原文:
zh.annas-archive.org/md5/6b2705e0d6d24d8c113752f67b42d7d8译者:飞龙
协议:CC BY-NC-SA 4.0
前言
在不断发展的网络安全领域中,由 OpenAI 推出的 ChatGPT 所代表的生成式人工智能和大型语言模型(LLMs)的出现,标志着一个重大的飞跃。本书致力于探索 ChatGPT 在网络安全领域的应用,从这个工具作为基本聊天界面的萌芽阶段开始,一直到它如今作为重塑网络安全方法论的先进平台的地位。
最初构想为通过分析用户交互来辅助 AI 研究,ChatGPT 从其于 2022 年底的首次发布到如今的形态,仅一年多的时间就经历了一次非凡的演变。通过集成诸如网络浏览、文档分析以及通过 DALL-E 创建图像等复杂功能,再加上语音识别和文本到图像理解方面的进步,ChatGPT 已经变成了一个多功能工具。这种转变不仅仅是技术上的,还延伸到功能领域,可能会对网络安全实践产生重大影响。
ChatGPT 演变的一个关键方面是加入代码补全和调试功能,这扩展了它在技术领域的实用性,特别是在软件开发和安全编码方面。这些进步显著提高了编码速度和效率,并有效地使编程技能和可访问性民主化。
高级数据分析功能(之前称为代码解释器)进一步开辟了网络安全的新途径。它使专业人员能够快速分析和调试与安全相关的代码,自动创建安全编码指南,并开发定制的安全脚本。能够处理和可视化来自各种来源的数据,包括文档和图像,并生成详细的图表和图形,将原始数据转化为可操作的网络安全见解。
ChatGPT 的网络浏览能力极大地增强了它在网络安全情报收集中的作用。通过使专业人员能够从各种在线来源中提取实时威胁信息,ChatGPT 促进了对新出现威胁的快速应对,并支持知情的战略决策。将数据综合成简洁、可操作的情报,突显了 ChatGPT 作为网络安全专家的动态工具在应对不断演变的网络威胁环境中的价值。
最后,本书超越了 ChatGPT 的网络界面的局限,涉足 OpenAI API,解锁了一系列可能性,使你不仅可以利用 OpenAI API,还可以创新。通过深入研究定制工具的创建,并扩展 ChatGPT 界面固有的能力,您可以为其独特的网络安全挑战量身定制基于 AI 的解决方案。
本书是网络安全专业人士利用 ChatGPT 在其项目和任务中发挥作用的基本指南,提供了如何在现实场景中应用 ChatGPT 的实用、逐步示例。
每一章都专注于网络安全的独特方面,从漏洞评估和代码分析到威胁情报和事件响应。通过这些章节,您将了解到 ChatGPT 在创建漏洞和威胁评估计划、分析和调试安全相关代码,甚至生成详细威胁报告方面的创新应用。本书深入探讨了如何将 ChatGPT 与 MITRE ATT&CK 等框架结合使用,自动创建安全编码准则,并编写自定义安全脚本,从而提供了增强网络安全基础设施的全面工具包。
通过整合 ChatGPT 的先进功能,本书不仅教育,还激励专业人士探索网络安全领域的新视野,使其成为人工智能驱动安全解决方案时代不可或缺的资源。
本书适合谁
网络安全菜谱:ChatGPT 面向对人工智能和网络安全交叉领域有共同兴趣的广泛受众。无论您是一名经验丰富的网络安全专业人士,希望将 ChatGPT 和 OpenAI API 的创新能力纳入您的安全实践中,还是一名渴望用人工智能工具拓展网络安全知识的 IT 专业人员,或者是一名学生或新兴网络安全爱好者,热衷于理解和应用 AI 在安全环境中的应用,或者是一名对 AI 在网络安全中的变革潜力感兴趣的安全研究人员,本书都为您量身定制。
本内容的结构设计可容纳各种知识水平,让您从基本概念开始,然后逐步进阶到复杂应用。这种包容性的方法确保本书对网络安全旅程的各个阶段的个人都具有相关性和可访问性。
本书涵盖内容
第一章,入门指南:ChatGPT、OpenAI API 和提示工程,介绍了 ChatGPT 和 OpenAI API,为在网络安全领域利用生成式人工智能奠定基础。它涵盖了设置账户的基础知识,掌握提示工程,以及利用 ChatGPT 进行包括编写代码和角色模拟在内的任务,为后续章节中的更高级应用做好铺垫。
第二章,漏洞评估,着重于增强漏洞评估任务,指导您如何使用 ChatGPT 创建评估计划,利用 OpenAI API 自动化流程,并与 MITRE ATT&CK 等框架集成,以进行全面的威胁报告和分析。
第三章,代码分析和安全开发,深入介绍了安全软件开发生命周期(SSDLC)的内容,展示了 ChatGPT 如何从规划到维护的整个流程。它强调了 AI 在制定安全需求,识别漏洞,生成文档以改善软件安全性和可维护性方面的应用。
第四章,治理,风险与合规(GRC),提供了使用 ChatGPT 增强网络安全治理,风险管理和合规努力的见解。包括生成网络安全政策,解读复杂标准,进行网络风险评估,并创建风险报告以加强网络安全框架。
第五章,安全意识和培训,关注在网络安全教育和培训中利用 ChatGPT。它探讨了创建引人入胜的培训材料,互动评估,钓鱼培训工具,考试准备辅助工具,并采用游戏化技术来增强网络安全的学习体验。
第六章,红队评估和渗透测试,探讨了在红队评估和渗透测试中使用 AI 增强技术。其中包括使用 MITRE ATT&CK 框架生成现实场景,进行 OSINT 侦察,自动化资产发现,并将 AI 与渗透测试工具集成,进行综合安全评估。
第七章,威胁监控和检测,涉及在威胁情报分析中使用 ChatGPT,进行实时日志分析,检测高级持续威胁(APTs),定制威胁检测规则,并使用网络流量分析来提高威胁检测和应对能力。
第八章,事件响应,着重于利用 ChatGPT 增强事件响应流程,包括事件分析,playbook 生成,根本原因分析,并自动化报告生成,以确保对网络安全事件进行高效和有效的应对。
第九章,使用本地模型和其他框架,探讨了在网络安全中使用本地 AI 模型和框架的内容,重点介绍了 LMStudio 和 Hugging Face AutoTrain 等工具,用于增强隐私保护的威胁检测,渗透测试和敏感文档审查。
第十章,最新 OpenAI 功能,提供了最新 OpenAI 功能及其在网络安全中的应用的概述。它强调了利用 ChatGPT 的先进功能进行网络威胁情报,安全数据分析,并采用可视化技术以深入了解漏洞。
要充分利用本书
为了最大限度地发挥本书带来的收益,建议您具备以下知识:
-
一个基本的网络安全原则的把握,包括常见术语和最佳实践,以便在安全领域内使用 ChatGPT 应用。(本书不旨在介绍网络安全)
-
对编程基础的理解,尤其是对 Python 的理解,因为本书广泛采用 Python 脚本来演示与 OpenAI API 的交互。
-
熟练使用命令行界面和对网络概念有一定了解,这对于执行实践练习和理解所讨论的网络安全应用至关重要。
-
对基本网络技术(如 HTML 和 JavaScript)的基本了解,这些技术支撑了本书中展示的几个网络应用安全和渗透测试示例。
| 书中涉及的软件/硬件 | 操作系统要求 |
|---|---|
| Python 3.10 或更高版本 | Windows、macOS 和 Linux(任意) |
| 代码编辑器(如 VS Code) | Windows、macOS 和 Linux(任意) |
| 命令行/终端应用 | Windows、macOS 和 Linux(任意) |
如果您使用的是本书的电子版本,我们建议您自己键入代码或通过 GitHub 仓库(下一节提供链接)访问代码。这样做将有助于避免与代码复制粘贴相关的任何潜在错误。
重要提示
生成式 AI 和 LLM 技术正在迅速发展,以至于在某些情况下,您会发现本书中的一些示例可能已经过时,由于最近的 API 和/或 AI 模型更新,甚至 ChatGPT web 界面本身也可能无法正常运行。因此,引用本书的最新代码和注意事项是至关重要的。我们将尽一切努力保持代码的更新,以反映 OpenAI 和本书中使用的其他技术提供商的最新更改和更新。
下载示例代码文件
您可以从 GitHub 上的github.com/PacktPublishing/ChatGPT-for-Cybersecurity-Cookbook处下载本书的示例代码文件。如果代码有更新,将在现有的 GitHub 仓库中进行更新。
我们还有来自我们丰富的图书和视频目录的其他代码包可在github.com/PacktPublishing/处下载。快来看看吧!
实战代码
本书的实战代码视频可以在(bit.ly/3uNma17)上观看。
使用的约定
本书中使用了许多文本约定。
文本中的代码:表示文本中的代码词,数据库表名,文件夹名称,文件名,文件扩展名,路径名,虚拟 URL,用户输入和 Twitter 句柄。例如:“如果您使用不同的 shell 配置文件,请将~/.bashrc替换为相应的文件(例如., ~/.zshrc或~/.profile)。”
一块代码设置如下:
import requests
url = "http://localhost:8001/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = { "messages": [{"content": "Analyze the Incident Response Plan for key strategies"}], "use_context": True, "context_filter": None, "include_sources": False, "stream": False }
response = requests.post(url, headers=headers, json=data)
result = response.json() print(result)
粗体:表示一个新术语,一个重要词,或您在屏幕上看到的词。例如,菜单中或对话框中的词语在文本中出现如此。举个例子:“在系统属性窗口中,单击环境变量按钮。”
提示或重要说明
以这种形式出现。
部分
在本书中,您会经常看到几个标题(准备就绪,如何做…,它是如何工作的…,还有更多…,以及另请参阅)。
为了清晰地说明如何完成菜谱,请使用以下各节部分:
准备就绪
该部分告诉您在菜谱中可以期待什么,并描述为菜谱设置任何软件或所需的任何初步设置。
如何做…
本节包含了遵循菜谱所需的步骤。
它是如何工作的…
本节通常详细解释了上一节发生的事情。
还有更多…
本节包含有关菜谱的附加信息,以使您对菜谱更加了解。
另请参阅
该部分提供有关菜谱其他有用信息的链接。
联系方式
我们的读者的反馈意见始终受欢迎。
一般反馈:如果您对本书的任何方面有疑问,请在您的邮件标题中提及书名,并发送电子邮件至 customercare@packtpub.com。
勘误:尽管我们已经尽一切努力确保我们的内容准确无误,但错误确实偶有发生。如果您在本书中发现错误,我们将不胜感激,如果您能向我们报告。请访问www.packtpub.com/support/errata,选择您的书籍,点击勘误提交表格链接,并输入详细信息。
