文章目录
- 1. Redis的持久化
- 1.1 RDB(快照模式)
- 1.2 AOF 模式
- 2. Redis主从模型(高可用)
- 2.1 Redis的主从复制
- 2.2 Redis拓扑结构
- 3. Redis集群模式(高并发)
- 3.1 Redis的Slots
- 3.2 集群模式的常用命令
- 3.3 多主多从架构
- 4. Redis的内存管理
- 4.1 Redis的内存模型
- 4.2 查看Redis内存占用情况
- 4.3 Redis内存管理与优化
- 5. Redis常见故障处理
- 5.1 内存溢出
- 5.2 命令阻塞
- 参考资料
1. Redis的持久化
为了保证Redis中的数据尽可能不丢失,需要对Redis中的数据进行持久化。
Redis提供两种持久化方案:
- 快照(snapshotting),也称为RDB:某一时刻将数据全部写入到磁盘(生成一个rdb文件)。
- 优点:① 数据恢复速度快。② 存储效率高;③ 可用于数据备份;④ 备份文件占用存储空间小。
- 缺点:① 数据会丢失一部分;② 备份时会占用系统资源;③ 备份文件在不同的redis版本之间存在兼容性问题。
- 只追加文件(append-only file, AOF):执行写命令时,将命令复制到磁盘中。
- 优点:① 数据不丢失或丢失较少(取决于策略);
- 缺点:① 数据恢复速度慢,因为是把之前执行过的命令都再执行一遍。② 会频繁写入磁盘;③ 备份文件占用磁盘空间过大。
两种方案可以同时使用。若同时使用,启动Redis时,会优先使用AOF恢复数据。
1.1 RDB(快照模式)
创建RDB快照的方法:
- 执行
save命令:save命令速度快,但会阻塞其他命令。因此生产应禁止使用。 - 执行
bgsave命令:bgsave相对较慢,但是是在后台“子进程”执行,不影响命令正常执行。 - 配置
save <second> <number>:即当<second>秒内发生了<number>次写入时,自动执行bgsave命令。可以配置多个,例如:save 60 10000,save 300 10,save 900 1,即若60秒内写入1w次则自动执行bgsave,如果300秒内写入10次也执行bgsave,最后再来个保底的,900秒内只要发生过一次写入就执行bgsave
BGSAVE注意事项:bgsave会先创建一个子进程,然后将现有内存中的数据复制一份,然后再持久化到硬盘中。因此,主节点最好只使用50%~65%的内存,以免bgsave导致内存溢出。
RDB方法注意事项:
- bgsave占用内存大:bgsave会将现有的数据拷贝一份,然后dump到硬盘中。因此,至少需要预留50%的内存空间
- bgsave的fork操作:bgsave执行时,首先会创建一个子进程(fork操作)。但是该fork操作是单线程的,其他命令需要排队。
- 数据丢失问题:如果只用rdb做备份,那么redis宕机后,就会丢失“上次备份”到“崩溃前”这段时间写入的数据。
1.2 AOF 模式
AOF的配置方法:修改redis.conf配置文件
# 这里改成yes
appendonly yes
# 配置策略,包含三种策略:always、everysec、no
appendfsync everysec
AOF的三种持久化策略:
- always:每个写命令都写入硬盘,数据基本不会丢失,最多丢失一条。风险点:① 若写入频繁,磁盘写入跟不上内存写入;② 若使用固态硬盘,频繁写入会缩短硬盘寿命;
- everysec(推荐):每秒写入一次。最多丢失一秒的数据。很好的平衡了数据丢失问题与磁盘频繁写入问题。
- no:系统自己决定什么时候写入,大约30s。不推荐,这样还不如不用AOF。
AOP的注意事项:
- 磁盘占用大:由于AOF会记录每条写日志,所以磁盘占用过大。因此,需要监控磁盘容量,避免出问题。
- 恢复时间长:AOF的恢复是逐条在执行一遍写操作。若仅使用AOF做备份,那么Redis宕机后的重启会过慢
- AOF重写机制:AOF的重写机制会定期重写AOF文件,降低文件大小(例如:对一个频繁更改的key,仅保留最后一个写命令即可)。但,重写期间会占用IO和CPU资源
