目录
一 、 时序数据库基本概念
- 采集量
- 标签
- 数据采集点
- 表
- 超级表
- 子表
- 库
二、 TDengine数据库建模策略
- 建表模式
- 建表情形
行列数据库存储的区别:
接触的传统业务的数据模式都是行存储,我们会把不同类型的对象创建不同的表进行存储他们各自的属性。一般情况我们会把他们的所有属性一次性封装起来进行写入数据,而不是一个属性一个属性的去保存。所以关系型数据库的行存储数据完整性是可以确定的。
列存储需要把一行数据拆分成单例进行保存,所以写入次数明显会比行存储多,所以时序数据库主要针对物联网,工业互联网等应用场景开发的一个数据存储引擎。
而数据按列存储的话即每一列都单独存放,数据类型一致,数据特征相似。数据即索引,所以查询效率也会明显提高。
因此我们在使用的时候对于数据建模方式和业务场景设计的思维逻辑也会和之前传统数据库的使用有些出入
一、时序数据库基本概念
基本属性
1.采集量
- 采集量是指传感器、设备或其他类型采集点采集的物理量,比如电流、电压、温度、压力、GPS 位置等,是随时间变化的参数
2.标签
- 标签是指传感器、设备或其他类型采集点的静态属性,不是随时间变化的。比如设备ID,设备型号,设备所在地
3.数据采集点
- 数据采集点是指按照预设时间周期或受事件触发采集物理量的硬件或软件。一个数据采集点可以采集一个或多个采集量,但这些采集量都是同一时刻采集的,具有相同的时间戳。对于复杂的设备,往往有多个数据采集点,每个数据采集点采集的周期都可能不一样,而且完全独立,不同步。
4.表
- TDengine 采取一个数据采集点一张表的策略,要求对每个数据采集点单独建表(比如有一千万个智能电表,就需创建一千万张表),用来存储这个数据采集点所采集的时序数据。这种设计有几大优点:
- ① 不同数据采集点产生数据的过程完全独立,每个数据采集点的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升。
- ② 对于一个数据采集点而言,其产生的数据是按照时间排序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。
