原文:
zh.annas-archive.org/md5/d06d282ea0d9c23c57f0ce31225acf76译者:飞龙
协议:CC BY-NC-SA 4.0
第九章:文本生成方法的崛起
在前几章中,我们讨论了不同的方法和技术来开发和训练生成模型。特别是在第六章“使用 GAN 生成图像”中,我们讨论了生成模型的分类以及介绍了显式和隐式类。在整本书中,我们的重点一直是在视觉空间中开发生成模型,利用图像和视频数据集。深度学习在计算机视觉领域的发展以及易于理解性是引入这样一个专注介绍的主要原因。
然而,在过去几年中,自然语言处理(NLP)或文本数据处理受到了极大的关注和研究。文本不只是另一种无结构类型的数据;其背后还有更多东西超出了表面所见。文本数据代表了我们的思想、想法、知识和交流。
在本章和下一章中,我们将专注于理解与 NLP 和文本数据的生成模型相关的概念。我们将在本章中涵盖与文本数据生成模型相关的不同概念、架构和组件,重点关注以下主题:
-
传统表示文本数据方式的简要概述
-
分布式表示方法
-
基于 RNN 的文本生成
-
LSTM 变体和文本卷积
我们将介绍不同架构的内部工作原理和使文本生成用例成为可能的关键贡献。我们还将构建和训练这些架构,以更好地理解它们。读者还应该注意,虽然我们将在第九章“文本生成方法的崛起”和第十章“NLP 2.0:使用 Transformer 生成文本”中深入研究关键贡献和相关细节,但这些模型中的一些非常庞大,无法在常规硬件上进行训练。我们将在必要时利用某些高级 Python 包,以避免复杂性。
本章中呈现的所有代码片段都可以直接在 Google Colab 中运行。由于篇幅原因,未包含依赖项的导入语句,但读者可以参考 GitHub 存储库获取完整的代码:github.com/PacktPublishing/Hands-On-Generative-AI-with-Python-and-TensorFlow-2。
在我们深入建模方面之前,让我们先了解如何表示文本数据。
表示文本
语言是我们存在中最复杂的方面之一。我们使用语言来传达我们的思想和选择。每种语言都有一个叫做字母表的字符列表,一个词汇表和一组叫做语法的规则。然而,理解和学习一门语言并不是一项微不足道的任务。语言是复杂的,拥有模糊的语法规则和结构。
文本是语言的一种表达形式,帮助我们交流和分享。这使得它成为研究的完美领域,以扩展人工智能可以实现的范围。文本是一种无结构数据,不能直接被任何已知算法使用。机器学习和深度学习算法通常使用数字、矩阵、向量等进行工作。这又引出了一个问题:我们如何为不同的与语言相关的任务表示文本?
词袋
正如我们之前提到的,每种语言都包括一个定义的字符列表(字母表),这些字符组合在一起形成单词(词汇表)。传统上,词袋(BoW)一直是表示文本信息的最流行方法之一。
词袋是将文本转换为向量形式的一种简单灵活的方法。这种转换不仅有助于从原始文本中提取特征,还使其适用于不同的算法和架构。正如其名称所示,词袋表示模型将每个单词作为一种基本的度量单位。词袋模型描述了在给定文本语料库中单词的出现情况。为了构建一个用于表示的词袋模型,我们需要两个主要的东西:
-
词汇表:从要分析的文本语料库中已知单词的集合。
-
出现的度量:根据手头的应用/任务选择的东西。例如,计算每个单词的出现次数,称为词频,就是一种度量。
与词袋模型相关的详细讨论超出了本章的范围。我们正在呈现一个高级概述,作为在本章后面引入更复杂主题之前的入门。
词袋模型被称为“袋子”,以突显其简单性和我们忽略出现次数的任何排序的事实。换句话说,词袋模型舍弃了给定文本中单词的任何顺序或结构相关信息。这听起来可能是一个很大的问题,但直到最近,词袋模型仍然是表示文本数据的一种流行和有效的选择。让我们快速看几个例子,了解这种简单方法是如何工作的。
“有人说世界将在火中终结,有人说在冰中。从我尝到的欲望中,我同意那些赞成火的人。”
Fire and Ice by Robert Frost. We'll use these few lines of text to understand how the BoW model works. The following is a step-by-step approach:
-
定义词汇表:
首先且最重要的步骤是从我们的语料库中定义一个已知单词列表。为了便于理解和实际原因,我们现在可以忽略大小写和标点符号。因此,词汇或唯一单词为 {some, say, the, world, will, end, in, fire, ice, from, what, i, have, tasted, of, desire, hold, with, those, who, favour}。
这个词汇表是一个包含 26 个词中的 21 个唯一单词的语料库。
-
定义出现的度量:
一旦我们有了词汇集,我们需要定义如何衡量词汇中每个单词的出现次数。正如我们之前提到的,有很多种方法可以做到这一点。这样的一个指标就是简单地检查特定单词是否存在。如果单词不存在,则使用 0,如果存在则使用 1。因此,句子“some say ice”可以得分为:
-
some: 1
-
say: 1
-
the: 0
-
world: 0
-
will: 0
-
end: 0
-
in: 0
-
fire: 0
-
ice: 1
因此,总向量看起来像[1, 1, 0, 0, 0, 0, 0, 0, 1]。
多年来已经发展了一些其他指标。最常用的指标是:
-
词频
-
TF-IDF,如第七章,使用 GAN 进行风格转移
-
哈希化
-
这些步骤提供了词袋模型如何帮助我们将文本数据表示为数字或向量的高层次概述。诗歌摘录的总体向量表示如下表所示:

图 9.1:词袋表示
矩阵中的每一行对应诗歌中的一行,而词汇表中的唯一单词构成了列。因此,每一行就是所考虑文本的向量表示。
改进此方法的结果涉及一些额外的步骤。这些优化与词汇和评分方面有关。管理词汇非常重要;通常,文本语料库的规模会迅速增大。处理词汇的一些常见方法包括:
-
忽略标点符号
-
忽略大小写
-
移除常见单词(或停用词)如 a, an, the, this 等
-
使用单词的词根形式的方法,如stop代替stopping。词干提取和词形还原是两种这样的方法
-
处理拼写错误
我们已经讨论了不同的评分方法以及它们如何帮助捕捉某些重要特征。词袋模型简单而有效,是大多数自然语言处理任务的良好起点。然而,它存在一些问题,可以总结如下:
-
缺失的上下文:
正如我们之前提到的,词袋模型不考虑文本的排序或结构。通过简单地丢弃与排序相关的信息,向量失去了捕捉基础文本使用上下文的机会。例如,“我肯定”和“我怀疑我肯定”这两句话将具有相同的向量表示,然而它们表达了不同的思想。扩展词袋模型以包括 n-gram(连续词组)而不是单个词确实有助于捕捉一些上下文,但在非常有限的范围内。
-
词汇和稀疏向量:
随着语料库的规模增加,词汇量也在增加。管理词汇量大小所需的步骤需要大量的监督和手动工作。由于这种模型的工作方式,大量的词汇导致非常稀疏的向量。稀疏向量对建模和计算需求(空间和时间)造成问题。激进的修剪和词汇管理步骤在一定程度上确实有所帮助,但也可能导致重要特征的丢失。
在这里,我们讨论了词袋模型如何帮助将文本转换为向量形式,以及这种设置中的一些问题。在下一节,我们将转向一些更多涉及的表示方法,这些方法缓解了一些这些问题。
分布式表示
词袋模型是将单词转换为向量形式的易于理解的方法。这个过程通常被称为向量化。虽然这是一种有用的方法,但在捕获上下文和与稀疏相关的问题方面,词袋模型也有它的局限性。由于深度学习架构正在成为大多数空间的事实上的最先进系统,显而易见的是我们应该在 NLP 任务中也利用它们。除了前面提到的问题,词袋模型的稀疏和大(宽)向量是另一个可以使用神经网络解决的方面。
一种处理稀疏问题的简单替代方案是将每个单词编码为唯一的数字。继续上一节的示例,“有人说冰”,我们可以将“有人”赋值为 1,“说”赋值为 2,“冰”赋值为 3,以此类推。这将导致一个密集的向量,[1, 2, 3]。这是对空间的有效利用,并且我们得到了所有元素都是完整的向量。然而,缺失上下文的限制仍然存在。由于数字是任意的,它们几乎不能单独捕获任何上下文。相反,将数字任意映射到单词并不是非常可解释的。
可解释性是 NLP 任务的重要要求。对于计算机视觉用例,视觉线索足以成为理解模型如何感知或生成输出的良好指标(尽管在那方面的量化也是一个问题,但我们现在可以跳过它)。对于 NLP 任务,由于文本数据首先需要转换为向量,因此重要的是理解这些向量捕获了什么,以及模型如何使用它们。
在接下来的章节中,我们将介绍一些流行的向量化技术,尝试捕捉上下文,同时限制向量的稀疏性。请注意,还有许多其他方法(例如基于 SVD 的方法和共现矩阵)也有助于向量化文本数据。在本节中,我们将只涉及那些有助于理解本章后续内容的方法。
Word2vec
英国牛津词典大约有 60 万个独特的单词,并且每年都在增长。然而,这些单词并非独立的术语;它们彼此之间存在一些关系。word2vec 模型的假设是学习高质量的向量表示,以捕获上下文。这更好地总结了 J.R. 菲斯的著名引文:“你可以通过它搭配的伙伴来认识一个词”。
在他们名为“Vector Space 中单词表示的高效估计”的工作中,Mikolov 等人¹介绍了两种学习大型语料库中单词向量表示的模型。Word2Vec 是这些模型的软件实现,属于学习这些嵌入的迭代方法。与一次性考虑整个语料库不同,这种方法尝试迭代地学习编码每个单词的表示及其上下文。学习词表示作为密集上下文向量的这一概念并不新鲜。这最初是由 Rumelhart 等人于 1990²年提出的。他们展示了神经网络如何学习表示,使类似的单词最终处于相同的聚类中。拥有捕获某种相似性概念的单词向量形式的能力是非常强大的。让我们详细看看 word2vec 模型是如何实现这一点的。
连续词袋 (CBOW) 模型
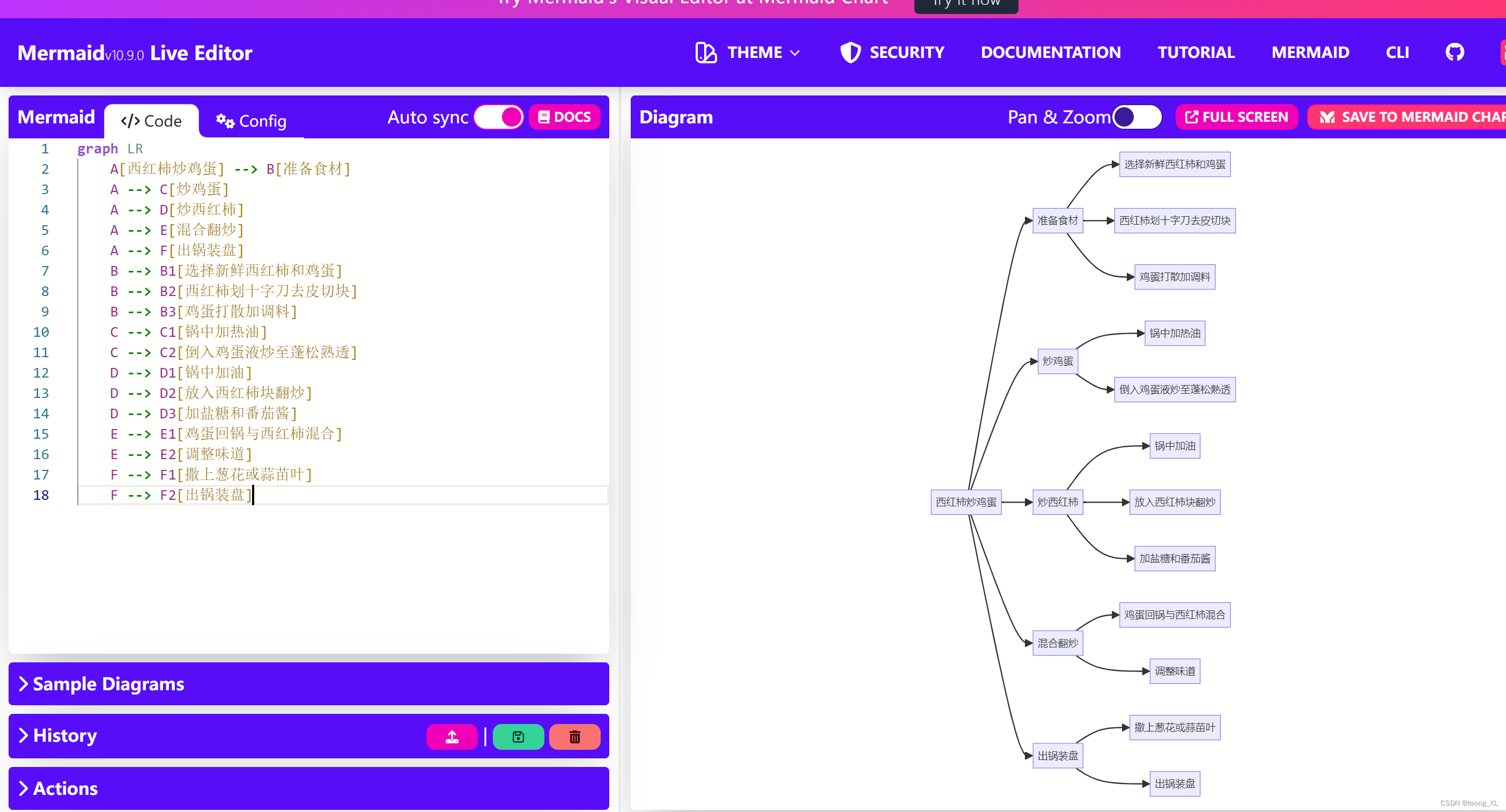
连续词袋模型是我们在上一节讨论的词袋模型的扩展。该模型的关键方面是上下文窗口。上下文窗口被定义为沿着句子移动的固定大小的滑动窗口。中间的词称为目标,窗口内的左右术语称为上下文术语。CBOW 模型通过给定其上下文术语来预测目标术语。
例如,让我们考虑一句参考句子,“some say the world will end in fire”。如果我们的窗口大小为 4,目标术语为world,那么上下文术语将会是{say, the}和{will, end}。模型的输入是形式为(上下文术语,目标术语)的元组,然后将其通过神经网络学习嵌入向量。
这个过程如下图所示:

图 9.2:连续词袋模型设置
如前面的图表所示,上下文术语,表示为 ,被作为输入传递给模型,以预测目标术语,表示为w[t]。CBOW 模型的整体工作可以解释如下:
,被作为输入传递给模型,以预测目标术语,表示为w[t]。CBOW 模型的整体工作可以解释如下:
-
对于大小为V的词汇表,定义了大小为C的上下文窗口。C可以是 4、6 或任何其他大小。我们还定义了两个矩阵W和W’来生成输入和输出向量。矩阵W是VxN,而W’是NxV的维度。N是嵌入向量的大小。
-
上下文术语(
 )和目标术语(y)被转化为独热编码(或标签编码),并且训练数据以元组的形式准备:(
)和目标术语(y)被转化为独热编码(或标签编码),并且训练数据以元组的形式准备:( ,y)。
,y)。 -
我们对上下文向量进行平均以得到
 。
。 -
最终的输出评分向量 z 是平均向量 v’ 和输出矩阵 W’ 的点积。
-
输出评分向量经过 softmax 函数转换为概率值;也就是说,y’ = softmax(z),其中 y’ 应该对应词汇表中的一个术语。
-
最终的目标是训练神经网络,使得 y’ 和实际目标 y 尽可能接近。
作者建议使用诸如交叉熵之类的成本函数来训练网络并学习这样的嵌入。
skip-gram 模型
skip-gram 模型是该论文中用于学习词嵌入的第二个变体。本质上,该模型的工作方式与 CBOW 模型完全相反。换句话说,在 skip-gram 的情况下,我们输入一个词(中心/目标词),预测上下文术语作为模型的输出。让我们用之前的例子进行说明,“some say the world will end in fire”。在这里,我们将用 world 作为输入术语,并训练一个模型以高概率预测 {say, the, will, end},作为上下文术语。
下图显示了 skip-gram 模型;如预期的那样,这是我们在 图 9.2 中讨论的 CBOW 设置的镜像:

图 9.3:skip-gram 模型设置
skip-gram 模型的逐步工作可以解释如下:
-
对于一个大小为 V 的词汇表,定义一个大小为 C 的上下文窗口。C 可以是 4、6 或其他任意大小。我们还定义了两个矩阵 W 和 W’,分别用于生成输入向量和输出向量。矩阵 W 是 VxN 的,而 W’ 的维度是 NxV。N 是嵌入向量的大小。
-
生成中心词 x 的独热编码表示。
-
通过 x 和 W 的点积来获取 x 的词嵌入表示。嵌入表示为 v = W.x。
-
我们通过将 W’ 和 v 的点积得到输出评分向量 z;也就是说,z = W’.v。
-
评分向量通过 softmax 层转换为输出概率,生成 y’。
-
最终的目标是训练神经网络,使得 y’ 和实际上的上下文 y 尽可能接近。
在 skip-gram 的情况下,对于任何给定的中心词,我们有多个输入-输出训练对。该模型将所有上下文术语都视为同等重要,无论它们与上下文窗口中的中心词之间的距离如何。这使我们能够使用交叉熵作为成本函数,并假设具有强条件独立性。
为了改善结果并加快训练过程,作者们引入了一些简单但有效的技巧。负采样、噪声对比估计和分层 softmax等概念是一些被利用的技术。要详细了解 CBOW 和 skip-gram,请读者阅读 Mikolov 等人引用的文献¹,作者在其中详细解释了每个步骤。
nltk to clean up this dataset and prepare it for the next steps. The text cleanup process is limited to lowercasing, removing special characters, and stop word removal only:
# import statements and code for the function normalize_corpus
# have been skipped for brevity. See corresponding
# notebook for details.
cats = ['alt.atheism', 'sci.space']
newsgroups_train = fetch_20newsgroups(subset='train',
categories=cats,
remove=('headers', 'footers',
'quotes'))
norm_corpus = normalize_corpus(newsgroups_train.data)
gensim to train a skip-gram word2vec model:
# tokenize corpus
tokenized_corpus = [nltk.word_tokenize(doc) for doc in norm_corpus]
# Set values for various parameters
embedding_size = 32 # Word vector dimensionality
context_window = 20 # Context window size
min_word_count = 1 # Minimum word count
sample = 1e-3 # Downsample setting for frequent words
sg = 1 # skip-gram model
w2v_model = word2vec.Word2Vec(tokenized_corpus, size=embedding_size,
window=context_window,
min_count =min_word_count,
sg=sg, sample=sample, iter=200)
只需几行代码,我们就可以获得我们词汇表的 word2vec 表示。检查后,我们发现我们的词汇表中有 19,000 个独特单词,并且我们为每个单词都有一个向量表示。以下代码片段显示了如何获得任何单词的向量表示。我们还将演示如何获取与给定单词最相似的单词:
# get word vector
w2v_model.wv['sun']
array([ 0.607681, 0.2790227, 0.48256198, 0.41311446, 0.9275479,
-1.1269532, 0.8191313, 0.03389674, -0.23167856, 0.3170586,
0.0094937, 0.1252524, -0.5247988, -0.2794391, -0.62564677,
-0.28145587, -0.70590997, -0.636148, -0.6147065, -0.34033248,
0.11295943, 0.44503215, -0.37155458, -0.04982868, 0.34405553,
0.49197063, 0.25858226, 0.354654, 0.00691116, 0.1671375,
0.51912665, 1.0082873 ], dtype=float32)
# get similar words
w2v_model.wv.most_similar(positive=['god'])
[('believe', 0.8401427268981934),
('existence', 0.8364629149436951),
('exists', 0.8211747407913208),
('selfcontradictory', 0.8076522946357727),
('gods', 0.7966105937957764),
('weak', 0.7965559959411621),
('belief', 0.7767481803894043),
('disbelieving', 0.7757835388183594),
('exist', 0.77425217628479),
('interestingly', 0.7742466926574707)]
前述输出展示了sun这个单词的 32 维向量。我们还展示了与单词god最相似的单词。我们可以清楚地看到,诸如 believe、existence 等单词似乎是最相似的,这是合乎逻辑的,考虑到我们使用的数据集。对于感兴趣的读者,我们在对应的笔记本中展示了使用 TensorBoard 的 3 维向量空间表示。TensorBoard 表示帮助我们直观地理解嵌入空间,以及这些向量是如何相互作用的。
GloVe
word2vec 模型有助于改进各种自然语言处理任务的性能。在相同的动力下,另一个重要的实现叫做 GloVe 也出现了。GloVe 或全局词向量表示于 2014 年由 Pennington 等人发表,旨在改进已知的单词表示技术。³
正如我们所见,word2vec 模型通过考虑词汇表中单词的局部上下文(定义的窗口)来工作。即使这是非常有效的,但还不够完善。单词在不同上下文中可能意味着不同的东西,这要求我们不仅要理解局部上下文,还要理解全局上下文。GloVe 试图在学习单词向量的同时考虑全局上下文。
有一些经典的技术,例如潜在语义分析(LSA),这些技术基于矩阵分解,在捕获全局上下文方面做得很好,但在向量数学等方面做得不太好。
GloVe 是一种旨在学习更好的词表示的方法。GloVe 算法包括以下步骤:
-
准备一个词共现矩阵X,使得每个元素x[i][j]表示单词i在单词j上下文中出现的频率。GloVe 使用了两个固定尺寸的窗口,这有助于捕捉单词之前和之后的上下文。
-
共现矩阵X使用衰减因子进行更新,以惩罚上下文中距离较远的术语。衰减因子定义如下:
 ,其中 offset 是考虑的单词的距离。
,其中 offset 是考虑的单词的距离。 -
然后,我们将准备 GloVe 方程如下软约束条件:

这里,w[i]是主要单词的向量,w[j]是上下文单词的向量,b[i],b[j]是相应的偏差项。
-
最后一步是使用前述约束条件来定义成本函数,其定义如下:

这里,f是一个加权函数,定义如下:

该论文的作者使用
 获得了最佳结果。
获得了最佳结果。
类似于 word2vec 模型,GloVe 嵌入也取得了良好的结果,作者展示了 GloVe 胜过 word2vec 的结果。他们将此归因于更好的问题表述和全局上下文的捕捉。
在实践中,这两种模型的性能差不多。由于需要更大的词汇表来获得更好的嵌入(对于 word2vec 和 GloVe),对于大多数实际应用情况,预训练的嵌入是可用且被使用的。
预训练的 GloVe 向量可以通过多个软件包获得,例如spacy。感兴趣的读者可以探索spacy软件包以获得更多详情。
FastText
Word2Vec 和 GloVe 是强大的方法,在将单词编码为向量空间时具有很好的特性。当涉及到获取在词汇表中的单词的向量表示时,这两种技术都能很好地工作,但对于词汇表之外的术语,它们没有明确的答案。
在 word2vec 和 GloVe 方法中,单词是基本单位。这一假设在 FastText 实现中受到挑战和改进。FastText 的单词表示方面基于 2017 年 Bojanowski 等人的论文使用子词信息丰富化词向量。⁴ 该工作将每个单词分解为一组 n-grams。这有助于捕捉和学习字符组合的不同向量表示,与早期技术中的整个单词不同。
例如,如果我们考虑单词“India”和n=3用于 n-gram 设置,则它将将单词分解为{, <in, ind, ndi, dia, ia>}。符号“<”和“>”是特殊字符,用于表示原始单词的开始和结束。这有助于区分,它代表整个单词,和<in,它代表一个 n-gram。这种方法有助于 FastText 生成超出词汇表的术语的嵌入。这可以通过添加和平均所需 n-gram 的向量表示来实现。
FastText 在处理可能有大量新/词汇表之外术语的用例时,被显示明显提高性能。FastText 是由Facebook AI Research(FAIR)的研究人员开发的,这应该不足为奇,因为在 Facebook 等社交媒体平台上生成的内容是巨大且不断变化的。
随着它的改进,也有一些缺点。由于这种情况下的基本单位是一个 n-gram,因此训练/学习这种表示所需的时间比以前的技术更长。 n-gram 方法还增加了训练这种模型所需的内存量。然而,论文的作者指出,散列技巧在一定程度上有助于控制内存需求。
为了便于理解,让我们再次利用我们熟悉的 Python 库gensim。我们将扩展上一节中 word2vec 模型练习所使用的相同数据集和预处理步骤。以下片段准备了 FastText 模型对象:
# Set values for various parameters
embedding_size = 32 # Word vector dimensionality
context_window = 20 # Context window size
min_word_count = 1 # Minimum word count
sample = 1e-3 # Downsample setting for frequent words
sg = 1 # skip-gram model
ft_model = FastText(tokenized_corpus, size=embedding_size,
window=context_window, min_count = min_word_count, sg=sg, sample=sample, iter=100)
word2vec 模型无法返回单词"sunny"的矢量表示,因为它不在训练词汇表中。以下片段显示了 FastText 仍能生成矢量表示的方法:
# out of vocabulary
ft_model.wv['sunny']
array([-0.16000476, 0.3925578, -0.6220364, -0.14427347, -1.308504,
0.611941, 1.2834805, 0.5174112, -1.7918613, -0.8964722,
-0.23748468, -0.81343293, 1.2371198 , 1.0380564, -0.44239333,
0.20864521, -0.9888209, 0.89212966, -1.1963437, 0.738966,
-0.60981965, -1.1683533, -0.7930039, 1.0648874, 0.5561004,
-0.28057176, -0.37946936, 0.02066167, 1.3181996, 0.8494686,
-0.5021836, -1.0629338], dtype=float32)
这展示了 FastText 如何改进基于 word2vec 和 GloVe 的表示技术。我们可以轻松处理词汇表之外的术语,同时确保基于上下文的密集表示。
现在让我们利用这个理解来开发文本生成模型。
文本生成和 LSTM 的魔法
在前几节中,我们讨论了不同的表示文本数据的方法,以使其适合不同的自然语言处理算法使用。在本节中,我们将利用这种对文本表示的理解来构建文本生成模型。
到目前为止,我们已经使用由不同种类和组合的层组成的前馈网络构建了模型。这些网络一次处理一个训练示例,这与其他训练样本是独立的。我们说这些样本是独立同分布的,或IID。语言,或文本,有点不同。
正如我们在前几节中讨论的,单词根据它们被使用的上下文而改变它们的含义。换句话说,如果我们要开发和训练一种语言生成模型,我们必须确保模型理解其输入的上下文。
循环神经网络(RNNs)是一类允许先前输出用作输入的神经网络,同时具有记忆或隐藏单元。对先前输入的意识有助于捕捉上下文,并使我们能够处理可变长度的输入序列(句子很少长度相同)。下图显示了典型的 RNN,既实际形式又展开形式:

图 9.4:一个典型的 RNN
如图 9.4所示,在时间 t[1],输入 x[1] 生成输出 y[1]。在时间 t[2],x[2] 和 y[1](前一个输出)一起生成输出 y[2],以此类推。与 typcial feedforward 网络不同,其中的每个输入都独立于其他输入,RNN 引入了前面的输出对当前和将来的输出的影响。
RNN 还有一些不同的变体,即门控循环单元(GRUs)和长短期记忆(LSTMs)。之前描述的原始 RNN 在自回归环境中工作良好。但是,它在处理更长上下文窗口(梯度消失)时存在问题。GRUs 和 LSTMs 通过使用不同的门和记忆单元来尝试克服此类问题。LSTMs 由 Hochreiter 和 Schmidhuber 于 1997 年引入,可以记住非常长的序列数据中的信息。LSTMs 由称为输入、输出和遗忘门的三个门组成。以下图表显示了这一点。
 图 9.5:LSTM 单元的不同门
图 9.5:LSTM 单元的不同门
有关 LSTMs 的详细了解,请参阅colah.github.io/posts/2015-08-Understanding-LSTMs/。
现在,我们将重点介绍更正式地定义文本生成任务。
语言建模
基于 NLP 的解决方案非常有效,我们可以在我们周围看到它们的应用。最突出的例子是手机键盘上的自动完成功能,搜索引擎(Google,Bing 等)甚至文字处理软件(如 MS Word)。
自动完成是一个正式概念称为语言建模的常见名称。简单来说,语言模型以某些文本作为输入上下文,以生成下一组单词作为输出。这很有趣,因为语言模型试图理解输入的上下文,语言结构和规则,以预测下一个单词。我们经常在搜索引擎,聊天平台,电子邮件等上使用它作为文本完成工具。语言模型是 NLP 的一个完美实际应用,并展示了 RNN 的威力。在本节中,我们将致力于建立对 RNN 基于语言模型的文本生成的理解以及训练。
让我们从理解生成训练数据集的过程开始。我们可以使用下面的图像来做到这一点。该图像描绘了一个基于单词的语言模型,即以单词为基本单位的模型。在同样的思路下,我们可以开发基于字符,基于短语甚至基于文档的模型:

图 9.6:用于语言模型的训练数据生成过程
正如我们之前提到的,语言模型通过上下文来生成接下来的单词。这个上下文也被称为一个滑动窗口,它在输入的句子中从左到右(从右到左对于从右往左书写的语言)移动。 图 9.6中的滑动窗口跨越三个单词,作为输入。每个训练数据点的对应输出是窗口后面紧跟的下一个单词(或一组单词,如果目标是预测下一个短语)。因此,我们准备我们的训练数据集,其中包括({上下文词汇}, 下一个单词)这种形式的元组。滑动窗口帮助我们从训练数据集中的每个句子中生成大量的训练样本,而无需显式标记。
然后使用这个训练数据集来训练基于 RNN 的语言模型。在实践中,我们通常使用 LSTM 或 GRU 单元来代替普通的 RNN 单元。我们之前讨论过 RNN 具有自动回归到先前时间步的数值的能力。在语言模型的上下文中,我们自动回归到上下文词汇,模型产生相应的下一个单词。然后我们利用时间反向传播(BPTT)通过梯度下降来更新模型权重,直到达到所需的性能。我们在 第三章,深度神经网络的构建模块中详细讨论了 BPTT。
现在我们对语言模型以及准备训练数据集和模型设置所涉及的步骤有了一定的了解。现在让我们利用 TensorFlow 和 Keras 来实现其中一些概念。
实践操作:字符级语言模型
我们在之前的部分中讨论了语言建模的基础知识。在这一部分中,我们将构建并训练自己的语言模型,但是有一点不同。与之前部分的讨论相反,在这里,我们将在字符级别而不是词级别工作。简单来说,我们将着手构建一个模型,将少量字符作为输入(上下文)来生成接下来的一组字符。选择更细粒度的语言模型是为了便于训练这样的模型。字符级语言模型需要考虑的词汇量(或独特字符的数量)要比词级语言模型少得多。
为了构建我们的语言模型,第一步是获取一个数据集用作训练的来源。古腾堡计划是一项志愿者工作,旨在数字化历史著作并提供免费下载。由于我们需要大量数据来训练语言模型,我们将选择其中最大的一本书,列夫·托尔斯泰的 战争与和平。该书可在以下网址下载:
www.gutenberg.org/ebooks/2600
以下代码片段载入了作为我们源数据集的书籍内容:
datafile_path = r'warpeace_2600-0.txt'
# Load the text file
text = open(datafile_path, 'rb').read().decode(encoding='utf-8')
print ('Book contains a total of {} characters'.format(len(text)))
Book contains a total of 3293673 characters
vocab = sorted(set(text))
print ('{} unique characters'.format(len(vocab)))
108 unique characters
下一步是准备我们的数据集用于模型。正如我们在表示文本部分讨论的那样,文本数据被转换为向量,使用词表示模型。一种方法是首先将它们转换为独热编码向量,然后使用诸如 word2vec 之类的模型将其转换为密集表示。另一种方法是首先将它们转换为任意数值表示,然后在 RNN-based 语言模型的其余部分中训练嵌入层。在这种情况下,我们使用了后一种方法,即在模型的其余部分一起训练一个嵌入层。
下面的代码片段准备了单个字符到整数映射的映射:
char2idx = {u:i for i, u in enumerate(vocab)}
idx2char = np.array(vocab)
text_as_int = np.array([char2idx[c] for c in text])
print('{')
for char,_ in zip(char2idx, range(20)):
print(' {:4s}: {:3d},'.format(repr(char), char2idx[char]))
print(' ...\n}')
{
'\n': 0,
'\r': 1,
' ' : 2,
'!' : 3,
...
如你所见,每个唯一的字符都映射到一个整数;例如,\n映射为 0,!映射为 3,依此类推。
为了最佳的内存利用,我们可以利用tf.data API 将我们的数据切片为可管理的片段。我们将我们的输入序列限制在 100 个字符长度,并且这个 API 帮助我们创建这个数据集的连续片段。这在下面的代码片段中展示:
seq_length = 100
examples_per_epoch = len(text)//(seq_length+1)
# Create training examples / targets
char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
for i in char_dataset.take(10):
print(idx2char[i.numpy()])
B
O
O
K
O
N
E
...
split_input_target to prepare the target output as a one-position-shifted transformation of the input itself. In this way, we will be able to generate consecutive (input, output) training pairs using just a single shift in position:
def split_input_target(chunk):
"""
Utility which takes a chunk of input text and target
as one position shifted form of input chunk.
Parameters:
chunk: input list of words
Returns:
Tuple-> input_text(i.e. chunk minus
last word),target_text(input chunk minus the first word)
"""
input_text = chunk[:-1]
target_text = chunk[1:]
return input_text, target_text
dataset = sequences.map(split_input_target)
for input_example, target_example in dataset.take(1):
print ('Input data: ', repr(''.join(idx2char[input_example.numpy()])))
print ('Target data:', repr(''.join(idx2char[target_example.numpy()])))
Input data: '\r\nBOOK ONE: 1805\r\n\r\n\r\n\r\n\r\n\r\nCHAPTER I\r\n\r\n"Well, Prince, so Genoa and Lucca are now just family estat'
Target data: '\nBOOK ONE: 1805\r\n\r\n\r\n\r\n\r\n\r\nCHAPTER I\r\n\r\n"Well, Prince, so Genoa and Lucca are now just family estate'
build_model that prepares a single layer LSTM-based language model:
def build_model(vocab_size, embedding_dim, rnn_units, batch_size):
"""
Utility to create a model object.
Parameters:
vocab_size: number of unique characters
embedding_dim: size of embedding vector.
This typically in powers of 2, i.e. 64, 128, 256 and so on
rnn_units: number of GRU units to be used
batch_size: batch size for training the model
Returns:
tf.keras model object
"""
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim,
batch_input_shape=[batch_size, None]),
tf.keras.layers.LSTM(rnn_units,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'),
tf.keras.layers.Dense(vocab_size)
])
return model
# Length of the vocabulary in chars
vocab_size = len(vocab)
# The embedding dimension
embedding_dim = 256
# Number of RNN units
rnn_units = 1024
model = build_model(
vocab_size = len(vocab),
embedding_dim=embedding_dim,
rnn_units=rnn_units,
batch_size=BATCH_SIZE)
我们已经创建了模型对象。从代码片段中可以看出,模型是一堆嵌入层、LSTM 层和稠密层。嵌入层有助于将原始文本转换为向量形式,然后是 LSTM 和稠密层,它们学习上下文和语言语义。
下一组步骤涉及定义损失函数和编译模型。我们将使用稀疏分类交叉熵作为我们的损失函数。下面的代码片段定义了损失函数和编译模型;我们使用 Adam 优化器进行最小化:
def loss(labels, logits):
return tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)
model.compile(optimizer='adam', loss=loss)
由于我们使用 TensorFlow 和高级 Keras API,训练模型就像调用fit函数一样简单。我们只训练了 10 个时代,使用ModelCheckpoint回调来保存模型的权重,如下面的代码片段所示:
# Directory where the checkpoints will be saved
checkpoint_dir = r'data/training_checkpoints'
# Name of the checkpoint files
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
checkpoint_callback=tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_prefix,
save_weights_only=True)
EPOCHS = 10
history = model.fit(dataset, epochs=EPOCHS, callbacks=[checkpoint_callback])
Epoch 1/10
254/254 [==============================] - 38s 149ms/step - loss: 2.4388
Epoch 2/10
254/254 [==============================] - 36s 142ms/step - loss: 1.7407
.
.
.
Epoch 10/10
254/254 [==============================] - 37s 145ms/step - loss: 1.1530
恭喜,你已经训练了你的第一个语言模型。现在,我们将使用它来生成一些假文本。在我们做到这一点之前,我们需要了解如何解码我们模型生成的输出。
解码策略
早些时候,我们将所有文本数据转换为适合训练和推理的向量形式。现在我们有了一个训练好的模型,下一步是输入一些上下文词,以及生成下一个词作为输出。这个输出生成步骤正式被称为解码步骤。它被称为"解码",因为模型输出一个向量,必须经过处理才能得到实际的词作为输出。有一些不同的解码技术;让我们简要讨论一下流行的:贪婪解码、束搜索和抽样。
贪婪解码
这是最简单和最快的解码策略。正如其名,贪婪解码是一种在每次预测步骤中选择最高概率项的方法。
尽管这样快速高效,但贪婪会在生成文本时产生一些问题。通过仅关注最高概率的输出,模型可能会生成不一致或不连贯的输出。在字符语言模型的情况下,这甚至可能导致非词典词的输出。贪婪解码还限制了输出的差异性,这也可能导致重复的内容。
波束搜索
波束搜索是广泛使用的贪婪解码的替代方法。该解码策略不是选择最高概率的术语,而是在每个时间步长跟踪n个可能的输出。下图说明了波束搜索解码策略。它展示了从步骤 0 开始形成的多个波束,创建了一个树状结构:

图 9.7:基于波束搜索的解码策略
如图 9.7所示,波束搜索策略通过在每个时间步长跟踪n个预测,并最终选择具有总体最高概率的路径来工作,在图中用粗线突出显示。让我们逐步分析在上述图中使用的波束搜索解码示例,假设波束大小为 2。
在时间步骤t[0]:
-
模型预测以下三个单词(带概率)为(the, 0.3),(when, 0.6)和(and, 0.1)。
-
在贪婪解码的情况下,我们将选择"when",因为它的概率最高。
-
在这种情况下,由于我们的波束大小为 2,我们将跟踪前两个输出。
在时间步骤t[2]:
-
我们重复相同的步骤;即,我们跟踪两个波束中的前两个输出。
-
通过沿着分支计算分支的概率,计算波束分数如下:
-
(when, 0.6) –> (the, 0.4) = 0.60.4 = 0.24*
-
(the, 0.3) –> (war, 0.9) = 0.30.9 = 0.27*
-
根据上述讨论,生成的最终输出是"It was July, 1805 the war"。与"它是 1805 年 7 月,当时的战争"这样的输出相比,它的最终概率为 0.27,而"它是 1805 年 7 月,当时的"这样的输出的分数为 0.24,这是贪婪解码给我们的结果。
这种解码策略大大改进了我们在前一节讨论的天真贪婪解码策略。这在某种程度上为语言模型提供了额外的能力,以选择最佳的可能结果。
抽样
抽样是一个过程,在此过程中从更大的总体中选择了预定义数量的观察结果。作为对贪婪解码的改进,可以采用随机抽样解码方法来解决变化/重复问题。一般来说,基于抽样的解码策略有助于根据迄今为止的上下文选择下一个词,即:

在这里,w[t]是在时间步t上的输出,已经根据在时间步t-1之前生成的单词进行了条件化。延续我们之前解码策略的示例,以下图像突出显示了基于采样的解码策略将如何选择下一个单词:

图 9.8:基于采样的解码策略
正如图 9.8所示,该方法在每个时间步从给定的条件概率中随机选择一个单词。在我们的示例中,模型最终通过随机选择in,然后选择Paris作为随后的输出。如果你仔细观察,在时间步t[1],模型最终选择了概率最低的单词。这带来了与人类使用语言方式相关的非常必要的随机性。 Holtzman 等人在其题为神经文本退化的奇特案例的作品⁵中通过陈述人类并不总是简单地使用概率最高的单词来提出了这个确切的论点。他们提出了不同的场景和示例,以突显语言是单词的随机选择,而不是由波束搜索或贪婪解码形成的典型高概率曲线。
这将引入一个重要的参数称为温度。
温度
正如我们之前讨论的,基于采样的解码策略有助于改善输出的随机性。然而,过多的随机性也不理想,因为它可能导致无意义和不连贯的结果。为了控制这种随机性的程度,我们可以引入一个可调参数称为温度。该参数有助于增加高概率项的概率,同时减少低概率项的概率,从而产生更尖锐的分布。高温度导致更多的随机性,而较低的温度则带来可预测性。值得注意的是,这可以应用于任何解码策略。
Top-k 采样
波束搜索和基于采样的解码策略都有各自的优缺点。Top-k 采样是一种混合策略,它兼具两者的优点,提供了更复杂的解码方法。简单来说,在每个时间步,我们不是选择一个随机单词,而是跟踪前 k 个条目(类似于波束搜索),并在它们之间重新分配概率。这给了模型生成连贯样本的额外机会。
实践操作:解码策略
现在,我们对一些最广泛使用的解码策略有了足够的理解,是时候看看它们的实际效果了。
第一步是准备一个实用函数generate_text,根据给定的解码策略生成下一个单词,如下面的代码片段所示:
def generate_text(model, mode='greedy', context_string='Hello',
num_generate=1000,
temperature=1.0):
"""
Utility to generate text given a trained model and context
Parameters:
model: tf.keras object trained on a sufficiently sized corpus
mode: decoding mode. Default is greedy. Other mode is
sampling (set temperature)
context_string: input string which acts as context for the model
num_generate: number of characters to be generated
temperature: parameter to control randomness of outputs
Returns:
string : context_string+text_generated
"""
# vectorizing: convert context string into string indices
input_eval = [char2idx[s] for s in context_string]
input_eval = tf.expand_dims(input_eval, 0)
# String for generated characters
text_generated = []
model.reset_states()
# Loop till required number of characters are generated
for i in range(num_generate):
predictions = model(input_eval)
predictions = tf.squeeze(predictions, 0)
if mode == 'greedy':
predicted_id = np.argmax(predictions[0])
elif mode == 'sampling':
# temperature helps control the character
# returned by the model.
predictions = predictions / temperature
# Sampling over a categorical distribution
predicted_id = tf.random.categorical(predictions,
num_samples=1)[-1,0].numpy()
# predicted character acts as input for next step
input_eval = tf.expand_dims([predicted_id], 0)
text_generated.append(idx2char[predicted_id])
return (context_string + ''.join(text_generated))
代码首先将原始输入文本转换为整数索引。然后我们使用模型进行预测,根据所选择的模式进行操作,贪婪或采样。我们已经从前面的练习中训练了一个字符语言模型,以及一个辅助工具,帮助我们根据所选择的解码策略生成下一个词。我们在以下片段中使用了这两者来理解使用不同策略生成的不同输出:
# greedy decoding
print(generate_text(model, context_string=u"It was in July, 1805
",num_generate=50,mode="greedy"))
# sampled decoding with different temperature settings
print(generate_text(model, context_string=u"It was in July, 1805
",num_generate=50, mode="sampling", temperature=0.3))
print(generate_text(model, context_string=u"It was in July, 1805
",num_generate=50, mode="sampling",temperature=0.9))
使用相同种子与不同解码策略的结果在以下屏幕截图中展示:

图 9.9:基于不同解码策略的文本生成。粗体文本是种子文本,后面是模型生成的输出文本。
这个输出突显了我们迄今讨论的所有解码策略的一些问题以及显著特征。我们可以看到温度的增加如何使模型更具表现力。我们还可以观察到模型已经学会了配对引号甚至使用标点符号。模型似乎还学会了如何使用大写字母。温度参数的增加表现力是以牺牲模型稳定性为代价的。因此,通常在表现力和稳定性之间存在权衡。
这就是我们生成文本的第一种方法的总结;我们利用了 RNNs(特别是 LSTMs)来使用不同的解码策略生成文本。接下来,我们将看一些 LSTM 模型的变体,以及卷积。
LSTM 变体和文本的卷积
当处理序列数据集时,RNNs 非常有用。我们在前一节中看到,一个简单的模型有效地学会了根据训练数据集学到的内容生成文本。
多年来,我们在对 RNNs 建模和使用的方式方面取得了许多改进。在本节中,我们将讨论前一节中讨论的单层 LSTM 网络的两种广泛使用的变体:堆叠和双向 LSTMs。
堆叠的 LSTMs
我们非常清楚神经网络的深度在处理计算机视觉任务时如何帮助其学习复杂和抽象的概念。同样,一个堆叠的 LSTM 架构,它有多个 LSTMs 层依次堆叠在一起,已经被证明能够带来相当大的改进。堆叠的 LSTMs 首次由格雷夫斯等人在他们的工作中提出使用深度循环神经网络进行语音识别⁶。他们强调了深度-多层 RNNs-与每层单位数目相比,对性能的影响更大。
尽管没有理论证明可以解释这种性能提升,经验结果帮助我们理解影响。这些增强可以归因于模型学习复杂特征甚至输入的抽象表示的能力。由于 LSTM 和 RNNs 一般具有时间成分,更深的网络学习在不同时间尺度上运行的能力。⁷
build_model function to do just that:
def build_model(vocab_size, embedding_dim, rnn_units, batch_size,is_bidirectional=False):
"""
Utility to create a model object.
Parameters:
vocab_size: number of unique characters
embedding_dim: size of embedding vector. This typically in powers of 2, i.e. 64, 128, 256 and so on
rnn_units: number of LSTM units to be used
batch_size: batch size for training the model
Returns:
tf.keras model object
"""
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(vocab_size, embedding_dim,
batch_input_shape=[batch_size, None]))
if is_bidirectional:
model.add(tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(rnn_units,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform')))
else:
model.add(tf.keras.layers.LSTM(rnn_units,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'))
model.add(tf.keras.layers.LSTM(rnn_units,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'))
model.add(tf.keras.layers.Dense(vocab_size))
return model
数据集、训练循环,甚至推理工具保持不变。为了简洁起见,我们跳过了再次展示这些代码摘录。我们不久将讨论我们在这里引入的双向参数。
现在,让我们看看这个更深的基于 LSTM 的语言模型的结果是如何的。下面的截图展示了这个模型的结果:

图 9.10: 基于不同解码策略的堆叠 LSTM 的语言模型的文本生成
我们可以清楚地看到,生成的文本如何更好地捕捉到书中的书写风格、大写、标点等方面,比图 9.9中显示的结果更好。这突出了我们讨论过的关于更深的 RNN 结构的一些优势。
双向 LSTM
现在非常广泛使用的第二个变体是双向 LSTM。我们已经讨论过 LSTMs 和 RNNs 生成它们的输出通过利用之前的时间步。当涉及到文本或任何序列数据时,这意味着 LSTM 能够利用过去的上下文来预测未来的时间步。虽然这是一个非常有用的特性,但这并不是我们可以达到的最好水平。让我们通过一个例子来说明为什么这是一个限制:

图 9.11: 查看给定单词的过去和未来上下文窗口
从这个例子可以明显看出,不看目标单词“Teddy”右侧的内容,模型无法正确地获取上下文。为了处理这种情况,引入了双向 LSTM。它们的背后的想法非常简单和直接。双向 LSTM(或者 biLSTM)是两个 LSTM 层同时工作的组合。第一个是通常的前向 LSTM,它按照原始顺序接受输入序列。第二个被称为后向 LSTM,它接受倒置的一份复制作为输入序列。下面的图表展示了一个典型的双向 LSTM 设置:

图 9.12: 双向 LSTM 设置
如图 9.12所示,前向和后向 LSTM 协作处理输入序列的原始和反转副本。由于在任何给定的时间步上有两个 LSTM 单元在不同的上下文上工作,我们需要一种定义输出的方式,以供网络中的下游层使用。输出可以通过求和、乘积、连接,甚至隐藏状态的平均值来组合。不同的深度学习框架可能会设置不同的默认值,但最常用的方法是双向 LSTM 输出的连接。请注意,与双向 LSTM 类似,我们可以使用双向 RNN 或甚至双向 GRU(门控循环单元)。
与普通 LSTM 相比,双向 LSTM 设置具有优势,因为它可以查看未来的上下文。当无法窥视未来时,这种优势也变成了限制。对于当前的文本生成用例,我们利用双向 LSTM 在编码器-解码器类型的架构中。我们利用双向 LSTM 来学习更好地嵌入输入,但解码阶段(我们使用这些嵌入去猜测下一个单词)只使用普通的 LSTM。与早期的实践一样,我们可以使用相同的一套工具来训练这个网络。我们把这留给你来练习;现在我们将继续讨论卷积。
卷积和文本
RNN 在序列对序列任务(例如文本生成)方面非常强大和表现出色。但它们也面临一些挑战:
-
当上下文窗口非常宽时,RNN 会受到消失梯度的影响。虽然 LSTM 和 GRU 在一定程度上克服了这一问题,但是与我们在正常用法中看到的非局部交互的典型情况相比,上下文窗口仍然非常小。
-
RNN 的反复出现使其变得顺序且最终在训练和推断时变得缓慢。
-
我们在上一节介绍的架构试图将整个输入语境(或种子文本)编码成单个向量,然后由解码器用于生成下一组单词。这在种子/语境非常长时会受到限制,正如 RNN 更多地关注上下文中最后一组输入的事实一样。
-
与其他类型的神经网络架构相比,RNN 具有更大的内存占用空间;也就是说,在实现过程中需要更多的参数和更多的内存。
另一方面,我们有卷积网络,在计算机视觉领域经过了战斗的检验。最先进的架构利用 CNN 提取特征,在不同的视觉任务上表现良好。CNN 的成功使研究人员开始探索它们在自然语言处理任务中的应用。
使用 CNN 处理文本的主要思想是首先尝试创建一组单词的向量表示,而不是单个单词。更正式地说,这个想法是在给定句子中生成每个单词子序列的向量表示。
让我们考虑一个示例句子,“流感爆发迫使学校关闭”。首先的目标将是将这个句子分解为所有可能的子序列,比如“流感爆发迫使”,“爆发迫使学校”,…,“学校关闭”,然后为每个子序列生成一个向量表示。虽然这样的子序列可能或可能不带有太多含义,但它们为我们提供了一种理解不同上下文中的单词以及它们的用法的方式。由于我们已经了解如何准备单词的密集向量表示(参见Distributed representation一节),让我们在此基础上了解如何利用 CNNs。
继续前面的例子,图 9.13(A) 描述了每个单词的向量形式。为了方便理解,向量仅为 4 维:

图 9.13:(A)示例句子中每个单词的向量表示(1x4)。 (B)两个大小为 3 的内核/过滤器。 (C)取 Hadamard 乘积后的每个内核的维度为 1x2 的短语向量,然后进行步幅为 1 的求和。
两个大小为 3 的内核分别显示在图 9.13(B) 中。在文本/NLP 用例中,内核的选择为单词向量维度的宽度。大小为 3 表示每个内核关注的上下文窗口。由于内核宽度与单词向量宽度相同,我们将内核沿着句子中的单词移动。这种尺寸和单向移动的约束是这些卷积滤波器被称为 1-D 卷积的原因。输出短语向量显示在图 9.13(C) 中。
类似于用于计算机视觉用例的深度卷积神经网络,上述设置也使我们能够为自然语言处理用例堆叠 1-D 卷积层。更大的深度不仅允许模型捕获更复杂的表示,还允许捕获更广泛的上下文窗口(这类似于增加视觉模型的感受野随深度增加)。
使用 CNNs 用于自然语言处理用例还提高了计算速度,同时减少了训练这种网络所需的内存和时间。事实上,这些都是以下研究中探索的一些使用 1-D CNNs 的自然语言处理任务的优势:
-
自然语言处理(几乎)从零开始,Collobert 等⁸
-
用于文本分类的字符级卷积网络,Zhang 等⁹
-
用于句子分类的卷积神经网络,Kim¹⁰
-
用于文本分类的循环卷积神经网络,Lai 和 Xu 等¹¹
到目前为止,我们已经讨论了 CNNs 如何用于提取特征并为自然语言处理用例捕获更大的上下文。与语言相关的任务,特别是文本生成,与之相关的有一定的时间方面。因此,下一个显而易见的问题是,我们是否可以利用 CNNs 来理解时间特征,就像 RNNs 一样?
研究人员已经探索使用 CNN 进行时间或序贯处理已经有一段时间了。虽然我们讨论了 CNN 如何是捕捉给定单词上下文的好选择,但这对于某些用例来说存在问题。例如,像语言建模/文本生成这样的任务需要模型理解上下文,但只需来自一侧。简单来说,语言模型通过查看已处理的单词(过去上下文)来生成未来单词。但 CNN 也可以覆盖未来的时间步。
从 NLP 领域稍微偏离,Van den Oord 等人关于 PixelCNNs¹²和 WaveNets¹³的作品对于理解 CNN 在时间设置中的应用特别重要。他们提出了因果卷积的概念,以确保 CNN 只利用过去而不是未来上下文。这一概念在下图中得到了突出:

图 9.14:基于 Van den Oord 等人¹³的 CNN 的因果填充。 图 2
因果卷积确保模型在任何给定的时间步t都会进行p(x[t+1] | x[1:][t])类型的预测,并且不依赖于未来的时间步x[t+1],x[t+2] … x[t+][T],正如 图 9.14所示。在训练过程中,可以并行地为所有时间步进行条件预测;但生成/推理步骤是顺序的;每个时间步的输出都会反馈给模型以进行下一个时间步的预测。
由于这个设置没有任何循环连接,模型训练速度更快,哪怕是更长序列也一样。因果卷积的设置最初来源于图像和音频生成用例,但也已扩展到 NLP 用例。WaveNet 论文的作者此外利用了一个称为dilated convolutions的概念,以提供更大的感知域,而不需要非常深的架构。
这种利用 CNN 捕捉和使用时间组件的想法已经为进一步探索打开了大门。
在我们进入下一章涉及更复杂的注意力和变换器架构之前,有必要强调一些先前的重要作品:
-
Kalchbrenner 等人¹⁴的时间内神经机器翻译介绍了基于编码器-解码器架构的 ByteNet 神经翻译模型。总体设置利用 1-D 因果卷积,以及扩张核,以在英德翻译任务上提供最先进的性能。
-
Dauphin 等人在他们名为具有门控卷积的语言建模的作品中提出了一个基于门控卷积的语言模型。(15) 他们观察到他们的门控卷积提供了显着的训练加速和更低的内存占用。
-
Gehring 等人¹⁶和 Lea 等人¹⁷的作品进一步探讨了这些想法,并提供了更好的结果。
-
感兴趣的读者还可以探索 Bai 等人的一篇题为基于序列建模的通用卷积和循环网络的实证评估的论文¹⁸。该论文为基于循环神经网络(RNN)和卷积神经网络(CNN)的架构提供了一个很好的概述,用于序列建模任务。
这结束了我们对语言建模旧架构的基本要素的讨论。
总结
祝贺你完成了涉及大量概念的复杂章节。在本章中,我们涵盖了处理文本数据以进行文本生成任务的各种概念。我们首先了解了不同的文本表示模型。我们涵盖了大多数广泛使用的表示模型,从词袋到 word2vec 甚至 FastText。
本章的下一部分重点讨论了发展对基于循环神经网络(RNN)的文本生成模型的理解。我们简要讨论了什么构成了语言模型以及我们如何为这样的任务准备数据集。之后我们训练了一个基于字符的语言模型,生成了一些合成文本样本。我们涉及了不同的解码策略,并用它们来理解我们 RNN 模型的不同输出。我们还深入探讨了一些变种,比如堆叠 LSTM 和双向 LSTM 的语言模型。最后,我们讨论了在 NLP 领域使用卷积网络的情况。
在下一章中,我们将重点关注 NLP 领域一些最新和最强大架构的基本构件,包括注意力和Transformers。
参考文献
-
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). 词向量的高效估计. arXiv.
arxiv.org/abs/1301.3781 -
Rumelhart, D.E., & McClelland, J.L. (1987). 分布表示, in 并行分布式处理: 认知微结构探索:基础, pp.77-109. MIT Press.
web.stanford.edu/~jlmcc/papers/PDP/Chapter3.pdf -
Pennington, J., Socher, R., & Manning, C.D. (2014). GloVe: 全局词向量表示. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).
nlp.stanford.edu/pubs/glove.pdf -
Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). 使用子词信息丰富词向量. arXiv.
arxiv.org/abs/1607.04606 -
Holtzman, A., Buys, J., Du, L., Forbes, M., & Choi, Y. (2019). 神经文本退化的好奇案例. arXiv.
arxiv.org/abs/1904.09751 -
Graves, A., Mohamed, A., & Hinton, G. (2013). 深度循环神经网络语音识别. arXiv.
arxiv.org/abs/1303.5778 -
Pascanu, R., Gulcehre, C., Cho, K., & Bengio, Y. (2013). 如何构建深度循环神经网络. arXiv.
arxiv.org/abs/1312.6026 -
Collobert, R., Weston, J., Karlen, M., Kavukcuoglu, K., & Kuksa, P. (2011). 几乎从零开始的自然语言处理. arXiv.
arxiv.org/abs/1103.0398 -
Zhang, X., Zhao, J., & LeCun, Y. (2015). 用于文本分类的字符级卷积网络. arXiv.
arxiv.org/abs/1509.01626 -
Kim, Y. (2014). 用于句子分类的卷积神经网络. arXiv.
arxiv.org/abs/1408.5882 -
Lai, S., Xu, L., Liu, K., & Zhao, J. (2015). 用于文本分类的循环卷积神经网络. 第二十九届 AAAI 人工智能大会论文集。
zhengyima.com/my/pdfs/Textrcnn.pdf -
van den Oord, A., Kalchbrenner, N., Vinyals, O., Espeholt, L., Graves, A., & Kavukcuoglu, K. (2016). 具有 PixelCNN 解码器的条件图像生成. arXiv.
arxiv.org/abs/1606.05328 -
van den Oord, A., Dieleman, S., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A., Kavukcuoglu, K. (2016). WaveNet:用于原始音频的生成模型.
arxiv.org/abs/1609.03499 -
Kalchbrenner, N., Espeholt, L., Simonyan, K., van den Oord, A., Graves, A., & Kavukcuoglu, K. (2016). 线性时间内的神经机器翻译. arXiv.
arxiv.org/abs/1609.03499 -
Dauphin, Y.N., Fan, A., Auli, M., & Grangier, D. (2016). 带门卷积网络的语言建模. arXiv.
arxiv.org/abs/1612.08083 -
Gehring, J., Auli, M., Grangier, D., Yarats, D., & Dauphin, Y.N. (2017). 卷积序列到序列学习. arXiv.
arxiv.org/abs/1705.03122 -
Lea, C., Flynn, M.D., Vidal, R., Reiter, A., & Hager, G.D. (2016). 用于动作分割和检测的时态卷积网络. arXiv.
arxiv.org/abs/1611.05267 -
Bai, S., Kolter, J.Z., & Koltun, V. (2018). 对序列建模的通用卷积和循环网络的经验评估. arXiv.
arxiv.org/abs/1803.01271
第十章:NLP 2.0:使用 Transformers 生成文本
正如我们在上一章中看到的,NLP 领域在我们理解、表示和处理文本数据的方式上取得了一些显著的飞跃。从使用 LSTMs 和 GRUs 处理长距离依赖/序列到使用 word2vec 和相关技术构建密集向量表示,该领域整体上取得了显著的改进。随着词嵌入几乎成为事实上的表示方法,以及 LSTMs 成为 NLP 任务的主力军,我们在进一步增强方面遇到了一些障碍。将嵌入与 LSTM 结合使用的这种设置充分利用了编码器-解码器(以及相关体系结构)风格模型。
我们在上一章中简要地看到了由于基于 CNN 的体系结构在 NLP 用例中的研究和应用而实现的某些改进。在本章中,我们将涉及导致当前最先进的 transformer 架构开发的下一组增强功能。我们将重点关注:
-
注意力的概述以及 transformers 如何改变 NLP 领域
-
GPT 系列模型,提供基于 GPT-2 的文本生成流程的逐步指南
我们将涵盖注意力、自注意力、上下文嵌入,最后是 transformer 架构等主题。
本章中呈现的所有代码片段都可以直接在 Google Colab 中运行。由于空间原因,未包含依赖项的导入语句,但读者可以参考 GitHub 存储库获取完整的代码:github.com/PacktPublishing/Hands-On-Generative-AI-with-Python-and-TensorFlow-2。
让我们首先把注意力转向注意力。
注意力
我们用于准备第一个文本生成语言模型的基于 LSTM 的架构存在一个主要限制。RNN 层(一般来说,可能是 LSTM 或 GRU 等)以定义大小的上下文窗口作为输入,并将其全部编码为单个向量。在解码阶段可以使用它开始生成下一个标记之前,这个瓶颈向量需要在自身中捕获大量信息。
注意力是深度学习空间中最强大的概念之一,真正改变了游戏规则。注意力机制背后的核心思想是在解码阶段使用之前利用 RNN 的所有中间隐藏状态来决定要关注哪个。更正式地表达注意力的方式是:
给定一组值的向量(所有 RNN 的隐藏状态)和一个查询向量(这可能是解码器的状态),注意力是一种计算值的加权和的技术,依赖于查询。
加权和作为隐藏状态(值向量)中包含的信息的选择性摘要,而查询决定了要关注哪些值。注意机制的根源可以在与神经机器翻译(NMT)架构相关的研究中找到。NMT 模型特别在对齐问题上遇到困难,而注意力在这方面大大帮助了。例如,从英语翻译成法语的句子可能不是单词一对一匹配的。注意力不仅限于 NMT 用例,而且广泛应用于其他 NLP 任务,如文本生成和分类。
这个想法非常简单,但我们如何实现和使用它呢?图 10.1展示了注意力机制的工作示例。图表展示了时间步t上展开的 RNN。

图 10.1:带有注意机制的简单 RNN
提到图表,我们来逐步了解注意力是如何计算的:
-
让 RNN 编码器隐藏状态表示为h[1]、h[2]…、h[N],当前输出向量为s[t]。
-
首先,我们计算时间步t的注意分数 e^t 如下:

这一步也被称为对齐步骤。
-
然后,我们将这个分数转换成注意力分布:
 。
。 -
使用 softmax 函数帮助我们将分数转换为总和为 1 的概率分布。
-
最后一步是计算注意力向量a[t],也称为上下文向量,方法是将编码器隐藏状态加权求和:
 :
:
一旦我们得到了注意向量,我们就可以简单地将其与先前时间步的解码器状态向量连接起来,并像以前一样继续解码向量。
到目前为止,各种研究人员已经探索了注意机制的不同变体。需要注意的一些重要点包括:
-
注意计算的前述步骤在所有变体中都相同。
-
然而,区别在于计算注意力分数(表示为e^t)的方式。
广泛使用的注意力评分函数有基于内容的注意力,加法注意力,点积和缩放的点积。鼓励读者进一步探索以更好地了解这些。
上下文嵌入
从基于 BoW 的文本表示模型到无监督的密集表示技术(如 word2vec、GloVe、fastText 等)的大跨越是改善深度学习模型在 NLP 任务上表现的秘密武器。然而,这些表示方法也有一些局限性,我们会提醒自己:
-
单词的含义取决于使用的上下文。这些技术导致无论上下文如何,都会得到相同的向量表示。虽然可以通过使用非常强大的词义消歧方法(例如使用监督学习算法消除单词歧义)来解决这个问题,但从本质上来讲,这并没有被任何已知技术所捕捉到。
-
单词可以有不同的用法、语义和句法行为,但单词表示保持不变。
仔细思考一下,我们在上一章中使用 LSTMs 准备的架构正试图在内部解决这些问题。为了进一步阐述,让我们快速回顾一下我们建立的架构:
-
我们开始将输入文本转换为字符或单词嵌入。
-
然后,这些嵌入向量通过一个 LSTM 层(或者一组 LSTM 层,甚至是双向 LSTM 层),最终的隐藏状态被转换和解码以生成下一个标记。
虽然起始点利用了预训练嵌入,这些嵌入在每个上下文中具有相同的表示,但 LSTM 层引入了上下文。一组 LSTM 层分析令牌序列,每一层都试图学习与语言句法、语义等相关的概念。这为每个令牌(单词或字符)的表示提供了非常重要的上下文。
Peters 等人在 2017 年提出的TagLM架构是第一批提供见解的工作之一,说明了如何将预训练的词嵌入与预训练的神经语言模型结合起来,为下游 NLP 任务生成具有上下文意识的嵌入向量。
改变了 NLP 领域的巨大突破是ELMo,即来自语言模型的嵌入。ELMo 架构由 Peters 等人在他们 2018 年的作品Deep Contextualized Word Representations中提出。不详细展开,ELMo 架构的主要亮点是:
-
模型使用基于双向 LSTM 的语言模型。
-
Character CNNs 被用来生成嵌入向量,取代了预训练的词向量,这些向量利用了 4096 个 LSTM 单元,但通过前向传播层转换成了更小的 512 大小的向量。
-
模型利用剩余层来帮助在架构的深层之间传递梯度。这有助于防止梯度消失等问题。
-
主要创新之处在于利用所有隐藏的双向 LSTM 层来生成输入表示。与以前的作品不同,在以前的作品中,只使用最终的 LSTM 层来获取输入表示,这项工作对所有隐藏层的隐藏状态进行加权平均。这有助于模型学习上下文词嵌入,其中每一层都有助于语法和语义等方面。
ELMo 备受关注的原因并不是它帮助提高了性能,而是 ELMo 学习的上下文嵌入帮助它在以往的架构上改进了最先进的性能,不仅在几个 NLP 任务上,而且几乎所有的任务上(详见论文)。
Howard 和 Ruder 在 2018 年提出的ULMFiT模型基于类似的概念,并帮助推广了在 NLP 领域的迁移学习的广泛应用。³
自注意力
我们已经简要讨论了注意力机制及其对改进 NLP 模型的影响。在本节中,我们将讨论关于注意力机制的后续改进,即自注意力。
自注意力是由程先生等人在他们 2016 年题为用于机器阅读的长短期记忆网络的论文中提出的。⁴ 自注意力概念是建立在注意力的一般思想之上的。自注意力使得模型能够学习当前标记(字符、单词或句子等)与其上下文窗口之间的相关性。换句话说,它是一种注意力机制,相关于给定序列的不同位置,以生成相同序列的表示。可以将其想象为一种将单词嵌入转换为给定句子/序列的方式。原始论文中呈现的自注意力概念如同 图 10.2 所示。

