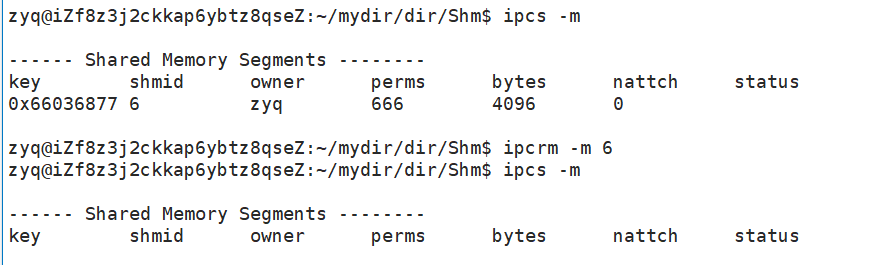
文献来源:徐芳,应洁茹.国内外用户画像研究综述[J].图书馆学研究,2020(12):7-16.DOI:10.15941/j.cnki.issn1001-0424.2020.12.002.
一、用户画像的概念
用户画像概念一经提出,便被广泛应用到精准营销等领域。后来,作为一种描绘用户特征、表达用户诉求的有效工具,用户画像被逐渐引入到图书馆服务等领域。关于用户画像的概念,普遍认为最早是由“交互设计之父”Cooper提出来的,他认为用户画像是真实用户的虚拟表示,是基于一系列真实数据(Marketing data,Usability data)的目标用户模型7。Massanari8将用户画像用于描述产品的使用对象中并认为用户画像是按照用户姓名、照片、兴趣爱好等特征对用户进行描述而形成的用户画像模型,强调了用户在产品开发过程中所起的决定性作用。国内方面,代表性观点有:用户画像是参考用户性别、受教育程度等人口统计学特征、社交关系和行为模式等标准而分析、总结和构建出来的一种标签化了的用户模型;用户画像的过程包括搜集用户数据、分析用户相关的业务特色以及可视化数据分析结果等;用户画像代表了某类目标用户群的特征。
关于用户画像的特征研究,Travis的研究提出了用户画像的基本性(Primary research)、真实性(Realistic)、目标性(Objectives)、独特性(Singular)、移情性(Empathy)等特性。梁荣贤认为用户画像具有真实性、独特性、动态性和应用性的特点。许鹏程的研究发现可迭代性、时效性、区隔性、交互性、知识性和聚类性是数据背景下用户画像的特征。宋美琦等把用户画像的特征归纳为标签化、时效性和动态性5。可见,用户画像是以大量真实用户数据为基础,对用户行为、兴趣等进行特征抽取而形成的虚拟用户模型,它具有全面性、真实性、代表性、动态性以及移情性等特征。
二、用户画像的构建流程
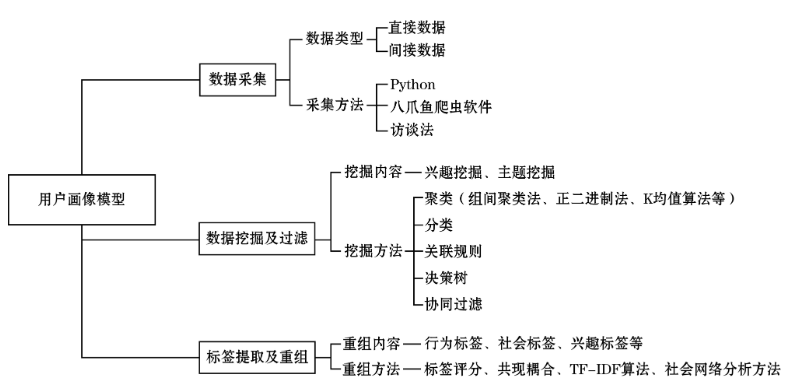
目前,有一些关于用户画像构建流程方面的研究。代表性的观点有:用户画像的构建流程包括用户的基本特征、需求、偏好等特征信息的提取和用户画像模型的建构;用户画像的构建流程是一个搜集用户特征数据、研究用户信息、细分标签、丰富用户画像描述的过程。在现有研究的基础上,我们将用户画像的构建流程划分为3个步骤:数据采集、数据挖掘及过滤和标签提取及重组。如图1所示。
(一) 数据的采集
用户数据是用户画像流程的基础。用户数据越全面准确,用户画像的刻画就越接近于真实用户,用户画像结果就会越成功。关于数据采集的方法,有许多学者从不同的学科和视角进行了探索。代表性的观点有:陈烨等研究者认为应该采集多视角数据,因为其对同一对象从不同层面或者不同方法进行数据的描述,数据可以呈现出多态性、多源性、多描述性和高维异构性等特点。柳益君等研究者则将用户数据划分为:显式行为数据、隐式行为数据、个人信息数据、社交数据以及终端感知数据。但是,当前研究对用户数据真实性、可靠性等方面尚缺乏系统而深入的研究。以视频网站账号为例,针对多人共用同一账号而产生的兴趣、行为方面的偏差可能会对用户画像构建的真实性方面存在一定的偏差。
(二) 数据挖掘及过滤
