https://leetcode.cn/problems/word-ladder/description/?envType=study-plan-v2&envId=top-interview-150
文章目录
- 题目描述
- 解题思路
- 代码-BFS
- 解题思路二——双向BFS
- 代码
题目描述
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> … -> sk:
- 每一对相邻的单词只差一个字母。
- 对于 1 <= i <= k 时,每个 si 都在 wordList 中。注意, beginWord 不需要在 wordList 中。
- sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
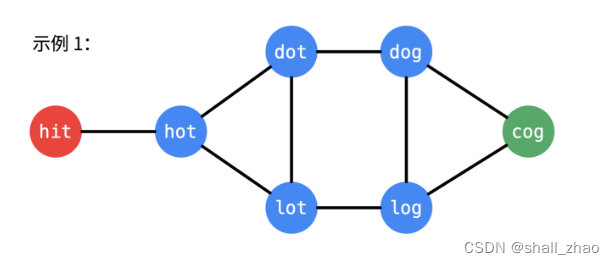
示例 1:
输入:beginWord = “hit”, endWord = “cog”, wordList = [“hot”,“dot”,“dog”,“lot”,“log”,“cog”]
输出:5
解释:一个最短转换序列是 “hit” -> “hot” -> “dot” -> “dog” -> “cog”, 返回它的长度 5。
示例 2:
输入:beginWord = “hit”, endWord = “cog”, wordList = [“hot”,“dot”,“dog”,“lot”,“log”]
输出:0
解释:endWord “cog” 不在字典中,所以无法进行转换。
提示:
1 <= beginWord.length <= 10
endWord.length == beginWord.length
1 <= wordList.length <= 5000
wordList[i].length == beginWord.length
beginWord、endWord 和 wordList[i] 由小写英文字母组成
beginWord != endWord
wordList 中的所有字符串 互不相同
解题思路
-
无向图中两个顶点之间的最短路径的长度,可以通过广度优先遍历得到;
-
为什么 BFS 得到的路径最短?可以把起点和终点所在的路径拉直来看,两点之间线段最短;
-
已知目标顶点的情况下,可以分别从起点和目标顶点(终点)执行广度优先遍历,直到遍历的部分有交集,这是双向广度优先遍历的思想。
-
「转换」意即:两个单词对应位置只有一个字符不同,例如 “hit” 与 “hot”,这种转换是可以逆向的,因此,根据题目给出的单词列表,可以构建出一个无向(无权)图;
-
如果一开始就构建图,每一个单词都需要和除它以外的另外的单词进行比较,复杂度是 O(NwordLen),这里 N是单词列表的长度;当单词个数很多的时候,找到邻居的时间复杂度就很高了。
-
为此,我们在遍历一开始,把所有的单词列表放进一个哈希表中,然后在遍历的时候构建图,每一次得到在单词列表里可以转换的单词,复杂度是 O(26×wordLen),借助哈希表,找到邻居与 N无关;
-
使用 BFS 进行遍历,需要的辅助数据结构是:
- 队列;
- visited 集合。说明:可以直接在 wordSet (由 wordList 放进集合中得到)里做删除。但更好的做法是新开一个哈希表,遍历过的字符串放进哈希表里。这种做法具有普遍意义。绝大多数在线测评系统和应用场景都不会在意空间开销。
代码-BFS
class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
// 单向BFS写法
// 第一步现将wordList放到哈希表中,便于判断某个单词是否在wordList中
Set<String> wordSet = new HashSet<>(wordList);
if(wordSet.size() == 0 || !wordSet.contains(endWord)){
return 0;
}
// 把起点删了,以免节外生枝,不删提交也能过
// wordSet.remove(beginWord);
// 广度的队列
Queue<String> queue = new LinkedList<>();
queue.offer(beginWord);
// 因为是字符串,所以要标记是否使用要用HashSet
Set<String> visited = new HashSet<>();
visited.add(beginWord);
// 开始广搜,包含起点,因此初始化的步数为1
int step = 1;
while(!queue.isEmpty()){
int currentSize = queue.size();
for(int i=0; i< currentSize; i++){
// 依次遍历当前队列中的单词
String currentWord = queue.poll();
// 尝试变异,修改其中的每一个字符,看看是否能与终态匹配
for(int j=0; j<currentWord.length(); j++){
char[] originWord = currentWord.toCharArray();
char originChar = originWord[j]; // 先保存,再恢复,或者使用originWord.clone(),修改备份
for(char k = 'a'; k<= 'z'; k++){
if(originChar == k) // 和当前位置相同,跳过