盗版:如果您在互联网上发现我们作品的任何形式的非法副本,我们将不胜感激,如果您能向我们提供位置地址或网站名称。请通过以下链接与我们联系:copyright@packt.com。
如果您对成为作者感兴趣:如果您对某个您擅长的主题感兴趣,并且有兴趣编写或为书籍做出贡献,请访问authors.packtpub.com。
分享您的想法
一旦您阅读了ChatGPT for Cybersecurity Cookbook,我们很乐意听到您的想法!请点击此处直接转到亚马逊书评页面,并分享您的反馈意见。
- 您的评论对我们和技术社区非常重要,将帮助我们确保我们提供的是优质内容。
- 下载本书的免费 PDF 副本
-
感谢购买本书!
-
您喜欢随时随地阅读,但无法随身携带您的纸质书吗?
-
您购买的电子书是否与您选择的设备不兼容?
-
别担心,现在每本 Packt 书籍都附赠该书的无 DRM PDF 版本,无需额外费用。
-
随时随地阅读,使用任何设备。直接从您最喜欢的技术书籍中搜索、复制和粘贴代码到您的应用程序中。
-
优惠不仅仅在这里,您还可以独家获取折扣、新闻快讯,并在您的收件箱中每天获得优质免费内容
-
按照以下简单步骤来获得这些好处:
-
- 扫描下面的二维码或访问上面的链接
-

-
packt.link/free-ebook/9781805124047
-
- 提交您的购买凭证
-
- 就是这样!我们将直接将免费的 PDF 和其他好处发送到您的电子邮件中
第一章:入门指南:ChatGPT、OpenAI API 和提示工程
ChatGPT是由OpenAI开发的一个大型语言模型(LLM),专门设计用于根据用户提供的提示生成具有上下文意识的响应和内容。它利用生成式人工智能的力量来理解并智能地回应各种查询,使其成为许多应用程序的宝贵工具,包括网络安全。
重要提示
生成式人工智能是人工智能(AI)的一个分支,它使用机器学习(ML)算法和自然语言处理(NLP)来分析数据集中的模式和结构,并生成类似原始数据集的新数据。如果你在文字处理应用程序、手机聊天应用等地方使用自动更正,那么你很可能每天都在使用这项技术。也就是说,LLM 的出现远远超出了简单的自动补全。
LLM 是一种经过大量文本数据训练的生成式人工智能,使其能够理解上下文,生成类似人类的响应,并根据用户输入创建内容。如果你曾与帮助台聊天机器人进行过沟通,那么你可能已经使用过 LLMs 了。
GPT代表生成式预训练识别器,顾名思义,它是一个预先训练的 LLM,用于提高准确性和/或提供特定的基于知识的数据生成。
ChatGPT 在一些学术和内容创作社区引起了关于抄袭的担忧。由于其生成逼真和类似人类的文本的能力,它还被牵涉到了误传和社会工程活动中。然而,其改革多个行业的潜力也是不可忽视的。特别是由于其深厚的知识基础和执行复杂任务的能力(比如即时分析数据甚至编写完全功能的代码),LLMs 在更严谨的领域,比如编程和网络安全,已经显示出了巨大的潜力。
在这一章中,我们将指导你完成与 OpenAI 建立账户、熟悉 ChatGPT 并掌握提示工程(这是发挥这项技术真正力量的关键)的过程。我们还将介绍 OpenAI API,为你提供必要的工具和技术,以充分发挥 ChatGPT 的潜力。
你将首先学习如何创建 ChatGPT 账户并生成 API 密钥,该密钥作为你访问 OpenAI 平台的唯一访问点。然后我们将探讨使用各种网络安全应用程序的基本 ChatGPT 提示技术,比如指导 ChatGPT 编写查找你的 IP 地址的 Python 代码以及模拟应用 ChatGPT 角色的 AI CISO 角色。
本章将深入探讨如何利用模板增强 ChatGPT 输出,生成全面的威胁报告,并将输出格式化为表格,以改善展示效果,例如创建安全控制表。在阅读本章的过程中,你将学会如何将 OpenAI API 密钥设置为环境变量,以简化开发流程;使用 Python 发送请求和处理响应;高效地利用文件进行提示和 API 密钥访问;有效地使用提示变量创建多功能应用程序,如根据用户输入生成手册页面。到本章结束时,你将对 ChatGPT 的各个方面有扎实的理解,以及如何在网络安全领域利用其功能。
小贴士
即使您已经熟悉基本的 ChatGPT 和 OpenAI API 设置和原理,回顾第一章中的菜谱仍然对您有利,因为几乎所有的例子都设置在网络安全的背景下,这在一些提示示例中得到了体现。
在本章中,我们将介绍以下的菜谱:
-
设置 ChatGPT 账号
-
创建 API 密钥和与 OpenAI 进行交互
-
基本提示(应用场景:查找您的 IP 地址)
-
应用 ChatGPT 角色(应用场景:AI CISO)
-
利用模板增强输出(应用场景:威胁报告)
-
将输出格式化为表格(应用场景:安全控制表)
-
将 OpenAI API 密钥设置为环境变量
-
使用 Python 发送 API 请求并处理响应
-
使用文件进行提示和 API 密钥访问
-
使用提示变量(应用场景:手册页面生成器)
技术要求
本章需要使用网络浏览器和稳定的互联网连接来访问 ChatGPT 平台并设置您的账户。需要基本熟悉 Python 编程语言和命令行操作,因为你将要使用Python 3.x,需要在系统上安装 Python 3.x,以便使用 OpenAI GPT API 并创建 Python 脚本。还需要一个代码编辑器来编写和编辑 Python 代码和提示文件,以便在此章节中编写和编辑代码。
本章的代码文件可以在此处找到:github.com/PacktPublishing/ChatGPT-for-Cybersecurity-Cookbook 。
设置 ChatGPT 账号
在本节中,我们将学习生成式人工智能、LLMs 和 ChatGPT。然后,我们将为你介绍如何注册 OpenAI 账户并探索其提供的功能。
准备工作
要设置 ChatGPT 账户,您需要一个活跃的电子邮件地址和现代的网络浏览器。
重要提示
在撰写本书时,我们已经尽力确保每个插图和指令都是正确的。但是,这是一个快速发展的技术领域,本书中使用的许多工具目前正在快速更新。因此,您可能会发现细微的差异。
如何做…
通过建立 ChatGPT 账号,您将获得访问一个强大 AI 工具的能力,可以极大地增强您的网络安全工作流程。在本节中,我们将指导您完成创建账号的步骤,让您能够利用 ChatGPT 的能力进行各种应用,从威胁分析到生成安全报告:
-
访问 OpenAI 网站
platform.openai.com/并点击 注册。 -
输入您的电子邮件地址然后点击 继续。另外,您也可以使用您现有的 Google 或 Microsoft 账号注册:
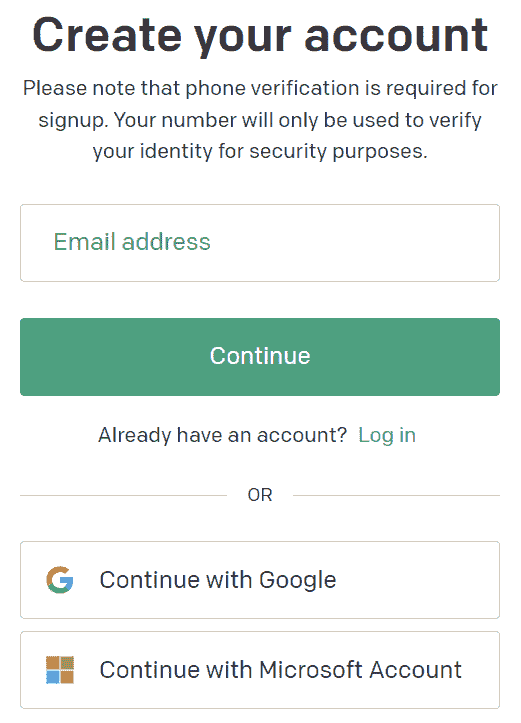
图 1.1 – OpenAI 注册表
-
输入一个强密码然后点击 继续。
-
检查您的电子邮件,看看来自 OpenAI 的验证消息。点击邮件中提供的链接验证您的账号。
-
完成账号验证后,输入所需信息(名字、姓氏、可选的机构名称和生日)然后点击 继续。
-
输入您的电话号码进行电话验证,然后点击 发送验证码。
-
当您收到包含验证码的短信时,输入验证码然后点击 继续。
-
访问并收藏
platform.openai.com/docs/以开始熟悉 OpenAI 的文档和功能。
工作原理…
通过建立一个 OpenAI 账号,您将获得访问 ChatGPT API 和平台提供的其他功能的权限,如 Playground 和所有可用模型。这将使您能够在您的网络安全操作中利用 ChatGPT 的能力,提升您的效率和决策流程。
还有更多…
当您注册免费的 OpenAI 账号时,您将获得价值 $18 的免费信用额度。虽然您可能不会在本书的内容中用完所有的免费信用额度,但随着持续使用,最终会用完。考虑升级到付费的 OpenAI 计划以访问额外功能,如增加的 API 使用限制以及优先访问新功能和改进:
-
升级到 ChatGPT Plus:
ChatGPT Plus 是一个订阅计划,提供了比免费访问 ChatGPT 更多的好处。通过 ChatGPT Plus 订阅,您可以期待更快的响应时间,在高峰时段甚至有通用访问 ChatGPT,以及优先访问新功能和改进(在撰写本文时包括访问 GPT-4)。这个订阅计划旨在提供增强的用户体验,并确保您能充分利用 ChatGPT 来满足您的网络安全需求。
-
拥有 API 密钥的好处:
拥有 API 密钥对通过 OpenAI API 以编程方式利用 ChatGPT 的功能至关重要。通过 API 密钥,您可以直接从您的应用程序、脚本或工具中访问 ChatGPT,从而实现更加定制化和自动化的交互。这使您可以构建各种应用程序,集成 ChatGPT 的智能以增强您的网络安全实践。通过设置 API 密钥,您将能够充分利用 ChatGPT 的全部功能,并根据您的具体需求定制其功能,使其成为您网络安全任务的不可或缺的工具。
提示
我强烈建议您升级到 ChatGPT Plus,这样您就可以访问 GPT-4。虽然 GPT-3.5 仍然非常强大,但 GPT-4 的编码效率和准确性使其更适合我们将在本书中涵盖的用例和普遍的网络安全。在撰写本文时,ChatGPT Plus 还具有其他附加功能,如插件的可用性和代码解释器,这些功能将在后续章节中介绍。
创建 API 密钥并与 OpenAI 交互
在此食谱中,我们将指导您完成获取 OpenAI API 密钥的过程,并向您介绍 OpenAI Playground,您可以在其中尝试不同的模型并了解它们的更多功能。
准备工作
要获得 OpenAI API 密钥,您需要拥有活跃的 OpenAI 帐户。如果还没有,请完成 设置 ChatGPT 帐户 食谱以设置您的 ChatGPT 帐户。
如何做…
创建 API 密钥并与 OpenAI 交互使您能够利用 ChatGPT 和其他 OpenAI 模型的功能进行应用程序开发。这意味着您将能够利用这些人工智能技术构建强大的工具,自动化任务,并定制与模型的交互。通过本食谱的最后,您将成功创建了用于程序访问 OpenAI 模型的 API 密钥,并学会如何使用 OpenAI Playground 进行实验。
现在,让我们按照创建 API 密钥并探索 OpenAI Playground 的步骤进行:
-
在
platform.openai.com上登录您的 OpenAI 帐户。 -
登录后,单击屏幕右上角的 个人资料图片/名称,然后从下拉菜单中选择 查看 API 密钥:
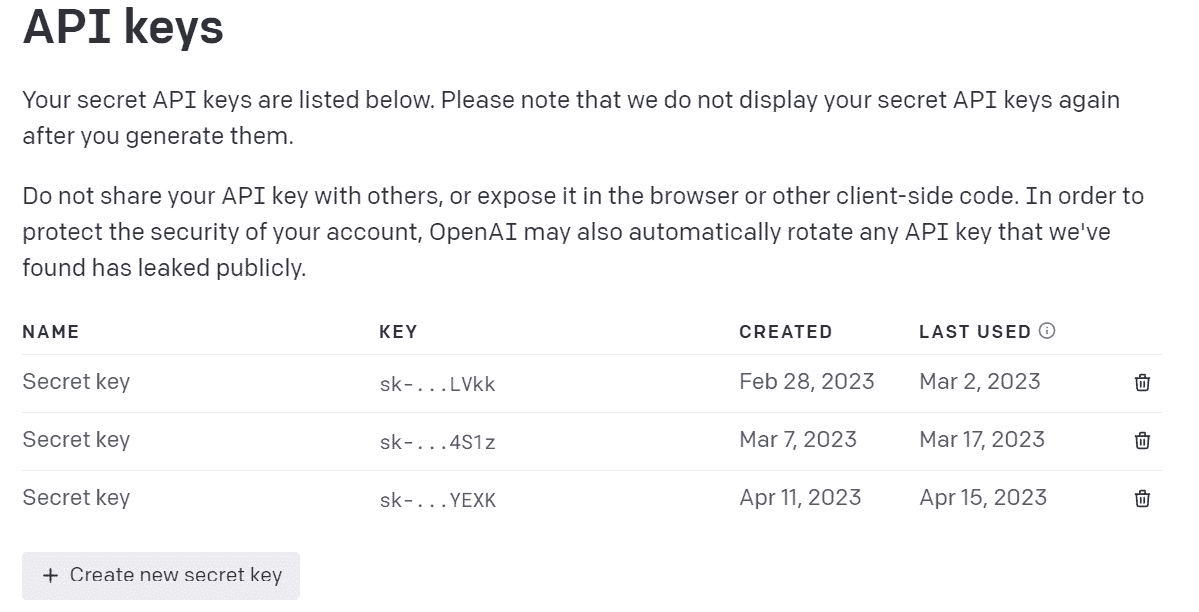
图 1.2 - API 密钥界面
-
单击“+ 创建新的秘密密钥”按钮以生成新的 API 密钥。
-
为您的 API 密钥命名(可选),然后单击 创建秘密密钥:
