前言
本文主要搜集了视频取证各个子领域近几年的高影响因子/引用数的文章及其主要思想和做法,旨在分析目前视频篡改检测的发展现状与热点领域,文章中也融合了自己的一点看法和展望,欢迎感兴趣的同学和我多多沟通。
本文无论是文献搜集还是方向发展和评价都是我一个字一个字敲出来的,如果你需要论文PDF/写论文要引用我的文字的话,请和我说一声。
本人能力有限,有很多领域了解的也不够深入,如果有表述错误也欢迎各位大佬指正,万分感谢!
视频篡改检测
视频篡改检测技术是确保数字视频内容真实性和完整性的关键手段。随着数字视频内容在社交媒体、新闻报道和法律证据中的广泛使用,视频篡改检测的重要性日益凸显。
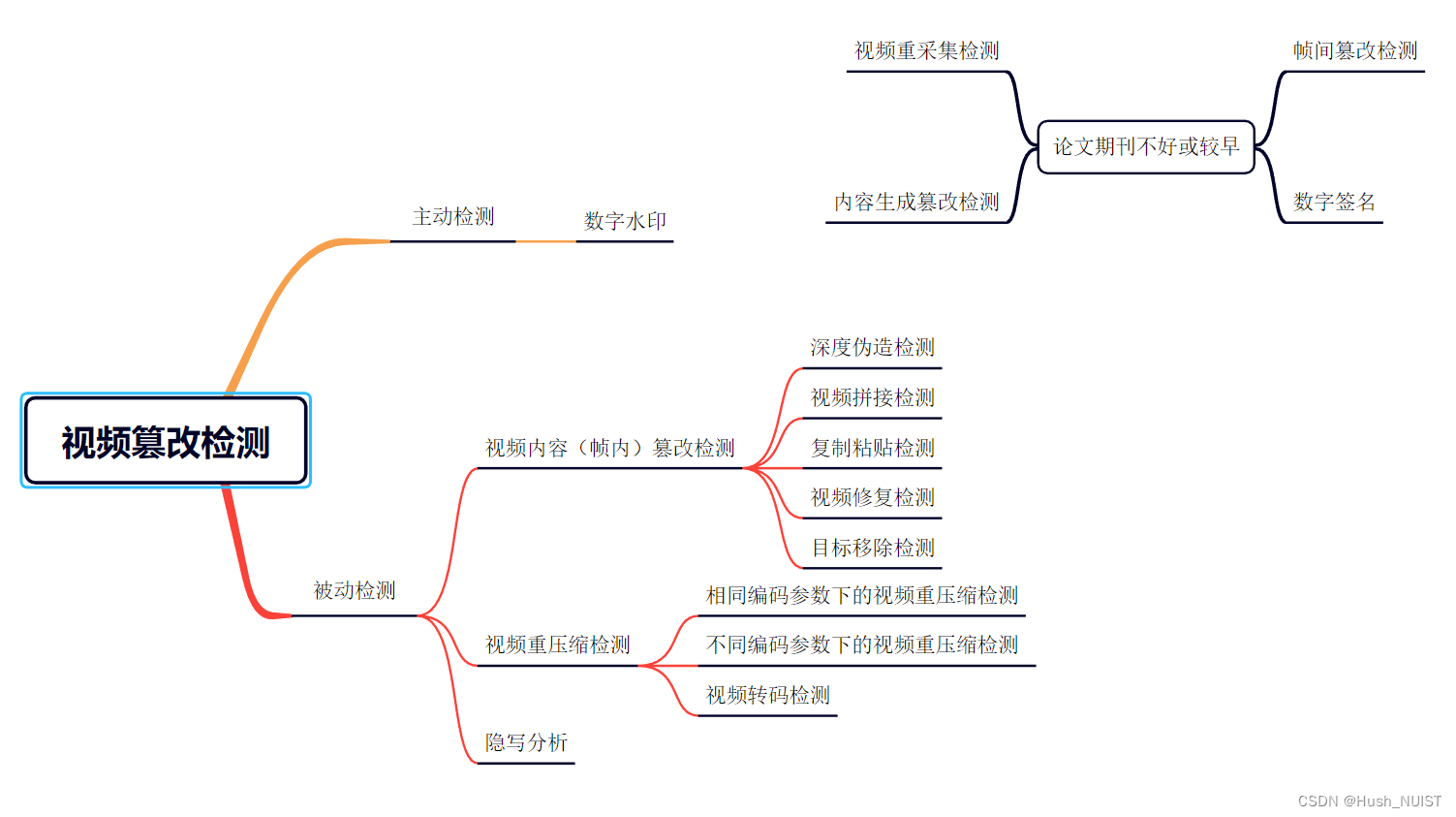
视频篡改检测技术可以分为两大类:主动检测和被动检测。
被动检测
与主动检测不同,被动检测不依赖于视频中预先嵌入的任何额外信息,而是通过分析视频本身的特征来检测篡改行为。被动检测又可细分为深度伪造检测、基于目标的视频篡改检测、视频重压缩检测和隐写分析。接下来分别详细介绍各类被动检测的方法:
深度伪造检测 (最热门的方向)
(1)深度伪造检测也被广泛称为Deepfake检测,涉及识别使用深度学习技术生成或修改的视频。这种类型的篡改通常通过替换视频中人物的面部或修改其口型来伪造言论或行为,进而产生误导性或损害性的内容。
Hu等人[5]提出了一种通过学习帧级特征和时间级特征的双流网络来检测经历社交媒体压缩后Deepfake视频的方法,其中帧级流利用一个低复杂度的网络来提取所有I帧特征,并通过剪枝模型以避免拟合压缩噪,时间级流用于提取由换脸过程引入的时间依赖特征。
Yin等人[6]设计了一个新颖的动态细粒度差异捕捉模块,用于挖掘帧间差异区域,并通过细粒度去噪操作消除由面部运动引起的影响。为了形成统一的时空不一致性特征,该方案还设计了一个多尺度时空融合模块,从而将上述帧间差异区域相关联并用于判断视频的真实性。
Wang等人[7]提出了一个补充动态交互网络(CDIN, Complementary Dynamic Interaction Network),利用局部的口部区域和全局即整个脸部的动态信息,通过充交叉动态融合模块(CCDFM, Complementary Cross Dynamics Fusion Module),将两区域的特征相互增强和融合,从而实现更准确和泛化的检测结果。
Liao等人[8]提出了一个基于面部肌肉运动(FAMM, Facial Muscle Motions)的检测框架来面对经历了社交媒体压缩后的Deepfake视频检测问题,通过时间维度上建模面部肌肉特征来挖掘DeepFake产生的不自然面部肌肉运动并构建几何特征。
Yu等人[9]提出了多时空视图变换器(MSVT, Multiple Spatiotemporal Views Transformer),包括通过设计的局部组来采样方法得到的局部时空视图(LSV, Local Spatiotemporal View)和由全视频部帧得到的全局时空视图(GSV, Global Spatiotemporal View),以深入挖掘更详细的时空信息,实验证明该方案对位置伪造方法和数据集具有更好的的泛化性。
Wang等人[10]设计了一种伪造线索增强网络(FCAN-DCT, Discrete Cosine Transform-based Forgery Clue Augmentation Network),该网络结合了紧凑特征提取(CFE, Compact Feature Extraction)和频率时间注意(FTA, Frequency Temporal Attention)模块,有效捕获视频中的关键伪造特征。在包括首创的近红外视频伪造数据集DeepfakeNIR在内的多个数据集上的实验,作者证明了该方法无论是在可见光还是近红外场景下都具有有效性和鲁棒性。
