文章目录
- 一、背景
- 二、实验
- 2.1 测评标准和结果
- 2.1.1 文本识别 Text Recognition
- 2.1.2 场景文本中心的视觉问答 Scene Text-Centric VQA
- 2.1.3 文档导向的视觉问答 Document-Oriented VQA
- 2.1.4 关键信息提取 Key Information Extraction
- 2.1.5 手写数学公式识别 Handwritten Mathematical Expression Recognition(HMER)
- 2.2 结果
- 2.3 OCRBench
- 三、讨论
论文:ON THE HIDDEN MYSTERY OF OCR IN LARGE MULTIMODAL MODELS
代码:https://github.com/Yuliang-Liu/MultimodalOCR
出处:华中科技大学 | 微软 等
时间:2024.01
贡献:
- 本文作者在 5 个和文本相关的任务上测评了 14 个 LMM 的效果
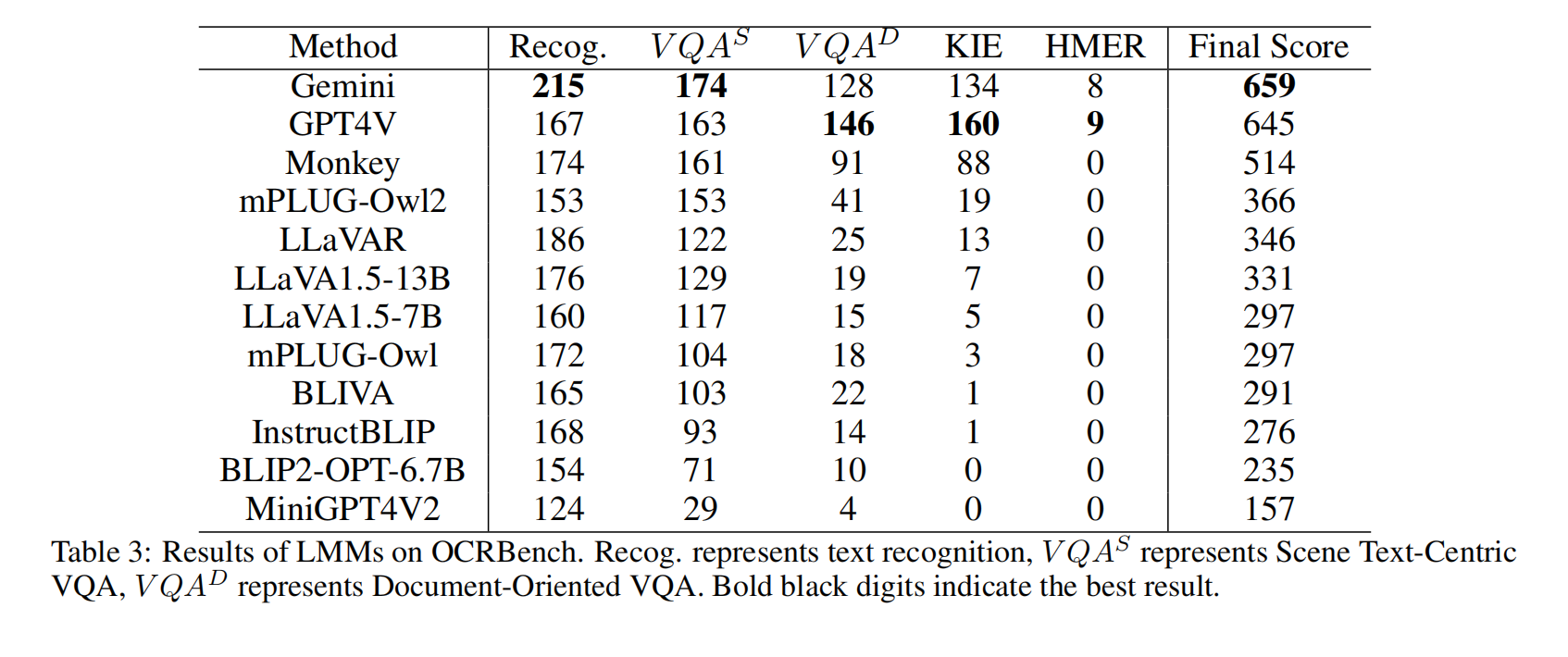
- 作者提出了 OCRBench 来进一步衡量 LMM 模型的 OCR 能力,OCRBench 包含1000个手工筛选并纠正的问题-答案对儿的集合,涵盖了五项代表性的与文本相关的任务。
一、背景
大语言模型的成功近期已经扩展到了多模态大模型的成功,催生了很多多模态大模型,包括对比学习和生成式模型,当然 OCR 领域也不例外
Visual instruction tuning [15] 这篇文章展示了 zero-shot OCR 在室外环境下良好的效果,而且是没有在 OCR domain 数据训练过的模型,这也很好的证明了大多模态模型(LMM)能够很好的处理和文本相关的视觉任务,但该模型不能很好的处理复杂的数据
所以,本文作者在 14个 LMM 模型上测试了 OCR 能力,包括 5 个任务:
- text recognition
- Scene Text-Centric VQA
- Document-Oriented VQA
- key information extraction
- handwritten mathematical expression recognition
作者发现,尽管很多很好的 LMM 模型在传统的 text 任务上表现的还算好,但在其他复杂的 text 任务的表现很差。SOTA 模型 Gemini[16] 和 GPT4V[17] 也很难很好的识别手写数学公式, LMM 模型在模糊文本、首先文本、多语言文本上的表现都不是很好,此外,由于大多模态模型主要还是会依赖语义理解来识别单词,所以会倾向于输出常见的单词。
使用的模型:

二、实验
2.1 测评标准和结果
由于 LMM 生成的结果包括很多解释性的术语(就是一些对特定场景进行充分介绍和解释所用到的词语),所以无法使用【精确匹配】或【Average Normalized Levenshtein Similarity(ANLS) 】等常用的衡量方式来衡量 LMM 输出的质量。
所以本文作者为所有数据集定义了一个统一的评估标准: GT 是否出现在 LMM 的输出中
为了减少 false positives(假阳性),作者过滤掉了数据集中答案少于 4 个符号的问题,此外还从大型数据集中选择了 3000 个问题用于测试。
