系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践
AI大模型探索之路-训练篇14:大语言模型Transformer库-Trainer组件实践
目录
- 系列篇章💥
- 前言
- 一、预训练任务类型
- 二、模型和数据集选择
- 三、指令微调数据处理
- 四、全量参数微调实践
- 学术资源加速
- 步骤1:导入相关包
- 步骤2:加载数据集
- 步骤3:数据预处理
- 步骤4:创建模型
- 步骤5:配置训练参数
- 步骤6:创建训练器
- 步骤7:模型训练
- 步骤8:模型推理
- 总结
前言
在自然语言处理(NLP)领域,预训练模型的应用已经越来越广泛。预训练模型通过大规模的无监督学习,能够捕捉到丰富的语言知识和上下文信息。然而,由于预训练模型通常需要大量的计算资源和时间进行训练,因此在实际使用时,我们往往需要对预训练模型进行微调,以便更好地适应特定的任务需求。本文将介绍全量参数微调的方法,以及如何在实践中进行操作。
一、预训练任务类型
1)掩码语言模型,自编码模型
将一些位置的token替换成特殊[MASK]字符,预测被替换的字符;(代表:BERT)

2)因果模型,自回归模型
将完整序列输入,基于上文的token预测下文的token;(代表:GPT)

3)序列到序列模型
采用编码器解码器的方式,预测放在解码器部分 (代表:GLM)

二、模型和数据集选择
目标:训练一个对话模型
模型:https://huggingface.co/Langboat/bloom-800m-zh
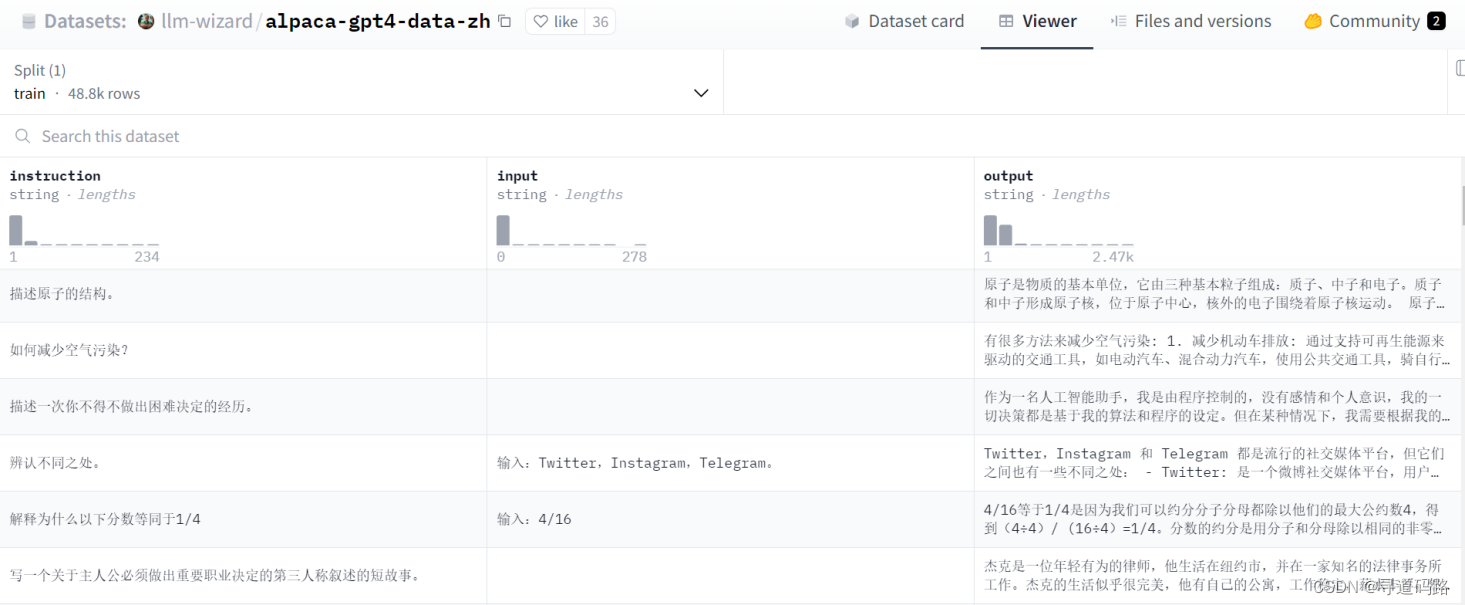
数据集:https://huggingface.co/datasets/c-s-ale/alpaca-gpt4-data-zh
三、指令微调数据处理
自回归编码指令微调数据处理过程
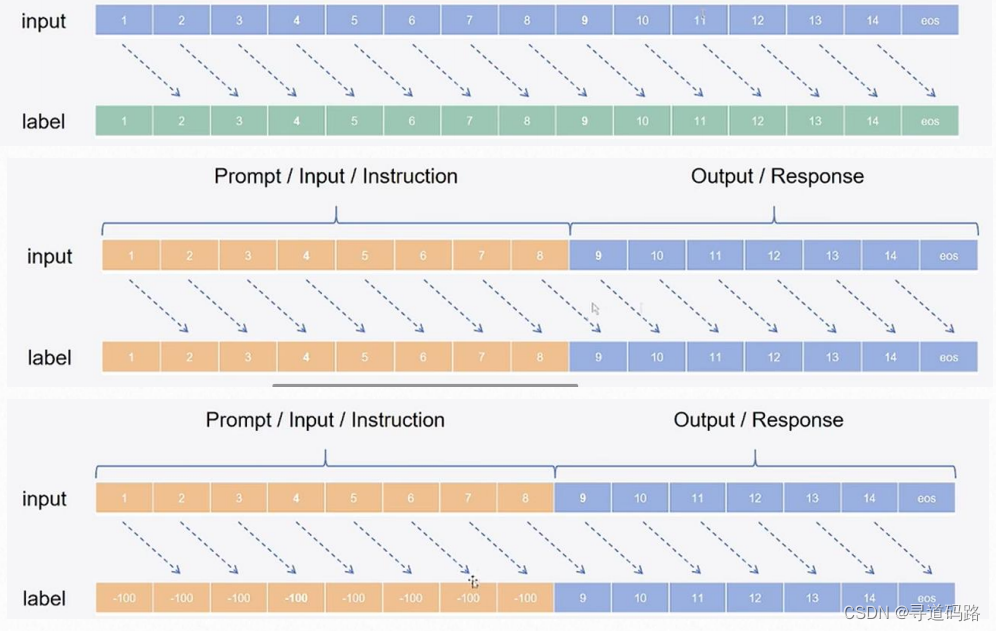
1)input输入构建:首先,我们将数据集中的指令(instruction),用户输入(input),以及预期输出(output)拼接成单一的字符串。这创建了一个格式为[instruction] [input] [output]的序列。
2)label标签创建:接着,为了构建训练标签,我们将用户输入部分保持不变,而对于输出部分,我们将其转化为目标标签。在掩码语言模型中,除了输出部分外,其他部分(包括指令和输入)的标签被替换为一个特殊的分隔符(例如:[SEP])加上-100,表示这部分不需要模型去预测。(前面instruction 和 input,对应部分不需要推理,采用-100填充;后面补上output)
四、全量参数微调实践
在自然语言处理(NLP)领域,全量参数微调(Fine-tuning)是释放预训练语言模型潜力的关键步骤。该过程涉及对大规模模型进行细微调整,以适应特定的下游任务。全量参数微调的标准流程包括:导包、加载数据集、数据预处理、创建模型、配置训练参数、创建训练器、模型训练、模型推理。
学术资源加速
方便从huggingface下载模型,这云平台autodl提供的,仅适用于autodl。
import subprocess
import os
result = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"', shell=True, capture_output=True, text=True)