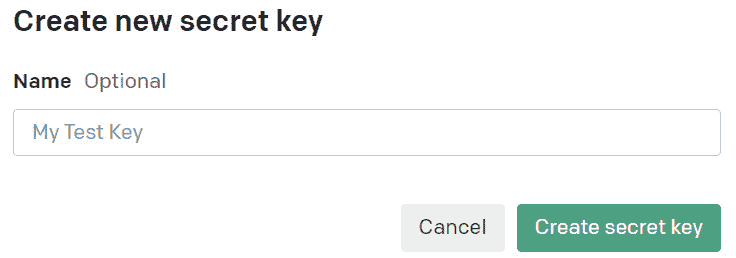
图 1.3 - 命名您的 API 密钥
- 您的新 API 密钥将显示在屏幕上。单击 复制图标
 ,将密钥复制到剪贴板:
,将密钥复制到剪贴板:
提示
立即将您的 API 密钥保存在安全的位置,因为稍后在使用 OpenAI API 时会需要它;一旦保存,您将无法再完整查看密钥。
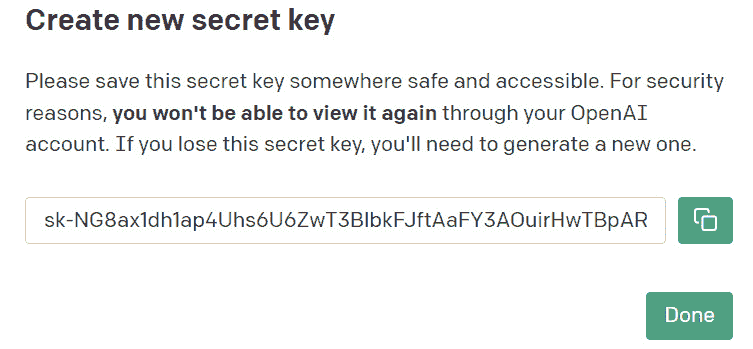
图 1.4 – 复制您的 API 密钥
工作原理…
通过创建 API 密钥,您可以通过 OpenAI API 实现对 ChatGPT 和其他 OpenAI 模型的编程访问。这使您能够将 ChatGPT 的功能集成到您的应用程序、脚本或工具中,从而实现更加定制化和自动化的交互。
更多内容…
OpenAI Playground 是一个交互式工具,允许您尝试不同的 OpenAI 模型,包括 ChatGPT,以及它们的各种参数,但不需要您编写任何代码。要访问和使用 Playground,请按照以下步骤操作:
重要提示
使用 Playground 需要令牌积分;您每个月都会为所使用的积分付费。从大多数情况来看,这个成本可以被认为是非常负担得起的,这取决于您的观点。然而,如果不加以监控,过度使用会导致显著的成本累积。
-
登录到您的 OpenAI 账户。
-
点击顶部导航栏中的 Playground:
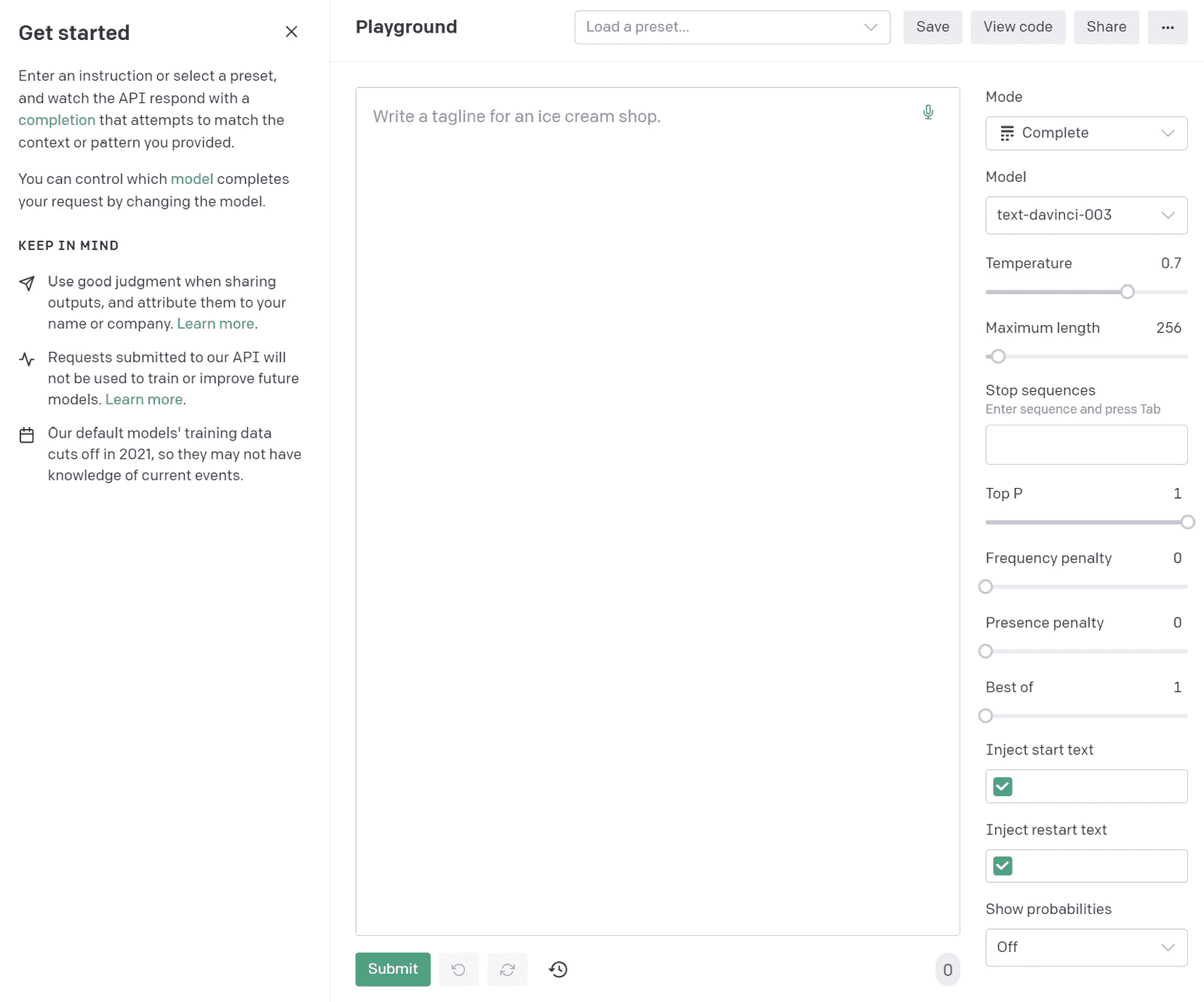
图 1.5 – OpenAI Playground
- 在 Playground 中,您可以通过从模型下拉菜单中选择要使用的模型来选择不同的模型:

图 1.6 – 选择模型
- 在提供的文本框中输入您的提示,然后点击 提交 查看模型的响应:

图 1.7 – 输入提示并生成响应
提示
即使您不需要输入 API 密钥来与 Playground 交互,使用仍然会计入您账户的令牌/积分使用情况。
- 您还可以从消息框右侧的设置面板调整各种设置,如最大长度、生成的响应数量等:

图 1.8 – 调整 Playground 中的设置
最重要的两个参数是温度和最大长度:
-
温度参数影响模型响应的随机性和创造性。较高的温度(例如,0.8)将产生更多样化和创造性的输出,而较低的温度(例如,0.2)将生成更加专注和确定性的响应。通过调整温度,您可以控制模型的创造性与对提供的上下文或提示的遵循之间的平衡。
-
最大长度参数控制模型在其响应中将生成的标记(单词或单词片段)的数量。通过设置较高的最大长度,您可以获得更长的响应,而较低的最大长度将产生更简洁的输出。调整最大长度可以帮助您将响应长度定制到您特定的需求或要求。
随意在 OpenAI Playground 中或在使用 API 时尝试这些参数,以找到适合您特定用例或期望输出的最佳设置。
Playground 允许您尝试不同的提示样式、预设和模型设置,帮助您更好地理解如何调整提示和 API 请求以获得最佳结果:
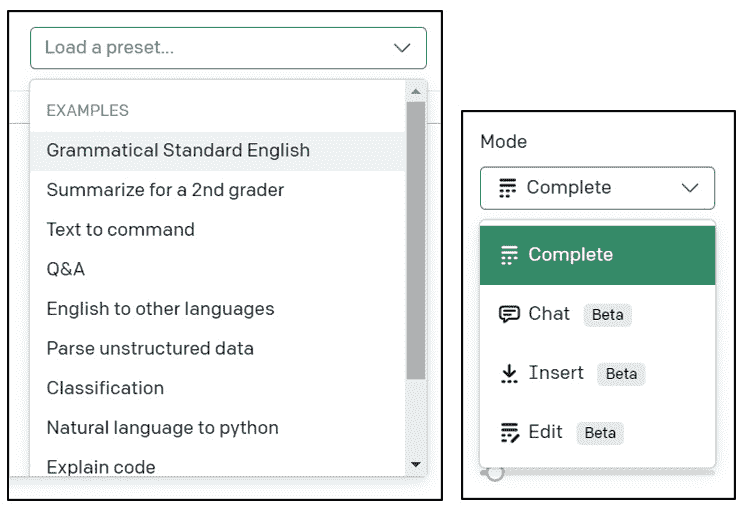
图 1.9 – 提示预设和模型模式
提示
虽然在本书中我们将使用 API 覆盖几种不同的提示设置,但我们不会涵盖所有情况。建议您查阅OpenAPI 文档以获取更多详情。
基本提示(应用程序:查找您的 IP 地址)
在本篇中,我们将使用 ChatGPT 界面探索 ChatGPT 提示的基础知识,该界面与我们在上一篇中使用的 OpenAI Playground 不同。使用 ChatGPT 界面的优点是它不消耗账户积分,并且更适合生成格式化输出,例如编写代码或创建表格。
准备工作
要使用 ChatGPT 界面,您需要拥有一个活跃的 OpenAI 账户。如果还没有,请完成设置 ChatGPT 账户的步骤来设置您的 ChatGPT 账户。
如何操作…
在本篇中,我们将指导您使用 ChatGPT 界面生成一个检索用户公共 IP 地址的 Python 脚本。通过按照这些步骤,您将学会如何与 ChatGPT 以对话方式交互,并接收上下文感知的响应,包括代码片段。
现在,让我们按照本篇的步骤进行:
-
在浏览器中,转到
chat.openai.com,然后单击登录。 -
使用您的 OpenAI 凭据登录。
-
一旦您登录,您将进入 ChatGPT 界面。该界面类似于聊天应用程序,在底部有一个文本框,您可以在其中输入您的提示:
图 1.10 – ChatGPT 界面
- ChatGPT 采用基于对话的方法,因此您只需将您的提示作为消息键入并按下Enter或单击
 按钮,即可从模型接收响应。例如,您可以询问 ChatGPT 生成一段 Python 代码以查找用户的公共 IP 地址:
按钮,即可从模型接收响应。例如,您可以询问 ChatGPT 生成一段 Python 代码以查找用户的公共 IP 地址:

图 1.11 – 输入提示
ChatGPT 将生成一个包含请求的 Python 代码以及详细解释的响应:
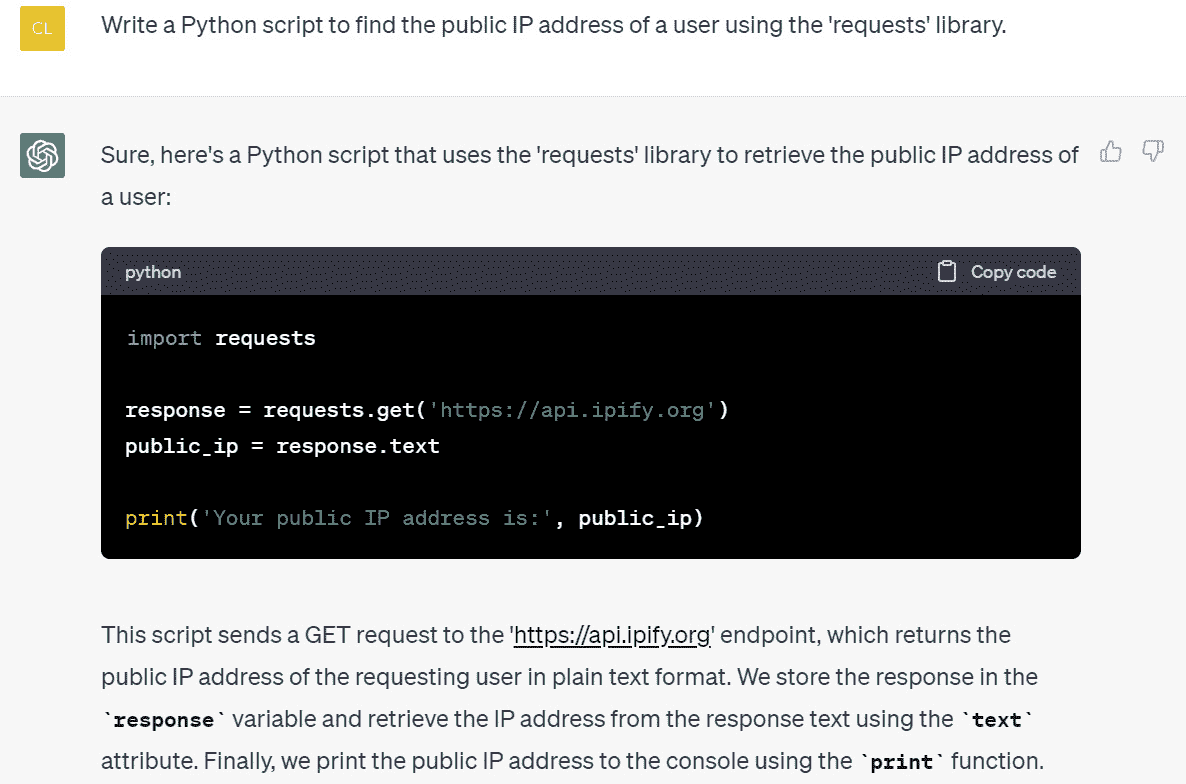
图 1.12 – ChatGPT 响应代码
- 继续对话,提出后续问题或提供额外信息,ChatGPT 将相应作出回应:
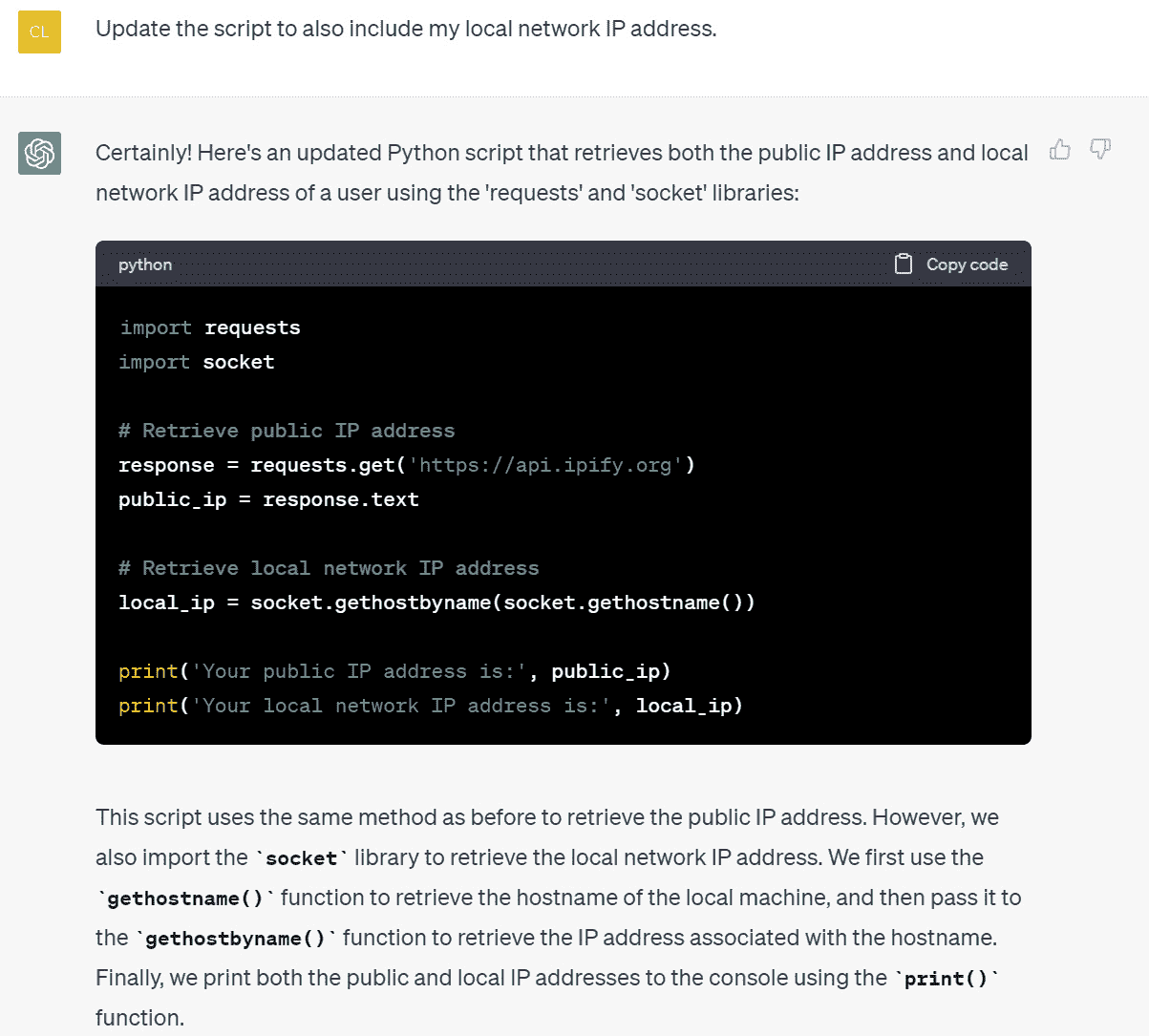
图 1.13 – ChatGPT 上下文跟进响应
-
通过点击
.pyPython 脚本运行 ChatGPT 生成的代码,并从终端运行:PS D:\GPT\ChatGPT for Cybersecurity Cookbook> python .\my_ip.py Your public IP address is:  Your local network IP address is: 192.168.1.105
图 1.14 – 运行 ChatGPT 生成的脚本
工作原理…
通过使用 ChatGPT 界面输入提示,你可以生成贯穿整个对话的具有上下文感知的响应和内容,类似于聊天机器人。基于对话的方法允许更自然的交互和能力提出跟进问题或提供额外的上下文。响应甚至可以包括复杂的格式,如代码片段或表格(稍后会介绍更多关于表格的内容)。
还有更多…
随着你对 ChatGPT 越来越熟悉,你可以尝试不同的提示样式、说明和上下文,以获得你网络安全任务所需的输出。你还可以比较通过 ChatGPT 界面和 OpenAI Playground 生成的结果,以确定哪种方法最适合你的需求。
小贴士
你可以通过提供非常清晰和具体的说明或使用角色来进一步完善生成的输出。将复杂的提示分解为几个较小的提示也有帮助,每个提示一个指令,随着你的进展构建在前一个提示的基础上。
在即将到来的示例中,我们将深入探讨更高级的提示技术,利用这些技术来帮助你从 ChatGPT 获得最准确和详细的响应。
当你与 ChatGPT 交互时,你的对话历史会自动保存在 ChatGPT 界面的左侧面板中。这个功能允许你轻松访问和审阅你以前的提示和响应。
通过利用对话历史功能,你可以跟踪你与 ChatGPT 的交互,并快速查阅以前的响应,用于你的网络安全任务或其他项目:
图 1.15 – ChatGPT 界面中的对话历史
要查看保存的对话,只需在左侧面板中点击所需对话即可。你也可以通过点击位于对话列表顶部的 + 新聊天 按钮来创建新的对话。这样可以根据特定任务或主题分离和组织你的提示和响应。
注意事项
开始新对话时,请记住模型会失去之前对话的上下文。如果你想引用以前对话中的任何信息,你需要在新提示中包含该上下文。
应用 ChatGPT 角色(应用:AI CISO)
在这个示例中,我们将演示如何在你的提示中使用角色,以提高 ChatGPT 响应的准确性和详细程度。为 ChatGPT 分配角色有助于它生成更具上下文感知和相关性的内容,特别是当你需要专业水平的见解或建议时。
准备工作
确保你可以访问 ChatGPT 界面,方法是登录你的 OpenAI 帐号。
如何操作…
通过分配角色,您将能够从模型中获得专家级别的见解和建议。让我们深入了解此配方的步骤:
-
要为 ChatGPT 分配一个角色,请在你的提示开头描述你希望模型扮演的角色。例如,你可以使用以下提示:
You are a cybersecurity expert with 20 years of experience. Explain the importance of multi-factor authentication (MFA) in securing online accounts, to an executive audience. -
ChatGPT 将生成一个符合分配角色的响应,根据网络安全专家的专业知识和观点提供关于该主题的详细解释:

图 1.16 – 具有基于角色的专业知识的 ChatGPT 响应
-
尝试为不同情景分配不同角色,例如以下情况:
You are a CISO with 30 years of experience. What are the top cybersecurity risks businesses should be aware of? -
或者,你可以使用以下方式:
You are an ethical hacker. Explain how a penetration test can help improve an organization's security posture.
注意事项
请记住,ChatGPT 的知识基于它所训练的数据,截止日期为 2021 年 9 月。因此,该模型可能不了解在其训练数据截止日期之后出现的网络安全领域的最新发展、趋势或技术。在解释其响应时,始终使用最新的来源验证 ChatGPT 生成的信息,并考虑其训练限制。我们将在本书的后面讨论如何克服这一限制的技术。
工作原理…
当你为 ChatGPT 分配一个角色时,你提供了一个特定的上下文或角色给模型参考。这有助于模型生成符合给定角色的响应,从而产生更准确、相关和详细的内容。该模型将生成符合分配角色的专业知识和观点的内容,提供更好的见解、意见或建议。
还有更多…
当你在提示中更加熟悉使用角色时,你可以尝试使用不同角色和场景的不同组合,以获得符合网络安全任务要求的期望输出。例如,你可以通过为每个角色交替提示来创建一个对话:
-
角色 1:
You are a network administrator. What measures do you take to secure your organization's network? -
角色 2:
You are a cybersecurity consultant. What additional recommendations do you have for the network administrator to further enhance network security?
