yolov8剪枝训练流程
流程:
- 约束
- 剪枝
- 微调
一、正常训练
yolo train model=./weights/yolov8s.pt data=yolo_bvn.yaml epochs=100 amp=False project=prun name=train
二、约束训练
2.1 修改YOLOv8代码:
ultralytics/yolo/engine/trainer.py
添加内容:
# Backward
self.scaler.scale(self.loss).backward()
# ========== 新增 ==========
l1_lambda = 1e-2 * (1 - 0.9 * epoch / self.epochs)
for k, m in self.model.named_modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(l1_lambda * torch.sign(m.weight.data))
m.bias.grad.data.add_(1e-2 * torch.sign(m.bias.data))
# ========== 新增 ==========
# Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
if ni - last_opt_step >= self.accumulate:
self.optimizer_step()
last_opt_step = ni
2.2 训练
需要注意的就是amp=False
yolo train model=prunt/train/weights/best.pt data=yolo_bvn.yaml epochs=100 amp=False project=prun name=constraint
训练完会得到一个best.pt和last.pt,推荐用last.pt
三、剪枝
上一步得到的last.pt作为剪枝对象,运行项目中的prun.py文件:
*这里的剪枝代码仅适用yolov8原模型,如有模块/模型的更改,则需要修改剪枝代码*
运行完会得到prune.pt和prune.onnx可以在netron.app网站拖入onnx文件查看是否剪枝成功了,成功的话可以看到某些通道数字为单数或者一些不规律的数字,如下图:
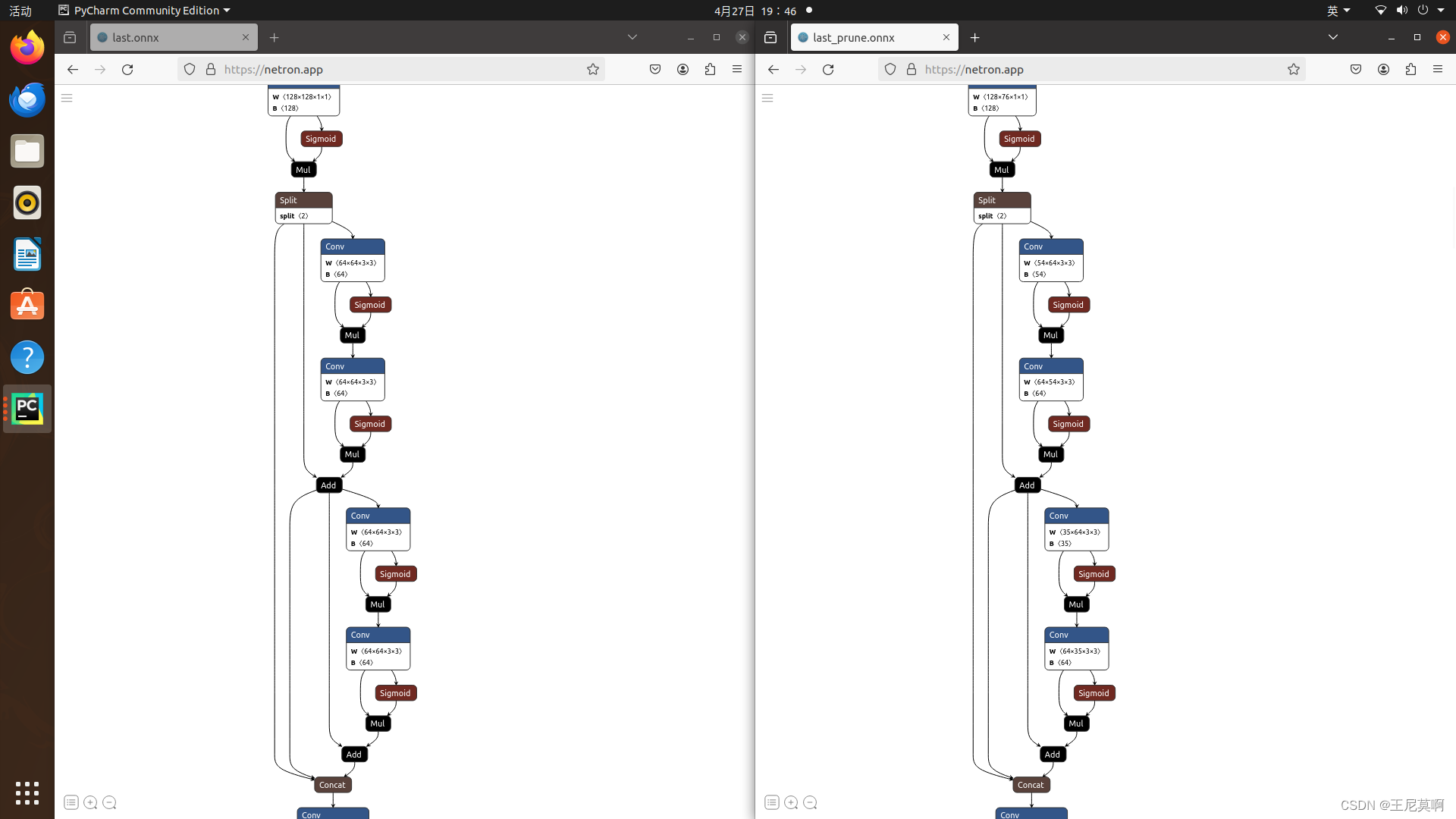
左侧为未剪枝的模型,右侧为剪枝后的模型。
关于yolov8剪枝有以下几点值得注意:
Pipeline:
-
- 为模型的BN增加L1约束,lambda用1e-2左右
-
- 剪枝模型使用的是全局阈值
-
- finetune模型时,一定要注意,此时需要去掉L1约束,最终的final的版本一定是去掉的(在