output = result.stdout
for line in output.splitlines():
if '=' in line:
var, value = line.split('=', 1)
os.environ[var] = value
步骤1:导入相关包
开始之前,我们需要导入适用于模型训练和推理的必要库,如transformers。
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
步骤2:加载数据集
使用适当的数据加载器,例如datasets库,来加载预处理过的指令遵循性任务数据集。
ds = Dataset.load_from_disk("data/alpaca_data_zh/")
ds
输出:
Dataset({
features: ['output', 'input', 'instruction'],
num_rows: 26858
})
数据查看:
ds[:3]
输出
{'output': ['以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。',
'4/16等于1/4是因为我们可以约分分子分母都除以他们的最大公约数4,得到(4÷4)/ (16÷4)=1/4。分数的约分是用分子和分母除以相同的非零整数,来表示分数的一个相同的值,这因为分数实际上表示了分子除以分母,所以即使两个数同时除以同一个非零整数,分数的值也不会改变。所以4/16 和1/4是两种不同的书写形式,但它们的值相等。',
'朱利叶斯·凯撒,又称尤利乌斯·恺撒(Julius Caesar)是古罗马的政治家、军事家和作家。他于公元前44年3月15日被刺杀。 \n\n根据历史记载,当时罗马元老院里一些参议员联合起来策划了对恺撒的刺杀行动,因为他们担心恺撒的统治将给罗马共和制带来威胁。在公元前44年3月15日(又称“3月的艾达之日”),恺撒去参加元老院会议时,被一群参议员包围并被攻击致死。据记载,他身中23刀,其中一刀最终致命。'],
'input': ['', '输入:4/16', ''],
'instruction': ['保持健康的三个提示。', '解释为什么以下分数等同于1/4', '朱利叶斯·凯撒是如何死亡的?']}
步骤3:数据预处理
利用预训练模型的分词器(Tokenizer)对原始文本进行编码,并生成相应的输入ID、注意力掩码和标签。
1)获取分词器
tokenizer = AutoTokenizer.from_pretrained("Langboat/bloom-800m-zh")
tokenizer

输出:
BloomTokenizerFast(name_or_path='Langboat/bloom-800m-zh', vocab_size=46145, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='left', truncation_side='right', special_tokens={'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>', 'pad_token': '<pad>'}, clean_up_tokenization_spaces=False), added_tokens_decoder={