- ③ 一个数据采集点的数据是以块为单位连续存储的。如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度。
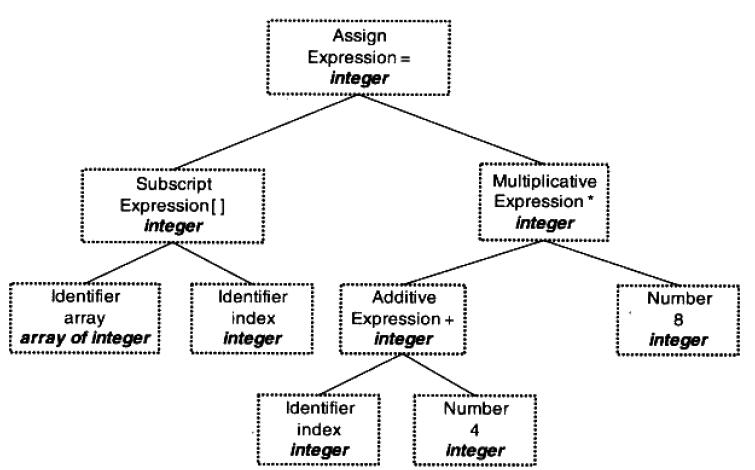
5.超级表
- 由于一个数据采集点一张表,导致表的数量巨增,而且应用经常需要做采集点之间的聚合操作,聚合的操作也变得复杂起来。为解决这个问题,TDengine 引入超级表(Super Table,简称为 STable)的概念。而且应用经常需要做采集点之间的聚合操作,聚合的操作也变得复杂起来。为解决这个问题,TDengine 引入超级表(Super Table,简称为 STable)的概念。
- 超级表是指某一特定类型的数据采集点的集合。同一类型的数据采集点,其表的结构是完全一样的,但每个表(数据采集点)的静态属性(标签)是不一样的。描述一个超级表(某一特定类型的数据采集点的集合),除需要定义采集量的表结构之外,还需要定义其标签的 Schema,标签的数据类型可以是整数、浮点数、字符串、JSON,标签可以有多个,可以事后增加、删除或修改。如果整个系统有 N 个不同类型的数据采集点,就需要建立 N 个超级表。
- 在 TDengine 的设计里,表用来代表一个具体的数据采集点,超级表用来代表一组相同类型的数据采集点集合。
6.子表
- 当为某个具体数据采集点创建表时,用户可以使用超级表的定义做模板,同时指定该具体采集点(表)的具体标签值来创建该表。通过超级表创建的表称之为子表。
- 一张超级表包含有多张子表,这些子表具有相同的采集量 Schema,但带有不同的标签值
- 不能通过子表调整数据或标签的模式,对于超级表的数据模式修改立即对所有的子表生效
- 超级表只定义一个模板,自身不存储任何数据或标签信息。因此,不能向一个超级表写入数据,只能将数据写入子表中
- 查询既可以在表上进行,也可以在超级表上进行。针对超级表的查询,TDengine 将把所有子表中的数据视为一个整体数据集进行处理,会先把满足标签过滤条件的表从超级表中找出来,然后再扫描这些表的时序数据,进行聚合操作,这样需要扫描的数据集会大幅减少,从而显著提高查询的性能。本质上,TDengine 通过对超级表查询的支持,实现了多个同类数据采集点的高效聚合
