一 简介
灵长类动物的视觉系统接受了大量的感官输入,这些感官输入远远超过了大脑能够完全处理的程度。然而, 并非所有刺激的影响都是相等的。意识的聚集和专注使灵长类动物能够在复杂的视觉环境中将注意力引向感 兴趣的物体,例如猎物和天敌。只关注一小部分信息的能力对进化更加有意义,使人类得以生存和成功。
自19世纪以来,科学家们一直致力于研究认知神经科学领域的注意力。首先回顾一个经典注意力框架,解释如何在视觉场景中展开注意力。受此框架中的 注意力提示(attention cues) 的启发,我们将设计能够利用这些注意力提示的模型。1964年的Nadaraya‐Waston核回归(kernel regression) 正是具有注意力机制(attention mechanism)的机器学习的简单演示。
然后继续介绍的是 注意力函数,它们在深度学习的注意力模型设计中被广泛使用。具体来说,我们将展示如何使用这些函数来设计Bahdanau注意力。Bahdanau注意力是深度学习中的具有突破性价值的注意力模型,它双向对齐并且可以微分。
最后将描述仅仅基于注意力机制的 Transformer架构,该架构中使用了 多头注意力(multi‐head attention)和 自注意力(self‐attention)。自2017年横空出世,Transformer一直都普遍存在于现代的深度学习应用中,例如 语言、视觉、语音和 强化学习 领域。
二 注意力机制
自经济学研究稀缺资源分配以来,人们正处在“注意力经济”时代,即 人类的注意力被视为可以交换的、有限的、有价值的且稀缺的商品。许多商业模式也被开发出来去利用这一点:在音乐或视频流媒体服务上,人 们要么消耗注意力在广告上,要么付钱来隐藏广告;为了在网络游戏世界的成长,人们要么消耗注意力在游 戏战斗中,从而帮助吸引新的玩家,要么付钱立即变得强大。总之,注意力不是免费的。
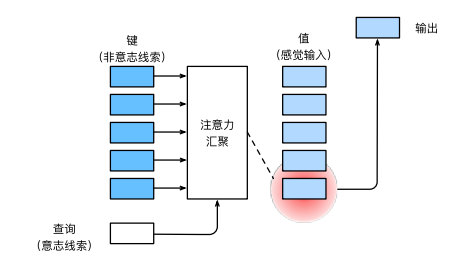
注意力机制通过注意力汇聚将查询(自主性提示)和键(非自主性提示)结合在一起,实现对值(感官输入)的选择倾向
2.1 注意力的可视化
平均汇聚层可以被视为输入的加权平均值,其中各输入的权重是一样的。实际上,注意力汇聚得到的是加权平均的总和值,其中权重是在给定的查询和不同的键之间计算得出的。
为了 可视化注意力权重,需要定义一个show_heatmaps函数。其输入matrices的形状是(要显示的行数,要显 示的列数,查询的数目,键的数目)。
import torch
from d2l import torch as d2l
#@save
def show_heatmaps(matrices, xlabel, ylabel, titles=None, figsize=(2.5, 2.5),
cmap='Reds'):
"""显示矩阵热图"""
d2l.use_svg_display()
num_rows, num_cols = matrices.shape[0], matrices.shape[1]
fig, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize,
sharex=True, sharey=True, squeeze=False)
for i, (row_axes, row_matrices) in enumerate(zip(axes, matrices)):
for j, (ax, matrix) in enumerate(zip(row_axes, row_matrices)):
pcm = ax.imshow(matrix.detach().numpy(), cmap=cmap)
if i == num_rows - 1:
ax.set_xlabel(xlabel)
if j == 0:
ax.set_ylabel(ylabel)
if titles:
ax.set_title(titles[j])
fig.colorbar(pcm, ax=axes, shrink=0.6)
下面使用一个例子进行演示。在本例子中,仅当查询和键相同时,注意力权重为1,否则为0。
attention_weights = torch.eye(10).reshape((1, 1, 10, 10))
show_heatmaps(attention_weights, xlabel='Keys', ylabel='Queries')
小结:
- 人类的注意力是有限的、有价值和稀缺的资源。
- 受试者使用非自主性和自主性提示 有选择性地引导注意力。前者基于突出性,后者则依赖于意识。
- 注意力机制 与全连接层或者汇聚层的 区别 源于增加的 自主提示。
- 由于 包含了自主性提示,注意力机制与全连接的层或汇聚层不同。
- 注意力机制通过注意力汇聚使选择 偏向于值(感官输入),其中包含查询(自主性提示)和键(非自主 性提示)。键和值是成对的。
- 可视化查询和键之间的注意力权重 是可行的。
2.2 注意力汇聚
2.2.1 生成数据集
根据下面的非线性函数生成一个人工数据集:
其中 ϵ服从均值为0和标准差为0.5的正态分布。在这里生成了50个训练样本和50个测试样本。为了更好地可视 化之后的注意力模式,需要将训练样本进行排序。
import torch
from torch import nn
from d2l import torch as d2l
n_train = 50 # 训练样本数
x_train, _ = torch.sort(torch.rand(n_train) * 5) # 排序后的训练样本
def f(x):
return 2 * torch.sin(x) + x**0.8
y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)) # 训练样本的输出
x_test = torch.arange(0, 5, 0.1) # 测试样本
y_truth = f(x_test) # 测试样本的真实输出