0: AddedToken("<unk>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
1: AddedToken("<s>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
2: AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
3: AddedToken("<pad>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
2)定义数据处理函数
def process_func(example):
MAX_LENGTH = 256 # 定义最大长度为256
input_ids, attention_mask, labels = [], [], [] # 初始化输入ID、注意力掩码和标签列表
# 对指令和输入进行编码,返回输入ID和注意力掩码
instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")
# 对输出进行编码,返回输出ID和注意力掩码
response = tokenizer(example["output"] + tokenizer.eos_token)
# 将指令和回应的输入ID合并
input_ids = instruction["input_ids"] + response["input_ids"]
# 将指令和回应的注意力掩码合并
attention_mask = instruction["attention_mask"] + response["attention_mask"]
# 标签列表的前半部分是指令的长度个-100(表示这些位置的标签是被忽略的),后半部分是回应的输入ID
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
# 如果输入ID的长度大于最大长度,将其截断为最大长度
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
# 返回一个包含输入ID列表、注意力掩码列表和标签列表的字典
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
3)对数据进行预处理
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds
输出:
Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 26858
})
4)数据格式检查
检查input部分
#检查一下数据格式,知识部分是否符合我们的需求
tokenizer.decode(tokenized_ds[1]["input_ids"])
输出:
'Human: 解释为什么以下分数等同于1/4\n输入:4/16\n\nAssistant: 4/16等于1/4是因为我们可以约分分子分母都除以他们的最大公约数4,得到(4÷4)/ (16÷4)=1/4。分数的约分是用分子和分母除以相同的非零整数,来表示分数的一个相同的值,这因为分数实际上表示了分子除以分母,所以即使两个数同时除以同一个非零整数,分数的值也不会改变。所以4/16 和1/4是两种不同的书写形式,但它们的值相等。</s>'
检查label部分