数据挖掘及过滤是用户画像流程的核心和关键。用户画像可以挖掘用户数据之间的关系,将用户画像结果应用到精准信息服务、精准营销等领域来实现其价值。国内外学者对此进行了不同程度的研究,代表性的研究有:Cooper利用数据挖掘对加州大学数字图书馆不同类型用户进行分析,从大量的图书馆数据中筛选隐藏数据,发掘了表面上复杂无序信息的联系,发现了不同类型用户逗留时间的规律。Skillen等人在文章中指出根据智能手机中日志数据进行数据挖掘可以提供个性化服务。陈丹等人认为基于大数据挖掘技术,可以从用户行为、用户社交数据、用户标签集这3种途径提取用户画像标签,从而构建用户画像,进而实现个性化的高质量服务。文献调查表明现有研究的重点关注于用户的行为、用户的关系网络以及兴趣等方面,但针对用户画像数据的过滤以及清洗方面的研究较为鲜见。
(三)标签的提取及重组
标签的提取与重组是用户画像流程的最后环节,是直接影响用户画像结果准确性的步骤,甚至标签权重的不同也会使得用户画像模型存在差异性。标签是一个对采集的用户数据进行挖掘与过滤,提取目标用户群的特征,用高度精炼词语对这些特征进行标识的过程,具有语义化、短文本化、专一性等特点。另外,标签出现的频率与用户兴趣也有明显的关系。国内学者对这方面进行了较多的研究。代表性的研究有:葛晓鸣将标签分为2D与3D标签,其中2D指用户标签中的人口属性、人格等具有相对稳定性的静态标签;而3D标签则指那些具有动态特征的标签,如:浏览器Cookies记录的信息检索、商品购买以及社交行为等。刘漫将用户画像构建的标签归为特征、行为以及用户兴趣标签。
综上,本文认为用户画像标签需要按照一定的标准进行划分和等级的排列,从分类的角度来讲,用户标签可以分为用户行为标签、社会网络标签以及兴趣标签等。用户行为标签包括:点击频率、浏览时间长短、搜索记录、评论等等。社会标签则包括:用户角色、用户关系网络、个体与群体的关系等等。用户的兴趣标签包括:用户的兴趣偏好、历史偏好、兴趣转变等标签。从等级排列的角度来讲,行为方面可以划分为一年内的行为、一月内的行为、一周内的行为、一日内的行为等。从社会关系网络的角度来划分可以分为个人与群体的关系、个人与社会的关系等。从兴趣角度来划分可以分为:当前兴趣以及潜在兴趣。
此外,值得注意的是用户画像模型的构建离不开各种算法与技术的支持。在用户画像构建的不同阶段需要不同技术手段的支持。 在数据采集方面,数据采集往往借用不同工具和方法进行数据的采集,国内外学者运用自编程序、八爪鱼爬虫软件、深度访谈等方法开展了相关的研究。 在数据挖掘和过滤方面,数据挖掘的方法有聚类、分类、关联规则、决策树、协同过滤等,聚类和分类的算法能够更好地将用户划分为具有相似特征的群体,以便于将这一类人视为具有共同特征的个体进行划分,关联规则则是基于对象的相似性进行数据关系的构建。根据目的的不同,选择数据挖掘的方法可以进行相应的选择。此外,有研究发现用户画像模型构建过程中常用到数据挖掘算法,如:向量空间模型等算法。标签的提取与重组方面,多数学者采用关联规则、标签评分、TF-IDF 算法、社会网络分析等来构建用户兴趣模型。另外,用户属性特征分析方面,常用数理统计、数据挖掘以及机器学习等方法。
三、用户画像研究的流派
按照用户画像模型构建流程中依据的用户数据不同,本文将国内外用户画像研究的流派划分为行为流派、社交媒体流派、兴趣流派以及基于本体的流派。
(一) 用户画像行为流派
