文章目录
- ChatDoctor
- 目标
- 方法
- 结果
- 结论
- 收集和准备医患对话数据集
- 创建外部知识数据库
- 具有知识大脑的自主聊天医生的开发
- 模型培训
- 结果
- 数据和模型:
- 微调
- 推理
ChatDoctor
目标
这项研究的主要目的是通过创建一个在医学建议中具有更高准确性的专业语言模型,来解决在诸如ChatGPT等流行的大型语言模型(LLM)的医学知识中观察到的局限性。
方法
我们通过使用来自广泛使用的在线医疗咨询平台的100000个医患对话的大型数据集来调整和完善大型语言模型元人工智能(LLaMA)来实现这一点。为了尊重隐私问题,这些对话被清理并匿名。除了模型的改进,我们还引入了一种自主的信息检索机制,使模型能够访问和利用维基百科等在线来源的实时信息以及精心策划的离线医疗数据库的数据。
结果
将模型与真实世界的医患互动进行微调,显著提高了模型了解患者需求和提供知情建议的能力。通过为该模型配备从可靠的在线和离线来源进行的自主信息检索,我们观察到其响应的准确性有了显著提高。
结论
我们提出的ChatDoctor代表了医学LLM的重大进步,表明在理解患者询问和提供准确建议方面有了重大改进。鉴于医疗领域的高风险和低容错性,这种提供准确可靠信息的增强不仅有益,而且至关重要。
收集和准备医患对话数据集
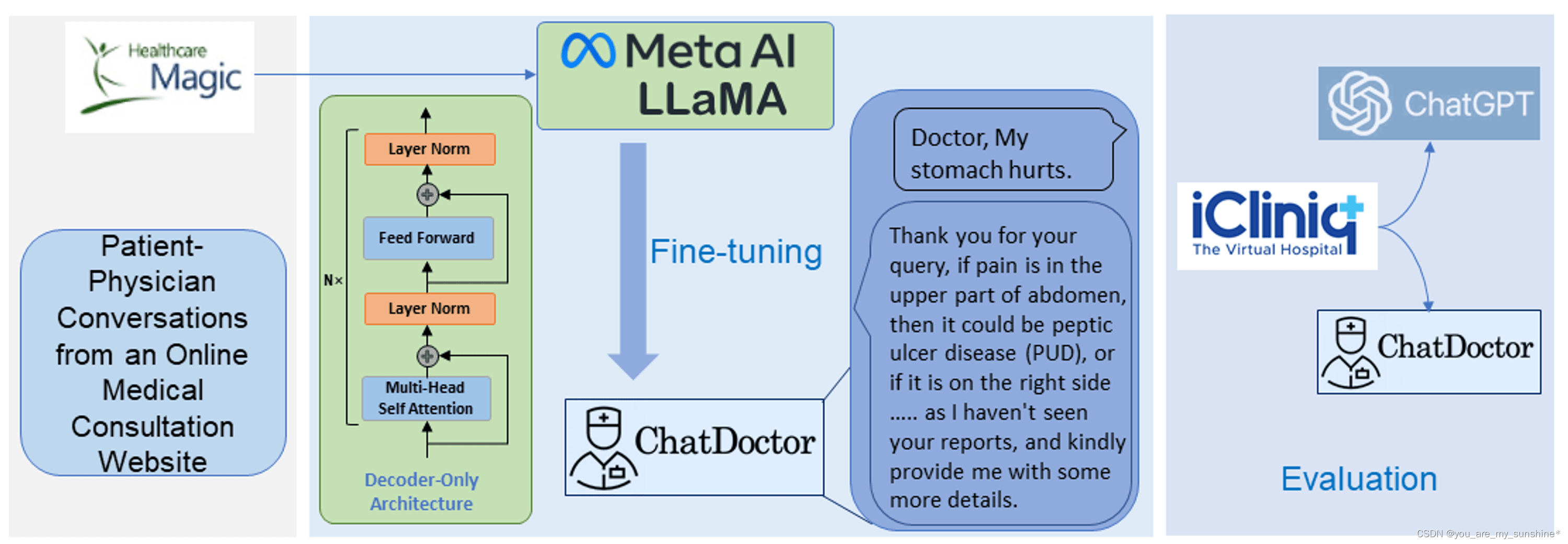
完善我们的模型的第一步涉及管理一个包括患者与医生互动的数据集。通常,患者用随意的、有点肤浅的语言描述自己的症状。如果我们试图像Alpaca一样综合生成这些对话,可能会导致过于具体的描述,其多样性和与现实世界的相关性有限。因此,我们选择收集真实的医患对话,从在线医疗咨询网站HealthCareMagic收集了约10万次此类互动。数据是手动和自动过滤的。具体来说,我们自动过滤掉了太短的对话,其中大多数都没有回答任何具有实际意义的问题。我们手动过滤了有错误的回复内容。为了维护隐私,我们删除了任何识别医生或患者的信息,并使用LanguageTool纠正任何语法错误。