在自然语言处理和信息检索等领域,假阳性(false positives)是指错误地将非相关或错误的信息识别为正确的结果。在评估语言模型时,尤其是在自动评估回答的正确性时,假阳性会导致评估结果的准确性下降。
作者选择过滤掉答案少于4个符号的问题,可能是基于以下几个原因:
-
简短答案的歧义性:非常短的答案可能具有高度的歧义性,因为短答案(例如单个字或短语)可能在不同的上下文中有不同的含义。这使得在没有充分上下文的情况下准确评估这些答案变得困难。
-
增加匹配难度:如果一个答案非常简短,例如只有一个单词或几个字符,那么它可能会在语言模型生成的文本中随机出现,而不是因为模型正确理解了问题。这可能导致评估过程中的假阳性结果增加。
-
评估方法的限制:某些评估方法,如基于编辑距离(例如Levenshtein距离)的方法,在处理非常短的文本时可能不够准确,因为即使是一个小的变化也会导致很大的相似度比率变化。
-
提高评估质量:通过排除这些可能导致评估方法产生误判的简短答案,可以提高评估过程的整体质量和可靠性。
-
确保有意义的评估:更长的答案往往能够提供更多的信息和上下文,有助于更准确地评估模型的性能。简短答案可能无法充分反映模型对问题的理解深度。
-
因此,排除答案少于4个符号的问题有助于减少评估过程中的噪声,确保评估结果更加准确和有意义。
2.1.1 文本识别 Text Recognition
作者使用了使用广泛的 OCR text recognition 数据集来测评 LMM,包括
- Regular Text Recognition: IIIT5K [34], SVT [35], IC13 [36]
- Irregular Text Recognition: IC15 [37], SVTP [38], CT80 [39],COCOText(COCO) [40], SCUT-CTW1500 (CTW) [41], Total-Text (TT) [42]
- Occlusion Scene Text [43], encompassing weakly occluded scene text (WOST) and heavily occluded scene text (HOST)
- Artistic Text Recognition WordArt [44]
- Handwirtten Text Recognition: IAM [45]
- Chinese Text Recognition: ReCTS [46]
- Handwritten Digit String Recognition: ORAND-CAR-2014(CAR-A) [47]
- Non-Semantic Text(NST) and Semantic Text(ST): LMMs 主要是依赖于语音理解来识别单词
作者发现 LMM 在缺乏语义上下文的场景中的识别效果不太好,比如只有公式的场合
为了证明这个结论,作者使用 IIIT5k dictionary 构建了 2 个 datasets:Semantic Text(ST) 和 Non-Semantic Text(NST):
- ST:包含 3000 个图片,其中的 words 都是从 IIIT5k dictionary 拿的
- NST:包含和 ST 同样的 words,但是打乱顺序了,没有语义信息
- 对英文 words,作者的 prompt 是 “what is written in the image?”
- 对于中文 words,prompt 是 “what are the Chinese characters in the image?”
- 对于手写数字,prompt 是 “what is the number in the image?”
2.1.2 场景文本中心的视觉问答 Scene Text-Centric VQA
“Scene Text-Centric VQA”(场景文本中心的视觉问答)是指一种特定类型的视觉问答任务,其中重点放在理解和回答与图像中的文本内容相关的问题。“场景文本”指的是图片中自然出现的文本,如路标、广告牌、菜单、标签等。
在传统的视觉问答(VQA)任务中,通常要求模型回答与图像内容相关的问题,这些内容可能包括物体、动作、场景、颜色等各种视觉元素。然而,在Scene Text-Centric VQA 中,问题的焦点是图像中的文本信息。这要求模型不仅能够识别和理解图像中的视觉元素,还要能够读取和理解图像中的文本,并结合这两方面的信息来回答问题。
例如,如果给定一张带有商店招牌的图片,一个 Scene Text-Centric VQA 的问题可能是“这家店主要卖什么?”为了回答这个问题,模型需要能够识别并理解招牌上的文字,并可能需要结合其他视觉线索来提供答案。
这种类型的VQA任务对于机器学习和计算机视觉研究领域来说是具有挑战性的,因为它需要高级的图像处理和自然语言处理能力的结合。
作者测试了 STVQA [48], TextVQA [49], OCRVQA [50] 和 ESTVQA [51] 上测试了 LMM 的效果
- 场景文本视觉问答(STVQA)包括来自各种公共数据集的 23,000 多张图片上的 31,000 多个问题。
- TextVQA数据集包含从特定 OpenImages 数据集类别中抽样的 28,000 多张图片上的 45,000 多个问题,这些类别预计包含文本。
- OCRVQA 拥有超过1百万个问题-答案对,涵盖 207,000 多张书籍封面图片。
- ESTVQA 包含 20757张图片以及15056个英文问题和13006个中文问题。作者将ESTVQA数据集分为ESTVQA(CN)和ESTVQA(EN),分别专门包含中文或英文的问题和答案。
2.1.3 文档导向的视觉问答 Document-Oriented VQA
Document-Oriented VQA(文档导向的视觉问答)是指一种专注于处理和理解文档图像内容的视觉问答任务。在这种类型的任务中,问题是关于文档图像中的信息,这些文档可能包括表格、发票、信件、报告、表单等各种印刷或手写的文件。
与场景文本中心的VQA(Scene Text-Centric VQA)不同,Document-Oriented VQA专注于更结构化的文档内容,其中文本的布局和格式对于理解和回答问题至关重要。这种类型的VQA任务要求算法不仅要识别和提取文档中的文本,还要理解文档的结构和语义信息。
例如,在Document-Oriented VQA中,系统可能会被问到:“这张发票的总金额是多少?”为了回答这个问题,模型需要能够定位发票上的总金额字段,识别数字,并正确解释该数字的含义。
Document-Oriented VQA是自然语言处理、计算机视觉和机器学习领域的一个重要研究方向,因为它涉及到复杂的文本识别、文档布局分析和理解等问题。这对于自动化文档管理、信息提取和数据分析等应用场景具有重要意义。
作者在 DocVQA[52], InfographicVQA [53] 和 ChartQA [54] 上测试了效果
- DocVQA是一个大规模数据集,包含12,767张不同类型和内容的文档图片,以及50,000多个问题和答案。
- InfographicVQA是一个包含5,485张信息图表和总共30,035个问题的多样化集合。
- ChartQA包括总共9,608个关于4,804张图表的人工编写的问题,以及基于17,141张图表的人工编写的图表摘要生成的23,111个问题。
2.1.4 关键信息提取 Key Information Extraction
作者在 SROIE [55]、FUNSD [56] 和 POIE [57] 数据集上进行了实验:
- SROIE包含1000张完整的扫描收据图像,用于OCR和关键信息提取效果对比。在这个对比中,需要基于收据提取公司、日期、地址和总支出信息。
- FUNSD数据集由199张实际的、完全注释的、可能包含噪声的扫描表格组成。
- POIE由产品营养成分标签的英文相机图像组成,收集了3,000张图像,包含111,155个文本实例。KIE数据集要求提取图像中的关键值对。
为了使大型语言模型(LMMs)能够准确地从 KIE 数据集中提取给定键的正确值,作者采用了手动提示设计。
对于SROIE数据集,使用以下提示来帮助LMMs生成"公司"、“日期”、"地址"和"总计"的相应值:
- “这张收据是哪家公司开的?”
