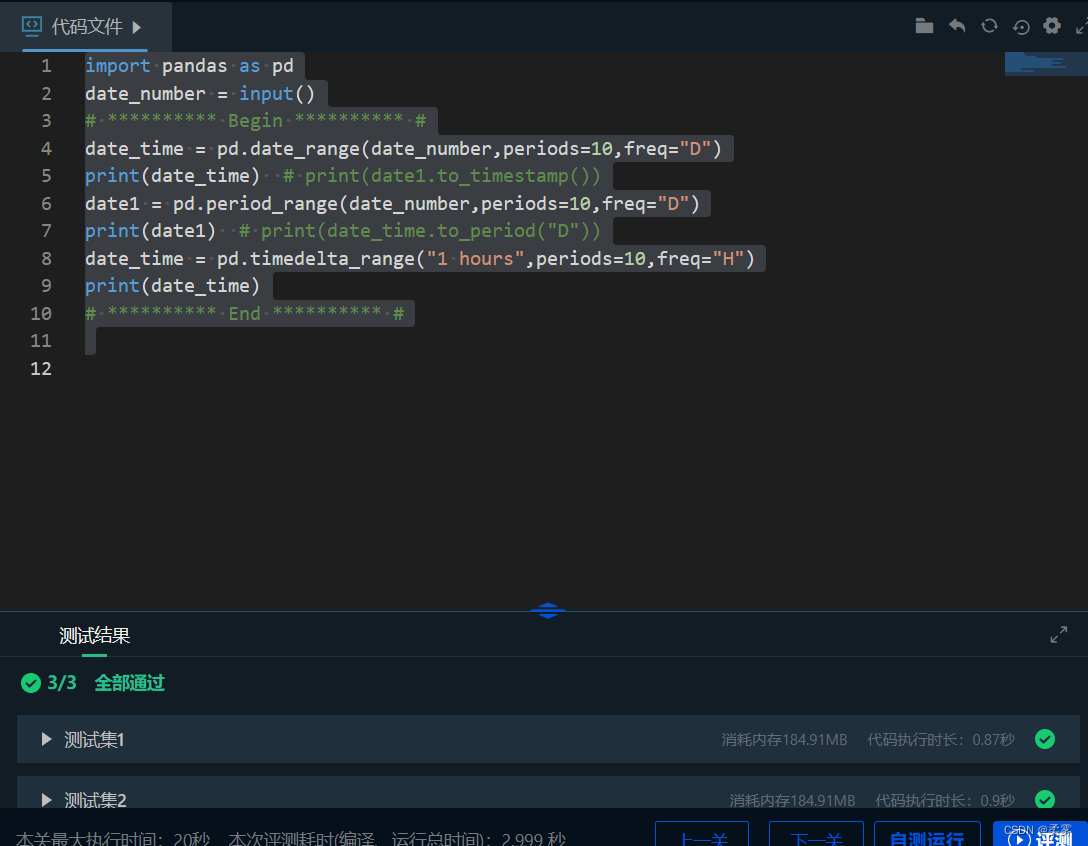
import pandas as pd
date_number = input()
# ********** Begin ********** #
date_time = pd.date_range(date_number,periods=10,freq="D")
print(date_time) # print(date1.to_timestamp())
date1 = pd.period_range(date_number,periods=10,freq="D")
print(date1) # print(date_time.to_period("D"))
date_time = pd.timedelta_range("1 hours",periods=10,freq="H")
print(date_time)
# ********** End ********** #
第3关:Pandas时间序列的高级应用
任务描述
根据相关知识完成下列任务:
求上个季度(仅含工作日)的平均值;
求每个月末(仅含工作日)的收盘价;
迁移数据365天;
求一年期移动标准差。
相关知识
学习本关卡知识之前,建议先了解matplotlib模块基础知识。
Pandas时间序列工具的基础是时间频率或偏移量代码。就像之前见过的D(day)和H(hour)代码,我们可以用这些代码设置任意需要的时间间隔。
Pandas频率代码表如下:
代码 描述
D 天(calendar day,按日历算,含双休日)
W 周(weekly) M 月末(month end)
Q 季末(quarter end)
A 年末(year end)
H 小时(hours)
T 分钟(minutes)
S 秒(seconds)
L 毫秒(milliseonds)
U 微秒(microseconds)
N 纳秒(nanoseconds)
B 天(business day,仅含工作日)
BM 月末(business month end,仅含工作日)
BQ 季末(business quarter end,仅含工作日)
BA 年末(business year end,仅含工作日)
BH 小时(business hours,工作时间)
MS 月初(month start)
BMS 月初(business month start,仅含工作日)
QS 季初(quarter start)
BQS 季初(business quarter start,仅含工作日)
AS 年初(year start)
BAS 年初(business year start,仅含工作日)
时间频率与偏移量
我们可以在频率代码后面加三位月份缩写字母来改变季、年频率的开始时间,也可以再后面加三位星期缩写字母来改变一周的开始时间:
Q-JAN、BQ-FEB、QS-MAR、BQS-APR 等;
W-SUN、W-MON、W-TUE、W-WED 等。
时间频率组合使用:
In[0]:pd.timedelta_range(0,periods=9,freq=“2H30T”)
Out[0]:TimedeltaIndex([‘00:00:00’, ‘02:30:00’, ‘05:00:00’, ‘07:30:00’, ‘10:00:00’, ‘12:30:00’, ‘15:00:00’, ‘17:30:00’, ‘20:00:00’], dtype=‘timedelta64[ns]’, freq=‘150T’)
所有这些频率代码都对应Pandas时间序列的偏移量,具体内容可以在 pd.tseries.offsets 模块中找到,比如直接创建一个工作日偏移序列:
In[1]:from pandas.tseries.offsets import BDay
pd.date_range(‘2015-07-01’, periods=5, freq=BDay())
Out[1]:DatetimeIndex([‘2015-07-01’, ‘2015-07-02’, ‘2015-07-03’, ‘2015-07-06’, ‘2015-07-07’], dtype=‘datetime64[ns]’, freq=‘B’)
重新取样、迁移和窗口
重新取样
处理时间序列数据时,经常需要按照新的频率(更高频率、更低频率)对数据进行重新取样。举个例子,首先通过pandas—datareader程序包(需要手动安装)导入Google的历史股票价格,只获取它的收盘价:
In[2]: from pandas_datareader import data
goog = data.DataReader(‘GOOG’,start=“2014”,end=“2016”,data_source=“google”)[‘Close’] # Close表示收盘价的列
In[3]: import matplotlib.pyplot as plt
import seaborn; seaborn.set()
goog.plot(); #数据可视化
输出:
我们可以通过resample()方法和asfreq()方法解决这个问题,resample() 方法是以数据累计为基础,而asfreq()方法是以数据选择为基础。
In[4]: goog.plot(alpha=0.5, style=‘-’)
goog.resample(‘BA’).mean().plot(style=‘:’)
goog.asfreq(‘BA’).plot(style=‘–’);
plt.legend([‘input’, ‘resample’, ‘asfreq’], loc=‘upper left’);
输出:
请注意这两种取样方法的差异:在每个数据点上,resample反映的是上一年的均值,而asfreq反映的是上一年最后一个工作日的收盘价。
数据集中经常会出现缺失值,从上面的例子来看,由于周末和节假日股市休市,周末和节假日就会产生缺失值,上面介绍的两种方法默认使用的是向前取样作为缺失值处理。与前面介绍过的pd.fillna()函数类似,asfreq()有一个method参数可以设置填充缺失值的方式。
In[5]:fig, ax = plt.subplots(2, sharex=True)
data = goog.iloc[:10]
data.asfreq(‘D’).plot(ax=ax[0], marker=‘o’)
data.asfreq(‘D’, method=‘bfill’).plot(ax=ax[1], style=‘-o’)
data.asfreq(‘D’, method=‘ffill’).plot(ax=ax[1], style=‘–o’)
ax[1].legend([“back-fill”, “forward-fill”]);
输出:
时间迁移
