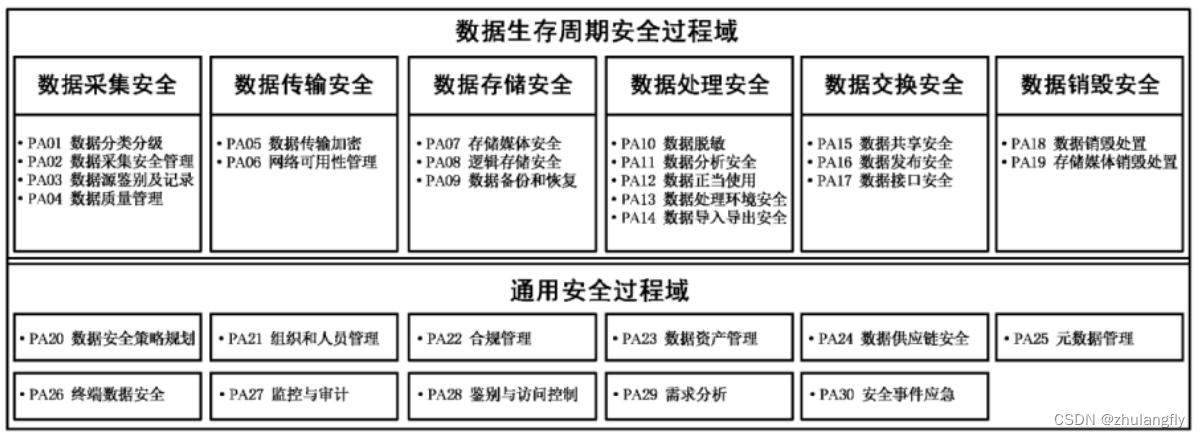
集合容器概述
什么是集合
集合框架:用于存储数据的容器。
集合框架是为表示和操作集合而规定的一种统一的标准的体系结构。
任何集合框架都包含三大块内容:对外的接口、接口的实现和对集合运算的算法。
接口:表示集合的抽象数据类型。接口允许我们操作集合时不必关注具体实现,从而达到“多态”。在面向对象编程语言中,接口通常用来形成规范。
实现:集合接口的具体实现,是重用性很高的数据结构。
算法:在一个实现了某个集合框架中的接口的对象身上完成某种有用的计算的方法,例如查找、排序等。这些算法通常是多态的,因为相同的方法可以在同一个接口被多个类实现时有不同的表现。事实上,算法是可复用的函数。
它减少了程序设计的辛劳。
集合框架通过提供有用的数据结构和算法使你能集中注意力于你的程序的重要部分上,而不是为了让程序能正常运转而将注意力于低层设计上。
通过这些在无关API之间的简易的互用性,使你免除了为改编对象或转换代码以便联合这些API而去写大量的代码。 它提高了程序速度和质量。
集合的特点
集合的特点主要有如下两点:
-
对象封装数据,对象多了也需要存储。集合用于存储对象。
-
对象的个数确定可以使用数组,对象的个数不确定的可以用集合。因为集合是可变长度的。
集合和数组的区别
- 数组是固定长度的;集合可变长度的。
- 数组可以存储基本数据类型,也可以存储引用数据类型;集合只能存储引用数据类型。
- 数组存储的元素必须是同一个数据类型;集合存储的对象可以是不同数据类型。
一、数组声明了它容纳的元素的类型,而集合不声明。
二、数组是静态的,一个数组实例具有固定的大小,一旦创建了就无法改变容量了。而集合是可以动态扩展容量,可以根据需要动态改变大小,集合提供更多的成员方法,能满足更多的需求。
三、数组的存放的类型只能是一种(基本类型/引用类型),集合存放的类型可以不是一种(不加泛型时添加的类型是Object)。
四、数组是java语言中内置的数据类型,是线性排列的,执行效率或者类型检查都是最快的。
数据结构:就是容器中存储数据的方式。
对于集合容器,有很多种。因为每一个容器的自身特点不同,其实原理在于每个容器的内部数据结构不同。
集合容器在不断向上抽取过程中,出现了集合体系。在使用一个体系的原则:参阅顶层内容。建立底层对象。
使用集合框架的好处
- 容量自增长;
- 提供了高性能的数据结构和算法,使编码更轻松,提高了程序速度和质量;
- 允许不同 API 之间的互操作,API之间可以来回传递集合;
- 可以方便地扩展或改写集合,提高代码复用性和可操作性。
- 通过使用JDK自带的集合类,可以降低代码维护和学习新API成本。
常用的集合类有哪些?
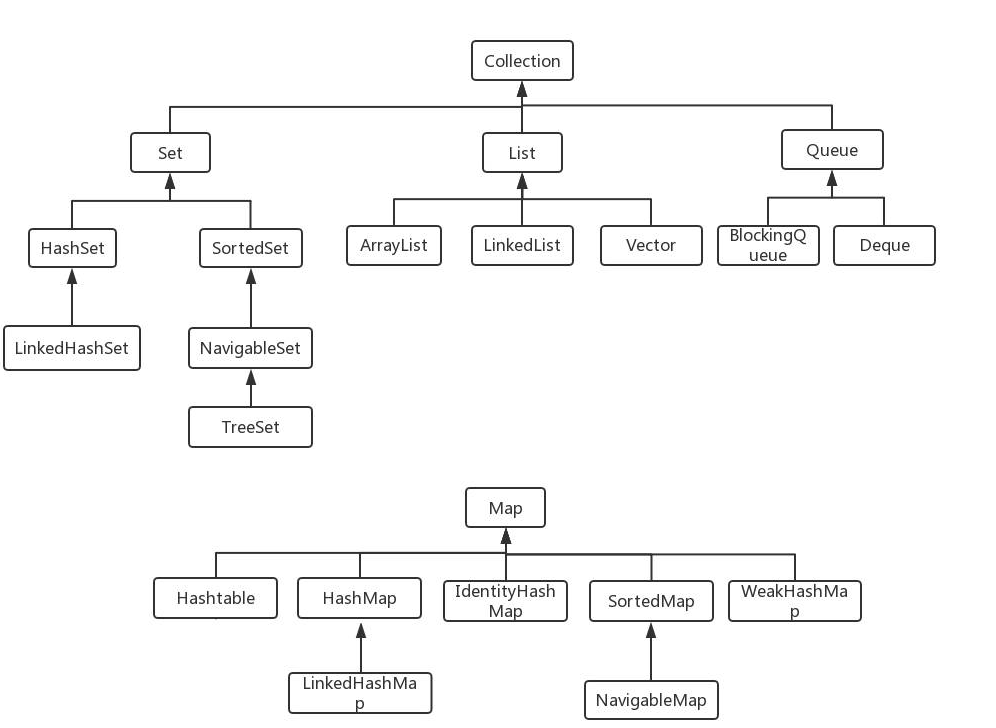
Map接口和Collection接口是所有集合框架的父接口: Collection父类是Iterable
- Collection接口的子接口包括:Set接口和List接口
- Map接口的实现类主要有:HashMap、TreeMap、Hashtable、ConcurrentHashMap以及Properties等
- Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
- List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等
List,Set,Map三者的区别?List、Set、Map 是否继承自 Collection 接口?List、Map、Set 三个接口存取元素时,各有什么特点?
Java 容器分为 Collection 和 Map 两大类,Collection集合的子接口有Set、List、Queue三种子接口。我们比较常用的是Set、List,Map接口不是collection的子接口。
Collection集合主要有List和Set两大接口
-
List:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重复,可以插入多个null元素,元素都有索引。常用的实现类有 ArrayList、LinkedList 和 Vector。(有序可重复)
-
Set:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素,只允许存入一个null元素,必须保证元素唯一性。Set 接口常用实现类是 HashSet、LinkedHashSet 以及 TreeSet。(无序不可重复)
Map是一个键值对集合,存储键、值和之间的映射。 Key无序,唯一;value 不要求有序,允许重复。Map没有继承于Collection接口,从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。 Key相同直接覆盖
Map 的常用实现类:HashMap、TreeMap、HashTable、LinkedHashMap、ConcurrentHashMap
集合框架底层数据结构
Collection
- List
- Arraylist: Object数组
- Vector: Object数组
- LinkedList: 双向循环链表
- Set
- HashSet(无序,唯一):基于 HashMap 实现的,底层采用 HashMap 来保存元素
- LinkedHashSet: LinkedHashSet 继承与 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 Hashmap 实现一样,不过还是有一点点区别的。
- TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树。)
Map
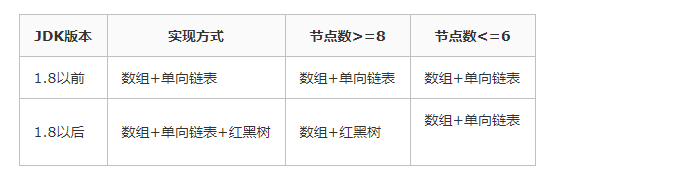
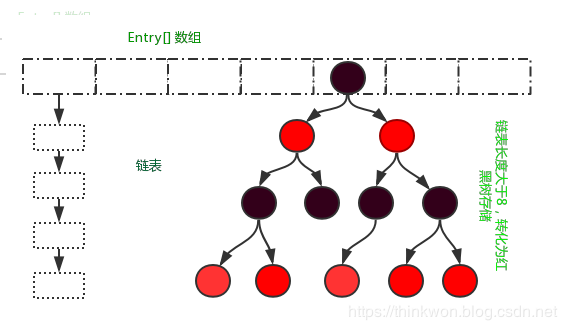
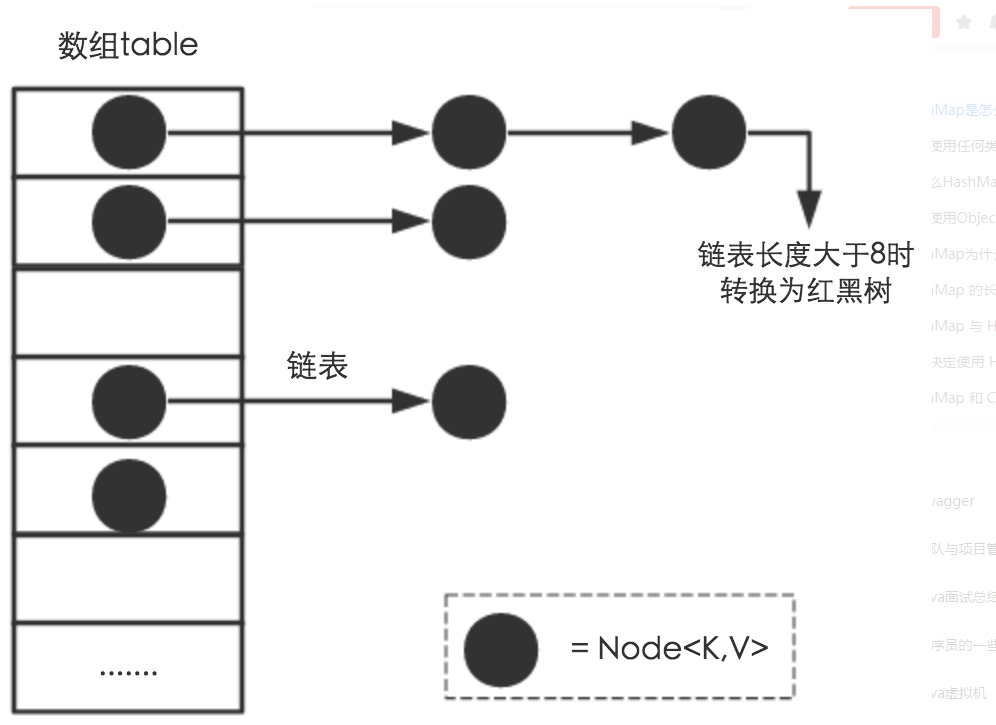
- HashMap: JDK1.8之前HashMap由 数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)并且数组长度大于64时,将链表转化为红黑树,以减少搜索时间
- LinkedHashMap:LinkedHashMap 继承自 HashMap,所以它的**底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。**另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
- HashTable: 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
- TreeMap: 红黑树**(自平衡的排序二叉树)**
LinkedList 的 element()方法 底层其实是 getFirst()和 peek()方法的区别?
两者都是 查看链表的第一个元素,不删除,但是 peek 当查找时,为空链表 返回null getFirst 则抛出NoSuchElementException异常
poll()与remove() 底层调用 removeFirst 也是 如此
哪些集合类是线程安全的?
- vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用。在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的。
- stack:堆栈类,先进后出。
- hashtable:就比hashmap多了个线程安全。
- enumeration:枚举,相当于迭代器。
Java集合的快速失败机制 “fail-fast”?
是java集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作时,有可能会产生 fail-fast 机制。
例如:假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生fail-fast机制。
原因:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
- 在遍历过程中,所有涉及到改变modCount值得地方全部加上synchronized。
- 使用CopyOnWriteArrayList来替换ArrayList
1.1 fail-fast 机制简介
**fail-fast 机制是java集合(Collection)中的一种错误机制。**当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。
例如:当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生fail-fast事件。
import java.util.*; import java.util.concurrent.*; /* * @desc java集合中Fast-Fail的测试程序。 * * fast-fail事件产生的条件:当多个线程对Collection进行操作时,若其中某一个线程通过iterator去遍历集合时,该集合的内容被其他线程所改变;则会抛出ConcurrentModificationException异常。 * fast-fail解决办法:通过util.concurrent集合包下的相应类去处理,则不会产生fast-fail事件。 * * 本例中,分别测试ArrayList和CopyOnWriteArrayList这两种情况。ArrayList会产生fast-fail事件,而CopyOnWriteArrayList不会产生fast-fail事件。 * (01) 使用ArrayList时,会产生fast-fail事件,抛出ConcurrentModificationException异常;定义如下: * private static List<String> list = new ArrayList<String>(); * (02) 使用时CopyOnWriteArrayList,不会产生fast-fail事件;定义如下: * private static List<String> list = new CopyOnWriteArrayList<String>(); * * @author Zeng */ public class FastFailTest { private static List<String> list = new ArrayList<String>(); //private static List<String> list = new CopyOnWriteArrayList<String>(); public static void main(String[] args) { // 同时启动两个线程对list进行操作! new ThreadOne().start(); new ThreadTwo().start(); } private static void printAll() { System.out.println(""); String value = null; Iterator iter = list.iterator(); while(iter.hasNext()) { value = (String)iter.next(); System.out.print(value+", "); } } /** * 向list中依次添加0,1,2,3,4,5,每添加一个数之后,就通过printAll()遍历整个list */ private static class ThreadOne extends Thread { public void run() { int i = 0; while (i<6) { list.add(String.valueOf(i)); printAll(); i++; } } } /** * 向list中依次添加10,11,12,13,14,15,每添加一个数之后,就通过printAll()遍历整个list */ private static class ThreadTwo extends Thread { public void run() { int i = 10; while (i<16) { list.add(String.valueOf(i)); printAll(); i++; } } } }运行结果
运行该代码,抛出异常java.util.ConcurrentModificationException!产生fail-fast事件!
结果说明
- FastFailTest中通过 new ThreadOne().start() 和 new ThreadTwo().start() 同时启动两个线程去操作list
ThreadOne线程:向list中依次添加0,1,2,3,4,5。每添加一个数之后,就通过printAll()遍历整个list
ThreadTwo线程:向list中依次添加10,11,12,13,14,15。每添加一个数之后,就通过printAll()遍历整个list - 当某一个线程遍历list的过程中,list的内容被另外一个线程所改变了;就会抛出ConcurrentModificationException异常,产生fail-fast事件
1.3 fail-fast解决办法
fail-fast机制,是一种错误检测机制。**它只能被用来检测错误,因为JDK并不保证fail-fast机制一定会发生。**若在多线程环境下使用fail-fast机制的集合,建议使用“java.util.concurrent包下的类”去取代“java.util包下的类”。
所以,本例中只需要将ArrayList替换成java.util.concurrent包下对应的类即可。
将代码private static List<String> list = new ArrayList<String>();替换为
private static List<String> list = new CopyOnWriteArrayList<String>();怎么确保一个集合不能被修改?
可以使用 Collections. unmodifiableCollection(Collection c) 方法来创建一个只读集合,这样改变集合的任何操作都会抛出 Java. lang. UnsupportedOperationException 异常。
List<String> list = new ArrayList<>(); list. add("x"); Collection<String> clist = Collections. unmodifiableCollection(list); clist. add("y"); // 运行时此行报错 System. out. println(list. size());
* 为什么会报ConcurrentModificationException异常?
* 1. Iterator 是工作在一个独立的线程中,并且拥有一个 mutex 互斥锁。
* 2. Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,
* 这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,
* 3. 所以按照 fail-fast 原则 Iterator 会马上抛出 java.util.ConcurrentModificationException 异常。
* 4. 所以 Iterator 在工作的时候是不允许被迭代的对象被改变的。
Collection接口
List接口
迭代器 Iterator 是什么?
Iterator 接口提供遍历任何 Collection 的接口。我们可以从一个 Collection 中使用迭代器方法来获取迭代器实例。迭代器取代了 Java 集合框架中的 Enumeration,迭代器允许调用者在迭代过程中移除元素。
Iterator 怎么使用?有什么特点?
List<String> list = new ArrayList<>();
Iterator<String> it = list. iterator();
while(it. hasNext()){
String obj = it. next();
System. out. println(obj);
}
Iterator 的特点是只能单向遍历,但是更加安全,因为它可以确保,在当前遍历的集合元素被更改的时候,就会抛出 ConcurrentModificationException 异常。
如何边遍历边移除 Collection 中的元素?
Iterator<Integer> it = list.iterator();
while(it.hasNext()){
*// do something*
it.remove();
}
一种最常见的错误代码如下:
for(Integer i : list){
list.remove(i)
}
运行以上错误代码会报 ConcurrentModificationException 异常。这是因为当使用 foreach(for(Integer i : list)) 语句时,会自动生成一个iterator 来遍历该 list,但同时该 list 正在被 Iterator.remove() 修改。Java 一般不允许一个线程在遍历 Collection 时另一个线程修改它。
主要是集合遍历是使用Iterator, Iterator是工作在一个独立的线程中,并且拥有一个互斥锁。Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,所以按照 fail-fast原则 Iterator 会马上抛出java.util.ConcurrentModificationException 异常。所以 Iterator 在工作的时候是不允许被迭代的对象被改变的。
ArrayList中MAX_ARRAY_SIZE为什么是 Integer.MAX_VALUE - 8 以及数组在java中到底是什么数据类型
数组在java里是一种特殊类型,既不是基本数据类型(开玩笑,当然不是)也不是引用数据类型。
有别于普通的“类的实例”对象,java里数组不是类,所以也就没有对应的class文件,数组类型是由jvm从元素类型合成出来的;在jvm中获取数组的长度是用arraylength这个专门的字节码指令的;
在数组的对象头里有一个_length字段,记录数组长度,只需要去读_length字段就可以了。

所以ArrayList中定义的最大长度为Integer最大值减8,这个8就是就是存了数组_length字段。
Iterator 和 ListIterator 有什么区别?
- Iterator 可以遍历 Set 和 List 集合,而 ListIterator 只能遍历 List。
- Iterator 只能单向遍历,而 ListIterator 可以双向遍历(向前/后遍历)。
- ListIterator 实现 Iterator 接口,然后添加了一些额外的功能,比如添加一个元素、替换一个元素、获取前面或后面元素的索引位置。
遍历一个 List 有哪些不同的方式?每种方法的实现原理是什么?Java 中 List 遍历的最佳实践是什么?
遍历方式有以下几种:
- for 循环遍历,基于计数器。在集合外部维护一个计数器,然后依次读取每一个位置的元素,当读取到最后一个元素后停止。
- 迭代器遍历,Iterator。Iterator 是面向对象的一个设计模式,目的是屏蔽不同数据集合的特点,统一遍历集合的接口。Java 在 Collections 中支持了 Iterator 模式。
- foreach 循环遍历。foreach 内部也是采用了 Iterator 的方式实现,使用时不需要显式声明 Iterator 或计数器。优点是代码简洁,不易出错;缺点是只能做简单的遍历,不能在遍历过程中操作数据集合,例如删除、替换。
最佳实践:Java Collections 框架中提供了一个 RandomAccess 接口,用来标记 List 实现是否支持 Random Access。
- 如果一个数据集合实现了该接口,就意味着它支持 Random Access,按位置读取元素的平均时间复杂度为 O(1),如ArrayList。
- 如果没有实现该接口,表示不支持 Random Access,如LinkedList。
推荐的做法就是,支持 Random Access 的列表可用 for 循环遍历,否则建议用 Iterator 或 foreach 遍历。
说一下 ArrayList 的优缺点
ArrayList的优点如下:
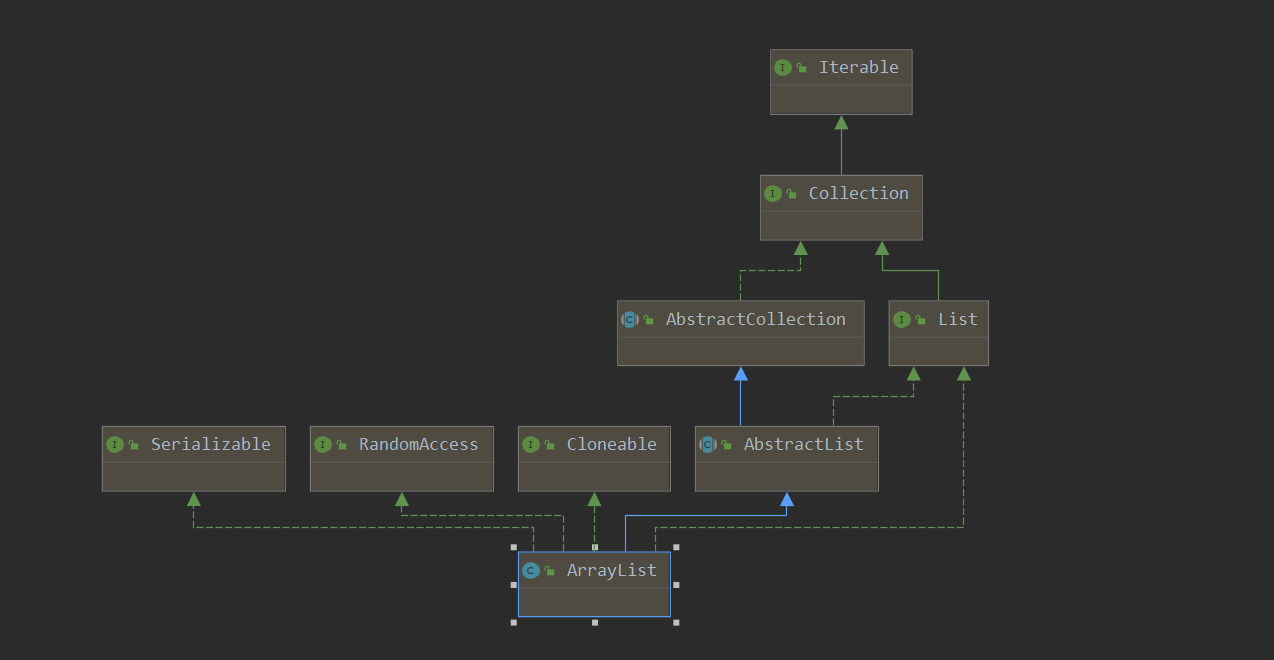
- ArrayList 底层以数组实现,是一种随机访问模式。ArrayList 实现了 RandomAccess 接口,因此查找的时候非常快。
- ArrayList 在顺序添加一个元素的时候非常方便。
ArrayList 的缺点如下:
- 删除元素的时候,需要做一次元素复制操作。如果要复制的元素很多,那么就会比较耗费性能。
- 插入元素的时候,也需要做一次元素复制操作,缺点同上。
ArrayList 比较适合顺序添加、随机访问的场景。
如何实现数组和 List 之间的转换?
- 数组转 List:使用 Arrays. asList(array) 进行转换。
- List 转数组:使用 List 自带的 toArray() 方法。
// list to array
List<String> list = new ArrayList<String>();
list.add("123");
list.add("456");
list.toArray();
// array to list
String[] array = new String[]{"123","456"};
Arrays.asList(array);
ArrayList 和 LinkedList 的区别是什么?
ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
本文主要看一下,两种List集合,插入删除效率情况,为什么使用ArrayList的情况更多些?
LinkedList首部插入数据很快,因为只需要修改插入元素前后节点的prev值和next值即可。
ArrayList首部插入数据慢,因为数组复制的方式移位耗时多。
LinkedList中间插入数据慢,因为遍历链表指针(二分查找)耗时多;
ArrayList中间插入数据快,因为定位插入元素位置快,移位操作的元素没那么多。
LinkedList尾部插入数据慢,因为遍历链表指针(二分查找)耗时多;
ArrayList尾部插入数据快,因为定位速度快,插入后移位操作的数据量少;
总结:在集合里面插入元素速度比对结果是,首部插入,LinkedList更快;中间和尾部插入,ArrayList更快;
在集合里面删除元素类似,首部删除,LinkedList更快;中间删除和尾部删除,ArrayList更快;
由此建议,数据量不大的集合,主要进行插入、删除操作,建议使用LinkedList;
数据量大的集合,使用ArrayList就可以了,不仅查询速度快,并且插入和删除效率也相对较高
- 数据结构实现:ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现。
- 随机访问效率:ArrayList 比 LinkedList 在随机访问的时候效率要高,因为 LinkedList 是线性的数据存储方式,所以需要移动指针从前往后依次查找。
- 增加和删除效率:在非首尾的增加和删除操作,LinkedList 要比 ArrayList 效率要高,因为 ArrayList 增删操作要影响数组内的其他数据的下标。
- 内存空间占用:LinkedList 比 ArrayList 更占内存,因为 LinkedList 的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
- 主要控件开销不同ArrayList主要控件开销在于需要在lList列表预留一定空间;而LinkedList主要控件开销在于需要存储结点信息以及结点指针信息。
- 线程安全:ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
- 自由性不同ArrayList自由性较低,因为它需要手动的设置固定大小的容量,但是它的使用比较方便,只需要创建,然后添加数据,通过调用下标进行使用;而LinkedList自由性较高,能够动态的随数据量的变化而变化,但是它不便于使用。
综合来说,在需要频繁读取集合中的元素时,更推荐使用 ArrayList,而在插入和删除操作较多时,更推荐使用 LinkedList。
补充:数据结构基础之双向链表
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
什么时候用LinkList,什么时候用ArrayList
当操作是在一列 数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能;
当你的操作是在一列数据的前面或中 间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
ArrayList的JDK1.8之前与之后的实现区别?
JDK1.7:ArrayList像饿汉式,直接创建一个初始容量为10的数组
JDK1.8:ArrayList像懒汉式,一开始创建一个长度为0的数组,当添加第一个元素时再创建一个始容量为10的数组
概括的说,LinkedList 是线程不安全的,允许元素为null的双向链表。
其底层数据结构是链表,它实现List<E>, Deque<E>, Cloneable, java.io.Serializable接口,它实现了Deque<E>,所以它也可以作为一个双端队列。和ArrayList比,没有实现RandomAccess所以其以下标,随机访问元素速度较慢。
因其底层数据结构是链表,所以可想而知,它的增删只需要移动指针即可,故时间效率较高。不需要批量扩容,也不需要预留空间,所以空间效率比ArrayList高。
缺点就是需要随机访问元素时,时间效率很低,虽然底层在根据下标查询Node的时候,会根据index判断目标Node在前半段还是后半段,然后决定是顺序还是逆序查询,以提升时间效率。不过随着n的增大,总体时间效率依然很低。
当每次增、删时,都会修改modCount。
总结:
LinkedList 是双向列表。
- 链表批量增加,是靠for循环遍历原数组,依次执行插入节点操作。对比ArrayList是通过System.arraycopy完成批量增加的。增加一定会修改modCount。
- 通过下标获取某个node 的时候,(add select),会根据index处于前半段还是后半段 进行一个折半,以提升查询效率
- 删也一定会修改modCount。 按下标删,也是先根据index找到Node,然后去链表上unlink掉这个Node。 按元素删,会先去遍历链表寻找是否有该Node,如果有,去链表上unlink掉这个Node。
- 改也是先根据index找到Node,然后替换值。改不修改modCount。
- 查本身就是根据index找到Node。
- 所以它的CRUD操作里,都涉及到根据index去找到Node的操作。
ArrayList 和 Vector 的区别是什么?
这两个类都实现了 List 接口(List 接口继承了 Collection 接口),他们都是有序集合
- 线程安全:Vector 使用了 Synchronized 来实现线程同步,是线程安全的,而 ArrayList 是非线程安全的。
- 性能:ArrayList 在性能方面要优于 Vector。
- 扩容:ArrayList 和 Vector 都会根据实际的需要动态的调整容量,只不过在 Vector 扩容每次会增加 1 倍如果有增长系数 则变为 原来的值 + 增长系数,而 ArrayList 只会增加 50%。
- 初始化 vector 容量 10 增长系数 0 也就是 initialCapacity = 10,capacityIncrement = 0; ArrayList初始化 10 DEFAULT_CAPACITY= 10
Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
Arraylist不是同步的,所以在不需要保证线程安全时时建议使用Arraylist。
插入数据时,ArrayList、LinkedList、Vector谁速度较快?阐述 ArrayList、Vector、LinkedList 的存储性能和特性?
ArrayList、Vector 底层的实现都是使用数组方式存储数据。数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢。
Vector 中的方法由于加了 synchronized 修饰,因此 Vector 是线程安全容器,但性能上较ArrayList差。
LinkedList 使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但插入数据时只需要记录当前项的前后项即可,所以 LinkedList 插入速度较快。
多线程场景下如何使用 ArrayList?
ArrayList 不是线程安全的,如果遇到多线程场景,可以通过 Collections 的 synchronizedList 方法将其转换成线程安全的容器后再使用。例如像下面这样:
List<String> synchronizedList = Collections.synchronizedList(list);
synchronizedList.add("aaa");
synchronizedList.add("bbb");
for (int i = 0; i < synchronizedList.size(); i++) {
System.out.println(synchronizedList.get(i));
}
为什么 ArrayList 的 elementData 加上 transient 修饰?
ArrayList 中的数组定义如下:
private transient Object[] elementData;
再看一下 ArrayList 的定义:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
可以看到 ArrayList 实现了 Serializable 接口,这意味着 ArrayList 支持序列化。transient 的作用是说不希望 elementData 数组被序列化,重写了 writeObject 实现:
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{
*// Write out element count, and any hidden stuff*
int expectedModCount = modCount;
s.defaultWriteObject();
*// Write out array length*
s.writeInt(elementData.length);
*// Write out all elements in the proper order.*
for (int i=0; i<size; i++)
s.writeObject(elementData[i]);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
每次序列化时,先调用 defaultWriteObject() 方法序列化 ArrayList 中的非 transient 元素,然后遍历 elementData,只序列化已存入的元素,这样既加快了序列化的速度,又减小了序列化之后的文件大小。
List 和 Set 的区别
List , Set 都是继承自Collection 接口
List 特点:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重复,可以插入多个null元素,元素都有索引。常用的实现类有 ArrayList、LinkedList 和 Vector。
Set 特点:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素,只允许存入一个null元素,必须保证元素唯一性。Set 接口常用实现类是 HashSet、LinkedHashSet 以及 TreeSet。
另外 List 支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想要的值。
Set和List对比
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变
Set接口
说一下 HashSet 的实现原理?
HashSet 是基于 HashMap 实现的,HashSet的值存放于HashMap的key上,HashMap的value统一为PRESENT,因此 HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,HashSet 不允许重复的值。
HashSet如何检查重复?HashSet是如何保证数据不可重复的?
向HashSet 中add ()元素时,判断元素是否存在的依据,不仅要比较hash值,同时还要结合equles 方法比较。
HashSet 中的add ()方法会使用HashMap 的put()方法。
HashMap 的 key 是唯一的,由源码可以看出 HashSet 添加进去的值就是作为HashMap 的key,并且在HashMap中如果K/V相同时,会用新的V覆盖掉旧的V,然后返回旧的V。所以不会重复( HashMap 比较key是否相等是先比较hashcode 再比较equals )。
以下是HashSet 部分源码:
private static final Object PRESENT = new Object();
private transient HashMap<E,Object> map;
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
// 调用HashMap的put方法,PRESENT是一个至始至终都相同的虚值
return map.put(e, PRESENT)==null;
}
hashCode()与equals()的相关规定:
- 如果两个对象相等,则hashcode一定也是相同的
- 两个对象相等,对两个equals方法返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的
- 综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
- hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
==与equals的区别
- == 是判断两个变量或实例是不是指向同一个内存空间 equals是判断两个变量或实例所指向的内存空间的值是不是相同
- == 是指对内存地址进行比较 equals()是对字符串的内容进行比较
- == 指引用是否相同 equals()指的是值是否相同
== 基本数据类型比较值,引用类型比较地址是否相等
HashSet与HashMap的区别

Queue
BlockingQueue是什么?
Java.util.concurrent.BlockingQueue是一个队列,在进行检索或移除一个元素的时候,它会等待队列变为非空;
当在添加一个元素时,它会等待队列中的可用空间。
BlockingQueue接口是Java集合框架的一部分,主要用于实现生产者-消费者模式。
我们不需要担心等待生产者有可用的空间,或消费者有可用的对象,因为它都在BlockingQueue的实现类中被处理了。
Java提供了集中BlockingQueue的实现,比如ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue,、SynchronousQueue等。
在 Queue 中 poll()和 remove()有什么区别?
- 相同点:都是返回第一个元素,并在队列中删除返回的对象。
- 不同点:如果没有元素 poll()会返回 null,而 remove()会直接抛出 NoSuchElementException 异常。
Queue<String> queue = new LinkedList<String>();
queue. offer("string"); // add
System. out. println(queue. poll());
System. out. println(queue. remove());
System. out. println(queue. size());
Map接口
HahsMap
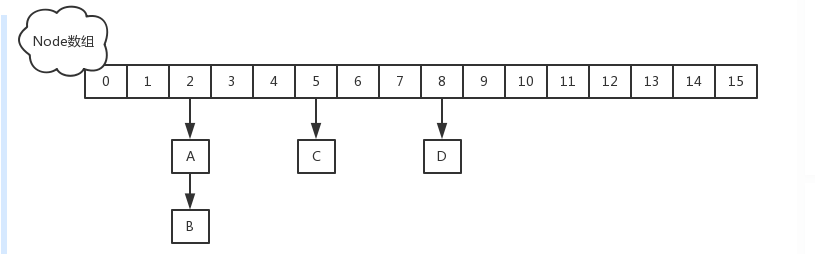
HashMap。HashMap 最早出现在JDK 1.2中,底层基于散列算法实现。
HashMap 允许null键和null值,
在计算哈键的哈希值时,null 键哈希值为0。
HashMap并不保证键值对的顺序,这意味着在进行某些操作后,键值对的顺序可能会发生变化。
另外,需要注意的是,HashMap 是非线程安全类,在多线程环境下可能会存在问题。
注意:不是说变成了红黑树效率就一定提高了,只有在链表的长度不小于8,而且数组的长度不小于64的时候才会将链表转化为红黑树,
hashMap初始容量赋值为1w,存入 1w 条数据,会进行扩容吗,1000条?
当指定初始容量,且table未初始化时,首先使用初始容量的HashMap构造器,会调用tableSizeFor() 方法进行处理,再把结果赋值给threshold (阈值)。当第一次添加元素的时候,会进行初始化,新的容量变为原来的阈值(既tableSizeFor()方法处理后的值),再,新的阈值为新的容量乘以负载因子1w经过 tableSizeFor() 方法处理之后,阈值变成 2 的 14 次幂 16384,初始化后,新的容量为原来的阈值16384,新的阈值为12288(16384 * 0.75)大于一万,所以不会扩容
1000条经过 tableSizeFor() 方法处理之后,阈值变成1024,初始化后,新的容量为原来的阈值1024,新的阈值为768(1024 * 0.75)小于1000,所以会扩容
https://www.cnblogs.com/xyy2019/p/11765941.html
为什么1.8中扩容后的元素新位置为原位置加数组长度?
https://blog.csdn.net/qq32933432/article/details/86668385
可以看到,由于每次扩容会把原数组的长度*2,那么再二进制上的表现就是多出来一个1,比如元数组16-1二进制为1111,那么扩容后的32-1的二进制就变成了1 1111
而扩容前和扩容后的位置是否一样完全取决于多出来的那一位与key值的hash做按位与运算之后的值值是为0还是1。为0则新位置与原位置相同,不需要换位置,不为零则需要换位置。
而为什么新的位置是原位置+原数组长度,是因为==每次换的位置只是前面多了一个1而已==。那么新位置的变化的高位进1位。而每一次高位进1都是在加上原数组长度的过程。

正好1+2=3 3+4=7 7+8=15 。也就验证了新的位置为原位置+原数组长度。
总结
jdk1.8中在计算新位置的时候并没有跟1.7中一样重新进行hash运算,而是用了原位置+原数组长度这样一种很巧妙的方式,而这个结果与hash运算得到的结果是一致的,只是会更块。
HahsMap中containsKey和get的区别
Map集合允许值对象为null,并且没有个数限制,所以当get()方法的返回值为null时,可能有两种情况,一种是在集合中没有该键对象,另一种是该键对象没有映射任何值对象,即值对象为null。因此,在Map集合中不应该利用get()方法来判断是否存在某个键,而应该利用containsKey()方法来判断
https://blog.csdn.net/u012903926/article/details/47293521
为什么HashMap是线程不安全的?
主要体现
· jdk1.7中,当多线程操作同一map时,在扩容的时候会因链表反转发生循环链表或丢失数据的情况
· jdk1.8中,当多线程操作同一map时,会发生数据覆盖的情况
在put的时候,由于put的动作不是原子性的,线程A在计算好链表位置后,挂起,线程B正常执行put操作,之后线程A恢复,会直接替换掉线程b put的值 所以依然不是线程安全的
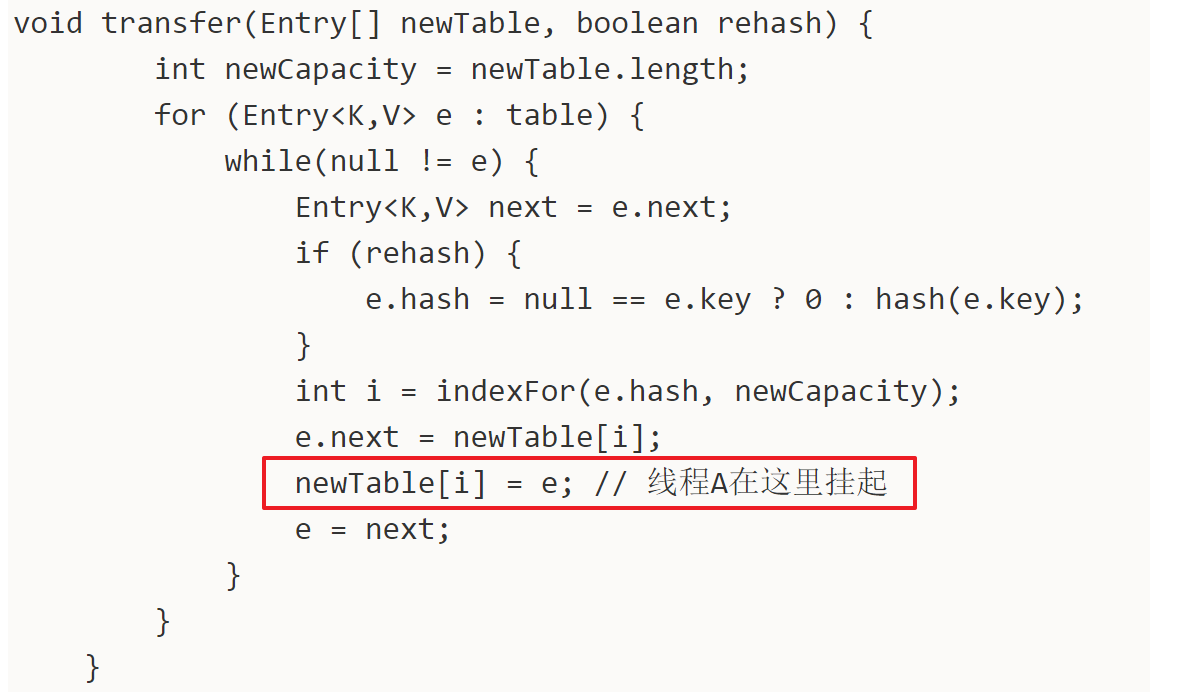
jdk1.7中HashMap的transfer函数如下:
1 void transfer(Entry[] newTable, boolean rehash) {
2 int newCapacity = newTable.length;
3 for (Entry<K,V> e : table) {
4 while(null != e) {
5 Entry<K,V> next = e.next;
6 if (rehash) {
7 e.hash = null == e.key ? 0 : hash(e.key);
8 }
9 int i = indexFor(e.hash, newCapacity);
10 e.next = newTable[i];
11 newTable[i] = e;
12 e = next;
13 }
14 }
15 }
总结下该函数的主要作用:
在对table进行扩容到newTable后,需要将原来数据转移到newTable中,注意10-12行代码,这里可以看出在转移元素的过程中,使用的是头插法,也就是链表的顺序会翻转,这里也是形成死循环的关键点。下面进行详细分析。
前提条件:
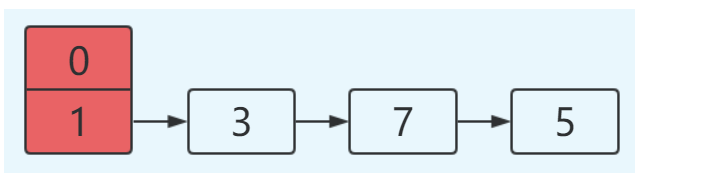
这里假设
#1.hash算法为简单的用key mod链表的大小。
#2.最开始hash表size=2,key=3,7,5,则都在table[1]中。
#3.然后进行resize,使size变成4。
未resize前的数据结构如下:
如果在单线程环境下,最后的结果如下:
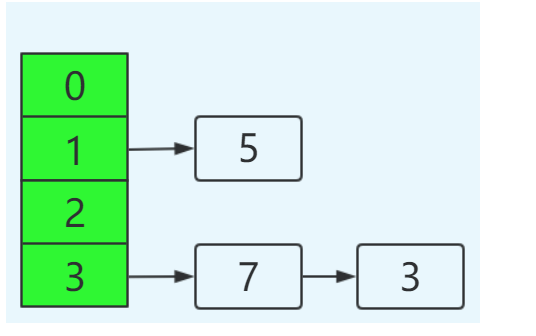
这里的转移过程,不再进行详述,只要理解transfer函数在做什么,其转移过程以及如何对链表进行反转应该不难。
然后在多线程环境下,假设有两个线程A和B都在进行put操作。线程A在执行到transfer函数中第11行代码处挂起,因为该函数在这里分析的地位非常重要,因此再次贴出来。
此时线程A中运行结果如下:

线程A挂起后,此时线程B正常执行,并完成resize操作,结果如下:
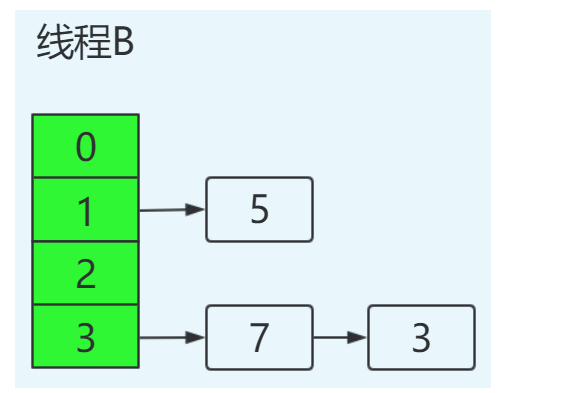
这里需要特别注意的点:由于线程B已经执行完毕,根据Java内存模型,现在newTable和table中的Entry都是主存中最新值:7.next=3,3.next=null。
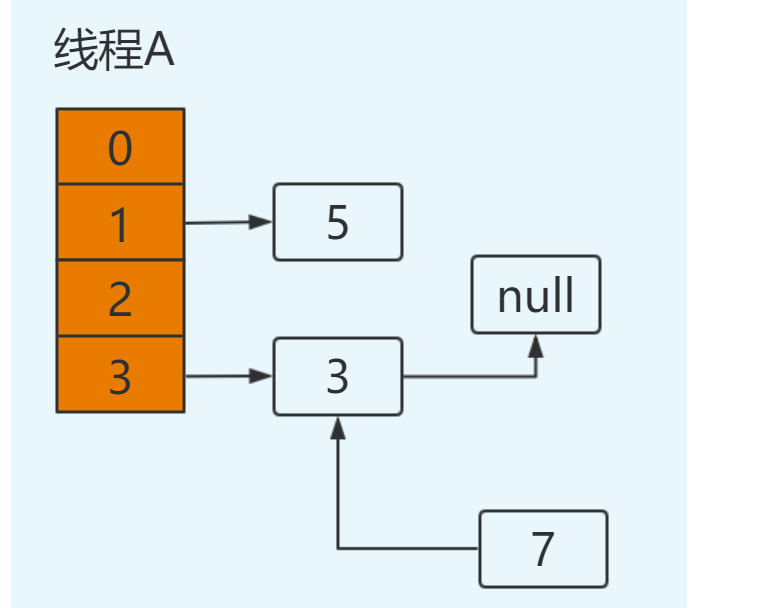
此时切换到线程A上,在线程A挂起时内存中值如下:e=3,next=7,newTable[3]=null,代码执行过程如下:
newTable[3]=e ----> newTable[3]=3
e=next ----> e=7
此时结果如下:
继续循环:
e=7
next=e.next ----> next=3【从主存中取值】
e.next=newTable[3] ----> e.next=3【从主存中取值】
newTable[3]=e ----> newTable[3]=7
e=next ----> e=3
结果如下:

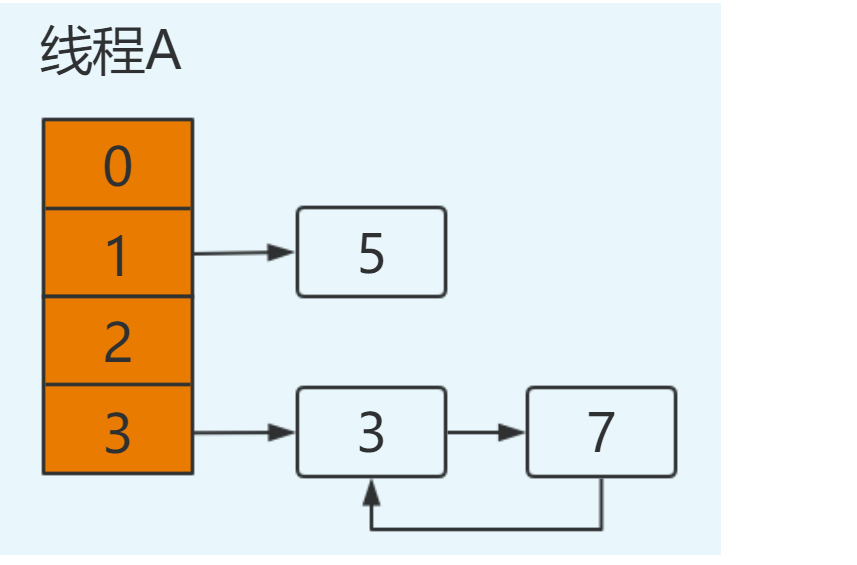
再次进行循环:
e=3
next=e.next ----> next=null
e.next=newTable[3] ----> e.next=7 即:3.next=7
newTable[3]=e ----> newTable[3]=3
e=next ----> e=null
注意此次循环:e.next=7,而在上次循环中7.next=3,出现环形链表,并且此时e=null循环结束。
结果如下:
在后续操作中只要涉及轮询hashmap的数据结构,就会在这里发生死循环,造成悲剧。
在jdk1.8中对HashMap进行了优化,在发生hash碰撞,不再采用头插法方式,而是直接插入链表尾部,因此不会出现环形链表的情况,但是在多线程的情况下仍然不安全,
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 如果没有hash碰撞则直接插入元素
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
这是jdk1.8中HashMap中put操作的主函数, 注意第6行代码,如果没有hash碰撞则会直接插入元素。如果线程A和线程B同时进行put操作,刚好这两条不同的数据hash值一样,并且该位置数据为null,所以这线程A、B都会进入第6行代码中。假设一种情况,线程A进入后还未进行数据插入时挂起,而线程B正常执行,从而正常插入数据,然后线程A获取CPU时间片,此时线程A不用再进行hash判断了,问题出现:线程A会把线程B插入的数据给覆盖,发生线程不安全。
这里只是简要分析下jdk1.8中HashMap出现的线程不安全问题的体现,后续将会对java的集合框架进行总结,到时再进行具体分析。
首先HashMap是线程不安全的,其主要体现:
1.在jdk1.7中,在多线程环境下,扩容时会造成环形链或数据丢失。
2.在jdk1.8中,在多线程环境下,会发生数据覆盖的情况。
HashMap中元素在数组中的下标
Index=(key的hashCode与其高16位进行异或运算)再与(数组长度-1)进行与的运算
HahsMap转变为红黑树
链表长度大于或等于8,数组长度大于或等于64转变为红黑树
小于或等于6退化为链表
问题一:什么是红黑树呢?
