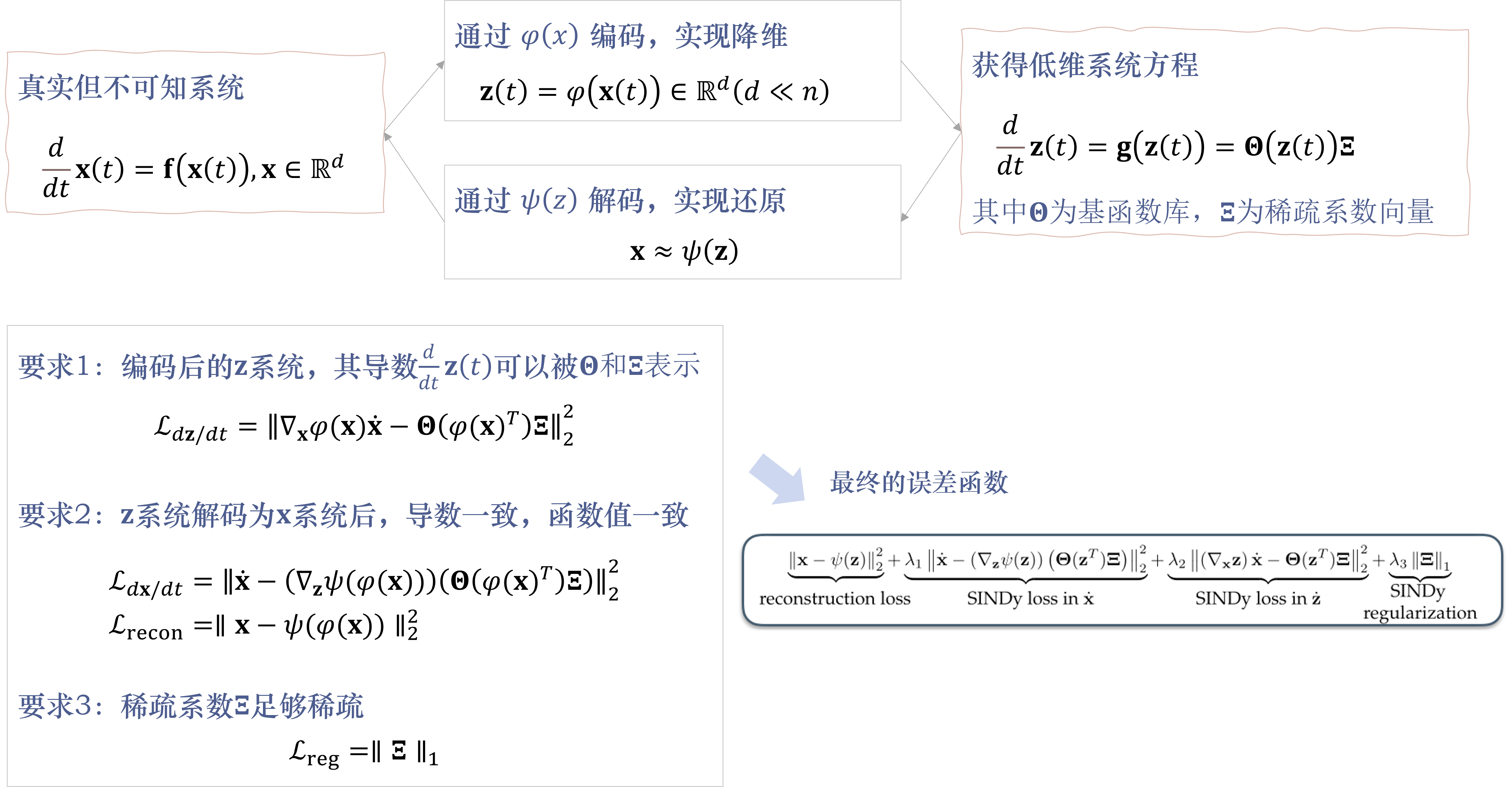
前言
这次的有一点点难~~~~~我也写了好久
练习题
题目一
在学生表pub.student中统计名字(姓名的第一位是姓氏,其余为名字,不考虑复姓)的使用的频率,将统计结果放入表test5_01中
create table test5_01(
First_name varchar(4),
frequency numeric(4)
)insert into test5_01(
select substr(name,2),count(*)
from pub.student
group by substr(name,2)
)关键点:
1、substr(‘name’,start_position,[length]):name表示列名;start_positon表示开始位置(不同于其他语言,SQL的下标从1开始);length表示长度(可写可不写,不写表示取到最后)
2、insert into table_name values():单行具体量插入
3、insert all
into table_name values()
into table_name values()
select * from dual:多行具体量插入
4、insert into table_name(
select 选择语句
):select实现批量插入操作
题目二
在学生表pub.student中统计名字(姓名的第一位是姓氏,不作统计,名字指姓名的第二个之后的汉字)的每个字使用的频率,将统计结果放入表test5_02中,表结构如下。
create table test5_02(
letter varchar(4),
frequency numeric(4)
)insert into test5_02(
select letter,count(*)
from(
(
select substr(name,2,1) letter
from pub.student
)
union all
(
select substr(name,3,1) letter
from pub.student
where substr(name,3,1) is not null
)
)
group by letter
)关键点:
1、第三个字有可能为空(有的人名字两个字),防止取出NULL,需要用where进行筛选
2、union all:保留所有的记录
union:删除重复的记录
题目三(难题)
先创建“学院班级学分达标情况统计表1”test5_03,依据pub.student, pub.course,pub.student_course统计形成表中各项数据,成绩>=60为及格计入学分,总学分>=10算作达标,院系为空值的数据不统计在下表中,表结构:院系名称dname、班级class、学分达标人数p_count1、学分未达标人数p_count2、总人数p_count。
创建表格
create table test5_03
(
dname varchar2(30),
class varchar(10),
p_count1 int,
p_count2 int,
p_count int
)
更新dname,class,以及总人数:
insert into test5_03(dname,class,p_count)(