通过创造性地使用角色并尝试不同的组合,你可以利用 ChatGPT 的专业知识,并获得更准确和详细的响应,涵盖了各种网络安全主题和情景。
我们将在后面的章节中尝试自动化角色对话。
使用模板增强输出(应用:威胁报告)
在本配方中,我们将探讨如何使用输出模板来引导 ChatGPT 的响应,使其更加一致、结构良好,并适用于报告或其他正式文档。通过为输出提供一个具体的格式,你可以确保生成的内容符合你的要求,并且更容易集成到你的网络安全项目中。
准备工作
确保你可以通过登录你的 OpenAI 帐户访问 ChatGPT 接口。
怎么做…
要开始,请按照以下步骤进行:
-
在制作提示时,您可以指定几种不同格式选项的输出,如标题、字体加粗、列表等。以下提示演示了如何创建带有标题、字体加粗和列表类型的输出:
Create an analysis report of the WannaCry Ransomware Attack as it relates to the cyber kill chain, using the following format: # Threat Report ## Overview - **Threat Name:** - **Date of Occurrence:** - **Industries Affected:** - **Impact:** ## Cyber Kill Chain Analysis 1\. **Kill chain step 1:** 2\. **Kill chain step 2:** 3\. … ## Mitigation Recommendations - *Mitigation recommendation 1* - *Mitigaiton recommendation 2* … -
ChatGPT 将生成符合指定模板的响应,提供结构良好且一致的输出:

图 1.17 – ChatGPT 响应与格式化(标题、粗体字体和列表)

图 1.18 – ChatGPT 响应与格式化(标题、列表和斜体文本)
- 现在,这种格式化的文本结构更加清晰,可以通过复制和粘贴轻松转移到其他文档中,并保留其格式。
它是如何工作的…
通过在提示中为输出提供清晰的模板,您可以引导 ChatGPT 生成符合指定结构和格式的响应。这有助于确保生成的内容一致、组织良好,并适用于报告、演示文稿或其他正式文档中使用。模型将重点放在生成符合您提供的输出模板格式和结构的内容,同时仍然提供您请求的信息。
在格式化 ChatGPT 输出时使用以下约定:
-
要创建一个主
#),后跟一个空格和标题的文本。在这种情况下,主标题是威胁报告。 -
要创建一个
##),后跟一个空格和子标题的文本。在这种情况下,子标题是概述、网络攻击链分析和缓解建议。您可以通过增加井号数来继续创建额外的子标题级别。 -
要创建一个
-)或星号(*),后跟一个空格和项目符号的文本。在这种情况下,项目符号在概述部分中用于指示威胁的名称、发生日期、受影响的行业和影响。 -
要创建
**)或下划线(__)来包围要加粗的文本。在这种情况下,每个项目符号和编号列表关键词都被加粗。 -
要用
*)或下划线(_)来包围您想要斜体的文本。在这种情况下,第二个攻击链步骤使用一对下划线斜体。这里,斜体文本用于缓解建议项目符号。 -
要创建一个编号列表,请使用一个数字后跟一个句点和一个空格,然后是列表项的文本。在这种情况下,网络攻击链分析部分是一个编号列表。
还有更多…
结合模板和其他技术,如角色,可以进一步提升生成内容的质量和相关性。通过应用模板和角色,您可以创建不仅结构良好、一致性强,而且还符合特定专家观点的输出。
随着您在提示中使用模板变得更加舒适,您可以尝试不同的格式、结构和场景,以获得您的网络安全任务所需的输出。例如,除了文本格式化之外,您还可以使用表格来进一步组织生成的内容,这是我们将在下一个示例中介绍的内容。
将输出格式化为表格(应用:安全控制表)
在本示例中,我们将演示如何创建引导 ChatGPT 生成表格格式输出的提示。表格可以是一种有效的组织和展示信息的方式,结构化且易于阅读。在本示例中,我们将创建一个安全控制比较表。
准备工作
确保您通过登录您的 OpenAI 账户来访问 ChatGPT 界面。
如何做到…
本示例将演示如何创建一个安全控制比较表。让我们深入了解如何实现这一目标:
-
通过指定表格格式和您想要包含的信息来制作您的提示。对于本示例,我们将生成一个比较不同安全控制的表格:
Create a table comparing five different security controls. The table should have the following columns: Control Name, Description, Implementation Cost, Maintenance Cost, Effectiveness, and Ease of Implementation. -
ChatGPT 将生成一个响应,其中包含一个具有指定列的表,填充有相关信息:
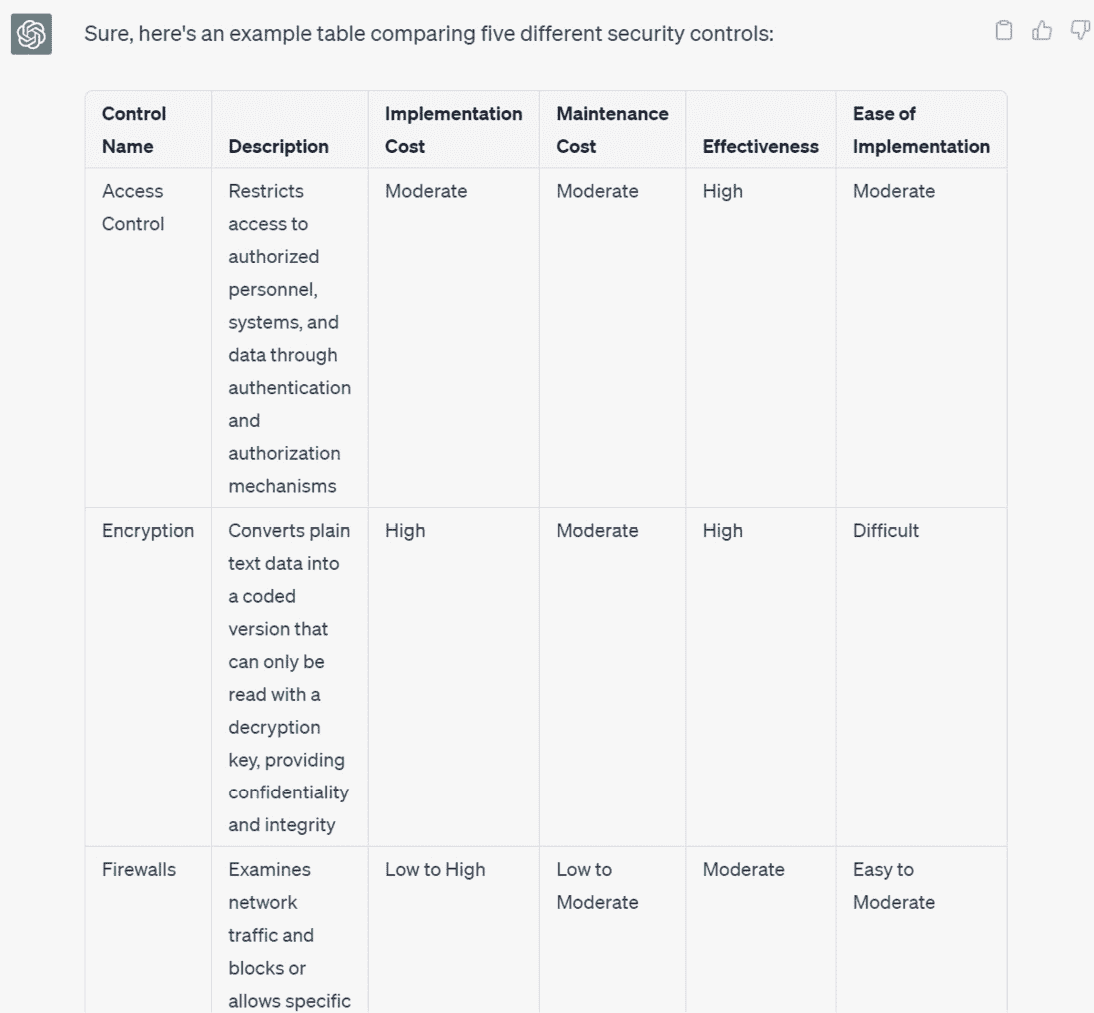
图 1.19 – ChatGPT 响应片段,带有表格
- 您现在可以轻松地将生成的表格直接复制粘贴到文档或电子表格中,然后可以进一步格式化和完善:
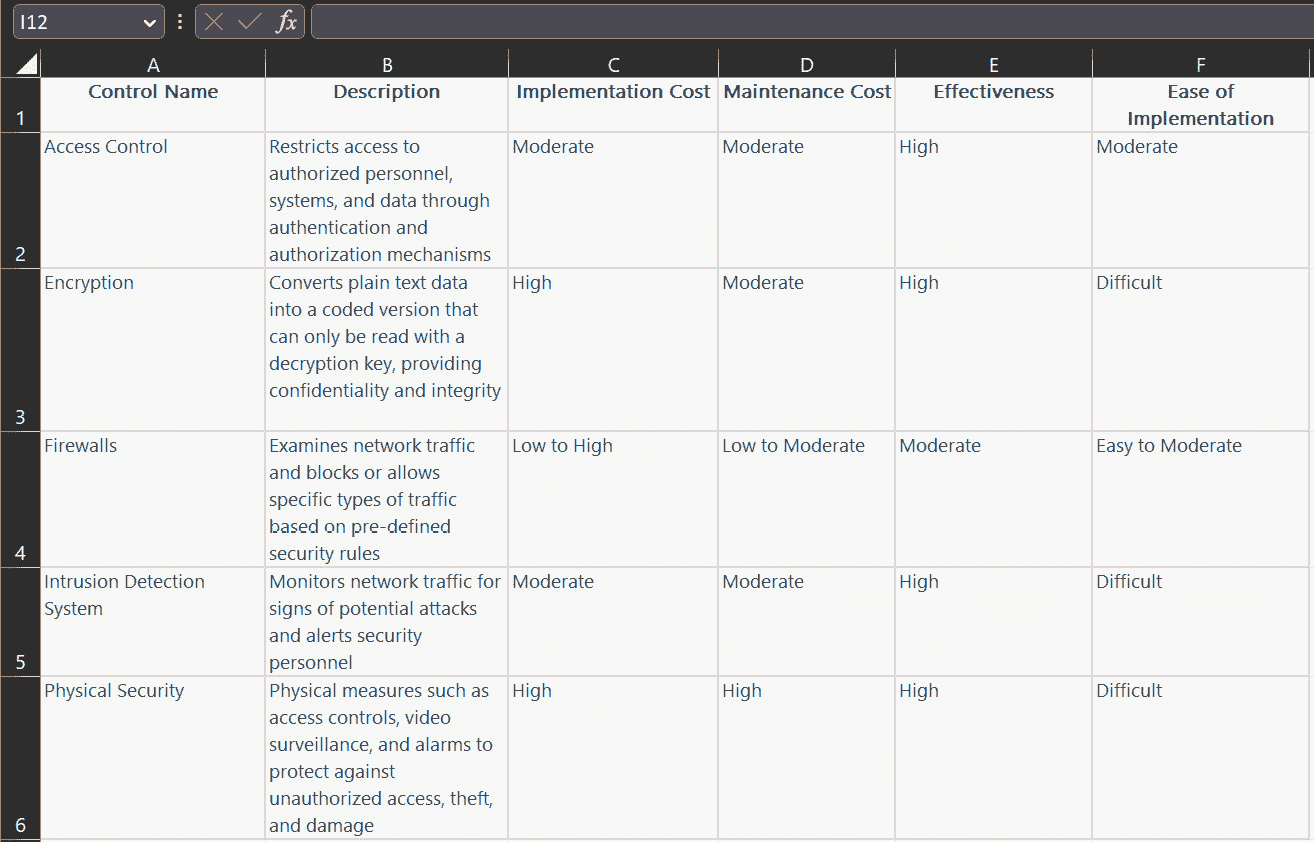
图 1.20 – ChatGPT 响应直接复制/粘贴到电子表格中
工作原理…
通过在提示中指定表格格式和所需信息,您引导 ChatGPT 以结构化的、表格化的方式生成内容。模型将专注于生成符合指定格式的内容,并填充表格所需的信息。ChatGPT 界面会自动理解如何使用 markdown 语言提供表格格式,然后由浏览器解释。
在本示例中,我们要求 ChatGPT 创建一个比较五种不同安全控制的表格,其中包括控制名称、描述、实施成本、维护成本、有效性和实施易用性等列。生成的表格提供了不同安全控制的有组织、易于理解的概览。
还有更多…
随着您在提示中使用表格变得更加熟练,您可以尝试不同的格式、结构和场景,以获得您的网络安全任务所需的输出。您还可以将表格与其他技术(如角色和模板)结合使用,以进一步提高生成内容的质量和相关性。
通过创造性地使用表格并尝试不同的组合,您可以利用 ChatGPT 的能力来为各种网络安全主题和情况生成结构化和有组织的内容。
将 OpenAI API 密钥设置为环境变量
在本教程中,我们将向您展示如何将您的 OpenAI API 密钥设置为环境变量。这是一个重要的步骤,因为它允许您在 Python 代码中使用 API 密钥而不是硬编码,这是出于安全目的的最佳做法。
准备工作
确保您已经通过注册帐户并访问 API 密钥部分获得了您的 OpenAI API 密钥,如创建 API 密钥和与 OpenAI 互动教程中所述。
如何做…
此示例将演示如何将您的 OpenAI API 密钥设置为环境变量,以在您的 Python 代码中安全访问。让我们深入了解实现这一目标的步骤。
- 在您的操作系统上设置 API 密钥作为环境变量。
对于 Windows
-
打开开始菜单,搜索
环境变量,然后点击编辑系统 环境变量。 -
在系统属性窗口中,点击环境 变量按钮。
-
在环境变量窗口中,点击用户变量或系统变量下的新建(取决于您的偏好)。
-
将
OPENAI_API_KEY作为变量名称,并将您的 API 密钥粘贴为变量值。点击确定保存新的环境变量。
对于 macOS/Linux
-
打开终端窗口。
-
通过运行以下命令(将
your_api_key替换为您的实际 API 密钥),将 API 密钥添加到您的 shell 配置文件(例如.bashrc、.zshrc或.profile)中:echo 'export OPENAI_API_KEY="your_api_key"' >> ~/.bashrc
提示
如果您使用不同的 shell 配置文件,请用适当的文件(例如.bashrc、.zshrc或.profile)替换~/.bashrc。
-
重新启动终端或运行
source ~/.bashrc(或适当的配置文件)以应用更改。 -
使用
os模块在你的 Python 代码中访问 API 密钥:import os # Access the OpenAI API key from the environment variable api_key = os.environ["OPENAI_API_KEY"]
重要提示
Linux 和基于 Unix 的系统有许多不同版本,设置环境变量的确切语法可能与此处所示略有不同。但是,一般的方法应该是类似的。如果遇到问题,请查阅您系统特定的文档,了解有关设置环境变量的指导。
工作原理…
通过将 OpenAI API 密钥设置为环境变量,您可以在 Python 代码中使用它,而无需将密钥硬编码,这是一种安全最佳实践。在 Python 代码中,您可以使用os模块从先前创建的环境变量中访问 API 密钥。
在处理敏感数据(如 API 密钥或其他凭证)时,使用环境变量是一个常见的做法。这种方法允许您将您的代码与敏感数据分离开来,并使您更容易地管理您的凭证,因为您只需要在一个地方更新它们(即环境变量)。此外,它还有助于在您与他人共享代码或在公共代码库中发布代码时,防止意外暴露敏感信息。
还有更多内容…
在某些情况下,您可能希望使用如python-dotenv这样的 Python 包来管理环境变量。这个包允许你将环境变量存储在.env文件中,并且你可以在 Python 代码中加载它。这种方法的优点是你可以将所有与项目相关的环境变量保存在单个文件中,从而更容易地管理和共享你的项目设置。不过要记住,你永远不应该将.env文件提交到公共的代码库中;要么将它包含在你的.gitignore文件或其他忽略版本控制的配置文件中。
使用 Python 发送 API 请求和处理响应
在这个配方中,我们将探讨如何使用 Python 发送请求到 OpenAI GPT API,以及如何处理响应。我们将逐步讲解构建 API 请求的过程,发送请求和使用openai模块处理响应。
准备就绪
-
确保在您的系统上安装了 Python。
-
在终端或命令提示符中运行以下命令以安装 OpenAI Python 模块:
pip install openai
怎么做…
使用 API 的重要性在于其在与 ChatGPT 实时通信并获取有价值的见解方面的能力。通过发送 API 请求和处理响应,您可以利用 GPT 的强大功能来回答问题、生成内容或以动态和可定制的方式解决问题。在接下来的步骤中,我们将演示如何构建 API 请求、发送请求和处理响应,使您能够有效地将 ChatGPT 集成到您的项目或应用程序中:
-
首先导入所需的模块:
import openai from openai import OpenAI import os -
通过检索环境变量来设置 API 密钥,就像在 将 OpenAI API 密钥设置为环境变量 配方中所做的那样:
openai.api_key = os.getenv("OPENAI_API_KEY") -
定义一个函数来向 OpenAI API 发送提示信息并接收响应:
client = OpenAI() def get_chat_gpt_response(prompt): response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": prompt}], max_tokens=2048, temperature=0.7 ) return response.choices[0].message.content.strip() -
使用提示调用函数来发送请求并接收响应:
prompt = "Explain the difference between symmetric and asymmetric encryption." response_text = get_chat_gpt_response(prompt) print(response_text)
它是如何工作的…
-
首先,我们导入所需的模块。
openai模块是 OpenAI API 库,而os模块帮助我们从环境变量中检索 API 密钥。 -
我们通过使用
os模块从环境变量中检索 API 密钥来设置 API 密钥。 -
接下来,我们定义一个名为
get_chat_gpt_response()的函数,它接受一个参数:提示信息。这个函数使用openai.Completion.create()方法向 OpenAI API 发送请求。这个方法有几个参数:-
engine:在这里,我们指定引擎(在本例中为chat-3.5-turbo)。 -
prompt:用于模型生成响应的输入文本。 -
max_tokens:生成响应中的标记的最大数量。标记可以短至一个字符或长至一个单词。 -
n:您希望从模型接收的生成响应的数量。在本例中,我们将其设置为1以接收单个响应。 -
stop:如果模型遇到的令牌序列将停止生成过程。这对于限制响应的长度或停止在特定点(例如句子或段落的末尾)非常有用。 -
temperature:控制生成响应的随机性的值。较高的温度(例如,1.0)会导致更随机的响应,而较低的温度(例如,0.1)会使响应更加集中和确定性。
-
-
最后,我们调用
get_chat_gpt_response()函数并提供提示,向 OpenAI API 发送请求,接收响应。该函数返回响应文本,然后将其打印到控制台。return response.choices[0].message.content.strip()代码行通过访问选择列表中的第一个选择(index 0)来检索生成的响应文本。 -
response.choices是从模型生成的响应列表。在我们的情况下,由于我们设置了n=1,因此列表中只有一个响应。.text属性检索响应的实际文本,.strip()方法删除任何前导或尾随空格。 -
例如,来自 OpenAI API 的非格式化响应可能如下所示:
{ 'id': 'example_id', 'object': 'text.completion', 'created': 1234567890, 'model': 'chat-3.5-turbo', 'usage': {'prompt_tokens': 12, 'completion_tokens': 89, 'total_tokens': 101}, 'choices': [ { 'text': ' Symmetric encryption uses the same key for both encryption and decryption, while asymmetric encryption uses different keys for encryption and decryption, typically a public key for encryption and a private key for decryption. This difference in key usage leads to different security properties and use cases for each type of encryption.', 'index': 0, 'logprobs': None, 'finish_reason': 'stop' } ] }在本示例中,我们使用
response.choices[0].text.strip()访问响应文本,返回以下文本:Symmetric encryption uses the same key for both encryption and decryption, while asymmetric encryption uses different keys for encryption and decryption, typically a public key for encryption and a private key for decryption. This difference in key usage leads to different security properties and use cases for each type of encryption.
还有更多…
您还可以通过修改openai.Completion.create()方法中的参数来进一步定制 API 请求。例如,您可以调整温度以获得更有创意或更有焦点的响应,将max_tokens值更改为限制或扩展生成内容的长度,或者使用stop参数来定义响应生成的特定停止点。
此外,您可以通过调整n参数来生成多个响应并比较它们的质量或多样性。请记住,生成多个响应将消耗更多的标记,并可能影响 API 请求的成本和执行时间。
了解和微调这些参数以从 ChatGPT 获取所需的输出非常重要,因为不同的任务或场景可能需要不同水平的创造力、响应长度或停止条件。随着您对 OpenAI API 的了解越来越深入,您将能够有效地利用这些参数,以便根据您特定的网络安全任务和要求定制生成的内容。
使用文件进行提示和 API 密钥访问
在这个配方中,你将学习如何使用外部文本文件来存储和检索与 Python 通过 OpenAI API 进行交互的提示。这种方法允许更好的组织和更容易的维护,因为你可以快速更新提示而不需要修改主要脚本。我们还将介绍一种访问 OpenAI API 密钥的新方法 - 即使用文件 - 使更改 API 密钥的过程更加灵活。
准备工作
确保你能够访问 OpenAI API,并根据创建 API 密钥并与 OpenAI 进行交互和将 OpenAI API 密钥设置为环境变量配方进行了设置。
如何做…
这个配方演示了一个实用的管理提示和 API 密钥的方法,使得更新和维护你的代码更加容易。通过使用外部文本文件,你可以有效地管理项目并与他人合作。让我们一起来实施这种方法的步骤:
-
创建一个新的文本文件,并将其保存为
prompt.txt。在这个文件中写下你想要的提示,并保存。 -
修改你的 Python 脚本,以包含一个函数来读取文本文件的内容:
def open_file(filepath): with open(filepath, 'r', encoding='UTF-8') as infile: return infile.read() -
在使用 Python 发送 API 请求并处理响应配方中使用脚本,将硬编码的提示替换为调用
open_file函数,将prompt.txt文件的路径作为参数传递:prompt = open_file("prompt.txt") -
创建一个名为
prompt.txt的文件并输入以下提示文本(与使用 Python 发送 API 请求并处理响应配方中的提示相同):Explain the difference between symmetric and asymmetric encryption. -
使用文件而不是环境变量设置 API 密钥:
openai.api_key = open_file('openai-key.txt')
重要提示
很重要的一点是,将这行代码放在open_file函数之后;否则,Python 会因为调用尚未声明的函数而抛出错误。
-
创建一个名为
openai-key.txt的文件,并将你的OpenAI API 密钥粘贴到该文件中,而不包括其他内容。 -
在 API 调用中像往常一样使用提示变量。
这里是一个示例,展示了修改自使用 Python 发送 API 请求并处理响应配方的脚本会是什么样子:
import openai from openai import OpenAI def open_file(filepath): with open(filepath, 'r', encoding='UTF-8') as infile: return infile.read() client = OpenAI() def get_chat_gpt_response(prompt): response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": prompt}], max_tokens=2048, temperature=0.7 ) return response.choices[0].message.content.strip() openai.api_key = open_file('openai-key.txt') prompt = open_file("prompt.txt") response_text = get_chat_gpt_response(prompt) print(response_text)
工作原理…
open_file()函数接受一个文件路径作为参数,并使用with open语句打开文件。它读取文件的内容并将其作为字符串返回。然后,这个字符串被用作 API 调用的提示。第二个open_file()函数调用是用来访问一个包含 OpenAI API 密钥的文本文件,而不是使用环境变量来访问 API 密钥。
通过使用外部文本文件来存储提示和访问 API 密钥,你可以轻松更新或更改两者,而不需要修改主要脚本或环境变量。当你使用多个提示或与他人合作时,这一点尤其有帮助。
注意事项
使用此技术访问您的 API 密钥确实存在一定的风险。与环境变量相比,文本文件更容易被发现和访问,因此请确保采取必要的安全预防措施。重要的是要记住,在与他人分享脚本之前,从openapi-key.txt文件中删除您的 API 密钥,以防止对您的 OpenAI 账户进行无意或未经授权的扣费。
还有更多…
您还可以使用此方法存储您可能希望频繁更改或与他人分享的其他参数或配置。这可能包括 API 密钥、模型参数或与您的用例相关的任何其他设置。
使用提示变量(应用程序:手动页生成器)
在此示例中,我们将创建一个类似 Linux 风格的手动页生成器,它将接受用户输入,然后我们的脚本将生成手动页输出,类似于在 Linux 终端中输入man命令。通过这样做,我们将学习如何在文本文件中使用变量来创建一个标准的提示模板,可以通过修改其中的某些方面来轻松修改。当您希望使用用户输入或其他动态内容作为提示的一部分并保持一致的结构时,此方法特别有用。
准备工作
确保您通过登录到您的 OpenAI 账户并安装 Python 和openai模块来访问 ChatGPT API。
如何操作…
使用包含提示和占位符变量的文本文件,我们可以创建一个 Python 脚本,用于将占位符替换为用户输入。在本示例中,我们将使用此技术创建一个类似 Linux 风格的手动页生成器。以下是步骤:
-
创建一个 Python 脚本并导入必要的模块:
from openai import OpenAI -
定义一个函数来打开和读取文件:
def open_file(filepath): with open(filepath, 'r', encoding='UTF-8') as infile: return infile.read() -
设置您的 API 密钥:
openai.api_key = open_file('openai-key.txt') -
以与上一个步骤相同的方式创建
openai-key.txt文件。 -
定义
get_chat_gpt_response()函数,以将提示发送到 ChatGPT 并获取响应:client = OpenAI() def get_chat_gpt_response(prompt): response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": prompt}], max_tokens=600, temperature=0.7 ) text = response.choices[0].message.content.strip() return text -
接收文件名的用户输入并读取文件内容:
file = input("ManPageGPT> $ Enter the name of a tool: ") feed = open_file(file) -
用文件内容替换
prompt.txt文件中的<<INPUT>>变量:prompt = open_file("prompt.txt").replace('<<INPUT>>', feed) -
创建包含以下文本的
prompt.txt文件:Provide the manual-page output for the following tool. Provide the output exactly as it would appear in an actual Linux terminal and nothing else before or after the manual-page output. <<INPUT>> -
将修改后的提示发送到
get_chat_gpt_response()函数并打印结果:analysis = get_chat_gpt_response(prompt) print(analysis)这是完整脚本的示例:
import openai from openai import OpenAI def open_file(filepath): with open(filepath, 'r', encoding='UTF-8') as infile: return infile.read() openai.api_key = open_file('openai-key.txt') client = OpenAI() def get_chat_gpt_response(prompt): response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": prompt}], max_tokens=600, temperature=0.7 ) text = response['choices'][0]['message']['content'].strip() return text feed = input("ManPageGPT> $ Enter the name of a tool: ") prompt = open_file("prompt.txt").replace('<<INPUT>>', feed) analysis = get_chat_gpt_response(prompt) print(analysis)
工作原理…
在本示例中,我们创建了一个 Python 脚本,利用文本文件作为提示模板。文本文件包含一个名为<<INPUT>>的变量,可以替换为任何内容,允许动态修改提示而无需更改整体结构。特别是在这种情况下,我们将其替换为用户输入:
-
导入
openai模块以访问 ChatGPT API,并导入os模块以与操作系统进行交互并管理环境变量。 -
open_file()函数被定义为打开和读取文件。它接受文件路径作为参数,使用读取访问和 UTF-8 编码打开文件,读取内容,然后返回内容。 -
通过使用
open_file()函数从文件中读取 API 密钥,并将其分配给openai.api_key来设置访问 ChatGPT 的 API 密钥。 -
get_chat_gpt_response()函数被定义为向 ChatGPT 发送提示并返回响应。它接受提示作为参数,使用所需的设置配置 API 请求,然后将请求发送到 ChatGPT API。它提取响应文本,删除前导和尾随空白,并返回它。 -
脚本接收 Linux 命令的用户输入。此内容将用于替换提示模板中的占位符。
-
在
prompt.txt文件中的<<INPUT>>变量被用户提供的文件内容替换。这是使用 Python 的字符串replace()方法完成的,该方法搜索指定的占位符并用所需内容替换它。 -
man命令。 -
修改后的提示,带有
<<INPUT>>占位符替换,被发送到get_chat_gpt_response()函数。该函数将提示发送到 ChatGPT,ChatGPT 检索响应,脚本打印分析结果。这演示了如何使用带有可替换变量的提示模板,为不同输入创建定制的提示。
这种方法在网络安全环境中特别有用,因为它允许您为不同类型的分析或查询创建标准提示模板,并根据需要轻松修改输入数据。
还有更多…
-
在提示模板中使用多个变量:您可以在提示模板中使用多个变量,使其更加灵活多变。例如,您可以创建一个包含不同组件占位符的模板,用于网络安全分析,如 IP 地址、域名和用户代理。只需确保在发送提示到 ChatGPT 之前替换所有必要的变量。
-
<<INPUT>>格式,您可以自定义变量格式以更好地适应您的需求或偏好。例如,您可以使用花括号(例如,{input})或任何您认为更可读和可管理的格式。 -
open_file()函数读取环境变量而不是文件,确保敏感数据不会意外泄漏或暴露。 -
错误处理和输入验证:为了使脚本更加健壮,您可以添加错误处理和输入验证。这可以帮助您捕获常见问题,例如丢失或格式不正确的文件,并为用户提供清晰的错误消息以指导其纠正问题。
通过探索这些额外的技术,您可以为在您的网络安全项目中与 ChatGPT 一起使用创建更强大、灵活和安全的提示模板。
第二章:漏洞评估
建立在第一章建立的基本知识和技能的基础上,本章将探讨使用 ChatGPT 和 OpenAI API 来帮助和自动化许多漏洞评估任务。
在本章中,您将发现如何使用 ChatGPT 来创建漏洞和威胁评估计划,这是任何网络安全策略的重要组成部分。您将看到如何使用 OpenAI API 和 Python 自动化这些过程,特别是在需要处理众多网络配置或经常性计划需求的环境中,这将提供更高的效率。
此外,本章还将深入研究将 ChatGPT 与 MITRE ATT&CK 框架结合使用,该框架是一个全球可访问的对手战术和技术知识库。这种融合将使您能够生成详细的威胁报告,为威胁分析、攻击向量评估和威胁猎捕提供有价值的见解。
您将介绍生成预训练变换器(GPT)辅助漏洞扫描的概念。这种方法简化了漏洞扫描的一些复杂性,将自然语言请求转换为可以在命令行接口(CLIs)中执行的准确命令字符串。这种方法不仅节省时间,而且在执行漏洞扫描时增加了准确性和理解力。
最后,本章将解决分析大型漏洞评估报告的难题。使用 OpenAI API 与 LangChain 结合使用,LangChain 是一个旨在使语言模型能够帮助解决复杂任务的框架,您将看到如何处理和理解大型文档,尽管 ChatGPT 目前存在令牌限制。
在本章中,我们将介绍以下内容:
-
创建漏洞评估计划
-
使用 ChatGPT 和 MITRE ATT&CK 框架进行威胁评估
-
使用 GPT 辅助进行漏洞扫描
-
使用 LangChain 分析漏洞评估报告
技术要求
对于本章,您将需要一个稳定的网络浏览器和互联网连接来访问 ChatGPT 平台并设置您的账户。您还需要设置您的 OpenAI 账户并获得您的 API 密钥。如果没有,请查看第一章获取详细信息。由于您将使用Python 3.x来使用 OpenAI GPT API 和创建 Python 脚本,所以基本熟悉 Python 编程语言和工作命令行是必要的。一个代码编辑器也是编写和编辑 Python 代码和提示文件的必要工具,因为您将通过本章中的配方逐步完成这些工作。
本章的代码文件可以在此处找到:github.com/PacktPublishing/ChatGPT-for-Cybersecurity-Cookbook。
创建漏洞评估计划
在此食谱中,您将学习如何利用ChatGPT和OpenAI API来使用网络、系统和业务细节创建全面的漏洞评估计划。此食谱对于既有网络安全专业学生和初学者尤其有价值,他们希望熟悉漏洞评估的适当方法和工具,也适用于有经验的网络安全专业人员,以节省在计划和文件记录上的时间。
基于第一章中所学到的技能,您将深入了解专门从事漏洞评估的网络安全专业人员的系统角色建立。您将学习如何使用 Markdown 语言制作有效的提示,生成格式良好的输出。此食谱还将扩展第一章中探讨的*使用模板增强输出(应用:威胁报告)以及将输出格式化为表格(应用:安全控制表)*的技术,使您能够设计生成所需输出格式的提示。
最后,您将了解如何使用 OpenAI API 和Python来生成漏洞评估计划,然后将其导出为 Microsoft Word 文件。此食谱将作为一个实用指南,教您如何使用 ChatGPT 和 OpenAI API 创建详细、高效的漏洞评估计划。
准备就绪
在进行食谱之前,您应该已经设置好 OpenAI 账户并获得了 API 密钥。如果没有,可以返回第一章了解详情。您还需要确保已安装以下 Python 库:
-
python-docx:将使用此库生成 Microsoft Word 文件。您可以使用pip install python-docx命令安装它。 -
tqdm:将使用此库显示进度条。您可以使用pip install tqdm命令安装它。
怎么做…
在本节中,我们将指导您使用 ChatGPT 创建针对特定网络和组织需求定制的全面漏洞评估计划的过程。通过提供必要的细节,并使用给定的系统角色和提示,您将能够生成结构良好的评估计划:
-
首先登录到您的 ChatGPT 账户,然后导航到 ChatGPT Web UI。
-
单击新建 聊天按钮,与 ChatGPT 开始新对话。
-
输入以下提示以建立系统角色:
You are a cybersecurity professional specializing in vulnerability assessment. -
输入以下消息文本,但用
{ }括号中的适当数据替换占位符。您可以将此提示与系统角色结合使用,也可以分开输入,如下所示:Using cybersecurity industry standards and best practices, create a complete and detailed assessment plan (not a penetration test) that includes: Introduction, outline of the process/methodology, tools needed, and a very detailed multi-layered outline of the steps. Provide a thorough and descriptive introduction and as much detail and description as possible throughout the plan. The plan should not be the only assessment of technical vulnerabilities on systems but also policies, procedures, and compliance. It should include the use of scanning tools as well as configuration review, staff interviews, and site walk-around. All recommendations should follow industry standard best practices and methods. The plan should be a minimum of 1500 words. Create the plan so that it is specific for the following details: Network Size: {Large} Number of Nodes: {1000} Type of Devices: {Desktops, Laptops, Printers, Routers} Specific systems or devices that need to be excluded from the assessment: {None} Operating Systems: {Windows 10, MacOS, Linux} Network Topology: {Star} Access Controls: {Role-based access control} Previous Security Incidents: {3 incidents in the last year} Compliance Requirements: {HIPAA} Business Critical Assets: {Financial data, Personal health information} Data Classification: {Highly confidential} Goals and objectives of the vulnerability assessment: {To identify and prioritize potential vulnerabilities in the network and provide recommendations for remediation and risk mitigation.} Timeline for the vulnerability assessment: {4 weeks{ Team: {3 cybersecurity professionals, including a vulnerability assessment lead and two security analysts} Expected deliverables of the assessment: {A detailed report outlining the results of the vulnerability assessment, including identified vulnerabilities, their criticality, potential impact on the network, and recommendations for remediation and risk mitigation.} Audience: {The organization's IT department, senior management, and any external auditors or regulators.} Provide the plan using the following format and markdown language: #Vulnerability Assessment Plan ##Introduction Thorough Introduction to the plan including the scope, reasons for doing it, goals and objectives, and summary of the plan ##Process/Methodology Description and Outline of the process/Methodology ##Tools Required List of required tools and applications, with their descriptions and reasons needed ##Assessment Steps Detailed, multi-layered outline of the assessment steps
提示
如果您在OpenAI Playground中进行此操作,建议使用聊天模式,在系统窗口中输入角色,在用户 消息窗口中输入提示。
图 2*.1*展示了输入到OpenAI Playground的系统角色和用户提示:
图 2.1 - OpenAI Playground 方法
-
查看 ChatGPT 生成的输出。如果输出满意并符合要求,您可以进入下一步。如果不符合,您可以修改提示或重新运行对话以生成新的输出。
-
一旦您获得了期望的输出,您可以使用生成的 Markdown 在您喜欢的文本编辑器或 Markdown 查看器中创建一个结构良好的漏洞评估计划。
-
图 2*.2*展示了使用 Markdown 语言格式的 ChatGPT 生成的漏洞评估计划示例:

图 2.2 - ChatGPT 评估计划输出示例
工作原理…
这个 GPT 辅助的漏洞评估计划配方利用了自然语言处理(NLP)和机器学习(ML)算法的复杂性,以生成一个全面且详细的漏洞评估计划。通过采用特定的系统角色和详细的用户请求作为提示,ChatGPT 能够定制其响应以满足被委托评估广泛网络系统的资深网络安全专业人士的要求。
让我们更近距离地看看这个过程是如何运作的:
-
系统角色和详细提示:系统角色指定 ChatGPT 为专门从事漏洞评估的资深网络安全专业人员。提示作为用户请求,具体阐述了评估计划的细节,从网络规模和设备类型到所需的合规性和预期的可交付成果。这些输入提供了上下文并指导 ChatGPT 的响应,确保其定制到漏洞评估任务的复杂性和要求。
-
NLP 和 ML:NLP 和 ML 构成了 ChatGPT 能力的基础。它应用这些技术来理解用户请求的复杂性,从模式中学习,并生成一个详细、具体和可行的漏洞评估计划。
-
知识和语言理解能力:ChatGPT 利用其广泛的知识库和语言理解能力来遵循行业标准的方法和最佳实践。这在不断发展的网络安全领域尤为重要,确保生成的漏洞评估计划是最新的并符合公认的标准。
-
Markdown 语言输出:使用 Markdown 语言输出可以确保计划以一致且易于阅读的方式进行格式化。这种格式可以轻松地整合到报告、演示文稿和其他正式文件中,在将计划传达给 IT 部门、高级管理人员和外部审计员或监管机构时至关重要。
-
简化评估计划过程:使用这个 GPT 辅助的漏洞评估计划配方的整体优势在于它简化了创建全面漏洞评估计划的过程。您节省了规划和文档编制的时间,并可以生成符合行业标准并根据您组织特定需求定制的专业级评估计划。