2. Redis主从模型(高可用)
使用Redis的主从模式可以实现Redis的高可用。在主从模式下,Redis的一个主节点可以有多个主节点。主节点负责读写,从节点负责备份主节点数据。(也可以使用主从模式做读写分离,也就是读从节点,但会有延迟)。
当Redis主节点宕机后,Redis会自动从从节点中选举一个节点作为新的主节点。因此,只要保证主节点和所有的从节点不一起宕机,就可以保证Redis的高可用。
2.1 Redis的主从复制
为了保证主节点和从节点的数据一致,需要进行主从复制。即,将主节点的数据同步给从节点。
主从同步有两种:
- 全量同步:将主节点的数据全部同步给从节点。
- 触发场景:若从节点与主节点的数据相差过大时,会进行全量同步。常见场景:① 从节点首次主节点;② 从节点宕机较长时间后,重新连接主节点。
- 判断方式:从节点连接主节点后,会告诉其同步的偏移量(即上次同步到哪个位置了)。主节点会检查缓冲区中的命令是否可以满足要求。若不满足,则全量同步,满足则部分同步。
- 同步方式:全量同步采用RDB方式。具体为:生成RDB文件,发送给从节点。后续开始进行部分同步。
- 部分同步:将近期写入的部分数据同步给从节点。
- 同步方式:当主节点写入命令后,会将命令写入到同步缓冲区(Replication Backlog)。当缓冲区满了,或定期触发时,主节点会将缓冲区的命令传给从节点。
从节点首次/或重连接主节点时的详细同步流程如下:
| 序号 | 主节点 | 从节点 |
|---|---|---|
| 1 | 等待从节点接入 | |
| 2 | 从节点发送SYNC命令连接主节点 | |
| 3 | 主节点执行BGSAVE。 执行过程以及之后用户写入的新命令都记录到缓冲区 | |
| 4 | BGSAVE执行完毕,向从节点发送rdb文件 | |
| 5 | 接收到rdb文件后,丢弃现有数据,载入主节点发过来的rdb文件 | |
| 6 | 向从节点发送缓冲区中的命令 | |
| 7 | 接受缓冲区中的命令,写入到从节点 | |
| 8 | 缓冲区命令发送完毕 | |
| 9 | 主节点收到一条写命令,同步给从节点 | |
| 10 | 从节点执行主节点同步过来的写命令 | |
| 11 | 后续过程就是不断重复9,10步骤 |
如果从节点宕机一小段时间,从节点重新连接后,会告诉主节点上次复制的偏移量。若主节点的缓冲区里有数据,则部分复制,否则会重新全量复制。
与主从复制相关的常用配置:
- slave-read-only=yes:从节点是否只读。一般为yes。因为从节点的写入无法同步给任何机器。
- repl-disable-tcp-nodelay:是否开启主从同步延迟。默认关闭,即每个命令都立刻同步给从节点,延迟低,消耗带宽大。若开启,则主节点会合并部分数据一起发送,节省带宽,但延迟较高(大约40毫秒)。若从节点只用于容灾(不做读写分离),且网络带宽紧张,那么就可以开启。
- repl-backlog-size:复制积压缓冲区大小,用于给从节点同步数据。若从节点要同步的数据超出了缓冲区,则会引起全量同步。 默认1M,建议改为100M,太小容易引起全量同步。
2.2 Redis拓扑结构
Redis主从模式一般可以设计成是三种拓扑结构:一主一从、一主多从、树状主从。
如果有多个主节点同理,上面说的只是站在其中一个主节点的视角说的。
一主一从:一个主节点有一个从节点,通常该从节点用于容灾。
一主一从注意事项和使用技巧:
- 不建议用一主一从做读写分离,这样主从都不能挂,没法做到容灾。
- 可以只在从节点开启AOF持久化,降低主节点压力。但要注意,这样做的话,主节点不要做自动重启,要不然主节点重启后因为没有持久化文件,最后把从节点也清空了,导致数据丢失。
一主多从:一个主节点对应多个从节点。通常用于做读写分离。
一主多从注意事项与使用技巧:
- 若读多写少,可以用一主多从做读写分离,降低主节点压力。
- 但如果读多,写也多,且从节点较多,建议改为树状主从结构,否则主节点的同步压力就太大了。
- 注意复制风暴,当主节点宕机后重启、或一次大量从节点连接主节点时,会同时有大量从节点要求全量复制,造成主节点带宽压力大。可改为树状主从结构解决。