- “这张收据是什么时候开的?”
- “这张收据是在哪里开的?”
- “这张收据的总金额是多少?”。
此外,为了在 FUNSD 和 POIE 中检索给定键的对应值,作者使用提示:“What is the value for ‘{key}’?”
2.1.5 手写数学公式识别 Handwritten Mathematical Expression Recognition(HMER)
作者在 HME100K[58] 上测试了相关效果,这个数据集包括 74502 张训练图片,24607 张测试图片,245 个公式类别
在测试时作者使用的 prompt 是 “Please write out the expression of the formula in the image using LaTeX format.”.
2.2 结果
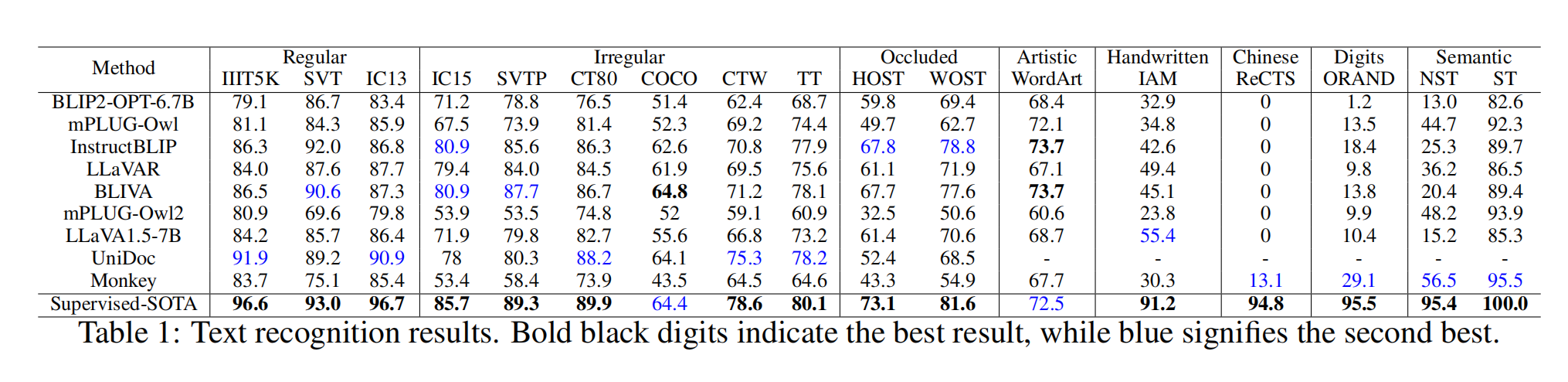
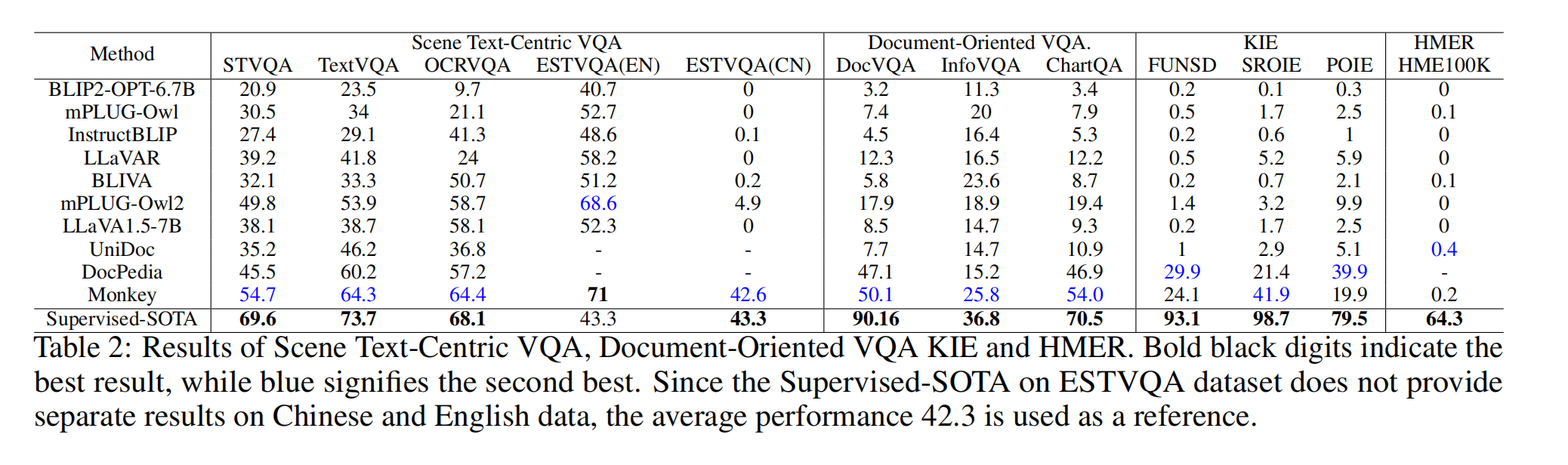
表1显示了文本识别的结果。在识别规则文本、不规则文本、被遮挡文本和艺术文本方面,大型语言模型(LMMs)的性能与最新的监督模型相当。即使在主要包含挑战性艺术文本的WordArt数据集中,InstructBLIP2和BLIVA也超越了监督的最新模型的性能。然而,LMMs在识别手写文本、中文文本、手写字符串和非语义文本方面表现不佳。在场景文本中心的视觉问答(VQA)、面向文档的VQA和知识信息提取(KIE)等任务中,输入分辨率较小的LMMs与输入分辨率较大的模型相比,一致地产生了较差的结果。