一. 简介
MySQL中的Buffer Pool是InnoDB存储引擎用来缓存表数据和索引的内存区域。这是InnoDB性能优化中最关键的部分之一。通过在内存中缓存这些数据,InnoDB可以极大减少对磁盘I/O的需求,因为从内存中读取数据远比从磁盘读取要快得多。因此,Buffer Pool的大小和管理方式直接影响到数据库的性能。
Buffer Pool的主要功能
-
数据缓存:当表中的数据被读取时,InnoDB首先检查这些数据是否已在Buffer Pool中。如果是,就直接从内存中读取数据,避免了磁盘I/O操作。如果不是,InnoDB会从磁盘读取数据,并将其缓存到Buffer Pool中,以供后续请求使用。
-
索引缓存:InnoDB使用B+树索引,这些索引同样被缓存在Buffer Pool中。这意味着数据的查找和访问也可以极大地加速,因为索引查找通常是数据库操作中最频繁执行的操作之一。
-
脏页的写回:当InnoDB中的数据被修改(如通过INSERT、UPDATE或DELETE语句)时,这些更改首先在Buffer Pool中的数据页(即“脏页”)上进行。然后,这些脏页会根据InnoDB的刷新策略异步地写回磁盘。这个过程称为CheckPointing,可以有效地减少对磁盘的写操作,并且提升事务的处理速度。
-
读预读:InnoDB的Buffer Pool还会根据数据的访问模式自动预读数据页到Buffer Pool中。这种预读操作可以减少未来读操作的等待时间,从而提高数据库性能。
Buffer Pool的配置
Buffer Pool的大小是影响InnoDB性能的最重要的配置之一。它通过innodb_buffer_pool_size配置参数设置。 默认值为 128M
- my.cnf
[server]
innodb_buffer_pool_size = 2147483648
- 查看参数
mysql> SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+
1 row in set (0.00 sec)
理想情况下,Buffer Pool的大小应该足以容纳绝大多数的数据库工作集(即活跃数据和索引)。这样可以确保大部分的数据库读操作都能从内存中完成,极大地提高性能。
在配置Buffer Pool时,需要考虑到服务器上可用的物理内存大小。通常建议将Buffer Pool的大小设置为系统物理内存的50%-80%,但这也取决于服务器上运行的其他应用程序及其内存需求。
从MySQL 5.5版本开始,Buffer Pool可以被配置为多个实例,这有助于提高并发性能,因为它减少了多个线程在访问Buffer Pool时的锁争用。
二. 名词解释
数据页
Buffer Pool中存放的是一个一个的数据页.
MySQL对数据抽象出来了一个数据页的概念, 多行数据放在了一个数据页里.
这样磁盘文件中就是会有很多的数据页,每一页数据里放了很多行数据
假设我们要更新一行数据,此时数据库会找到这行数据所在的数据页,然后从磁盘文件里把这行数据所在的数据页直接给加载到Buffer Pool里去
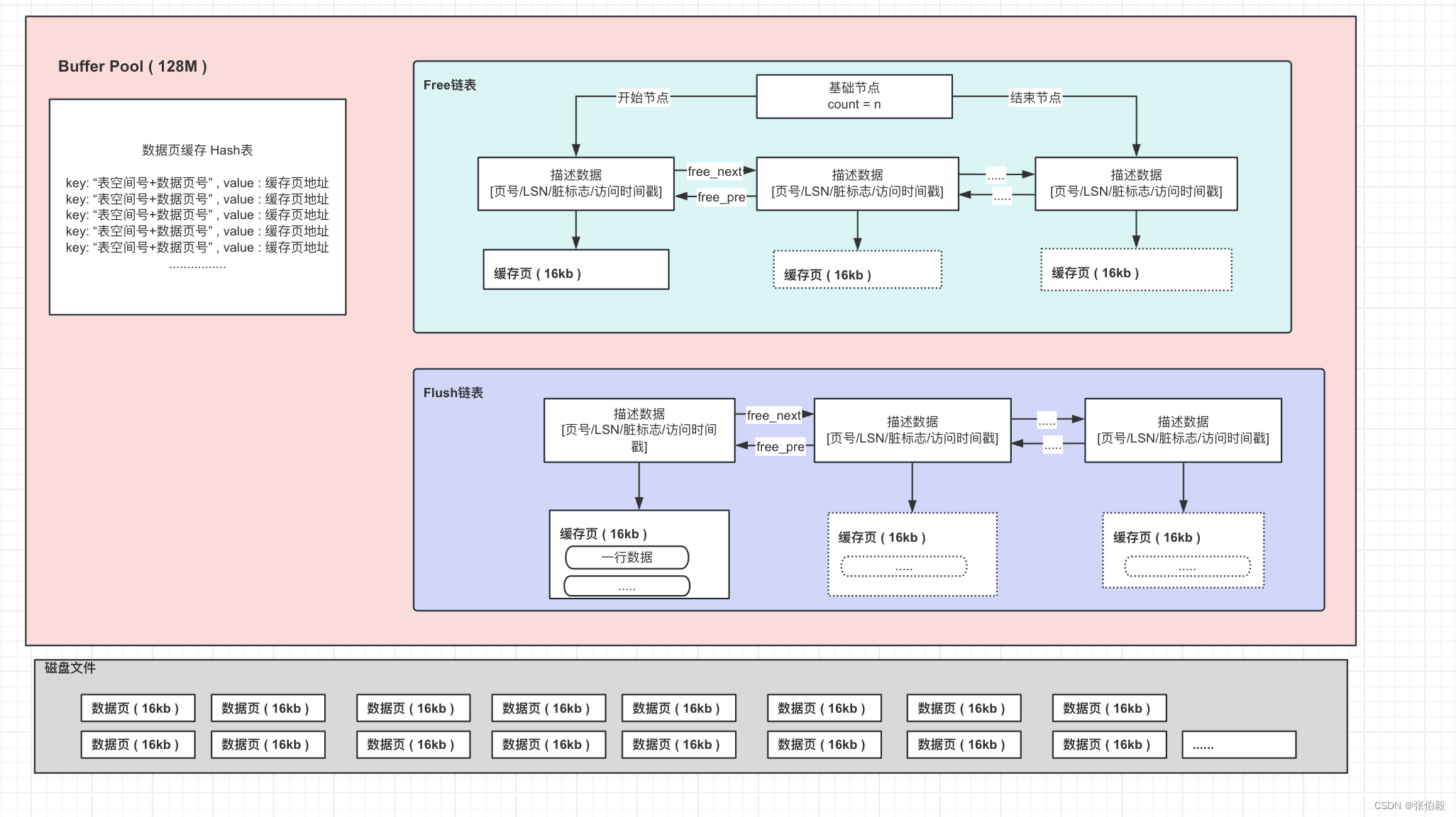
Buffer Pool中的缓存页
在MySQL的InnoDB存储引擎中,Buffer Pool是一个非常重要的内存区域,用于缓存数据和索引,从而减少对磁盘的I/O操作,提高数据库操作的速度。在这个上下文中,"缓存页"是Buffer Pool中的基本单位。
缓存页的概念
-
