简介
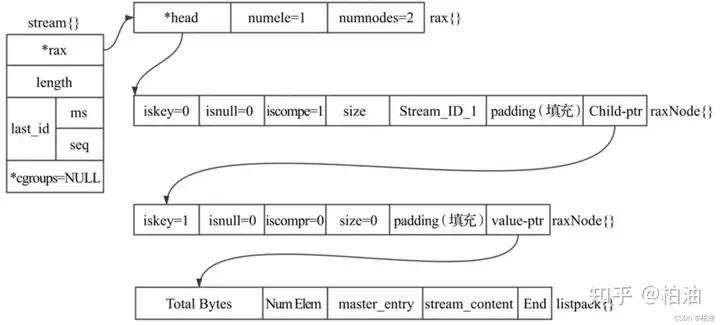
stream 作为消息队列,支持多次消费,重复消费,ack机制,消息异常处理机制。
涉及到以下几个概念,消息流,消费者组,消费者。
涉及到以下命令
# 添加消息到流中
XADD key [NOMKSTREAM] [<MAXLEN | MINID> [= | ~] threshold [LIMIT count]] <* | id> field value [field value ...]
# 创建消费则组(加上MKSTREAM,会校验消息流是否存在,不存在会创建)
XGROUP CREATE key group <id | $> [MKSTREAM] [ENTRIESREAD entries-read]
# 消费者读取消息
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] id [id ...]
1. 环境
redis server 7.2.2
> info server
# Server
redis_version:7.2.2
redis可视化工具(可以直接使用命令行) redisInsight 2.44.0
2. 生产消费流程测试
消息队列,涉及到如下几个流程
- 发送消息到消息流
- 创建消费者组,并进行消费
- 正常消费,消息确认 ack
- 异常消费,转移消息的归属权 claim
2.1 发送消息到消息流
使用如下命令发送消息
XADD key [NOMKSTREAM] [<MAXLEN | MINID> [= | ~] threshold [LIMIT count]] <* | id> field value [field value ...]
各参数说明
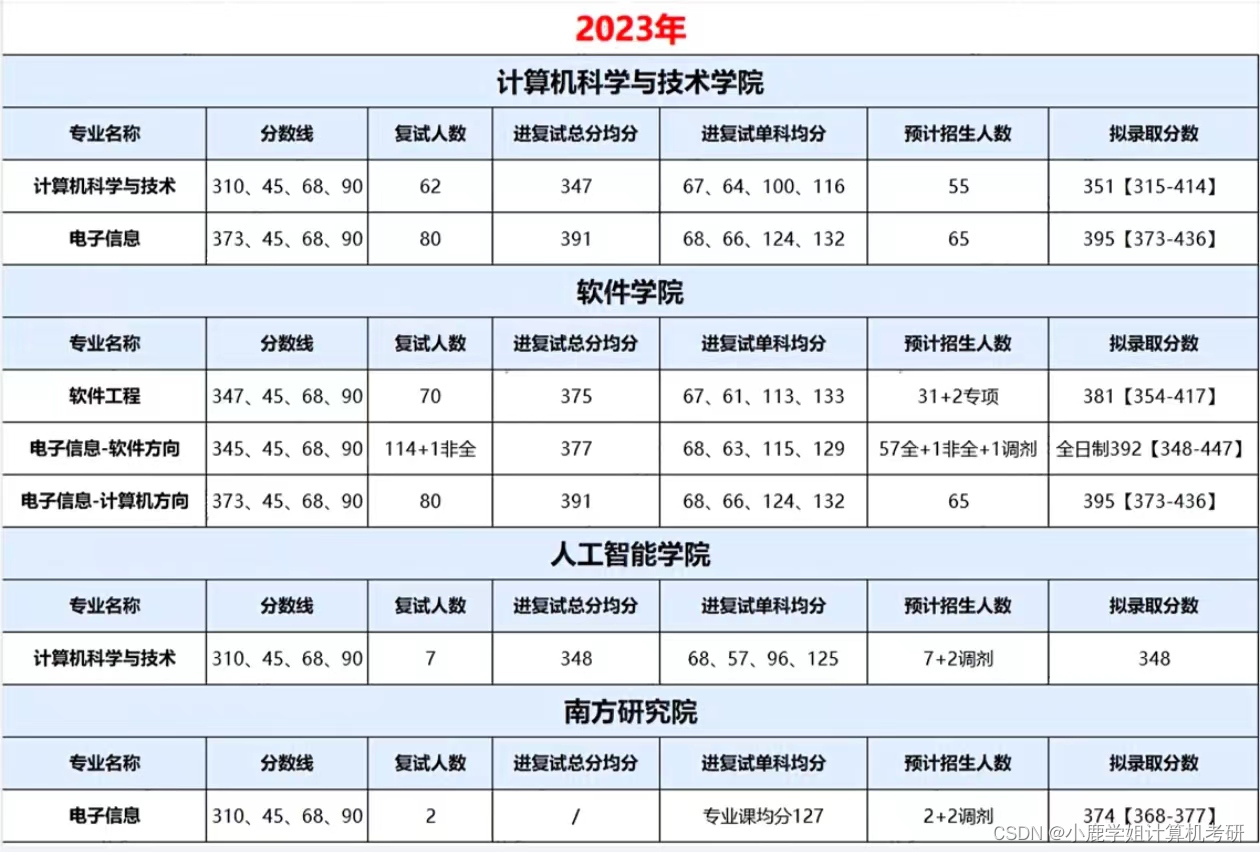
| 参数名 | 说明 |
|---|---|
| NOMKSTREAM | 默认情况下,如果消息流不存在,则会创建消息流。 使用该参数,则不会创建,如果不存在则返回 (nil) |
| [<MAXLEN | MINID> [= | ~] threshold [LIMIT count]] | 等同于 xtrim 的参数,在添加消息后,会对 stream 裁剪,将先加入的消息剔除。 MAXLEN 表示stream长度不大于 threshold,MINID 表示stream的消息id不小于 threshold; = 表示精确删除 ~ 表示近似删除; threshold 表示长度或者id; limit count 表示最多剔除多少消息 |
| <* | id> | * 表示由系统生成消息id,id 表示用用户指定的消息id |
| field value [field value …] | 消息采用键值对列表形式存储 |
# 1.1 执行 lua 脚本,批量添加 10000 个消息
eval "local key = 'test:stream_1';redis.call('del', key); for i=1,ARGV[1],1 do redis.call('xadd', key, i + '-0', 'index' i) end;local res = redis.call('xinfo', 'stream', key); return res[6];" 0 10000
# 1.2 查看 stream 的信息
xinfo stream test:stream_1
# 1.3 添加消息,后执行精确修剪。不输入 = | ~,表示使用 = 。会添加一条消息,然后删除消息,使流长度为10
xadd test:stream_1 maxlen 10 '10001-0' index 10001
# 1.4 近似删除。stream 中的消息是以基数树的结构存储,一个节点可能存储多个数据,所以当某个节点中存在
# 不能删除的数据时,这个节点就不会删除,因此会导致裁剪后的数据多一些。一个节点会存储 100 个数据。
# 取消 1.3 命令,执行如下命令后,流的长度会变成 101
xadd test:stream_1 maxlen ~ 10 '10001-0' index 10001
