Java 凭借着自身活跃的开源社区和完善的生态优势,在过去的二十几年一直是最受欢迎的编程语言之一。步入云原生时代,蓬勃发展的云原生技术释放云计算红利,推动业务进行云原生化改造,加速企业数字化转型。
然而 Java 的云原生转型之路面临着巨大的挑战,Java 的运行机制和云原生特性存在着诸多矛盾。企业借助云原生技术进行深层次成本优化,资源成本管理被上升到前所未有的高度。公有云上资源按量收费,用户对资源用量十分敏感。在内存使用方面,基于 Java 虚拟机的执行机制使得任何 Java 程序都会有固定的基础内存开销,相比 C++/Golang 等原生语言,Java 应用占用的内存巨大,被称为“内存吞噬者”,因此 Java 应用上云更加昂贵。并且应用集成到云上之后系统复杂度增加,普通用户对云上 Java 应用内存没有清晰的认识,不知道如何为应用合理配置内存,出现 OOM 问题时也很难排障,遇到了许多问题。
为什么 堆内存未超过 Xmx 却发生了 OOM?怎么理解操作系统和JVM的内存关系?为什么程序占用的内存比 Xmx 大不少,内存都用在哪儿了?为什么线上容器内的程序内存需求更大?本文将 在 Java 应用云原生化演进实践中遇到的这些问题进行了抽丝剥茧的分析,并给出云原生 Java 应用内存的配置建议。
背景知识
K8s 应用的资源配置
云原生架构以 K8s 为基石,应用在 K8s 上部署,以容器组的形态运行。K8s 的资源模型有两个定义,资源请求(request)和资源限制(limit),K8s 保障容器拥有 request数量的资源,但不允许使用超过limit数量的资源。以如下的内存配置为例,容器至少能获得 1024Mi 的内存资源,但不允许超过 4096Mi,一旦内存使用超限,该容器将发生OOM,而后被 K8s 控制器重启。
spec:
containers:
- name: edas
image: alibaba/edas
resources:
requests:
memory: "1024Mi"
limits:
memory: "4096Mi"
command: ["java", "-jar", "edas.jar"]
容器 OOM
对于容器的 OOM 机制,首先需要来复习一下容器的概念。当我们谈到容器的时候,会说这是一种沙盒技术,容器作为一个沙盒,内部是相对独立的,并且是有边界有大小的。容器内独立的运行环境通过 Linux的Namespace 机制实现,对容器内 PID、Mount、UTS、IPD、Network 等 Namespace 进行了障眼法处理,使得容器内看不到宿主机 Namespace 也看不到其他容器的 Namespace;而所谓容器的边界和大小,是指要对容器使用 CPU、内存、IO 等资源进行约束,不然单个容器占用资源过多可能导致其他容器运行缓慢或者异常。Cgroup 是 Linux 内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,也是实现容器资源约束的核心技术。容器在操作系统看来只不过是一种特殊进程,该进程对资源的使用受 Cgroup 的约束。当进程使用的内存量超过 Cgroup 的限制量,就会被系统 OOM Killer 无情地杀死。
所以,所谓的容器 OOM,实质是运行在Linux系统上的容器进程发生了 OOM。Cgroup 并不是一种晦涩难懂的技术,Linux 将其实现为了文件系统,这很符合 Unix 一切皆文件的哲学。对于 Cgroup V1 版本,我们可以直接在容器内的 /sys/fs/cgroup/ 目录下查看当前容器的 Cgroup 配置。
对于容器内存来说,memory.limit_in_bytes 和 memory.usage_in_bytes 是内存控制组中最重要的两个参数,前者标识了当前容器进程组可使用内存的最大值,后者是当前容器进程组实际使用的内存总和。一般来说,使用值和最大值越接近,OOM 的风险越高。
