高级DBA教你达梦8国产数据库MergeInto批量插入并忽略主键重复报错特殊用法(达梦官方手册没有的内容)
一、达梦8国产数据库简介
达梦 8 是一款由武汉达梦数据库有限公司基于 C/C++语言开发的国产关系型数据库,有支持 X86 和 ARM 平台的版本,可以部署到开源系统 CentOS6.X+及国产系统 KyLin-V4+上。作为国产关系型数据库,其 DM8 与 Oracle 数据库的设计思路非常相似。达梦数据库具有高性能、高可靠性和高安全性的特点,支持标准 SQL 语言,提供了丰富的数据库管理和查询功能,适用于各种规模和复杂度的企业应用。它可以运行在多种操作系统上,包括 Windows、Linux 和 UNIX 等。达梦数据库还提供了分布式数据库和集群技术,可以实现数据的高可用性和扩展性。它还支持数据备份和恢复、数据加密、权限管理等安全功能,保护数据的完整性和机密性。
达梦数据库在政府、金融、电信、制造等行业得到了广泛应用,具有较低的成本和良好的本地化支持,适合中国企业的需求。
达梦8(DM8)是武汉达梦数据库有限公司自主研发的新一代数据库管理系统,它是达梦数据库系列产品的最新版本之一,具有完全自主知识产权,是中国国产数据库领域中的重要产品。以下是达梦8数据库的一些核心特点和优势:
-
高性能与高可用性:DM8设计了全新的体系架构,旨在提升数据库处理大规模并发事务的能力,支持大规模并行计算和海量数据处理技术,适用于企业级应用,满足高吞吐量和低延迟的需求。同时,提供了多种高可用性解决方案,包括数据守护、读写分离等,保障业务连续性。
-
兼容性与易用性:DM8对Oracle SQL及过程化语言PL/SQL有良好的兼容性,这意味着对于熟悉Oracle的用户和开发者来说,转向DM8的学习曲线较低。此外,DM8提供了图形化的管理工具DM8Manager,界面友好,操作便捷,符合中国用户的使用习惯。
-
安全性与标准化:遵循国际和国内的多项安全标准,提供了全面的安全防护机制,包括数据加密、访问控制、审计追踪等功能,确保数据的安全性。同时,支持多种国家标准和行业规范,便于在不同领域的应用集成。
-
分布式与云计算支持:DM8融合了分布式和弹性计算技术,能够适配云计算环境,支持分布式部署,实现资源的弹性伸缩和负载均衡,满足云计算平台上的大数据处理需求。
-
智能化管理与运维:内置了智能化的诊断、优化和自我调优功能,能自动分析和解决数据库运行中遇到的问题,降低运维成本,提高效率。
-
广泛的应用场景:适用于政府、金融、电信、能源、制造等多个行业,支持OLTP(在线事务处理)、OLAP(在线分析处理)、数据仓库等多种应用场景。
达梦数据库作为国产数据库的代表之一,DM8在技术和市场上持续发展,致力于为用户提供稳定、可靠、高效的数据管理解决方案,推动国产数据库技术的进步与应用推广。
二、核心需求说明
笔者现在存在大数据条件,预计有几千万数据,我现在想批量插入表里面!
但是在插入过程中,遇到主键重复,导致一批数据插入失败了,我现在想解决一批数据插入过程中,如果遇到主键重复,忽略报错,继续插入呢!
数据库传统批量如下:
CREATE TABLE new_employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50) NOT NULL,
department VARCHAR(50),
join_date DATE
);
INSERT INTO new_employees (emp_id, emp_name, department, join_date)
VALUES (1, 'Alice Lee', 'Marketing', '2023-01-01'),
(3, 'Charlie Brown', 'HR', '2024-03-01');
MyBatis 批处理用法
在 MyBatis 中,可以使用<foreach>标签来实现批量插入。以下是一个示例代码:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.swsmu.ebs.ebsbackend.ebsuser.mapper.TestMapper">
<insert id="saveBatch">
INSERT INTO product_test1 (
`fund_code`,
`fund_name`,
`interview`,
`deleted`,
`born_date`
) VALUES
<foreach collection="list" separator="," item="item">
(#{item.fundCode},#{item.fundName},#{item.interview},0,#{item.bornDate})
</foreach>
</insert>
</mapper>
在上述代码中,saveBatch方法用于执行批量插入操作。<foreach>标签用于遍历集合中的每个元素,并将每个元素的值作为插入语句的参数。separator属性指定了元素之间的分隔符,在上述示例中,使用逗号作为分隔符。
在 Java 代码中,可以按照以下方式使用saveBatch方法:
List<FundProduct> list = new ArrayList<>();
list.add(new FundProduct("11", "Alice Lee", "Marketing", "2023-01-01"));
list.add(new FundProduct("3", "Charlie Brown", "HR", "2024-03-01"));
// 分片批量插入
List<List<FundProduct>> listPartition = Lists.partition(list, 500);
for (List<FundProduct> item : listPartition) {
mapper.saveBatch(item);
}
在上述示例中,首先创建了一个包含要插入数据的列表list。然后,使用Lists.partition方法将列表分为多个子列表,每个子列表包含 500 个元素。最后,遍历每个子列表,并使用mapper.saveBatch方法将子列表中的数据批量插入到数据库中。
请注意,在实际应用中,可能需要根据具体的数据库配置和性能要求进行适当的调整。例如,可能需要考虑数据库的最大允许数据包大小、并发插入的数量等因素。
三、引入达梦数据库 MERGE INTO 解决
-- 创建临时表并插入数据
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50) NOT NULL,
department VARCHAR(50),
join_date DATE
);
drop table new_employees;
-- 创建临时表并插入数据
CREATE TABLE new_employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50) NOT NULL,
department VARCHAR(50),
join_date DATE
);
INSERT INTO new_employees (emp_id, emp_name, department, join_date)
VALUES (1, 'Alice Lee', 'Marketing', '2023-01-01'),
(3, 'Charlie Brown', 'HR', '2024-03-01');
-- 执行MERGE INTO操作
MERGE INTO employees e
USING new_employees ne
ON e.emp_id = ne.emp_id
WHEN MATCHED THEN
UPDATE SET e.emp_name = ne.emp_name, e.department = ne.department, e.join_date = ne.join_date
WHEN NOT MATCHED THEN
INSERT (emp_id, emp_name, department, join_date)
VALUES (ne.emp_id, ne.emp_name, ne.department, ne.join_date);
new_employees表数据插入employees表,过程中如果发现主键重复了,则更新!
传统批量插入语句如下:
INSERT INTO new_employees (emp_id, emp_name, department, join_date)
VALUES (1, 'Alice Lee', 'Marketing', '2023-01-01'),
(3, 'Charlie Brown', 'HR', '2024-03-01');
用达梦8 的MERGE INTO 批出来帮我写出来如下:
看起来可能存在一点混淆。实际上,MERGE INTO语句本身即用于实现根据匹配条件更新现有记录或插入新记录的目的,它已经支持批量处理多条数据。在之前的回答中,我已经提供了一个使用MERGE INTO来同时处理插入和更新的示例,其中包含了多条记录的操作。这里再次明确展示该批处理的MERGE INTO语句:
MERGE INTO employees e
USING (
SELECT 1 AS emp_id, 'Alice Lee' AS emp_name, 'Marketing' AS department, '2023-01-01' AS join_date FROM DUAL
UNION ALL
SELECT 3, 'Charlie Brown', 'HR', '2024-03-01' FROM DUAL
) ne
ON e.emp_id = ne.emp_id
WHEN MATCHED THEN
UPDATE SET e.emp_name = ne.emp_name, e.department = ne.department, e.join_date = ne.join_date
WHEN NOT MATCHED THEN
INSERT (emp_id, emp_name, department, join_date)
VALUES (ne.emp_id, ne.emp_name, ne.department, ne.join_date);
在这个例子中,我使用了一个子查询(联合了两个SELECT语句通过UNION ALL)来代替直接从new_employees临时表中选择数据,这样做是为了直接在MERGE INTO语句内部定义要处理的数据集,但这并不改变MERGE INTO批处理的本质。原本的临时表方法也是有效的,只要确保数据源(这里是new_employees)包含你想要合并的所有记录即可。
下面的执行例子也是笔者亲自执行过的!
drop table employees;
-- 创建临时表并插入数据
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50) NOT NULL,
department VARCHAR(50),
join_date DATE
);
-- 下面是合并批量插入语句:反复执行插入同样的数据,最终结果只有2条,并且主键重发会触发更新!