树状主从:主节点有从节点,从节点还有从节点。用于降低主节点的同步压力,由下游的从节点数据来自上游从节点的复制。
3. Redis集群模式(高并发)
所有的写操作一定要在主节点完成,若Redis仅有一个主节点,则无法实现高并发。
因此,Redis之后提供了分布式解决方案,Redis集群。
3.1 Redis的Slots
Redis之所以可以实现高吞吐量,除了基于内存的设计外,更重要的是:Redis是基于Hash算法实现的。
Redis的Hash桶大小为16384,被称为16384个槽(Slots)
当操作key时,Redis首先会使用CRC16(key) % 16384(CRC16是一种Hash算法)计算出该key存放的slot,然后在该slot对其进行操作。
在Redis单主节点模式下,所有的slot都在该主节点上。
在Redis集群模式下(多主节点),slot会平均分到不同的主节点上。例如:
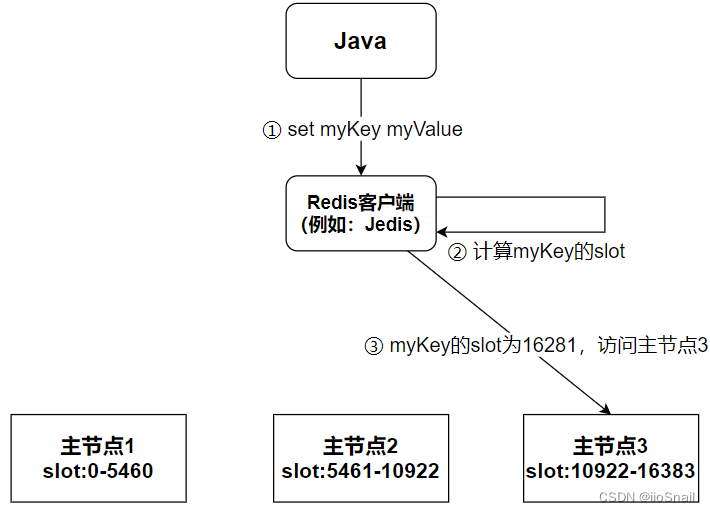
当客户端连接Redis后,会获取到Redis集群的各个节点信息。在对key操作时,客户端会计算key的slot,然后直接访问对应的主节点。
若该slot不在对应的主节点时,会返回moved错误。例如:“(error) MOVED 16281 127.0.0.1:7003”。即该key的slot为16281,其不在该机器上,请移动到“127.0.0.1:7003”上访问。
3.2 集群模式的常用命令
可以使用该项目快速搭建一个Redis集群进行测试
# 查看集群信息,包括集群基本信息、集群状态、slot状态等
> cluster info
# 查看节点信息,包括各节点的IP端口、主从状态、slot范围等
> cluster nodes
# 计算key所属的slot
> cluster keyslot <your-key>
3.3 多主多从架构
使用Redis集群可以将slots分散在不同的主节点上,分散了单机写入的压力,实现了高并发。
使用主从架构可以为一个主节点配置多个从节点,当主节点宕机后可以自动主从切换,实现了高可用。
Redis本身基于Hash算法和内存数据库,可以做到高吞吐量,实现了高性能。
因此,将三者结合起来,则可以实现一个三高Redis:高并发、高可用、高性能。
例如,一个三主六从的Redis架构如下:
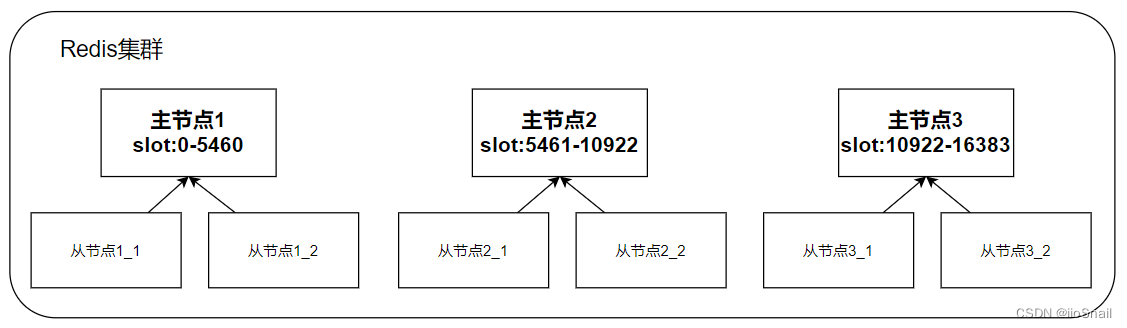
共有三个主节点,平分slot。每个主节点有两个从节点做容灾。
4. Redis的内存管理
4.1 Redis的内存模型
Redis的内存占用主要包含如下部分:
- 数据对象内存:用户存储的数据所占的内存大小。
- 程序自身内存:Redis自身进程所要占用的内存。占用很小。
- 缓冲区内存:Redis有三种缓冲区,分别是:
- 客户端缓冲:客户端对Redis读取和写入都会经过读或写缓冲区。若有大量客户端连接,或有BigKey,可能导致缓冲区内存溢出,引起OOM。
- 复制积压缓冲区:用于给丛节点同步数据。若从节点要求的数据已经不在缓冲区了,则会引起全量同步。建议设置大一点。
- AOF缓冲区:用于AOF重写期间保存最近写入的命令。占用通常很小。
- 内存碎片:为了便于内存管理,Redis内的内存分配器会将内存划分为不同的固定大小的内存块。每个key会选择适合自己大小的内存块来存放数据,但通常不会刚好,总会有些内存被浪费掉,这部分称为内存碎片。
- 子进程内存:(这部分可以被归类到“程序自身内存”中)通常指执行
bgsave或“AOF重写”时创建的子进程。由于要复制一份父进程的数据对象内存,因此内存占用量是数据对象内存的1倍。
4.2 查看Redis内存占用情况
使用info memory命令可以看到Redis的内存使用情况。在展示的结果中,常用的信息如下:
- used_memory:“数据对象内存+程序自身内存+缓冲区”三者所占用的内存总量。
- used_memory_human:used_memory的易读模式。
- used_memory_rss:Redis占用的物理内存,即“used_memory+内存碎片”
- used_memory_peak:used_memory的峰值。帮助运维人员判断redis的最大使用量,防止内存不够用。