该数据集被标记为HealthCareMagic100k,如图1所示。我们还从另一个独立的在线医疗咨询网站iCliniq获得了大约1万次额外的对话,以测试我们模型的性能。iCliniq数据集是以分层方式随机选择的,以确保在各种医学专业中的代表性。还确保所选数据不包含可识别的患者信息,严格遵守隐私和道德标准。
创建外部知识数据库
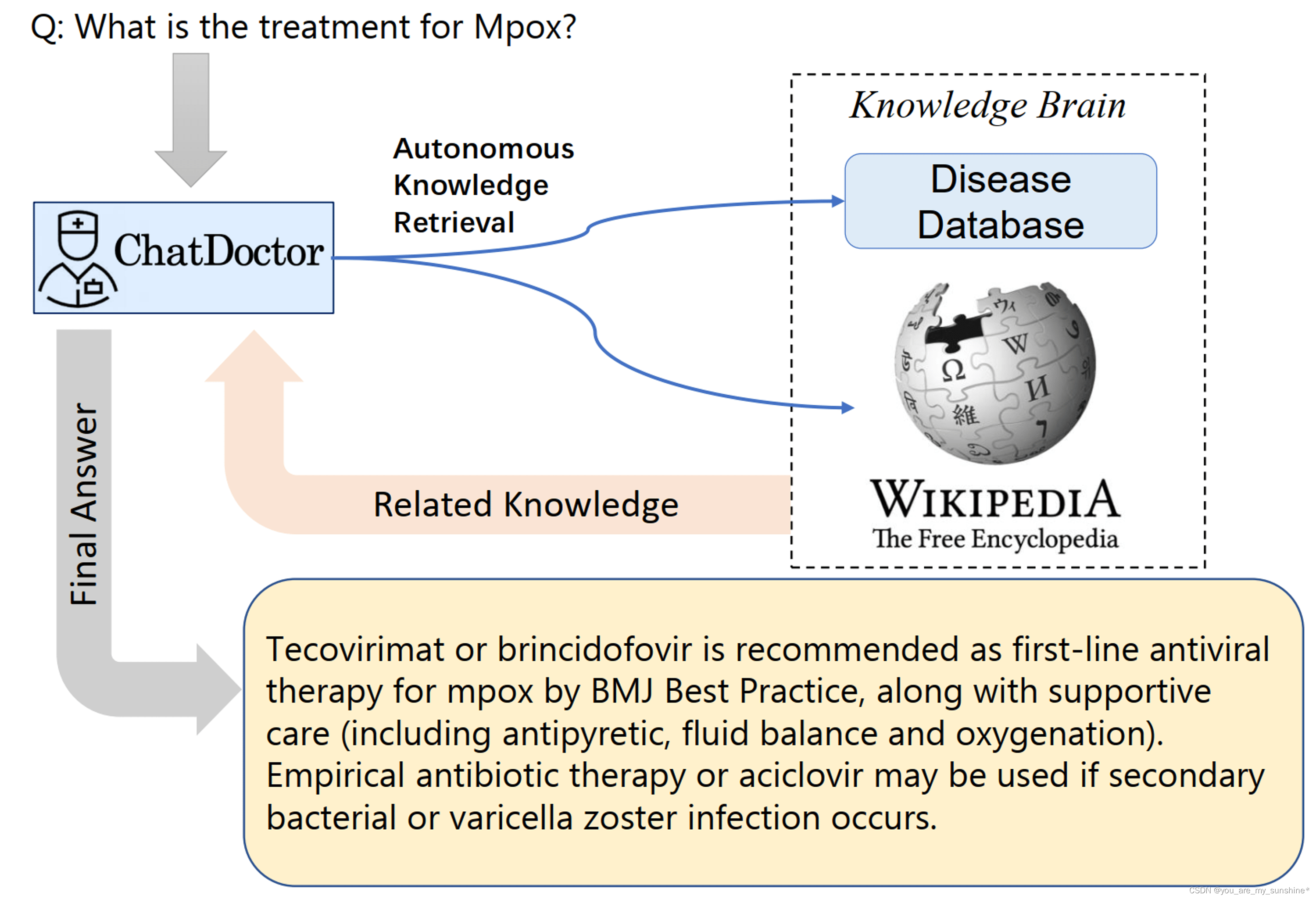
LLM通常预测序列中的下一个单词,导致对问题的潜在不准确或错误回答(幻觉)。此外,该模型的输出在一定程度上是不可预测的,这在医学领域是不可接受的。然而,如果这些模型能够基于可靠的知识数据库生成或评估响应,则其准确性可以显著提高,如下图一所示。因此,我们策划了一个数据库(如下图二所示),包括疾病、其症状、相关的医学测试/治疗程序和潜在的药物。该数据库是ChatDoctor的外部和离线知识大脑。该数据库可持续更新,无需模型再培训,可针对特定疾病或医学专业进行定制。我们利用MedlinePlus构建了这个疾病数据库,但也可以使用其他可靠的来源。此外,像维基百科这样的在线信息源可以补充我们自主模型的知识库。值得注意的是,维基百科可能不是一个完全可靠的数据库,但我们的框架可以很容易地扩展到更可靠的在线数据库,如声誉良好的学术期刊。

具有知识大脑的自主聊天医生的开发
借助外部知识大脑,即维基百科或我们的自定义疾病数据库,ChatDoctor可以通过检索可靠的信息来更准确地回答患者的询问。在建立外部知识大脑后,我们设计了一种机制,使ChatDoctor能够自主检索必要的信息来回答问题。这是通过构建适当的提示来输入ChatDoctor模型来实现的。具体来说,我们设计了关键词挖掘提示(下图一),作为ChatDoctor从患者查询中提取关键术语以进行相关知识搜索的初始步骤。基于这些关键词,使用术语匹配检索系统从知识大脑中检索排名靠前的信息。给定LLM的单词限制(标记大小),我们将要阅读的文本划分为相等的部分,并根据关键词点击次数对每个部分进行排名。然后,ChatDoctor模型依次读取前N个部分(在我们的研究中使用了五个),通过提示选择并总结相关信息(下图二)。最终,模型处理并编译所有知识条目,以生成最终响应(下图三)。这种信息检索方法确保患者收到有可靠来源支持的准确、知情的回复,并可作为ChatDoctor根据先前知识生成的回复的验证方法。