在智能电表的示例中,我们可以通过超级表 meters 创建子表 d1001、d1002、d1003、d1004 等。为了更好地理解采集量、标签、超级与子表的关系,可以参考下面关于智能电表数据模型的示意图。
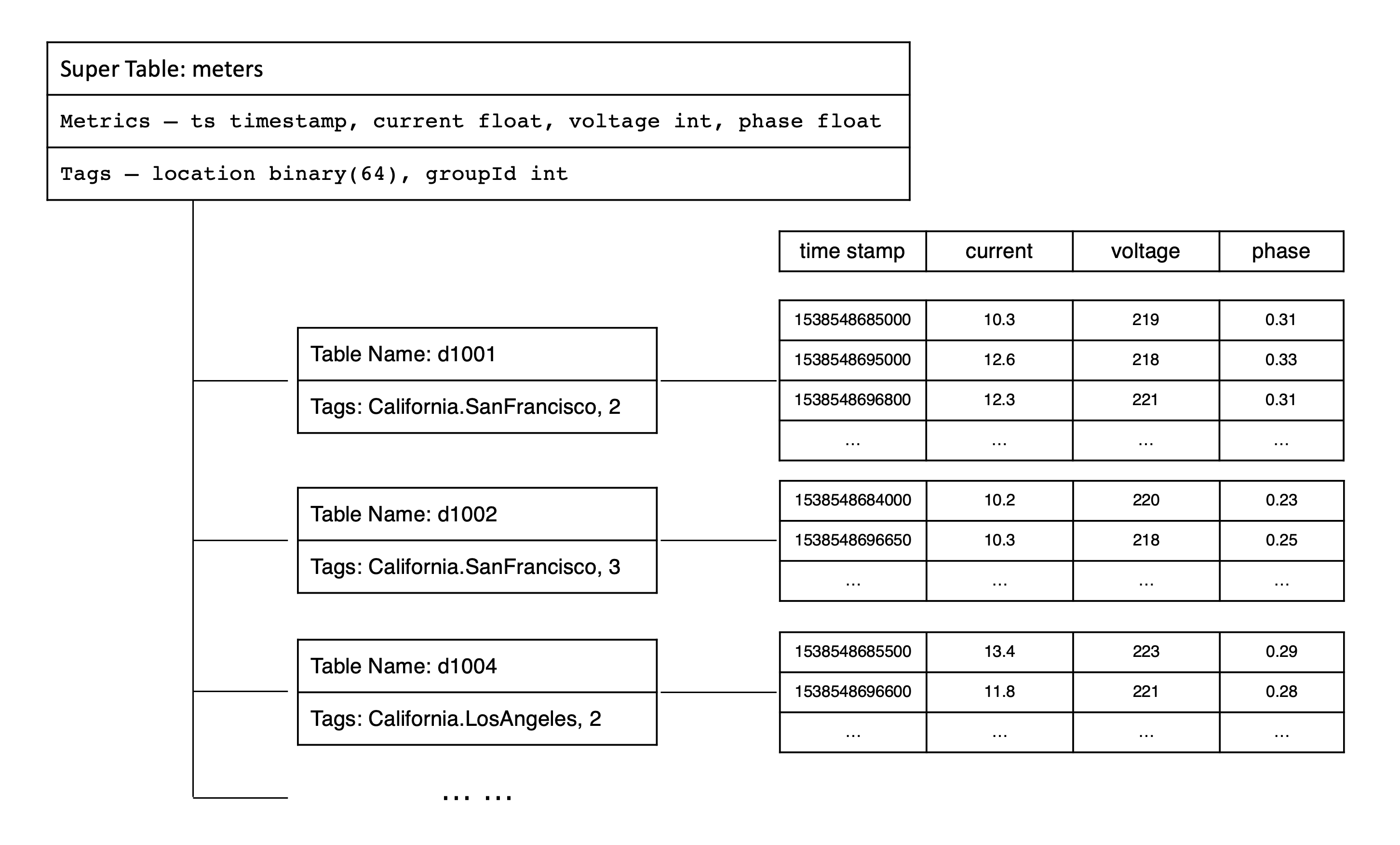
7.库
- TDengine 容许一个运行实例有多个库,而且每个库可以配置不同的存储策略。不同类型的数据采集点往往具有不同的数据特征,包括数据采集频率的高低,数据保留时间的长短,副本的数目,数据块的大小,是否允许更新数据等等。为了在各种场景下 TDengine 都能最大效率的工作,TDengine 建议将不同数据特征的超级表创建在不同的库里
二、TDengine数据库建模策略
1.建表模式
1.单列模式:
每个采集的物理量都单独建表,因此每种类型的物理量都单独建立一超级表
2.多列模式:
只要物理量是一个数据采集点同时采集的(时间戳一致),这些量就可以作为不同列放在一张超级表里
2.建表情形
一、按照设备建表即一个设备一张表,这种情况有以下特点
- 就同一个设备而言,各采集指标同时采集,采集时间戳相同。
- 就同一个设备而言,各采集指标每次采集的数据最好是在同一个消息中上报到 TDengine,而非分别上报
- 相同类型的设备,采集指标完全相同。
这种情景下采用多列模式,即为每个类型的设备创建一张多列超级表。
为该类型的每个设备创建一张子表。
子表从第二列起,每一列均为一个采集指标。
二、按照设备建表,但同类型设备的采集指标不完全相同
这种情况和情形一的区别是每个设备可能有个性化的采集指标。:
- ① 相同类型的设备,采集指标大体相同,但每个设备可能有少量个性化的指标。
- (前提:所有个性化指标总数加上共有指标总数不超过 4096 个)
针对这种情形的处理思路常称为“大宽表”:
1.创建一个多列超级表,包含所有不同的采集指标列,为所有采集指标的全集。
2.为每个设备创建一张子表。
3.子表从第二列起,每一列均为一个采集指标。
