论文地址:
论文地址:Sarcasm Analysis Using Conversation Context | Computational Linguistics | MIT Press
github地址:https://github.com/debanjanghosh/sarcasm_context
Alex-Fabbri/deep_learning_nlp_sarcasm: code for deep learning models applied to nlp tasks (github.com)
论文首页:

利用对话语境进行讽刺分析
📅出版年份:2018
📖出版期刊:Computational Linguistics
📈影响因子:2
🧑文章作者:Ghosh Debanjan,Fabbri Alexander R.,Muresan Smaranda
📍 期刊分区:
JCR分区: Q1 中科院分区升级版: 计算机科学2区 中科院分区基础版: 工程技术4区 影响因子: 9.3 5年影响因子: 6.2 EI: 是 CCF: B
🔎摘要:
讽刺检测的计算模型通常依赖于孤立的语句内容。然而,如果没有额外的语境,说话者的讽刺意图并不总是很明显。我们以社交媒体讨论为重点,研究了三个问题:(1) 对话语境建模是否有助于讽刺检测?(2) 我们能否识别是对话上下文的哪一部分触发了讽刺回复? (3) 对于包含多个句子的讽刺帖子,我们能否识别出讽刺的具体句子?为了解决第一个问题,我们研究了几种类型的长短时记忆(LSTM)网络,它们可以对对话上下文和当前回合进行建模。我们的研究表明,在句子层面关注上下文和当前转折的 LSTM 网络以及条件 LSTM 网络优于只读取当前转折的 LSTM 模型。