通过应用这些详细的输入,您可以将 ChatGPT 转化为一个潜在的工具,以协助创建全面、定制的漏洞评估计划。这不仅增强了您的网络安全工作,还确保您有效利用资源来保护网络系统。
还有更多…
除了使用 ChatGPT 生成漏洞评估计划外,您还可以使用 OpenAI API 和 Python 来自动化该过程。当您需要评估大量网络配置或需要定期生成计划时,这种方法特别有用。
我们将在这里介绍的 Python 脚本从文本文件中读取输入数据,并将其用于填充提示中的占位符。然后,生成的 Markdown 输出可用于创建结构良好的漏洞评估计划。
虽然该过程与 ChatGPT 版本相似,但使用 OpenAI API 可以提供对生成内容的额外灵活性和控制。让我们深入了解 OpenAI API 版本的漏洞评估计划配方中涉及的步骤:
-
导入必要的库并设置 OpenAI API:
import openai from openai import OpenAI import os from docx import Document from tqdm import tqdm import threading import time from datetime import datetime # Set up the OpenAI API openai.api_key = os.getenv("OPENAI_API_KEY")在本部分中,我们导入必要的库,如
openai、os、docx、tqdm、threading、time和datetime。我们还通过提供 API 密钥来设置 OpenAI API。 -
从文本文件中读取用户输入数据:
def read_user_input_file(file_path: str) -> dict: user_data = {} with open(file_path, 'r') as file: for line in file: key, value = line.strip().split(':') user_data[key.strip()] = value.strip() return user_data user_data_file = "assessment_data.txt" user_data = read_user_input_file(user_data_file)在这里,我们定义了一个
read_user_input_file函数,用于从文本文件中读取用户输入数据并将其存储在字典中。然后,我们使用assessment_data.txt文件调用此功能以获得user_data字典。 -
使用 OpenAI API 生成漏洞评估计划:
重要提示
…'注释表示我们将在稍后的步骤中填写此代码部分。
def generate_report(network_size,
number_of_nodes,
type_of_devices,
special_devices,
operating_systems,
network_topology,
access_controls,
previous_security_incidents,
compliance_requirements,
business_critical_assets,
data_classification,
goals,
timeline,
team,
deliverables,
audience: str) -> str:
# Define the conversation messages
messages = [ ... ]
client = OpenAI()
# Call the OpenAI API
response = client.chat.completions.create( ... )
# Return the generated text
return response.choices[0].message.content.strip()
在此代码块中,我们定义了一个generate_report函数,该函数接受用户输入数据并调用 OpenAI API 来生成漏洞评估计划。该函数返回所生成的文本。
-
定义 API 消息:
# Define the conversation messages messages = [ {"role": "system", "content": "You are a cybersecurity professional specializing in vulnerability assessment."}, {"role": "user", "content": f'Using cybersecurity industry standards and best practices, create a complete and detailed assessment plan ... Detailed outline of the assessment steps'} ] client = OpenAI() # Call the OpenAI API response = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, max_tokens=2048, n=1, stop=None, temperature=0.7, ) # Return the generated text return return response.choices[0].message.content.strip()在对话消息中,我们定义了两个角色:
system和user。system角色用于为 AI 模型设置上下文,告知其是一位专门从事漏洞评估的网络安全专业人员。user角色为 AI 提供指令,包括基于行业标准、最佳实践和用户提供的数据生成详细的漏洞评估计划。system角色有助于为 AI 设置舞台,而user角色则指导 AI 进行内容生成。这种方法遵循我们之前讨论的 ChatGPT UI 部分类似的模式,在那里我们向 AI 提供了一个初始消息来设置上下文。欲了解有关发送 API 请求和处理响应的更多信息,请参阅 第一章 中的 使用 Python 发送 API 请求和处理响应 配方。该配方提供了与 OpenAI API 交互的更深入理解,包括如何构建请求和处理生成的内容。
-
将生成的 Markdown 文本转换为 Word 文档:
def markdown_to_docx(markdown_text: str, output_file: str): document = Document() # Iterate through the lines of the markdown text for line in markdown_text.split('\n'): # Add headings and paragraphs based on the markdown formatting ... # Save the Word document document.save(output_file)markdown_to_docx函数将生成的 Markdown 文本转换为 Word 文档。它遍历 Markdown 文本的各行,根据 Markdown 格式添加标题和段落,并保存生成的 Word 文档。 -
在等待 API 调用完成时显示经过时间:
def display_elapsed_time(): start_time = time.time() while not api_call_completed: elapsed_time = time.time() - start_time print(f"\rCommunicating with the API - Elapsed time: {elapsed_time:.2f} seconds", end="") time.sleep(1)display_elapsed_time函数用于在等待 API 调用完成时显示经过时间。它使用循环打印经过的秒数。 -
编写主函数:
current_datetime = datetime.now().strftime('%Y-%m-%d_%H-%M-%S') assessment_name = f"Vuln_ Assessment_Plan_{current_datetime}" api_call_completed = False elapsed_time_thread = threading.Thread(target=display_elapsed_time) elapsed_time_thread.start() try: # Generate the report using the OpenAI API report = generate_report( user_data["Network Size"], user_data["Number of Nodes"], user_data["Type of Devices"], user_data["Specific systems or devices that need to be excluded from the assessment"], user_data["Operating Systems"], user_data["Network Topology"], user_data["Access Controls"], user_data["Previous Security Incidents"], user_data["Compliance Requirements"], user_data["Business Critical Assets"], user_data["Data Classification"], user_data["Goals and objectives of the vulnerability assessment"], user_data["Timeline for the vulnerability assessment"], user_data["Team"], user_data["Expected deliverables of the assessment"], user_data["Audience"] ) api_call_completed = True elapsed_time_thread.join() except Exception as e: api_call_completed = True elapsed_time_thread.join() print(f"\nAn error occurred during the API call: {e}") exit() # Save the report as a Word document docx_output_file = f"{assessment_name}_report.docx" # Handle exceptions during the report generation try: with tqdm(total=1, desc="Generating plan") as pbar: markdown_to_docx(report, docx_output_file) pbar.update(1) print("\nPlan generated successfully!") except Exception as e: print(f"\nAn error occurred during the plan generation: {e}")在脚本的主要部分中,我们首先根据当前日期和时间定义一个
assessment_name函数。然后我们使用线程来显示调用 API 时的经过时间。脚本使用用户数据调用generate_report函数,并在成功完成后使用markdown_to_docx函数将生成的报告保存为 Word 文档。进度使用tqdm库进行显示。如果在 API 调用或报告生成过程中发生任何错误,它们将显示给用户。
提示
如果您是 ChatGPT Plus 订阅者,可以将 chat-3.5-turbo 模型替换为 GPT-4 模型,以获得通常改进的结果。事实上,GPT-4 能够生成更长更详细的生成和/或文档。只需记住,GPT-4 模型比 chat-3.5-turbo 模型稍微昂贵一些。
这是完成的脚本应该如何看起来:
import openai
from openai import OpenAI
import os
from docx import Document
from tqdm import tqdm
import threading
import time
from datetime import datetime
# Set up the OpenAI API
openai.api_key = os.getenv("OPENAI_API_KEY")
current_datetime = datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
assessment_name = f"Vuln_Assessment_Plan_{current_datetime}"
def read_user_input_file(file_path: str) -> dict:
user_data = {}
with open(file_path, 'r') as file:
for line in file:
key, value = line.strip().split(':')
user_data[key.strip()] = value.strip()
return user_data
user_data_file = "assessment_data.txt"
user_data = read_user_input_file(user_data_file)
# Function to generate a report using the OpenAI API
def generate_report(network_size,
number_of_nodes,
type_of_devices,
special_devices,
operating_systems,
network_topology,
access_controls,
previous_security_incidents,
compliance_requirements,
business_critical_assets,
data_classification,
goals,
timeline,
team,
deliverables,
audience: str) -> str:
# Define the conversation messages
messages = [
{"role": "system", "content": "You are a cybersecurity professional specializing in vulnerability assessment."},
{"role": "user", "content": f'Using cybersecurity industry standards and best practices, create a complete and detailed assessment plan (not a penetration test) that includes: Introduction, outline of the process/methodology, tools needed, and a very detailed multi-layered outline of the steps. Provide a thorough and descriptive introduction and as much detail and description as possible throughout the plan. The plan should not only assessment of technical vulnerabilities on systems but also policies, procedures, and compliance. It should include the use of scanning tools as well as configuration review, staff interviews, and site walk-around. All recommendations should follow industry standard best practices and methods. The plan should be a minimum of 1500 words.\n\
Create the plan so that it is specific for the following details:\n\
Network Size: {network_size}\n\
Number of Nodes: {number_of_nodes}\n\
Type of Devices: {type_of_devices}\n\
Specific systems or devices that need to be excluded from the assessment: {special_devices}\n\
Operating Systems: {operating_systems}\n\
Network Topology: {network_topology}\n\
Access Controls: {access_controls}\n\
Previous Security Incidents: {previous_security_incidents}\n\
Compliance Requirements: {compliance_requirements}\n\
Business Critical Assets: {business_critical_assets}\n\
Data Classification: {data_classification}\n\
Goals and objectives of the vulnerability assessment: {goals}\n\
Timeline for the vulnerability assessment: {timeline}\n\
Team: {team}\n\
Expected deliverables of the assessment: {deliverables}\n\
Audience: {audience}\n\
Provide the plan using the following format and observe the markdown language:\n\
#Vulnerability Assessment Plan\n\
##Introduction\n\
Introduction\n\
##Process/Methodology\n\
Outline of the process/Methodology\n\
##Tools Required\n\
List of required tools and applications\n\
##Assessment Steps\n\
Detailed outline of the assessment steps'}
]
client = OpenAI()
# Call the OpenAI API
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
max_tokens=2048,
n=1,
stop=None,
temperature=0.7,
)
# Return the generated text
return response.choices[0].message.content.strip()
# Function to convert markdown text to a Word document
def markdown_to_docx(markdown_text: str, output_file: str):
document = Document()
# Iterate through the lines of the markdown text
for line in markdown_text.split('\n'):
# Add headings based on the markdown heading levels
if line.startswith('# '):
document.add_heading(line[2:], level=1)
elif line.startswith('## '):
document.add_heading(line[3:], level=2)
elif line.startswith('### '):
document.add_heading(line[4:], level=3)
elif line.startswith('#### '):
document.add_heading(line[5:], level=4)
# Add paragraphs for other text
else:
document.add_paragraph(line)
# Save the Word document
document.save(output_file)
# Function to display elapsed time while waiting for the API call
def display_elapsed_time():
start_time = time.time()
while not api_call_completed:
elapsed_time = time.time() - start_time
print(f"\rCommunicating with the API - Elapsed time: {elapsed_time:.2f} seconds", end="")
time.sleep(1)
api_call_completed = False
elapsed_time_thread = threading.Thread(target=display_elapsed_time)
elapsed_time_thread.start()
# Handle exceptions during the API call
try:
# Generate the report using the OpenAI API
report = generate_report(
user_data["Network Size"],
user_data["Number of Nodes"],
user_data["Type of Devices"],
user_data["Specific systems or devices that need to be excluded from the assessment"],
user_data["Operating Systems"],
user_data["Network Topology"],
user_data["Access Controls"],
user_data["Previous Security Incidents"],
user_data["Compliance Requirements"],
user_data["Business Critical Assets"],
user_data["Data Classification"],
user_data["Goals and objectives of the vulnerability assessment"],
user_data["Timeline for the vulnerability assessment"],
user_data["Team"],
user_data["Expected deliverables of the assessment"],
user_data["Audience"]
)
api_call_completed = True
elapsed_time_thread.join()
except Exception as e:
api_call_completed = True
elapsed_time_thread.join()
print(f"\nAn error occurred during the API call: {e}")
exit()
# Save the report as a Word document
docx_output_file = f"{assessment_name}_report.docx"
# Handle exceptions during the report generation
try:
with tqdm(total=1, desc="Generating plan") as pbar:
markdown_to_docx(report, docx_output_file)
pbar.update(1)
print("\nPlan generated successfully!")