n_test = len(x_test) # 测试样本数
n_test # 50下面的函数将绘制所有的训练样本(样本由圆圈表示),不带噪声项的真实数据生成函数f(标记为“Truth”), 以及学习得到的预测函数(标记为“Pred”)。
2.2.2 平均汇聚
先使用最简单的估计器来解决回归问题。基于平均汇聚来计算所有训练样本输出值的平均值。
def plot_kernel_reg(y_hat):
d2l.plot(x_test, [y_truth, y_hat], 'x', 'y', legend=['Truth', 'Pred'],
xlim=[0, 5], ylim=[-1, 5])
d2l.plt.plot(x_train, y_train, 'o', alpha=0.5);
y_hat = torch.repeat_interleave(y_train.mean(), n_test)
plot_kernel_reg(y_hat)
2.2.3 非参数注意力汇聚
如果一个键xi越是接近给定的查询x,那么分配给这个键对应值yi的注意力权重就会越大,也就“获得了更多的注意力”。
值得注意的是,Nadaraya‐Watson核回归是一个非参数模型。因此,是非参数的注意力汇聚(non‐ parametric attention pooling)模型。接下来,我们将基于这个非参数的注意力汇聚模型来绘制预测结果。从 绘制的结果会发现新的模型预测线是平滑的,并且比平均汇聚的预测更接近真实值。
# X_repeat的形状:(n_test,n_train),
# 每一行都包含着相同的测试输入(例如:同样的查询)
X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))
# x_train包含着键。attention_weights的形状:(n_test,n_train),
# 每一行都包含着要在给定的每个查询的值(y_train)之间分配的注意力权重
attention_weights = nn.functional.softmax(-(X_repeat - x_train)**2 / 2, dim=1)
# y_hat的每个元素都是值的加权平均值,其中的权重是注意力权重
y_hat = torch.matmul(attention_weights, y_train)
plot_kernel_reg(y_hat)
现在来观察注意力的权重。这里测试数据的输入相当于查询,而训练数据的输入相当于键。因为两个输入都 是经过排序的,因此由观察可知 “查询‐键”对越接近,注意力汇聚的注意力权重就越高。
d2l.show_heatmaps(attention_weights.unsqueeze(0).unsqueeze(0),
xlabel='Sorted training inputs',
ylabel='Sorted testing inputs')
2.2.4 带参数注意力汇聚
非参数的Nadaraya‐Watson核回归具有一致性(consistency)的优点:如果有足够的数据,此模型会收敛到最优结果。尽管如此,我们还是可以轻松地将可学习的参数集成到注意力汇聚中。
为了更有效地计算小批量数据的注意力,我们可以利用深度学习开发框架中提供的批量矩阵乘法。
假设第一个小批量数据包含n个矩阵X1, . . . , Xn,形状为a × b,第二个小批量包含n个矩阵Y1, . . . , Yn,形状 为b × c。它们的批量矩阵乘法得到n个矩阵 X1Y1, . . . , XnYn,形状为a × c。因此,假定两个张量的形状分别 是(n, a, b)和(n, b, c),它们的 批量矩阵乘法输出的形状为(n, a, c)。
X = torch.ones((2, 1, 4))
Y = torch.ones((2, 4, 6))
torch.bmm(X, Y).shape # torch.Size([2, 1, 6])
torch.bmm(X, Y)
# tensor([[[4., 4., 4., 4., 4., 4.]],
# [[4., 4., 4., 4., 4., 4.]]])在注意力机制的背景中,我们可以使用 小批量矩阵乘法来计算小批量数据中的加权平均值。
weights = torch.ones((2, 10)) * 0.1
values = torch.arange(20.0).reshape((2, 10))
torch.bmm(weights.unsqueeze(1), values.unsqueeze(-1))
# tensor([[[ 4.5000]],
# [[14.5000]]])2.2.5 定义模型
使用 小批量矩阵乘法,定义Nadaraya‐Watson核回归的带参数版本为:
class NWKernelRegression(nn.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand((1,), requires_grad=True))
def forward(self, queries, keys, values):
# queries和attention_weights的形状为(查询个数,“键-值”对个数)
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
self.attention_weights = nn.functional.softmax(
-((queries - keys) * self.w)**2 / 2, dim=1)
# values的形状为(查询个数,“键-值”对个数)
return torch.bmm(self.attention_weights.unsqueeze(1),
values.unsqueeze(-1)).reshape(-1)接下来,将训练数据集变换为键和值用于训练注意力模型。在带参数的注意力汇聚模型中,任何一个训练样 本的输入都会和除自己以外的所有训练样本的“键-值”对进行计算,从而得到其对应的预测输出。