4.数据写入时,对于该设备不具备的采集指标填入 null 值。
三、按照采集指标建表,每一个采集参数对应一张表
更复杂的场景中,设备的固定表结构很难抽象出来,或者表结构经常改变,无法固定,此时需要有更灵活的处理思路。以下任一个特点满足时,需考虑按指标建表的思路:
1.相同类型的设备,采集指标无法固定,或者每个设备有大量个性化的指标。
2.就同一个设备而言,各采集指标有各自的采集时间戳。(即同一个设备的不同采集指标的采集时间、采集周期等无法保证相同)
3.就同一个设备而言,各采集指标每次采集的数据分多个消息上报到 TDengine,且时间延迟无法确定。
这种情形要求更高的灵活性。一般处理思路如下:
-
创建单列的超级表,即时间戳+采集值,而在标签项中增加采集指标的设备ID这一标签。
-
每个设备的每个采集指标单独创建一张表,在标签项中增加具体的设备ID。
-
不同数据类型的采集指标要划归不同超级表,比如数值型、布尔型和字符串型的数据应该分别归入三类对应的超级表。

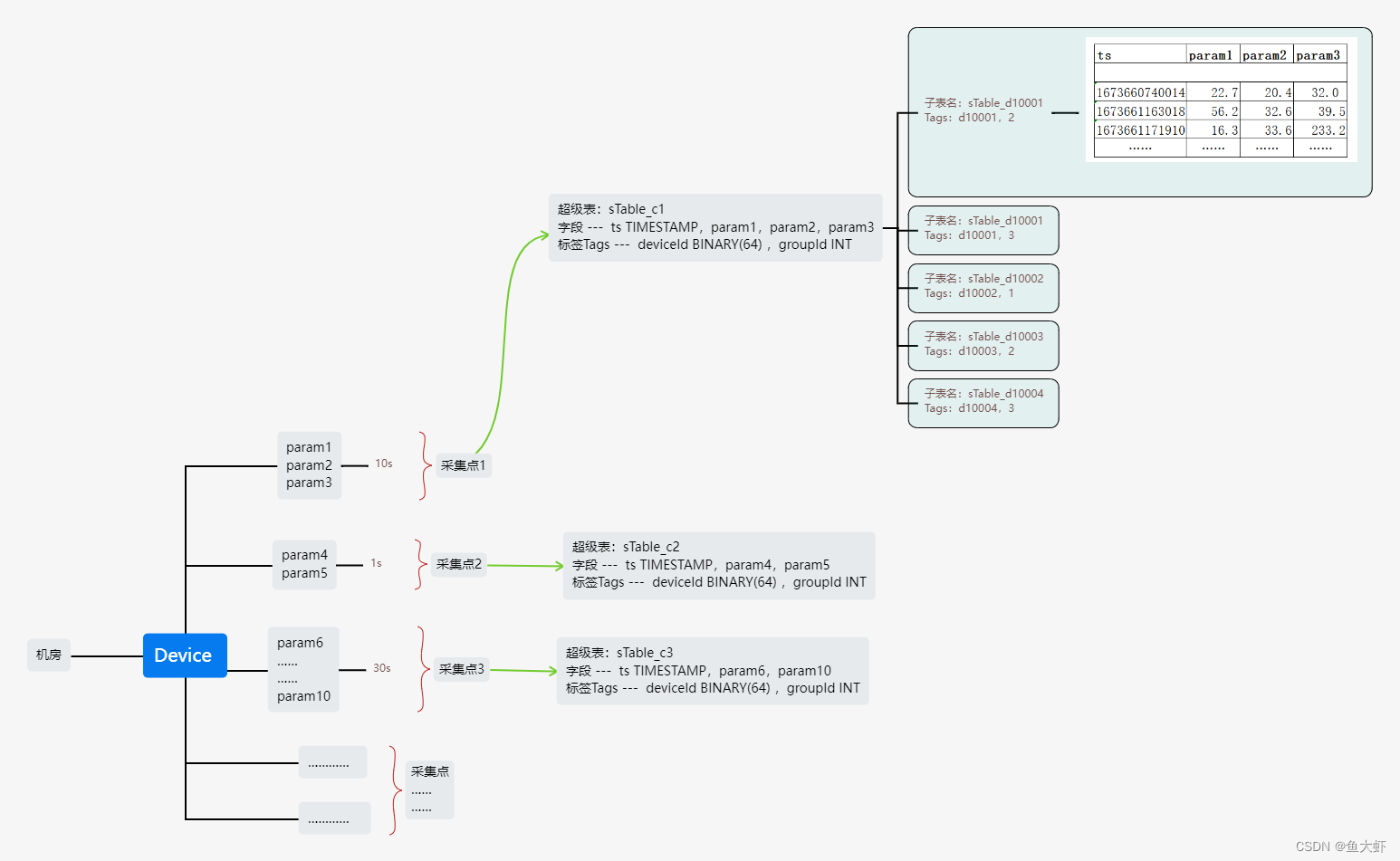
四、按照数据采集点建表
对每个数据采集点需要独立建表。创建时,需要使用超级表做模板,同时指定标签的具体值
应用场景:
1.相同类型的设备,采集指标不固定。
2.就同一设备而言,各采集指标有各自的采集频率,不过采集频率是确定的,比如 PLC1~PLC10 的采集频率是 10ms,PLC11~PLC20 的采集频率是 20ms。
3.就同一设备而言,后续可能会动态添加 PLC 通道。期望可以在不修改代码的情况下动态增加超级表的列。
可以为每一种类型的数据采集点建立一个超级表,在物联网中,一个设备就可能有多个数据采集点(比如一台风力发电的风机,有的采集点采集电流、电压等参数,有的采集点采集温度、湿度、风向等环境参数),这个时候,对这一类型的设备,需要建立多张超级表。
将同一设备下采集周期相同的指标也就是具有相同的时间戳的参数作为一个采集点创建超级表。
每个采集点的数据对应一个子表。
以上几种建模思路基本可以应对大多数的业务场景。当然实际业务中的情况是多种多样的,更为复杂的业务场景可以再共同讨论。