except Exception as e:
print(f"\nAn error occurred during the plan generation: {e}")
此脚本通过结合使用 OpenAI API 和 Python 自动化生成漏洞评估计划的流程。它首先导入必要的库并设置 OpenAI API。然后从文本文件中读取用户输入数据(文件路径存储为 user_data_file 字符串),然后将此数据存储在字典中以便轻松访问。
脚本的核心是生成漏洞评估计划的函数。它利用 OpenAI API 基于用户输入数据创建详细报告。与 API 的对话以 system 和 user 角色的格式进行,以有效地指导生成过程。
一旦报告生成,它就会从 Markdown 文本转换为 Word 文档,提供结构良好、易读的输出。为了在过程中提供用户反馈,脚本包括一个在进行 API 调用时显示经过时间的函数。
最后,脚本的主函数将所有内容联系在一起。它启动使用 OpenAI API 生成报告的过程,在 API 调用期间显示经过时间,并最终将生成的报告转换为 Word 文档。如果在 API 调用或文档生成过程中发生任何错误,都会进行处理并向用户显示。
使用 ChatGPT 和 MITRE ATT&CK 框架进行威胁评估
在这个步骤中,你将学习如何利用ChatGPT和OpenAI API来通过提供威胁、攻击或活动名称进行威胁评估。通过将 ChatGPT 的能力与MITRE ATT&CK框架相结合,你将能够生成详细的威胁报告、战术、技术和程序(TTPs)映射,以及相关的威胁指标(IoCs)。这些信息将使网络安全专业人员能够分析其环境中的攻击向量,并将其能力扩展到威胁猎捕。
基于在第一章中获得的技能,本步骤将引导你建立网络安全分析员的系统角色,并设计能够生成格式良好的输出(包括表格)的有效提示。你将学习如何设计提示以从 ChatGPT 中获取所需的输出,包括使用 ChatGPT Web UI 和 Python 脚本。此外,你还将学习如何使用 OpenAI API 生成 Microsoft Word 文件格式的综合威胁报告。
准备工作
在着手执行该步骤之前,你应该已经设置好了你的 OpenAI 账户并获取了你的 API 密钥。如果没有,请返回第一章查看详情。你还需要执行以下操作:
-
请确保在你的 Python 环境中安装了
python-docx库,因为它将用于生成 Microsoft Word 文件。你可以使用pip installpython-docx命令来安装它。 -
熟悉 MITRE ATT&CK 框架:要充分利用这个步骤,了解 MITRE ATT&CK 框架的基本知识是有帮助的。访问
attack.mitre.org/获取更多信息和资源。 -
列举样本威胁:准备一个示例威胁名称、攻击活动或对手组织的列表,以便在执行该步骤时作为示例使用。
如何操作…
通过遵循以下步骤,您可以成功地利用 ChatGPT 利用 MITRE ATT&CK 框架和适当的 Markdown 格式生成基于 TTP 的威胁报告。我们将指定威胁的名称并应用提示工程技术。然后,ChatGPT 将生成一个格式良好的报告,其中包含有价值的见解,可帮助您进行威胁分析、攻击向量评估,甚至为威胁猎杀收集 IoC:
-
登录到您的 ChatGPT 帐户并导航到 ChatGPT web UI。
-
点击新对话按钮与 ChatGPT 开启新的对话。
-
输入以下提示以建立一个系统角色:
You are a professional cyber threat analyst and MITRE ATT&CK Framework expert. -
在下面的用户提示中用您选择的威胁名称(在我们的示例中,我们将使用WannaCry)替换
{threat_name}。您可以将此提示与系统角色结合使用,也可以单独输入它:Provide a detailed report about {threat_name}, using the following template (and proper markdown language formatting, headings, bold keywords, tables, etc.): Threat Name (Heading 1) Summary (Heading 2) Short executive summary Details (Heading 2) Description and details including history/background, discovery, characteristics and TTPs, known incidents MITRE ATT&CK TTPs (Heading 2) Table containing all of the known MITRE ATT&CK TTPs that the {threat_name} attack uses. Include the following columns: Tactic, Technique ID, Technique Name, Procedure (How WannaCry uses it) Indicators of Compromise (Heading 2) Table containing all of the known indicators of compromise. Include the following columns: Type, Value, Description
提示
就像之前的配方一样,您可以在 OpenAI Playground 中执行此操作,并使用 Chat mode 输入在 System 窗口中的角色,并在 User message 窗口中输入提示。
图 2*.3* 显示了输入到 OpenAI Playground 的系统角色和用户提示:
图 2.3 – OpenAI Playground 方法
-
输入适当的系统角色和用户提示后,按 Enter。
-
ChatGPT 将处理提示并生成带有 Markdown 语言格式、标题、粗体关键字、表格和其他指定提示中的元素的格式化威胁报告。
图 2*.4* 和 图 2*.5* 用 Markdown 语言格式化的表格显示了 ChatGPT 生成威胁报告的示例:

图 2.4 – ChatGPT 威胁报告叙述输出
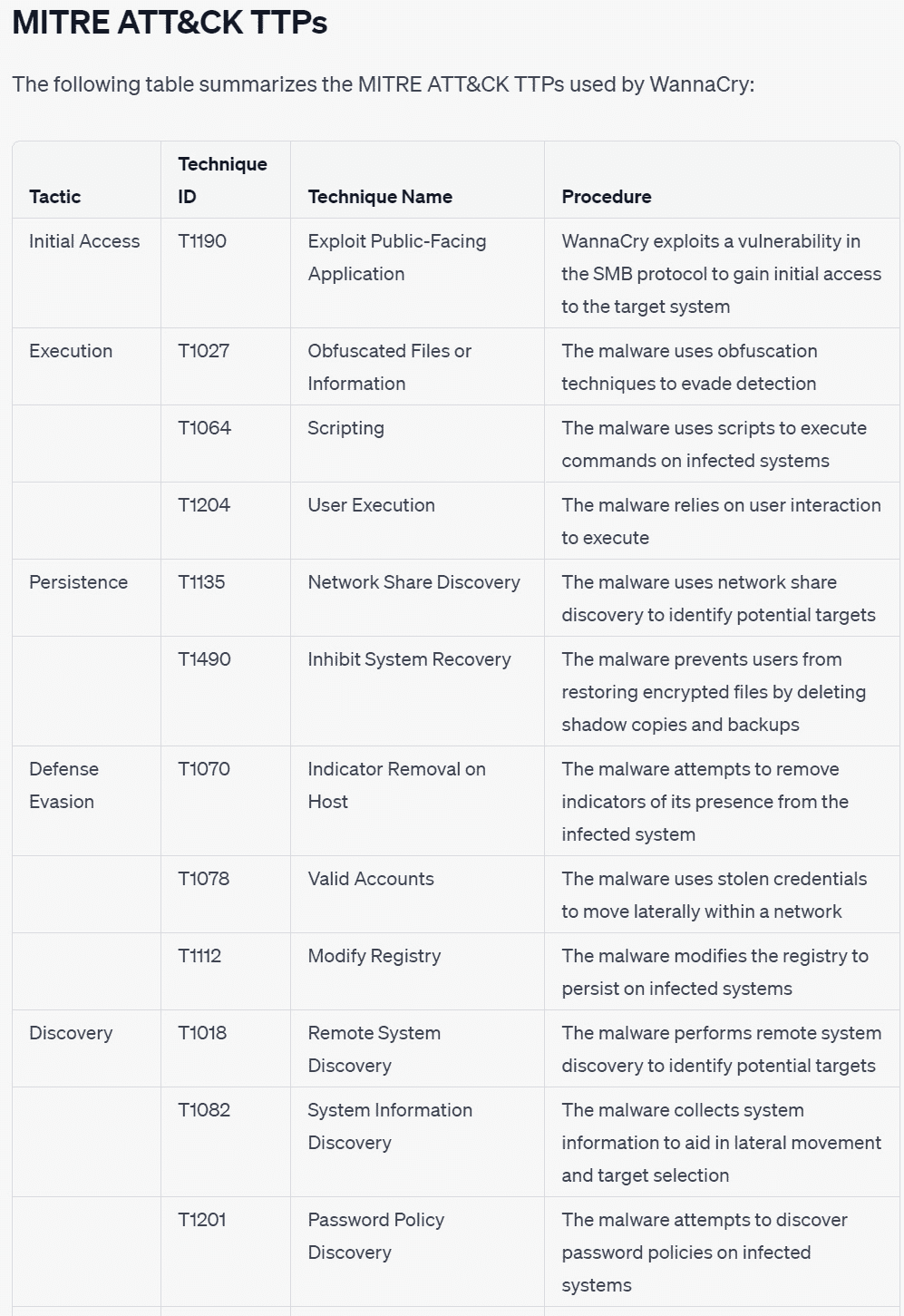
图 2.5 – ChatGPT 威胁报告表输出
- 查看生成的报告,确保其包含所需的信息和格式。如有必要,调整您的用户提示并重新提交以改善输出。
提示
有时,ChatGPT 在生成完整输出之前会停止生成。这是由于所使用的模型的令牌限制造成的。在这种情况下,您可以点击继续生成按钮。
工作原理…
正如我们在应用 ChatGPT 角色(应用:AI CISO)配方中所做的那样第一章,当您为 ChatGPT 分配一个角色时,您为模型提供一个特定的上下文或角色。这有助于模型生成与所分配角色相匹配的响应,从而产生更准确、相关和详细的内容。模型将生成与所分配角色的专业知识和观点相一致的内容,提供更好的见解、意见或建议。
当我们提供威胁名称并指示 ChatGPT 引用 MITRE ATT&CK 框架时,我们能够利用其庞大的数据集,其中包括关于威胁和 MITRE ATT&CK 框架的详细信息。因此,它能够将两者相关联,并快速为我们提供与框架中识别的 TTP 相关的威胁信息。
重要提示
当使用当前版本的 ChatGPT 和 OpenAI API 至本文撰写时,数据集仅训练至 2021 年 9 月。因此,它不会了解此后的任何威胁数据。但是,本书后面会介绍如何使用 API 和 Python 将最新数据输入到请求中的技术。
通过在提示中提供清晰的输出模板,你可以引导 ChatGPT 生成符合指定结构和格式的响应。这有助于确保生成的内容一致、组织良好,并适合用于报告、演示文稿或其他正式文件中。模型将专注于生成符合你提供的格式和结构的内容,同时仍然提供你请求的信息。有关更多详细信息,请参阅第一章中的 使用模板增强输出(应用:威胁报告) 和 将输出格式化为表格(应用:安全控制表) 小节。
还有更多内容…
通过使用 Python 脚本结合 OpenAI API 生成威胁报告,你可以扩展此方法的能力和灵活性,类似于在 ChatGPT web UI 中创建的报告。以下是操作步骤:
-
从导入所需库开始:
import openai from openai import OpenAI import os from docx import Document from tqdm import tqdm import threading import time -
在第一章的将 OpenAI API 密钥设置为环境变量小节中,设置 OpenAI API,方法与我们之前相同:
openai.api_key = os.getenv("OPENAI_API_KEY") -
创建一个使用 OpenAI API 生成报告的函数:
def generate_report(threat_name: str) -> str: ... return response['choices'][0]['message']['content'].strip()此函数以威胁名称作为输入,并将其作为提示的一部分发送到 OpenAI API。它返回 API 响应中生成的文本。
-
创建一个函数来将生成的 Markdown 格式文本转换为 Microsoft Word 文档:
def markdown_to_docx(markdown_text: str, output_file: str): ... document.save(output_file)此函数接受 Markdown 格式的生成文本和输出文件名作为参数。它解析 Markdown 文本并创建具有适当格式的 Word 文档。
-
创建一个函数来从 Markdown 文本中提取表格:
def extract_tables(markdown_text: str): ... return tables此函数迭代 Markdown 文本并提取其中找到的任何表格。
-
创建一个函数来显示等待 API 调用的经过时间:
def display_elapsed_time(): ...此函数在等待 API 调用完成时显示经过的秒数。
-
从用户输入中获取威胁名称:
threat_name = input("Enter the name of a cyber threat: ") -
启动一个单独的线程来显示进行 API 调用时经过的时间:
api_call_completed = False elapsed_time_thread = threading.Thread(target=display_elapsed_time) elapsed_time_thread.start() -
进行 API 调用并处理异常:
try: report = generate_report(threat_name) api_call_completed = True elapsed_time_thread.join() except Exception as e: ... -
将生成的报告保存为 Word 文档:
docx_output_file = f"{threat_name}_report.docx" -
生成报告并处理异常:
try: with tqdm(total=1, desc="Generating report and files") as pbar: markdown_to_docx(report, docx_output_file) print("\nReport and tables generated successfully!") except Exception as e: ...
这是完成的脚本应该看起来的样子:
import openai
from openai import OpenAI
import os
from docx import Document
from tqdm import tqdm
import threading
import time
# Set up the OpenAI API
openai.api_key = os.getenv("OPENAI_API_KEY")
# Function to generate a report using the OpenAI API
def generate_report(threat_name: str) -> str:
# Define the conversation messages
messages = [
{"role": "system", "content": "You are a professional cyber threat analyst and MITRE ATT&CK Framework expert."},
{"role": "user", "content": f'Provide a detailed report about {threat_name}, using the following template (and proper markdown language formatting, headings, bold keywords, tables, etc.):\n\n\
Threat Name (Heading 1)\n\n\
Summary (Heading 2)\n\
Short executive summary\n\n\
Details (Heading 2)\n\
Description and details including history/background, discovery, characteristics and TTPs, known incidents\n\n\
MITRE ATT&CK TTPs (Heading 2)\n\
Table containing all of the known MITRE ATT&CK TTPs that the {threat_name} attack uses. Include the following columns: Tactic, Technique ID, Technique Name, Procedure (How {threat_name} uses it)\n\n\
Indicators of Compromise (Heading 2)\n\
Table containing all of the known indicators of compromise. Include the following collumns: Type, Value, Description\n\n\ '}
]
client = OpenAI()
# Call the OpenAI API
response = client.chat.completions.create
model="gpt-3.5-turbo",
messages=messages,
max_tokens=2048,
n=1,
stop=None,
temperature=0.7,
)
# Return the generated text
return response.choices[0].message.content.strip()
# Function to convert markdown text to a Word document
def markdown_to_docx(markdown_text: str, output_file: str):
document = Document()
# Variables to keep track of the current table
table = None
in_table = False
# Iterate through the lines of the markdown text
for line in markdown_text.split('\n'):
# Add headings based on the markdown heading levels
if line.startswith('# '):
document.add_heading(line[2:], level=1)
elif line.startswith('## '):
document.add_heading(line[3:], level=2)
elif line.startswith('### '):
document.add_heading(line[4:], level=3)
elif line.startswith('#### '):
document.add_heading(line[5:], level=4)
# Handle tables in the markdown text
elif line.startswith('|'):
row = [cell.strip() for cell in line.split('|')[1:-1]]
if not in_table:
in_table = True
table = document.add_table(rows=1, cols=len(row), style='Table Grid')
for i, cell in enumerate(row):
table.cell(0, i).text = cell
else:
if len(row) != len(table.columns): # If row length doesn't match table, it's a separator
continue
new_row = table.add_row()
for i, cell in enumerate(row):
new_row.cells[i].text = cell
# Add paragraphs for other text
else:
if in_table:
in_table = False
table = None
document.add_paragraph(line)
# Save the Word document
document.save(output_file)
# Function to extract tables from the markdown text
def extract_tables(markdown_text: str):
tables = []
current_table = []
# Iterate through the lines of the markdown text
for line in markdown_text.split('\n'):
# Check if the line is part of a table
if line.startswith('|'):
current_table.append(line)
# If the table ends, save it to the tables list
elif current_table:
tables.append('\n'.join(current_table))
current_table = []
return tables
# Function to display elapsed time while waiting for the API call
def display_elapsed_time():
start_time = time.time()
while not api_call_completed:
elapsed_time = time.time() - start_time
print(f"\rCommunicating with the API - Elapsed time: {elapsed_time:.2f} seconds", end="")
time.sleep(1)
# Get user input
threat_name = input("Enter the name of a cyber threat: ")
api_call_completed = False
elapsed_time_thread = threading.Thread(target=display_elapsed_time)
elapsed_time_thread.start()
# Handle exceptions during the API call
try:
# Generate the report using the OpenAI API
report = generate_report(threat_name)
api_call_completed = True
elapsed_time_thread.join()
except Exception as e:
api_call_completed = True
elapsed_time_thread.join()
print(f"\nAn error occurred during the API call: {e}")
exit()
# Save the report as a Word document
docx_output_file = f"{threat_name}_report.docx"
# Handle exceptions during the report generation
try:
with tqdm(total=1, desc="Generating report and files") as pbar:
markdown_to_docx(report, docx_output_file)
print("\nReport and tables generated successfully!")