select dname,class,count(sid)
from pub.student
where dname is not null
group by dname,class
)更新学分达标人数p_count1
update test5_03 t
set p_count1=(
select count(sid)
from(
select S.sid,S.dname,S.class
from pub.student S,pub.course C,(
SELECT sid, cid, MAX(score) AS max_score
FROM pub.student_course
GROUP BY sid, cid
) SC
where S.sid = SC.sid and C.cid=SC.cid and SC.max_score >= 60
group by S.sid,S.dname,S.class
having sum(C.credit)>=10
)a
where t.dname=a.dname
and t.class=a.class
)更新学分未达标人数p_count2
update test5_03 t
set p_count2=(
select count(sid)
from(
(
select S.dname,S.class,S.sid
from pub.student S,pub.course C,(
SELECT sid, cid, MAX(score) AS max_score
FROM pub.student_course
GROUP BY sid, cid
) SC
where SC.sid=S.sid
and SC.cid=C.cid
and SC.max_score>=60
group by S.dname,S.class,S.sid
having sum(C.credit)<10
)
union
(
select dname,class,sid
from pub.student
where sid not in(
select sid
from pub.student_course
)
)
)a
where t.dname=a.dname
and t.class=a.class
)
关键点:
1、统计学分达标人数和未达标人数的答题思路是相似的。可以将这个问题进行分解:
- 统计人数,所以要select count(sid)
- 统计达标的人数,所以from里面的表格一定都是已经达标的,也就是要筛选出达标的人
- 达标也就是学分大于10,统计学分可以对选课表格按每个学院每个年级每个人进行分组,然后再统计sum(credit)
- 要注意这个选课表格分组前也需要筛选出分数大于60的课
2、利用自然连接时,要注意大集合连接小集合会导致部分数据缺失。我们要考虑我们需要的from数据是大集合中的还是小集合中的,如上题:
- 统计未达标人数时,因为前面的筛选、更新操作是在student_course自然连接student表格中进行的,所以如果有学生没有选课的话,就不会出现在筛选结果中。而学分未达标人数中需要包括这些没有选课的同学,所以在from中需要用union对集合进行合并增加
3、is只适用于null前面:is null;is not null.
in和not in适用于select前面
4、用insert进行插入时,如果插入内容select的列数与表格数目不相同,那么一定要在插入时明确插入到哪些列
5、更新p_count1、2时where语句在set语句内,因为要保证一个数值位对应一个数值
6、考虑到有的学生存在同一门课程参与多次考试的情况,并且每一次考试都大于60,那么此时在筛选60分以上成绩后该学生仍然有多次成绩,直接sum(credit)会导致学分重复计算。这要求我们要对重复成绩进行删除,删除方法有:1、select distinct;2、利用sid、cid分组后选出max(score),并用这个结果作为新的from内的关系(from中可以用select结果作为新关系)
题目四
创建“学院班级学分达标情况统计表2”test5_04,依据pub.student, pub.course,pub.student_course统计形成表中各项数据,成绩>=60为及格计入学分,2008级及之前的班级总学分>=8算作达标,2008级之后的班级学分>=10算作达标,院系为空值的数据不统计在下表中,表结构:院系名称dname、班级class、学分达标人数p_count1、学分未达标人数p_count2、总人数p_count。
创建表
create table test5_04
(
dname varchar2(30),
class varchar(10),
p_count1 int,
p_count2 int,
p_count int
)关键点:
1、直接create后面不需要as,可以直接写创建的表的结构
2、create as后面接select操作来实现对表格结构、表格源数据的复制
3、create like后面跟 table_name 可以复制表格结构
4、oracle中不能用like
更新p_count1
update test5_04 t set p_count1 =
(select count(sid)
from
(
(select S.sid,S.dname,S.class
from pub.student S,pub.course C,(
SELECT sid, cid, MAX(score) AS max_score
FROM pub.student_course
GROUP BY sid, cid
) SC
where S.sid = SC.sid and C.cid=SC.cid and SC.max_score >= 60 and S.class > 2008
group by S.sid,S.dname,S.class
having sum(C.credit) >= 10)
union
(select S.sid,S.dname,S.class
from pub.student S,pub.course C,(
SELECT sid, cid, MAX(score) AS max_score
FROM pub.student_course
GROUP BY sid, cid
) SC
where S.sid = SC.sid and C.cid=SC.cid and SC.max_score >= 60 and S.class <= 2008
group by S.sid,S.dname,S.class
having sum(C.credit) >= 8)
) temp
where t.dname = temp.dname and t.class = temp.class)更新p_count2
update test5_04 t set p_count2 =
(
select count(sid)
from
(
(select S.sid,S.dname,S.class
from pub.student S,pub.course C,(
SELECT sid, cid, MAX(score) AS max_score
FROM pub.student_course
GROUP BY sid, cid
) SC
where S.sid = SC.sid and C.cid=SC.cid and SC.max_score >= 60 and S.class > 2008
group by S.sid,S.dname,S.class
having sum(C.credit) < 10)
union
(select S.sid,S.dname,S.class
from pub.student S,pub.course C,(
SELECT sid, cid, MAX(score) AS max_score
FROM pub.student_course
GROUP BY sid, cid
) SC
where S.sid = SC.sid and C.cid=SC.cid and SC.max_score >= 60 and S.class <= 2008
group by S.sid,S.dname,S.class
having sum(C.credit) < 8)
union
(
select sid,dname,class
from pub.student
where sid
not in
(
select sid
from pub.student_course
)
)
) temp
where t.dname = temp.dname and t.class = temp.class)关键点:
1、本题思路和前一题是完全相同的,就是增加更新条件,重复更新几次
题目五
查询各院系(不包括院系名称为空的)的数据结构平均成绩avg_ds_score、操作系统平均成绩avg_os_score,平均成绩四舍五入到个位,创建表test5_05
create view test5_05 as (
select *
from
(
select S.dname,round(avg(SC.max_score)) avg_ds_score
from pub.student S,pub.course C,(
select sid,cid,max(score) max_score
from pub.student_course
group by sid,cid
)SC
where S.sid=SC.sid and C.cid=SC.cid and C.name='数据结构' and S.dname is not null
group by S.dname
)
natural full outer join
(
select S.dname,round(avg(SC.max_score)) avg_os_score
from pub.student S,pub.course C,(
select sid,cid,max(score) max_score
from pub.student_course
group by sid,cid
)SC
where S.sid=SC.sid and C.cid=SC.cid and C.name='操作系统' and S.dname is not null
group by S.dname
)
)关键点:
1、实验要求创建视图而不是创建临时表 。很多时候在软件开发中我们都是创建一个视图对临时变量进行处理,因为这样不占用内存空间
2、对视图的处理一般只能是select,因为视图是基本表的复制品而不是表格本身。对视图进行insert和updata没有什么意义
3、两个select结果进行自然全外连接从而完成匹配
4、按照dname分组前需要筛选dname不为空
题目六
查询”计算机科学与技术学院”的同时选修了数据结构、操作系统两门课的学生的学号sid、姓名name、院系名称dname、数据结构成绩ds_score、操作系统成绩os_score,创建表test5_06
create view test5_06 as (
select *
from
(
select S.sid,S.name,S.dname,SC.max_score ds_score
from pub.student S,pub.course C,(
select sid,cid,max(score) max_score
from pub.student_course
group by sid,cid
)SC
where S.sid=SC.sid and C.cid=SC.cid and S.dname='计算机科学与技术学院' and C.name='数据结构' and S.sid in(
(
select sid
from pub.student_course SC,pub.course C
where C.cid=SC.cid and C.name='数据结构'
)
intersect
(
select sid
from pub.student_course SC,pub.course C
where C.cid=SC.cid and C.name='操作系统'
)
)
)
natural full outer join
(
select S.sid,S.name,S.dname,SC.max_score os_score
from pub.student S,pub.course C,(
select sid,cid,max(score) max_score
from pub.student_course
group by sid,cid
)SC
where S.sid=SC.sid and C.cid=SC.cid and S.dname='计算机科学与技术学院' and C.name='操作系统' and S.sid in(
(
select sid
from pub.student_course SC,pub.course C
where C.cid=SC.cid and C.name='数据结构'
)
intersect
(
select sid
from pub.student_course SC,pub.course C
where C.cid=SC.cid and C.name='操作系统'
)
)
)
)关键点:
1、select选数据结构、选操作系统的学生sid结果取交集成一个新关系。让参与平均分计算的学生sid在这个关系中
题目七
查询计算机科学与技术学院的选修了数据结构或者操作系统的学生的学号sid、姓名name、院系名称dname、数据结构成绩ds_score、操作系统成绩os_score,创建表test5_07
create view test5_07 as (
select *
from
(
select S.sid,S.name,S.dname,SC.max_score ds_score
from pub.student S,pub.course C,(
select sid,cid,max(score) max_score
from pub.student_course
group by sid,cid
)SC
where S.sid=SC.sid and C.cid=SC.cid and S.dname='计算机科学与技术学院' and C.name='数据结构' and S.sid in(
(
select sid
from pub.student_course SC,pub.course C