这是因为文本通常包含复杂的结构,并且大小各异,需要LMMs捕捉精细的细节。结果显示在表2中。LMMs在完成识别手写数学表达式的复杂任务方面挣扎。通过广泛分析结果,作者从定性的角度总结了LMMs在文本任务中的局限性:
1、语义依赖性
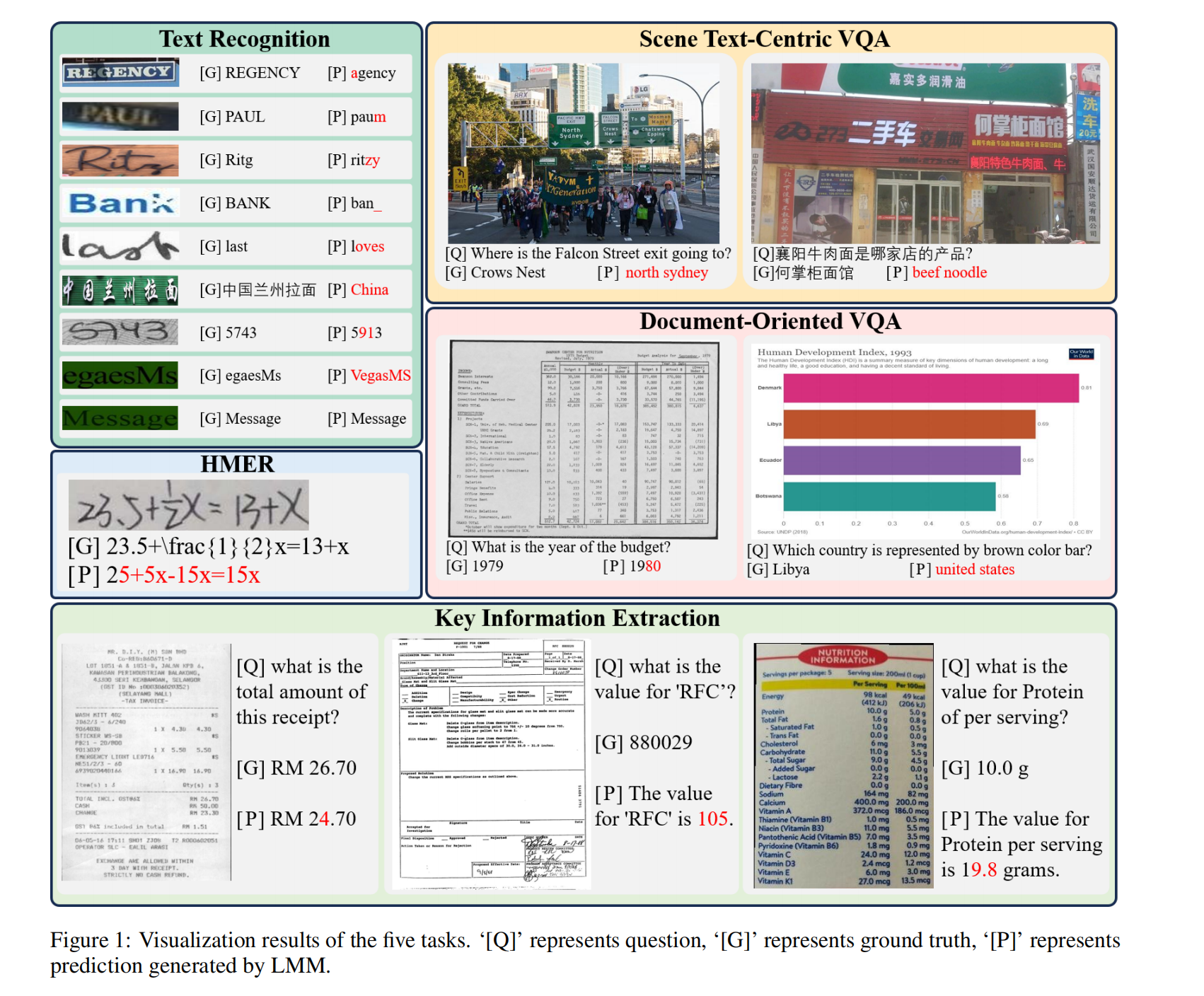
当遇到缺乏语义意义的字符组合时,大型语言模型(LMMs)表现出较差的识别性能。具体来说,当改变每个单词中字母的顺序时,LMMs 在NST数据集上的准确率平均下降了57.0%,而最新的场景文本识别方法仅下降了大约 4.6%。作者认为这是因为场景文本识别的最新方法直接识别每个字符,语义信息只是用来辅助识别过程,而LMMs主要依赖于语义理解来识别单词。这一发现进一步得到了在ORAND数据集上观察到的低准确率的支持。如图1所示,LMM成功识别了单词“Message”,但错误地识别了“egaesMs”,这是单词“Message”的字母重新排列版本。
2、手写文本
由于包括手写字母和数字之间的形状相似性在内的各种原因,LMMs可能在准确识别手写文本方面遇到困难。由于快速书写速度、不规则的书写或低质量的纸张等因素,手写文本通常看起来不完整或模糊。平均而言,LMMs在这项任务上的表现比有监督的最新模型差51.9%。
3、多语言文本
LMMs 在 ReCTS、ESTVQA(En) 和 ESTVQA(Ch) 上的表现说明,LMM 在中文上的表现不及预期,如表1和表2所示。在LMMs中,很难准确识别中文单词或回答中文问题。Monkey 在中文场景中的表现优于其他LMMs,这是由于其LLM和视觉编码器在大量中文数据上进行了训练,
4、细粒度感知。
目前,大多数 LMMs 的输入图像分辨率限制为 224 x 224,与它们架构中使用的视觉编码器的输入尺寸一致。然而,高分辨率输入图像能够捕捉图像中更多的细节。由于像 BLIP2 这样的 LMMs 输入分辨率的限制,它们在场景文本中心的VQA、面向文档的VQA和KIE等任务中提取细粒度信息的能力受到限制。然而,像Monkey这样可以支持1344×896分辨率的LMMs,在这些特定任务中表现出了改进的性能。
5、HMER
由于存在凌乱的手写字符、复杂的空间结构和间接的 LaTeX 表示,LMMs难以识别手写数学表达式。缺乏针对手写数学表达式识别任务的训练数据也是一个关键因素。
2.3 OCRBench
评估多个数据集非常耗时,而且某些数据集中的不准确标注使得基于准确性的评估变得不那么精确。
所示作者收集了一个标准测评基准:OCRBench,以便准确和方便地评估LMMs的OCR能力。
OCRBench包含五个组成部分,包括1000个问题-答案对:
- 文本识别
- 场景文本中心的VQA
- 面向文档的VQA
- KIE:且对于KIE任务,作者添加了提示“直接使用图像中的文本回答这个问题。”来限制模型的响应格式
- HMER
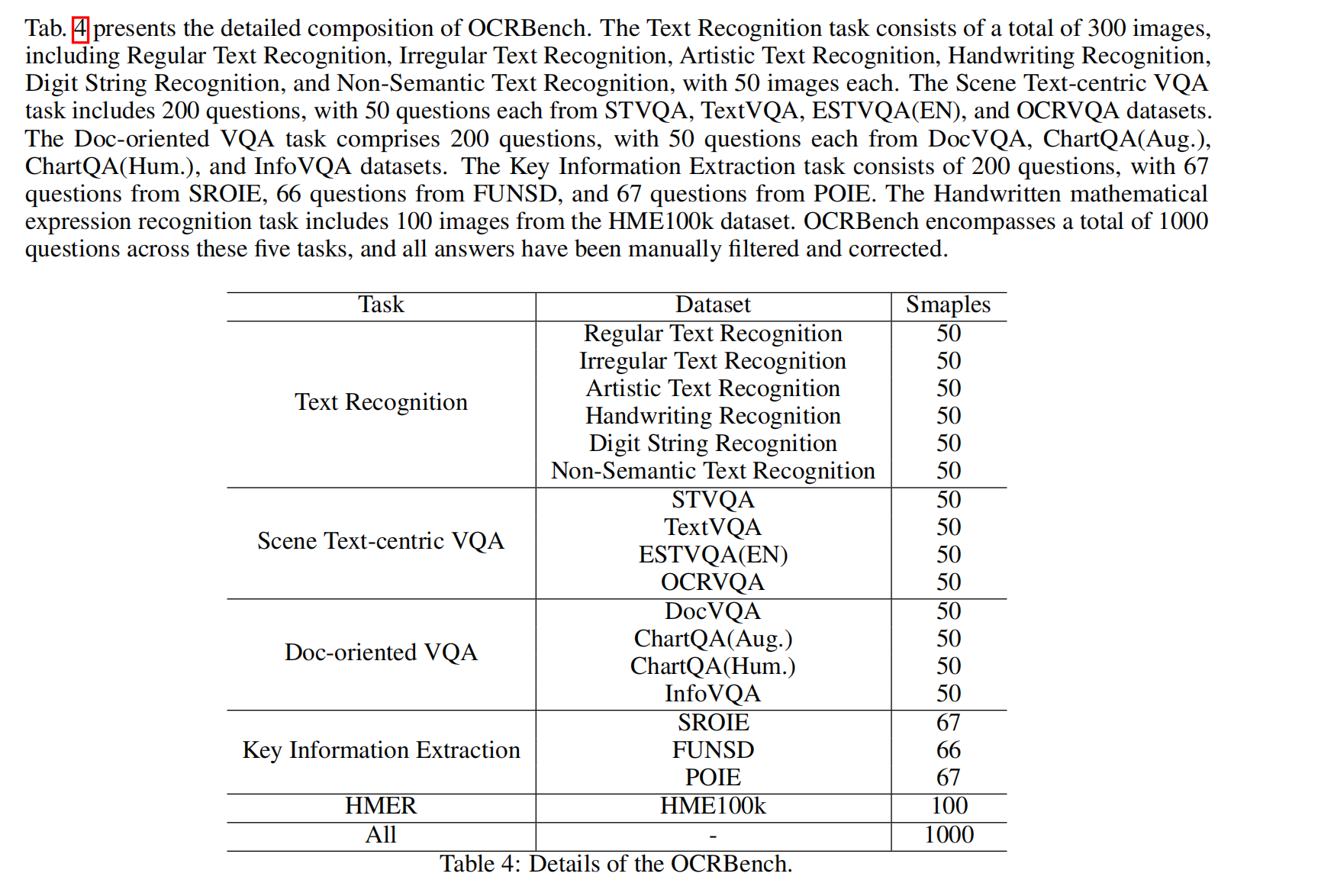
结果见表 3 ,Gemini获得了最高分,GPT4V 位居第二(而且由于 OPEN AI 的严格安全审查,GPT4V 拒绝提供 OCRBench 中 84 张图片的结果)。
