IvyPdf 帮助您快速轻松地从非结构化 PDF 文档中提取有价值的信息。它可以提取无限的单个值和表格,并提供强大的后处理机制来进一步清理和格式化数据。
虽然 PDF 是图书馆的主要目标,但它们也可用于解析 Excel、文本、HTML 和其他文件格式,从而使您可以使用一个工具来满足所有数据处理需求。
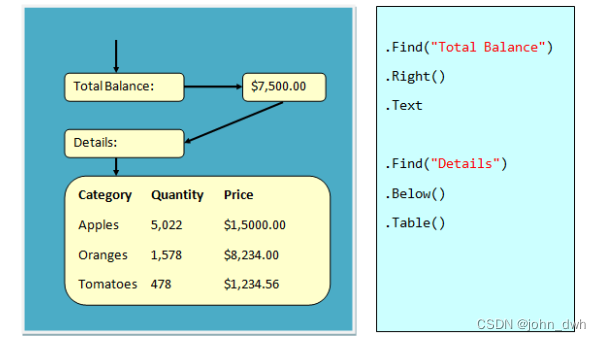
区别:
传统上,PDF 提取工具将 PDF 文档转换为纯文本并使用各种方式进行搜索。这种方法消除了任何丰富的格式信息,如字体类型、字符大小或粗体/斜体属性。
Ivy Pdf Parser 将 PDF 读取为图形文档,因此您可以使用所有富文本属性进行匹配。对于某些文档,它有助于从纯文本中提取最后无法确定的信息。
Ivy Pdf 解析器(.NET 库)
我们的 Pdf 解析器支持从复杂的 PDF 文档中搜索和提取信息,包括格式不一致、可变长度文本列和表格的文档。
IvyPdf 的强大功能:
- 灵活的文本搜索。
搜索文本、正则表达式和字体属性。 - 几何搜索。
查找相对于其他元素的元素。
(例如,“总计”一词右侧的文字) - 表提取。
表格是自动识别的。 - 内置函数。
清理提取的数据并连接片段。 - 可扩展。
使用原始元素的集合并编写您的逻辑来解析它。 - 100% .Net 托管代码。
非常快。
现在包括功能强大的模板编辑器。
- 易于使用的图形用户界面。同时在多个文档上创建和测试表达式并预览结果。
- 任意数量的数据点。提取单个值和表格。
- 强大的后处理。加入、筛选、转换和 C# 的所有功能,为您提供便利。
- 模板继承。创建子模板来处理不同的文档变体。
- 验证测试。编写逻辑来验证结果。
- 将结果导出到 Excel 或 JSON。在结果中包含表格。
- 自动化支持。将提取集成到您的过程中。
- 可扩展。引用任何 .Net 库。