MERGE INTO employees e
USING (
SELECT 1 AS emp_id, 'Alice Lee' AS emp_name, 'Marketing' AS department, '2023-01-01' AS join_date FROM dual
UNION ALL
SELECT 3, 'Charlie Brown', 'HR', '2024-03-01' FROM dual
) new_records
ON (e.emp_id = new_records.emp_id)
WHEN MATCHED THEN
UPDATE SET e.emp_name = new_records.emp_name, e.department = new_records.department, e.join_date = new_records.join_date
WHEN NOT MATCHED THEN
INSERT (emp_id, emp_name, department, join_date)
VALUES (new_records.emp_id, new_records.emp_name, new_records.department, new_records.join_date);
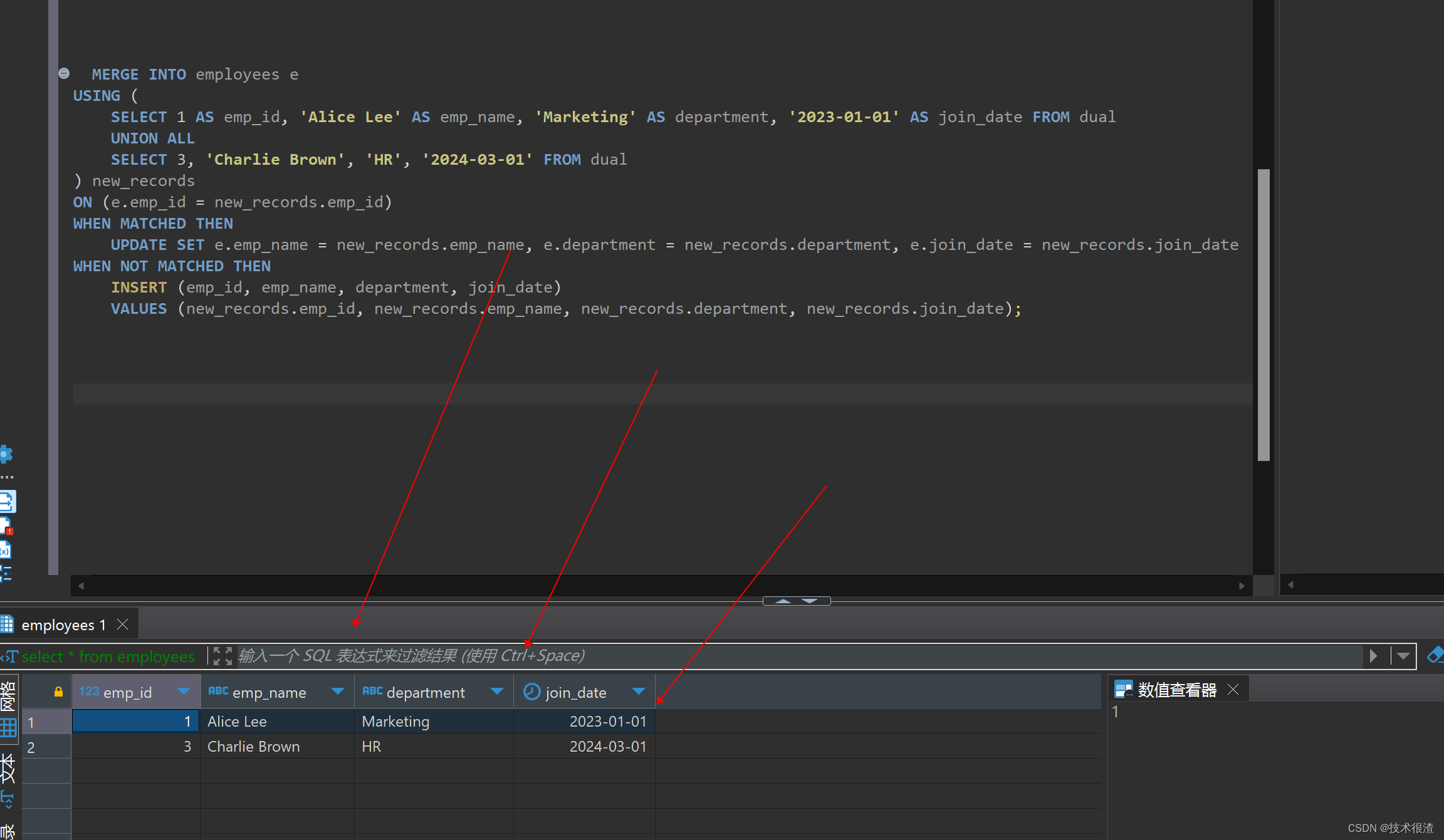
数据重复插入,反复执行,但是最终employees表中只存在2条,并且不会报错,也不会报主键重复,因为发现主键重复会触发更新操作!