用户画像行为流派将用户的行为作为描绘用户画像模型构建的依据。用户行为是指用户为满足特定的信息需求在信息行为中采取的各种动作和表现。一般来说,用户画像行为流派对用户行为的研究主要包括用户的信息检索行为、信息浏览行为等。国外方面代表性的研究主要有:早在2005年,Barabasi的研究发现人们的行为轨迹服从“幂律分布(Power Law Distribution)”和人的行为都是可预测的。Adomavicius等研究者通过对用户阅读时间和点击率等行为进行分析来发现用户消费特征与规律,为用户画像构建提供支持。Svendsen等研究技术接受程度行为与人的性格之间的关系,发现外向人表现出行为积极接受行为。Iglesias 等研究人员应用聚类方法对不同用户群体行为的网络日志进行数据挖掘,为用户画像的构建提供支持。国内方面代表性的研究成果主要有:郝增勇归纳了用户画像模型构建过程中用户行为分析的主要方法,如:用户流量统计、用户分布等。王仁武等利用自编的 Python 爬虫程序抓取高校教师和学生使用图书馆电子资源的访问时间、访问方式等日志数据,并对其进行分析、标引、解析等处理,试图构建学术用户画像的行为标签。刘锦宏等研究人员应用 “用户行为理论”和“技术接受模型(TAM)”,构建移动图书馆用户行为模型。何胜等研究人员分析了用户日志库中的数据,发现用户的显性兴趣和隐性需求,为制定个性化的用户服务策略提供支持。综上可知,用户画像的行为流派是以用户行为数据为依据,从看似散乱无序的行为数据中挖掘出用户行为的规律与特征,构建用户画像模型。根据用户画像模型,信息服务提供者可以预测用户的行动,实现精准信息服务的目的。但应该注意的是虽然用户画像行为流派的模型构建方法应用较为广泛,但是用户画像行为流派的研究尚存在一些局限,如:用户画像模型构建方法与可视化、人工智能等技术手段的结合尚不够紧密,使得基于用户行为数据构建的户画像模型在动态性、立体感等方面尚有待完善。
(二) 用户画像社交媒体流派
社交媒体的出现改变了人类的信息行为,构建了现实社会中难以构建的虚拟社会关系。社交网络中的用户由于评论、转发、点赞等行为在网络世界构建了各种各样的社会化联系,这种联系具有纽带的作用,增强了用户与用户之间的联系,且用户之间的联系具有实时性与动态性特征。目前,使用社交媒体采集用户数据来进行用户画像研究的文献有所增加,形成了较为丰富的研究成果。因此,非常有必要对该领域研究的文献进行梳理。
用户画像社交媒体流派的代表性研究主要有:Bhtacharyya等研究人员以Facebook用户关键词为样本,分析用户之间的相似性,找到交友中受影响的相似之处。徐海玲等人以豆瓣网为例,通过采集和分析社交媒体网站上的用户数据,构建了用户画像模型和资源画像模型。林燕霞等研究人员以微博为例,通过采集和分析用户微博上的动态来挖掘用户感兴趣的主题,构建微博用户画像,发现用户画像在社交媒体个性化信息服务、舆论治理等方面能够产生一定的作用。张亚楠等研究人员以科研社交媒体平台为例,通过采集和分析科研社交平台的用户数据,构建科研社交平台的用户画像,对于提高科研社交平台信息服务的精准性具有一定的参考意义。张艳丰等研究人员以移动社交媒体为例,通过采集和分析移动社交媒体的用户数据,构建了潜水忽略型、忍耐使用型、平台转移型和行为替代型等用户画像模型。综上可知,用户画像社交媒体流派用户画像模型构建的要点有:一是注重对用户社交媒体社会关系的描绘;二是注重用户数据的群体性特征,根据相似性等指标将用户划分为具有某一共同标签的群体。但是,现有用户画像社交媒体流派的研究同样也存在一定的局限性。例如:社交媒体存在于具有虚拟性的非现实网络世界,有些用户会因为求异心理、从众心理等原因在社交媒体社会网络中构建出一个与现实生活中行为、表现完全不同的虚拟用户形象,以此虚拟用户相关的社交媒体数据刻画的用户画像,其准确性有待商榷。因此,用户画像社交媒体流派的研究还需要对搜集到的社交媒体用户数据的真实性进行辨别,以便提高用户画像的准确性。
(三) 用户画像兴趣流派