红黑树是一个自平衡的二叉查找树,也就是说红黑树的查找效率是非常的高,查找效率会从链表的o(n)降低为o(logn)。如果之前没有了解过红黑树的话,也没关系,你就记住红黑树的查找效率很高就OK了
问题二:为什么不一下子把整个链表变为红黑树呢?
这个问题的意思是这样的,就是说我们为什么非要等到链表的长度大于等于8的时候,才转变成红黑树?在这里可以从两方面来解释
(1)构造红黑树要比构造链表复杂,在链表的节点不多的时候,从整体的性能看来, 数组+链表+红黑树的结构可能不一定比数组+链表的结构性能高。就好比杀鸡焉用牛刀的意思。
(2)HashMap频繁的扩容,会造成底部红黑树不断的进行拆分和重组,这是非常耗时的。因此,也就是链表长度比较长的时候转变成红黑树才会显著提高效率。
OK,到这里相信我们对hashMap的底层数据结构有了一个认识。现在带着上面的结构图,看一下如何存储一个元素。
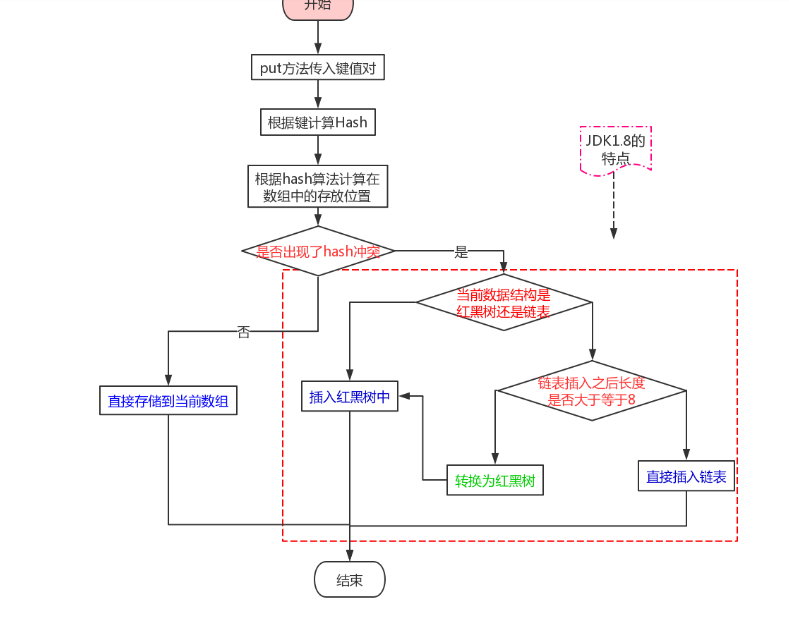
上面这个流程,不知道你能否看到,红色字迹的是三个判断框,也是转折点,我们使用文字来梳理一下这个流程:
(1)第一步:调用put方法传入键值对
(2)第二步:使用hash算法计算hash值
(3)第三步:根据hash值确定存放的位置,判断是否和其他键值对位置发生了冲突
(4)第四步:若没有发生冲突,直接存放在数组中即可
(5)第五步:若发生了冲突,还要判断此时的数据结构是什么?
(6)第六步:若此时的数据结构是红黑树,那就直接插入红黑树中
(7)第七步:若此时的数据结构是链表,判断插入之后是否大于等于8
(8)第八步:插入之后大于8了,就要先调整为红黑树,在插入
(9)第九步:插入之后不大于8,那么就直接插入到链表尾部即可。
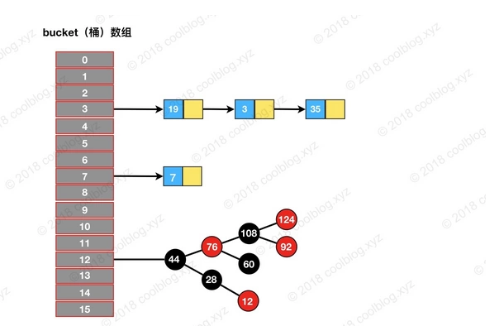
对于拉链式的散列算法,其数据结构是由数组和链表(或树形结构)组成。在进行增删查等操作时,首先要定位到元素的所在桶的位置,之后再从链表中定位该元素。比如我们要查询上图结构中是否包含元素 35,步骤如下:
- 定位元素
35所处桶的位置,index = 35 % 16 = 3 - 在
3号桶所指向的链表中继续查找,发现35在链表中。
考虑一个问题:桶数组 table 是 HashMap 底层重要的数据结构,不序列化的话,别人还怎么还原呢?
HashMap 并没有使用默认的序列化机制,而是通过实现 readObject/writeObject 两个方法自定义了序列化的内容。HashMap 中存储的内容是键值对,只要把键值对序列化了,就可以根据键值对数据重建 HashMap。
也有的人可能会想,序列化 table 不是可以一步到位,后面直接还原不就行了吗?但序列化 table 存在着两个问题:
- table 多数情况下是无法被存满的,序列化未使用的部分**,浪费空间**
- 同一个键值对在不同 JVM 下,所处的桶位置可能是不同的,在不同的 JVM 下反序列化 table 可能会发生错误。
以上两个问题中,第一个问题比较好理解,第二个问题解释一下。
HashMap 的 get/put/remove 等方法第一步就是根据 hash 找到键所在的桶位置,但如果键没有覆写 hashCode 方法,计算 hash 时最终调用 Object 中的 hashCode 方法。但 Object 中的 hashCode 方法是 native 型的,**不同的 JVM 下,可能会有不同的实现,产生的 hash 可能也是不一样的。**也就是说==同一个键在不同平台下可能会产生不同的 hash,此时再对在同一个 table 继续操作,就会出现问题。==
loadFactor 负载因子
loadFactor 指的是负载因子 HashMap 能够承受住自身负载(大小或容量)的因子,loadFactor 的默认值为 0.75 认情况下,数组大小为 16,那么当 HashMap 中元素个数超过 16 * 0.75=12 的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知 HashMap 中元素的个数,那么预设元素的个数能够有效的提高 HashMap 的性能
**负载因子越大表示散列表的装填程度越高,反之愈小。**对于使用链表法的散列表来说,查找一个元素的平均时间是 O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费
需要指出的一点是:HashMap 要求容量必须是 2 的幂
先看看阈值的计算方法,需要指出的一点是:HashMap 要求容量必须是 2 的****幂 。阈值具体计算方式如下:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
下面分析这个算法:
首先,要注意的是这个操作是无符号右移后,再或上原来的值。
为什么要对 cap 做减 1 操作:int n = cap - 1 ?
这是为了防止,cap 已经是 2 的幂。如果 cap 已经是 2 的幂, 又没有执行这个减 1 操作,则执行完后面的几条无符号右移操作之后,返回的 capacity 将是这个 cap 的 2 倍。如果不懂,要看完后面的几个无符号右移之后再回来看看。
下面看看这几个无符号右移操作:
如果 n 这时为 0 了(经过了 cap-1 之后),则经过后面的几次无符号右移依然是 0,最后返回的 capacity 是 1(最后有个 n+1 的操作)。
这里只讨论 n 不等于 0 的情况。
第一次右移
n |= n >>> 1;
由于 n 不等于 0,则 n 的二进制表示中总会有一bit为 1,这时考虑最高位的 1。通过无符号右移 1 位,则将最高位的 1 右移了 1 位,再做或操作,使得 n 的二进制表示中与最高位的 1 紧邻的右边一位也为 1,如 000011xxxxxx。
第二次右移
n |= n >>> 2;
注意,这个 n 已经经过了 n |= n >>> 1; 操作。假设此时 n 为 000011xxxxxx ,则 n 无符号右移两位,会将最高位两个连续的 1 右移两位,然后再与原来的 n 做或操作,这样 n 的二进制表示的高位中会有 4 个连续的 1。如 00001111xxxxxx 。
第三次右移
n |= n >>> 4;
这次把已经有的高位中的连续的 4 个 1,右移 4 位,再做或操作,这样 n 的二进制表示的高位中会有8个连续的 1。如 00001111 1111xxxxxx 。
以此类推
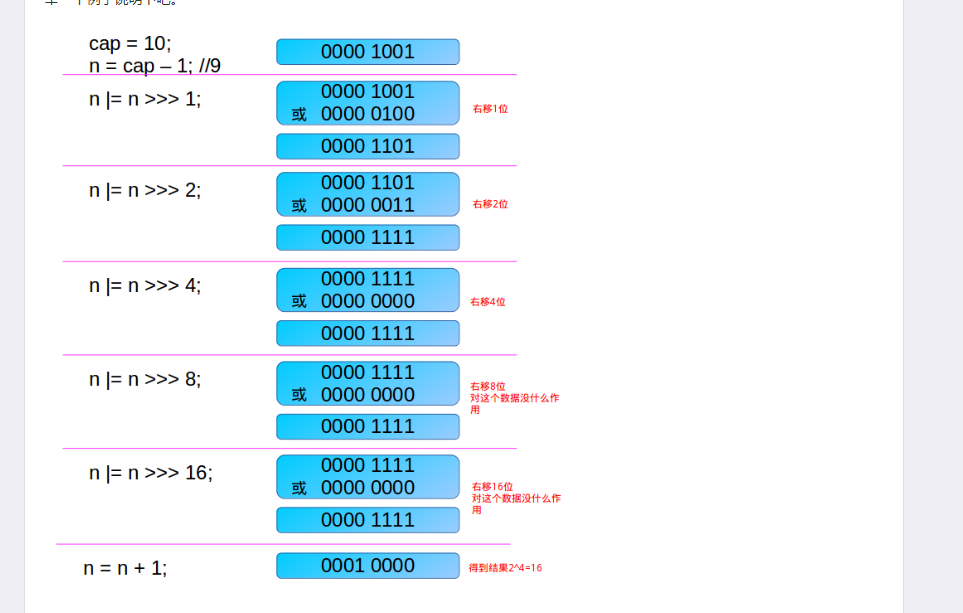
注意,容量最大也就是 32bit 的正数,因此最后 n |= n >>> 16; ,最多也就 32 个 1,但是这时已经大于了 MAXIMUM_CAPACITY ,所以取值到 MAXIMUM_CAPACITY 。
注意,得到的这个 capacity 赋值给了 threshold,因此 threshold 就是所说的容量。当 HashMap 的 size 到达 threshold 这个阈值时会扩容。
但是,请注意,在构造方法中,并没有对 table 这个成员变量进行初始化,table 的初始化被推迟到了 put 方法中,在 put 方法中会对 threshold 重新计算。

这里的 hash 值是 key.hashCode() 得到的。但是在 HashMap 这里,通过位运算重新计算了 hash 值的值。为什么要重新计算?
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
主要是因为 n (HashMap 的容量) 值比较小,hash 只参与了低位运算,高位运算没有用上。这就增大了 hash 值的碰撞概率。而通过这种位运算的计算方式,使得高位运算参与其中,减小了 hash 的碰撞概率,使 hash 值尽可能散开。如何理解呢?把前面举的例子 hash = 185,n = 16,按照 HashMap 的计算方法咱们再来走一遍。
图中的 hash 是由键的 hashCode 产生。计算余数时,由于 n 比较小,hash 只有低 4 位参与了计算,高位的计算可以认为是无效的。这样导致了计算结果只与低位信息有关,高位数据没发挥作用。为了处理这个缺陷,我们可以上图中的 hash 高 4 位数据与低 4 位数据进行异或运算,即 hash ^ (hash >>> 4)。通过这种方式,让高位数据与低位数据进行异或,以此加大低位信息的随机性,变相的让高位数据参与到计算中。此时的计算过程如下:
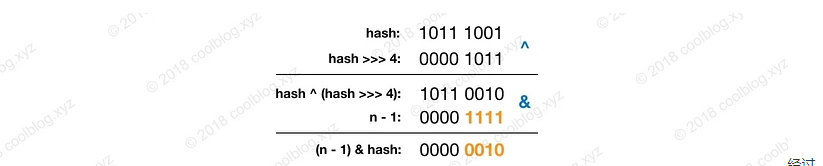
这次计算以后,发现最后的结果已经不一样了,hash 的高位值对结果产生了影响。这里为了举例子,使用了 8 位数据做讲解。在 Java 中,hashCode 方法产生的 hash 是 int 类型,32 位宽。前 16 位为高位,后16位为低位,所以要右移 16 位。
扩容:
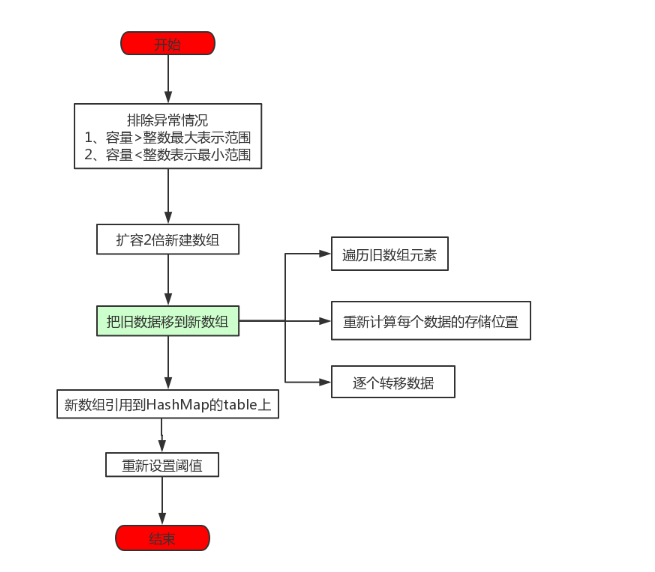
HashMap 在设计之初,并没有考虑到以后会引入红黑树进行优化。所以并没有像 TreeMap 那样,要求键类实现 comparable 接口或提供相应的比较器。但由于树化过程需要比较两个键对象的大小,在键类没有实现 comparable 接口的情况下,怎么比较键与键之间的大小了就成了一个棘手的问题。为了解决这个问题,HashMap 是做了三步处理,确保可以比较出两个键的大小,如下:
- 比较键与键之间 hash 的大小,如果 hash 相同,继续往下比较
- 检测键类是否实现了 Comparable 接口,如果实现调用 compareTo 方法进行比较
- 如果仍未比较出大小,就需要进行仲裁了,仲裁方法为 tieBreakOrder(大家自己看源码吧)
通过上面三次比较,最终就可以比较出孰大孰小。比较出大小后就可以构造红黑树了,最终构造出的红黑树如下:
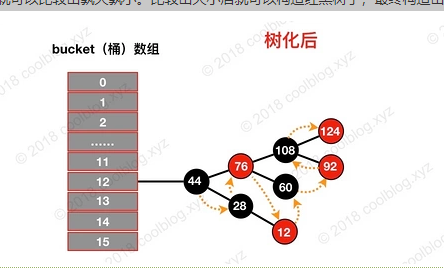
橙色的箭头表示 TreeNode 的 next 引用。由于空间有限,prev 引用未画出。可以看出,链表转成红黑树后,原链表的顺序仍然会被引用仍被保留了(红黑树的根节点会被移动到链表的第一位),我们仍然可以按遍历链表的方式去遍历上面的红黑树。这样的结构为后面红黑树的切分以及红黑树转成链表做好了铺垫,我们继续往下分析。
梳理以下 get 函数的执行过程
- 判定三个条件 table 不为 Null & table 的长度大于 0 & table 指定的索引值不为 Null,否则直接返回 null,这也是可以存储 null
- 判定匹配 hash 值 & 匹配 key 值,成功则返回该值,这里用了 == 和 equals 两种方式,对于 int,string,同一个实例对象等可以适用。
- 若 first 节点的下一个节点不为 Null
- 若下一个节点类型为 TreeNode 红黑树,通过红黑树查找匹配值,并返回查询值
- 否则就是单链表,还是通过匹配 hash 值 & 匹配 key 值来获取数据。
HashMap 的删除操作并不复杂,仅需三个步骤即可完成。
第一步是定位桶位置,
第二步遍历链表并找到键值相等的节点,
第三步删除节点。
说一下 HashMap 的实现原理?
HashMap概述: HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
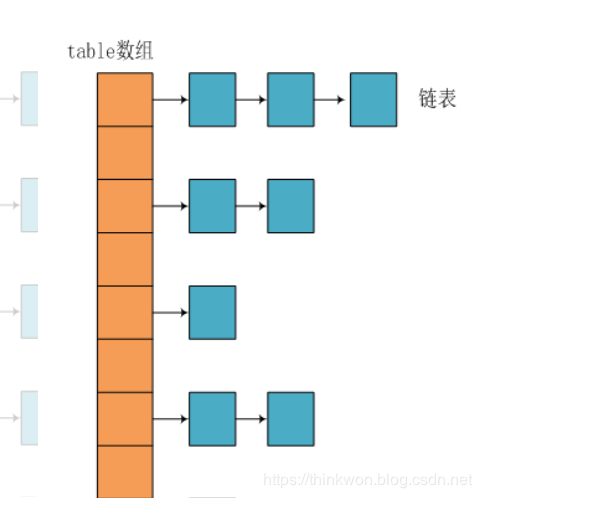
HashMap的数据结构: 在Java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
HashMap 基于 Hash 算法实现的
-
当我们往Hashmap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
-
存储时,如果出现hash值相同的key,此时有两种情况。
(1)如果key相同,则覆盖原始值;
(2)如果key不同(出现冲突),则将当前的key-value放入链表中
-
获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
-
理解了以上过程就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组的存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
需要注意Jdk 1.8中对HashMap的实现做了优化,当链表中的节点数据超过八个之后并且数组的长度大于64,该链表会转为红黑树来提高查询效率,从原来的O(n)到O(logn)
之前jdk1.7的存储结构是数组+链表,到了jdk1.8变成了数组+链表+红黑树。
JDK1.8之前
JDK1.8之前采用的是拉链法。
拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
JDK1.8之后
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时 并且数组长度大于64,将链表转化为红黑树,以减少搜索时间。
JDK1.7 VS JDK1.8 比较
JDK1.8主要解决或优化了一下问题:
- resize 扩容优化
- 引入了红黑树,目的是避免单条链表过长而影响查询效率,红黑树算法请参考
- 解决了多线程死循环问题,但仍是非线程安全的,多线程时可能会造成数据丢失问题。
总结:JDK1.8相较于之前的变化:
1.HashMap map = new HashMap();//默认情况下,先不创建长度为16的数组
2.当首次调用map.put()时,再创建长度为16的数组
3.数组为Node类型,在jdk7中称为Entry类型
4.形成链表结构时,新添加的key-value对在链表的尾部(七上八下)
5.当数组指定索引位置的链表长度>8时,且map中的数组的长度> 64时,此索引位置
上的所有key-value对使用红黑树进行存储。
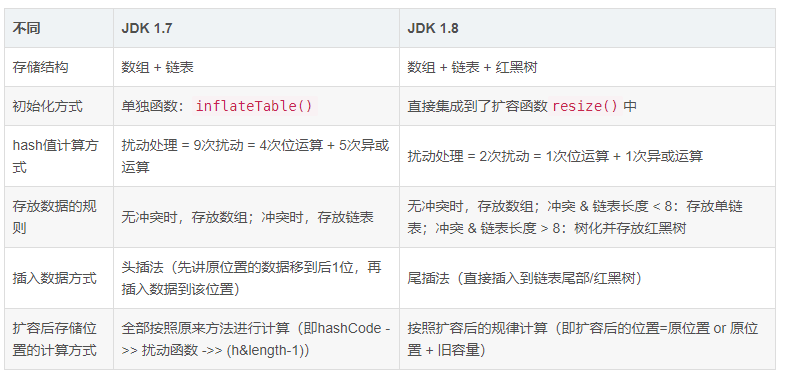
1)JDK1.7 用的是头插法,而 JDK1.8 及之后使用的都是尾插法,那么为什么要这样做呢?