页(Page):InnoDB存储引擎以页为单位管理数据和索引,一页通常是16KB大小(这是默认值,但可以配置)。无论是数据行还是索引条目,都存储在这些页中。
-
缓存页:当数据被读取(查询)或修改(插入、更新、删除等)时,相关的数据页和索引页会从磁盘加载到Buffer Pool中,这时,这些页就成为了"缓存页"。这意味着它们被缓存于内存中,以便快速访问。
实际上默认情况下, 磁盘中存放的数据页的大小是16KB,也就是说,一页数据包含了16KB的内容。
而Buffer Pool中存放的一个一个的数据页,我们通常叫做缓存页,因为毕竟Buffer Pool是一个缓冲池,里面的数据都是从磁盘缓存到内存去的。
而Buffer Pool中默认情况下,一个缓存页的大小和磁盘上的一个数据页的大小是一一对应起来的,都是16KB。
-
缓存页的类型
脏页(Dirty Page):当一个缓存页上的数据被修改后,该页就变成了脏页。脏页表示它包含的数据与磁盘上的原始数据不同步。InnoDB定期将这些页写回磁盘,以保持数据的持久性和一致性。
干净页(Clean Page):如果一个缓存页上的数据没有被修改,或者虽然被修改但已经被写回磁盘,那么这个页就是干净页。干净页可以在需要为新的数据页腾出空间时无损删除。 -
缓存页的作用
提高数据访问速度:通过将热点数据和索引页缓存在内存中,Buffer Pool可以极大地减少对磁盘的读写需求,从而提高查询和事务处理的速度。
优化数据写入性能:通过合并多个写操作(即将多次对同一数据页的修改累积在一次写回磁盘操作中),减少了磁盘I/O的次数,提高了写入性能。 -
InnoDB使用一种复杂的算法来管理Buffer Pool中的页,包括:
页的加载:当需要访问的数据不在Buffer Pool中时,InnoDB会从磁盘中加载相应的数据页到Buffer Pool中。
页的替换:当Buffer Pool满时,InnoDB需要替换旧的页来为新页腾出空间。InnoDB通常使用LRU(最近最少使用)算法来决定哪些页被替换。
脏页的刷新:InnoDB不断地将脏页异步写回磁盘,以确保数据的持久性和减少系统崩溃时数据丢失的风险。
缓存页对应的描述信息
在MySQL的InnoDB存储引擎中,每个缓存页(即在Buffer Pool中缓存的数据页或索引页)都有对应的描述信息,这些信息帮助InnoDB有效管理和使用Buffer Pool。这些描述信息包括但不限于:
-
页号(Page Number):这是缓存页在其所属的表空间(Tablespace)中的唯一标识符。页号允许InnoDB快速定位并访问特定的缓存页。
-
LSN(Log Sequence Number):每个缓存页包含一个LSN,标识了页的最新修改版本。LSN是InnoDB重做日志(Redo Log)中一个递增的序列号,用于跟踪数据的修改。当一个页被加载到Buffer Pool中,或者在Buffer Pool中被修改时,该页的LSN会被更新。LSN对于数据恢复和确保数据页与重做日志同步至关重要。
-
脏标志(Dirty Mark):如果缓存页自从被加载到Buffer Pool中后发生了修改,就会被标记为“脏页”(Dirty Page)。脏标志指示该页包含未被写回磁盘的修改,需要在适当时机通过CheckPointing机制写回磁盘,以确保数据的持久性。
-
访问时间戳(Access Time Stamp):记录了缓存页最后一次被访问(读取或修改)的时间。这个时间戳是管理Buffer Pool中页的替换策略的重要因素,特别是在使用最近最少使用(LRU)算法时,可以根据访问时间戳来确定哪些页应该被保留,哪些页应该被替换出Buffer Pool。