continue;
originWord[j] = k; // 尝试修改
String nextWord = String.valueOf(originWord); // 还要在换回字符串判断
if(wordSet.contains(nextWord)){
if(nextWord.equals(endWord)){
return step + 1;
}
if(!visited.contains(nextWord)){
queue.offer(nextWord);
visited.add(nextWord); // 注意,添加到队列以后,必须马上标记为已访问
}
}
}
originWord[j] = originChar; // 恢复
}
}
step += 1;
}
return 0;
}
}
解题思路二——双向BFS
- 已知目标顶点的情况下,可以分别从起点和目标顶点(终点)执行广度优先遍历,直到遍历的部分有交集。这种方式搜索的单词数量会更小一些;
- 优化一下,每次从单词数量小的集合开始扩散;
- 这里 beginVisited 和 endVisited 交替使用,等价于单向 BFS 里使用队列,每次扩散都要加到总的 visited 里。
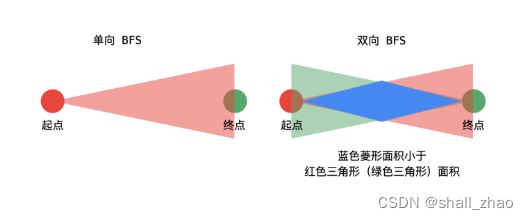
这样可以看出,使用双向BFS遍历的时候,访问的节点个数更少,当两侧的BFS交叉的时候就说明联通了。
代码
class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
// 双向BFS
// 第 1 步:先将 wordList 放到哈希表里,便于判断某个单词是否在 wordList 里
Set<String> wordSet = new HashSet<>(wordList);
if(wordSet.size() == 0 || !wordSet.contains(endWord)){
return 0;
}
// 已经访问过得word,添加到visited哈希表里
Set<String> visited = new HashSet<>();
//分别用左边和右边扩散的哈希表代替单向 BFS 里的队列,它们在双向 BFS 的过程中交替使用
Set<String> beginVisited = new HashSet<>();
beginVisited.add(beginWord);
Set<String> endVisited = new HashSet<>();
endVisited.add(endWord);
visited.add(beginWord);
visited.add(endWord);
// 执行双向BFS,左右交替扩散步数之和为答案
int step = 1;
while(!beginVisited.isEmpty() && !endVisited.isEmpty()){
// 优先选择小的哈希表进行扩散,考虑到的情况更少
if(beginVisited.size() > endVisited.size()){
Set<String> temp = beginVisited;
beginVisited = endVisited;
endVisited = temp;
}
// 逻辑到这里,保证 beginVisited 是相对较小的集合,nextLevelVisited 在扩散完成以后,会成为新的 beginVisited
Set<String> nextLevelVisited = new HashSet<>();
for(String word: beginVisited){
char[] originWord = word.toCharArray();
for(int i=0; i<word.length(); i++){
char originChar = originWord[i];
for(char k = 'a'; k<='z'; k++){
if(originWord[i] == k)
continue;
originWord[i] = k;
String nextWord = String.valueOf(originWord);
if(wordSet.contains(nextWord)){
if(endVisited.contains(nextWord)){ // 前后的BFS交叉了,说明连上了
return step + 1;
}
if(!visited.contains(nextWord)){
nextLevelVisited.add(nextWord);
visited.add(nextWord);
}
}
}
originWord[i] = originChar;
}
}
// 原来的 beginVisited 废弃,从 nextLevelVisited 开始新的双向 BFS
beginVisited = nextLevelVisited;
step++;
}
return 0;
}
}
![[C++核心编程-01]----C++内存四区详细解析](https://img-blog.csdnimg.cn/direct/fa47ee2ea80f4fda9b6c27152cef7d04.png)








![[NSSRound#1 Basic]basic_check](https://img-blog.csdnimg.cn/img_convert/e44781c2d6f7112cb158501699d2e10d.png)