另一种常用的时间序列操作是对数据按时间进行迁移,Pandas有两种解决这类问题的方法:shift()和tshift()。简单来说,shift()就是迁移数据,而 tshift()就是迁移索引。两种方法都是按照频率代码进行迁移。
下面我们将用shift() 和tshift()这两种方法让数据迁移900天:
In[6]:fig, ax = plt.subplots(3, sharey=True)
# 对数据应用时间频率,用向后填充解决缺失值
goog = goog.asfreq(‘D’, method=‘pad’)
goog.plot(ax=ax[0])
goog.shift(900).plot(ax=ax[1])
goog.tshift(900).plot(ax=ax[2])
# 设置图例与标签
local_max = pd.to_datetime(‘2007-11-05’)
offset = pd.Timedelta(900, ‘D’)
ax[0].legend([‘input’], loc=2)
ax[0].get_xticklabels()[4].set(weight=‘heavy’, color=‘red’)
ax[0].axvline(local_max, alpha=0.3, color=‘red’)
ax[1].legend([‘shift(900)’], loc=2)
ax[1].get_xticklabels()[4].set(weight=‘heavy’, color=‘red’)
ax[1].axvline(local_max + offset, alpha=0.3, color=‘red’)
ax[2].legend([‘tshift(900)’], loc=2)
ax[2].get_xticklabels()[1].set(weight=‘heavy’, color=‘red’)
ax[2].axvline(local_max + offset, alpha=0.3, color=‘red’);
输出:
shift(900)将数据向前推进了900天,这样图形中的一段就消失了(最左侧就变成了缺失值),而tshift(900)方法是将时间索引值向前推进了900天。
移动时间窗口
Pandas处理时间序列数据的第3种操作是移动统计值。这些指标可以通过 Series和DataFrame的rolling()属性来实现,它会返回与groupby操作类似的结果,移动视图使得许多累计操作成为可能,rolling函数的具体参数可以查看其 官方文档 。
In[7]: rolling = goog.rolling(365, center=True)
data = pd.DataFrame({‘input’: goog, ‘one-year rolling_mean’: rolling.mean(), ‘one-year rolling_std’: rolling.std()})
ax = data.plot(style=[‘-’, ‘–’, ‘:’])
ax.lines[0].set_alpha(0.3)
输出:
编程要求
本关的编程任务是补全右侧上部代码编辑区内的相应代码,要求实现如下功能:
求上个季度(仅含工作日)的平均值;
求每个月末(仅含工作日)的收盘价;
迁移数据365天;
求一年期移动标准差;
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
无测试输入
预期输出:
开始你的任务吧,祝你成功!