## 检查一下数据格式,目标值是否符合我们的需求
tokenizer.decode(list(filter(lambda x: x != -100, tokenized_ds[1]["labels"])))
输出
'4/16等于1/4是因为我们可以约分分子分母都除以他们的最大公约数4,得到(4÷4)/ (16÷4)=1/4。分数的约分是用分子和分母除以相同的非零整数,来表示分数的一个相同的值,这因为分数实际上表示了分子除以分母,所以即使两个数同时除以同一个非零整数,分数的值也不会改变。所以4/16 和1/4是两种不同的书写形式,但它们的值相等。</s>'
步骤4:创建模型
实例化一个预训练模型,它将作为我们微调的基础。
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-800m-zh")

步骤5:配置训练参数
定义训练参数,包括输出目录、学习率、批次大小、梯度累积步数、优化器选择等。
args = TrainingArguments(
output_dir="/root/autodl-tmp/tuningdata/boomtuning",# 指定模型训练结果的输出目录。
per_device_train_batch_size=4, # 指定每个设备(如GPU)上的批次大小
gradient_accumulation_steps=8, # 指定梯度累积步数。在本例子中,每8个步骤进行一次梯度更新。
logging_steps=10, #指定日志记录的频率。在本例子中,每10个步骤记录一次日志
num_train_epochs=1 #指定训练的总轮数。在本例子中,训练将进行1轮, 实际使用是会是多轮
)
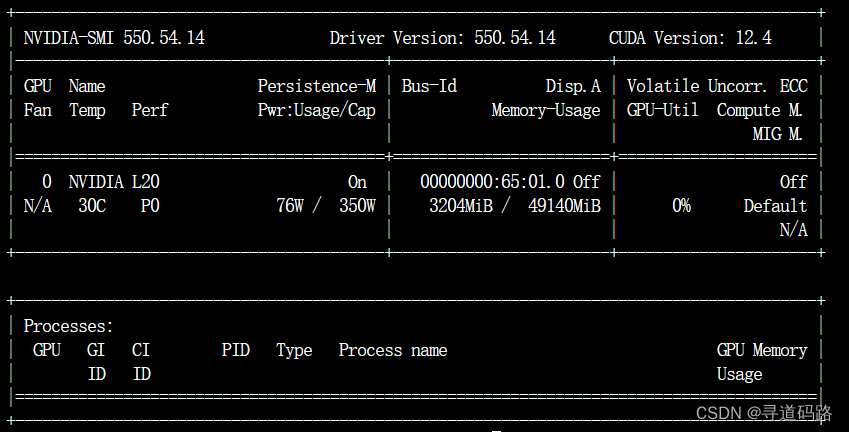
查看服务器当前GPU使用情况,大概48G
nvidia-smi
步骤6:创建训练器
初始化Trainer类,它封装了训练循环,并提供了一种简单的方式来运行训练和评估。
trainer = Trainer(
model=model,#指定训练模型
args=args, #指定训练参数
train_dataset=tokenized_ds, #指定数据集
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True) #指定数据收集器。其中tokenizer是分词器,padding=True表示对输入进行填充以保持批次大小一致。
)
data_collator在训练机器学习模型时,有以下作用:
1)数据转换:data_collator负责将输入的特征数据转换成统一形状和格式的张量(tensor),这是为了便于模型进行统一的处理。
2)批量处理:它能够将多个数据样本整合成一个小批次(batch)的数据,这有助于提高模型训练的效率。
3)填充(padding):在文本处理中,不同大小的输入需要被填充或截断到相同的长度以形成统一的形状,这对于很多自然语言处理模型来说是必要的,而DataCollatorWithPadding就是执行这一操作的常用collator。
综上所述,data_collator是连接数据处理与模型训练之间的重要桥梁,确保了数据的有效整理和组织,以便模型可以高效地从中学习。
步骤7:模型训练
模型训练资源估算:
1)模型大小:4G(模型参数数量是8亿,按10亿估算,如果参数使用32位浮点数,每个参数需要4字节的空间。因此,模型大小差不多是4G)