作为会话上下文,我们考虑了前一轮、后一轮或两者。我们的计算模型在两种类型的社交媒体平台上进行了测试: 推特和论坛。我们讨论了这些数据集之间的一些差异,包括它们的规模和金标签注释的性质。为了解决后两个问题,我们对 LSTM 模型产生的注意力权重进行了定性分析,并将结果与人类在这两个任务中的表现进行了比较。
🌐研究目的:
我们以社交媒体讨论为重点,研究了三个问题:p756
(1) 对话语境建模是否有助于讽刺检测?
(2) 我们能否识别是对话上下文的哪一部分触发了讽刺回复?
(3) 对于包含多个句子的讽刺帖子,我们能否识别出讽刺的具体句子?
我们的研究目标之一是对两类社交媒体平台进行比较研究,这两类平台已被单独考虑用于讽刺检测。
📰研究背景:
-
讽刺检测的计算模型通常依赖于孤立的语句内容。然而,如果没有额外的语境,说话者的讽刺意图并不总是很明显。p756
-
曾经的大多数方法大多考虑的是孤立的语篇。p759
-
目前有两个主要的研究方向--作者语境和对话语境p759
🔬研究方法:
🔩模型架构:
两种架构:
-
一种是同时使用单词级和句子级注意力的分层结构(Yang et al. 2016),
-
另一种仅使用句子级注意力(这里我们仅使用平均单词嵌入来表示句子) 。
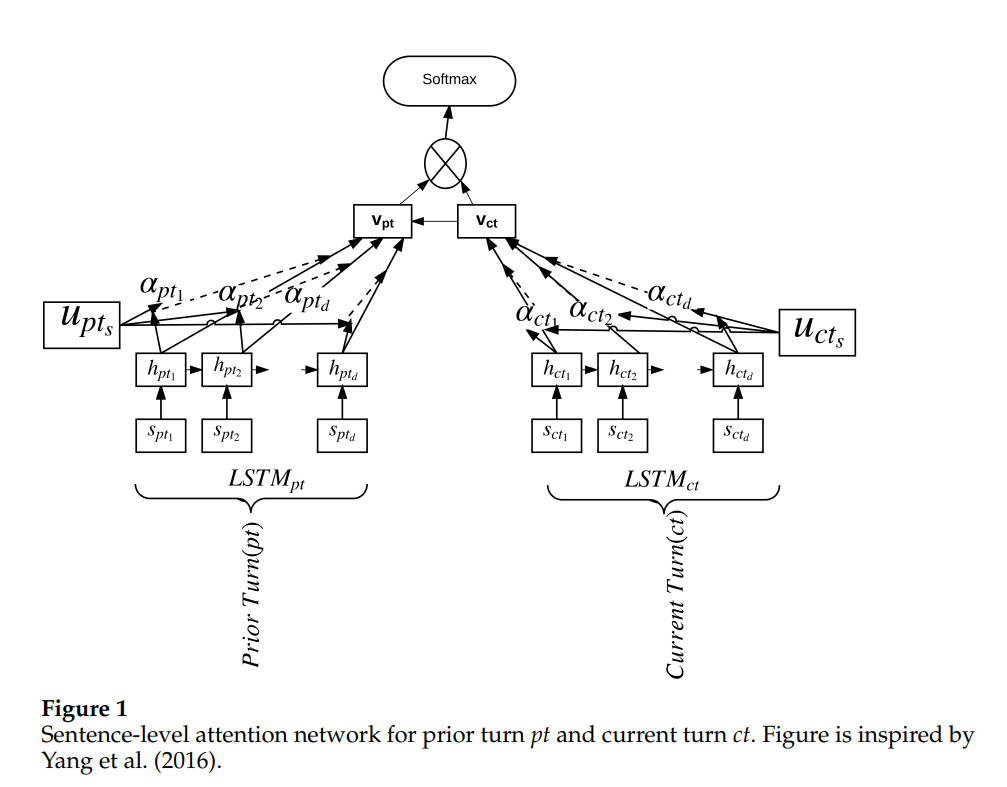
基于注意力的 LSTM 网络 p767
-
对话上下文由先前的回合 pt 表示。上下文(左)由 LSTM (LSTMpt) 读取,
-
当前轮 ct(右)由另一个 LSTM (LSTMct) 读取。
请注意,对于我们也考虑后续转 st 的模型,我们只需使用另一个 LSTM 来读取 st。
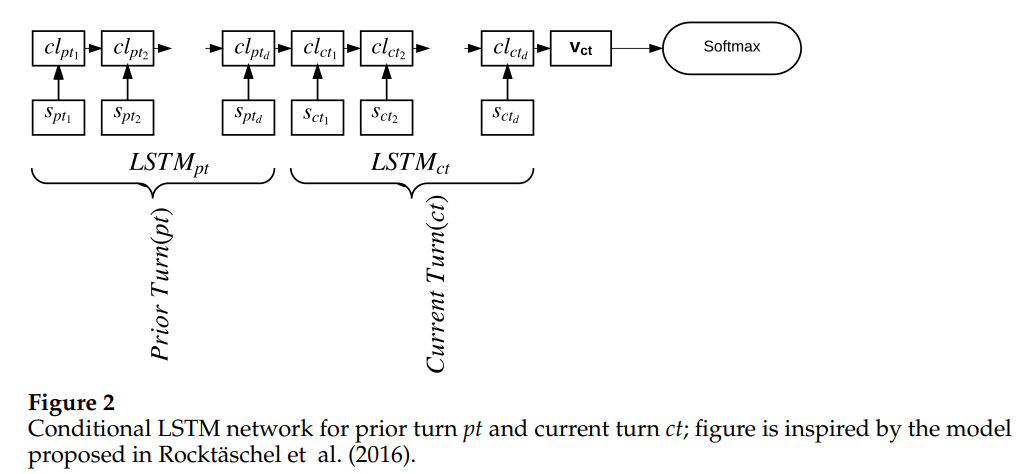