ultralytics/yolo/engine/trainer.py中注释)
- finetune模型时,一定要注意,此时需要去掉L1约束,最终的final的版本一定是去掉的(在
-
- 对于
yolo.model.named_parameters()循环,需要设置p.requires_grad为True
- 对于
Future work:
-
- 不能剪枝的layer,其实可以不用约束
-
- 对于低于全局阈值的,可以删掉整个module
-
- keep channels,对于保留的channels,它应该能整除n才是最合适的,否则硬件加速比较差
- n怎么选呢?一般fp16时,n为8;int8时,n为16
四、 回调训练(finetune)
回调训练的唯一关键点就在于不让模型从yaml文件加载结构,直接加载pt文件
两种方法(因yolov8版本不同而选择不同方法):
方法一:
3.1 首先要把第一步约束训练的代码注释掉
3.2 修改相关代码,使模型不加载yaml文件
修改位置:yolo/engine/model.py的443行左右
self.model = self.get_model(cfg=cfg, weights=weights, verbose=RANK == -1) # calls Model(cfg, weights)
# ========== 新增该行代码 ==========
self.model = weights
# ========== 新增该行代码 ==========
return ckpt
方法二:
3.1 首先要把第一步约束训练的代码注释掉
3.2 修改相关代码,使模型不加载yaml文件
修改位置:yolo/engine/model.py的335行左右
if not args.get('resume'): # manually set model only if not resuming
# self.trainer.model = self.trainer.get_model(weights=self.model if self.ckpt else None, cfg=self.model.yaml)
# self.model = self.trainer.model
######################上面两行注释掉,添加下面一行#####
self.trainer.model = self.model.train()
##########################修改####################
self.trainer.hub_session = self.session # attach optional HUB session
3.3 修改完代码就可以进行finetun训练了
命令行输入:
yolo train model=prun/prune/weights/last_prune.pt data="yolo_bvn.yaml" amp=False epochs=100 project=prun name=finetune device=0
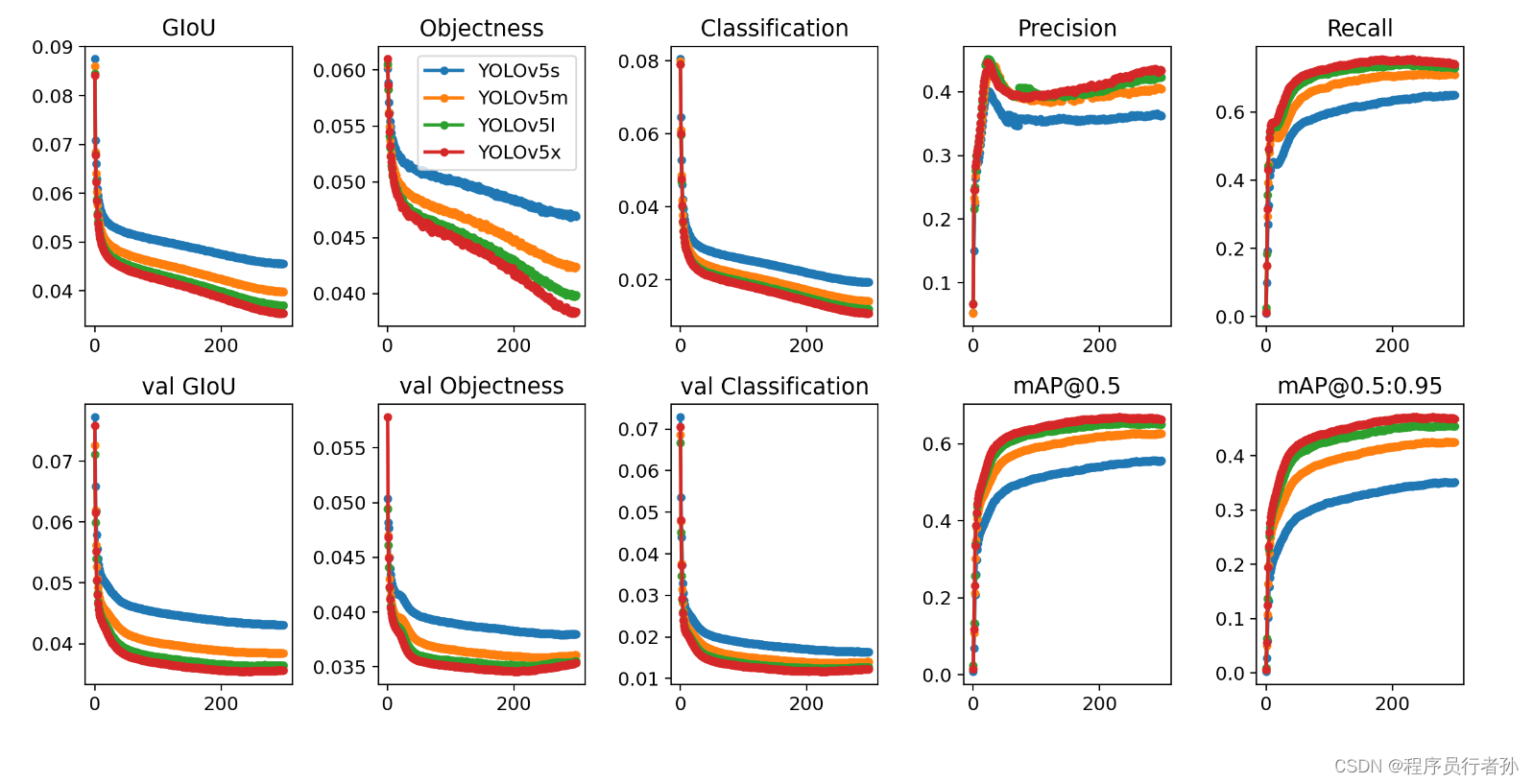
五、结果展示:
5.1模型大小:ONNX模型大小从42M减少到34M
5.2PR曲线:
| 正常训练 | 约束训练 | 100轮微调 |
|---|---|---|
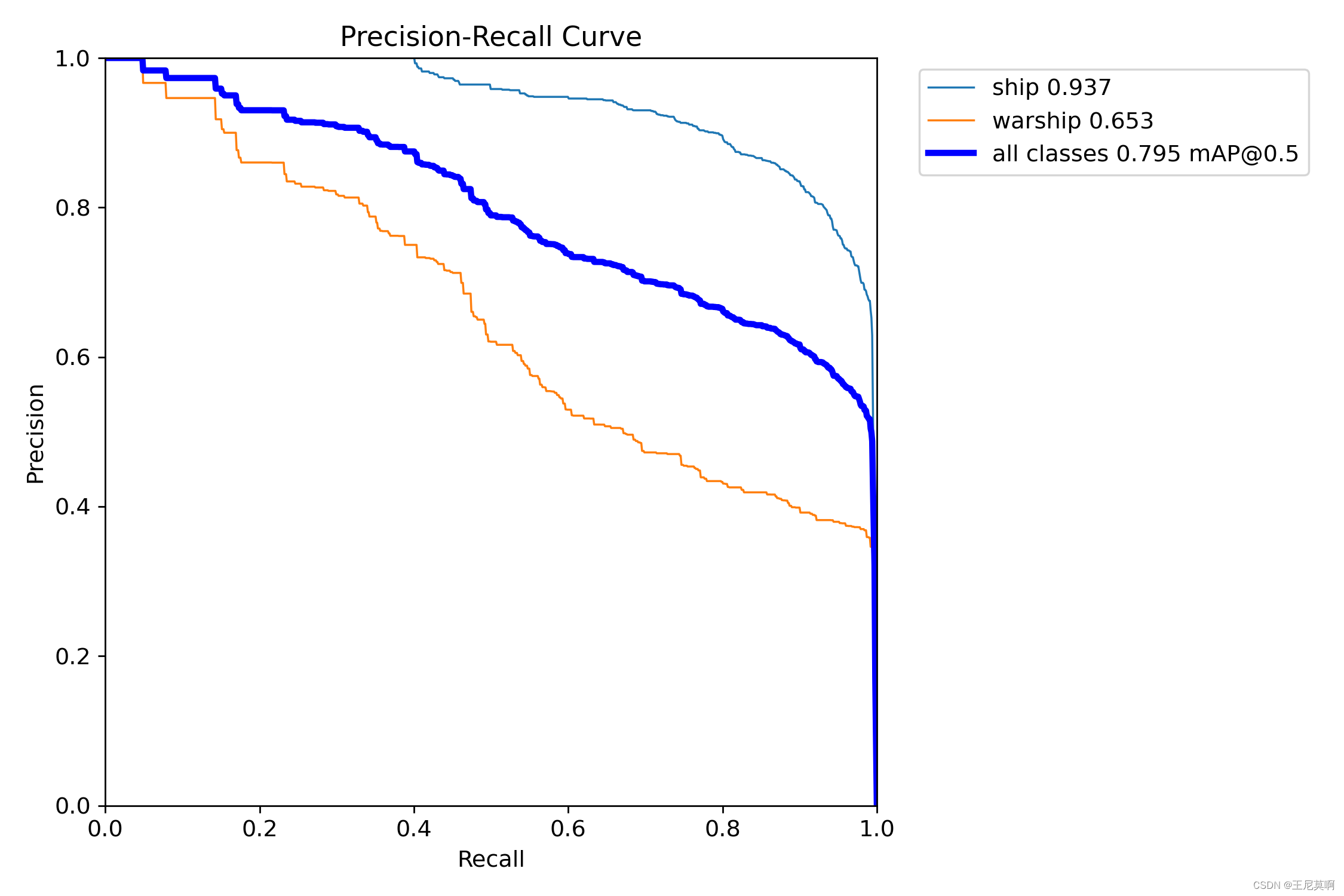 | 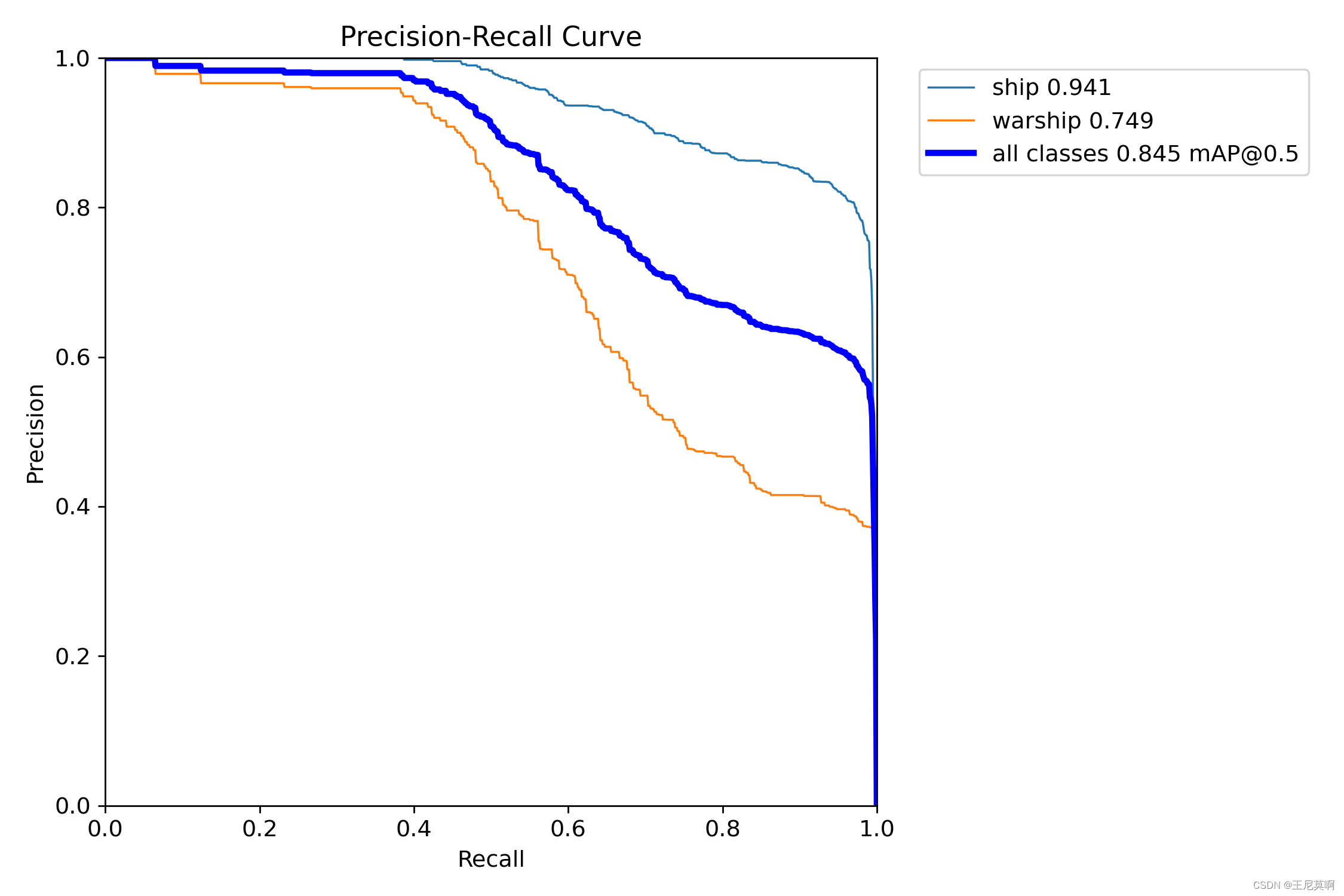 | 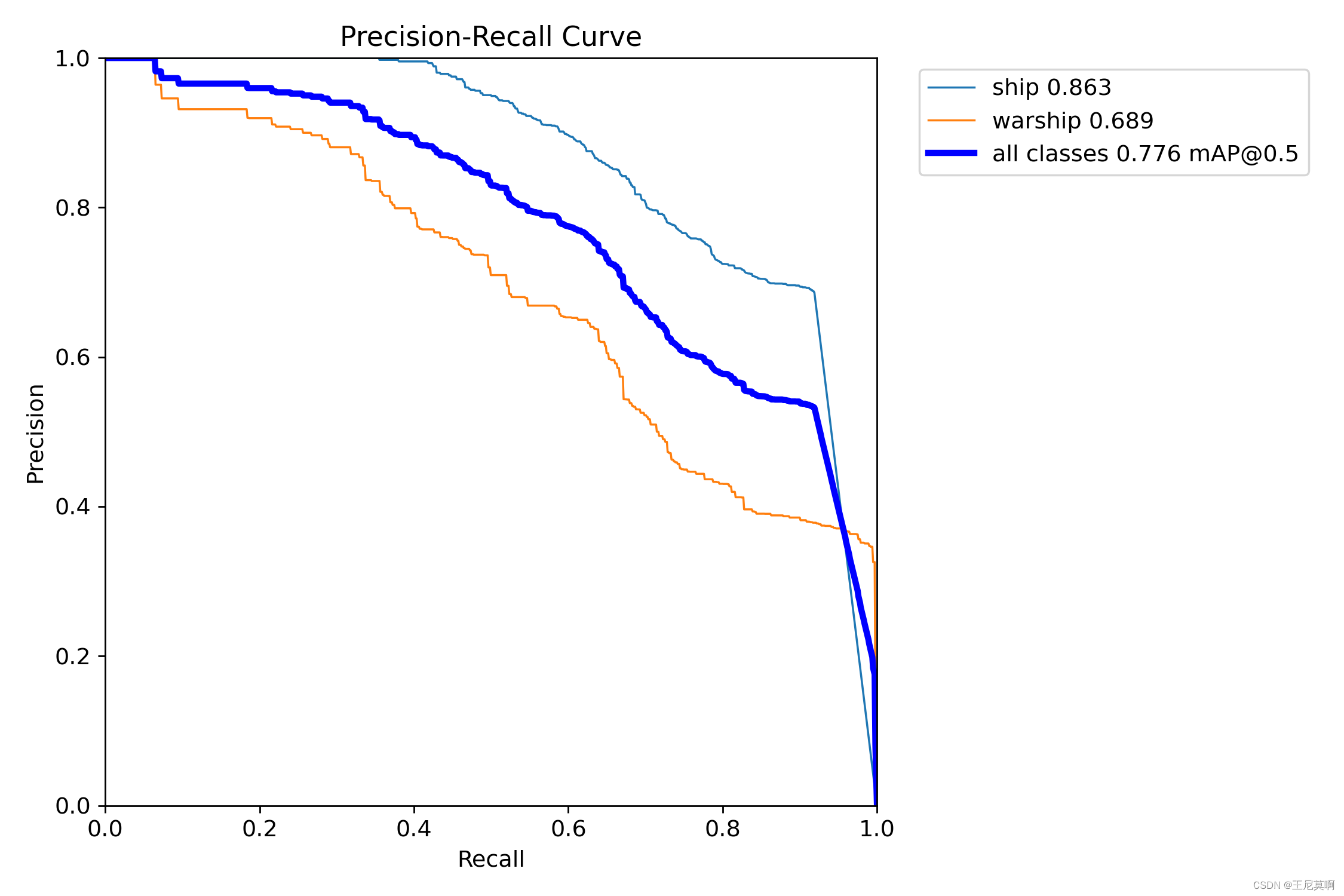 |
5.3实测视频在ubuntu上检测速度:
未剪枝:平均每帧5毫秒
剪枝后:平均每帧3.7毫秒
六、问题及解决:
对剪枝完的yolov8进行finetune时遇到RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument mat2 in method wrapper_mm)
self.proj 可能不在与 pred_dist 相同的设备上。这可能是因为 self.proj 被指定在 CPU 上,而 pred_dist 在 GPU 上(或反之)。
要解决这个问题,需要确保两个张量位于相同的设备上。可以使用 to() 方法将 self.proj 放到与 pred_dist 相同的设备上。
解决:在loss.py添加如下代码:
def bbox_decode(self, anchor_points, pred_dist):
"""Decode predicted object bounding box coordinates from anchor points and distribution."""
if self.use_dfl:
b, a, c = pred_dist.shape # batch, anchors, channels
####添加
device = pred_dist.device
self.proj = self.proj.to(device)
#####
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
return dist2bbox(pred_dist, anchor_points, xywh=False)
七、参考:
7.1 【yolov8系列】 yolov8 目标检测的模型剪枝_yolov8 剪枝-CSDN博客
7.2 YOLOv8剪枝全过程-CSDN博客
7.3 剪枝与重参第七课:YOLOv8剪枝-CSDN博客