模型培训
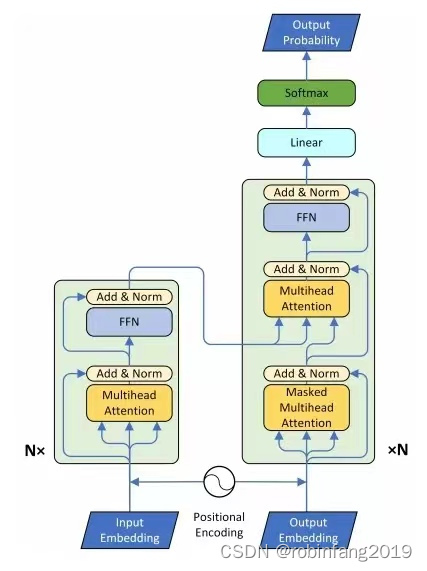
我们使用Meta的可公开访问的LLaMA-7B模型[14]开发了ChatDoctor模型,该模型仅使用具有解码器结构的Transformers。尽管LLaMA模型具有相对适中的70亿个参数,但在几个NLP基准中,其性能与更大的GPT-3模型(具有1750亿个参数)相当。这种性能增强是通过使训练数据多样化而不是增加网络参数来实现的。我们使用HealthCareMagic-100k的对话,根据Stanford Alpaca[5]的训练方法对LLaMA模型[15]进行了微调。该模型首先根据Alpaca的数据进行了微调,以获得基本的会话技能,然后在HealthCareMagic-100k上使用6*A100 GPU进行了三个小时的进一步改进。训练过程遵循这些超参数:总批量为192,学习率为2×10−5,3个时期,最大序列长度为512个令牌,预热比为0.03,没有权重衰减。
结果
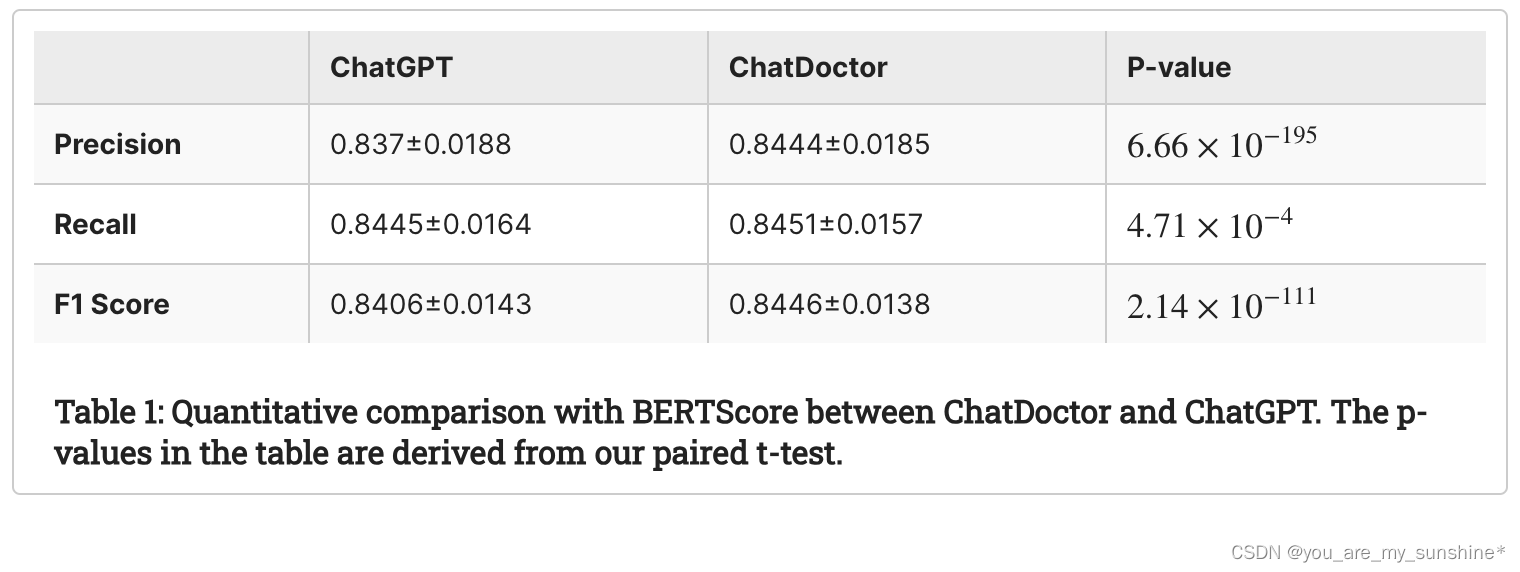
为了评估自主ChatDoctor模型的熟练程度,我们使用各种现代医学查询对其进行了测试。其中包括一个与“猴痘”(简称猴痘)有关的问题,如图7所示。猴痘最近于2022年11月28日被世界卫生组织(世界卫生组织)指定为猴痘,这使其成为一个相对新颖的术语。虽然ChatGPT无法提供令人满意的回应,但由于其自主知识检索功能,ChatDoctor能够从维基百科中提取有关猴痘的相关信息,并提供准确的答案。同样,如图8所示,对于更一般的医学查询,如“Otitis”,ChatDoctor能够在检索相关知识后提供可靠的响应。在另一个例子中,我们的模型在自主检索相关信息后,准确地解决了关于“Daybue”的问题,该药物于2023年3月获得了美国食品药品监督管理局的批准,证明了其优于ChatGPT,如图所示。