Guo等人[11]提出了一种通用的空间-频率交互卷积(SFIConv, Space-Frequency Interactive Convolution),以交互方式融合空间域特征和高频信息,构建包含操纵痕迹的更强特征表示。实验表明,SFIConv可以作为一个高效的组件,无缝替换现有主干网络中的标准卷积,从而在不改变模型结构的情况下提升Deepfake检测的性能。
值得一提的是,该方向我在阅读的过程中就是感觉动机很杂乱,虽然有统一的评价指标和数据集,但是总感觉现在的文章逐渐走向以结果为导向了,实用价值可能没文章中说的那么好。
另外,这个热门方向一个优势是目前热门的各类深度学习/模型几乎都用到了这个领域中,如果你想学习一些深度学习技术,用这个技术+DeepFake的关键词,找个好点的文章学习学习,可以在短时间内快速了解如何结合深度学习做篡改检测。(学会了也能用到别的方向里,也不失为一个找idea的好办法)
目标移除检测 (还有很多研究的空间,尤其是空域的篡改定位)

目标移除检测侧重于发现视频帧中特定目标或物体被故意移除的情况。这种篡改可能旨在隐藏视频中的关键信息或者改变场景的上下文,从而影响观众对视频内容的理解。
Mohammed Aloraini等人[12]通过将视频序列建模为随机过程和正异常补丁混合模型,利用序列和补丁分析相结合的方法,有效检测并准确定位视频中的对象移除伪造。实验证明该方案以低计算复杂性实现了出色的检测性能,而且对抗压缩和低分辨率视频具有一定鲁棒性。
Yang等人[13]提出了一种时空三叉戟网络(STN, Spatiotemporal Trident Network),用于视频被动取证中目标移除篡改检测和定位,他们使用连续的5帧作为网络输入,通过空域富模型(SRM, Steganalysis Rich Model)滤波和三维卷积(C3D, 3D Convolution)提取特征编码,然后利用双向长短时记忆网络(BiLSTM, Bi-directional Long Short-term Memory)解码特征来检测时域篡改,该方案具有很高的分类准确性。
Xiong等人[14]提出了一种基于三维双流网络的视频篡改取证方法。作者利用SRM层提取视频帧的高频信息;然后,使用改进的C3D网络作为双流网络的特征提取器从高频图像帧和原始视频帧中分别提取高频信息和低频信息;最后,通过紧凑双线性池化(CBP, Compact Bilinear Pooling)层将两组不同的特征向量融合成一组特征向量并用于分类检测。实验证明该方案在时域检测和空域定位上都具有优势。
复制粘贴检测 (图片的这个方向很成熟,视频Copy-move还有很多发展空间)

复制粘贴检测关注的是视频帧内部的特定区域被复制并粘贴到该视频帧或该视频其他帧的其他位置,以伪造或隐藏某些信息的行为。这种篡改通常涉及到物体的添加或移除,可能会对视频的原始场景造成重大改变,进而影响视频内容的真实性和完整性。
Zhong等人[15]提出了一种新颖的视频伪造检测方法,能够准确鉴别帧内和帧间复制移动伪造视频以及真实视频。该方法首先将视频序列转换为一系列静态图像帧,利用统一的矩算法框架提取每个像素的多维特征,并使用特征索引表示方法来识别像素的独特性,从而在小范围内有效地找到最佳匹配像素,最后通过帧间和帧内后处理算法,可以精确地指出伪造区域。