-
固定计数(Fix Count):表示当前有多少操作正在访问该页。如果一个页被固定(即Fix Count大于0),则它不能被替换出Buffer Pool,因为有操作依赖于这个页的数据。页的固定状态确保了数据的一致性和稳定性。
-
哈希索引(Hash Index):为了快速查找Buffer Pool中的页,InnoDB维护了一个哈希表,将页号映射到Buffer Pool中页的具体位置。这使得根据页号快速定位页成为可能。
在Buffer Pool中,每个缓存页的描述数据放在最前面,然后各个缓存页放在后面
Buffer Pool中的描述数据大概相当于缓存页大小的5%左右,也就是每个描述数据大概是800个字节左右的大小,然后假设你设置的buffer pool大小是128MB,实际上Buffer Pool真正的最终大小会超出一些,可能有个130多MB的样子,因为他里面还要存放每个缓存页的描述数据。
free链表
free链表本质上是一种链表数据结构,用于链接所有被释放的、尚未被重新使用的内存块。每个节点代表一个空闲的内存块,这些节点按照一定规则(如内存块的大小、地址等)组织起来,形成链表。这样当MySQL需要分配内存时,可以通过遍历free链表,快速找到合适大小的空闲内存块进行重用,如果没有合适的内存块,再从内存池中分配新的内存空间。
free链表里面就是各个缓存页的描述数据块,只要缓存页是空闲的,那么他们对应的描述数据块就会加入到这个free链表中,每个节点都会双向链接自己的前后节点,组成一个双向链表
free链表有一个基础节点,他会引用链表的头节点和尾节点,里面还存储了链表中有多少个描述数据块的节点,也就是有多少个空闲的缓存页。
free链表,他本身其实就是由Buffer Pool里的描述数据块组成的,你可以认为是每个描述数据块里都有两个指针,一个是free_pre,一个是free_next,分别指向自己的上一个free链表的节点,以及下一个free链表的节点。
对于free链表而言,只有一个基础节点是不属于Buffer Pool的,他是40字节大小的一个节点,里面就存放了free链表的头节点的地址,尾节点的地址,还有free链表里当前有多少个节点。
- 使用free链表的好处包括:
减少内存碎片:通过重用空闲内存块,减少了内存碎片的产生。
提高内存分配效率:直接从free链表中找到合适的内存块进行分配,避免了每次都从内存池分配新的内存块的开销。
简化内存管理:通过统一的free链表来管理所有的空闲内存块,简化了内存的管理逻辑。
flush链表
flush链表本质也是通过缓存页的描述数据块中的两个指针,让被修改过的缓存页的描述数据块,组成一个双向链表。
凡是被修改过的缓存页,都会把他的描述数据块加入到flush链表中去,flush的意思就是这些都是脏页,后续都是要flush刷新到磁盘上去的
LRU
MySQL中使用的InnoDB存储引擎实现了一种改良的最近最少使用(LRU, Least Recently Used)算法来管理其Buffer Pool中页(数据和索引页)的缓存。这个改良的LRU算法旨在平衡新加入的页和频繁访问的页之间的关系,确保热门数据能够留在内存中,同时给新数据一定的机会证明其是否也可能成为热门数据。以下是InnoDB LRU算法的具体实现细节:
基础LRU列表
- LRU列表:InnoDB的Buffer Pool维护一个LRU列表来记录每个页的使用情况。当一个页被访问时(无论是读取还是写入),如果它已经在Buffer Pool中,则它会被移动到LRU列表的前端,表示它最近被使用过。如果一个新页被读取进来且Buffer Pool已满,那么LRU列表末尾(即最长时间未被使用的页)将被移除以腾出空间。