# 当前容器内存限制量
[root@zhz ~]# cat /sys/fs/cgroup/memory/memory.limit_in_bytes
9223372036854771712
# 当前容器内存实际用量
[root@zhz ~]# cat /sys/fs/cgroup/memory/memory.usage_in_bytes
4529991680
JVM OOM
说到 OOM,Java 开发者更熟悉的是 JVM OOM,当 JVM 因为没有足够的内存来为对象分配空间并且垃圾回收器也已经没有空间可回收时,将会抛出 java.lang.OutOfMemoryError。按照 JVM 规范,除了程序计数器不会抛出 OOM 外,其他各个内存区域都可能会抛出 OOM。最常见的 JVM OOM 情况有几种:
☑ java.lang.OutOfMemoryError:
<<<Java heap space 堆内存溢出>>>。当堆内存 (Heap Space) 没有足够空间存放新创建的对象时,就会抛出该错误。一般由于内存泄露或者堆的大小设置不当引起。对于内存泄露,需要通过内存监控软件查找程序中的泄露代码,而堆大小可以通过-Xms,-Xmx等参数修改。
☑ java.lang.OutOfMemoryError:
<<<PermGen space / Metaspace 永久代/元空间溢出>>>。永久代存储对象包括class信息和常量,JDK 1.8 使用 Metaspace 替换了永久代(Permanent Generation)。通常因为加载的 class 数目太多或体积太大,导致抛出该错误。可以通过修改 -XX:MaxPermSize 或者 -XX:MaxMetaspaceSize 启动参数, 调大永久代/元空间大小。
☑ java.lang.OutOfMemoryError:
<<<Unable to create new native thread 无法创建新线程>>>。每个 Java 线程都需要占用一定的内存空间, 当 JVM 向底层操作系统请求创建一个新的 native 线程时, 如果没有足够的资源分配就会报此类错误。可能原因是 native 内存不足、线程泄露导致线程数超过操作系统最大线程数 ulimit 限制或是线程数超过 kernel.pid_max。需要根据情况进行资源升配、限制线程池大小、减少线程栈大小等操作。
为什么堆内存未超过 Xmx 却发生了 OOM?
相信很多人都遇到过这一场景,在 K8s 部署的 Java 应用经常重启,查看容器退出状态为exit code 137 reason: OOM Killed 各方信息都指向明显的 OOM,然而 JVM 监控数据显示堆内存用量并未超过最大堆内存限制Xmx,并且配置了 OOM 自动 heapdump 参数之后,发生 OOM 时却没有产生 dump 文件。
根据上面的背景知识介绍,容器内的 Java 应用可能会发生两种类型的 OOM 异常,
一种是 JVM OOM,一种是容器 OOM。
JVM 的 OOM 是 JVM 内存区域空间不足导致的错误,JVM 主动抛出错误并退出进程,通过观测数据可以看到内存用量超限,并且 JVM 会留下相应的错误记录。而容器的 OOM 是系统行为,整个容器进程组使用的内存超过 Cgroup 限制,被系统 OOM Killer 杀死,在系统日志和 K8s 事件中会留下相关记录。
总的来说,Java程序内存使用同时受到来自 JVM 和 Cgroup 的限制,其中 Java 堆内存受限于 Xmx 参数,超限后发生 JVM OOM;整个进程内存受限于容器内存limit值,超限后发生容器 OOM。需要结合观测数据、JVM 错误记录、系统日志和 K8s 事件对 OOM 进行区分、排障,并按需进行配置调整。
怎么理解操作系统和 JVM 的内存关系?
上文说到 Java 容器 OOM 实质是 Java 进程使用的内存超过 Cgroup 限制,被操作系统的 OOM Killer 杀死。那在操作系统的视角里,如何看待 Java 进程的内存?操作系统和 JVM 都有各自的内存模型,二者是如何映射的?对于探究 Java 进程的 OOM 问题,理解 JVM 和操作系统之间的内存关系非常重要。
以最常用的 OpenJDK 为例,JVM 本质上是运行在操作系统上的一个 C++ 进程,因此其内存模型也有 Linux 进程的一般特点。Linux 进程的虚拟地址空间分为内核空间和用户空间,用户空间又细分为很多个段,此处选取几个和本文讨论相关度高的几个段,描述 JVM 内存与进程内存的映射关系。
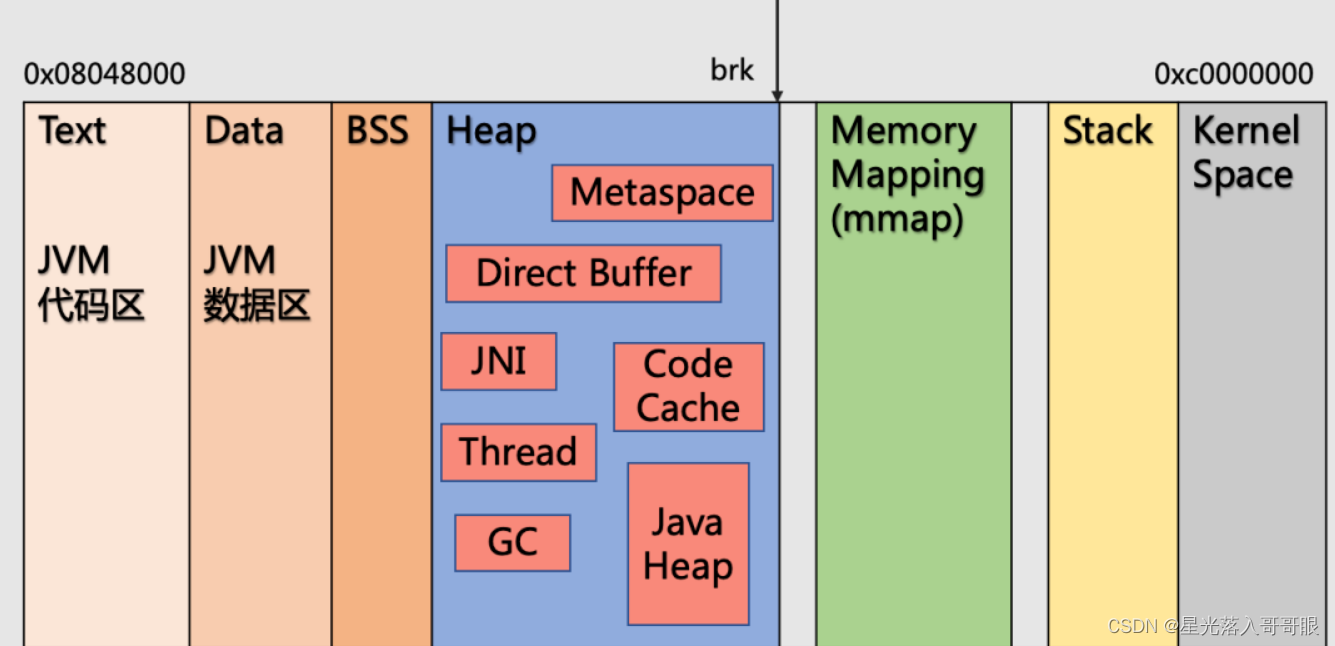
☑ 代码段。一般指程序代码在内存中的映射,这里特别指出是 JVM 自身的代码,而不是Java代码。
☑ 数据段。在程序运行初已经对变量进行初始化的数据,此处是 JVM 自身的数据。
☑ 堆空间。运行时堆是 Java 进程和普通进程区别最大的一个内存段。Linux 进程内存模型里的堆是为进程在运行时动态分配的对象提供内存空间,而几乎所有JVM内存模型里的东西,都是 JVM 这个进程在运行时新建出来的对象。而 JVM 内存模型中的 Java 堆,只不过是 JVM 在其进程堆空间上建立的一段逻辑空间。
☑ 栈空间。存放进程的运行栈,此处并不是 JVM 内存模型中的线程栈,而是操作系统运行 JVM 本身需要留存的一些运行数据。
如上所述,堆空间作为 Linux 进程内存布局和 JVM 内存布局都有的概念,是最容易混淆也是差别最大的一个概念。Java 堆相较于 Linux 进程的堆,范围更小,是 JVM 在其进程堆空间上建立的一段逻辑空间,而进程堆空间还包含支撑 JVM 虚拟机运行的内存数据,例如 Java 线程堆栈、代码缓存、GC 和编译器数据等。
为什么程序占用的内存比 Xmx 大不少,内存都用在哪了?
在 Java 开发者看来,Java 代码运行中开辟的对象都放在 Java 堆中,所以很多人会将 Java 堆内存等同于 Java 进程内存,将 Java 堆内存限制参数Xmx当作进程内存限制参数使用,并且把容器内存限制也设置为 Xmx 一样大小,然后悲催地发现容器被 OOM 了。
实质上除了大家所熟悉的堆内存 (Heap),JVM 还有所谓的非堆内存 (Non-Heap),除去 JVM 管理的内存,还有绕过 JVM 直接开辟的本地内存。Java 进程的内存占用情况可以简略地总结为下图:

JDK8 引入了 Native Memory Tracking (NMT)特性,可以追踪 JVM 的内部内存使用。默认情况下,NMT 是关闭状态,使用 JVM 参数开启:-XX:NativeMemoryTracking=[off | summary | detail]
注意:启用 NMT 会导致 5% -10% 的性能开销。
// 此处限制最大堆内存为 300M,使用 G1 作为 GC 算法,开启 NMT 追踪进程的内存使用情况。
java -Xms300m -Xmx300m -XX:+UseG1GC -XX:NativeMemoryTracking=summary -jar app.jar
开启 NMT 后,可以使用 jcmd 命令打印 JVM 内存的占用情况。此处仅查看内存摘要信息,设置单位为 MB。
jcmd <pid> VM.native_memory summary scale=MB
JVM 总内存
Native Memory Tracking:
Total: reserved(保留)=1764MB, committed(使用的)=534MB
NMT 报告显示进程当前保留内存为 1764MB,已提交内存为 534MB,远远高于最大堆内存 300M。
保留指为进程开辟一段连续的虚拟地址内存,可以理解为进程可能使用的内存量;
提交指将虚拟地址与物理内存进行映射,可以理解为进程当前占用的内存量。
需要特别说明的是,NMT 所统计的内存与操作系统统计的内存有所差异,Linux 在分配内存时遵循 lazy allocation 机制,只有在进程真正访问内存页时才将其换入物理内存中,所以使用 top 命令看到的进程物理内存占用量与 NMT 报告中看到的有差别。此处只用 NMT 说明 JVM 视角下内存的占用情况。
Java Heap
Java 堆内存如设置的一样,实际开辟了 300M 的内存空间。
Java Heap (reserved=300MB, committed=300MB)
(mmap: reserved=300MB, committed=300MB)
Metaspace
加载的类被存储在 Metaspace,此处元空间加载了 11183 个类,保留了近 1G,提交了 61M。
加载的类越多,使用的元空间就越多。元空间大小受限于-XX:MaxMetaspaceSize(默认无限制)和 -XX:CompressedClassSpaceSize(默认 1G)。
Class (reserved=1078MB, committed=61MB)
(classes #11183)
(malloc=2MB #19375)
(mmap: reserved=1076MB, committed=60MB)
Thread
JVM 线程堆栈也需要占据一定空间。此处 61 个线程占用了 60M 空间,每个线程堆栈默认约为 1M。堆栈大小由 -Xss 参数控制。
Thread (reserved=60MB, committed=60MB)
(thread #61)
(stack: reserved=60MB, committed=60MB)
Code Cache
代码缓存区主要用来保存 JIT 即时编译器编译后的代码和 Native(本地) 方法,目前缓存了 36M 的代码。代码缓存区可以通过 -XX:ReservedCodeCacheSize 参数进行容量设置。
Code (reserved=250MB, committed=36MB)
(malloc=6MB #9546)
(mmap: reserved=244MB, committed=30MB)
GC
GC (reserved=47MB, committed=47MB)
(malloc=4MB #11696)
(mmap: reserved=43MB, committed=43MB)
GC 垃圾收集器也需要一些内存空间支撑 GC 操作,GC 占用的空间与具体选用的 GC 算法有关,此处的 GC 算法使用了 47M。在其他配置相同的情况下,换用 SerialGC:
GC (reserved=1MB, committed=1MB)
(mmap: reserved=1MB, committed=1MB)
可以看到 SerialGC 算法仅使用 1M 内存。这是因为 SerialGC 是一种简单的串行算法,涉及数据结构简单,计算数据量小,所以内存占用也小。但是简单的 GC 算法可能会带来性能的下降,需要平衡性能和内存表现进行选择。
Symbol
JVM 的 Symbol 包含符号表和字符串表,此处占用 15M。
Symbol (reserved=15MB, committed=15MB)
(malloc=11MB #113566)
(arena=3MB #1)
非 JVM 内存
NMT 只能统计 JVM 内部的内存情况,还有一部分内存不由JVM管理。除了 JVM 托管的内存之外,程序也可以显式地请求堆外内存 ByteBuffer.allocateDirect,这部分内存受限于 -XX:MaxDirectMemorySize 参数(默认等于-Xmx)。System.loadLibrary 所加载的 JNI 模块也可以不受 JVM 控制地申请堆外内存。
综上 其实并没有一个能准确估量 Java 进程内存用量的模型,只能够尽可能多地考虑到各种因素。其中有一些内存区域能通过 JVM 参数进行容量限制,例如代码缓存、元空间等,但有些内存区域不受 JVM 控制,而与具体应用的代码有关。
Total memory = Heap + Code Cache + Metaspace + Thread stacks +
Symbol + GC + Direct buffers + JNI + ...