2)梯度大小:4G(梯度的大小通常与模型大小相同,因为它们是针对每个参数计算的。所以,如果模型大小是4GB,梯度大小也应该是4GB)
3)优化器状态:4G * 2 = 8G (优化器状态的大小取决于使用的优化器类型和其内部参数的数量。Adam优化器通常会为每个模型参数维护两个额外的向量。因此,如果模型大小是4GB,优化器状态可能需要额外的8GB,每个参数两个额外的值。)
4)其他开销:还需要考虑数据加载、中间变量、系统进程等其他内存开销。
大约需要16G,实际资源则要比16G多一点
调用train()方法启动训练过程。
trainer.train()
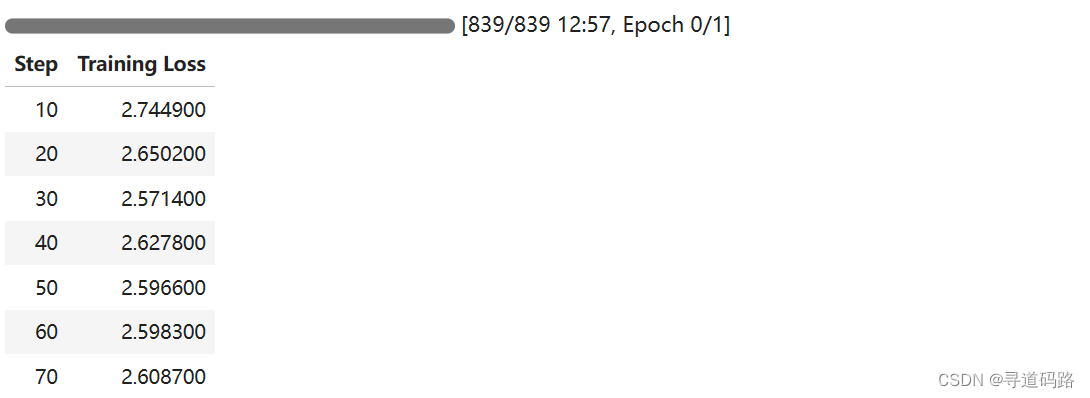
训练后查看GPU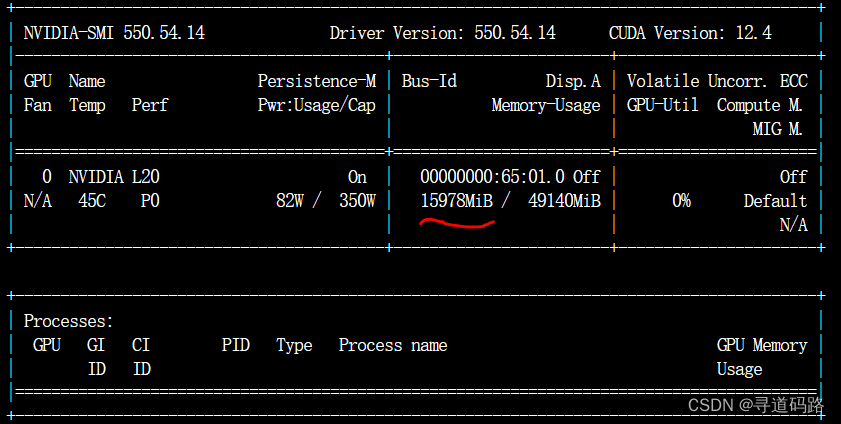
步骤8:模型推理
使用pipeline进行推理,展示模型的能力。
from transformers import pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, device=0)
ipt = "Human: {}\n{}".format("如何写好一个简历?", "").strip() + "\n\nAssistant: "
pipe(ipt, max_length=256, do_sample=True, )
输出
[{'generated_text': 'Human: 如何写好一个简历?\n\nAssistant: 在撰写一份简历时,需要考虑很多细节。以下是一些关键因素:\n\n1. 结构清晰:将信息组织在一个清晰的的结构里。例如,使用一个目录或列表来将信息组织。避免使用令人反感的混乱结构,例如使用树、流程图或层次结构。\n\n2. 内容丰富:列出最重要的信息。包括关键字和关键问题,以吸引招聘师的注意。此外,可以使用大量的数据和图表来增强整张简历的信息性。\n\n3. 恰当的背景信息:用适当的背景信息进行补充和修饰,例如加入家庭信息、教育经历或工作经验等。可以提供更加个性化和关键性的背景信息来帮助招聘师更好地了解你的工作技能和能力。'}]
总结
在当今的自然语言处理领域,全量参数微调(Fine-tuning)已成为释放大型预训练语言模型潜力的关键技术手段。然而,随着模型规模的扩大,这一过程对计算资源的要求也急剧上升。
在本次实践中,我们选择了一个拥有约8亿参数的模型进行全量参数微调。这一规模级别的模型,通常需要大约18GB的显存资源。尽管这在现代硬件上是可行的,但当模型规模扩大到80亿参数时,所需的显存将飙升至180GB,这种级别的资源消耗通常只有资金雄厚的企业才能承担。
进一步地,如果模型的规模达到惊人的800亿参数,那么所需的显存将达到庞大的1800GB。如此巨大的资源需求,即便是对于许多公司而言,也是一项极具挑战的任务,往往超出了他们的能力范围。因此,尽管全量参数微调在技术上可行,但在实际的应用和研究中,由于资源的限制,这样的实践相对较少。
鉴于此,大多数实际应用场景倾向于采用部分微调(Partial Fine-tuning)或迁移学习,这样既可以利用预训练模型中的知识,又可以针对性地调整模型以适应特定任务,而无需动用如全量微调那般庞大的计算资源。这种方法更加经济高效,同时也能产生令人满意的结果。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!