自动伸缩 API
创建或更新自动伸缩策略 API
此特性设计用于 Elasticsearch Service、Elastic Cloud Enterprise 和 Kubernetes 上的 Elastic Cloud 的间接使用。不支持直接用户使用。
创建或更新一个自动伸缩策略。
请求
PUT /_autoscaling/policy/<name>
{
"roles": [],
"deciders": {
"fixed": {
}
}
}前置条件
-
如果 Elasticsearch 安全特性启用,你必须有
manage_autoscaling集群权限来使用此 API。 -
如果启用了操作员权限特性,则只有操作员用户可以使用此 API。
描述
此 API 使用提供的名称修改自动伸缩策略。关于可用的决策器,参阅自动伸缩决策器。
示例
此示例使用固定的自动缩放决策器,将名为 my_autoscaling_policy 的自动缩放策略应用于(仅)具有 “data_hot” 角色的节点集。
PUT /_autoscaling/policy/my_autoscaling_policy
{
"roles" : [ "data_hot" ],
"deciders": {
"fixed": {
}
}
}删除自动伸缩策略 API
此特性设计用于 Elasticsearch Service、Elastic Cloud Enterprise 和 Kubernetes 上的 Elastic Cloud 的间接使用。不支持直接用户使用。
删除自动伸缩策略。
请求
DELETE /_autoscaling/policy/<name>
前置条件
-
如果 Elasticsearch 安全特性启用,你必须有
manage_autoscaling集群权限来使用此 API。 -
如果启用了操作员权限特性,则只有操作员用户可以使用此 API。
描述
此 API 使用提供的名称删除一个自动伸缩策略。
示例
此示例删除一个名为 my_autoscaling_policy 的 自动伸缩策略。
DELETE /_autoscaling/policy/my_autoscaling_policy
此示例删除所有自动伸缩策略。
DELETE /_autoscaling/policy/*
获取自动伸缩容量 API
请求
GET /_autoscaling/capacity/前置条件
- 如果 Elasticsearch 安全特性启用,你必须有
manage_autoscaling集群权限来使用此 API。
描述
此 API 根据配置的自动伸缩策略获取当前自动缩放容量。此 API 将返回信息,以根据当前工作负载适当调整集群大小。
required_capacity 计算为针对策略启用的所有单个决策者的 required_capacity 结果的最大值。
操作员应验证 current_nodes 是否与操作员对集群的了解相匹配,以避免根据陈旧或不完整的信息做出自动伸缩决策。
响应包含特定于决策者的信息,你可以使用这些信息诊断自动缩放如何以及为什么确定需要某个容量。此信息仅用于诊断。不要使用此信息进行自动伸缩决策。
响应体
-
policies(对象)包含策略名称到容量结果的映射
-
policies属性-
<policy_name>(对象)包含策略的容量信息。-
<policy_name>属性-
required_capacity(对象)包含策略所需的容量。required_capacity属性node(对象)包含每个节点所需的最小节点大小,确保单个碎片或机器学习(ML)作业可以装入单个节点。node属性storage(整数)每个节点所需的存储字节数。memory(整数)每个节点所需的内存字节数。
total(对象)包含策略所需的总大小。total属性storage(整数)策略所需的总存储字节数。memory(整数)策略所需的总内存字节数。
-
current_capacity(对象)包含受策略控制的节点的当前容量,即 Elasticsearch 计算所基于的节点。current_capacity属性node(对象)包含由策略管理的节点的最大大小。node属性storage(整数)节点的最大存储字节数。memory(整数)节点的最大内存字节数。
total(对象)包含受策略控制的节点的当前总存储和内存大小。total属性storage(整数)可用于策略的当前存储字节数。memory(整数)可用于策略的当前内存字节数。
-
current_nodes(对象数组)用于容量计算的节点列表。current_nodes中元素的属性name(字符串)节点名字。
-
deciders(对象)容量是由单个决策者得出的结果,允许深入了解外部级别required_capacity是如何计算的。deciders属性<decider_name>(对象)为策略启用的特定决策器的容量结果。<decider_name>属性required_capacity(对象)由决策器确定的所需容量。required_capacity属性node(对象)包含每个节点所需的最小节点大小,确保单个分片或机器学习作业可以装入单个节点。node属性storage(整数)每个节点所需的存储字节数。memory(整数)每个节点所需的内存字节数。
total(对象)包含策略所需的总大小。total属性storage(整数)策略所需的总存储字节数。memory(整数)策略所需的总内存字节数。
reason_summary(字符串)描述决策器结果的依据。reason_details(对象)每个决策器的结构,包含决策器结果基础的详细信息。内容不应用于应用目的,也不受向后兼容性保证的约束。
-
-
-
-
示例
此示例获取当前自动伸缩容量。
复制代码
GET /_autoscaling/capacity
此 API 返回以下结果:

获取自动伸缩策略 API
请求
GET /_autoscaling/policy/<name>前置条件
- 如果 Elasticsearch 安全特性启用,你必须有
manage_autoscaling集群权限。更多信息,参阅安全权限。
描述
此 API 获取指定名字的自动伸缩策略。
示例
此示例获取名为 my_autoscaling_policy 自动伸缩策略。
GET /_autoscaling/policy/my_autoscaling_policy此 API 返回以下结果:

紧凑和对齐文本(CAT)API
JSON 用于计算机很棒。即使它的显示格式很好,但试图在数据中找到关系也是乏味的。人类的眼睛,尤其是在看终端时,需要紧凑和对齐的文本。紧凑和对齐文本(CAT)API 旨在满足这一需求。
cat API 仅用于使用 Kibana 控制台或命令行的人使用。它们不适用于应用程序。对于应用程序使用,我们建议使用相应的 JSON API。
所有 cat 命令都接受查询字符串参数 help 以查看它们提供的所有标题和信息,而 /_cat 命令单独列出了所有可用的命令。
普通参数
冗长(Verbose)
每个命令都接受一个查询字符串参数 v 以打开详细输出。例如:
GET _cat/master?v=true
可能响应:

帮助(help)
每个命令都接受一个查询字符串参数 help,该帮助将输出其可用列。例如:
GET _cat/master?help
可能响应:

如果使用任何可选的 url 参数,则不支持 help。例如 GET _cat/shards/my-index-000001?help 或 GET _cat/indices/my-index-*?help 会导致错误。使用 GET _cat/shards?help 或 GET _cat/indices?help 替代。
头(Headers)
每个命令都接受一个查询字符串参数 h,该参数仅强制显示这些列。例如:
GET _cat/nodes?h=ip,port,heapPercent,name
响应:
![]()
你还可以使用简单的通配符请求多个列,例如 /_cat/thread_pool?h=ip,queue* 以获取以 queue 开头的所有头(或别名)。
数字格式
许多命令提供几种类型的数字输出,可以是字节、大小或时间值。默认情况下,这些类型是人工格式化的,例如,3.5mb 而不是 3763212。人的价值观是不可数字排序的,所以为了在顺序重要的地方对这些价值观进行操作,你可以更改它。
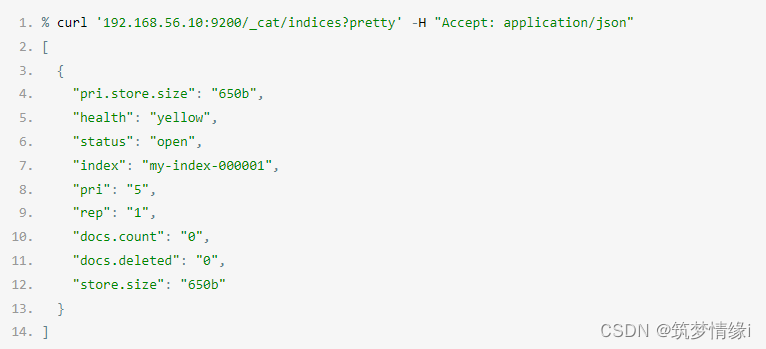
假设您要查找集群中最大的索引(所有分片使用的存储,而不是文档数量)。 /_cat/index API 非常理想。您只需向API请求中添加三项内容:
bytes查询字符串参数的值为b,以获得字节级结果。- 值为
store.size:desc的s(sort,排序)参数,以及逗号分隔的index:asc,将输出结果按分片存储大小降序,再按索引名字升序排列。 v(冗长,verbose)参数,用于在响应中包括列标题。GET _cat/indices?bytes=b&s=store.size:desc,index:asc&v=true
此 API 返回以下响应:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open my-index-000001 u8FNjxh8Rfy_awN11oDKYQ 1 1 1200 0 72171 72171
green open my-index-000002 nYFWZEO7TUiOjLQXBaYJpA 1 0 0 0 230 230如果你想修改 time units_apis-rest_apis-api_convention-common_options?id=时间单位),使用 time 参数。
如果你想修改 size units_apis-rest_apis-api_convention-common_options?id=无单位数量),使用 size 参数。
如果你想修改 byte units_apis-rest_apis-api_convention-common_options?id=字节大小单位),使用 bytes 参数。
以文本(text)、json、smile、yaml 或 cbor 形式响应

当前支持的格式(如 ?format= 参数):
- text(默认)
- json
- smile
- yaml
- cbor
或者,你可以将 “Accept” HTTP 头设置为适当的媒体格式。支持上述所有格式,GET 参数优先于标头。例如:
排序
每个命令都接受一个查询字符串参数 s,该参数按指定为参数值的列对表进行排序。列按名称或别名指定,并以逗号分隔的字符串形式提供。默认情况下,排序以升序方式完成。向列追加 :desc 将颠倒该列的顺序 :asc 也支持,但表现出与默认排序顺序相同的行为。
例如,对于排序字符串 s=column1,column2:desc,column3,表将按 column1 升序、column2 降序和 column3 升序进行排序。
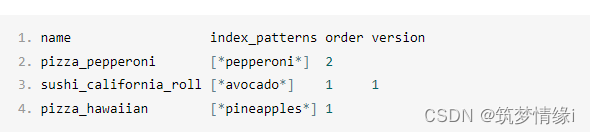
GET _cat/templates?v=true&s=order:desc,index_patterns
返回: