算法(algorithm)简单说就是解决问题的方法。方法有好坏,同样算法也是,有效率高的算法,也有效率低的算法。衡量算法的好坏一般从时间和空间两个维度衡量,也就是本文要介绍的时间复杂度和空间复杂度。有些时候,时间与空间不可兼得,会出现以时间换空间或者以空间换时间
1.时间复杂度
I.时间复杂度概念
在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。一个算法所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。但是我们需要每个算法都上机测试吗?最简单的方法就是将算法运行一遍,但是运行时间容易受到环境、数据规模等的影响,所以才有了这个时间复杂度这个分析方式,一个算法所花费的时间与其中语句的执行次数成正比列,算法中的基本操作的执行次数,为算法的的时间复杂度。
找到某条基本语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度。
//请计算Fun1中++count语句总共执行了多少次
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N; ++i)
{
++count;
}
for (int k = 0; k< 2*N; ++k)
{
++count;
}
int M = 0;
while (M--)
{
++count;
}
printf("%d\n",count);
}
Func1执行的基本操作次数:
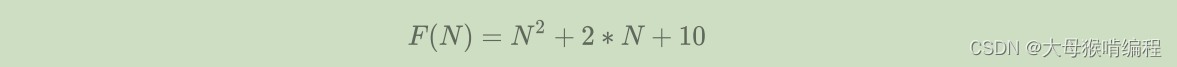
- N=10 F(N)=130
- N=100 F(N)=10210
- N=1000 F(N)=1002010
实际中计算时间复杂度时,其实并不一定要计算精确的执行次数,而只需要大概执行次数,因此在计算时使用大O渐近表示法。
II.大O渐近表示法
大O符号(Big O notation):是用于描述函数渐进行为的数学符号
推导大O阶方法:
(1).用常数1取代运行时间中的所有加法常数
(2).在修改后的运行次数函数中,只保留最高阶项
(3).如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶
使用大O阶渐进表示法以后,Func1的时间复杂度是
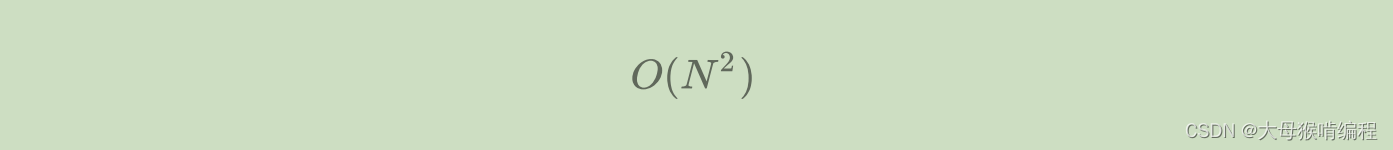
- N=10 F(N)=100
- N=100 F(N)=10000
- N=1000 F(N)=1000000
通过上面可以看出发现大O的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。
另外有些算法的时间复杂度存在最好、平均和最坏情况:
- 最坏情况:任意输入规模的最大运行次数(上界)
- 平均情况:任意输入规模的期望运行次数
- 最好情况:任意输入规模的最小运行次数(下界)
比如说:在一个长度为N的数组中搜索一个数据x
最坏情况:N次找到
平均情况:N/2次找到
最好情况:1次找到
在实际中一般情况下关注的是算法的最坏运行情况,所以数组中搜索数据时间复杂度为O(N)
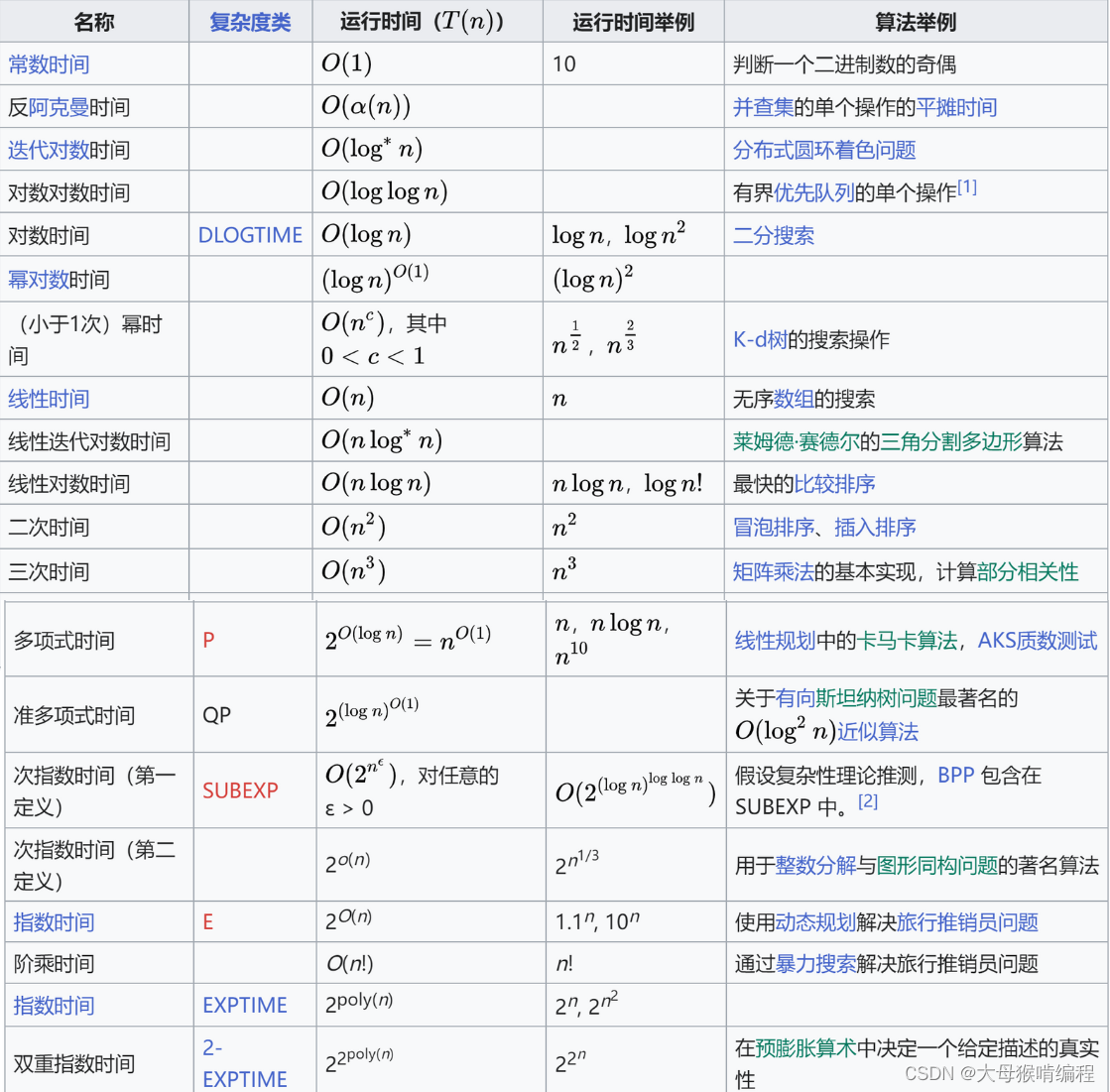
时间复杂度的计算是确定它的量级,通过确定不同的量级来比较算法的好坏,常见量级如下

完整的如下:
III.示例:
//计算Func2的时间复杂度
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}Func2中第一个循环循环2*N次,第二个while循环循环10次,用数学表达式写的结果就是F(N)=2*N+10 ,经过推导可得,2是系数和常数M对整体的影响较小,故最终的时间复杂度就是O(N)
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; M++)
{
++count;
}
for (int k = 0; k < N; ++k)
{
++count;
}
printf("%d\n", count);
}Func3中第一个循环循环M次,第二个循环循环M次,F(N)=M+N,对应的时间复杂度就是O(M+N)(Omax(M,N)),如果M远大于N,就是O(M),如果N远大于M,就是O(N)
void Func4(int N)
{
int count = 0;
for (int k = 0; k < N; ++k)
{
++count;
}
printf("%d\n", count);
}Func4中只有一个循环,循环N次,时间复杂度就是O(N)
//计算strchr的时间复杂度
const char*strchr(const char *str,int charcter);最坏情况是O(N),最好的情况是O(1)
void Bubblesort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for(size_t i=1;i<end;++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
冒泡排序中,两层循环,外层循环控制每次遍历的范围,内层粗那混执行相邻的元素的比较和交换
- 外层循环的迭代次数为n,其中n是数组的长度
- 内层的迭代次数随外层循环的进行而减少,但是最坏情况下,内层迭代的次数也是n
因此,此方法的冒泡排序的时间复杂度为O(n^2)
long long Fac(size_t N)
{
if (N == 0)
{
return 1;
}
return Fac(N - 1) * N;
}
总共递归N次,数学表达式可写为F(N)=N+(N-1)+(N-2)+......+(1)+(0),时间复杂度就为O(N)
long long Fib(size_t N)
{
if (N < 3)
{
return 1;
}
return Fib(N - 1) + Fib(N - 2);
}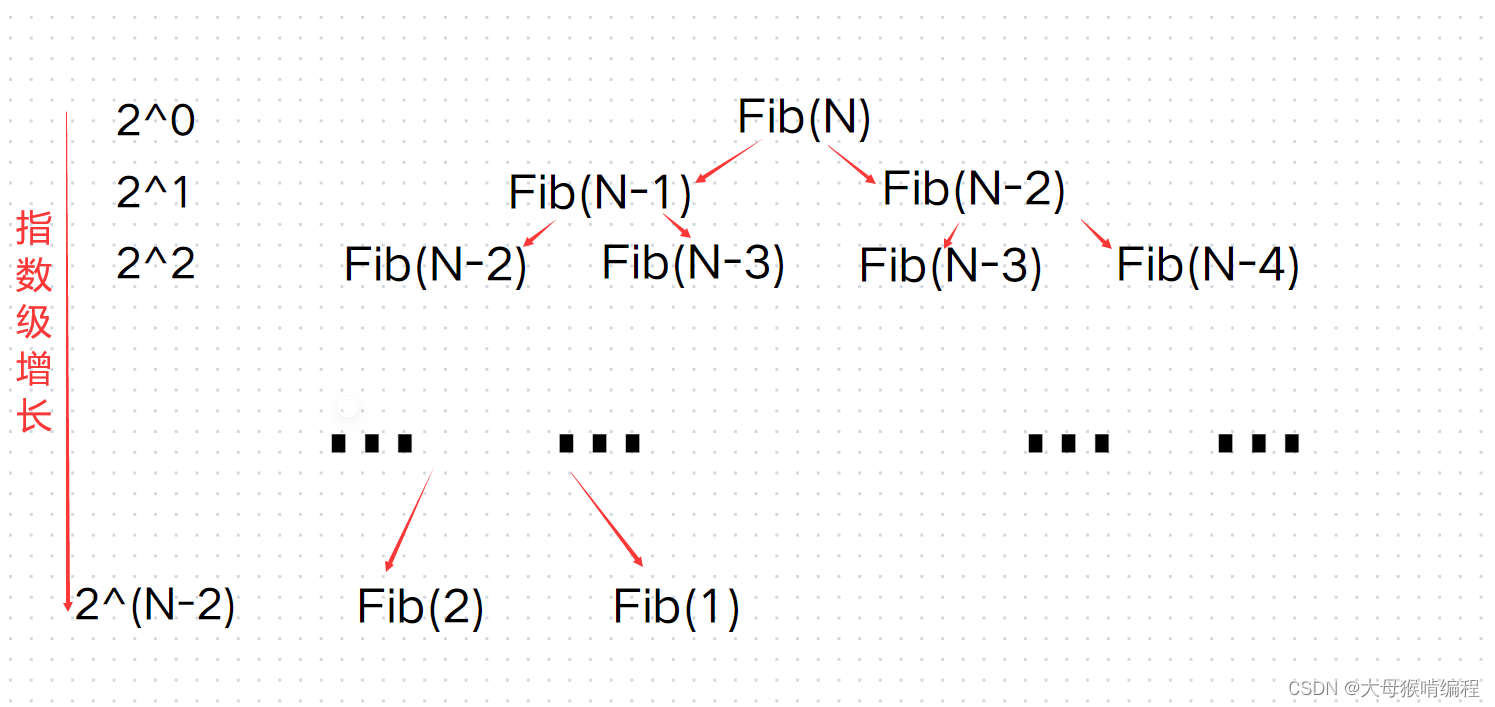
- 在每次的递归调用中,函数都会进行一次加法操作
- 递归的深度取决于输入参数N的大小
数学表达式可写作F(N)=2^(N-2),时间复杂度就为O(2^N)(关于斐波那契数列的时间复杂度,深入探讨见:http://递归求解斐波那契数列的时间复杂度——几种简洁证明 - SleepyBag的文章 - 知乎 https://zhuanlan.zhihu.com/p/257214075)
2.空间复杂度
I.空间复杂度概念
空间复杂度也是有个数学表达式,是对一个算法在运行过程中临时占用储存空间大小的量度。
空间复杂度不是程序占用了多少bytes的空间,因为这个没有实际意义,所以空间复杂度是变量的个数,空间复杂度计算规则基本跟时间复杂度类似,也是采用大O渐近表示法。
注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了,因此空间复杂度主要通过函数在运行时候显示申请的额外空间来确定。
就像时间复杂度的计算不考虑算法所使用的空间大小一样,空间复杂度也不考虑算法运行需要的时间长短,空间复杂度计算的是算法中额外的空间
II.示例:
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int tmp = 0;
for (size_t i = 0; i < end; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
tmp = 1;
}
}
if (tmp == 0)
break;
}
}在冒泡排序中,变量的个数只有end、tmp、i三个,是确定的,所以空间复杂度是O(1)(数组中的空间不计入,不属于算法中额外开辟的空间)
long long* Fibonacci(size_t n)
{
if (n == 0)
{
return NULL;
}
long long* fibArray = (long long)malloc((n + 1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i < n; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray[i - 2];
}
return fibArray;
}上述代码中在求斐波那契额数列的过程中开辟了数列,这个数列属于额开辟的空间,此外,还有一个变量n,综上,空间复杂度为O(N)
long long Fac(size_t N)
{
if (N == 0)
{
return 1;
}
return Fac(N - 1) * N;
}上述代码并没有创建变量,但是每次函数的调用都需要创建函数栈帧,这个算法调用了N次(具体取决于递归深度),所以空间复杂度是O(N)



![[入门] Unity Shader前置知识(5) —— 向量的运算](https://img-blog.csdnimg.cn/direct/8e4fc9ca347248dca9ec01c0e5b03e59.png)