改良策略
- 分区:InnoDB将其LRU列表分为两个部分,一个是用于存储最近访问较多的“热”页的“young”区域,另一个是用于存储其他页的“old”区域。默认情况下,“young”区域占LRU列表的约63%,而“old”区域占37%。
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_old_blocks_pct | 37 |
+-----------------------+-------+
1 row in set (0.00 sec)
-
中点插入策略(Mid-Point Insertion Strategy):在InnoDB中,新读取的页不是直接被放到LRU列表的最前端,而是被插入到“old”和“young”区域的分界点。这种方法给新页一个机会,让它们在被确认为不够“热门”而从列表中移除之前,有一段时间可以被访问和使用。如果这些页在“old”区域中被访问,它们会被移动到LRU列表的前端,即“young”区域。
-
访问控制:为了进一步控制页在LRU列表中的移动,InnoDB引入了一个机制,其中只有当一页在“old”区域被访问的次数超过一定阈值时,这个页才会被移动到“young”区域。这个阈值可以通过
innodb_old_blocks_time参数设置,该参数指定一个页必须在“old”区域中停留的最小时间(以毫秒为单位),在此期间页的访问不会导致它被移动到“young”区域。
总结
InnoDB通过这种改良的LRU算法有效地管理Buffer Pool中的数据和索引页,既保证了频繁访问的热门数据能够快速被访问,又为新页提供了一定的空间和机会展示其重要性。这种平衡策略对于数据库的性能优化至关重要,有助于提高缓存效率和查询性能。
MySQL的预读机制
MySQL的预读机制主要与其底层存储引擎的实现有关,尤其是InnoDB存储引擎。预读(Pre-reading)或预取(Prefetching)是一种性能优化技术,其中数据库系统主动读取可能很快就会被查询到的数据页到缓冲池(Buffer Pool)中,即使这些数据页此刻还没有被直接请求。这样做的目的是减少等待I/O操作完成的时间,从而提高查询性能。
在MySQL的InnoDB存储引擎中,预读机制可以在以下情况下被触发:
-
- 顺序扫描
当InnoDB检测到对表的顺序扫描操作时,它可能会预读更多的数据页到缓冲池中。顺序扫描通常发生在全表扫描或索引扫描时,此时InnoDB会预测接下来会访问哪些数据页,并尝试提前将它们加载到内存中。
-
- 范围查询
在对索引进行范围查询时(如使用BETWEEN、>、<等操作符),如果数据库发现查询正在按顺序访问大量连续的数据页,它可能会启动预读,因为系统推测接下来的查询将继续沿着这个范围进展。
-
- 索引扫描
在进行索引扫描时(尤其是对主键或唯一索引的扫描),如果扫描操作按照顺序访问索引页,InnoDB也可能会执行预读,尝试提前加载可能会被访问的数据页。
-
- 背景预读
InnoDB也有一些背景操作,可能在系统空闲时自动进行数据页的预读。这些操作依赖于InnoDB的内部调度和优化决策,目的是优化数据在缓冲池中的布局,提高缓冲池的命中率。
- 配置和限制
值得注意的是,预读的行为可以通过一系列的配置参数来调整,例如innodb_read_ahead_threshold,这个参数用来设置InnoDB启动线性预读操作之前要观察到的顺序访问的页面数量。此外,操作系统和硬件的能力也影响预读的效率,例如磁盘的I/O性能和操作系统的文件系统缓存策略。