# 1.5 精确删除,根据 MINID ;添加一个消息,并将流中所有消息id 小于 1714746952323-9 删除
# 取消 1.3, 1.4 的命令,执行如下命令。结果是,保留 id >= '9001-0' 的所有数据, 流的长度会变成 1001
xadd test:stream_1 minid = '9001-0' '10001-0' index 10001
# 1.6 近似删除,根据 minid 和 limit count。
# 取消 1.3、1.4、1.5 的命令,执行如下命令。结果是,保留 id >= '9001-0' 的所有数据,并且最多删除 8950 个, 流的长度会变成 1101
# 因为限制 删除 8950 个,所以最后一个节点,计算到一半发现不能删除了,所以最后计算的节点的数据全部保留,故只删除了 8900个
xadd test:stream_1 minid ~ '9001-0' limit 8950 '10001-0' index 10001
为什么 xadd 需要添加 xtrim 的操作呢?因为有些消息,如果闲置的时间太长是要废弃掉的;所以可以加上这个。
xinfo stream test:stream_0 返回的结果字段中
radix-tree-keys:表示有几个id节点,一个id节点 至多会存储 100 个 id
radix-tree-nodes: radix tree 节点数量
2. 创建消费者组,消费消息
XGROUP CREATE key group <id | $> [MKSTREAM] [ENTRIESREAD entries-read]
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] id [id ...]
2.1 创建消费者组
MKSTREAM: 表示如果 stream 不存在则创建。如果不加 MKSTREAM参数,且stream不存在,执行的 xgroup create 会报错。
ENTRIESREAD:Redis version 7.0.0 可以添加此参数。如果使用了 ENTRIESREAD entries-read 参数, 设置 entries-read 已消费数量;lag 待消费数量, entries-read + lag 等于总数(包含已删除的消息数)
# id = 0 表示 从头开始消费
# id = 具体id,表示从指定 id 之后开始消费,不包含当前id
# id = $ 消费新消息
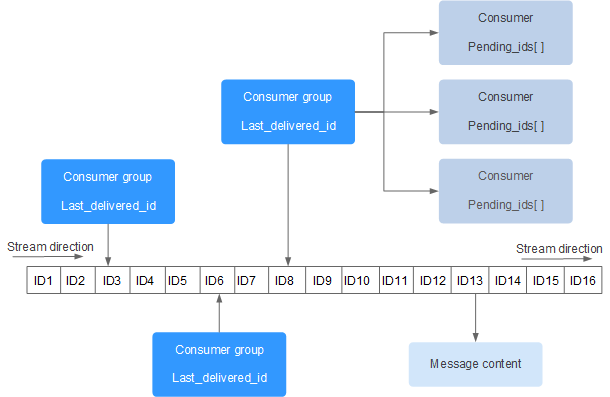
# 每一个消费者组都有一个 last_delivered_id 记录发送的最后一个消息id, 相互之间不会影响,比如来了一个新消息加入到队列中,通过 xreadgroup 可以让每一个消费者组都消费
# last_delivered_id = 0-0, 1714581497948-0, stream 中的最大的id
xgroup create test:stream_1 test:stream_1:group_0 0
# last_delivered_id = 1714581497948-0
xgroup create test:stream_1 test:stream_1:group_1 1714581497948-0
# last_delivered_id = stream 中的最大的id
xgroup create test:stream_1 test:stream_1:group_2 $
# 执行一下命令之后 消费者组的 entries-read = 1, lag = stream.entries-added - entries-read
xgroup create test:stream_1 test:stream_1:group_3 0 ENTRIESREAD 1
xgroup create test:stream_1 test:stream_1:group_4 1714581525681-0 ENTRIESREAD 1
xgroup create test:stream_1 test:stream_1:group_5 $ ENTRIESREAD 1
2.2 拉取消息消费
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] id [id ...]