数据和模型:
1.聊天医生数据集:
您可以下载以下训练数据集
来自HealthCareMagic.com HealthCareMagic-100k的10万次患者和医生之间的真实对话。
来自icliniq.com icliniq-10k的患者和医生之间的10k真实对话。
5k生成了来自ChatGPT GenMedGPT-5k和疾病数据库的患者和医生之间的对话。
我们的模型首先根据Stanford Alpaca的数据进行了微调,使其具有一些基本的会话能力。羊驼链接
微调
下载项目地址
git clone https://github.com/Kent0n-Li/ChatDoctor.git
切换项目路径
cd ChatDoctor
切换chatdoctor环境
source activate
conda env list
conda activate chatdoctor
全量微调(官方版本)
torchrun --nproc_per_node=4 --master_port=<your_random_port> train.py \
--model_name_or_path <your_path_to_hf_converted_llama_ckpt_and_tokenizer> \
--data_path ./HealthCareMagic-100k.json \
--bf16 True \
--output_dir pretrained \
--num_train_epochs 1 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 2000 \
--save_total_limit 1 \
--learning_rate 2e-6 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LLaMADecoderLayer' \
--tf32 True
用lora微调(官方版本)
WORLD_SIZE=6 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5 torchrun --nproc_per_node=6 --master_port=4567 train_lora.py \
--base_model './weights-alpaca/' \
--data_path 'HealthCareMagic-100k.json' \
--output_dir './lora_models/' \
--batch_size 32 \
--micro_batch_size 4 \
--num_epochs 1 \
--learning_rate 3e-5 \
--cutoff_len 256 \
--val_set_size 120 \
--adapter_name lora
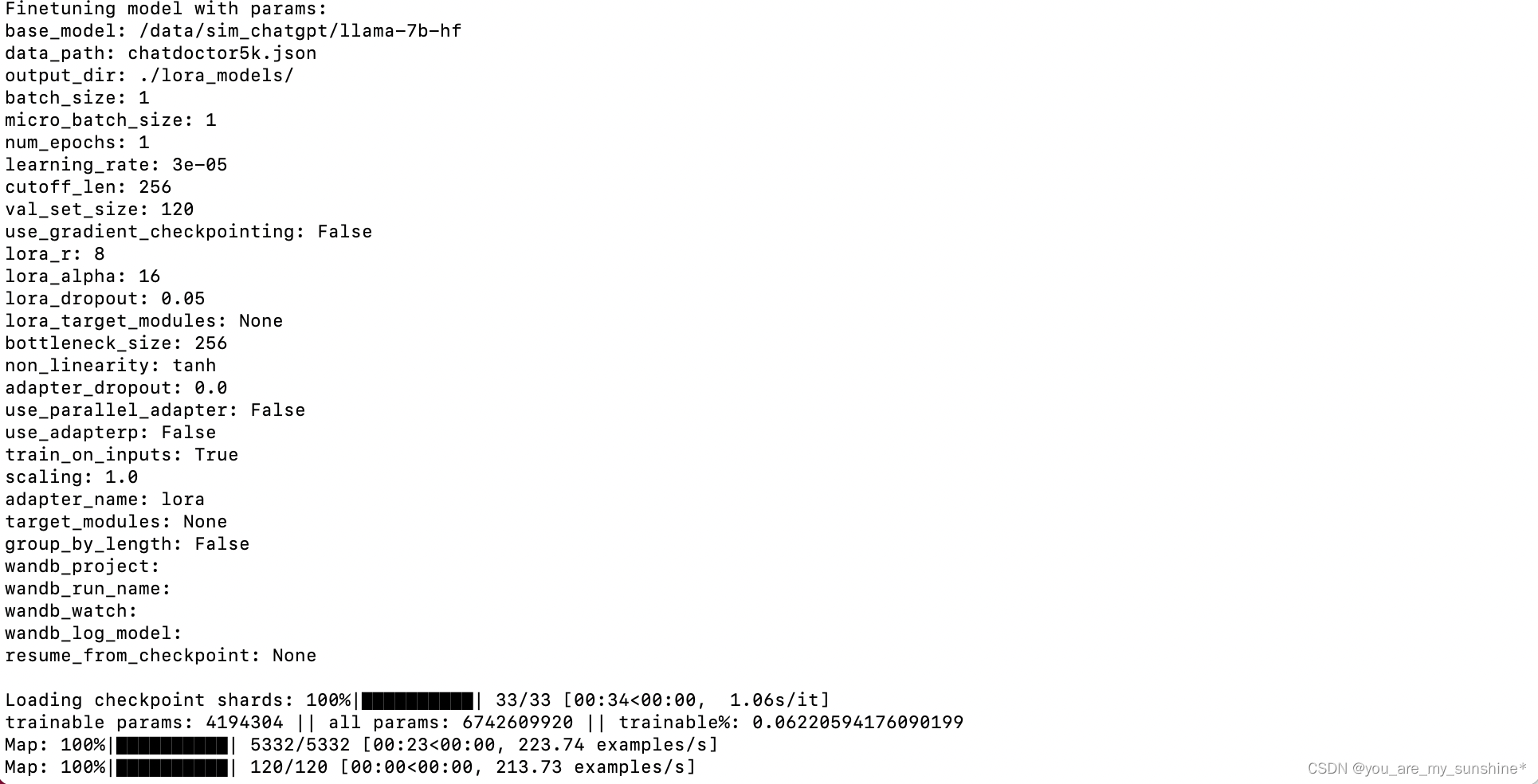
用lora微调(本项目实际运行版本)
nohup python train_lora.py \
--base_model '/data/sim_chatgpt/llama-7b-hf' \
--data_path 'chatdoctor5k.json' \
--output_dir './lora_models/' \
--batch_size 1 \
--micro_batch_size 1 \
--num_epochs 1 \
--learning_rate 3e-5 \
--cutoff_len 256 \
--val_set_size 120 \
--adapter_name lora \
>> log.out 2>&1 &
推理
修改chat.py
load_model("/data/sim_chatgpt/chatdoctor")
执行文件
python3 chat.py
在Patient处输入: Doctor, I have been experiencing sudden and frequent panic attacks. I don’t know what to do.