mybatis的达梦8数据库的merge into 批量处理用法
在MyBatis中,你可以使用动态SQL标签来实现这样的迭代处理。通常,如果你有多个记录需要通过MERGE INTO语句处理,你会从一个集合中获取这些数据,然后在MyBatis映射文件中使用<foreach>标签来遍历这些记录。但是,直接将整个MERGE INTO语句作为动态SQL的一部分可能不太直观,因为MyBatis主要用于处理单行操作,而MERGE INTO是一个复合操作,涉及多行数据的逻辑处理。
一种可行的方法是将数据批量加载到数据库中后,单独执行一个MERGE INTO操作。不过,如果非要在MyBatis中模拟这种行为,可以通过构建动态的SQL片段来尝试接近这个目标。请注意,以下示例是概念性的,实际应用中可能需要根据具体需求调整,并且需要注意SQL注入风险和性能问题。
首先,假设你有一个Java实体类Employee,并且你的Mapper接口有一个方法接收List<Employee>类型参数。
Java Mapper Interface
public interface EmployeeMapper {
@Insert("<script>" +
"MERGE INTO employees e " +
"USING (" +
"<foreach item='item' collection='employees' separator=' UNION ALL '> " +
"SELECT #{item.empId} AS emp_id, #{item.empName} AS emp_name, #{item.department} AS department, #{item.joinDate} AS join_date FROM dual " +
"</foreach> " +
") new_records " +
"ON (e.emp_id = new_records.emp_id) " +
"WHEN MATCHED THEN " +
"UPDATE SET e.emp_name = new_records.emp_name, e.department = new_records.department, e.join_date = new_records.join_date " +
"WHEN NOT MATCHED THEN " +
"INSERT (emp_id, emp_name, department, join_date) " +
"VALUES (new_records.emp_id, new_records.emp_name, new_records.department, new_records.join_date)" +
"</script>")
void mergeEmployees(@Param("employees") List<Employee> employees);
}
注意事项
-
安全性与性能:这种方式虽然实现了动态生成
MERGE INTO语句,但是可能对数据库性能产生较大影响,特别是当传入的集合非常大时。实际应用中应考虑分批处理或直接使用数据库的批量操作能力。 -
SQL注入:MyBatis会自动处理参数绑定以防止SQL注入,但构建动态SQL时仍需小心处理。
-
数据库兼容性:请确保所使用的数据库(达梦8)支持
MERGE INTO语法,并且MyBatis配置正确以适应特定的数据库方言。 -
测试:由于这种方法较为特殊,强烈建议在实际部署前进行充分的测试,以验证其正确性和性能表现。
四、笔者简介
国内某一线知名软件公司企业认证在职员工:任JAVA高级研发工程师,大数据领域专家,数据库领域专家兼任高级DBA!10年软件开发经验!现任国内某大型软件公司大数据研发工程师、MySQL数据库DBA,软件架构师。直接参与设计国家级亿级别大数据项目!并维护真实企业级生产数据库300余个!紧急处理数据库生产事故上百起,挽回数据丢失所造成的灾难损失不计其数!并为某国家级大数据系统的技术方案(国家知识产权局颁布)专利权的第一专利发明人!


![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-14-主频和时钟配置](https://img-blog.csdnimg.cn/direct/bf7a1beff5b24b219d6877d398a2cb0a.png)