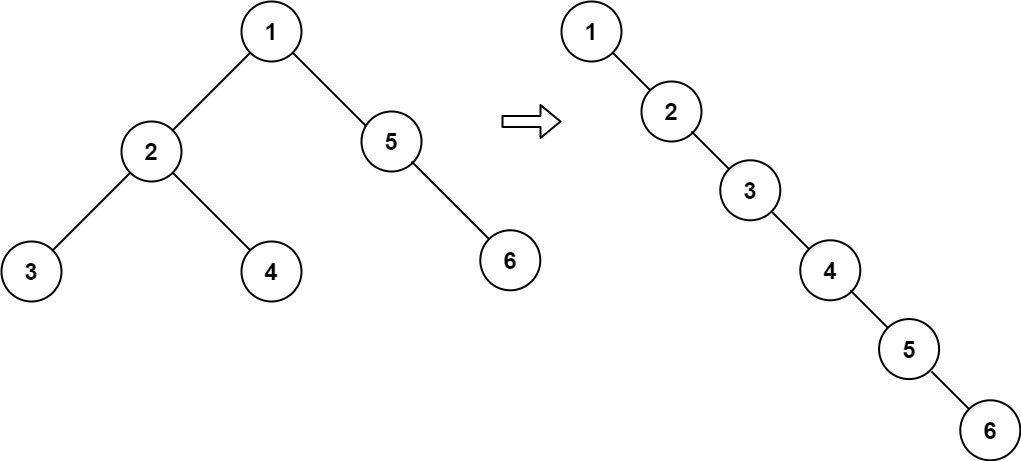
Patch & Window
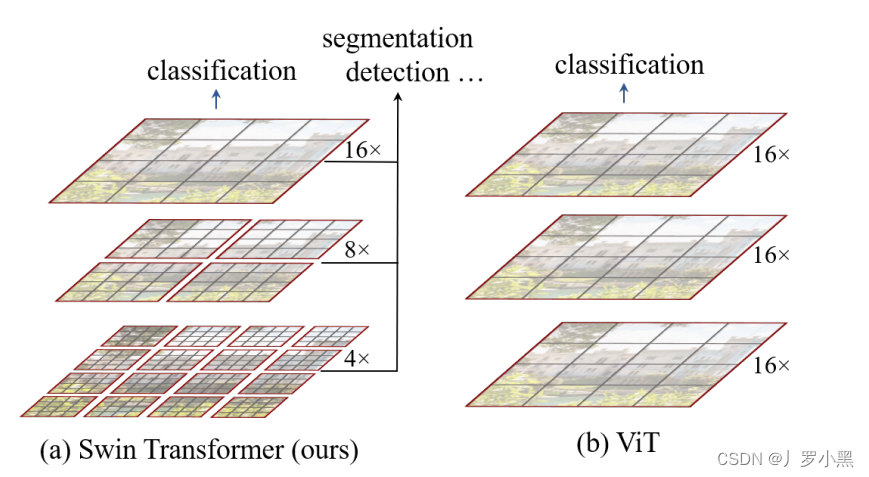
- 在Swin Transformer中,不同层级的窗口内部的补丁数量是固定的,补丁内部的像素数量也是固定的,如上图的红色框就是不同的窗口(Window),窗口内部的灰色框就是补丁(Patch)
- 如果输入图像的宽W、高H,增加到原来的两倍,那么输入图像的总面积(总像素数量)就增加到原来的四倍(2H * 2W = 4HW)
- 在ViT中,由于窗口是固定的,且就是整个输入图片,所以当我们将输入图片分割成很多个尺寸为16 * 16 的patch时,如果输入图像的总面积增加到原来的四倍,那么patch的数量也会变成原来的四倍,那么计算复杂度 O ( N 2 ⋅ d ) O( N^2 · d) O(N2⋅d),就变成了 O ( ( 4 N ) 2 ⋅ d ) = O ( 16 N 2 ⋅ d ) O( (4N)^2 · d) = O( 16N^2 · d) O((4N)2⋅d)=O(16N2⋅d),其中d是每个patch的维度,N是patch的数量。因此,对于ViT来说,计算复杂度是跟图像增加的大小成平方关系
- 在Swin Transformer中,由于窗口不是固定的,但是窗口内部的补丁数量是固定的,补丁的尺寸也是固定的,所以当我们将输入图片的总面积增加到原来的四倍,那么只有窗口的数量增加到原来的四倍,那么计算复杂度 O ( M 2 ⋅ N ⋅ d ) O( M^2 · N · d) O(M2⋅N⋅d),就变成了 O ( M 2 ⋅ 4 N ⋅ d ) O( M^2 · 4N · d) O(M2⋅4N⋅d),其中M是每个窗口内补丁的数量,N是窗口的数量,d是每个补丁patch的维度。(虽然每个patch的维度都不一样,这里先不管了)
Swin Transformer
Swin Transformer 提出ViT具有两个缺点:
1. 没有多尺度特征 ,不能像FPN那样,对于不同大小的物体都能进行良好感知
2. 全局计算自注意力浪费资源,并且计算复杂度跟图像增加的大小成平方关系
- 不同于ViT在整张输入图片上进行自注意力计算,Swin Transformer是在窗口内进行自注意力计算的,同时这个窗口又是包含固定数量的patch,每个patch的尺寸也是固定的。由于在图像领域中,同一个物体的不同部位、或语义相似的不同物体大概率会出现在相邻的地方,所以没必要像ViT那样–对整张图进行自注意力操作,其实可以借鉴CNN卷积的局部性的归纳偏置,在一个小的局部窗口内进行自注意力计算,也是差不多够用的
- 不同于ViT在每个Transformer Encoder Block上都是做相同尺寸的自注意力操作,得到的也是相同尺寸的特征,
![[qnx] 通过zcu104 SD卡更新qnx镜像的步骤](https://img-blog.csdnimg.cn/direct/c7eb82c8f7d84fc0ae73e83b0dee9ac0.png)







![[Flutter]创建一个私有包并使用](https://img-blog.csdnimg.cn/direct/8396ab73e6084503a899618ead7d0154.png)