在[16]中,同一作者提出了一种新颖的视频剪辑移动伪造检测(VCMFD, Video Copy-move Forgery Detection)方法,旨在解决视频伪造检测中的关键挑战,如大量视频信息的处理、多样化的伪造类型、丰富的伪造对象和同源的伪造来源等。该方法采用四种新技术:彻底的尺度不变特征变换(SIFT, Scale-Invariant Feature Transform)特征提取、快速的关键点标签匹配(FKLM, Fast Keypoint-Label Matching)、高效的粗到细过滤以及自适应块填充。通过创新改进的SIFT结构,该方法能够在各种视频剪辑移动伪造案例中彻底提取有效特征;采用简化的关键点标签匹配算法显著提高匹配效率;并通过精确的关键点匹配与自适应块填充算法,从而在像素级别上能准确高效地定位可疑区域。
视频拼接检测 (有几篇顶会做的都是这一类基于目标的视频篡改)
视频拼接检测是一种识别和确定视频内容中哪些部分被替换或插入自另一个视频的技术。这种篡改形式特别是指用其他视频的片段替换原视频中的一部分,从而创造出一个在视觉上可能看起来连贯,但实际上是由不同视频源材料混合而成的视频。与复制移动操作不同,拼接的篡改区域必须来源于另一个视频。J
in等人[17]提出了一种针对视频中不同类型的基于对象的伪造检测框架,专注于揭示基于对象的篡改,即拼接、VCMFD、目标移除等。独特之处在于它结合了深度学习的强大表示能力和双流特征融合技术,通过条件随机场(CRF, Conditional Random Field)层优化分割结果,并利用视频跟踪引入时间约束以提高定位精度。此外,该框架通过在相关图像数据集上训练以减少过拟合,证明了神经网络在图像和视频取证间的通用性和可转移性。
视频修复检测 (同上)
视频修复检测是一项关注如何识别和分析视频序列中经过视觉修复的区域的技术,近年来由于视频修复技术的广泛应用而变得尤为重要。视频修复是一种通过用视觉上可信的像素填充视频序列中缺失或损坏区域的技术,近年来引起了广泛关注。这项技术被广泛应用于多种场景,包括视频编辑和虚拟现实,因其能够例如删除视频中不希望出现的对象等。然而,随着深度学习技术的飞速发展,视频修复的质量大幅提升,使得修复过的视频与原始内容之间的区别变得越来越微妙,以至于肉眼难以识别。因此,开发出能够准确检测出视频是否经过修复的方法,对于保护信息的真实性和完整性,维护公共利益,以及防止法律和道德问题的产生具有至关重要的意义。
Tai D. Nguyen等人[18]提出了VideoFACT(Video Forensics using Attention, Context, and Traces),一个新颖的网络,旨在检测和定位视频中的广泛伪造,如视频拼接、DeepFake、视频修复等。通过结合专为捕获视频操纵痕迹而设计的取证嵌入、用于控制视频编码引入的取证痕迹变化的上下文嵌入,以及一个用于估计取证嵌入的质量和相对重要性的深度自注意力机制来评估取证嵌入的局部质量和相关性,VideoFACT能够有效地识别包括训练期间未遇到的多样化视频伪造在内的假内容。此外,该网络还展示了在面对基于AI的视频修复时,通过微调可以实现更强大的性能。
Yu等人[19]提出了频率感知时空Transformer(FAST, Frequency-Aware Spatiotemporal Transformer),它旨在综合利用空间、时间和频率域的信息来检测视频中的修复痕迹。FAST通过全局自注意力机制和时空Transformer架构,深入挖掘视频帧之间的长距离空间和时间依赖关系,同时引入频率域信息来识别通常在修复视频中缺失的高频细节。此方法不仅打破了传统依赖手工设计注意力模块和记忆机制的限制,实验证明了其出色的性能和良好的泛化能力。
视频隐写检测 (不了解,就不赘述了)
视频隐写分析指的是分析是否有信息被隐藏于视频帧之中,这通常用于检测恶意信息传输。