条件 LSTM 网络 p769
我们还尝试了 Rockta ̈schel 等人引入的条件编码模型。
使用了两个独立的LSTM——LSTMpt和LSTMct——与之前的架构类似,没有任何注意力,但是对于LSTMct来说,它的内存状态是用LSTMpt的最后一个单元状态来初始化的。对于使用连续转弯 st 作为上下文的模型,LSTM 表示 LSTMst 以 LSTMct 的表示为条件。
🧪实验:
📇 数据集:
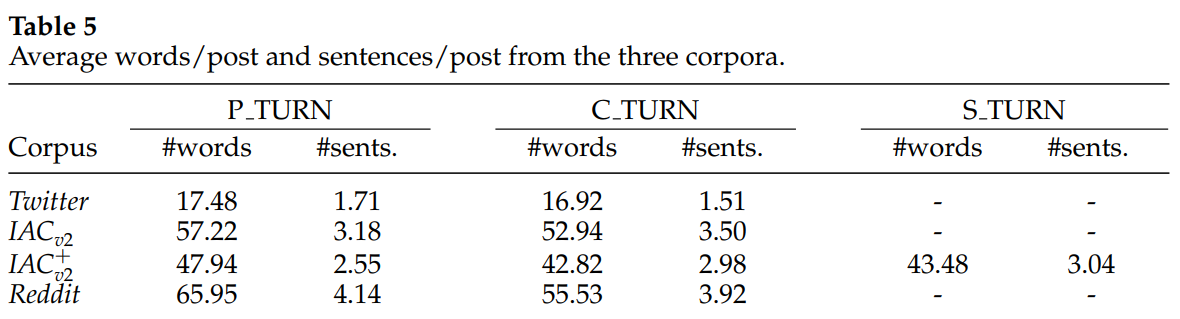
互联网论证语料库IACv2
Twitter 和 Reddit 数据集
-
在 Twitter 和 Reddit 数据中,我们拥有自标注数据(即发言者自己将其帖子标注为讽刺信息)
-
我们有通过众包获得的标签,如 IAC 的情况(Oraby 等人,2016 年)
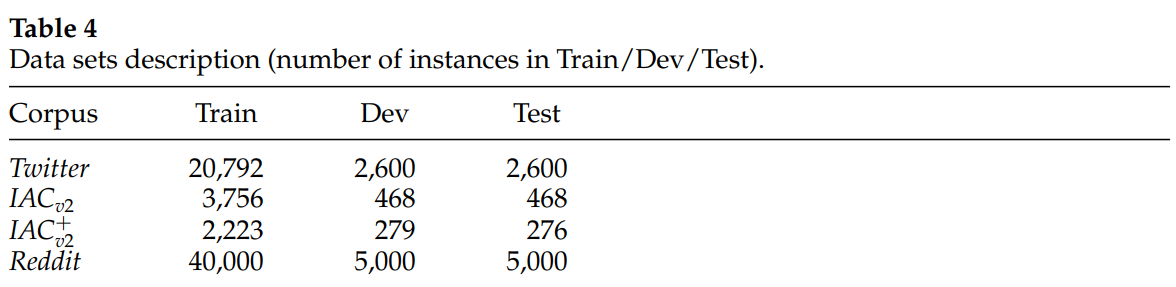
所有数据集被随机分为训练(80%)、开发(10%)和测试(10%),保持讽刺与讽刺的相同分布。
📏评估指标:
-
我们报告讽刺 (S) 和非讽刺 (NS) 类别的准确率 (P)、召回率 (R) 和 F1 分数。
-
我们通过对模型的误差分析来结束本节(第 5.3 节)
📉 优化器&超参数:
-
训练集中的词汇外单词通过从 (−0.05, 0.05) 均匀采样的值来随机初始化,并在训练期间进行优化。
-
dropout :0.5
-
小批量大小: 16
-
L2 正则化为:1E-4
-
epoch:30
-
每个帖子的最大句子数阈值:10
📋 实验结果:
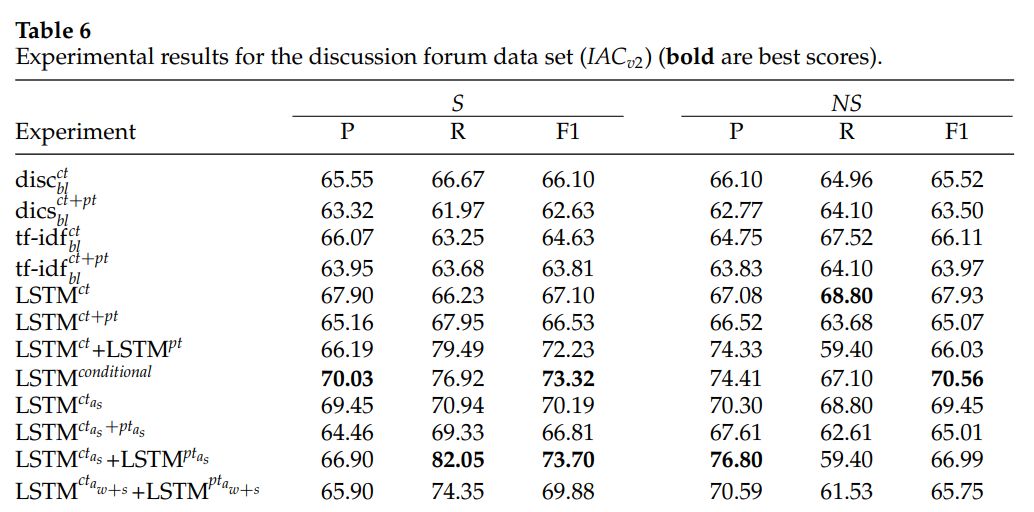