为什么线上容器比本地测试内存需求更大?
经常有用户反馈,为什么相同的一份代码,在线上容器里跑总是要比本地跑更耗内存,甚至出现 OOM。可能的情况的情况有如下几种:
没有使用容器感知的 JVM 版本
在一般的物理机或虚拟机上,当未设置 -Xmx 参数时,JVM 会从常见位置(例如,Linux 中的 /proc目录下)查找其可以使用的最大内存量,然后按照主机最大内存的 1/4 作为默认的 JVM 最大堆内存量。而早期的 JVM 版本并未对容器进行适配,当运行在容器中时,仍然按照主机内存的 1/4 设置 JVM最 大堆,而一般集群节点的主机内存比本地开发机大得多,容器内的 Java 进程堆空间开得大,自然更耗内存。同时在容器中又受到 Cgroup 资源限制,当容器进程组内存使用量超过 Cgroup 限制时,便会被 OOM。为此,8u191 之后的 OpenJDK 引入了默认开启的 UseContainerSupport 参数,使得容器内的 JVM 能感知容器内存限制,按照 Cgroup 内存限制量的 1/4 设置最大堆内存量
线上业务耗费更多内存
对外提供服务的业务往往会带来更活跃的内存分配动作,比如创建新的对象、开启执行线程,这些操作都需要开辟内存空间,所以线上业务往往耗费更多内存。并且越是流量高峰期,耗费的内存会更多。所以为了保证服务质量,需要依据自身业务流量,对应用内存配置进行相应扩容。
云原生 Java 应用内存的配置建议
★ 使用容器感知的 JDK 版本。 对于使用 Cgroup V1 的集群,需要升级至 8u191+、Java 9、Java 10 以及更高版本;对于使用 Cgroup V2 的集群,需要升级至 8u372+ 或 Java 15 及更高版本。
★ 使用 NativeMemoryTracking(NMT) 了解应用的 JVM 内存用量。 NMT 能够追踪 JVM 的内存使用情况,在测试阶段可以使用 NMT 了解程序JVM使用内存的大致分布情况,作为内存容量配置的参考依据。JVM 参数 -XX:NativeMemoryTracking 用于启用 NMT,开启 NMT 后,可以使用 jcmd 命令打印 JVM 内存的占用情况。
★ 根据 Java 程序内存使用量设置容器内存 limit。 容器 Cgroup 内存限制值来源于对容器设置的内存 limit 值,当容器进程使用的内存量超过 limit,就会发生容器 OOM。为了程序在正常运行或业务波动时发生 OOM,应该按照 Java 进程使用的内存量上浮 20%~30% 设置容器内存 limit。如果初次运行的程序,并不了解其实际内存使用量,可以先设置一个较大的 limit 让程序运行一段时间,按照观测到的进程内存量对容器内存 limit 进行调整。
★ OOM 时自动 dump 内存快照,并为 dump 文件配置持久化存储,比如使用 PVC 挂载到 hostPath、OSS 或 NAS,尽可能保留现场数据,支撑后续的故障排查。
The process of heart, the result