因为 JDK1.7 是用单链表进行的纵向延伸,当采用头插法就是能够提高插入的效率,但是也会容易出现逆序且环形链表死循环问题。
但是在 JDK1.8 之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
(2)扩容后数据存储位置的计算方式也不一样:
- 在 JDK1.7 的时候是直接用 hash 值和需要扩容的二进制数进行 &(这里就是为什么扩容的时候为啥一定必须是 2 的多少次幂的原因所在,因为如果只有 2 的 n 次幂的情况时最后一位二进制数才一定是 1,这样能最大程度减少 hash 碰撞)(hash 值 & length-1) 。
- 而在 JDK1.8 的时候直接用了 JDK1.7 的时候计算的规律,也就是扩容前的原始位置+扩容的大小值 = JDK1.8 的计算方式,而不再是 JDK1.7 的那种异或的方法。但是这种方式就相当于只需要判断 hash 值的新增参与运算的位是 0 还是 1 就直接迅速计算出了扩容后的储存方式。
(3)JDK1.7 的时候使用的是数组+ 单链表的数据结构。但是在 JDK1.8 及之后时,使用的是数组+链表+红黑树的数据结构(当链表的深度达到 8 的时候,也就是默认阈值,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从 O(N) 变成 O(logN) 提高了效率)。
2.2. hashMap1.7与1.8的区别
①JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,那么他们为什么要这样做呢?
因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
②. 扩容后数据存储位置的计算方式也不一样:
1.在JDK1.7的时候是键的hash值与新数组的长度(此处为8)进行&运算得到新数组的位置。然后把键值对放到对应的位置(这里就是为什么扩容的时候为啥一定必须是2的多少次幂的原因所在,因为如果只有2的n次幂的情况时最后一位二进制数才一定是1,这样能最大程度减少hash碰撞)(hash值 & length-1)
而在JDK1.8的时候是扩容前的原始位置+原数组长度=JDK1.8的计算方式,而不再是JDK1.7的那种异或的方法。但是这种方式就相当于只需要判断Hash值的新增参与运算的位是0还是1就直接迅速计算出了扩容后的储存方式。

计算hash值的时候,JDK1.7用了9次扰动处理=4次位运算+5次异或,而JDK1.8只用了2次扰动处理=1次位运算+1次异或
③.JDK1.7的时候使用的是数组+ 单链表的数据结构。拉链过长会严重影响hashmap的性能,所以1.8的hashmap引入了红黑树。
但是在JDK1.8及之后时,使用的是数组+链表+红黑树的数据结构(当链表的深度达到8 的时候,也就是默认阈值 并且数组的长度大于 64,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从O(n)变成O(logN)提高了效率)少于6时改为链表,中间7不改是避免频繁转换降低性能。
相对于链表,改为红黑树后碰撞元素越多查询效率越高。
https://blog.csdn.net/qq_36520235/article/details/82417949
优化具体请见
https://www.cnblogs.com/williamjie/p/11089547.html
线程安全的map是什么
线程安全的Map:hashtable,synchronizedMap,ConcurrentHashMap
**具体请见:**https://blog.csdn.net/weixin_42812598/article/details/90708472
HashMap变成线程安全方法
1.替换成Hashtable,Hashtable通过对整个表上锁实现线程安全,因此效率比较低
2.使用Collections类的synchronizedMap方法包装一下。方法如下:
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) 返回由指定映射支持的同步(线程安全的)映射
使用ConcurrentHashMap,它使用分段锁来保证线程安全
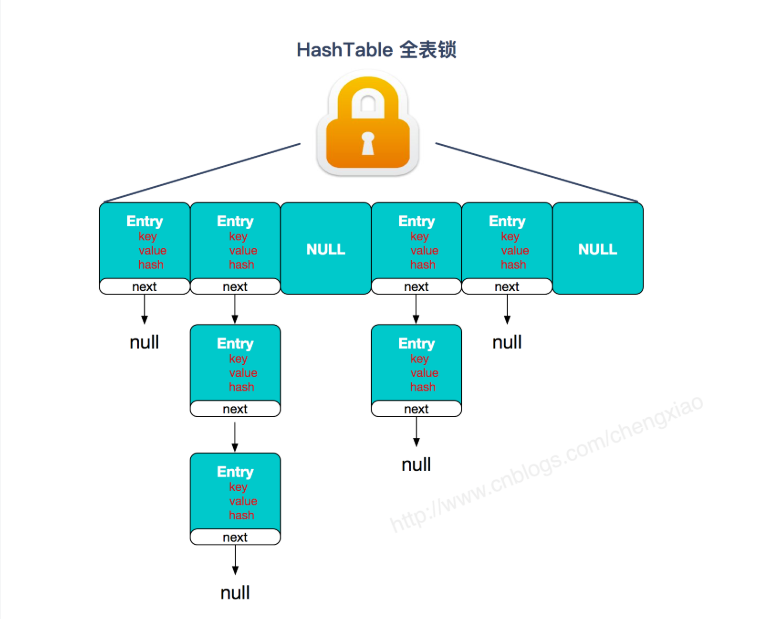
HashTable
底层数组+链表实现,无论可以还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
ConcurrentHashMap
默认将hash表分为16个桶,诸如get、put、remove等常用操作值锁住当前需要用到的桶,这样,原来只能一个线程进入,而现在却能同时有16个线程执行,并发性能提升显而易见的。
当两个对象的 hashcode 相同会发生什么?获取元素的时候,如何区分?
hashcode 相同,说明两个对象 HashMap 数组的同一位置上,接着 HashMap 会遍历链表中的每个元素,通过 key 的 equals 方法来判断是否为同一个 key,如果是同一个key,则新的 value 会覆盖旧的 value,并且返回旧的 value。如果不是同一个 key,则存储在该位置上的链表的链尾。
获取元素的时候遍历 HashMap 链表中的每个元素,并对每个 key 进行 hash 计算,只有 hash 和 key 都相等,才返回对应的值对象。
HashMap的put方法的具体流程?
当我们put的时候,首先计算 key的hash值,这里调用了 hash方法,hash方法实际是让key.hashCode()与key.hashCode()>>>16进行异或操作,高16bit补0,一个数和0异或不变,所以 hash 函数大概的作用就是:高16bit不变,低16bit和高16bit做了一个异或,目的是减少碰撞。按照函数注释,因为bucket数组大小是2的幂,计算下标index = (table.length - 1) & hash,如果不做 hash 处理,相当于散列生效的只有几个低 bit 位,为了减少散列的碰撞,设计者综合考虑了速度、作用、质量之后,使用高16bit和低16bit异或来简单处理减少碰撞,而且JDK8中用了复杂度 O(logn)的树结构来提升碰撞下的性能。
putVal方法执行流程图
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//实现Map.put和相关方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 步骤①:tab为空则创建
// table未初始化或者长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 步骤②:计算index,并对null做处理
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素
else {
Node<K,V> e; K k;
// 步骤③:节点key存在,直接覆盖value
// 比较桶中第一个元素(数组中的结点)的hash值相等,key相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 将第一个元素赋值给e,用e来记录
e = p;
// 步骤④:判断该链为红黑树
// hash值不相等,即key不相等;为红黑树结点
// 如果当前元素类型为TreeNode,表示为红黑树,putTreeVal返回待存放的node, e可能为null
else if (p instanceof TreeNode)
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 步骤⑤:该链为链表
// 为链表结点
else {
// 在链表最末插入结点
for (int binCount = 0; ; ++binCount) {
// 到达链表的尾部
//判断该链表尾部指针是不是空的
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
//判断链表的长度是否达到转化红黑树的临界值,临界值为8
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//链表结构转树形结构
treeifyBin(tab, hash);
// 跳出循环
break;
}
// 判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
//判断当前的key已经存在的情况下,再来一个相同的hash值、key值时,返回新来的value这个值
if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 结构性修改
++modCount;
// 步骤⑥:超过最大容量就扩容
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
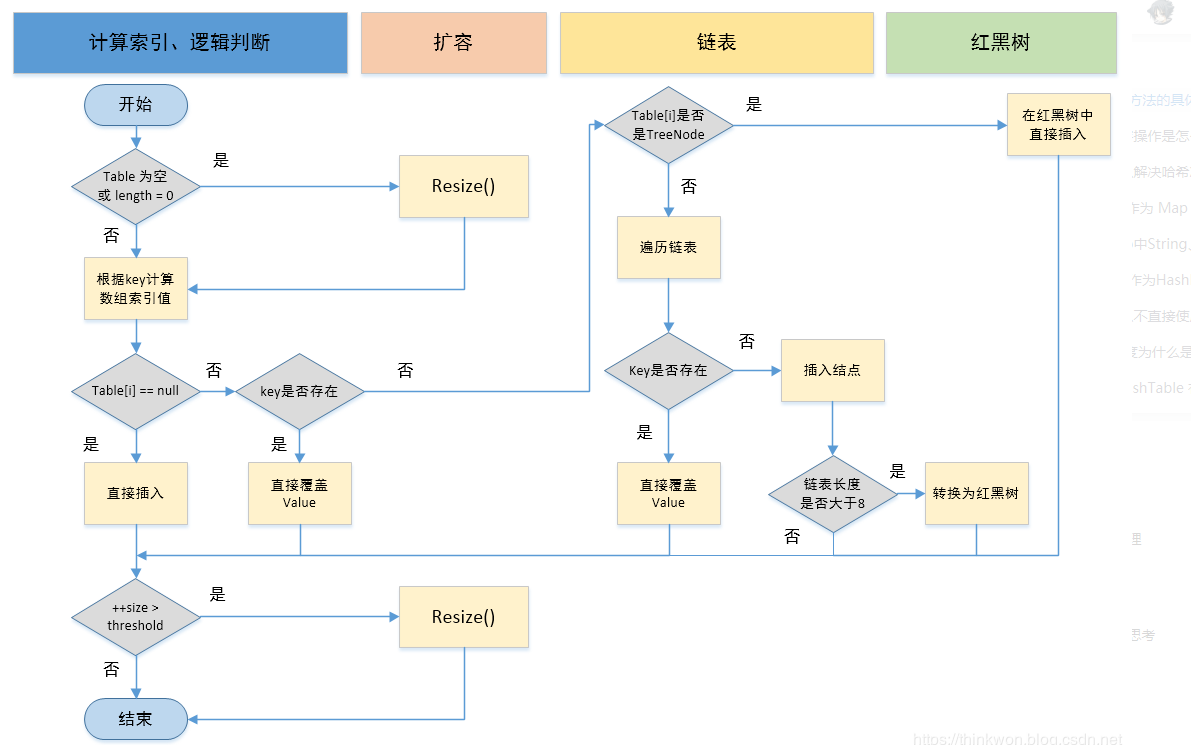
①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表并且数组长度小于64转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
HashMap的扩容操作是怎么实现的?
①.在jdk1.8中,resize方法是在hashmap中的键值对大于阀值时或者初始化时,就调用resize方法进行扩容;
②.每次扩展的时候,都是扩展2倍;
③**.扩展后Node对象的位置要么在原位置,要么移动到原偏移量两倍的位置。**
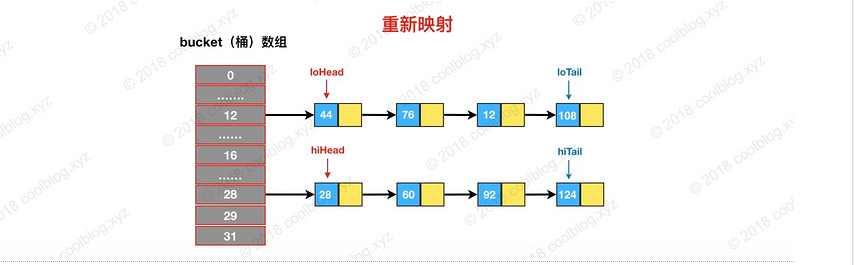
在putVal()中,我们看到在这个函数里面使用到了2次resize()方法,resize()方法表示的在进行第一次初始化时会对其进行扩容,或者当该数组的实际大小大于其临界值值(第一次为12),这个时候在扩容的同时也会伴随的桶上面的元素进行重新分发,这也是JDK1.8版本的一个优化的地方,在1.7中,扩容之后需要重新去计算其Hash值,根据Hash值对其进行分发,但在1.8版本中,则是根据在同一个桶的位置中进行判断(e.hash & oldCap)是否为0,重新进行hash分配后,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;//oldTab指向hash桶数组
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {//如果oldCap不为空的话,就是hash桶数组不为空
if (oldCap >= MAXIMUM_CAPACITY) {//如果大于最大容量了,就赋值为整数最大的阀值
threshold = Integer.MAX_VALUE;
return oldTab;//返回
}//如果当前hash桶数组的长度在扩容后仍然小于最大容量 并且oldCap大于默认值16
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold 双倍扩容阀值threshold
}
// 旧的容量为0,但threshold大于零,代表有参构造有cap传入,threshold已经被初始化成最小2的n次幂
// 直接将该值赋给新的容量
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
// 无参构造创建的map,给出默认容量和threshold 16, 16*0.75
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 新的threshold = 新的cap * 0.75
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
// 计算出新的数组长度后赋给当前成员变量table
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//新建hash桶数组
table = newTab;//将新数组的值复制给旧的hash桶数组
// 如果原先的数组没有初始化,那么resize的初始化工作到此结束,否则进入扩容元素重排逻辑,使其均匀的分散
if (oldTab != null) {
// 遍历新数组的所有桶下标
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
// 旧数组的桶下标赋给临时变量e,并且解除旧数组中的引用,否则就数组无法被GC回收
oldTab[j] = null;
// 如果e.next==null,代表桶中就一个元素,不存在链表或者红黑树
if (e.next == null)
// 用同样的hash映射算法把该元素加入新的数组
newTab[e.hash & (newCap - 1)] = e;
// 如果e是TreeNode并且e.next!=null,那么处理树中元素的重排
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// e是链表的头并且e.next!=null,那么处理链表中元素重排
else { // preserve order
// loHead,loTail 代表扩容后不用变换下标,见注1
Node<K,V> loHead = null, loTail = null;
// hiHead,hiTail 代表扩容后变换下标,见注1
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// 遍历链表
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
// 初始化head指向链表当前元素e,e不一定是链表的第一个元素,初始化后loHead
// 代表下标保持不变的链表的头元素
loHead = e;
else
// loTail.next指向当前e
loTail.next = e;
// loTail指向当前的元素e
// 初始化后,loTail和loHead指向相同的内存,所以当loTail.next指向下一个元素时,
// 底层数组中的元素的next引用也相应发生变化,造成lowHead.next.next.....
// 跟随loTail同步,使得lowHead可以链接到所有属于该链表的元素。
loTail = e;
}
else {
if (hiTail == null)
// 初始化head指向链表当前元素e, 初始化后hiHead代表下标更改的链表头元素
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 遍历结束, 将tail指向null,并把链表头放入新数组的相应下标,形成新的映射。
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap是怎么解决哈希冲突的?
答:在解决这个问题之前,我们首先需要知道什么是哈希冲突,而在了解哈希冲突之前我们还要知道什么是哈希才行;
什么是哈希?
Hash,一般翻译为“散列”,也有直接音译为“哈希”的,这就是把任意长度的输入通过散列算法,变换成固定长度的输出,该输出就是散列值(哈希值);这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
所有散列函数都有如下一个基本特性**:根据同一散列函数计算出的散列值如果不同,那么输入值肯定也不同。但是,根据同一散列函数计算出的散列值如果相同,输入值不一定相同**。
什么是哈希冲突?
当两个不同的输入值,根据同一散列函数计算出相同的散列值的现象,我们就把它叫做碰撞(哈希碰撞)。
在数据结构中,我们处理hash冲突常使用的方法有:开发定址法、再哈希法、链地址法、建立公共溢出区。而hashMap中处理hash冲突的方法就是链地址法。
1, 开放定址法:
所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入
公式为:fi(key) = (f(key)+di) MOD m (di=1,2,3,……,m-1)
※ 用开放定址法解决冲突的做法是:当冲突发生时,使用某种探测技术在散列表中形成一个探测序列。沿此序列逐个单元地查找,直到找到给定的关键字,或者
碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探测到开放的地址则表明表
中无待查的关键字,即查找失败。
2, 再哈希法:
再哈希法又叫双哈希法,有多个不同的Hash函数,当发生冲突时,使用第二个,第三个,….,等哈希函数
计算地址,直到无冲突。虽然不易发生聚集,但是增加了计算时间。
3, 链地址法:
链地址法的基本思想是:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向 链表连接起来。
4, 建立公共溢出区:
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表
HashMap的数据结构
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,但插入和删除容易;所以我们将数组和链表结合在一起,发挥两者各自的优势,使用一种叫做链地址法的方式可以解决哈希冲突:
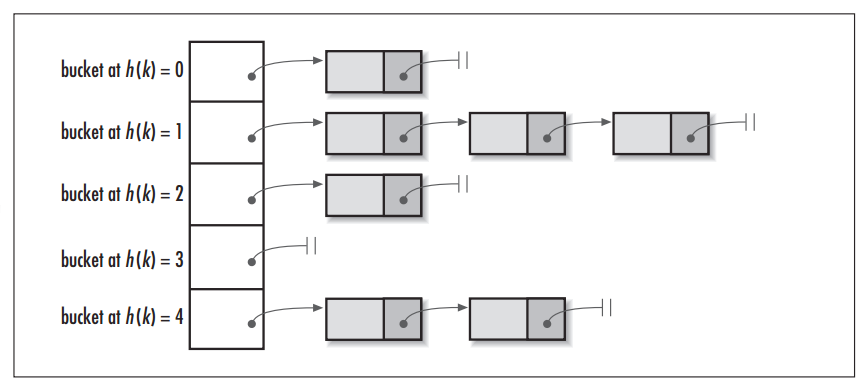
这样我们就可以将拥有相同哈希值的对象组织成一个链表放在hash值所对应的bucket下,但相比于hashCode返回的int类型,我们HashMap初始的容量大小DEFAULT_INITIAL_CAPACITY = 1 << 4(即2的四次方16)要远小于int类型的范围,所以我们如果只是单纯的用hashCode取余来获取对应的bucket这将会大大增加哈希碰撞的概率,并且最坏情况下还会将HashMap变成一个单链表,所以我们还需要对hashCode作一定的优化
hash()函数
上面提到的问题,主要是因为如果使用hashCode取余,那么相当于参与运算的只有hashCode的低位,高位是没有起到任何作用的,所以我们的思路就是让hashCode取值出的高位也参与运算,进一步降低hash碰撞的概率,使得数据分布更平均,我们把这样的操作称为扰动,在JDK 1.8中的hash()函数如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);// 与自己右移16位进行异或运算(高低位异或)
}
这比在JDK 1.7中,更为简洁,相比在1.7中的4次位运算,5次异或运算(9次扰动),在1.8中,只进行了1次位运算和1次异或运算(2次扰动);
通过上面的链地址法(使用散列表)和扰动函数我们成功让我们的数据分布更平均,哈希碰撞减少,但是当我们的HashMap中存在大量数据时,加入我们某个bucket下对应的链表有n个元素,那么遍历时间复杂度就为O(n),为了针对这个问题,JDK1.8在HashMap中新增了红黑树的数据结构,进一步使得遍历复杂度降低至O(logn);
总结
简单总结一下HashMap是使用了哪些方法来有效解决哈希冲突的:
1. 使用链地址法(使用散列表)来链接拥有相同hash值的数据;
2. 使用2次扰动函数(hash函数)来降低哈希冲突的概率,使得数据分布更平均;
3. 引入红黑树进一步降低遍历的时间复杂度,使得遍历更快;
能否使用任何类作为 Map 的 key?
可以使用任何类作为 Map 的 key,然而在使用之前,需要考虑以下几点:
- 如果类重写了 equals() 方法,也应该重写 hashCode() 方法。
- 类的所有实例需要遵循与 equals() 和 hashCode() 相关的规则。
- 如果一个类没有使用 equals(),不应该在 hashCode() 中使用它。
- 用户自定义 Key 类最佳实践是使之为不可变的,这样 hashCode() 值可以被缓存起来,拥有更好的性能。不可变的类也可以确保 hashCode() 和 equals() 在未来不会改变,这样就会解决与可变相关的问题了。
为什么HashMap中String、Integer这样的包装类适合作为K?
答:String、Integer等包装类的特性能够保证Hash值的不可更改性和计算准确性,能够有效的减少Hash碰撞的几率
- 都是final类型,即不可变性,保证key的不可更改性,不会存在获取hash值不同的情况
- 内部已重写了
equals()、hashCode()等方法,遵守了HashMap内部的规范(不清楚可以去上面看看putValue的过程),不容易出现Hash值计算错误的情况;
如果使用Object作为HashMap的Key,应该怎么办呢?
答:重写hashCode()和equals()方法
- 重写
hashCode()是因为需要计算存储数据的存储位置,需要注意不要试图从散列码计算中排除掉一个对象的关键部分来提高性能,这样虽然能更快但可能会导致更多的Hash碰撞; - 重写
equals()方法,需要遵守自反性、对称性、传递性、一致性以及对于任何非null的引用值x,x.equals(null)必须返回false的这几个特性,目的是为了保证key在哈希表中的唯一性;
HashMap为什么不直接使用hashCode()处理后的哈希值直接作为table的下标?
答:hashCode()方法返回的是int整数类型,其范围为-(2 ^ 31)~(2 ^ 31 - 1),约有40亿个映射空间,而HashMap的容量范围是在16(初始化默认值)~2 ^ 30,HashMap通常情况下是取不到最大值的,并且设备上也难以提供这么多的存储空间,从而导致通过hashCode()计算出的哈希值可能不在数组大小范围内,进而无法匹配存储位置;
那怎么解决呢?