示例代码如下:
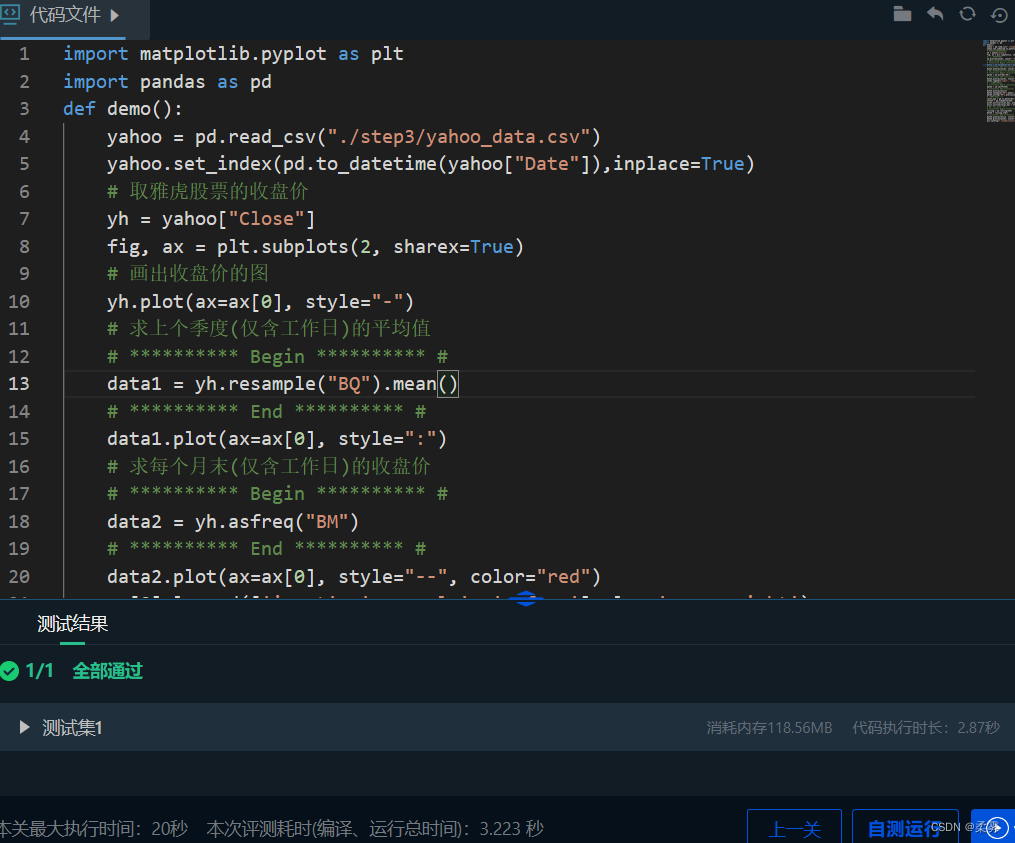
import matplotlib.pyplot as plt
import pandas as pd
def demo():
yahoo = pd.read_csv("./step3/yahoo_data.csv")
yahoo.set_index(pd.to_datetime(yahoo["Date"]),inplace=True)
# 取雅虎股票的收盘价
yh = yahoo["Close"]
fig, ax = plt.subplots(2, sharex=True)
# 画出收盘价的图
yh.plot(ax=ax[0], style="-")
# 求上个季度(仅含工作日)的平均值
# ********** Begin ********** #
data1 = yh.resample("BQ").mean()
# ********** End ********** #
data1.plot(ax=ax[0], style=":")
# 求每个月末(仅含工作日)的收盘价
# ********** Begin ********** #
data2 = yh.asfreq("BM")
# ********** End ********** #
data2.plot(ax=ax[0], style="--", color="red")
ax[0].legend(['input', 'resample', 'asfreq'], loc='upper right')
# 迁移数据365天
# ********** Begin ********** #
data3 = yh.shift(365)
# ********** End ********** #
data3.plot(ax=ax[1])
data3.resample("BQ").mean().plot(ax=ax[1], style=":")
data3.asfreq("BM").plot(ax=ax[1], style="--", color="red")
# 设置图例与标签
local_max = pd.to_datetime('2007-11-05')
offset = pd.Timedelta(365, 'D')
ax[0].axvline(local_max, alpha=0.3, color='red')
ax[1].axvline(local_max + offset, alpha=0.3, color='red')
# 求一年期移动标准差
# ********** Begin ********** #
rolling = yh.rolling(365)
data4 = rolling.std()
# ********** End ********** #
data4.plot(ax=ax[1], style="y:")
data4.plot(ax=ax[0], style="y:")
plt.savefig("./step3/result/2.png")


![[Collection与数据结构] Map与Set(一):二叉搜索树与Map,Set的使用](https://img-blog.csdnimg.cn/direct/3069ea5b6d6347439610ad8cf557cd17.png)