where C.cid=SC.cid and C.name='数据结构'
)
union
(
select sid
from pub.student_course SC,pub.course C
where C.cid=SC.cid and C.name='操作系统'
)
)
)
natural full outer join
(
select S.sid,S.name,S.dname,SC.max_score os_score
from pub.student S,pub.course C,(
select sid,cid,max(score) max_score
from pub.student_course
group by sid,cid
)SC
where S.sid=SC.sid and C.cid=SC.cid and S.dname='计算机科学与技术学院' and C.name='操作系统' and S.sid in(
(
select sid
from pub.student_course SC,pub.course C
where C.cid=SC.cid and C.name='数据结构'
)
union
(
select sid
from pub.student_course SC,pub.course C
where C.cid=SC.cid and C.name='操作系统'
)
)
)
)关键点:
1、整体思路和上题完全相同,仅仅是将intersect改为union
2、集合交:intersect
集合并: union
集合差:minus
题目八
查询计算机科学与技术学院所有学生的学号sid、姓名name、院系名称dname、数据结构成绩ds_score、操作系统成绩os_score,创建表test5_08,表结构及格式如下
create view test5_08 as (
select *
from
(
select S.sid,S.name,S.dname,SC.max_score ds_score
from pub.student S,pub.course C,(
select sid,cid,max(score) max_score
from pub.student_course
group by sid,cid
)SC
where S.sid=SC.sid and C.cid=SC.cid and S.dname='计算机科学与技术学院' and C.name='数据结构'
)
natural full outer join
(
select S.sid,S.name,S.dname,SC.max_score os_score
from pub.student S,pub.course C,(
select sid,cid,max(score) max_score
from pub.student_course
group by sid,cid
)SC
where S.sid=SC.sid and C.cid=SC.cid and S.dname='计算机科学与技术学院' and C.name='操作系统'
)
natural full outer join
(
select S.sid,S.name,S.dname
from pub.student S
where S.dname = '计算机科学与技术学院' and S.sid not in (select S.sid from pub.student S,pub.course C,pub.student_course SC where S.sid = SC.sid and C.cid = SC.cid and (C.name = '数据结构' or C.name = '操作系统'))
)
)关键点:
1、自然全外连接解决了只考了其中一门课学生的情况。但如果一个计算机科学与技术学院的学生没有考这两门课,那么他将不在自然全外连接的关系结果中。所以需要加上这一部分的学生
2、这里用来全新的思路来处理两门课中选一门的学生这个问题。在上一题中采用两个select取并集,本题中直接select语句中的where里面采用c.name用or连接(这个处理方式不能在同时选两门课中使用,同时选两门课仍然要用集合取并而不是and来处理!!)
题目九
创建“成绩及格学生每个成绩人数百分比统计表” 视图test5_09,依据pub.student_course统计形成视图中各项数据,成绩>=60为及格,视图结构:成绩score、对应成绩人数count1、及格总人数count0、站总人数的百分比percentage(即前面两列相除后乘以100)。其中百分比四舍五入到小数点后面2位。输出按成绩排序。上面说的“人数”理解成 “人次”更加准确,亦既一个同学同一门考试考两次,算两人次。视图如下:
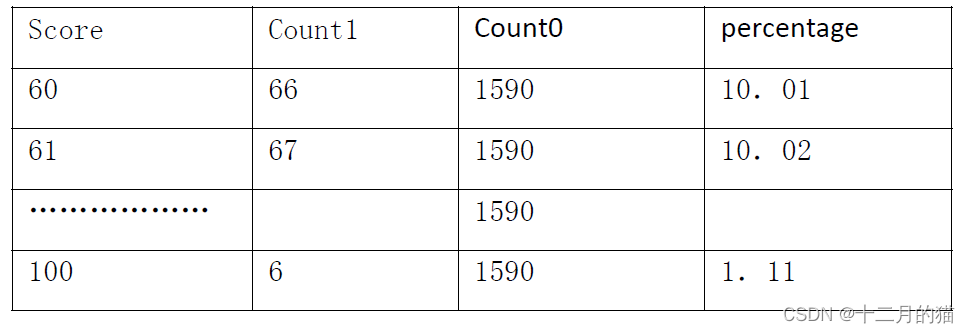
create view test5_09 as
with temp as(
select SC.sid,SC.score
from pub.student_course SC
where SC.score>=60
)
select temp.score,count(sid) count1,
(select count(sid) from temp) count0,
(round(count(sid)/(select count(sid) from temp),4)*100) percentage
from temp
group by score关键点:
1、考虑到后面的查询都不能直接用pub.student_course进行,而是需要利用筛选后的这个表格。所以在select之前统一对pub.student_course进行筛选处理并创建新的临时表格
2、group by后的select有限制,只能是:a.group by的列 b.聚集函数 c.常数。
看这个select后面的对象,前两个score,count1自然对应a和b没有问题。
关键在于:count0和percentage为什么可以
3、count0:count0在这里是一个子查询,是对外表进行一个count统计,所以对于外部这个select来说,它眼中的count0就是一个确定的数,所以是常数。并且select会自动按照前面查询的行数去对这个常数进行复制填充
4、percentage:分为两个部分:前面是count(sid)对于select来说是一个聚集函数没有问题;后面是一个和3一样的子查询,结果是常数,对于外部select来说依旧没有问题,所以是符合语法要求的
5、在 percentage中前面是count(sid),所以对于每一个percentage行来说不用考虑和前面select对象行匹配的问题
题目十
创建“每个课程成绩在60-99分之间每段成绩的人数百分比统计表”视图test5_10,依据pub.course,pub.student_course统计形成视图中各项数据,仅仅统计成绩在60-99(包含60和99)之间成绩,视图结构:课程编号cid、课程名称cname、成绩score(这个列内容不要包含空格)、对应成绩人数count1、及格总人数count0(仅统计60-99分)、站总人数的百分比percentage(即前面两列相除后乘以100)。其中百分比四舍五入到小数点后面2位。输出按课程编号、成绩排序。上面说的“人数”理解成 “人次”更加准确,亦既一个同学同一门考试考两次,算两人次。
create or replace view test5_10 as
with temp as (
select score, sid, cid
from pub.student_course
where score >= 60 and score <= 149
)
select
sc.cid,
c.name as cname,
to_char(trunc(sc.score, -1), 'fm000') || '-' || to_char(trunc(sc.score, -1) + 9, 'fm000') as score,
count(*) as count1,
(select count(*)
from temp
where temp.cid = sc.cid) as count0,
(round(count(sid)/(select count(*)
from temp
where temp.cid = sc.cid),4)*100) as percentage
from
pub.course c,
temp sc
where
c.cid = sc.cid
group by
sc.cid,
c.name,
to_char(trunc(sc.score, -1), 'fm000') || '-' || to_char(trunc(sc.score, -1) + 9, 'fm000');
关键点:
1、 trunc(sc.score, -1):把score中的数向下处理为10的倍数(例如38——30,24——20)
2、to_char(......, 'fm000'):将前面.....的内容转为char类型并且改为3位数的输出(例如38——038)
3、select后面可以跟表达式,group by后面也可以跟表达式
下面是我一开始写的错误例子(改了好久。。。。。):
create or replace view test5_10 as
with temp as
(select score,sid,cid from pub.student_course where score>=60 and score<=149)
select cid,C.name cname,
to_char(trunc(score,-1),'fm000')||'-'||to_char(trunc(score,-1)+9,'fm000') Score,
count(*)count1,
(select count(*) from temp group by cid ) count0 //这行有问题
from pub.course C,temp SC
where C.cid=SC.cid
group by SC.cid,C.name,
to_char(trunc(score,-1),'fm000')||'-'||to_char(trunc(score,-1)+9,'fm000') Score这一行的问题在于cid聚集后count(*)得到的行数和外部select是不同的,此时sql就不知道要如何处理两者的匹配问题,就会报语法错误
总结
本文的所有题目均来自《数据库系统概念》(黑宝书)、山东大学数据库实验五。不可用于商业用途转发。
如果能帮助到大家,大家可以点点赞、收收藏呀~






![[Flutter]创建一个私有包并使用](https://img-blog.csdnimg.cn/direct/8396ab73e6084503a899618ead7d0154.png)



![[信息收集]-端口扫描--Nmap](https://img-blog.csdnimg.cn/direct/3020b6f437344220a36a8eadd11a5258.png)