- mem_fragmentation_ratio:内存碎片率。计算方式为:
used_memory_rss / used_memory。若mem_fragmentation_ratio较大,说明内存碎片率严重。若mem_fragmentation_ratio<1,说明发生了内存交换(使用到了虚拟内存),需要格外注意。
4.3 Redis内存管理与优化
与Redis内存管理相关的常用设置有:
- maxmemory:最大可用内存(不包含内存碎片),可动态使用修改。通常需要为操作系统和Redis内存碎片预留一部分空间,避免OOM。
- maxmemory-policy:内存回收策略,可动态设置。当内存使用达到maxmemory上限后,使用哪种策略对key进行回收。常用的策略有:
- noeviction:默认策略,不删除数据,给客户端返回OOM错误;
- volatile-lru:删除最近最少使用(LRU)且设置了超时时间的key。若没有可删除的,则按noeviction处理。
- allkeys-lru:删除最近最少使用的key
- volatile-ttl:删除最近将要过期的key。如果没有,则按noeviction处理。
Redis常用的优化策略有:
- 缩短key的长度
- 缩短value的长度:当Redis用作对象缓存时,可以用如下手段降低value长度,包括:① 去掉无用的字段;② json压缩后再存;③ 选用压缩比更高的序列化手段,如:protostuff、kryo等。
- 使用整数:Redis中维护了一个[0-9999]的整数共享对象池。若你的key、value或list、set等内的对象使用的是整数,那么就会共享整数对象,节约内存。注意:当
volatile-lru或allkyes-lru等lru策略时,共享对象池会失效。因为对象要记录自己的lru值(即上次被访问的时间),导致没法共享了。 - 指定
ziplist作为底层数据结构:当使用list/hash/zset时,可以指定使用ziplist作为底层数据结构,这样可以节省空间,不过增改查的效率会受影响,即使用时间换空间。若不是很熟悉数据结构,不建议使用。
5. Redis常见故障处理
5.1 内存溢出
Redis发生OOM或内存突然增加可能是因为如下原因造成的:
- 数据量大:确实是写入的数据太多了。
- 正在执行
bgsave:bgsave的执行会将现在的内存拷贝一份,因此会占用大量内存。典型的现象是:主节点的内存占用量是从节点的一倍。 - 缓冲区被占满:客户端与Redis服务器交互时(写入和读取),会使用缓冲区(详情可参考Redis缓冲区机制)。若写入/读取速度过快,或写入/读取过多BigKey,就会导致缓冲区被占满。
5.2 命令阻塞
现象:客户端收到大量的超时异常
发生命令阻塞的原因可能有:
- 存在慢查询:由于Redis是单线程执行的,若出现慢查询命令,那么后面的命令都会处于等待状态,那如果这个慢查询过慢,那么后面排队的命令对应的客户端可能都会超时。造成慢查询通常是因为“不合理的使用API或数据结构”,例如:
keys *,操作大对象等。 - CPU饱和:Redis是单线程执行的,因此执行命令只会在一个CPU上(其他CPU负责Redis的其他后台线程)。若该CPU饱和,也会造成命令执行阻塞。
- fork子进程:“RDB”和“AOF重写”会fork一个子进程, fork过程是主线程执行的,其它命令需等待。由于fork过程需要拷贝主进程的内存页表,因此,若Redis内存过大,则fork过程就会慢。(通常10GB的redis内存大约有20MB的内存页表)。
- AOF刷盘阻塞:AOF持久化会每秒做一次fsync操作,也就是写入数据到硬盘。若硬盘压力大,fsync操作会等待。若超过2秒未完成,为了保证数据安全,主线程会等待fsync完成后,再执行后续命令。
- CPU竞争:若你的Redis服务器部署了其他程序,那CPU可能被其他程序给抢占了
- 内存交换:如果内存不够大,导致一部分数据存到虚拟内存里,那读写速度会极大变慢,一定要警惕,最好禁止使用虚拟内存。
- 网络问题
参考资料
- Redis设计与实现(黄健宏 著)