Monkey展示的 OCR能力仅次于 GPT4V 和 Gemini。从测试结果来看,即使是像GPT4V和Gemini这样的最先进模型也在 HMER 任务上挣扎。此外,它们在处理不清晰的图像、手写文本、非语义文本以及遵守任务指令方面也面临挑战。如图2(g)所示,即使明确要求使用图像中找到的文本回答问题,Gemini也一致地将“02/02/2018”解释为“2018年2月2日”。

三、讨论
大型多模态模型(LMM)之所以能在 OCR 任务中表现出较好的性能,一个可能的解释是这些模型(类似于CLIP)的训练中包含了一些OCR数据。然而,训练数据中的无监督文本-图像对与全监督数据相比还是有差距。
从网络的角度来看,视觉编码器和大型语言模型(LLM)预训练模型已经在各自的领域数据中展现出了强大的掌握能力,每个模型都在其结构化的特征空间内运作。这些LMM通过诸如线性投影层这样的组件来桥接视觉和语言信息,该层功能类似于视觉标记化的步骤。这个过程将视觉标记与预训练语言模型的词嵌入空间对齐,从而产生与对应词嵌入紧密相连的视觉嵌入。这种对齐促进了文本识别,LLM随后以生成性的方式将这些OCR数据展示给用户。
未来的研究可以通过剥离分析来了解多模态训练数据量对OCR性能的影响。
未来方向:这些模型应该专注于提炼在图像中检测细粒度特征的能力,增强对单个字符形状的理解,并构建用于训练的多语言数据。