# X_tile的形状:(n_train,n_train),每一行都包含着相同的训练输入
X_tile = x_train.repeat((n_train, 1))
# Y_tile的形状:(n_train,n_train),每一行都包含着相同的训练输出
Y_tile = y_train.repeat((n_train, 1))
# keys的形状:('n_train','n_train'-1)
keys = X_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
# values的形状:('n_train','n_train'-1)
values = Y_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))训练带参数的注意力汇聚模型时,使用平方损失函数和随机梯度下降。
net = NWKernelRegression()
loss = nn.MSELoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=0.5)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[1, 5])
for epoch in range(5):
trainer.zero_grad()
l = loss(net(x_train, keys, values), y_train)
l.sum().backward()
trainer.step()
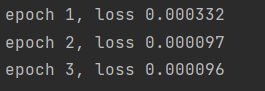
print(f'epoch {epoch + 1}, loss {float(l.sum()):.6f}')
animator.add(epoch + 1, float(l.sum()))
如下所示,训练完带参数的注意力汇聚模型后可以发现:在尝试拟合带噪声的训练数据时,预测结果绘制的 线不如之前非参数模型的平滑。
# keys的形状:(n_test,n_train),每一行包含着相同的训练输入(例如,相同的键)
keys = x_train.repeat((n_test, 1))
# value的形状:(n_test,n_train)
values = y_train.repeat((n_test, 1))
y_hat = net(x_test, keys, values).unsqueeze(1).detach()
plot_kernel_reg(y_hat)
为什么新的模型更不平滑了呢?下面看一下输出结果的绘制图:与非参数的注意力汇聚模型相比,带参数的模型加入可学习的参数后,曲线在注意力权重较大的区域变得更不平滑。
d2l.show_heatmaps(net.attention_weights.unsqueeze(0).unsqueeze(0),
xlabel='Sorted training inputs',
ylabel='Sorted testing inputs')
小结:
- Nadaraya‐Watson核回归是 具有注意力机制的机器学习范例。
- Nadaraya‐Watson核回归的注意力汇聚是 对训练数据中输出的加权平均。从注意力的角度来看,分配给每个值的注意力权重取决于将值所对应的键和查询作为输入的函数。
- 注意力汇聚可以分为 非参数型和带参数型。
三 注意力评分函数
上节使用了 高斯核 来对查询和键之间的关系建模。其中的高斯核指数部分可以视为 注意力评分函数 (attention scoring function),简称评分函数(scoring function),然后把这个函数的输出结果输入到 softmax函数中进行运算。通过上述步骤,将得到与键对应的值的概率分布(即注意力权重)。最后,注意力汇聚的输出 就是基于这些注意力权重的值的加权和。
从宏观来看,上述算法可以用来实现了之前的注意力机制框架。下图说明了如何将注意力汇聚的输出 计算成为值的加权和,其中a表示注意力评分函数。由于注意力权重是概率分布,因此加权和其本质上是加权平均值。
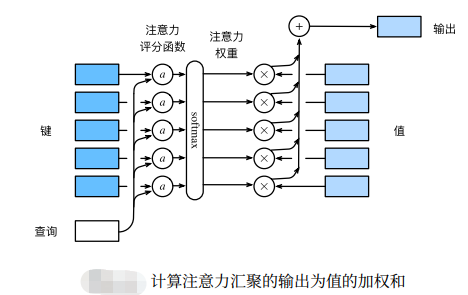
正如上图所示,选择不同的注意力评分函数a会导致不同的注意力汇聚操作。本节将介绍两个流行的评分函数,稍后将用他们来实现更复杂的注意力机制。
softmax操作 用于输出一个概率分布作为 注意力权重。在某些情况下,并非所有的值都应该 被纳入到注意力汇聚中。为了仅将有意义的词元作为值来获取注意力汇聚,可以指定一个有效序列长度(即词元的个数), 以便在计算softmax时过滤掉超出指定范围的位置。下面的masked_softmax函数 实现了这样的掩蔽softmax操 作(masked softmax operation),其中任何超出有效长度的位置都被掩蔽并置为0。
import math
import torch
from torch import nn
from d2l import torch as d2l
#@save
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
为了 演示此函数 是如何工作的,考虑由两个2 × 4矩阵表示的样本,这两个样本的有效长度分别为2和3。经过掩蔽softmax操作,超出有效长度的值都被掩蔽为0。
masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))
# tensor([[[0.5572, 0.4428, 0.0000, 0.0000],
# [0.5652, 0.4348, 0.0000, 0.0000]],
# [[0.3246, 0.2382, 0.4372, 0.0000],
# [0.2726, 0.4352, 0.2922, 0.0000]]])同样,也可以使用二维张量,为矩阵样本中的每一行指定有效长度。
masked_softmax(torch.rand(2, 2, 4), torch.tensor([[1, 3], [2, 4]]))