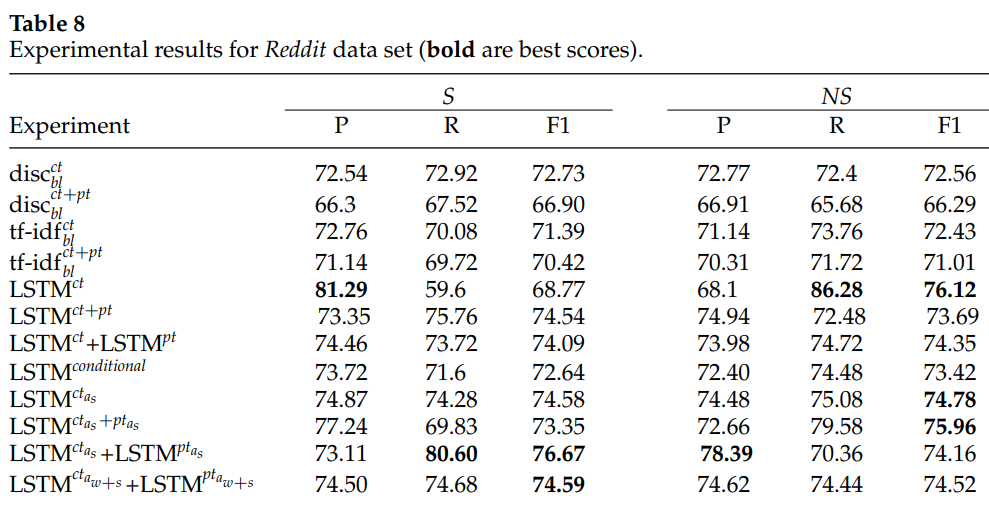


我们的实验表明,基于注意力的模型可以识别讽刺的固有特征(即讽刺标记和讽刺因素,例如上下文不一致)。
🚩研究结论:
我们表明,与外部注释(众包)转弯的语料库(例如 IACv2)相比,自我标记的讽刺转弯(例如 Reddit)更难识别。我们证明即使如果Reddit中的训练数据大十倍,对我们的实验没有太大影响。
📝总结
💡创新点:
-
本文扩展了语境的概念,将 "后一轮 "与 "前一轮 "一并考虑。本文从数据集的规模和金色标签的获取方式(自我标签与众包标签)两个方面讨论了数据集的性质。
-
解决了一个新问题:对于问题3,我们对人类的任务表现和 LSTM 模型的注意力权重进行了比较分析。
-
加入了新的基线(tf-idf;RBF 内核)和使用不平衡数据集的运行。
-
经验表明,明确地建立转折模型比仅仅将当前转折和先前转折(和/或后续转折)连接起来更有帮助,也能提供更好的结果。
-
使用了两个情感词典来建立转弯情感模型:MPQA 情感词典和个意见词典
-
使用多个 LSTM:一个读取当前一轮,一个(或两个)读取上下文(如一个 LSTM 读取前一轮,一个读取后一轮)
⚠局限性:
我们还进行了彻底的错误分析,并发现了几种类型的错误:缺少世界知识、使用俚语、使用反问句和使用数字。
🔧改进方法:
在未来的工作中,我们计划开发方法来解决这些错误,例如
-
对反问句进行建模(类似于 Oraby 等人[2017])
-
采用专门的方法来对与数字相关的讽刺消息进行建模
-
使用其他基于词典的特征来包括俚语。
🖍️知识补充:
-
Schifanella 等人(2016 年)提出了一种多模态方法,即结合文本和视觉特征来检测讽刺语言。p758