-
HashMap自己实现了自己的
hash()方法,通过两次扰动使得它自己的哈希值高低位自行进行异或运算,降低哈希碰撞概率也使得数据分布更平均; -
在保证数组长度为2的幂次方的时候,使用
hash()运算之后的值与运算(&)(数组长度 - 1)来获取数组下标的方式进行存储,这样一来是比取余操作更加有效率,
二来也是因为只有当数组长度为2的幂次方时,h&(length-1)才等价于h%length,
三来解决了“哈希值与数组大小范围不匹配”的问题;
HashMap 的长度为什么是2的幂次方
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀,每个链表/红黑树长度大致相同。这个实现就是把数据存到哪个链表/红黑树中的算法。
HashMap为了存取高效,要尽量较少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同,这个实现就在把数据存到哪个链表中的算法;
这个算法实际就是取模,hash%length,计算机中直接求余效率不如位移运算,源码中做了优化hash&(length-1),
hash%length==hash&(length-1)的前提是length是2的n次方;
为什么这样能均匀分布减少碰撞呢?2的n次方实际就是1后面n个0,2的n次方-1 实际就是n个1;
例如长度为9时候,3&(9-1)=0 2&(9-1)=0 ,都在0上,碰撞了;
例如长度为8时候,3&(8-1)=3 2&(8-1)=2 ,不同位置上,不碰撞;
这个算法应该如何设计呢?
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。
那为什么是两次扰动呢?
答:这样就是加大哈希值低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性&均匀性,最终减少Hash冲突,两次就够了,已经达到了高位低位同时参与运算的目的;
HashMap 与 HashTable 有什么区别?
-
线程安全: HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过
synchronized修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!); -
效率: 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
-
对Null key 和Null value的支持: HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛NullPointerException。
-
**初始容量大小和每次扩充容量大小的不同 **:
①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。
②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
-
底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
-
推荐使用:在 Hashtable 的类注释可以看到,Hashtable 是保留类不建议使用,推荐在单线程环境下使用 HashMap 替代,如果需要多线程使用则用 ConcurrentHashMap 替代。
-
HashMap 几乎可以等价于 Hashtable,除了 HashMap 是非 synchronized 的,并可以接受 null -> null 键值对,而 Hashtable 则不行)。
-
Hashtable 是线程安全的,多个线程可以共享一个Hashtable;。Java 5提供了ConcurrentHashMap,它是 HashTable 的替代,比 HashTable 的扩展性更好。
-
由于 Hashtable 是线程安全的,在单线程环境下它比 HashMap 要慢。在单一线程下,使用 HashMap 性能要好过 Hashtable。
-
HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
-
HashMap 的迭代器 (Iterator) 是 fail-fast 迭代器,而 Hashtable 的 enumerator 迭代器不是 fail-fast 的。所以当有其它线程改变了 HashMap 的结构(增加或者移除元素),将会抛出 ConcurrentModificationException,但迭代器本身的 remove() 方法移除元素则不会抛出 ConcurrentModificationException 异常。但这并不是一个一定发生的行为,要看 JVM。这条同样也是 Enumeration 和 Iterator 的区别。
1、HashMap是继承自AbstractMap类,而HashTable是继承自Dictionary类。不过它们都实现了同时实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。
2、HashMap的key-value支持key-value,null-null,key-null,null-value四种。而Hashtable只支持key-value一种
3、线程安全性不同,HashMap的方法都没有使用synchronized关键字修饰,都是非线程安全的,而Hashtable的方法几乎
都是被synchronized关键字修饰的。
4.初始容量大小和每次扩充容量大小的不同
Hashtable默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。
https://blog.csdn.net/luojishan1/article/details/81952147
如何决定使用 HashMap 还是 TreeMap?
对于在Map中插入、删除和定位元素这类操作,HashMap是最好的选择。然而,假如你需要对一个有序的key集合进行遍历,TreeMap是更好的选择。基于你的collection的大小,也许向HashMap中添加元素会更快,将map换为TreeMap进行有序key的遍历。
HashMap 和 ConcurrentHashMap 的区别
- ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的synchronized锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。(JDK1.8之后ConcurrentHashMap启用了一种全新的方式实现,利用CAS算法。)
- HashMap的键值对允许有null,但是ConCurrentHashMap都不允许。
Hashmap本质是数组加链表。根据key取得hash值,然后计算出数组下标,如果多个key对应到同一个下标,就用链表串起来,新插入的在前面。
ConcurrentHashMap:在hashMap的基础上,ConcurrentHashMap将数据分为多个segment(段),默认16个(concurrency level),然后每次操作对一个segment(段)加锁,避免多线程锁的几率,提高并发效率。
https://www.cnblogs.com/shan1393/p/8999458.html
ConcurrentHashMap 和 Hashtable 的区别?
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
- 底层数据结构: JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
- 实现线程安全的方式(重要): ① 在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配16个Segment,比Hashtable效率提高16倍。) 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
两者的对比图:
HashTable
JDK1.7的ConcurrentHashMap:

JDK1.8的ConcurrentHashMap(TreeBin: 红黑二叉树节点 Node: 链表节点):
答:ConcurrentHashMap 结合了 HashMap 和 HashTable 二者的优势。HashMap 没有考虑同步,HashTable 考虑了同步的问题。但是 HashTable 在每次同步执行时都要锁住整个结构。 ConcurrentHashMap 锁的方式是稍微细粒度的。
我们都知道HashMap不是线程安全的,所以在处理并发的时候会出现问题。
而HashTable虽然是线程安全的,但是是通过整个来加锁的方式,当一个线程在写操作的时候,另外的线程则不能进行读写。
而ConcurrentHashMap则可以支持并发的读写。跟1.7版本相比,1.8版本又有了很大的变化,已经抛弃了Segment的概念,虽然源码里面还保留了,也只是为了兼容性的考虑。
ConcurrentHashMap 底层具体实现知道吗?实现原理是什么?
JDK1.7
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
在JDK1.7中,ConcurrentHashMap采用Segment + HashEntry的方式进行实现,结构如下:
一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment的锁。
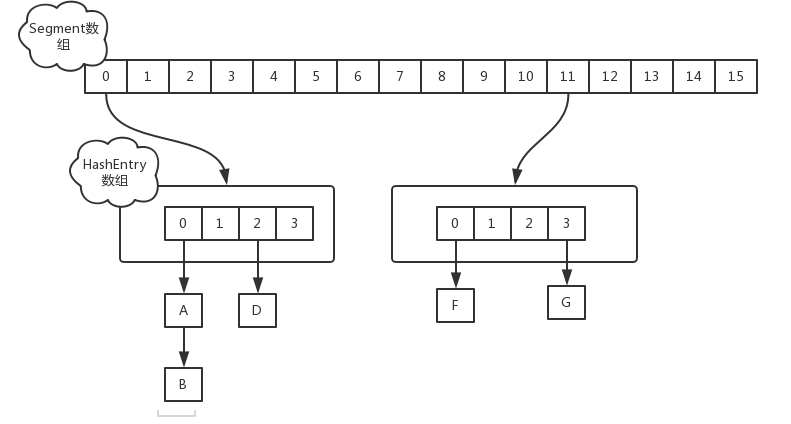
- 该类包含两个静态内部类 HashEntry 和 Segment ;前者用来封装映射表的键值对,后者用来充当锁的角色;
- Segment 是一种可重入的锁 ReentrantLock,每个 Segment 守护一个HashEntry 数组里得元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 锁。
JDK1.8
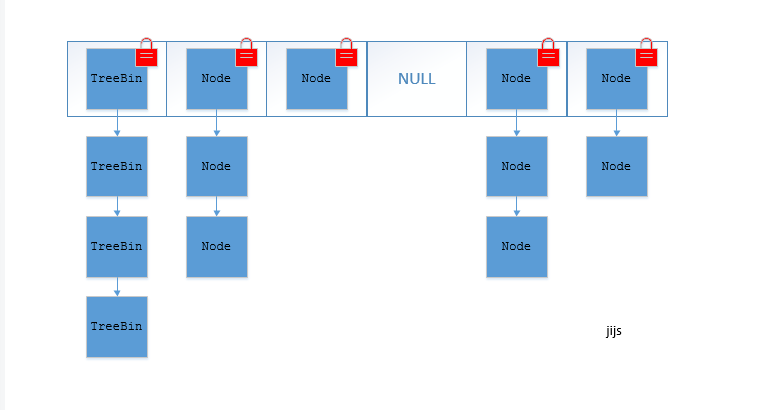
在JDK1.8中,放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
结构如下:
插入元素过程(建议去看看源码):
如果相应位置的Node还没有初始化,则调用CAS插入相应的数据;
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
如果相应位置的Node不为空,且当前该节点不处于移动状态,则对该节点加synchronized锁,如果该节点的hash不小于0,则遍历链表更新节点或插入新节点;
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value, null);
break;
}
}
}
- 如果该节点是TreeBin类型的节点,说明是红黑树结构,则通过putTreeVal方法往红黑树中插入节点;如果binCount不为0,说明put操作对数据产生了影响,如果当前链表的个数达到8个,则通过treeifyBin方法转化为红黑树,如果oldVal不为空,说明是一次更新操作,没有对元素个数产生影响,则直接返回旧值;
- 如果插入的是一个新节点,则执行addCount()方法尝试更新元素个数baseCount;
ConcurrentHashMap原理概览
在ConcurrentHashMap中通过一个Node<K,V>[]数组来保存添加到map中的键值对,而在同一个数组位置是通过链表和红黑树的形式来保存的。但是这个数组只有在第一次添加元素的时候才会初始化,否则只是初始化一个ConcurrentHashMap对象的话,只是设定了一个sizeCtl变量,这个变量用来判断对象的一些状态和是否需要扩容,后面会详细解释。
第一次添加元素的时候,默认初期长度为16,当往map中继续添加元素的时候,通过hash值跟数组长度取与来决定放在数组的哪个位置,如果出现放在同一个位置的时候,优先以链表的形式存放,在同一个位置的个数又达到了8个以上,如果数组的长度还小于64的时候,则会扩容数组。如果数组的长度大于等于64了的话,在会将该节点的链表转换成树。
通过扩容数组的方式来把这些节点给分散开。然后将这些元素复制到扩容后的新的数组中,同一个链表中的元素通过hash值的数组长度位来区分,是还是放在原来的位置还是放到扩容的长度的相同位置去 。在扩容完成之后,如果某个节点的是树,同时现在该节点的个数又小于等于6个了,则会将该树转为链表。
取元素的时候,相对来说比较简单,通过计算hash来确定该元素在数组的哪个位置,然后在通过遍历链表或树来判断key和key的hash,取出value值。
往ConcurrentHashMap中添加元素的时候,里面的数据以数组的形式存放的样子大概是这样的:

ConcurrentHashMap的同步机制
前面分析了下ConcurrentHashMap的源码,那么,对于一个映射集合来说,ConcurrentHashMap是如果来做到并发安全,又是如何做到高效的并发的呢?
首先是读操作,从源码中可以看出来,在get操作中,根本没有使用同步机制,也没有使用unsafe方法,所以读操作是支持并发操作的。
那么写操作呢?
分析这个之前,先看看什么情况下会引起数组的扩容,扩容是通过transfer方法来进行的。而调用transfer方法的只有trePresize、helpTransfer和addCount三个方法。
这三个方法又是分别在什么情况下进行调用的呢?
·tryPresize是在treeIfybin和putAll方法中调用,treeIfybin主要是在put添加元素完之后,判断该数组节点相关元素是不是已经超过8个的时候,如果超过则会调用这个方法来扩容数组或者把链表转为树。
·helpTransfer是在当一个线程要对table中元素进行操作的时候,如果检测到节点的HASH值为MOVED的时候,就会调用helpTransfer方法,在helpTransfer中再调用transfer方法来帮助完成数组的扩容
·addCount是在当对数组进行操作,使得数组中存储的元素个数发生了变化的时候会调用的方法。
所以引起数组扩容的情况如下:
·只有在往map中添加元素的时候,在某一个节点的数目已经超过了8个,同时数组的长度又小于64的时候,才会触发数组的扩容。
·当数组中元素达到了sizeCtl的数量的时候,则会调用transfer方法来进行扩容
那么在扩容的时候,可以不可以对数组进行读写操作呢?
事实上是可以的。当在进行数组扩容的时候,如果当前节点还没有被处理(也就是说还没有设置为fwd节点),那就可以进行设置操作。
如果该节点已经被处理了,则当前线程也会加入到扩容的操作中去。
那么,多个线程又是如何同步处理的呢?
在ConcurrentHashMap中,同步处理主要是通过Synchronized和unsafe两种方式来完成的。
·在取得sizeCtl、某个位置的Node的时候,使用的都是unsafe的方法,来达到并发安全的目的
·当需要在某个位置设置节点的时候,则会通过Synchronized的同步机制来锁定该位置的节点。
·在数组扩容的时候,则通过处理的步长和fwd节点来达到并发安全的目的,通过设置hash值为MOVED
·当把某个位置的节点复制到扩张后的table的时候,也通过Synchronized的同步机制来保证现程安全
辅助工具类
Array 和 ArrayList 有何区别?
- Array 可以存储基本数据类型和对象,ArrayList 只能存储对象。
- Array 是指定固定大小的,而 ArrayList 大小是自动扩展的。
- Array 内置方法没有 ArrayList 多,比如 addAll、removeAll、iteration 等方法只有 ArrayList 有。
对于基本类型数据,集合使用自动装箱来减少编码工作量。但是,当处理固定大小的基本数据类型的时候,这种方式相对比较慢。
如何实现 Array 和 List 之间的转换?
- Array 转 List: Arrays. asList(array) ;
- List 转 Array:List 的 toArray() 方法。
comparable 和 comparator的区别?
- comparable接口实际上是出自java.lang包,它有一个 compareTo(Object obj)方法用来排序
- comparator接口实际上是出自 java.util 包,它有一个compare(Object obj1, Object obj2)方法用来排序
一般我们需要对一个集合使用自定义排序时,我们就要重写compareTo方法或compare方法,当我们需要对某一个集合实现两种排序方式,比如一个song对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写compareTo方法和使用自制的Comparator方法或者以两个Comparator来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的Collections.sort()
Collection 和 Collections 有什么区别?
- java.util.Collection 是一个集合接口(集合类的一个顶级接口)。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式,其直接继承接口有List与Set。
- Collections则是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作。
TreeMap 和 TreeSet 在排序时如何比较元素?Collections 工具类中的 sort()方法如何比较元素?
TreeSet 要求存放的对象所属的类必须实现 Comparable 接口,该接口提供了比较元素的 compareTo()方法,当插入元素时会回调该方法比较元素的大小。TreeMap 要求存放的键值对映射的键必须实现 Comparable 接口从而根据键对元素进 行排 序。
Collections 工具类的 sort 方法有两种重载的形式,
第一种要求传入的待排序容器中存放的对象比较实现 Comparable 接口以实现元素的比较;
第二种不强制性的要求容器中的元素必须可比较,但是要求传入第二个参数,参数是Comparator 接口的子类型(需要重写 compare 方法实现元素的比较),相当于一个临时定义的排序规则,其实就是通过接口注入比较元素大小的算法,也是对回调模式的应用(Java 中对函数式编程的支持)。
TreeSet去重,如何排序
去重
添加元素到TreeSet中实际是添加元素到TreeMap中,添加的元素作为键,一个Object的常量作为值,
如果是key实现Comparable接口的话,Entry在红黑树中的位置是根据key和key的compareTo方法确定的,如果是自定义比较器的话,Entry在红黑树中的位置是根据key和比较器的compare方法确定的
一般来说,相同的key会找到相同的位置,当出现key重复的时候,只会替换value值,不会新增key(compareTo()返回值固定为0则不同的key也会找到相同的位置,大于或小于0的数相同的key也会找到不同的位置)
排序
以Student类的id进行排序
public int compareTo(Object o) {
Student s=(Student)o;
return -(this.id-s.id);
}
用当前student对象的id减去下一个添加Student对象的id(既参数Object o),既是按student的id正序排列,反之则是逆序
注解返回常数
如果返回0则只能添加一天数据,键为第一条数据的键,值为最后一条数据的值
如果返回大于0的常数,则重复的key也能添加进去,且按添加先后顺序正序排列
如果返回小于0的常数,则重复的key也能添加进去,且按添加先后顺序逆序排列
排序原理
以key实现Comparable接口为例,当添加元素到TreeSet中时,也就是添加到TreeMap中,会将当前元素的key转换为Comparable并调用CompareTo方法,将头结点的key放进这个方法中比较
,如果大于0,右结点再会与之比较,小于0左节点会与之比较,等于0则会替换掉头结点的值,
以小于0为例,key会和头结点的左节点key比较,大于0,则再和该节点的右节点比较,小于0和左节点比较,等于0替换值
比较依此类推,如果比较过程中和key比较的那个节点为null,则会直接将添加的元素放到那个位置,当遍历TreeMap的时候,会从最左节点遍历到最右节点,所以会出现以下情况
以strudent为例
用当前student对象的id减去下一个添加Student对象的id(既参数Object o),既是按student的id正序排列,反之则是逆序
注解返回常数
如果返回0则只能添加一天数据,键为第一条数据的键,值为最后一条数据的值
如果返回大于0的常数,则重复的key也能添加进去,且按添加先后顺序正序排列
如果返回小于0的常数,则重复的key也能添加进去,且按添加先后顺序逆序排列
红黑树
红黑树是一种自平衡排序二叉树,树中每个节点的值,都大于或等于在它的左子树中的所有节点的值,并且小于或等于在它的右子树中的所有节点的值,这确保红黑树运行时可以快速地在树中查找和定位的所需节点。
对于 TreeMap 而言,由于它底层采用一棵“红黑树”来保存集合中的 Entry,这意味这 TreeMap 添加元素、取出元素的性能都比 HashMap 低:当 TreeMap 添加元素时,需要通过循环找到新增 Entry 的插入位置,因此比较耗性能;当从 TreeMap 中取出元素时,需要通过循环才能找到合适的 Entry,也比较耗性能。但 TreeMap、TreeSet 比 HashMap、HashSet 的优势在于:TreeMap 中的所有 Entry 总是按 key 根据指定排序规则保持有序状态,TreeSet 中所有元素总是根据指定排序规则保持有序状态。
为了理解 的底层实现,必须先介绍排序二叉树和红黑树这两种数据结构。其中红黑树又是一种特殊的排序二叉树。
排序二叉树是一种特殊结构的二叉树,可以非常方便地对树中所有节点进行排序和检索。
排序二叉树要么是一棵空二叉树,要么是具有下列性质的二叉树:
- 若它的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
- 若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
- 它的左、右子树也分别为排序二叉树。
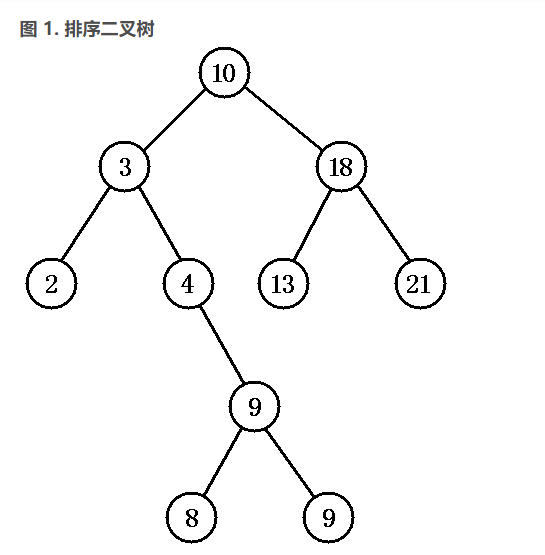
对排序二叉树,若按中序遍历就可以得到由小到大的有序序列。如图 1 所示二叉树,中序遍历得:
{2,3,4,8,9,9,10,13,15,18}
创建排序二叉树的步骤,也就是不断地向排序二叉树添加节点的过程,向排序二叉树添加节点的步骤如下:
- 以根节点当前节点开始搜索。
- 拿新节点的值和当前节点的值比较。
- 如果新节点的值更大,则以当前节点的右子节点作为新的当前节点;如果新节点的值更小,则以当前节点的左子节点作为新的当前节点。
- 重复 2、3 两个步骤,直到搜索到合适的叶子节点为止。
- 将新节点添加为第 4 步找到的叶子节点的子节点;如果新节点更大,则添加为右子节点;否则添加为左子节点。
上面程序中粗体字代码就是实现“排序二叉树”的关键算法,每当程序希望添加新节点时:系统总是从树的根节点开始比较 —— 即将根节点当成当前节点,如果新增节点大于当前节点、并且当前节点的右子节点存在,则以右子节点作为当前节点;如果新增节点小于当前节点、并且当前节点的左子节点存在,则以左子节点作为当前节点;如果新增节点等于当前节点,则用新增节点覆盖当前节点,并结束循环 —— 直到找到某个节点的左、右子节点不存在,将新节点添加该节点的子节点 —— 如果新节点比该节点大,则添加为右子节点;如果新节点比该节点小,则添加为左子节点。
TreeMap 的删除节点
当程序从排序二叉树中删除一个节点之后,为了让它依然保持为排序二叉树,程序必须对该排序二叉树进行维护。维护可分为如下几种情况:
(1)被删除的节点是叶子节点,则只需将它从其父节点中删除即可。
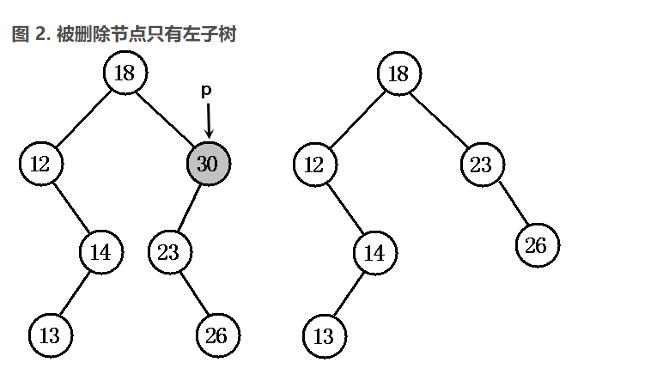
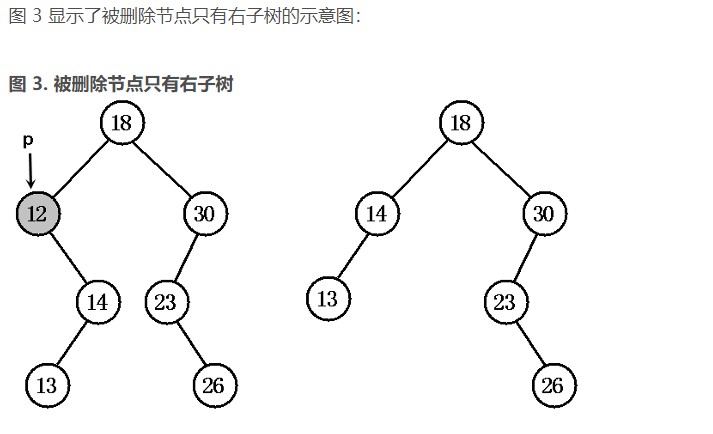
(2)被删除节点 p 只有左子树,将 p 的左子树 pL 添加成 p 的父节点的左子树即可;被删除节点 p 只有右子树,将 p 的右子树 pR 添加成 p 的父节点的右子树即可。 删除节点后 变换为父节点对应的子树
(3)若被删除节点 p 的左、右子树均非空,有两种做法:
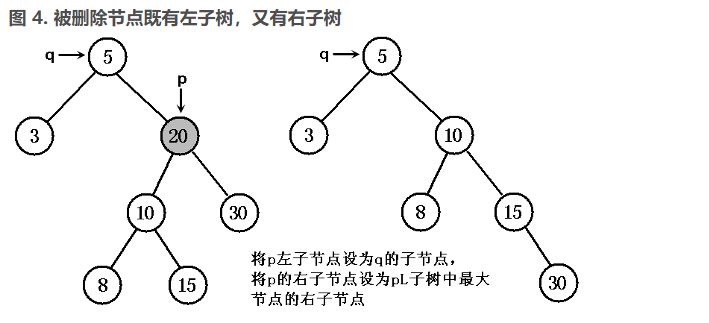
- 将 pL 设为 p 的父节点 q 的左或右子节点(取决于 p 是其父节点 q 的左、右子节点),将 pR 设为 p 节点的中序前趋节点 s 的右子节点(s 是 pL 最右下的节点,也就是 pL 子树中最大的节点)。
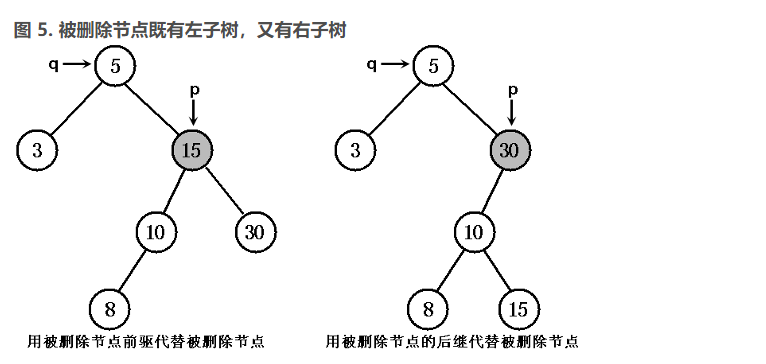
- 以 p 节点的中序前趋或后继替代 p 所指节点,然后再从原排序二叉树中删去中序前趋或后继节点即可。(也就是用大于 p 的最小节点或小于 p 的最大节点代替 p 节点即可)。
红黑树
排序二叉树虽然可以快速检索,但在最坏的情况下:如果插入的节点集本身就是有序的,要么是由小到大排列,要么是由大到小排列,那么最后得到的排序二叉树将变成链表:所有节点只有左节点(如果插入节点集本身是大到小排列);或所有节点只有右节点(如果插入节点集本身是小到大排列)。在这种情况下,排序二叉树就变成了普通链表,其检索效率就会很差。
为了改变排序二叉树存在的不足,Rudolf Bayer 与 1972 年发明了另一种改进后的排序二叉树:红黑树,他将这种排序二叉树称为“对称二叉 B 树”,而红黑树这个名字则由 Leo J. Guibas 和 Robert Sedgewick 于 1978 年首次提出。
红黑树是一个更高效的检索二叉树,因此常常用来实现关联数组。典型地,JDK 提供的集合类 TreeMap 本身就是一个红黑树的实现。
红黑树在原有的排序二叉树增加了如下几个要求:
- 性质 1:每个节点要么是红色,要么是黑色。
- 性质 2:根节点永远是黑色的。
- 性质 3:所有的叶节点都是空节点(即 null),并且是黑色的。
- 性质 4:每个红色节点的两个子节点都是黑色。(从每个叶子到根的路径上不会有两个连续的红色节点)
- 性质 5:从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点。
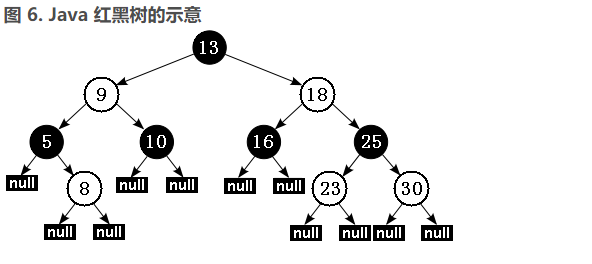
根据性质 5:红黑树从根节点到每个叶子节点的路径都包含相同数量的黑色节点,因此从根节点到叶子节点的路径中包含的黑色节点数被称为树的“黑色高度(black-height)”。
性质 4 则保证了从根节点到叶子节点的最长路径的长度不会超过任何其他路径的两倍。假如有一棵黑色高度为 3 的红黑树:从根节点到叶节点的最短路径长度是 2,该路径上全是黑色节点(黑节点 - 黑节点 - 黑节点)。最长路径也只可能为 4,在每个黑色节点之间插入一个红色节点(黑节点 - 红节点 - 黑节点 - 红节点 - 黑节点),性质 4 保证绝不可能插入更多的红色节点。由此可见,红黑树中最长路径就是一条红黑交替的路径。
红黑树的查找时间复杂度O(logn)
如果二叉排序树是平衡的,则n个节点的二叉排序树的高度为Log2n+1,其查找效率为O(Log2n),近似于折半查找。如果二叉排序树完全不平衡,则其深度可达到n,查找效率为O(n),退化为顺序查找。一般的,二叉排序树的查找性能在O(Log2n)到O(n)之间。因此,为了获得较好的查找性能,就要构造一棵平衡的二叉排序树。