用户画像兴趣流派的研究特征主要体现在:用户画像模型构建时是以用户兴趣、偏好等用户数据为基础。这方面的文献较为丰富,国外代表性的研究成果主要有:Godoy等研究者采用聚类方法对用户浏览过的网页痕迹数据进行分析,以此来挖掘用户的兴趣、偏好等特征;Pazani 等研究者对用户生成的兴趣标签进行分析,总结用户兴趣建档方法;Li 等研究者对用户和社会化标签进行共现分析(Co-occurrence Analysis)来发现用户兴趣,利用主题聚类方法来划分用户兴趣主题;依据用户兴趣进行用户画像模型构建,从而提高个性化搜索的性能;采用潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)主题模型来分析用户所关注的文档,挖掘用户兴趣主题并实现其可视化展示。国内代表性的研究成果主要有:石宇等研究者以电影数据为例,采集和分析用户感兴趣资源的相关数据,构建用户兴趣画像模型;王顺箐以图书馆智慧推荐系统为例,采集和分析了图书馆读者的数据,构建读者兴趣用户画像模型;王庆等研究者以图书馆馆藏资源推荐为例,采集和分析了图书馆读者的兴趣数据,构建了单用户兴趣画像模型和多用户兴趣画像模型;赵开慧采用聚类方法对用户标签和资源标签进行分析,实现用户内容的推荐;夏立新等研究者利用LDA主题模型分析用户标签的主题,探索用户兴趣层级演化规律,发现了始终处于核心层、核心层向边缘层淡化和始终处于边缘层的3种用户兴趣层级状态;唐晓波等研究者以新浪微博为例,分析了新浪微博用户的兴趣主题,构建用户画像并实现个性化的信息推荐。可见,用户兴趣流派的用户画像模型构建主要是以用户兴趣数据为基础。与用户画像行为流派和用户画像社交媒体流派不同,这种流派在描述用户画像时,重点关注用户的兴趣而非用户本身。根据用户喜欢的商品或者兴趣点等数据进行深入的挖掘与分析,发现用户兴趣的特征与规律,以便将相似的产品或者服务推荐给感兴趣的用户。
2.4 基于本体的用户画像流派
基于本体(Ontology)的用户画像流派是从本体的角度对用户数据进行规范化的提取、定义、表达、组织和评价,构建一套能被广为接受和理解的用户数据本体体系,以便用户画像模型构建的重用和共享。国外代表性的研究有:Chen等研究者提出了一种基于本体的用户画像建模方法,以树图和空间图为基础;Razmerita 等人提出了基于本体的用户画像模型架构,并应用该用户画像架构进行知识管理领域的移动用户行为研究;Issam等人描述了一种基于通用本体的用户建模技术,以满足用户画像的需求;Hawalah等人将用户兴趣表示为本体概念,本体概念通过将用户访问的网页映射到参考本体来构建,然后被用于学习短期和长期兴趣的挖掘与分析。国内代表性的研究有:郑建兴等人以微博为例,利用本体的部分结构来表示用户画像模型,提出了neighbor-user画像的实现方法,以便全面地反映用户兴趣;唐晓波等人构建了一种基于本体和标签的个性化推荐模型,并发现该模型优于传统的基于社会化标签的推荐;姜建武等人用结构化信息本体来表示抽象的用户,构建数学模型来研究结构化信息本体的提取方法。可见,基于本体的用户画像模型构建流派相较于其它用户画像构建流派能够考虑信息源包含的具体含义,并且在语义表达能力以及逻辑推理方面具有更强的优势。但同时也应该注意的是,该流派的研究技术性比较强,通常要求研究人员具备计算机等学科知识。


![[入门] Unity Shader前置知识(5) —— 向量的运算](https://img-blog.csdnimg.cn/direct/8e4fc9ca347248dca9ec01c0e5b03e59.png)