论文:Self-Knowledge Guided Retrieval Augmentation for Large Language Models
⭐⭐⭐⭐
Tsinghua, arXiv:2310.05002
文章目录
- 一、论文速读
- 二、实现细节
- 2.1 数据的收集
- 2.2 引出 LLM 的 Self-Knowledge 的方法
- 1)Direct Prompting
- 2)In-Context Learning
- 3)Training a Classifier
- 4)KNN(k-nearest-neighbor)
- 三、实验结果及分析
一、论文速读
传统 RAG 的思路是引入外部知识来增强 LLM 的生成,但是现在的研究发现,有时候引入检索到的文档反而会给 LLM 的生成产生消极影响。
为了更好利用 LLM 的内部参数化知识和外部世界知识,我们需要激发模型识别自己知道还是不知道的能力,也被称为 self-knowledge。因此,本工作提出了 SKR(Self-Knowledge guided Retrieval augmentation):当 LLM 面对一个 user query,先识别出 LLM 知不知道这个问题,如果知道的话就直接让 LLM 回复,如果不知道的话就调用 retriever 进行检索。
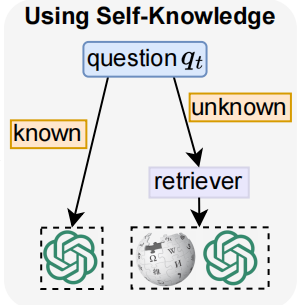
二、实现细节
该工作在 QA 的场景下做的研究,首先收集了一批研究数据,然后提出了四个方法来激发 LLM 的 Self-Knowledge 的能力。
2.1 数据的收集
对于已有的 QA 数据集,我们希望把其中的所有 question 分成两类:LLM "知道"的和"不知道"的,即 D + D^+ D+ 和 D − D^- D−。
给定一个 question q i q_i qi,我们先直接把它输入给 LLM 得到 answer α ( q i ) \alpha(q_i) α(qi),然后再把它调用 retriever 后以 RAG 的形式输入给 LLM 得到 answer α R ( q i ) \alpha^R(q_i) αR(qi),然后我们拿 ground-truth answer 来衡量两种方式得到的 LLM answer:
- 如果 α ( q i ) \alpha(q_i) α(qi) 和 α R ( q i ) \alpha^R(q_i) αR(qi) 都不正确,直接丢弃 question q i q_i qi
- 如果 E [ α ( q i ) ] ≥ E [ α R ( q i ) ] E[\alpha(q_i)] \ge E[\alpha^R(q_i)] E[α(qi)]≥E[αR(qi)],那就把 question 归为 D + D^+ D+
- 反之则归为 D − D^- D−
其中 E [ ⋅ ] E[\cdot] E[⋅] 是一个 evaluation metric,比如 accuracy。
2.2 引出 LLM 的 Self-Knowledge 的方法
论文提出了四种方法:direct prompting、in-context learning、classifier、KNN,下面分别介绍一下。
1)Direct Prompting
也就是设计 prompt template 然后填充 question 后,直接问 LLM 是否需要额外信息来辅助生成。prompt template 如下:

2)In-Context Learning
基于前面的 direct prompting,首先给 LLM 几个示例,教会它输出 Yes 或者 No,然后再问他是否需要更多信息来辅助增强,如下图所示:

3)Training a Classifier
使用之前的数据集,基于 BERT-base 训练一个二分类的 classifier,从而决定一个 question 要不要进行检索。
4)KNN(k-nearest-neighbor)
这里基于一个 motivation:如果两个 question 在语义嵌入空间中相近,那么 LLM 会倾向于对两个 question 展示出相似的 self-knowledge。
于是,可以使用一个 pre-trained fixed encoder 来对 question 做 KNN 从而推断出它的 label。
三、实验结果及分析
论文在 5 个 QA 数据集上进行了实验,最终,KNN 的方法在 5 个数据集上平均表现最好,而 direct prompting 的方法则表现较差。
论文还发现,无论是内部知识还是外部知识,都存在自己的限制:
- 像 CoT 这样利用 LLM 内部知识的方法,并不总是能有效提升效果
- 检索文档这样的利用外部知识的方法,也不总是有用的,有时甚至会让模型表现更差
论文还做了如下的分析:
- 不同 template 的 self-knowledge 影响:发现所有设计的模板,都可以让 LLM 表达出自己的响应。论文发现,LLM 对于自己认为可以回答的问题,准确率可以达到 70%~73%,这也表明仍有 30% 的问题,模型是不知道自己“不知道”的。
- 不同数据集的 self-knowledge 影响:发现不同的方法在不同的数据集上会有一定的差距,这可能与数据集的问题有关。
- 训练数据大小的影响:随着训练数据的增加,性能逐渐提高,这说明从训练数据中收集的 self-knowledge 是有价值的。
- 不同知识源的影响:整体来看,Wikipedia 作为外部知识源可以让 LLM 表现更好。