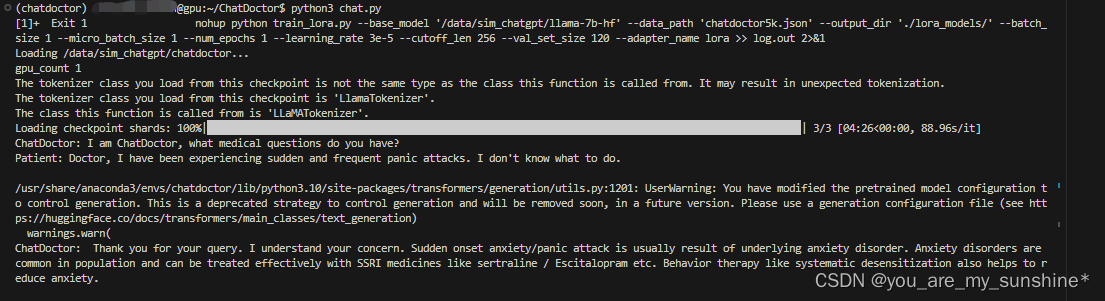
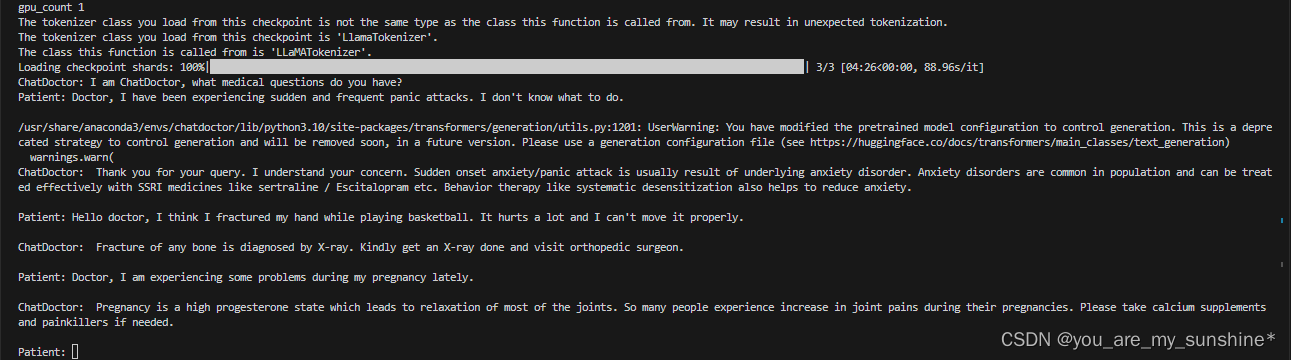
后面再接着问
若遇见该类错误:ImportError: LlamaConverter requires the protobuf library but it was
not found in your environment.
执行该代码操作试下即可解决
pip install protobuf==3.19.0
学习的参考资料:
ChatDoctor项目地址
ChatDoctor: A Medical Chat Model Fine-Tuned on a Large Language Model Meta-AI (LLaMA) Using Medical Domain Knowledge
ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge
基于医疗领域数据微调LLaMA——ChatDoctor模型
![[Flutter]创建一个私有包并使用](https://img-blog.csdnimg.cn/direct/8396ab73e6084503a899618ead7d0154.png)



![[信息收集]-端口扫描--Nmap](https://img-blog.csdnimg.cn/direct/3020b6f437344220a36a8eadd11a5258.png)


![[leetcode] 63. 不同路径 II](https://img-blog.csdnimg.cn/direct/a36c1b59f2eb48eebd27dc7ba26116ca.png)