- GROUP group consumer: 与stream 绑定的 消费者组、消费者
- COUNT count: 查找最大消息数量
- BLOCK milliseconds: 如果一条消息都没有,阻塞多少时间
- NOACK: 无需消息确认。相当于在读取的时候就已经确认消息了。
- STREAMS key [key …] id [id …]
- id 为 “>” 表示取 stream 中 message_id > consumer_group.last_delivered_id 的消息
- id 为特定数字,表示 从 padding_list 中取 message_id > id 消息。 使用了具体id, BLOCK 和 NOACK 无效。
# 获取全部未消费的消息
XREADGROUP GROUP test:stream_1:group_0 test:stream_1:group_0:consumer_0 STREAMS test:stream_1 >
# 获取至多 10 条消息;若一条消息都没有,等待 20 秒。超时返回 nil
XREADGROUP GROUP test:stream_1:group_0 test:stream_1:group_0:consumer_0 count 10 BLOCK 20000 STREAMS test:stream_1 >
# 获取正在消费中的消息
XREADGROUP GROUP test:stream_1:group_0 test:stream_1:group_0:consumer_0 count 100 STREAMS test:stream_1 0
3. 正常消费,消息确认 ack
XACK key group id [id ...]
key 流名称
group 组名称
id 消息id
# 读取pel列表(pedding entries list: 消费中的列表)的消息的id,并确认
eval "local key = 'test:stream_1';local list = redis.call('xreadgroup','group','test:stream_1:group_0','test:stream_1:group_0:consumer_0','STREAMS',key,0); local entries = list[1][2];local sum = 0; for i=1,#entries, 1 do sum = sum + redis.call('xack', key, 'test:stream_1:group_0', entries[i][1]); end; return sum;" 0
4. 异常消费,转移消息的归属权 claim
XCLAIM key group consumer min-idle-time id [id ...] [IDLE ms] [TIME unix-time-milliseconds] [RETRYCOUNT count] [FORCE] [JUSTID] [LASTID lastid]
- min-idle-time:最小闲置时间,如果闲置时间小于min-idle-time,则不处理
- IDLE :设置消息的空闲时间(上次发送时间)。如果未指定 IDLE,则假定 IDLE 为 0,即重置时间计数,因为该消息现在有一个新所有者正在尝试处理它。
- TIME :这与 IDLE 相同,但不是相对的毫秒数,而是将空闲时间设置为特定的 Unix 时间(以毫秒为单位)。像当于设置下发时间
- RETRYCOUNT :将重试计数器设置为指定值。每次再次传送消息时,该计数器都会递增。通常XCLAIM不会更改此计数器,该计数器仅在调用 XPENDING 命令时提供给客户端:这样客户端可以检测异常情况,例如在大量传递尝试后由于某种原因从未处理的消息。
- FORCE:即使某些指定的 ID 尚未在分配给其他客户端的 PEL 中,也会在 PEL 中创建待处理消息条目。但是该消息必须存在于流中,否则不存在的消息的 ID 将被忽略。
- JUSTID:仅返回成功领取的消息ID数组,不返回实际消息。使用此选项意味着重试计数器不会增加。
# 强制处理id为 11-0 的,闲置时间大于 1 小时的消息;设置闲置时间为 0
xclaim test:stream_1 test:stream_1:group_0 test:stream_1:group_0:consumer_2 3600000 '11-0' IDLE 0 TIME 15 RETRYCOUNT 1 FORCE JUSTID
# 设置下发时间,并返回待处理消息列表
eval "local key = 'test:stream_1';local group = 'test:stream_1:group_0';local consumer = 'test:stream_1:group_0:consumer_2';local id = '11-0';local t = redis.call('time');local time = t[1] * 1000;redis.call('xclaim', key, group, consumer, 3600, id, 'TIME', time, 'RETRYCOUNT', 1, 'FORCE', 'JUSTID');return redis.call('xpending', key, group, '-', '+', 10, consumer);" 0