except Exception as e:
print(f"\nAn error occurred during the report generation: {e}")
此脚本使用OpenAI API生成网络威胁报告,格式为Microsoft Word 文档。
此脚本的关键在于几个关键函数。第一个函数,generate_report(),接收一个网络威胁名称,并将其用作 OpenAI API 的提示。它返回 API 响应中生成的文本。此文本采用 Markdown 格式,然后由markdown_to_docx()函数转换为 Microsoft Word 文档。
此函数逐行解析 Markdown 文本,根据需要创建表格和标题,最终将其保存为 Word 文档。同时,还有一个extract_tables()函数,用于定位和提取 Markdown 文本中的任何表格。
为了增强用户体验,display_elapsed_time()函数被整合进来。此函数跟踪并显示 API 调用完成所花费的时间。在进行 API 调用之前,它在一个单独的线程中运行:

图 2.6 – display_elapsed_time 函数示例输出
API 调用本身以及报告生成都包含在try-except块中,以处理任何潜在的异常。一旦报告生成完成,它将以用户输入的网络威胁名称为基础的文件名保存为 Word 文档。
执行此脚本成功后,将生成一个详细的威胁报告,格式为 Word 文档,模仿 ChatGPT Web UI 生成的输出。这个示例展示了如何在 Python 脚本中使用 OpenAI API,自动化生成综合报告的过程。
提示
如果您是 ChatGPT Plus 的订阅用户,可以将chat-3.5-turbo模型替换为GPT-4模型,通常会获得更好的结果。只需记住,GPT-4 模型比 chat-3.5-turbo 模型稍微昂贵一些。
通过降低temperature值,还可以提高准确性并获得更一致的输出。
ChatGPT 辅助漏洞扫描
漏洞扫描在识别和消除漏洞之前被恶意行为者利用的过程中起着至关重要的作用。我们用于进行这些扫描的工具,如NMAP、OpenVAS或Nessus,提供了强大的功能,但通常会复杂且难以导航,特别是对于新手或不熟悉其高级选项的人来说。
这就是我们示例发挥作用的地方。它利用 ChatGPT 的功能简化了根据用户输入为这些工具生成命令字符串的过程。通过此示例,您将能够创建精确的命令字符串,可以直接复制并粘贴到 CLI 中以启动漏洞扫描,前提是已安装了相应的工具。
这个配方不仅仅是为了节省时间;它还能增强准确性、理解力和效果。这对于学习漏洞评估、对这些工具尚不熟悉的人以及需要快速参考以确保命令选项正确的经验丰富的专业人士都是有益的。当涉及到高级选项时,例如解析输出或将结果输出到文件或其他格式时,这非常有用。
在完成这个配方时,您将能够为 NMAP、OpenVAS 或 Nessus 生成精确的命令字符串,帮助您轻松自信地使用它们的功能。无论您是网络安全初学者还是经验丰富的专家,这个配方都将成为您漏洞评估工具库中宝贵的工具。
准备就绪
在开始这个配方之前,确保您已经正确设置了您的 OpenAI 账户并获得了您的 API 密钥是很重要的。如果还没有完成这一步,您可以查看第一章中的详细说明。另外,您将需要以下内容:
-
漏洞扫描工具:对于这些特定工具而言,安装 NMAP、OpenVAS 或 Nessus 非常重要,因为该配方生成针对这些特定工具的命令字符串。请参考它们的官方文档以获取安装和设置指南。
-
基本工具的理解:您对 NMAP、OpenVAS 或 Nessus 越熟悉,就越能够更好地利用这个配方。如果您对这些工具还不熟悉,考虑花些时间了解它们的基本功能和命令行选项。
-
命令行环境:由于该配方生成供 CLI 使用的命令字符串,您应该能够访问一个适合的命令行环境,您可以在其中运行这些命令。这可以是 Unix/Linux 系统中的终端,也可以是 Windows 中的命令提示符或 PowerShell。
-
样本网络配置数据:准备一些样本网络数据,供漏洞扫描工具使用。这可能包括 IP 地址、主机名或关于您想要扫描的系统的其他相关信息。
如何做…
在这个配方中,我们将向您展示如何使用 ChatGPT 创建用于漏洞扫描工具(如 NMAP、OpenVAS 和 Nessus)的命令字符串。我们将向 ChatGPT 提供必要的细节,并使用特定的系统角色和提示。这将使您能够生成完成您请求所需的命令的最简单形式:
-
首先登录到您的 OpenAI 帐户,然后转到 ChatGPT Web UI。
-
通过点击New chat按钮开始与 ChatGPT 进行新的对话。
-
接下来,通过输入以下内容来确定系统的角色:
You are a professional cybersecurity red team specialist and an expert in penetration testing as well as vulnerability scanning tools such as NMap, OpenVAS, Nessus, Burpsuite, Metasploit, and more.
重要说明
就像在创建漏洞评估计划配方中一样,您可以在OpenAI Playground中单独输入角色,或者将其合并为 ChatGPT 中的单个提示。
-
现在,准备好您的请求。这是将在下一步中替换
{user_input}占位符的信息。它应该是一个自然语言请求,例如以下内容:Use the command line version of OpenVAS to scan my 192.168.20.0 class C network starting by identifying hosts that are up, then look for running web servers, and then perform a vulnerability scan of those web servers. -
一旦您的请求准备好了,请输入以下消息文本,用前一步中的具体请求替换
{user_input}占位符:Provide me with the Linux command necessary to complete the following request: {user_input} Assume I have all the necessary apps, tools, and commands necessary to complete the request. Provide me with the command only and do not generate anything further. Do not provide any explanation. Provide the simplest form of the command possible unless I ask for special options, considerations, output, etc. If the request does require a compound command provide all necessary operators, pipes, etc. as a single one-line command. Do not provide me with more than one variation or more than one line.然后,ChatGPT 将根据您的请求生成命令字符串。审查输出。如果符合您的要求,您可以继续复制命令并根据需要使用它。如果不符合,您可能需要优化您的请求并重试。
一旦您获得了满意的命令,您可以直接将其复制并粘贴到命令行中,以执行您请求中描述的漏洞扫描。
重要提示
记住——在您的环境中运行任何命令之前,审查和理解任何命令都是很重要的。虽然 ChatGPT 的目标是提供准确的命令,但最终您负责确保命令在您的具体环境中的安全性和适用性。
图 2*.7*显示了从本配方中使用的提示生成的 ChatGPT 命令的示例:

图 2.7 – ChatGPT 命令生成示例
工作原理…
GPT 辅助的漏洞扫描配方利用了 NLP 的力量和 ML 算法的广泛知识,生成准确和适当的命令字符串,用于漏洞扫描工具,如 NMAP、OpenVAS 和 Nessus。当您提供了一个特定的系统角色和一个代表用户请求的提示时,ChatGPT 使用这些输入来理解上下文,并生成与给定角色一致的响应:
-
系统角色定义:通过将 ChatGPT 的角色定义为专业的网络安全红队专家和渗透测试和漏洞扫描工具方面的专家,您指示模型从深度技术理解和专业知识的角度来回答。这种背景有助于生成准确和相关的命令字符串。
-
自然语言提示:模拟用户请求的自然语言提示使 ChatGPT 能够以类似人类的方式理解手头的任务。与需要结构化数据或特定关键字不同,ChatGPT 可以像人类一样解释请求,并提供合适的响应。
-
命令生成:有了角色和提示,ChatGPT 生成完成请求所需的 Linux 命令。该命令基于用户输入的具体细节和所分配角色的专业知识。这是 AI 利用其对网络安全和语言理解的知识构建必要命令字符串的地方。
-
一行命令:规定提供一行命令,包括所有必要的运算符和管道,促使 ChatGPT 生成一个可立即粘贴到命令行中进行执行的命令。这消除了用户手动组合或修改命令的需要,节省了时间和可能的错误。
-
简单和清晰:只需请求命令的最简单形式,而无需进一步解释,输出就保持了清晰简洁,这对于那些在学习或需要快速参考的人来说特别有帮助。
总而言之,GPT 辅助的漏洞扫描配方利用了自然语言处理和机器学习算法的力量,生成精确的、可立即运行的漏洞扫描命令。通过使用定义的系统角色和提示,用户可以简化漏洞评估命令的制作过程,节省时间,并提高准确性。
还有更多…
这个由 GPT 辅助的流程的灵活性和功能远远超出了给出的示例。首先是提示的多功能性。它实际上旨在适应几乎任何对任何 Linux 命令的请求,跨越任何领域或任务。这是一个重大优势,因为它使您能够在各种场景下利用 ChatGPT 的能力。通过适当地分配角色,比如 "您是一名 Linux 系统管理员",并将您的具体请求替换为 {user_input},您可以引导 AI 生成准确和特定上下文的命令字符串,用于大量的 Linux 操作。
除了简单地生成命令字符串之外,当与 OpenAI API 和 Python 结合使用时,这个配方的潜力得到了增强。通过正确设置,您不仅可以生成必要的 Linux 命令,还可以自动执行这些命令。基本上,这可以将 ChatGPT 变成您命令行操作的积极参与者,潜在地为您节省大量的时间和精力。这种程度的自动化代表了与 AI 模型交互的实质性进步,将它们转变为积极的助手而不是被动的信息生成器。
在本书的后续配方中,我们将更深入地探讨命令自动化。这只是 AI 与您的操作系统任务集成所开启的可能性的开始。
使用 LangChain 分析漏洞评估报告
尽管 ChatGPT 和 OpenAI API 非常强大,但它们目前有一个重大的限制—令牌窗口。这个窗口决定了用户和 ChatGPT 之间在完整消息中可以交换多少个字符。一旦令牌数量超出此限制,ChatGPT 可能会丢失原始上下文,使得分析大量文本或文档变得具有挑战性。
进入 LangChain—一个旨在绕过这个障碍的框架。LangChain 允许我们嵌入和向量化大量文本。
重要提示
嵌入指的是将文本转换为机器学习模型可以理解和处理的数字向量的过程。向量化,另一方面,是一种将非数字特征编码为数字的技术。通过将大量文本转换为向量,我们可以使 ChatGPT 能够访问和分析大量信息,从而有效地将文本转化为模型可以参考的知识库,即使该模型之前并没有在这些数据上进行训练。
在这个示例中,我们将利用 LangChain、Python、OpenAI API 和Streamlit(一个快速轻松创建 Web 应用程序的框架)的功能来分析大量文档,例如漏洞评估报告、威胁报告、标准等。通过一个简单的 UI 来上传文件和制作提示,分析这些文档的任务将简化到向 ChatGPT 直接提出简单的自然语言查询的程度。
准备开始
在开始本示例之前,请确保您已经设置了 OpenAI 账户并获得了 API 密钥。如果还没有完成此步骤,请返回第一章获取步骤。除此之外,您还需要以下内容:
-
python-docx、langchain、streamlit和openai。您可以使用以下命令pip install安装这些软件:pip install python-docx langchain streamlit openai -
漏洞评估报告(或您选择的大型文档进行分析):准备一个漏洞评估报告或其他重要文档,您打算对其进行分析。只要可以将其转换为PDF格式,该文档可以采用任何格式。
-
获取 LangChain 文档:在本示例中,我们将使用 LangChain,这是一个相对较新的框架。虽然我们会带您了解整个过程,但随手准备 LangChain 文档可能会有所益处。您可以在
docs.langchain.com/docs/获取它。 -
Streamlit:我们将使用 Streamlit,这是一种快速简单的方法来为 Python 脚本创建 Web 应用程序。尽管在本示例中我们将引导您了解其基础知识,但您可能希望自行探索。您可以在
streamlit.io/了解更多关于 Streamlit 的信息。
如何做…
在这个示例中,我们将带您了解如何使用 LangChain、Streamlit、OpenAI 和 Python 创建一个文档分析器。该应用程序允许您上传 PDF 文档,用自然语言提出相关问题,并根据文档内容生成语言模型的响应:
-
使用
dotenv加载环境变量,streamlit创建 Web 界面,PyPDF2读取 PDF 文件,以及来自langchain的各种组件来处理语言模型和文本处理:import streamlit as st from PyPDF2 import PdfReader from langchain.text_splitter import CharacterTextSplitter from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import FAISS from langchain.chains.question_answering import load_qa_chain from langchain.llms import OpenAI from langchain.callbacks import get_openai_callback -
"文档分析器"和"您想了解这个文档的什么情况?"的标题文本提示:def main(): st.set_page_config(page_title="Document Analyzer") st.header("What would you like to know about this document?") -
上传 PDF:向 Streamlit 应用程序添加文件上传器,以允许用户上传 PDF 文档:
pdf = st.file_uploader("Upload your PDF", type="pdf") -
从 PDF 中提取文本:如果上传了 PDF,读取 PDF 并从中提取文本:
if pdf is not None: pdf_reader = PdfReader(pdf) text = "" for page in pdf_reader.pages: text += page.extract_text() -
将文本分割成块: 将提取的文本分解为可由语言模型处理的可管理块:
text_splitter = CharacterTextSplitter( separator="\n", chunk_size=1000, chunk_overlap=200, length_function=len ) chunks = text_splitter.split_text(text) if not chunks: st.write("No text chunks were extracted from the PDF.") return -
使用
OpenAIEmbeddings来创建对块的向量表示:embeddings = OpenAIEmbeddings() if not embeddings: st.write("No embeddings found.") return knowledge_base = FAISS.from_texts(chunks, embeddings) -
关于 PDF 提问:在 Streamlit 应用程序中显示一个文本输入字段,用户可以就上传的 PDF 提问:
user_question = st.text_input("Ask a question about your PDF:") -
生成响应: 如果用户提问,找到与问题语义相似的块,将这些块输入语言模型,并生成响应:
if user_question: docs = knowledge_base.similarity_search(user_question) llm = OpenAI() chain = load_qa_chain(llm, chain_type="stuff") with get_openai_callback() -
使用 Streamlit 运行脚本。从与脚本相同的目录中使用命令行终端,运行以下命令:
localhost using a web browser.
这就是完成脚本应该是什么样子的:
import streamlit as st
from PyPDF2 import PdfReader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
def main():
st.set_page_config(page_title="Ask your PDF")
st.header("Ask your PDF")
# upload file
pdf = st.file_uploader("Upload your PDF", type="pdf")
# extract the text
if pdf is not None:
pdf_reader = PdfReader(pdf)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
# split into chunks
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
if not chunks:
st.write("No text chunks were extracted from the PDF.")
return
# create embeddings
embeddings = OpenAIEmbeddings()
if not embeddings:
st.write("No embeddings found.")
return
knowledge_base = FAISS.from_texts(chunks, embeddings)
# show user input
user_question = st.text_input("Ask a question about your PDF:")
if user_question:
docs = knowledge_base.similarity_search(user_question)
llm = OpenAI()
chain = load_qa_chain(llm, chain_type="stuff")
with get_openai_callback() as cb:
response = chain.run(input_documents=docs, question=user_question)
print(cb)
st.write(response)
if __name__ == '__main__':
main()
该脚本主要是利用 LangChain 框架、Python 和 OpenAI 自动化分析大型文档,比如漏洞评估报告。它利用 Streamlit 创建直观的网络界面,用户可以上传 PDF 文件进行分析。
上传的文档经历了一系列操作:它被读取并提取文本,然后分成可管理的块。这些块使用 OpenAI Embeddings 转换成向量表示(嵌入),使语言模型能够语义解释和处理文本。这些嵌入被存储在数据库(Facebook AI Similarity Search)中,便于高效的相似度搜索。
然后,该脚本为用户提供一个界面,可以就上传的文档提问。收到问题后,它从数据库中识别最语义相关的文本块来回答问题。这些块以及用户的问题由 LangChain 中的问答链处理,生成的响应会显示给用户。
本质上,此脚本将大型的非结构化文档转换为交互式知识库,使用户能够提出问题,并根据文档内容接收 AI 生成的响应。
运行原理…
-
首先,导入必要的模块。包括用于加载环境变量的
dotenv模块,用于创建应用程序 UI 的streamlit,用于处理 PDF 文档的PyPDF2,以及来自langchain的各种模块,用于处理语言模型任务。 -
使用
PyPDF2来读取 PDF 的文本。 -
然后,使用 LangChain 的
chunksize,overlap和separator将 PDF 的文本分割成较小的块。 -
接下来,使用 LangChain 的 OpenAI Embeddings将文本块转换为向量表示。这涉及将文本的语义信息编码为可由语言模型处理的数学形式。这些嵌入被存储在 FAISS 数据库中,允许对高维向量进行高效的相似度搜索。
-
然后,应用程序以关于 PDF 的问题形式接受用户输入。它使用 FAISS 数据库来查找语义上与问题最相似的文本块。这些文本块很可能包含回答问题所需的信息。
-
所选的文本块和用户的问题被馈送到 LangChain 的问答链中。此链加载了一个 OpenAI 语言模型的实例。该链处理输入文档和问题,使用语言模型生成响应。
-
OpenAI 回调用于捕获有关 API 使用情况的元数据,例如请求中使用的令牌数量。
-
最后,链的响应被显示在 Streamlit 应用程序中。
此过程允许对超出语言模型令牌限制的大型文档进行语义查询。通过将文档分割成较小的块,并使用语义相似性找到与用户问题最相关的块,即使语言模型无法一次处理整个文档,应用程序也可以提供有用的答案。这演示了在处理大型文档和语言模型时克服令牌限制挑战的一种方法。
还有更多…
LangChain 不仅仅是一种克服令牌窗口限制的工具;它是一个全面的框架,用于创建与语言模型智能交互的应用程序。这些应用程序可以连接语言模型与其他数据源,并允许模型与其环境交互——从根本上为模型提供了一定程度的代理。LangChain 提供了用于处理语言模型所需组件的模块化抽象,以及这些抽象的一系列实现。设计用于易于使用,这些组件可以在使用完整的 LangChain 框架或不使用时使用。
此外,LangChain 还引入了链的概念——这些是上述组件的组合,以特定方式组装以完成特定用例。链为用户提供了一个高级接口,以便轻松开始特定用例,并设计为可定制以满足各种任务的需求。
在后续的示例中,我们将演示如何使用 LangChain 的这些功能来分析更大更复杂的文档,例如.csv文件和电子表格。