总的来说,MySQL(特别是InnoDB存储引擎)的预读机制旨在通过智能预测即将需要的数据,提前将这些数据加载到内存中,以减少数据库操作的磁盘I/O需求,从而提高整体的查询性能。然而,过度的预读可能会消耗过多的系统资源,因此需要根据具体的工作负载和系统配置适当调整。
- innodb_read_ahead_threshold 默认值为56
如果顺序的访问了一个区里的多个数据页,访问的数据页的数量超过了这个阈值,此时就会触发预读机制,把下一个相邻区中的所有数据页都加载到缓存里去
mysql> SHOW VARIABLES LIKE 'innodb_read_ahead_threshold';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| innodb_read_ahead_threshold | 56 |
+-----------------------------+-------+
1 row in set (0.01 sec)
- innodb_random_read_ahead 默认关闭
如果Buffer Pool里缓存了一个区里的13个连续的数据页,而且这些数据页都是比较频繁会被访问的,此时就会直接触发预读机制,把这个区里的其他的数据页都加载到缓存里去
这个机制是通过参数innodb_random_read_ahead来控制的,他默认是OFF,也就是这个规则是关闭的
mysql> SHOW VARIABLES LIKE 'innodb_random_read_ahead';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_random_read_ahead | OFF |
+--------------------------+-------+
1 row in set (0.00 sec)
冷热数据分离的思想设计LRU链表
真正的LRU链表,会被拆分为两个部分,一部分是热数据,一部分是冷数据,这个冷热数据的比例是由innodb_old_blocks_pct参数控制的,他默认是37,也就是说冷数据占比37%。
- 查看配置参数
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_old_blocks_pct | 37 |
+-----------------------+-------+
1 row in set (0.00 sec)
所以MySQL设定了一个规则,他设计了一个innodb_old_blocks_time参数,默认值1000,也就是1000毫秒
mysql>
mysql>
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_time';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_old_blocks_time | 1000 |
+------------------------+-------+
1 row in set (0.00 sec)
也就是说,必须是一个数据页被加载到缓存页之后,在1s之后,你访问这个缓存页,他才会被挪动到热数据区域的链表头部去。
因为假设你加载了一个数据页到缓存去,然后过了1s之后你还访问了这个缓存页,说明你后续很可能会经常要访问它,这个时间限制就是1s,因此只有1s后你访问了这个缓存页,他才会给你把缓存页放到热数据区域的链表头部去。