最近的研究,例如ICL-D3IE [59],引入了一个利用像GPT-3和ChatGPT这样的大型语言模型的上下文学习框架,用于文档信息提取。这种方法有效地解决了在这一领域的模态差异和任务差异,能够从难以训练的文档中提取出具有挑战性和独特性的段落,设计关系演示以增强位置理解,并融入格式演示以提取答案。尽管在不同的数据集和设置中取得了显著的成功,ICL-D3IE在CORD [60]的领域内设置中遇到了挑战。这一结果指向了大型语言模型在处理视觉复杂文档的任务中的潜力,并鼓励开发新颖的、最少监督的OCR技术。
此外,[61]评估了ChatGPT在七个详细的信息提取任务中的表现。这一评估揭示了ChatGPT在OpenIE设置中表现良好,生成高质量的响应,显示出过度自信的倾向,并且对原始文本保持了强烈的忠实度。然而,这项研究专门关注纯文本,没有涉及OCR领域内的视觉丰富文档文本。因此,未来的研究应该探索ChatGPT在这些视觉丰富的环境中的表现。
在专业领域中应用大型语言模型(LMMs)也是一个关键的领域,最近的发展显示了它们巨大的潜力。谷歌开发的一个此类模型是Med-PaLM2 [62],它在PaLM2的医学知识上进行了微调。它是第一个在美国医学执照考试(USMLE)风格的问题上表现出专家级别的语言模型,并且可以通过医学图像分析病人的状况,包括平片和乳房X光片。谷歌声称其性能已接近临床专家。此外,LLaVA-Med [63]尝试将多模态指令调整扩展到生物医学领域,并展示出具有领域知识的出色聊天能力。这些研究突出了LMM在垂直领域任务中的潜力。进一步探索它们在其他领域如游戏和教育中的应用也是值得的。
最终,这些发展和未来的研究方向可能会为多模态模型铺平道路,这些模型可以更有效地处理像OCR这样的复杂任务,扩大了LMM的应用范围。