图 10.2:自注意力⁴
让我们尝试理解这张图中展示的自注意力输出。每一行/句子表示模型在每个时间步的状态,当前单词用红色突出显示。蓝色表示模型的注意力,其集中程度由蓝色的深浅表示。因此,上下文中的每个单词都有一定程度地影响当前单词的嵌入。
感兴趣的读者可以探索 Google Brain 团队制作的一个展示名为 Tensor2Tensor(现已废弃,改用 JAX)的框架的 notebook,这个 notebook 呈现了一个交互式可视化,帮助理解自注意力的概念:colab.research.google.com/github/tensorflow/tensor2tensor/blob/master/tensor2tensor/notebooks/hello_t2t.ipynb。
这个概念是我们即将讨论的 Transformer 架构的核心构建模块之一。
Transformer
注意、上下文嵌入和无循环体系结构等概念的结合导致了我们现在所谓的Transformers体系结构的诞生。Transformers体系结构是由瓦斯瓦尼等人于 2017 年在具有里程碑意义的论文注意力就是你所需要的中提出的。⁵ 这项工作代表了自然语言处理领域的完全范式转变;它不仅提出了一个强大的体系结构,还巧妙地利用了一些最近发展的概念,帮助它在不同基准测试中击败了最先进的模型。
我们将简要介绍Transformers体系结构的内部。欲了解逐步说明,请参阅 Jay Alammar 的插图Transformers:jalammar.github.io/illustrated-transformer/。
在核心部分,Transformers是一种无循环和无卷积的基于注意力的编码器-解码器架构。它完全依赖于注意机制来学习局部和全局依赖关系,从而实现了大规模并行化。现在让我们来看看这项工作的主要贡献。
总体架构
如前所述,Transformers在其核心是一个编码器-解码器架构。但与 NLP 领域已知的编码器-解码器体系结构不同,这项工作呈现了一个堆叠的编码器-解码器设置。
图 10.3 展示了高级Transformers设置。

图 10.3:Transformers体系结构的高级示意图
如图所示,该架构利用多个堆叠在一起的编码器块。解码器本身由堆叠的解码块组成,并且最后一个编码器块馈送到每个解码器块中。这里要注意的重要一点是,编码器和解码器块都不包含循环或卷积层。图 10.4 (A) 概述了编码器块,而 图 10.4 (B) 概述了解码器块。虚线表示不同层之间的残差连接。原始论文以相同的 6 个编码器块和解码器块呈现了Transformers体系结构。

图 10.4:A) 编码器块,B) 在Transformers体系结构中使用的解码器块
编码器块,如*图 10.4 (A)*所示,包括一个用于计算自注意力的层,然后是归一化和前馈层。这些层之间有跳跃连接。解码器块与编码器块几乎相同,只是多了一个由自注意力和归一化层组成的子块。这个额外的子块从最后一个编码器块获取输入,以确保编码器的注意力传播到解码块。
解码器块中的第一层进行了轻微修改。这个多头自注意力层对未来的时间步/上下文进行了屏蔽。这确保了模型在解码当前标记时不会关注目标的未来位置。让我们花点时间来理解多头自注意力组件。
多头自注意力
我们在上一节讨论了自注意力的概念。在本节中,我们将讨论变换器架构如何实现自注意力及其相关参数。在介绍注意力概念时,我们将其描述为查询向量(解码器状态,表示为q)和值向量(编码器的隐藏状态,表示为v)。
对于变换器而言,这有所修改。我们使用编码器状态或输入标记作为查询和值向量(自注意力),以及一个额外的向量称为键向量(表示为k)。在这种情况下,键、值和查询向量的维度相同。
变换器架构使用缩放点积作为其注意力机制。这个评分函数定义如下:

其中注意力输出首先计算为查询向量Q和键向量K(实际上这些是矩阵,但我们稍后会解释)的点积QK^T。点积试图捕捉查询与编码器状态的相似性,然后乘以输入向量的维度n的平方根进行缩放。引入这个缩放因子是为了确保梯度能够正确传播,因为对于大的嵌入向量观察到了梯度消失。Softmax 操作将分数转换为总和为 1 的概率分布。最后一步是计算编码器状态(这次是值向量V)的加权和与 Softmax 输出的乘积。整个操作在图 10.5中表示:

图 10.5:(左)缩放点积注意力,(右)多头自注意力,将几个自注意力层并行组合在一起。
在每个编码器块中使用单个注意头的位置,模型使用多个注意头并行进行操作(如 图 10.5(右) 所示)。作者在论文中提到,“多头注意力使模型能够同时关注不同位置的不同表示子空间的信息。使用单个注意头,平均会抑制这种情况。”换句话说,多头注意力使模型能够学习输入中每个单词的不同方面,即,一个注意头可能捕捉与介词的关系的影响,另一个可能专注于它与动词的交互作用,依此类推。由于每个注意头都有自己的 Q、K 和 V 向量集,实际上这些被实现为矩阵,每行对应于一个特定的头。
这里提供了多头自注意的高度直观的可视化解释,供参考:www.youtube.com/watch?v=-9vVhYEXeyQ&ab_channel=Peltarion。
有人可能会认为,由于多头设置,参数数量会突然激增并减慢训练过程。为了抵消这一点,作者们首先将较大的输入嵌入投影到较小的维度向量(大小为 64),然后使用 8 个头在原始实现中进行操作。这导致最终的连接向量(来自所有注意头)与具有较大输入嵌入向量的单个注意头的维度相同。这个巧妙的技巧帮助模型在相同的空间中捕捉更多的语义,而不会对整体训练速度产生影响。整体Transformers架构使用多个这样的编码器块,每个编码器块都包含多头注意层。
位置编码
Transformers模型不包含任何循环或卷积层,因此为了确保模型理解输入序列的重要性,使用了“位置嵌入”的概念。作者选择使用以下方法生成位置编码:


其中 pos 是输入令牌的位置,i 是维度,d[model] 是输入嵌入向量的长度。作者在偶数位置使用正弦,奇数位置使用余弦。位置编码向量的维度与输入向量相同,并且在输入编码器或解码器块之前将两个向量相加。
多头自注意力机制与位置编码的结合帮助Transformers网络构建输入序列的高度上下文表示。这个结合着完全基于注意力机制的架构,使得Transformers不仅能够在许多基准测试中超越现有模型,还能够构建一整个基于Transformers的模型系列。在下一节中,我们将简要介绍这一系列Transformers。
BERT-ology
Transformers架构在自然语言处理领域引入了完全前所未有的性能基准。这种无循环设置导致了对基于Transformers的完整系列架构的研究和开发。最初和最成功的其中之一是 BERT 模型。BERT,或者来自Transformers的双向编码器表示,是由 Google AI 的 Devlin 等人于 2018 年提出的。⁶
该模型在Transformers模型设定的基准上取得了显著的改进。BERT 还通过展示如何对预训练模型进行微调以提供最先进的性能,推动了自然语言处理领域的迁移学习的发展。在计算机视觉用例中,我们可以使用类似 VGG 或 ResNet 这样的大型预训练网络作为特征提取器并带有分类层,或者我们可以对给定任务微调整个网络。我们也可以使用 BERT 来实现相同的功能。
BERT 模型采用具有不同数量的编码器块的Transformers式编码器。作者提出了两个模型,BERT-base 包含 12 个块,BERT-large 包含 24 个块。这两个模型相比原始Transformers设置具有更大的前馈网络(分别为 768 和 1024)和更多的注意力头(分别为 12 和 16)。
与原始Transformers实现的另一个主要变化是双向掩码语言模型目标。典型的语言模型确保因果关系,即解码过程只关注过去的上下文而不是未来的时间步。BERT 的作者调整了这个目标,以从两个方向构建上下文,即 预测掩码词 和 下一个句子预测。这在 图 10.6 中有所描述:

图 10.6:BERT 训练目标,包括掩码语言模型和下一个句子预测
如图所示,掩码语言模型随机掩码了训练过程中的 15% 的标记。他们在大规模语料库上训练模型,然后在 GLUE (gluebenchmark.com/) 和其他相关基准上对其进行微调。据报告,该模型在性能上明显优于所有先前的架构。
BERT 的成功导致一系列改进模型,通过调整嵌入、编码器层等方面的某些方面来提供渐进性能提升。像 RoBERTa⁷、ALBERT⁸、DistilBERT⁹、XLNet¹⁰ 等模型共享核心思想并在此基础上提供改进。
由于 BERT 不符合因果关系,因此不能用于典型的语言建模任务,如文本生成。在接下来的章节中,我们将讨论 OpenAI 提出的Transformers并行架构系列。
GPT 1, 2, 3…
OpenAI 是一个人工智能研究团体,由于他们的具有新闻价值的作品,如 GPT、GPT-2 和最近发布的 GPT-3,一直备受关注。在本节中,我们将讨论与这些架构及其新颖贡献相关的简要讨论。最后,我们将使用 GPT-2 的预训练版本来执行我们的文本生成任务。
生成式预训练: GPT
这个系列中的第一个模型被称为GPT,或生成式预训练。它于 2018 年发布,大约与 BERT 模型同时。该论文¹¹ 提出了一个基于Transformers和无监督学习思想的任务无关架构。GPT 模型被证明在 GLUE 和 SST-2 等多个基准测试中取得了胜利,虽然其性能很快被 BERT 超越,后者在此后不久发布。
GPT 本质上是基于我们在上一章节中提出的transformer-decoder的语言模型(参见Transformers部分)。由于语言模型可以以无监督方式进行训练,该模型的作者利用了这种无监督方法在非常大的语料库上进行训练,然后针对特定任务进行了微调。作者使用了包含超过 7,000 本不同流派的独特未发表书籍的BookCorpus数据集¹²。作者声称,该数据集使得模型能够学习到长距离信息,这是由于存在着长串连续文本。这被认为比之前使用的 1B Word Benchmark 数据集更好,后者由于句子被打乱而丧失了长距离信息。GPT 的整体设置如下图所示:

图 10.7: GPT 架构(左), 使用 GPT 的基于任务的设置(右)
如*图 10.7 (左)所示,GPT 模型与原始Transformers-解码器类似。作者使用了 12 个解码器块(而不是原始Transformers中的 6 个),每个块具有 768 维状态和 12 个自注意头。由于该模型使用了掩码自注意力,它保持了语言模型的因果属性,因此还可以用于文本生成。对于图 10.7 (右)*展示的其余任务,基本上使用相同的预训练语言模型,并对输入进行最小的任务特定预处理和最终任务特定的层/目标。
GPT-2
GPT 被一个更加强大的模型 GPT-2 取代。Radford 等人在 2019 年的论文Language Models are Unsupervised Multi-task Learners中展示了 GPT-2 模型。¹³ 最大的 GPT-2 变体是一个庞大的 15 亿参数的基于 transformer 的模型,在各种 NLP 任务上表现出色。
这项工作最引人注目的是,作者展示了一个以无监督方式训练的模型(语言建模)如何在few-shot设置中实现了最先进的性能。这一点特别重要,因为与 GPT 甚至 BERT 相比,GPT-2 在特定任务上不需要进行任何微调。
与 GPT 类似,GPT-2 的秘密武器是它的数据集。作者们通过对一个名为 Reddit 的社交网站的 4500 万个外链进行爬取,准备了一个庞大的 40 GB 数据集。他们进行了一些基于启发式的清理、去重和移除维基百科文章(当然,为什么不呢?)最终得到了大约 800 万个文档。这个数据集被称为WebText数据集。
GPT-2 的总体结构与 GPT 相同,只是稍微更改了一些地方,比如在每个次块的开头放置层归一化,并在最终的自注意力块之后添加了额外的层归一化。模型的四个变体分别利用了 12、24、36 和 48 层。词汇量也扩展到了 50000 个词,并且上下文窗口扩展到了 1024 个标记(而 GPT 为 512)。
GPT-2 作为一种语言模型表现非常出色,以至于作者最初决定不释放预训练模型以造福大众¹⁴。最终他们还是释放了它,理由是迄今为止还没有发现恶意使用。需注意的是,这不仅仅是道德问题。数据和模型的庞大规模使得大多数人甚至无法想象训练这样的模型的可能性。Figure 10.8 描述了一些最近的 NLP 模型的规模和训练所需的计算量:

Figure 10.8: NLP 模型的规模¹⁵
TPU 的速度比典型的 GPU 快多次,如图所示,GPT-2 需要在报告的数据集上进行 2048 TPU 天的训练。与大型 BERT 模型的 256 TPU 天相比是相当大的差距。
有兴趣的读者可以在这里探索 GPT-2 的官方实现:github.com/openai/gpt-2.
虽然官方实现是基于 TensorFlow 1.14,但此链接提供了使用 TensorFlow 2.x 的非官方实现:
akanyaani.github.io/gpt-2-tensorflow2.0/
幸运的是,由于预训练模型的发布,Hugging Face 的研究人员决定致力于使Transformers架构民主化。来自 Hugging Face 的 transformer 包是一个高级包装器,使我们能够使用几行代码就可以使用这些大规模的自然语言处理模型。该库还提供了一个 Web 应用程序,用于探索不同的基于Transformers的模型。图 10.9 是当提供了一个 “GPT is” 种子时,由该 Web 应用程序生成的段落的快照:

图 10.9:使用基于 Hugging Face transformer 包的 GPT-2 的示例输出¹⁶
图中生成的文本显示了 GPT-2 的惊人效果。在第一句中,模型表现出色,甚至遵循了正确引用先前工作的惯例(尽管引用本身并不正确)。内容并不是很有意义,但在语法上是准确的,相对于我们提供的最小种子文本而言,它是相当连贯的。
现在,我们将利用 transformers 包来构建一个基于 GPT-2 的文本生成流水线,看看我们的模型能做多好。
亲身体验 GPT-2
保持与之前某些章节主题的一致性,在那些章节中,我们使用各种复杂的架构生成了一些虚假内容,让我们使用 GPT-2 生成一些虚假新闻标题。百万条新闻标题数据集包含了澳大利亚广播公司的一百多万条新闻标题,历时 17 年收集。该数据集可在以下链接处获得:
dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/SYBGZL
www.kaggle.com/therohk/million-headlines
我们将使用 Hugging Face 的 transformers 库来对这个数据集上的 GPT-2 进行微调。从高层次来看,这个假新闻生成任务与我们在 第九章 的初始部分中进行的语言建模任务是一样的。由于我们使用的是 transformers 包,与训练数据集的创建、标记化和最终训练模型相关的步骤都是使用高级 API 进行抽象化的。
transformers 库与 TensorFlow 和 PyTorch 后端都兼容。对于这种特殊情况,我们使用基于 PyTorch 的默认重新训练设置。该库不断改进,在撰写本文时,稳定版本 3.3.1 在使用 TensorFlow 对 GPT-2 进行微调时存在问题。由于 transformers 是一个高级库,读者在以下代码片段中不会注意到太大的差异。
如往常一样,第一步是读取手头的数据集,并将其转换为所需的格式。我们不需要自己准备单词到整数和反向映射。transformers库中的Tokenizer类会为我们处理这些。以下代码片段准备了数据集和所需的对象:
import pandas as pd
from sklearn.model_selection import train_test_split
from transformers import AutoTokenizer
from transformers import TextDataset,DataCollatorForLanguageModeling
# Get dataset
news = pd.read_csv('abcnews-date-text.csv')
X_train, X_test= train_test_split(news.headline_text.tolist(),test_size=0.33, random_state=42)
# Write the headlines from training dataset
with open('train_dataset.txt','w') as f:
for line in X_train:
f.write(line)
f.write("\n")
# Write the headlines from testing dataset
with open('test_dataset.txt','w') as f:
for line in X_test:
f.write(line)
f.write("\n")
# Prepare tokenizer object
tokenizer = AutoTokenizer.from_pretrained("gpt2",pad_token='<pad>')
train_path = 'train_dataset.txt'
test_path = 'test_dataset.txt'
# Utility method to prepare DataSet objects
def load_dataset(train_path,test_path,tokenizer):
train_dataset = TextDataset(
tokenizer=tokenizer,
file_path=train_path,
block_size=4)
test_dataset = TextDataset(
tokenizer=tokenizer,
file_path=test_path,
block_size=4)
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=False,
)
return train_dataset,test_dataset,data_collator
train_dataset,test_dataset,data_collator = load_dataset(train_path, test_path, tokenizer)
sklearn to split our dataset into training and test segments, which are then transformed into usable form using the TextDataset class. The train_dataset and test_dataset objects are simple generator objects that will be used by the Trainer class to fine-tune our model. The following snippet prepares the setup for training the model:
from transformers import Trainer,TrainingArguments,AutoModelWithLMHead
model = AutoModelWithLMHead.from_pretrained("gpt2")
training_args = TrainingArguments(
output_dir="./headliner", # The output directory
overwrite_output_dir=True, # overwrite the content of
# the output directory
num_train_epochs=1, # number of training epochs
per_device_train_batch_size=4, # batch size for training
per_device_eval_batch_size=2, # batch size for evaluation
eval_steps = 400, # Number of update steps
# between two evaluations.
save_steps=800, # after # steps model is saved
warmup_steps=500, # number of warmup steps for
# learning rate scheduler
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=test_dataset,
prediction_loss_only=True,
)
我们使用AutoModelWithLMHead类作为对 GPT-2 的高级封装,具有语言模型目标。Trainer类根据TrainingArguments类设置的参数简单地迭代训练步骤。
下一步只需调用train函数,让微调开始。以下代码片段展示了 GPT-2 的训练步骤:
trainer.train()
{'loss': 6.99887060546875, 'learning_rate': 5e-05, 'epoch': 0.0010584004182798454, 'total_flos': 5973110784000, 'step': 500}
{'loss': 6.54750146484375, 'learning_rate': 4.994702390916932e-05, 'epoch': 0.0021168008365596907, 'total_flos': 11946221568000, 'step': 1000}
{'loss': 6.5059072265625, 'learning_rate': 4.989404781833863e-05, 'epoch': 0.003175201254839536, 'total_flos': 17919332352000, 'step': 1500}
{'loss': 6.46778125, 'learning_rate': 4.9841071727507945e-05, 'epoch': 0.0042336016731193814, 'total_flos': 23892443136000, 'step': 2000}
{'loss': 6.339587890625, 'learning_rate': 4.978809563667726e-05, 'epoch': 0.005292002091399226, 'total_flos': 29865553920000, 'step': 2500}
{'loss': 6.3247421875, 'learning_rate': 4.973511954584657e-05, 'epoch': 0.006350402509679072, 'total_flos': 35838664704000, 'step': 3000}
pipeline object along with the utility function get_headline, which we need to generate headlines using this fine-tuned model:
from transformers import pipeline
headliner = pipeline('text-generation',
model='./headliner',
tokenizer='gpt2',
config={'max_length':8})
# Utility method
def get_headline(headliner_pipeline, seed_text="News"):
return headliner_pipeline(seed_text)[0]['generated_text'].split('\n')[0]
现在让我们生成一些虚假的新闻标题,看看我们的 GPT-2 模型的表现好坏。图 10.10展示了使用我们的模型生成的一些虚假新闻标题:

图 10.10:使用微调 GPT-2 生成的虚假新闻标题。粗体文本是种子文本。
生成的输出展示了 GPT-2 和基于 transformer 的架构的潜力。读者应该将此与我们在《第九章 文本生成方法的兴起》的初始部分中训练的基于 LSTM 的变体进行比较。这里展示的模型能够捕捉到与新闻标题相关的一些细微差别。例如,它生成了简短而精练的句子,捕捉到了像袋鼠、土著甚至墨尔本这样在澳大利亚环境中都相关的词语,这些都存在于我们的训练数据集的领域。所有这些都是模型在仅经过几个 epoch 的训练后所捕获的。可能性是无穷无尽的。
猛犸 GPT-3
OpenAI 小组并未在 GPT-2 取得巨大成功后就止步不前。相反,GPT-2 展示了模型容量(参数大小)和更大数据集如何可能导致令人印象深刻的结果。Brown 等人在 2020 年 5 月发布了题为语言模型是少样本学习者的论文。¹⁷此论文介绍了巨大的 1750 亿参数 GPT-3 模型。
GPT-3 比以往任何语言模型都要庞大(大约 10 倍),并且将 transformer 架构发挥到了极限。在这项工作中,作者展示了模型的 8 个不同变体,从一个拥有 1.25 亿参数,12 层的“GPT-3 小”到一个拥有 1750 亿参数,96 层的 GPT-3 模型。
模型架构与 GPT-2 相同,但有一个主要变化(除了嵌入尺寸、注意头和层数的增加之外)。这个主要变化是在Transformers块中使用交替的密集和局部带状稀疏注意力模式。这种稀疏注意技术类似于为稀疏变换器(参见使用稀疏变换器生成长序列,Child 等人¹⁸))提出的技术。
与之前的 GPT 模型类似,作者们不得不为这第三次迭代准备一个更大的数据集。他们基于类似 Common Crawl(过滤了更好的内容)、WebText2(WebText 的更大版本,用于 GPT-2)、Books1 和 Books2,以及维基百科数据集准备了一个 3000 亿标记的数据集。他们按各自数据集的质量比例抽样。
作者比较了 NLP 模型和总体机器学习的学习范式与人类学习方式。尽管语言模型在这些年来的性能和容量上有所改进,但最先进模型仍需要特定于任务的精细调整。为展示 GPT-3 的能力,他们评估了该模型的 少例学习、一例学习 和 零例学习 模式。精细调整模式暂时留给未来练习。
这三种评估模式可以总结如下:
-
零-shot:仅凭任务的自然语言描述,即在没有展示任何正确输出示例的情况下,模型就能预测答案。
-
一例:除了任务描述外,模型还展示了一个任务示例。
-
少例学习:除了任务描述外,模型还展示了一些任务示例。
在每种情况下,都不进行梯度更新(因为我们只是评估模型,在任何这些模式中都不是在训练)。图 10.11 显示了每种评估模式的示例设置,任务是将文本从英语翻译成西班牙语。

图 10.11: GPT-3 的评估模式
如图所示,在零-shot 模式下,模型展示了任务描述和一个用于翻译的提示。类似地,在一例和少例模式下,模型分别展示了一个和一些示例,然后展示了实际翻译提示。作者观察到 GPT-3 在零-shot 和一例设置下取得了有希望的结果。在少例设置中,该模型大多数情况下是竞争性的,甚至在某些任务中超过了当前的最先进水平。
除了通常的 NLP 任务外,GPT-3 似乎展示了一些在其他情况下需要快速适应或即兴推理的非凡能力。作者观察到 GPT-3 能够在一些任务上表现良好,如拼词、进行三位数的算术,甚至在看到一次定义后就能在句子中使用新词。作者还观察到,在少例学习设置下,GPT-3 生成的新闻文章足够好,以至于在区分它们与人为生成的文章时会给人类评估者带来困难。有趣的是,在之前部分准备的 GPT-2 上测试一下 GPT-3。
该模型足够庞大,需要一个专门的高性能集群来训练,正如论文中所描述的。作者就训练这个巨大模型所需的计算量和能量进行了讨论。在当前状态下,这个模型对我们大多数人来说还是难以企及的。OpenAI 计划以 API 的形式展示这个模型,但在撰写本章时,细节尚不明朗。
摘要
在本章中,我们介绍了近期 NLP 模型中一些主要的概念,如attention机制、contextual embeddings和self-attention。然后我们使用这个基础来学习transformer架构及其内部组件。我们简要地讨论了 BERT 及其系列架构。
在本章的下一节中,我们对 OpenAI 的基于 transformer 的语言模型进行了讨论。我们讨论了 GPT 和 GPT-2 的架构和数据集相关的选择。我们还使用了 Hugging Face 的transformer包来开发我们自己的基于 GPT-2 的文本生成流水线。最后,我们对最新、最尖端的语言模型 GPT-3 进行了简要讨论。我们讨论了开发这样一个巨大模型的各种动机以及它超越传统测试基准列表的功能清单。
本章和第九章 文本生成方法的兴起 展示了自然语言处理(NLP)是自己的研究领域。然而,来自计算机视觉和深度学习/机器学习的概念通常相互交叉,以推动技术边界。
在下一章中,我们将把我们的焦点转移到理解音频领域以及生成模型在音频领域中的工作。
参考文献
-
Peters, M.E., Ammar, W., Bhagavatula, C., & Power, R. (2017). Semi-supervised sequence tagging with bidirectional language models. arXiv.
arxiv.org/abs/1705.00108 -
Peters, M.E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contexualized word representations. arXiv.
arxiv.org/abs/1802.05365 -
Howard, J., & Ruder, S. (2018). Universal Language Model Fine-tuning for Text Classification. arXiv.
arxiv.org/abs/1801.06146 -
Cheng, J., Dong, L., & Lapata, M. (2016). Long Short-Term Memory-Networks for Machine Reading. arXiv.
arxiv.org/abs/1601.06733 -
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. arXiv.
arxiv.org/abs/1706.03762 -
Devlin, J., Chang, M-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv.
arxiv.org/abs/1810.04805 -
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019)。RoBERTa: A Robustly Optimized BERT Pretaining Approach。arXiv。
arxiv.org/abs/1907.11692 -
Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019)。ALBERT: A Lite BERT for Self-supervised Learning of Language Representations。arXiv。
arxiv.org/abs/1909.11942 -
Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019)。DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter。arXiv。
arxiv.org/abs/1910.01108 -
Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R., & Le, Q.V. (2019)。XLNet: Generalized Autoregressive Pretraining for Language Understanding。arXiv。
arxiv.org/abs/1906.08237 -
Radford, A. (2018 年 6 月 11 日)。Improving Language Understanding with Unsupervised Learning。OpenAI。
openai.com/blog/language-unsupervised/ -
Zhu, Y., Kiros, R., Zemel, R., Salakhutdinov, R., Urtasun, R., Torralba, A., & Fidler, S. (2015)。Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books。arXiv。
arxiv.org/abs/1506.06724 -
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019)。Language Models are Unsupervised Multitask Learners。OpenAI。
cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf -
Radford, A., Wu, J., Amodei, D., Amodei, D., Clark, J., Brundage, M., & Sutskever, I. (2019 年 2 月 14 日)。Better Language Models and Their Implications。OpenAI。
openai.com/blog/better-language-models/ -
stanfordonline. (2019 年 3 月 21 日)。斯坦福 CS224N: NLP with Deep Learning | Winter 2019 | Lecture 13 – Contextual Word Embeddings [视频]。YouTube。
www.youtube.com/watch?v=S-CspeZ8FHc&ab_channel=stanfordonline -
Hugging Face。 (无日期)。gpt2 abstract。检索于 2021 年 4 月 22 日,来源:
transformer.huggingface.co/doc/arxiv-nlp/ByLHXHhnBJtBLOpRENZmulqc/edit -
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., & Amodei, D. (2020). “语言模型是少样本学习器”. arXiv.
arxiv.org/abs/2005.14165 -
Child, R., Gray, S., Radford, A., & Sutskever, I. (2019). 使用稀疏 Transformer 生成长序列. arXiv.
arxiv.org/abs/1904.10509
第十一章:使用生成模型作曲音乐
在之前的章节中,我们讨论了许多以图像、文本和视频生成为重点的生成模型。从非常基本的 MNIST 数字生成到像模仿巴拉克·奥巴马这样更复杂的任务,我们探讨了许多复杂的作品及其新颖的贡献,并花时间了解所涉及的任务和数据集的细微差别。
我们看到,在之前关于文本生成的章节中,计算机视觉领域的改进如何帮助促进自然语言处理领域的显著进步。同样,音频是另一个领域,在这个领域,来自计算机视觉和自然语言处理领域的思想交叉已经扩大了视角。音频生成并不是一个新领域,但由于深度学习领域的研究,这个领域近年来也取得了一些巨大的进步。
音频生成有许多应用。如今最突出和流行的是一系列智能助手(谷歌助手、苹果 Siri、亚马逊 Alexa 等等)。这些虚拟助手不仅试图理解自然语言查询,而且还以非常人性化的声音作出回应。音频生成还在辅助技术领域找到应用,在那里,文本到语音引擎用于为阅读障碍者阅读屏幕上的内容。
在音乐生成领域利用这样的技术越来越受到关注。字节跳动(社交网络 TikTok 的母公司)收购了基于人工智能的免版税音乐生成服务 Jukedeck,这一举动充分展示了这个领域的潜在价值和影响力。¹
实际上,基于人工智能的音乐生成是一个不断增长的趋势,有许多竞争性的解决方案和研究工作。诸如苹果的 GarageBand² 等商业化产品提供了许多易于使用的界面,供新手只需点击几下即可创作出高质量音乐曲目。谷歌的 Magenta³ 项目的研究人员正在通过尝试不同的技术、工具和研究项目,将音乐生成的边界推向新的极限,使对这些复杂主题几乎没有知识的人也能够自己生成令人印象深刻的音乐作品。
在本章中,我们将介绍与音频数据生成模型相关的不同概念、架构和组件。特别是,我们将把焦点限制在音乐生成任务上。我们将专注于以下主题:
-
音乐表示的简要概述
-
基于 RNN 的音乐生成
-
一个简单的设置,以了解如何利用 GANs 进行音乐生成
-
基于 MuseGAN 的复音音乐生成
本章中介绍的所有代码片段都可以直接在 Google Colab 中运行。出于空间原因,依赖项的导入语句没有包含在内,但读者可以参考 GitHub 存储库获取完整的代码:github.com/PacktPublishing/Hands-On-Generative-AI-with-Python-and-TensorFlow-2。
我们将从音乐生成任务的介绍开始。
开始学习音乐生成
音乐生成是一个固有复杂且困难的任务。通过算法(机器学习或其他方式)进行这样的任务甚至更具挑战性。尽管如此,音乐生成是一个有趣的研究领域,有许多待解决的问题和令人着迷的作品。
在本节中,我们将建立对这一领域的高层次理解,并了解一些重要且基础的概念。
计算机辅助音乐生成或更具体地说是深度音乐生成(由于使用深度学习架构)是一个由生成乐谱和表现生成两个主要组成部分组成的多层学习任务。让我们简要讨论每个组件:
-
生成乐谱:乐谱是音乐的符号表示,可供人类或系统使用/阅读以生成音乐。类比一下,我们可以将乐谱与音乐之间的关系安全地视为文本与言语之间的关系。音乐乐谱由离散符号组成,可以有效地传达音乐。一些作品使用术语AI 作曲家来表示与生成乐谱任务相关的模型。
-
表现生成:延续文本-语音类比,表现生成(类似于言语)是表演者使用乐谱以其自己的节奏、韵律等特征生成音乐的地方。与表现生成任务相关的模型有时也被称为AI 表演者。
我们可以根据目标组件针对不同的用例或任务来实现。图 11.1强调了在音乐生成的上下文中正在研究的一些任务:

图 11.1:音乐生成的不同组件及相关任务列表
如图所示,通过仅关注乐谱生成,我们可以致力于诸如旋律生成和旋律和声化以及音乐修补(与填补音乐中缺失或丢失的信息相关联)等任务。除了作曲家和表演者之外,还有研究正在进行中,旨在构建 AI DJ。与人类唱片骑师(DJ)类似,AI DJ 利用现有的音乐组件创建串烧、混搭、混音,甚至高度个性化的播放列表。
在接下来的章节中,我们将主要致力于构建我们自己的乐谱生成模型或 AI 作曲家。既然我们对整体音乐生成的景观有了高层次的理解,让我们专注于理解音乐的表示方式。
表示音乐
音乐是代表情绪、节奏、情感等的艺术作品。类似于文本,文本是字母和语法规则的集合,音乐谱有自己的符号和一套规则。在前几章中,我们讨论了如何在任何自然语言处理任务之前,将文本数据首先转换为可用的向量形式。在音乐的情况下,我们也需要做类似的事情。
音乐表示可以分为两大类:连续和离散。连续表示也称为音频领域表示。它将音乐数据处理为波形。如图 11.2(a)所示,音频领域表示捕捉丰富的声学细节,如音色和发音。

图 11.2:音乐的连续或音频领域表示。a)1D 波形是音频信号的直接表示。b)音频数据的二维表示可以是以时间为一轴,频率为第二轴的频谱图形式。
如图所示,音频领域表示可以直接是 1D 波形或 2D 频谱图:
-
一维波形是音频信号的直接表示,其中x轴表示时间,y轴表示信号的变化。
-
二维频谱图将时间作为x轴,频率作为y轴。
我们通常使用短时傅里叶变换(STFT)将一维波形转换为二维频谱图。根据我们如何获得最终的频谱图,有不同的变体,如梅尔频谱图或幅度频谱图。
另一方面,离散或符号表示使用离散符号来捕获与音高、持续时间、和弦等相关的信息。尽管不如音频域表示那样具有表现力,但符号表示被广泛应用于不同的音乐生成工作中。这种流行程度主要是由于易于理解和处理这种表示形式。图 11.3展示了音乐谱的一个示例符号表示:

图 11.3:音乐的离散或符号表示
如图所示,符号表示使用各种符号/位置捕获信息。MIDI,或音乐乐器数字接口,是音乐家用来创建、谱写、演奏和分享音乐的可互操作格式。它是各种电子乐器、计算机、智能手机甚至软件用来读取和播放音乐文件的常用格式。
符号表示可以设计成捕捉诸如note-on、note-off、时间偏移、小节、轨道等许多事件。为了理解即将出现的部分和本章的范围,我们只会关注两个主要事件,即note-on和note-off。MIDI 格式捕捉了 16 个通道(编号为 0 到 15)、128 个音符和 128 个响度设置(也称为速度)。还有许多其他格式,但为了本章的目的,我们将仅使用基于 MIDI 的音乐文件,因为它们被广泛使用、富有表现力、可互操作且易于理解。
music21. We then use its utility function to visualize the information in the file:
from music21 import converter
midi_filepath = 'Piano Sonata No.27.mid'
midi_score = converter.parse(midi_filepath).chordify()
# text-form
print(midi_score.show('text'))
# piano-roll form
print(midi_score.show())
到目前为止,我们在理解整体音乐生成格局和一些重要的表示技术方面已经取得了相当大的进展。接下来,我们将开始进行音乐生成本身。
使用 LSTM 进行音乐生成
歌曲是连续信号,由各种乐器和声音的组合构成,这一点我们在前一节已经看到。另一个特点是结构性的循环模式,我们在听歌时要注意。换句话说,每首音乐都有其独特的连贯性、节奏和流畅性。
这样的设置与我们在 第九章 文本生成方法的兴起 中看到的文本生成情况类似。在文本生成的情况下,我们看到了基于 LSTM 的网络的力量和有效性。在本节中,我们将扩展堆叠 LSTM 网络来执行音乐生成任务。
为了保持简单和易于实现,我们将专注于单个乐器/单声部音乐生成任务。让我们先看看数据集,然后考虑如何为我们的音乐生成任务准备它。
数据集准备
MIDI 是一种易于使用的格式,可以帮助我们提取文件中包含的音乐的符号表示。在本章的实践练习中,我们将利用 reddit 用户u/midi_man收集并分享的大规模公共 MIDI 数据集的子集,该数据集可以在以下链接中找到:
www.reddit.com/r/WeAreTheMusicMakers/comments/3ajwe4/the_largest_midi_collection_on_the_inte
基于贝多芬、巴赫、巴托克等伟大音乐家的古典钢琴作品。该子集可以在压缩文件midi_dataset.zip中找到,并且连同本书的代码一起放在 GitHub 存储库中。
正如前面提到的,我们将利用 music21 来处理此数据集的子集,并准备我们的数据来训练模型。由于音乐是各种乐器和声音/歌手的集合,因此为了本练习的目的,我们将首先使用 chordify() 函数从歌曲中提取和弦。以下代码片段可以帮助我们以所需格式获取 MIDI 分数的列表:
from music21 import converter
data_dir = 'midi_dataset'
# list of files
midi_list = os.listdir(data_dir)
# Load and make list of stream objects
original_scores = []
for midi in tqdm(midi_list):
score = converter.parse(os.path.join(data_dir,midi))
original_scores.append(score)
# Merge notes into chords
original_scores = [midi.chordify() for midi in tqdm(original_scores)]
一旦我们有了分数列表,下一步就是提取音符及其对应的时间信息。为了提取这些细节,music21具有诸如element.pitch和element.duration之类的简单易用的接口。
以下代码片段帮助我们从 MIDI 文件中提取这样的信息,并准备两个并行的列表:
# Define empty lists of lists
original_chords = [[] for _ in original_scores]
original_durations = [[] for _ in original_scores]
original_keys = []
# Extract notes, chords, durations, and keys
for i, midi in tqdm(enumerate(original_scores)):
original_keys.append(str(midi.analyze('key')))
for element in midi:
if isinstance(element, note.Note):
original_chords[i].append(element.pitch)
original_durations[i].append(element.duration.quarterLength)
elif isinstance(element, chord.Chord):
original_chords[i].append('.'.join(str(n) for n in element.pitches))
original_durations[i].append(element.duration.quarterLength)
C major key:
# Create list of chords and durations from songs in C major
major_chords = [c for (c, k) in tqdm(zip(original_chords, original_keys)) if (k == 'C major')]
major_durations = [c for (c, k) in tqdm(zip(original_durations, original_keys)) if (k == 'C major')]
mapping and presents a sample output as well:
def get_distinct(elements):
# Get all pitch names
element_names = sorted(set(elements))
n_elements = len(element_names)
return (element_names, n_elements)
def create_lookups(element_names):
# create dictionary to map notes and durations to integers
element_to_int = dict((element, number) for number, element in enumerate(element_names))
int_to_element = dict((number, element) for number, element in enumerate(element_names))
return (element_to_int, int_to_element)
# get the distinct sets of notes and durations
note_names, n_notes = get_distinct([n for chord in major_chords for n in chord])
duration_names, n_durations = get_distinct([d for dur in major_durations for d in dur])
distincts = [note_names, n_notes, duration_names, n_durations]
with open(os.path.join(store_folder, 'distincts'), 'wb') as f:
pickle.dump(distincts, f)
# make the lookup dictionaries for notes and durations and save
note_to_int, int_to_note = create_lookups(note_names)
duration_to_int, int_to_duration = create_lookups(duration_names)
lookups = [note_to_int, int_to_note, duration_to_int, int_to_duration]
with open(os.path.join(store_folder, 'lookups'), 'wb') as f:
pickle.dump(lookups, f)
print("Unique Notes={} and Duration values={}".format(n_notes,n_durations))
Unique Notes=2963 and Duration values=18
我们现在准备好映射。在以下代码片段中,我们将训练数据集准备为长度为 32 的序列,并将它们的对应目标设为序列中紧接着的下一个标记:
# Set sequence length
sequence_length = 32
# Define empty array for training data
train_chords = []
train_durations = []
target_chords = []
target_durations = []
# Construct train and target sequences for chords and durations
# hint: refer back to Chapter 9 where we prepared similar
# training data
# sequences for an LSTM-based text generation network
for s in range(len(major_chords)):
chord_list = [note_to_int[c] for c in major_chords[s]]
duration_list = [duration_to_int[d] for d in major_durations[s]]
for i in range(len(chord_list) - sequence_length):
train_chords.append(chord_list[i:i+sequence_length])
train_durations.append(duration_list[i:i+sequence_length])
target_chords.append(chord_list[i+1])
target_durations.append(duration_list[i+1])
正如我们所看到的,数据集准备阶段除了与处理 MIDI 文件相关的一些细微差别之外,大部分都是直截了当的。生成的序列及其对应的目标在下面的输出片段中供参考:
print(train_chords[0])
array([ 935, 1773, 2070, 2788, 244, 594, 2882, 1126, 152, 2071,
2862, 2343, 2342, 220, 221, 2124, 2123, 2832, 2584, 939,
1818, 2608, 2462, 702, 935, 1773, 2070, 2788, 244, 594,
2882, 1126])
print(target_chords[0])
1773
print(train_durations[0])
array([ 9, 9, 9, 12, 5, 8, 2, 9, 9, 9, 9, 5, 5, 8, 2,
5, 5, 9, 9, 7, 3, 2, 4, 3, 9, 9, 9, 12, 5, 8,
2, 9])
print(target_durations[0])
9
转换后的数据集现在是一系列数字,就像文本生成的情况一样。列表中的下一项是模型本身。
用于音乐生成的 LSTM 模型
如前所述,我们的第一个音乐生成模型将是第九章,文本生成方法的崛起中基于 LSTM 的文本生成模型的扩展版本。然而,在我们可以将该模型用于这项任务之前,有一些注意事项需要处理和必要的变更需要进行。
不像文本生成(使用 Char-RNN)只有少数输入符号(小写和大写字母、数字),音乐生成的符号数量相当大(~500)。在这个符号列表中,还需要加入一些额外的符号,用于时间/持续时间相关的信息。有了这个更大的输入符号列表,模型需要更多的训练数据和学习能力(学习能力以 LSTM 单元数量、嵌入大小等方面来衡量)。
我们需要处理的下一个明显变化是模型能够在每个时间步骤上接受两个输入的能力。换句话说,模型应能够在每个时间步骤上接受音符和持续时间信息,并生成带有相应持续时间的输出音符。为此,我们利用功能性的tensorflow.keras API,构建一个多输入多输出的架构。
正如在第九章,文本生成方法的崛起中详细讨论的那样,堆叠的 LSTM 在能够学习更复杂特征方面具有明显优势,这超过了单个 LSTM 层网络的能力。除此之外,我们还讨论了注意机制以及它们如何帮助缓解 RNN 所固有的问题,比如难以处理长距离依赖关系。由于音乐由在节奏和连贯性方面可感知的局部和全局结构组成,注意机制肯定可以起作用。下面的代码片段按照所讨论的方式准备了一个多输入堆叠的 LSTM 网络:
def create_network(n_notes, n_durations, embed_size = 100, rnn_units = 256):
""" create the structure of the neural network """
notes_in = Input(shape = (None,))
durations_in = Input(shape = (None,))
x1 = Embedding(n_notes, embed_size)(notes_in)
x2 = Embedding(n_durations, embed_size)(durations_in)
x = Concatenate()([x1,x2])
x = LSTM(rnn_units, return_sequences=True)(x)
x = LSTM(rnn_units, return_sequences=True)(x)
# attention
e = Dense(1, activation='tanh')(x)
e = Reshape([-1])(e)
alpha = Activation('softmax')(e)
alpha_repeated = Permute([2, 1])(RepeatVector(rnn_units)(alpha))
c = Multiply()([x, alpha_repeated])
c = Lambda(lambda xin: K.sum(xin, axis=1), output_shape=(rnn_units,))(c)
notes_out = Dense(n_notes, activation = 'softmax', name = 'pitch')(c)
durations_out = Dense(n_durations, activation = 'softmax', name = 'duration')(c)
model = Model([notes_in, durations_in], [notes_out, durations_out])
model.compile(loss=['sparse_categorical_crossentropy',
'sparse_categorical_crossentropy'], optimizer=RMSprop(lr = 0.001))
return model
network (one input each for notes and durations respectively). Each of the inputs is transformed into vectors using respective embedding layers. We then concatenate both inputs and pass them through a couple of LSTM layers followed by a simple attention mechanism. After this point, the model again diverges into two outputs (one for the next note and the other for the duration of that note). Readers are encouraged to use keras utilities to visualize the network on their own.
训练这个模型就像在 keras 模型对象上调用 fit() 函数一样简单。我们将模型训练约 100 个周期。图 11.4 描述了模型在不同周期下的学习进展:

图 11.4:模型输出随着训练在不同周期下的进展
如图所示,模型能够学习一些重复模式并生成音乐。在这里,我们使用基于温度的抽样作为我们的解码策略。正如在 第九章,文本生成方法的兴起 中讨论的,读者可以尝试诸如贪婪解码、纯抽样解码等技术,以了解输出音乐质量如何变化。
这是使用深度学习模型进行音乐生成的一个非常简单的实现。我们将之前两章学到的概念与之进行了类比,那两章是关于文本生成的。接下来,让我们使用对抗网络进行一些音乐生成。
使用 GAN 进行音乐生成
在前一节中,我们尝试使用一个非常简单的基于 LSTM 的模型进行音乐生成。现在,让我们提高一点标准,看看如何使用 GAN 生成音乐。在本节中,我们将利用我们在前几章学到的与 GAN 相关的概念,并将它们应用于生成音乐。
我们已经看到音乐是连续且序列化的。LSTM 或 RNN 等模型非常擅长处理这样的数据集。多年来,已经提出了各种类型的 GAN,以有效地训练深度生成网络。
Mogren 等人于 2016 年提出了 连续循环神经网络与对抗训练:C-RNN-GAN⁴,结合了 LSTM 和基于 GAN 的生成网络的能力,作为音乐生成的方法。这是一个直接但有效的音乐生成实现。与前一节一样,我们将保持简单,并且只关注单声道音乐生成,尽管原始论文提到了使用音调长度、频率、强度和音符之间的时间等特征。论文还提到了一种称为 特征映射 的技术来生成复调音乐(使用 C-RNN-GAN-3 变体)。我们将只关注理解基本架构和预处理步骤,而不试图按原样实现论文。让我们开始定义音乐生成 GAN 的各个组件。
生成器网络
tensorflow.keras to prepare our generator model:
def build_generator(latent_dim,seq_shape):
model = Sequential()
model.add(Dense(256, input_dim=latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(seq_shape), activation='tanh'))
model.add(Reshape(seq_shape))
model.summary()
noise = Input(shape=(latent_dim,))
seq = model(noise)
return Model(noise, seq)
生成器模型是一个相当简单的实现,突显了基于 GAN 的生成模型的有效性。接下来,让我们准备判别器模型。
判别器网络
在 GAN 设置中,判别器的任务是区分真实和生成的(或虚假的)样本。在这种情况下,由于要检查的样本是一首音乐作品,所以模型需要有处理序列输入的能力。
为了处理顺序输入样本,我们使用一个简单的堆叠 RNN 网络。第一个递归层是一个具有 512 个单元的 LSTM 层,后面是一个双向 LSTM 层。第二层的双向性通过查看特定和弦或音符之前和之后的内容来帮助判别器更好地学习上下文。递归层后面是一堆密集层和一个用于二元分类任务的最终 sigmoid 层。判别器网络如下代码片段所示:
def build_discriminator(seq_shape):
model = Sequential()
model.add(LSTM(512, input_shape=seq_shape, return_sequences=True))
model.add(Bidirectional(LSTM(512)))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
seq = Input(shape=seq_shape)
validity = model(seq)
return Model(seq, validity)
如代码片段所示,判别器也是一个非常简单的模型,由几个递归和密集层组成。接下来,让我们将所有这些组件组合起来并训练整个 GAN。
训练与结果
第一步是使用我们在前几节介绍的实用程序实例化生成器和判别器模型。一旦我们有了这些对象,我们将生成器和判别器组合成一个堆栈,形成整体的 GAN。以下片段展示了三个网络的实例化:
rows = 100
seq_length = rows
seq_shape = (seq_length, 1)
latent_dim = 1000
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
discriminator = build_discriminator(seq_shape)
discriminator.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
# Build the generator
generator = build_generator(latent_dim,seq_shape)
# The generator takes noise as input and generates note sequences
z = Input(shape=(latent_dim,))
generated_seq = generator(z)
# For the combined model we will only train the generator
discriminator.trainable = False
# The discriminator takes generated images as input and determines validity
validity = discriminator(generated_seq)
# The combined model (stacked generator and discriminator)
# Trains the generator to fool the discriminator
gan = Model(z, validity)
gan.compile(loss='binary_crossentropy', optimizer=optimizer)
就像我们在前几章中所做的那样,在堆叠到 GAN 模型对象之前,首先将鉴别器训练设置为false。这确保只有在生成周期期间更新生成器权重,而不是鉴别器权重。我们准备了一个自定义训练循环,就像我们在之前的章节中多次介绍的那样。
为了完整起见,我们在此提供参考:
def train(latent_dim,
notes,
generator,
discriminator,
gan,
epochs,
batch_size=128,
sample_interval=50):
disc_loss =[]
gen_loss = []
n_vocab = len(set(notes))
X_train, y_train = prepare_sequences(notes, n_vocab)
# ground truths
real = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
idx = np.random.randint(0, X_train.shape[0], batch_size)
real_seqs = X_train[idx]
noise = np.random.normal(0, 1, (batch_size, latent_dim))
# generate a batch of new note sequences
gen_seqs = generator.predict(noise)
# train the discriminator
d_loss_real = discriminator.train_on_batch(real_seqs, real)
d_loss_fake = discriminator.train_on_batch(gen_seqs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# train the Generator
noise = np.random.normal(0, 1, (batch_size, latent_dim))
g_loss = gan.train_on_batch(noise, real)
# visualize progress
if epoch % sample_interval == 0:
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0],100*d_loss[1],g_loss))
disc_loss.append(d_loss[0])
gen_loss.append(g_loss)
generate(latent_dim, generator, notes)
plot_loss(disc_loss,gen_loss)
我们使用了与上一节相同的训练数据集。我们将我们的设置训练了大约 200 个时代,批量大小为 64。图 11.5展示了鉴别器和生成器在训练周期中的损失以及在不同时间间隔内的一些输出:

图 11.5:a)随着训练的进行,鉴别器和生成器损失。b)在不同训练间隔内生成器模型的输出
图中显示的输出突显了基于 GAN 的音乐生成设置的潜力。读者可以选择尝试不同的数据集,甚至是 Mogren 等人在 C-RNN-GAN 论文中提到的细节。生成的 MIDI 文件可以使用 MuseScore 应用程序播放。
与上一节中基于 LSTM 的模型相比,基于这个 GAN 的模型的输出可能会感觉更加精致一些(尽管这纯粹是主观的,考虑到我们的数据集很小)。这可能归因于 GAN 相对于基于 LSTM 的模型更好地建模生成过程的固有能力。有关生成模型拓扑结构及其各自优势的更多细节,请参阅第六章,使用 GAN 生成图像。
现在我们已经看到了两种单声部音乐生成的变体,让我们开始尝试使用 MuseGAN 进行复声音乐生成。
MuseGAN – 复声音乐生成
到目前为止,我们训练的两个模型都是音乐实际感知的简化版本。虽然有限,但基于注意力的 LSTM 模型和基于 C-RNN-GAN 的模型都帮助我们很好地理解了音乐生成过程。在本节中,我们将在已学到的基础上进行拓展,朝着准备一个尽可能接近实际音乐生成任务的设置迈出一步。
在 2017 年,Dong 等人在他们的作品《MuseGAN: 多轨序列生成对抗网络用于符号音乐生成和伴奏》中提出了一种多轨音乐生成的 GAN 类型框架⁵。这篇论文详细解释了各种与音乐相关的概念,以及 Dong 和他的团队是如何应对它们的。为了使事情保持在本章的范围内,又不失细节,我们将涉及这项工作的重要贡献,然后继续进行实现。在我们进入“如何”部分之前,让我们先了解 MuseGAN 工作试图考虑的与音乐相关的三个主要属性:
-
多轨互依性:大多数我们听的歌曲通常由多种乐器组成,如鼓,吉他,贝斯,人声等。在这些组件的演奏方式中存在着很高的互依性,使最终用户/听众能够感知到连贯性和节奏。
-
音乐结构:音符常常被分成和弦和旋律。这些分组以高度重叠的方式进行,并不一定是按照时间顺序排列的(这种对时间顺序的简化通常适用于大多数与音乐生成相关的已知作品)。时间顺序的排列不仅是出于简化的需要,也是从 NLP 领域,特别是语言生成的概括中得出的。
-
时间结构:音乐具有分层结构,一首歌可以看作是由段落组成(在最高级别)。段落由各种短语组成,短语又由多个小节组成,如此类推。图 11.6以图像方式描述了这种层级结构:

图 11.6:一首歌的时间结构
- 如图所示,一根小节进一步由节拍组成,在最低的级别上,我们有像素。MuseGAN 的作者们提到小节作为作曲的单位,而不是音符,这是为了考虑多轨设置中的音符分组。
MuseGAN 通过基于三种音乐生成方法的独特框架来解决这三个主要挑战。这三种基本方法分别采用即兴演奏,混合和作曲家模型。我们现在简要解释一下这些方法。
即兴演奏模型
如果我们将前一节中的简化单声部 GAN 设置外推到多声部设置,最简单的方法是利用多个发电机-鉴别器组合,每个乐器一个。干扰模型正是这个设定,其中M个独立的发电机从各自的随机向量准备音乐。每个发电机都有自己的评论家/鉴别器,有助于训练整体 GAN。此设置如图 11.7所示:

图 11.7: 由 M 个发电机和鉴别器对组成的干扰模型,用于生成多轨道输出
如上图所示,干扰设置模拟了一群音乐家的聚合,他们通过独立即兴创作音乐,没有任何预定义的安排。
作曲家模型
如其名称所示,此设置假设发生器是一个典型的能够创建多轨钢琴卷的人类作曲家,如图 11.8所示:

图 11.8: 单发电机组成的作曲家模型,能够生成 M 轨道,一个用于检测假样本和真实样本的鉴别器
如图所示,这个设置只有一个鉴别器来检测真实或假的(生成的)样本。与前一个干扰模型设置中的M个随机向量不同,这个模型只需要一个公共随机向量z。
混合模型
这是通过将干扰和作曲家模型结合而产生的有趣想法。混合模型有M个独立的发电机,它们利用各自的随机向量,也被称为轨内随机向量。每个发电机还需要另一个称为轨间随机向量的额外随机向量。这个额外的向量被认为是模仿作曲家并帮助协调独立的发电机。图 11.9描述了混合模型,每个发电机都需要轨内和轨间随机向量作为输入:

图 11.9: 由 M 个发电机和一个单一鉴别器组成的混合模型。每个发电机需要两个输入,即轨间和轨内随机向量的形式。
如图所示,混合模型的M发电机仅与一个鉴别器一起工作,以预测一个样本是真实的还是假的。将演奏和作曲家模型结合的优势在于生成器端的灵活性和控制。由于我们有M个不同的发电机,这个设定允许在不同的轨道上选择不同的架构(不同的输入大小、过滤器、层等),以及通过轨间随机向量的额外控制来管理它们之间的协调。
除了这三个变体,MuseGAN 的作者还提出了一个时间模型,我们将在下面讨论。
临时模型
音乐的时间结构是我们讨论的 MuseGAN 设置的三个重要方面之一。我们在前几节中解释的三个变体(即即兴、作曲家和混合模型)都在小节级别上工作。换句话说,每个模型都是一小节一小节地生成多音轨音乐,但可能两个相邻小节之间没有连贯性或连续性。这与分层结构不同,分层结构中一组小节组成一个乐句等等。
为了保持生成歌曲的连贯性和时间结构,MuseGAN 的作者提出了一个时间模型。在从头开始生成时(作为其中一种模式),该额外的模型通过将小节进行为一个附加维度来生成固定长度的乐句。该模型由两个子组件组成,时间结构生成器 G[时间] 和小节生成器 G[小节]。该设置在 图 11.10 中呈现:

图 11.10:时间模型及其两个子组件,时间结构生成器 G[时间] 和小节生成器 G[小节]
时间结构生成器将噪声向量 z 映射到一个潜在向量序列  。这个潜在向量
。这个潜在向量  携带时间信息,然后由 G[小节] 用于逐小节生成音乐。时间模型的整体设置如下所示:
携带时间信息,然后由 G[小节] 用于逐小节生成音乐。时间模型的整体设置如下所示:

作者指出,该设置类似于一些关于视频生成的作品,并引用了进一步了解的参考文献。作者还提到了另一种情况,其中呈现了一个条件设置,用于通过学习来生成由人类生成的音轨序列的时间结构。
我们已经介绍了 MuseGAN 设置的具体构建块的细节。现在让我们深入了解这些组件如何构成整个系统。
MuseGAN
MuseGAN 的整体设置是一个复杂的架构,由多个活动部分组成。为了使时间结构保持连贯,该设置使用了我们在前一节中讨论的两阶段时间模型方法。图 11.11 展示了 MuseGAN 架构的简化版本:

图 11.11:简化的 MuseGAN 架构,由 M 个生成器和一个判别器组成,以及一个用于生成短语连贯输出的两阶段时间模型。
如图所示,该设置使用时间模型用于某些音轨和直接的随机向量用于其他音轨。时间模型和直接输入的输出然后在传递给小节生成器模型之前进行连接(或求和)。
然后小节生成器逐小节创建音乐,并使用评论者或鉴别器模型进行评估。在接下来的部分,我们将简要触及生成器和评论者模型的实现细节。
请注意,本节介绍的实现与原始工作接近,但并非完全复制。为了简化并便于理解整体架构,我们采取了某些捷径。有兴趣的读者可以参考官方实现详情和引文工作中提到的代码库。
生成器
如前一节所述,生成器设置取决于我们是使用即兴演奏、作曲家还是混合方法。为简单起见,我们只关注具有多个生成器的混合设置,其中每个音轨都有一个生成器。
一组生成器专注于需要时间连贯性的音轨;例如,旋律这样的组件是长序列(超过一小节长),它们之间的连贯性是一个重要因素。对于这样的音轨,我们使用如下片段所示的时间架构:
def build_temporal_network(z_dim, n_bars, weight_init):
input_layer = Input(shape=(z_dim,), name='temporal_input')
x = Reshape([1, 1, z_dim])(input_layer)
x = Conv2DTranspose(
filters=512,
kernel_size=(2, 1),
padding='valid',
strides=(1, 1),
kernel_initializer=weight_init
)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation('relu')(x)
x = Conv2DTranspose(
filters=z_dim,
kernel_size=(n_bars - 1, 1),
padding='valid',
strides=(1, 1),
kernel_initializer=weight_init
)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation('relu')(x)
output_layer = Reshape([n_bars, z_dim])(x)
return Model(input_layer, output_layer)
如图所示,时间模型首先将随机向量重塑为所需的维度,然后通过转置卷积层将其传递,以扩展输出向量,使其跨越指定小节的长度。
对于我们不需要小节间连续性的音轨,我们直接使用随机向量 z。在实践中,与节奏或节拍相关的信息涵盖了这些音轨。
时序生成器和直接随机向量的输出首先被连结在一起,以准备一个更大的协调向量。然后,这个向量作为输入传递给下面片段所示的小节生成器 G[bar]:
def build_bar_generator(z_dim, n_steps_per_bar, n_pitches, weight_init):
input_layer = Input(shape=(z_dim * 4,), name='bar_generator_input')
x = Dense(1024)(input_layer)
x = BatchNormalization(momentum=0.9)(x)
x = Activation('relu')(x)
x = Reshape([2, 1, 512])(x)
x = Conv2DTranspose(
filters=512,
kernel_size=(2, 1),
padding='same',
strides=(2, 1),
kernel_initializer=weight_init
)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation('relu')(x)
x = Conv2DTranspose(
filters=256,
kernel_size=(2, 1),
padding='same',
strides=(2, 1),
kernel_initializer=weight_init
)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation('relu')(x)
x = Conv2DTranspose(
filters=256,
kernel_size=(2, 1),
padding='same',
strides=(2, 1),
kernel_initializer=weight_init
)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation('relu')(x)
x = Conv2DTranspose(
filters=256,
kernel_size=(1, 7),
padding='same',
strides=(1, 7),
kernel_initializer=weight_init
)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation('relu')(x)
x = Conv2DTranspose(
filters=1,
kernel_size=(1, 12),
padding='same',
strides=(1, 12),
kernel_initializer=weight_init
)(x)
x = Activation('tanh')(x)
output_layer = Reshape([1, n_steps_per_bar, n_pitches, 1])(x)
return Model(input_layer, output_layer)
shows that the bar generator consists of a dense layer followed by batch-normalization, before a stack of transposed convolutional layers, which help to expand the vector along time and pitch dimensions.
评论者
评论者模型相对于我们在前一节中构建的生成器来说更简单。评论者基本上是一个卷积 WGAN-GP 模型(类似于 WGAN,在 第六章 使用 GAN 生成图像 中涵盖的),它从小节生成器的输出以及真实样本中获取信息,以检测生成器输出是伪造的还是真实的。以下片段呈现了评论者模型:
def build_critic(input_dim, weight_init, n_bars):
critic_input = Input(shape=input_dim, name='critic_input')
x = critic_input
x = conv_3d(x,
num_filters=128,
kernel_size=(2, 1, 1),
stride=(1, 1, 1),
padding='valid',
weight_init=weight_init)
x = conv_3d(x,
num_filters=64,
kernel_size=(n_bars - 1, 1, 1),
stride=(1, 1, 1),
padding='valid',
weight_init=weight_init)
x = conv_3d(x,
num_filters=64,
kernel_size=(1, 1, 12),
stride=(1, 1, 12),
padding='same',
weight_init=weight_init)
x = conv_3d(x,
num_filters=64,
kernel_size=(1, 1, 7),
stride=(1, 1, 7),
padding='same',
weight_init=weight_init)
x = conv_3d(x,
num_filters=64,
kernel_size=(1, 2, 1),
stride=(1, 2, 1),
padding='same',
weight_init=weight_init)
x = conv_3d(x,
num_filters=64,
kernel_size=(1, 2, 1),
stride=(1, 2, 1),
padding='same',
weight_init=weight_init)
x = conv_3d(x,
num_filters=128,
kernel_size=(1, 4, 1),
stride=(1, 2, 1),
padding='same',
weight_init=weight_init)
x = conv_3d(x,
num_filters=256,
kernel_size=(1, 3, 1),
stride=(1, 2, 1),
padding='same',
weight_init=weight_init)
x = Flatten()(x)
x = Dense(512, kernel_initializer=weight_init)(x)
x = LeakyReLU()(x)
critic_output = Dense(1,
activation=None,
kernel_initializer=weight_init)(x)
critic = Model(critic_input, critic_output)
return critic
一个需要注意的重点是使用 3D 卷积层。对于大多数任务,我们通常使用 2D 卷积。在这种情况下,由于我们有 4 维输入,需要使用 3D 卷积层来正确处理数据。
我们使用这些实用工具来为四个不同的音轨准备一个通用的生成器模型对象。在下一步中,我们准备训练设置并生成一些示例音乐。
训练和结果
所有组件都准备就绪。最后一步是将它们组合在一起,并按照典型 WGAN-GP 的训练方式进行训练。论文的作者提到,如果他们每更新 5 次鉴别器,就更新一次生成器,模型将达到稳定的性能。我们遵循类似的设置来实现 图 11.12 中显示的结果:

图 11.12:从 MuseGAN 设置中得到的结果展示了多轨输出,这在各个小节之间似乎是连贯的,并且具有一致的节奏。
如图所示,MuseGAN 产生的多轨多声部输出确实令人印象深刻。我们鼓励读者使用 MIDI 播放器(甚至是 MuseScore 本身)播放生成的音乐样本,以了解输出的复杂性及其相较于前几节中准备的简单模型的改进。
总结
恭喜你完成了另一个复杂的章节。在本章中,我们覆盖了相当多的内容,旨在建立对音乐作为数据源的理解,然后使用生成模型生成音乐的各种方法。
在本章的第一部分,我们简要讨论了音乐生成的两个组成部分,即乐谱和表演生成。我们还涉及了与音乐生成相关的不同用例。下一部分集中讨论了音乐表示的不同方法。在高层次上,我们讨论了连续和离散的表示技术。我们主要关注1D 波形和2D 频谱图作为音频或连续域中的主要表示形式。对于符号或离散表示,我们讨论了基于音符/和弦的乐谱。我们还使用music21库进行了一个快速的动手练习,将给定的 MIDI 文件转换成可读的乐谱。
当我们对音乐如何表示有了基本的了解后,我们开始构建音乐生成模型。我们首先研究的最简单方法是基于堆叠的 LSTM 架构。该模型利用注意力机制和符号表示来生成下一组音符。这个基于 LSTM 的模型帮助我们窥探了音乐生成的过程。
下一部分集中使用 GAN 设置来生成音乐。我们设计的 GAN 类似于 Mogren 等人提出的C-RNN-GAN。结果非常鼓舞人心,让我们深入了解了对抗网络如何被用于音乐生成任务。
在前两个动手练习中,我们将我们的音乐生成过程仅限于单声音乐,以保持简单。在本章的最后一节,我们的目标是理解生成复音轨/多轨音乐所需的复杂性和技术。我们详细讨论了* MUSEGAN*,这是 2017 年由 Dong 等人提出的基于 GAN 的复音轨/多轨音乐生成架构。Dong 和他的团队讨论了多轨相互依赖,音乐纹理和时间结构三个主要方面,这些方面应该由任何多轨音乐生成模型处理。他们提出了音乐生成的三种变体,即即兴演奏,作曲家和混合模型。他们还讨论了时间和小节生成模型,以便更好地理解这些方面。MUSEGAN 论文将混音音乐生成模型作为这些更小组件/模型的复杂组合来处理多轨/复音轨音乐的生成。我们利用了这一理解来构建这项工作的简化版本,并生成了我们自己的复音轨音乐。
本章让我们进一步了解了可以使用生成模型处理的另一个领域。在下一章中,我们将升级并专注于令人兴奋的强化学习领域。使用 RL,我们也将构建一些很酷的应用程序。请继续关注。
参考
-
Butcher, M. (2019 年 7 月 23 日). 看起来 TikTok 已经收购了英国创新音乐人工智能初创公司 Jukedeck。 TechCrunch.
techcrunch.com/2019/07/23/it-looks-like-titok-has-acquired-jukedeck-a-pioneering-music-ai-uk-startup/ -
Apple. (2021). GarageBand for Mac - Apple.
www.apple.com/mac/garageband/ -
Magenta. (未知发布日期) 使用机器学习创作音乐和艺术.
magenta.tensorflow.org/ -
Mogren, O. (2016). C-RNN-GAN:带对抗性训练的连续循环神经网络. NIPS 2016 年 12 月 10 日,在西班牙巴塞罗那举办的建设性机器学习研讨会(CML)。
arxiv.org/abs/1611.09904 -
Dong, H-W., Hsiao, W-Y., Yang, L-C., & Yang, Y-H. (2017). MuseGAN:用于符号音乐生成和伴奏的多轨序列生成对抗网络. 第 32 届 AAAI 人工智能会议(AAAI-18)。
salu133445.github.io/musegan/pdf/musegan-aaai2018-paper.pdf