# tensor([[[1.0000, 0.0000, 0.0000, 0.0000],
# [0.3557, 0.2924, 0.3519, 0.0000]],
# [[0.4293, 0.5707, 0.0000, 0.0000],
# [0.3322, 0.1845, 0.2947, 0.1886]]])3.1 加性注意力
一般来说,当查询和键是不同长度的矢量时,可以使用加性注意力作为评分函数。
其中可学习的参数是Wq ∈ R^h×q、Wk ∈ R^h×k和 wv ∈ R h。将查询和键连结起来后输入到一 个多层感知机(MLP)中,感知机包含一个隐藏层,其隐藏单元数是一个超参数h。通过 使用tanh作为激活函数,并且 禁用偏置项。
#@save
class AdditiveAttention(nn.Module):
"""加性注意力"""
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
queries, keys = self.W_q(queries), self.W_k(keys)
# 在维度扩展后,
# queries的形状:(batch_size,查询的个数,1,num_hidden)
# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
# 使用广播方式进行求和
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
# self.w_v仅有一个输出,因此从形状中移除最后那个维度。
# scores的形状:(batch_size,查询的个数,“键-值”对的个数)
scores = self.w_v(features).squeeze(-1)
self.attention_weights = masked_softmax(scores, valid_lens)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
return torch.bmm(self.dropout(self.attention_weights), values)用一个 小例子来演示 上面的AdditiveAttention类,其中查询、键和值的形状为(批量大小,步数或词元序列 长度,特征大小),实际输出为(2, 1, 20)、(2, 10, 2)和(2, 10, 4)。注意力汇聚输出的形状为(批量大小,查询的 步数,值的维度)。
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))
# values的小批量,两个值矩阵是相同的
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
valid_lens = torch.tensor([2, 6])
attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8,
dropout=0.1)
attention.eval()
attention(queries, keys, values, valid_lens)
# tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
# [[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=<BmmBackward0>)尽管加性注意力包含了 可学习的参数,但由于本例子中每个键都是相同的,所以注意力权重是均匀的,由指 定的有效长度决定。
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')
3.2 缩放点积注意力
使用 点积可以得到计算效率更高的评分函数,但是 点积操作要求查询和键具有相同的长度d。假设查询和键 的所有元素都是独立的随机变量,并且都满足零均值和单位方差,那么两个向量的点积的均值为0,方差为d。 为确保无论向量长度如何,点积的方差在不考虑向量长度的情况下仍然是1,我们再将点积除以√ d。
下面的缩放点积注意力的实现 使用了暂退法进行模型正则化。
#@save
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)为了演示上述的DotProductAttention类,我们使用与先前加性注意力例子中相同的键、值和有效长度。对于 点积操作,我们令 查询的特征维度与键的特征维度大小相同。
queries = torch.normal(0, 1, (2, 1, 2))
attention = DotProductAttention(dropout=0.5)
attention.eval()
attention(queries, keys, values, valid_lens)
# tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
# [[10.0000, 11.0000, 12.0000, 13.0000]]])与加性注意力演示相同,由于键包含的是相同的元素,而这些元素无法通过任何查询进行区分,因此获得了 均匀的注意力权重。
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')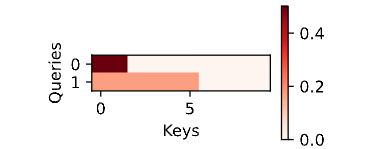
小结:
- 将注意力汇聚的输出计算可以作为值的加权平均,选择不同的注意力评分函数会带来不同的注意力汇聚操作。
- 当查询和键是不同长度的矢量时,可以使用可加性注意力评分函数。当它们的长度相同时,使用缩放的 “点-积”注意力评分函数的计算效率更高。