红黑树并不是一个完美平衡二叉查找树,根结点的左子树如果比右子树高,但左子树和右子树的黑结点的层数是相等的,也即任意一个结点到到每个叶子结点的路径都包含数量相同的黑结点。所以我们叫红黑树这种平衡为黑色完美平衡。
红黑树的主要目的是实现一种平衡二叉树,这样可以达到最优的查询性能,时间复杂度为(O(logn)、 n为数据个数。
红黑树查找,因为红黑树是一颗二叉平衡树,并且查找不会破坏树的平衡,所以查找跟二叉平衡树的查找无异。正由于红黑树总保持黑色完美平衡,所以它的查找最坏时间复杂度为O(2lgN),也即整颗树刚好红黑相隔的时候,能有这么好的查找效率得益于红黑树自平衡的特性。
红黑树插入操作包括两部分工作:一查找插入的位置;二插入后自平衡。
红黑树的删除操作也包括两部分工作:一查找目标结点;而删除后自平衡。
网上有很多使用数学归纳法来计算红黑树时间复杂度的证明了,这里就不再赘述。我们可以简单思考一下,对于一棵普通的平衡二叉搜索树来说,它的搜索时间复杂度为O(logn),而作为红黑树,存在着最坏的情况,也就是查找的过程中,经过的节点全都是原来2-3树(读作二三树)里的3-节点,导致路径延长两倍,时间复杂度为O(2logn),由于时间复杂度的计算可以忽略系数,因此红黑树的搜索时间复杂度依然是O(logn),当然,由于这个系数的存在,在实际使用中,红黑树会比普通的平衡二叉树(AVL树)搜索效率要低一些。
红黑树和平衡二叉树
红黑树并不是真正的平衡二叉树,但在实际应用中,红黑树的统计性能要高于平衡二叉树,但极端性能略差。
由此我们可以得出结论:对于给定的黑色高度为 N 的红黑树,从根到叶子节点的最短路径长度为 N-1,最长路径长度为 2 * (N-1)。
提示:排序二叉树的深度直接影响了检索的性能,正如前面指出,当插入节点本身就是由小到大排列时,排序二叉树将变成一个链表,这种排序二叉树的检索性能最低:N 个节点的二叉树深度就是 N-1。
红黑树通过上面这种限制来保证它大致是平衡的——因为红黑树的高度不会无限增高,这样保证红黑树在最坏情况下都是高效的,不会出现普通排序二叉树的情况。
由于红黑树只是一个特殊的排序二叉树,因此对红黑树上的只读操作与普通排序二叉树上的只读操作完全相同,只是红黑树保持了大致平衡,因此检索性能比排序二叉树要好很多。
但在红黑树上进行插入操作和删除操作会导致树不再符合红黑树的特征,因此插入操作和删除操作都需要进行一定的维护,以保证插入节点、删除节点后的树依然是红黑树。
源码分析项目: E:\idea-workplace\javasource\src
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
/**
* 序列号
*/
private static final long serialVersionUID = 8683452581122892189L;
/**
* 默认容量
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 一个空数组
* 当用户指定该 ArrayList 容量为 0 时,返回该空数组
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* 一个空数组实例
* - 当用户没有指定 ArrayList 的容量时(即调用无参构造函数),返回的是该数组==>刚创建一个 ArrayList 时,其内数据量为 0。
* - 当用户第一次添加元素时,该数组将会扩容,变成默认容量为 10(DEFAULT_CAPACITY) 的一个数组===>通过 ensureCapacityInternal() 实现
* 它与 EMPTY_ELEMENTDATA 的区别就是:该数组是默认返回的,而后者是在用户指定容量为 0 时返回
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* ArrayList基于数组实现,用该数组保存数据, ArrayList 的容量就是该数组的长度
* - 该值为 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 时,当第一次添加元素进入 ArrayList 中时,数组将扩容值 DEFAULT_CAPACITY(10)
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* ArrayList实际存储的数据数量
*/
private int size;
/**
* 创建一个初试容量的、空的ArrayList
* @param initialCapacity 初始容量
* @throws IllegalArgumentException 当初试容量值非法(小于0)时抛出
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* 无参构造函数:
* - 创建一个 空的 ArrayList,此时其内数组缓冲区 elementData = {}, 长度为 0
* - 当元素第一次被加入时,扩容至默认容量 10
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 创建一个包含collection的ArrayList
* @param c 要放入 ArrayList 中的集合,其内元素将会全部添加到新建的 ArrayList 实例中
* @throws NullPointerException 当参数 c 为 null 时抛出异常
*/
public ArrayList(Collection<? extends E> c) {
//将集合转化成Object[]数组
elementData = c.toArray();
//把转化后的Object[]数组长度赋值给当前ArrayList的size,并判断是否为0
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
// 这句话意思是:c.toArray 可能不会返回 Object[],可以查看 java 官方编号为 6260652 的 bug
if (elementData.getClass() != Object[].class)
// 若 c.toArray() 返回的数组类型不是 Object[],则利用 Arrays.copyOf(); 来构造一个大小为 size 的 Object[] 数组
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 替换空数组
this.elementData = EMPTY_ELEMENTDATA;
}
}
/**
* 将数组缓冲区大小调整到实际 ArrayList 存储元素的大小,即 elementData = Arrays.copyOf(elementData, size);
* - 该方法由用户手动调用,以减少空间资源浪费的目的 ce.
*/
public void trimToSize() {
// modCount 是 AbstractList 的属性值:protected transient int modCount = 0;
// [问] modCount 有什么用?
modCount++;
// 当实际大小 < 数组缓冲区大小时
// 如调用默认构造函数后,刚添加一个元素,此时 elementData.length = 10,而 size = 1
// 通过这一步,可以使得空间得到有效利用,而不会出现资源浪费的情况
if (size < elementData.length) {
// 注意这里:这里的执行顺序不是 (elementData = (size == 0) ) ? EMPTY_ELEMENTDATA : Arrays.copyOf(elementData, size);
// 而是:elementData = ((size == 0) ? EMPTY_ELEMENTDATA : Arrays.copyOf(elementData, size));
// 这里是运算符优先级的语法
// 调整数组缓冲区 elementData,变为实际存储大小 Arrays.copyOf(elementData, size)
//先判断size是否为0,如果为0:实际存储为EMPTY_ELEMENTDATA,如果有数据就是Arrays.copyOf(elementData, size)
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
/**
* 指定 ArrayList 的容量
* @param minCapacity 指定的最小容量
*/
public void ensureCapacity(int minCapacity) {
// 最小扩充容量,默认是 10
//这句就是:判断是不是空的ArrayList,如果是的最小扩充容量10,否则最小扩充量为0
//上面无参构造函数创建后,当元素第一次被加入时,扩容至默认容量 10,就是靠这句代码
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
? 0
: DEFAULT_CAPACITY;
// 若用户指定的最小容量 > 最小扩充容量,则以用户指定的为准,否则还是 10
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
/**
* 私有方法:明确 ArrayList 的容量,提供给本类使用的方法
* - 用于内部优化,保证空间资源不被浪费:尤其在 add() 方法添加时起效
* @param minCapacity 指定的最小容量
*/
private void ensureCapacityInternal(int minCapacity) {
// 若 elementData == {},则取 minCapacity 为 默认容量和参数 minCapacity 之间的最大值
// 注:ensureCapacity() 是提供给用户使用的方法,在 ArrayList 的实现中并没有使用
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity= Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
/**
* 私有方法:明确 ArrayList 的容量
* - 用于内部优化,保证空间资源不被浪费:尤其在 add() 方法添加时起效
* @param minCapacity 指定的最小容量
*/
private void ensureExplicitCapacity(int minCapacity) {
// 将“修改统计数”+1,该变量主要是用来实现fail-fast机制的
modCount++;
// 防止溢出代码:确保指定的最小容量 > 数组缓冲区当前的长度
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
/**
* 数组缓冲区最大存储容量
* - 一些 VM 会在一个数组中存储某些数据--->为什么要减去 8 的原因
* - 尝试分配这个最大存储容量,可能会导致 OutOfMemoryError(当该值 > VM 的限制时)
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* 私有方法:扩容,以确保 ArrayList 至少能存储 minCapacity 个元素
* - 扩容计算:newCapacity = oldCapacity + (oldCapacity >> 1); 扩充当前容量的1.5倍
* @param minCapacity 指定的最小容量
*/
private void grow(int minCapacity) {
// 防止溢出代码
int oldCapacity = elementData.length;
// 运算符 >> 是带符号右移. 如 oldCapacity = 10,则 newCapacity = 10 + (10 >> 1) = 10 + 5 = 15
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0) // 若 newCapacity 依旧小于 minCapacity
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0) // 若 newCapacity 大于最大存储容量,则进行大容量分配
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
/**
* 私有方法:大容量分配,最大分配 Integer.MAX_VALUE
* @param minCapacity
*/
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
/**
* 返回ArrayList实际存储的元素数量
*/
public int size() {
return size;
}
/**
* ArrayList是否有元素
*/
public boolean isEmpty() {
return size == 0;
}
/**
* 是否包含o元素
*/
public boolean contains(Object o) {
// 根据 indexOf() 的值(索引值)来判断,大于等于 0 就包含
// 注意:等于 0 的情况不能漏,因为索引号是从 0 开始计数的
return indexOf(o) >= 0;
}
/**
* 顺序查找,返回元素的最低索引值(最首先出现的索引位置)
* @return 存在?最低索引值:-1
*/
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* 逆序查找,返回元素的最低索引值(最首先出现的索引位置)
* @return 存在?最低索引值:-1
*/
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* 实现的有Cloneable接口,深度复制:对拷贝出来的 ArrayList 对象的操作,不会影响原来的 ArrayList
* @return 一个克隆的 ArrayList 实例(深度复制的结果)
*/
public Object clone() {
try {
// Object 的克隆方法:会复制本对象及其内所有基本类型成员和 String 类型成员,但不会复制对象成员、引用对象
ArrayList<?> v = (ArrayList<?>) super.clone();
// 对需要进行复制的引用变量,进行独立的拷贝:将存储的元素移入新的 ArrayList 中
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
/**
* 返回 ArrayList 的 Object 数组
* - 包含 ArrayList 的所有储存元素
* - 对返回的该数组进行操作,不会影响该 ArrayList(相当于分配了一个新的数组)==>该操作是安全的
* - 元素存储顺序与 ArrayList 中的一致
*/
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
/**
* 返回 ArrayList 元素组成的数组
* @param a 需要存储 list 中元素的数组
* 若 a.length >= list.size,则将 list 中的元素按顺序存入 a 中,然后 a[list.size] = null, a[list.size + 1] 及其后的元素依旧是 a 的元素
* 否则,将返回包含list 所有元素且数组长度等于 list 中元素个数的数组
* 注意:若 a 中本来存储有元素,则 a 会被 list 的元素覆盖,且 a[list.size] = null
* @return
* @throws ArrayStoreException 当 a.getClass() != list 中存储元素的类型时
* @throws NullPointerException 当 a 为 null 时
*/
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
// 若数组a的大小 < ArrayList的元素个数,则新建一个T[]数组,
// 数组大小是"ArrayList的元素个数",并将“ArrayList”全部拷贝到新数组中
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
// 若数组a的大小 >= ArrayList的元素个数,则将ArrayList的全部元素都拷贝到数组a中。
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
/**
* 获取指定位置上的元素,从0开始
*/
public E get(int index) {
rangeCheck(index);//检查是否越界
return elementData(index);
}
/**
* 检查数组是否在界线内
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 返回在索引为 index 的元素:数组的随机访问
* - 默认包访问权限
*
* 封装粒度很强,连数组随机取值都封装为一个方法。
* 主要是避免每次取值都要强转===>设置值就没有封装成一个方法,因为设置值不需要强转
* @param index
* @return
*/
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
/**
* 设置 index 位置元素的值
* @param index 索引值
* @param element 需要存储在 index 位置的元素值
* @return 替换前在 index 位置的元素值
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E set(int index, E element) {
rangeCheck(index);//越界检查
E oldValue = elementData(index);//获取旧数值
elementData[index] = element;
return oldValue;
}
/**
*增加指定的元素到ArrayList的最后位置
* @param e 要添加的元素
* @return
*/
public boolean add(E e) {
// 确定ArrayList的容量大小---严谨
// 注意:size + 1,保证资源空间不被浪费,
// ☆☆☆按当前情况,保证要存多少个元素,就只分配多少空间资源
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
/**
*
*在这个ArrayList中的指定位置插入指定的元素,
* - 在指定位置插入新元素,原先在 index 位置的值往后移动一位
* @param index 指定位置
* @param element 指定元素
* @throws IndexOutOfBoundsException
*/
public void add(int index, E element) {
rangeCheckForAdd(index);//判断角标是否越界
//看上面的,size+1,保证资源空间不浪费,按当前情况,保证要存多少元素,就只分配多少空间资源
ensureCapacityInternal(size + 1); // Increments modCount!!
//第一个是要复制的数组,第二个是从要复制的数组的第几个开始,
// 第三个是复制到那,四个是复制到的数组第几个开始,最后一个是复制长度
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
/**
* 移除指定位置的元素
* index 之后的所有元素依次左移一位
* @param index 指定位置
* @return 被移除的元素
* @throws IndexOutOfBoundsException
*/
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;//要移动的长度
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// 将最后一个元素置空
elementData[--size] = null;
return oldValue;
}
/**
* 移除list中指定的第一个元素(符合条件索引最低的)
* 如果list中不包含这个元素,这个list不会改变
* 如果包含这个元素,index 之后的所有元素依次左移一位
* @param o 这个list中要被移除的元素
* @return
*/
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/**
* 快速删除第 index 个元素
* 和public E remove(int index)相比
* 私有方法,跳过检查,不返回被删除的值
* @param index 要删除的脚标
*/
private void fastRemove(int index) {
modCount++;//这个地方改变了modCount的值了
int numMoved = size - index - 1;//移动的个数
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; //将最后一个元素清除
}
/**
* 移除list中的所有元素,这个list表将在调用之后置空
* - 它会将数组缓冲区所以元素置为 null
* - 清空后,我们直接打印 list,却只会看见一个 [], 而不是 [null, null, ….] ==> toString() 和 迭代器进行了处理
*/
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
/**
* 将一个集合的所有元素顺序添加(追加)到 lits 末尾
* - ArrayList 是线程不安全的。
* - 该方法没有加锁,当一个线程正在将 c 中的元素加入 list 中,但同时有另一个线程在更改 c 中的元素,可能会有问题
* @param c 要追加的集合
* @return <tt>true</tt> ? list 元素个数有改变时,成功:失败
* @throws NullPointerException 当 c 为 null 时
*/
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;//要添加元素的个数
ensureCapacityInternal(size + numNew); //扩容
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
/**
* 从 List 中指定位置开始插入指定集合的所有元素,
* -list中原来位置的元素向后移
* - 并不会覆盖掉在 index 位置原有的值
* - 类似于 insert 操作,在 index 处插入 c.length 个元素(原来在此处的 n 个元素依次右移)
* @param index 插入指定集合的索引
* @param c 要添加的集合
* @return ? list 元素个数有改变时,成功:失败
* @throws IndexOutOfBoundsException {@inheritDoc}
* @throws NullPointerException if the specified collection is null
*/
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();//是将list直接转为Object[] 数组
int numNew = a.length; //要添加集合的元素数量
ensureCapacityInternal(size + numNew); // 扩容
int numMoved = size - index;//list中要移动的数量
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
/**
* 移除list中 [fromIndex,toIndex) 的元素
* - 从toIndex之后(包括toIndex)的元素向前移动(toIndex-fromIndex)个元素
* -如果(toIndex==fromIndex)这个操作没有影响
* @throws IndexOutOfBoundsException if {@code fromIndex} or
* {@code toIndex} is out of range
* ({@code fromIndex < 0 ||
* fromIndex >= size() ||
* toIndex > size() ||
* toIndex < fromIndex})
*/
protected void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = size - toIndex;//要移动的数量
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// 删除后,list 的长度
int newSize = size - (toIndex-fromIndex);
//将失效元素置空
for (int i = newSize; i < size; i++) {
elementData[i] = null;
}
size = newSize;
}
/**
* 添加时检查索引是否越界
*/
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 构建IndexOutOfBoundsException详细消息
*/
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
/**
* 移除list中指定集合包含的所有元素
* @param c 要从list中移除的指定集合
* @return {@code true} if this list changed as a result of the call
* @throws ClassCastException 如果list中的一个元素的类和指定集合不兼容
* (<a href="Collection.html#optional-restrictions">optional</a>)
* @throws NullPointerException 如果list中包含一个空元素,而指定集合中不允许有空元素
*/
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);//判断集合是否为空,如果为空报NullPointerException
//批量移除c集合的元素,第二个参数:是否采补集
return batchRemove(c, false);
}
/**
* Retains only the elements in this list that are contained in the
* specified collection. In other words, removes from this list all
* of its elements that are not contained in the specified collection.
*
* @param c collection containing elements to be retained in this list
* @return {@code true} if this list changed as a result of the call
* @throws ClassCastException if the class of an element of this list
* is incompatible with the specified collection
* (<a href="Collection.html#optional-restrictions">optional</a>)
* @throws NullPointerException if this list contains a null element and the
* specified collection does not permit null elements
* (<a href="Collection.html#optional-restrictions">optional</a>),
* or if the specified collection is null
* @see Collection#contains(Object)
*/
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}
/**
* 批处理移除
* @param c 要移除的集合
* @param complement 是否是补集
* 如果true:移除list中除了c集合中的所有元素
* 如果false:移除list中 c集合中的元素
*/
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
//遍历数组,并检查这个集合是否对应值,移动要保留的值到数组前面,w最后值为要保留的值得数量
//如果保留:将相同元素移动到前段,如果不保留:将不同的元素移动到前段
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
//最后 r=size 注意for循环中最后的r++
// w=保留元素的大小
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
//r!=size表示可能出错了,
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
//如果w==size:表示全部元素都保留了,所以也就没有删除操作发生,所以会返回false;反之,返回true,并更改数组
//而 w!=size;即使try抛出异常,也能正常处理异常抛出前的操作,因为w始终要为保留的前半部分,数组也不会因此乱序
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}
/**
* 私有方法
* 将ArrayList实例序列化
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// 写入所有元素数量的任何隐藏的东西
int expectedModCount = modCount;
s.defaultWriteObject();
//写入clone行为的容量大小
s.writeInt(size);
//以合适的顺序写入所有的元素
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
/**
* 私有方法
* 从反序列化中重构ArrayList实例
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
//读出大小和隐藏的东西
s.defaultReadObject();
// 从输入流中读取ArrayList的size
s.readInt(); // ignored
if (size > 0) {
ensureCapacityInternal(size);
Object[] a = elementData;
// 从输入流中将“所有的元素值”读出
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
/**
* 返回从指定索引开始到结束的带有元素的list迭代器
*/
public ListIterator<E> listIterator(int index) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index);
return new ListItr(index);
}
/**
* 返回从0索引开始到结束的带有元素的list迭代器
*/
public ListIterator<E> listIterator() {
return new ListItr(0);
}
/**
* 以一种合适的排序返回一个iterator到元素的结尾
*/
public Iterator<E> iterator() {
return new Itr();
}
/**
* Itr是AbstractList.Itr的优化版本
* 为什么会报ConcurrentModificationException异常?
* 1. Iterator 是工作在一个独立的线程中,并且拥有一个 mutex 锁。
* 2. Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,
* 这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,
* 3. 所以按照 fail-fast 原则 Iterator 会马上抛出 java.util.ConcurrentModificationException 异常。
* 4. 所以 Iterator 在工作的时候是不允许被迭代的对象被改变的。
* 但你可以使用 Iterator 本身的方法 remove() 来删除对象,
* 5. Iterator.remove() 方法会在删除当前迭代对象的同时维护索引的一致性。
*/
private class Itr implements Iterator<E> {
int cursor; // 下一个元素返回的索引
int lastRet = -1; // 最后一个元素返回的索引 -1 if no such
int expectedModCount = modCount;
/**
* 是否有下一个元素
*/
public boolean hasNext() {
return cursor != size;
}
/**
* 返回list中的值
*/
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;//i当前元素的索引
if (i >= size)//第一次检查:角标是否越界越界
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)//第二次检查,list集合中数量是否发生变化
throw new ConcurrentModificationException();
cursor = i + 1; //cursor 下一个元素的索引
return (E) elementData[lastRet = i];//最后一个元素返回的索引
}
/**
* 移除集合中的元素
*/
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
//移除list中的元素
ArrayList.this.remove(lastRet);
//由于cursor比lastRet大1,所有这行代码是指指针往回移动一位
cursor = lastRet;
//将最后一个元素返回的索引重置为-1
lastRet = -1;
//重新设置了expectedModCount的值,避免了ConcurrentModificationException的产生
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
/**
* jdk 1.8中使用的方法
* 将list中的所有元素都给了consumer,可以使用这个方法来取出元素
*/
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
/**
* 检查modCount是否等于expectedModCount
* 在 迭代时list集合的元素数量发生变化时会造成这两个值不相等
*/
final void checkForComodification() {
//当expectedModCount和modCount不相等时,就抛出ConcurrentModificationException
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
/*------------------------------------- Itr 结束 -------------------------------------------*/
/**
* AbstractList.ListItr 的优化版本
* ListIterator 与普通的 Iterator 的区别:
* - 它可以进行双向移动,而普通的迭代器只能单向移动
* - 它可以添加元素(有 add() 方法),而后者不行
*/
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
super();
cursor = index;
}
/**
* 是否有前一个元素
*/
public boolean hasPrevious() {
return cursor != 0;
}
/**
* 获取下一个元素的索引
*/
public int nextIndex() {
return cursor;
}
/**
* 获取 cursor 前一个元素的索引
* - 是 cursor 前一个,而不是当前元素前一个的索引。
* - 若调用 next() 后马上调用该方法,则返回的是当前元素的索引。
* - 若调用 next() 后想获取当前元素前一个元素的索引,需要连续调用两次该方法。
*/
public int previousIndex() {
return cursor - 1;
}
/**
* 返回 cursor 前一元素
*/
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)//第一次检查:索引是否越界
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)//第二次检查
throw new ConcurrentModificationException();
cursor = i;//cursor回移
return (E) elementData[lastRet = i];//返回 cursor 前一元素
}
/**
* 将数组的最后一个元素,设置成元素e
*/
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
//将数组最后一个元素,设置成元素e
ArrayList.this.set(lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
/**
* 添加元素
*/
public void add(E e) {
checkForComodification();
try {
int i = cursor;//当前元素的索引后移一位
ArrayList.this.add(i, e);//在i位置上添加元素e
cursor = i + 1;//cursor后移一位
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
/*------------------------------------- ListItr 结束 -------------------------------------------*/
/**
* 获取从 fromIndex 到 toIndex 之间的子集合(左闭右开区间)
* - 若 fromIndex == toIndex,则返回的空集合
* - 对该子集合的操作,会影响原有集合
* - 当调用了 subList() 后,若对原有集合进行删除操作(删除subList 中的首个元素)时,会抛出异常 java.util.ConcurrentModificationException
* 这个和Itr的原因差不多由于modCount发生了改变,对集合的操作需要用子集合提供的方法
* - 该子集合支持所有的集合操作
*
* 原因看 SubList 内部类的构造函数就可以知道
* @throws IndexOutOfBoundsException {@inheritDoc}
* @throws IllegalArgumentException {@inheritDoc}
*/
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, 0, fromIndex, toIndex);
}
/**
* 检查传入索引的合法性
* 注意[fromIndex,toIndex)
*/
static void subListRangeCheck(int fromIndex, int toIndex, int size) {
if (fromIndex < 0)
throw new IndexOutOfBoundsException("fromIndex = " + fromIndex);
if (toIndex > size)//由于是左闭右开的,所以toIndex可以等于size
throw new IndexOutOfBoundsException("toIndex = " + toIndex);
if (fromIndex > toIndex)
throw new IllegalArgumentException("fromIndex(" + fromIndex +
") > toIndex(" + toIndex + ")");
}
/**
* 私有类
* 嵌套内部类:也实现了 RandomAccess,提供快速随机访问特性
* 这个是通过映射来实现的
*/
private class SubList extends AbstractList<E> implements RandomAccess {
private final AbstractList<E> parent; //实际传入的是ArrayList本身
private final int parentOffset; // 相对于父集合的偏移量,其实就是 fromIndex
private final int offset; // 偏移量,默认是 0
int size; //SubList中的元素个数
SubList(AbstractList<E> parent,
int offset, int fromIndex, int toIndex) {
// 看到这部分,就理解为什么对 SubList 的操作,会影响父集合---> 因为子集合的处理,仅仅是给出了一个映射到父集合相应区间的引用
// 再加上 final,的修饰,就能明白为什么进行了截取子集合操作后,父集合不能删除 SubList 中的首个元素了--->offset 不能更改
this.parent = parent;
this.parentOffset = fromIndex;//原来的偏移量
this.offset = offset + fromIndex;//加了offset的偏移量
this.size = toIndex - fromIndex;
this.modCount = ArrayList.this.modCount;
}
/**
* 设置新值,返回旧值
*/
public E set(int index, E e) {
rangeCheck(index);//越界检查
checkForComodification();//检查
//从这一条语句可以看出:对子类添加元素,是直接操作父类添加的
E oldValue = ArrayList.this.elementData(offset + index);
ArrayList.this.elementData[offset + index] = e;
return oldValue;
}
/**
* 获取指定索引的元素
*/
public E get(int index) {
rangeCheck(index);
checkForComodification();
return ArrayList.this.elementData(offset + index);
}
/**
* 返回元素的数量
*/
public int size() {
checkForComodification();
return this.size;
}
/**
* 指定位置添加元素
*/
public void add(int index, E e) {
rangeCheckForAdd(index);
checkForComodification();
//从这里可以看出,先通过index拿到在原来数组上的索引,再调用父类的添加方法实现添加
parent.add(parentOffset + index, e);
this.modCount = parent.modCount;
this.size++;
}
/**
* 移除指定位置的元素
*/
public E remove(int index) {
rangeCheck(index);
checkForComodification();
E result = parent.remove(parentOffset + index);
this.modCount = parent.modCount;
this.size--;
return result;
}
/**
* 移除subList中的[fromIndex,toIndex)之间的元素
*/
protected void removeRange(int fromIndex, int toIndex) {
checkForComodification();
parent.removeRange(parentOffset + fromIndex,
parentOffset + toIndex);
this.modCount = parent.modCount;
this.size -= toIndex - fromIndex;
}
/**
* 添加集合中的元素到subList结尾
* @param c
* @return
*/
public boolean addAll(Collection<? extends E> c) {
//调用父类的方法添加集合元素
return addAll(this.size, c);
}
/**
* 在subList指定位置,添加集合中的元素
*/
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);//越界检查
int cSize = c.size();
if (cSize==0)
return false;
checkForComodification();
//调用父类的方法添加
parent.addAll(parentOffset + index, c);
this.modCount = parent.modCount;
this.size += cSize;
return true;
}
/**
* subList中的迭代器
*/
public Iterator<E> iterator() {
return listIterator();
}
/**
* 返回从指定索引开始到结束的带有元素的list迭代器
*/
public ListIterator<E> listIterator(final int index) {
checkForComodification();
rangeCheckForAdd(index);
final int offset = this.offset;//偏移量
return new ListIterator<E>() {
int cursor = index;
int lastRet = -1;//最后一个元素的下标
int expectedModCount = ArrayList.this.modCount;
public boolean hasNext() {
return cursor != SubList.this.size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= SubList.this.size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (offset + i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[offset + (lastRet = i)];
}
public boolean hasPrevious() {
return cursor != 0;
}
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (offset + i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[offset + (lastRet = i)];
}
//jdk8的方法
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = SubList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (offset + i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[offset + (i++)]);
}
// update once at end of iteration to reduce heap write traffic
lastRet = cursor = i;
checkForComodification();
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
SubList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = ArrayList.this.modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.set(offset + lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
SubList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = ArrayList.this.modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (expectedModCount != ArrayList.this.modCount)
throw new ConcurrentModificationException();
}
};
}
//subList的方法,同样可以再次截取List同样是使用映射方式
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, offset, fromIndex, toIndex);
}
private void rangeCheck(int index) {
if (index < 0 || index >= this.size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private void rangeCheckForAdd(int index) {
if (index < 0 || index > this.size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+this.size;
}
private void checkForComodification() {
if (ArrayList.this.modCount != this.modCount)
throw new ConcurrentModificationException();
}
/**
* subList方法:获取一个分割器
* - fail-fast
* - late-binding:后期绑定
* - java8 开始提供
*/
public Spliterator<E> spliterator() {
checkForComodification();
return new ArrayListSpliterator<E>(ArrayList.this, offset,
offset + this.size, this.modCount);
}
}
/*------------------SubList结束-------------------------------*/
//1.8方法
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);//这里将所有元素都接受到Consumer中了,所有可以使用1.8中的方法直接获取每一个元素
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
/**
* 获取一个分割器
* - fail-fast 机制和itr,subList一个机制
* - late-binding:后期绑定
* - java8 开始提供
* @return a {@code Spliterator} over the elements in this list
* @since 1.8
*/
@Override
public Spliterator<E> spliterator() {
return new ArrayListSpliterator<>(this, 0, -1, 0);
}
/** Index-based split-by-two, lazily initialized Spliterator */
// 基于索引的、二分的、懒加载的分割器
static final class ArrayListSpliterator<E> implements Spliterator<E> {
//用于存放ArrayList对象
private final ArrayList<E> list;
//起始位置(包含),advance/split操作时会修改
private int index;
//结束位置(不包含),-1 表示到最后一个元素
private int fence;
//用于存放list的modCount
private int expectedModCount;
//默认的起始位置是0,默认的结束位置是-1
ArrayListSpliterator(ArrayList<E> list, int origin, int fence,
int expectedModCount) {
this.list = list; // OK if null unless traversed
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
//在第一次使用时实例化结束位置
private int getFence() {
int hi; // (a specialized variant appears in method forEach)
ArrayList<E> lst;
//fence<0时(第一次初始化时,fence才会小于0):
if ((hi = fence) < 0) {
//如果list集合中没有元素
if ((lst = list) == null)
//list 为 null时,fence=0
hi = fence = 0;
else {
//否则,fence = list的长度。
expectedModCount = lst.modCount;
hi = fence = lst.size;
}
}
return hi;
}
//分割list,返回一个新分割出的spliterator实例
//相当于二分法,这个方法会递归
//1.ArrayListSpliterator本质上还是对原list进行操作,只是通过index和fence来控制每次处理范围
//2.也可以得出,ArrayListSpliterator在遍历元素时,不能对list进行结构变更操作,否则抛错。
public ArrayListSpliterator<E> trySplit() {
//hi:结束位置(不包括) lo:开始位置 mid:中间位置
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
//当lo>=mid,表示不能在分割,返回null
//当lo<mid时,可分割,切割(lo,mid)出去,同时更新index=mid
/**如: | 0 | 1 | 2 | 3 | 4 | 5 | 数组长度为6 的进行 split
* 结束角标 hi:6 开始角标lo:0 mid:3 lo<mid
* [0,3) 同时 lo:3 hi:6 mid:4
* [3,4) 同时 lo:4 hi:6 mid:5
* [4,5) 同时 lo:5 hid:6 mid:5
* null
*/
return (lo >= mid) ? null : // divide range in half unless too small
new ArrayListSpliterator<E>(list, lo, index = mid,
expectedModCount);
}
//返回true 时,只表示可能还有元素未处理
//返回false 时,没有剩余元素处理了。。。
public boolean tryAdvance(Consumer<? super E> action) {
if (action == null)
throw new NullPointerException();
int hi = getFence(), i = index;
if (i < hi) {
index = i + 1;//角标前移
@SuppressWarnings("unchecked") E e = (E)list.elementData[i];//取出元素
action.accept(e);//给Consumer类函数
if (list.modCount != expectedModCount)//遍历时,结构发生变更,抛错
throw new ConcurrentModificationException();
return true;
}
return false;
}
//顺序遍历处理所有剩下的元素
//Consumer类型,传入值处理
public void forEachRemaining(Consumer<? super E> action) {
int i, hi, mc; // hi list的长度 )
ArrayList<E> lst; Object[] a;//数组,元素集合
if (action == null)
throw new NullPointerException();
//如果list不为空 而且 list中的元素不为空
if ((lst = list) != null && (a = lst.elementData) != null) {
//当fence<0时,表示fence和expectedModCount未初始化,可以思考一下这里能否直接调用getFence(),嘿嘿?
if ((hi = fence) < 0) {
mc = lst.modCount;
hi = lst.size;//由于上面判断过了,可以直接将lst大小给hi(不包括)
}
else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {//将所有元素给Consumer
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
if (lst.modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
//估算大小
public long estimateSize() {
return (long) (getFence() - index);
}
//打上特征值:、可以返回size
public int characteristics() {
//命令,大小,子大小
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}
/**
* 1.8方法
* 根据Predicate条件来移除元素
* 将所有元素依次根据filter的条件判断
* Predicate 是 传入元素 返回 boolean 类型的接口
*/
@Override
public boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
// figure out which elements are to be removed
// any exception thrown from the filter predicate at this stage
// will leave the collection unmodified
int removeCount = 0;
final BitSet removeSet = new BitSet(size);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
@SuppressWarnings("unchecked")
final E element = (E) elementData[i];
if (filter.test(element)) {//如果元素满足条件
removeSet.set(i);//将满足条件的角标存放到set中
removeCount++;//移除set的数量
}
}
if (modCount != expectedModCount) {//判断是否外部修改了
throw new ConcurrentModificationException();
}
// shift surviving elements left over the spaces left by removed elements
final boolean anyToRemove = removeCount > 0;//如果有移除元素
if (anyToRemove) {
final int newSize = size - removeCount;//新大小
//i:[0,size) j[0,newSize)
for (int i=0, j=0; (i < size) && (j < newSize); i++, j++) {
i = removeSet.nextClearBit(i);//i是[0,size)中不是set集合中的角标
elementData[j] = elementData[i];//新元素
}
//将空元素置空
for (int k=newSize; k < size; k++) {
elementData[k] = null; // Let gc do its work
}
this.size = newSize;
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
return anyToRemove;
}
/**
* UnaryOperator 接受一个什么类型的参数,返回一个什么类型的参数
* 对数组中的每一个元素进行一系列的操作,返回同样的元素,
* 如果 List<Student> lists 将list集合中的每一个student姓名改为张三
* 使用这个方法就非常方便
* @param operator
*/
@Override
@SuppressWarnings("unchecked")
public void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
//取出每一个元素给operator的apply方法
elementData[i] = operator.apply((E) elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
/**
* 根据 Comparator条件进行排序
* Comparator(e1,e2) 返回 boolean类型
*/
@Override
@SuppressWarnings("unchecked")
public void sort(Comparator<? super E> c) {
final int expectedModCount = modCount;
Arrays.sort((E[]) elementData, 0, size, c);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
}
// 看到这部分,就理解为什么对 SubList 的操作,会影响父集合--->
因为子集合的处理,仅仅是给出了一个映射到父集合相应区间的引用
// 再加上 final,的修饰,就能明白为什么进行了截取子集合操作后,父集合不能删除 SubList 中的首个元素了--->
offset 不能更改

为什么链表的长度为8是变成红黑树?为什么为6时又变成链表?
因为,大部分的文章都是分析链表是怎么转换成红黑树的,但是并没有说明为什么当链表长度为8的时候才做转换动作。本人 第 一反应也是一样,只能初略的猜测是因为时间和空间的权衡
首先当链表长度为6时 查询的平均长度为 n/2=3
红黑树为 log(6)=2.6
为8时 : 链表 8/2=4
红黑树 log(8)=3
根据两者的函数图也可以知道随着bin中的数量越多那么红黑树花的时间远远比链表少,所以我觉得这也是原因之一。为7的时候两者应该是 链表花的时间小于红黑树的,但是为什么不是在7的时候转成链表呢,我觉得可能是因为把7当做一个链表和红黑树的过渡点。
事实上真的是因为考虑到时间复杂度所以才把是在8的时候进行转成红黑树吗?其实这并不是真正的原因
为什么在JDK1.8中进行对HashMap优化的时候,把链表转化为红黑树的阈值是8,而不是7或者不是20呢(面试蘑菇街问过)?
- 如果选择6和8(如果链表小于等于6树还原转为链表,大于等于8转为树),中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
- 还有一点重要的就是**由于treenodes的大小大约是常规节点的两倍,因此我们仅在容器包含足够的节点以保证使用时才使用它们,当它们变得太小(由于移除或调整大小)时,它们会被转换回普通的node节点,容器中节点分布在hash桶中的频率遵循泊松分布,桶的长度超过8的概率非常非常小。所以作者应该是根据概率统计而选择了8作为阀值**
为什么HashMap 数组长度小于64优先扩容?
链表长度大于8有两种情况:
- 1、table长度足够,hash冲突过多
- 2、hash没有冲突,但是在计算table下标的时候,由于table长度太小,导致很多hash不一致的
第二种情况是可以用扩容的方式来避免的,扩容后链表长度变短,读写效率自然提高。另外,扩容相对于转换为红黑树的好处在于可以保证数据结构更简单。
由此可见并不是链表长度超过8就一定会转换成红黑树,而是先尝试扩容
基本思想是当红黑树中的元素减少并小于一定数量时,会切换回链表。而元素减少有两种情况:
- 1、调用map的remove方法删除元素
hashMap的remove方法,会进入到removeNode方法,找到要删除的节点,并判断node类型是否为treeNode,然后进入删除红黑树节点逻辑的removeTreeNode方法中,该方法有关解除红黑树结构的分支如下:
//判断是否要解除红黑树的条件
if (root == null || root.right == null ||
(rl = root.left) == null || rl.left == null) {
tab[index] = first.untreeify(map); // too small
return;
}
可以看到,此处并没有利用到网上所说的,当节点数小于UNTREEIFY_THRESHOLD时才转换,而是通过红黑树根节点及其子节点是否为空来判断。
如果红黑树的节点不为null并且链表的长度小于等于6才会将红黑树转成链表。
1、hashMap并不是在链表元素个数大于8就一定会转换为红黑树,而是先考虑扩容,扩容达到默认限制后才转换
2、hashMap的红黑树不一定小于6的时候才会转换为链表,而是只有在resize的时候才会根据 UNTREEIFY_THRESHOLD 进行转换。(原因?不太明白hhh)
1.JDK1.7版本的CurrentHashMap的实现原理
在JDK1.7中ConcurrentHashMap采用了数组+Segment+分段锁的方式实现。
1.Segment(分段锁)
ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表,同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
2.内部结构
ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。如下图是ConcurrentHashMap的内部结构图:
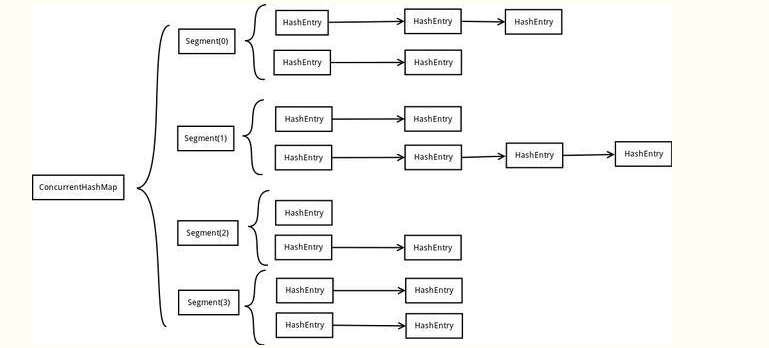
从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作。
第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部。
3.该结构的优劣势
坏处
这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长
好处
写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上)。
所以,通过这一种结构,ConcurrentHashMap的并发能力可以大大的提高。
2.JDK1.8版本的CurrentHashMap的实现原理
JDK8中ConcurrentHashMap参考了JDK8 HashMap的实现,采用了数组+链表+红黑树的实现方式来设计,内部大量采用CAS操作,这里我简要介绍下CAS。
CAS是compare and swap的缩写,即我们所说的比较交换。cas是一种基于锁的操作,而且是乐观锁。在java中锁分为乐观锁和悲观锁。悲观锁是将资源锁住,等一个之前获得锁的线程释放锁之后,下一个线程才可以访问。而乐观锁采取了一种宽泛的态度,通过某种方式不加锁来处理资源,比如通过给记录加version来获取数据,性能较悲观锁有很大的提高。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存地址里面的值和A的值是一样的,那么就将内存里面的值更新成B。CAS是通过无限循环来获取数据的,若果在第一轮循环中,a线程获取地址里面的值被b线程修改了,那么a线程需要自旋,到下次循环才有可能机会执行。
JDK8中彻底放弃了Segment转而采用的是Node,其设计思想也不再是JDK1.7中的分段锁思想。
Node:保存key,value及key的hash值的数据结构。其中value和next都用volatile修饰,保证并发的可见性。
Java8 ConcurrentHashMap结构基本上和Java8的HashMap一样,不过保证线程安全性。
在JDK8中ConcurrentHashMap的结构,由于引入了红黑树,使得ConcurrentHashMap的实现非常复杂,我们都知道,红黑树是一种性能非常好的二叉查找树,其查找性能为O(logN),但是其实现过程也非常复杂,而且可读性也非常差,DougLea的思维能力确实不是一般人能比的,早期完全采用链表结构时Map的查找时间复杂度为O(N),JDK8中ConcurrentHashMap在链表的长度大于某个阈值的时候会将链表转换成红黑树进一步提高其查找性能。
总结
其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树。
1.数据结构:取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
2.保证线程安全机制:JDK1.7采用segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。JDK1.8采用CAS+Synchronized保证线程安全。
3.锁的粒度:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
4.链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
5.查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。
CurrentHashMap的线程安全
初始化数据结构时的线程安全
HashMap的底层数据结构这里简单带过一下,不做过多赘述:
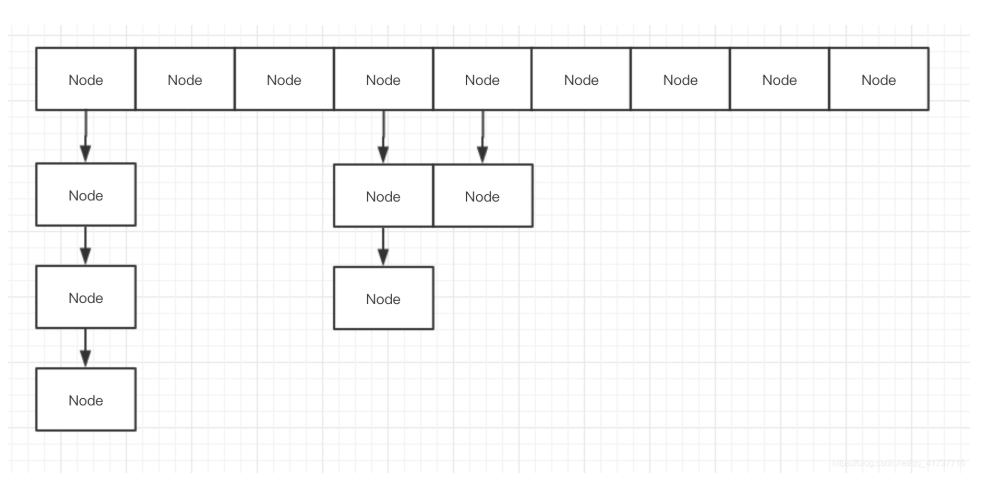
大致是以一个Node对象数组来存放数据,Hash冲突时会形成Node链表,在链表长度超过8,Node数组超过64时会将链表结构转换为红黑树,Node对象:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
...
}
值得注意的是,value和next指针使用了volatile来保证其可见性
在JDK1.8中,初始化ConcurrentHashMap的时候这个Node[]数组是还未初始化的,会等到第一次put方法调用时才初始化:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//判断Node数组为空
if (tab == null || (n = tab.length) == 0)
//初始化Node数组
tab = initTable();
...
}
此时是会有并发问题的,如果多个线程同时调用initTable初始化Node数组怎么办?看看大师是如何处理的:
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
//每次循环都获取最新的Node数组引用
while ((tab = table) == null || tab.length == 0) {
//sizeCtl是一个标记位,若为-1也就是小于0,代表有线程在进行初始化工作了
if ((sc = sizeCtl) < 0)
//让出CPU时间片
Thread.yield(); // lost initialization race; just spin
//CAS操作,将本实例的sizeCtl变量设置为-1
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
//如果CAS操作成功了,代表本线程将负责初始化工作
try {
//再检查一遍数组是否为空
if ((tab = table) == null || tab.length == 0) {
//在初始化Map时,sizeCtl代表数组大小,默认16
//所以此时n默认为16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
//Node数组
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
//将其赋值给table变量
table = tab = nt;
//通过位运算,n减去n二进制右移2位,相当于乘以0.75
//例如16经过运算为12,与乘0.75一样,只不过位运算更快
sc = n - (n >>> 2);
}
} finally {
//将计算后的sc(12)直接赋值给sizeCtl,表示达到12长度就扩容
//由于这里只会有一个线程在执行,直接赋值即可,没有线程安全问题
//只需要保证可见性
sizeCtl = sc;
}
break;
}
}
return tab;
}
table变量使用了volatile来保证每次获取到的都是最新写入的值
transient volatile Node<K,V>[] table;
总结
就算有多个线程同时进行put操作,在初始化数组时使用了乐观锁CAS操作来决定到底是哪个线程有资格进行初始化,其他线程均只能等待。
用到的并发技巧:
- volatile变量(sizeCtl):它是一个标记位,用来告诉其他线程这个坑位有没有人在,其线程间的可见性由volatile保证。
- CAS操作:CAS操作保证了设置sizeCtl标记位的原子性,保证了只有一个线程能设置成功
put操作的线程安全
直接看代码:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//对key的hashCode进行散列
int hash = spread(key.hashCode());
int binCount = 0;
//一个无限循环,直到put操作完成后退出循环
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//当Node数组为空时进行初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//Unsafe类volatile的方式取出hashCode散列后通过与运算得出的Node数组下标值对应的Node对象
//此时的Node对象若为空,则代表还未有线程对此Node进行插入操作
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//直接CAS方式插入数据
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
//插入成功,退出循环
break; // no lock when adding to empty bin
}
//查看是否在扩容,先不看,扩容再介绍
else if ((fh = f.hash) == MOVED)
//帮助扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//对Node对象进行加锁
synchronized (f) {
//二次确认此Node对象还是原来的那一个
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
//无限循环,直到完成put
for (Node<K,V> e = f;; ++binCount) {
K ek;
//和HashMap一样,先比较hash,再比较equals
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
//和链表头Node节点不冲突,就将其初始化为新Node作为上一个Node节点的next
//形成链表结构
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
...
}
值得关注的是tabAt(tab, i)方法,其使用Unsafe类volatile的操作volatile式地查看值,保证每次获取到的值都是最新的:
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
虽然上面的table变量加了volatile,但也只能保证其引用的可见性,并不能确保其数组中的对象是否是最新的,所以需要Unsafe类volatile式地拿到最新的Node
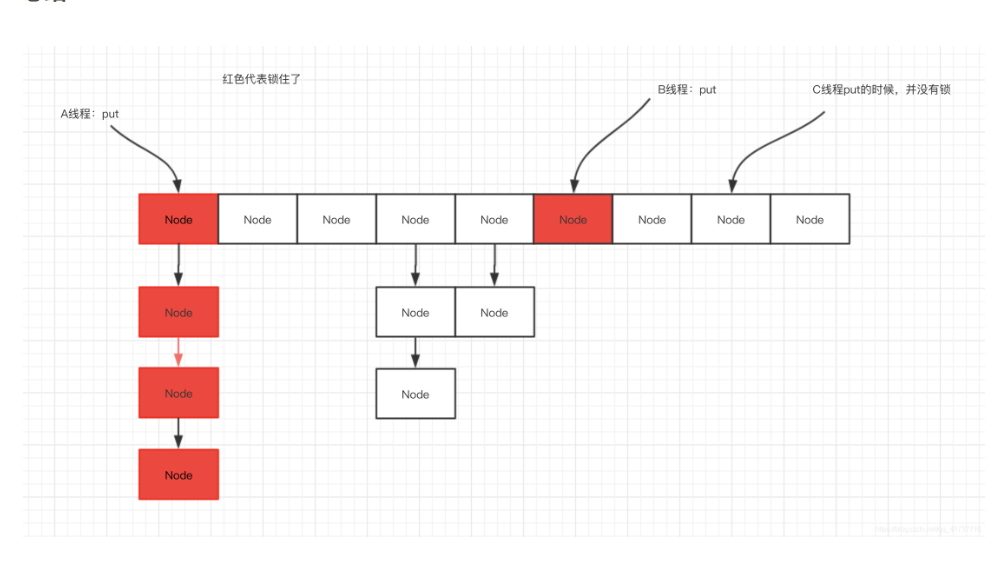
由于其减小了锁的粒度,若Hash完美不冲突的情况下,可同时支持n个线程同时put操作,n为Node数组大小,在默认大小16下,可以支持最大同时16个线程无竞争同时操作且线程安全。当hash冲突严重时,Node链表越来越长,将导致严重的锁竞争,此时会进行扩容,将Node进行再散列,下面会介绍扩容的线程安全性。总结一下用到的并发技巧:
- 减小锁粒度:将Node链表的头节点作为锁,若在默认大小16情况下,将有16把锁,大大减小了锁竞争(上下文切换),就像开头所说,将串行的部分最大化缩小,在理想情况下线程的put操作都为并行操作。同时直接锁住头节点,保证了线程安全
- Unsafe的getObjectVolatile方法:此方法确保获取到的值为最新
扩容操作的线程安全
在扩容时,ConcurrentHashMap支持多线程并发扩容,在扩容过程中同时支持get查数据,若有线程put数据,还会帮助一起扩容,这种无阻塞算法,将并行最大化的设计,堪称一绝。
先来看看扩容代码实现:
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//根据机器CPU核心数来计算,一条线程负责Node数组中多长的迁移量
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
//本线程分到的迁移量
//假设为16(默认也为16)
stride = MIN_TRANSFER_STRIDE; // subdivide range
//nextTab若为空代表线程是第一个进行迁移的
//初始化迁移后的新Node数组
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
//这里n为旧数组长度,左移一位相当于乘以2
//例如原数组长度16,新数组长度则为32
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
//设置nextTable变量为新数组
nextTable = nextTab;
//假设为16
transferIndex = n;
}
//假设为32
int nextn = nextTab.length;
//标示Node对象,此对象的hash变量为-1
//在get或者put时若遇到此Node,则可以知道当前Node正在迁移
//传入nextTab对象
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
//i为当前正在处理的Node数组下标,每次处理一个Node节点就会自减1
if (--i >= bound || finishing)
advance = false;
//假设nextIndex=16
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
//由以上假设,nextBound就为0
//且将nextIndex设置为0
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
//bound=0
bound = nextBound;
//i=16-1=15
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
//此时i=15,取出Node数组下标为15的那个Node,若为空则不需要迁移
//直接设置占位标示,代表此Node已处理完成
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
//检测此Node的hash是否为MOVED,MOVED是一个常量-1,也就是上面说的占位Node的hash
//如果是占位Node,证明此节点已经处理过了,跳过i=15的处理,继续循环
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
//锁住这个Node
synchronized (f) {
//确认Node是原先的Node
if (tabAt(tab, i) == f) {
//ln为lowNode,低位Node,hn为highNode,高位Node
//这两个概念下面以图来说明
Node<K,V> ln, hn;
if (fh >= 0) {
//此时fh与原来Node数组长度进行与运算
//如果高X位为0,此时runBit=0
//如果高X位为1,此时runBit=1
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
//这里的Node,都是同一Node链表中的Node对象
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
//正如上面所说,runBit=0,表示此Node为低位Node
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
//Node为高位Node
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
//若hash和n与运算为0,证明为低位Node,原理同上
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
//这里将高位Node与地位Node都各自组成了两个链表
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
//将低位Node设置到新Node数组中,下标为原来的位置
setTabAt(nextTab, i, ln);
//将高位Node设置到新Node数组中,下标为原来的位置加上原Node数组长度
setTabAt(nextTab, i + n, hn);
//将此Node设置为占位Node,代表处理完成
setTabAt(tab, i, fwd);
//继续循环
advance = true;
}
....
}
}
}
}
}
这里说一下迁移时为什么要分一个ln(低位Node)、hn(高位Node),首先说一个现象:
我们知道,在put值的时候,首先会计算hash值,再散列到指定的Node数组下标中:
//根据key的hashCode再散列
int hash = spread(key.hashCode());
//使用(n - 1) & hash 运算,定位Node数组中下标值
(f = tabAt(tab, i = (n - 1) & hash);
1234
其中n为Node数组长度,这里假设为16。
假设有一个key进来,它的散列之后的hash=9,那么它的下标值是多少呢?
- (16 - 1)和 9 进行与运算 -> 0000 1111 和 0000 1001 结果还是 0000 1001 = 9
假设Node数组需要扩容,我们知道,扩容是将数组长度增加两倍,也就是32,那么下标值会是多少呢?
- (32 - 1)和 9 进行与运算 -> 0001 1111 和 0000 1001 结果还是9
此时,我们把散列之后的hash换成20,那么会有怎样的变化呢?
- (16 - 1)和 20 进行与运算 -> 0000 1111 和 0001 0100 结果是 0000 0100 = 4
- (32 - 1)和 20 进行与运算 -> 0001 1111 和 0001 0100 结果是 0001 0100 = 20
此时细心的读者应该可以发现,如果hash在高X位为1,(X为数组长度的二进制-1的最高位),则扩容时是需要变换在Node数组中的索引值的,不然就hash不到,丢失数据,所以这里在迁移的时候将高X位为1的Node分类为hn,将高X位为0的Node分类为ln。
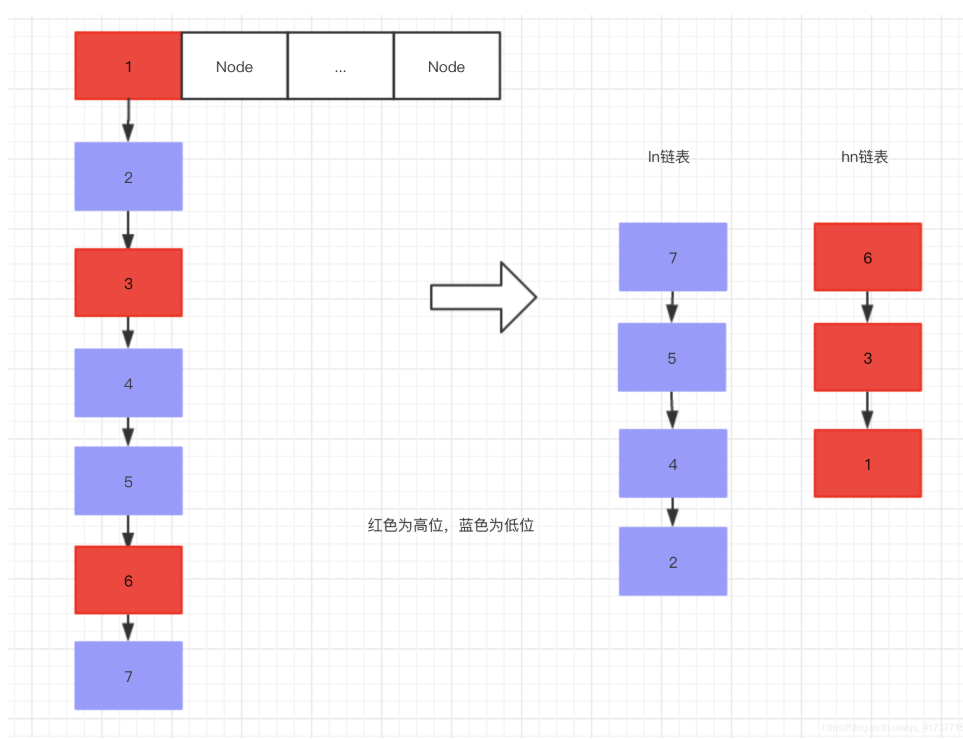
其中,低位链表放入原下标处,而高位链表则需要加上原Node数组长度,其中为什么不多赘述,上面已经举例说明了,这样就可以保证高位Node在迁移到新Node数组中依然可以使用hash算法散列到对应下标的数组中去了。
最后将原Node数组中对应下标Node对象设置为fwd标记Node,表示该节点迁移完成,到这里,一个节点的迁移就完成了,将进行下一个节点的迁移,也就是i-1=14下标的Node节点。
扩容时的get操作
假设Node下标为16的Node节点正在迁移,突然有一个线程进来调用get方法,正好key又散列到下标为16的节点,此时怎么办?
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//假如Node节点的hash值小于0
//则有可能是fwd节点
else if (eh < 0)
//调用节点对象的find方法查找值
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
重点看有注释的那两行,在get操作的源码中,会判断Node中的hash是否小于0,是否还记得我们的占位Node,其hash为MOVED,为常量值-1,所以此时判断线程正在迁移,委托给fwd占位Node去查找值:
//内部类 ForwardingNode中
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
// 这里的查找,是去新Node数组中查找的
// 下面的查找过程与HashMap查找无异,不多赘述
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}
到这里应该可以恍然大悟了,之所以占位Node需要保存新Node数组的引用也是因为这个,它可以支持在迁移的过程中照样不阻塞地查找值,可谓是精妙绝伦的设计。
HashMap默认加载因子为什么选择0.75?(阿里)
Hashtable 初始容量是11 ,扩容 方式为2N+1;
HashMap 初始容量是16,扩容方式为2N;
阿里的人突然问我为啥扩容因子是0.75,回来总结了一下; 提高空间利用率和 减少查询成本的折中,主要是泊松分布,0.75的话碰撞最小,
HashMap有两个参数影响其性能:初始容量和加载因子。容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子是哈希表在其容量自动扩容之前可以达到多满的一种度量。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行扩容、rehash操作(即重建内部数据结构),扩容后的哈希表将具有两倍的原容量。
通常,加载因子需要在时间和空间成本上寻求一种折衷。
加载因子过高,例如为1,虽然减少了空间开销,提高了空间利用率,但同时也增加了查询时间成本;
加载因子过低,例如0.5,虽然可以减少查询时间成本,但是空间利用率很低,同时提高了rehash操作的次数。
在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少rehash操作次数,所以,一般在使用HashMap时建议根据预估值设置初始容量,减少扩容操作。
选择0.75作为默认的加载因子,完全是时间和空间成本上寻求的一种折衷选择,
简单翻译一下就是在理想情况下,使用随机哈希码,节点出现的频率在hash桶中遵循泊松分布,同时给出了桶中元素个数和概率的对照表。
从上面的表中可以看到当桶中元素到达8个的时候,概率已经变得非常小,也就是说用0.75作为加载因子,每个碰撞位置的链表长度超过8个是几乎不可能的。
好了,再深挖就要挖到统计学那边去了,就此打住,重申一下使用hash容器请尽量指定初始容量,且是2的幂次方。
ConcurrentHashMap 与HashMap和Hashtable 最大的不同在于:put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Segment里面的Entry,然后在遍历entry链表
从JDK1.7版本的ReentrantLock+Segment+HashEntry,
到JDK1.8版本中synchronized+CAS+HashEntry+红黑树,
https://www.cnblogs.com/aspirant/p/8623864.html
一致性Hash算法
https://segmentfault.com/a/1190000021199728
HashMap并发下死循环问题解析
https://coolshell.cn/articles/9606.html
Java集合体系结构图
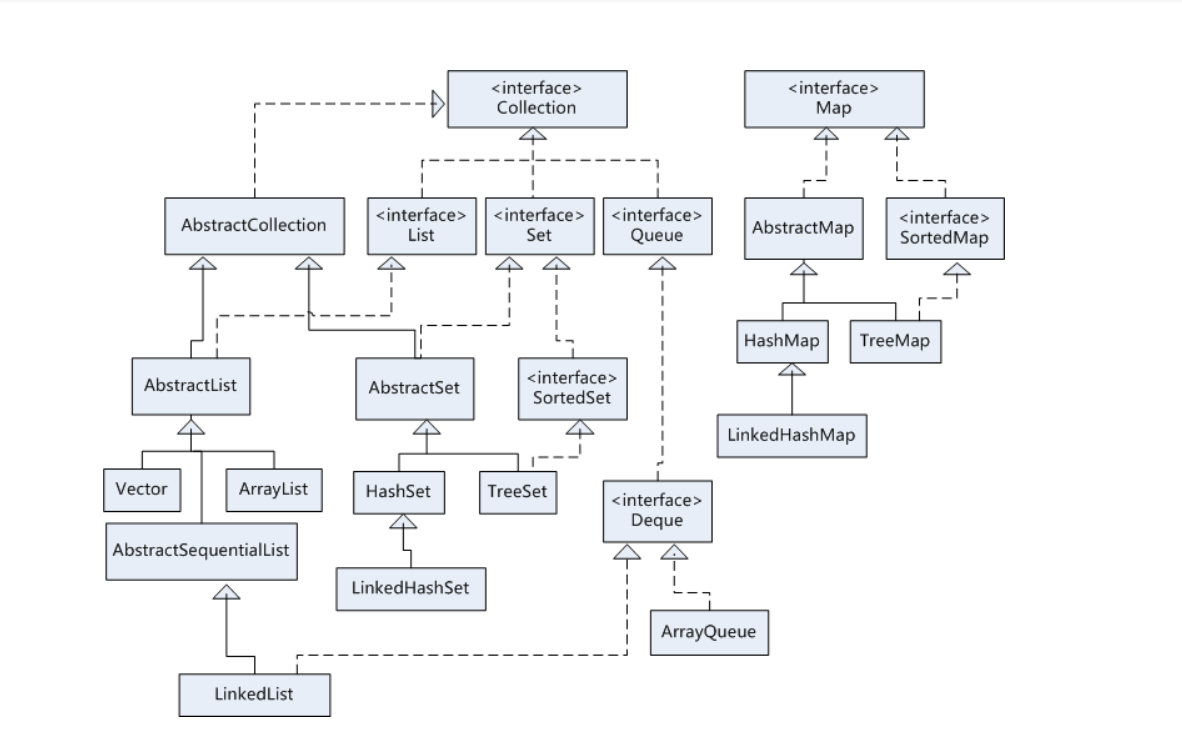
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8xJ9YXHw-1673797486001)(…/…/…/typora/image/image-20201128171836940.png)]
HashMap遍历的其中方式以及性能的比较
HashMap 的 7 种遍历方式与性能分析!
[面试|HashMap|红黑树] 转载:HashMap到8时转为红黑树到6转为链表 原因详解
https://melodyjerry.blog.csdn.net/article/details/116201883?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&utm_relevant_index=1