Zhai等人[20]提出了一套通用特征集,针对数字视频中的隐写术进行高效检测,尤其关注分区模式(PM, Partition Mode)域和运动向量(MV, Motion Vector)域这两个具有大嵌入容量的关键域。通过深入分析运动向量一致性(MVC, Motion Vector Consistency)的统计特性变化,该研究成功地设计出一个既能在PM域也能在MV域实现高准确度检测的特征集,克服了传统方法中域特异性的限制,实现了模型级别的通用性。此外,特征集仅有12维且低计算复杂度使其非常适合于实时视频隐写分析应用。实验证明该方案对不匹配封面源和视频运动变化具有高度鲁棒性。
Cao等人[21]针对H.264视频格式中基于量化离散余弦变换(QDCT, Quantized Discrete Cosine Transform)的隐写术提出了一种有效且高效的隐写分析方法。考虑到H.264视频的压缩数据大多来源于预测残差,作者将分析焦点从空间域转移到预测误差域,并利用特定的语法元素内部预测模式(IPM, Intra Prediction Mode)作为辅助信息以促进隐写分析。通过定义基于预测误差块(PEBs, Prediction Error Blocks)的特征和结合IPM转移概率,设计了SUPERB((SUbtractive Prediction Error Block)特征集,有效揭示了异常的QDCT系数操纵行为。广泛的实验验证了SUPERB特征的有效性,尤其是在训练和测试数据属性差异显著的真实场景中,显著降低了由内容特定掩模(CSM, Cover Source Mismatch)引起的准确率下降,彰显了其广泛的实用性和通用适用性。
Dai等人[22]提出了一种基于PU映射和多尺度卷积残差网络的视频隐写分析方法。该方案通过分析基于预测单元(PU, Prediction Unit)的隐写术对空间域和压缩域的不同影响,发现隐写操作显著破坏了PU块间的连接,在压缩域中留下易于检测的痕迹。为此,该方案引入了PU映射和一个基于预测单元的视频隐写分析网络(PUSN, Prediction Unit Steganalysis Network),包括特征提取、表示和二分类,以及一个多尺度模块以增强检测性能。通过投票机制实现对隐写视频检测,实验结果表明,该方法能有效检测多种基于PU的隐写技术,并在不同嵌入率下实现更高的检测准确率,展现出对嵌入率变化的强大鲁棒性。
视频重压缩检测(门槛较高,要学习视频编码基础知识)
具体来说,不法分子想要篡改视频,首先将视频码流解压成视频序列,随后进行一些空域的篡改如帧删除、插入、目标对象的复制粘贴以及移除等篡改操作。最后将篡改后的视频再次压缩成视频码流文件。因此,被篡改的视频必然经历了二次压缩。研究人员可以通过二次压缩检测技术初步判断视频是否经过篡改。
针对不同的篡改目的来区分,视频重压缩检测又可以进一步区分为不同编码参数下的视频重压缩检测、相同编码参数下的视频重压缩检测、视频转码检测。
不同编码参数下的视频重压缩检测聚焦于两次压缩参数不同导致的各类异常痕迹,当篡改者在压缩过程中两次编码参数图像组(GOP, Group of Pictures)设置不同时,会导致重定位I帧现象,即第一次编码中的P帧在第二次编码时变成了I帧,该现象可以用于检测视频是否经过二次压缩。
Xu等人[23]分析了HEVC(High Efficiency Video Coding)编码格式下的帧间编码中的质量退化过程,尤其是环路滤波以及决策模式中的影响。据此,作者提出了一种基于环路滤波决策和预测单元模式的检测算法,证明了其在检测HEVC重压缩视频方面的有效性和稳健性。He等人[24]提出了一个混合神经网络,利用设计的编码单元大小图(CSM, Coding Unit Size Map)和编码单元模式图(CPM, Coding Unit mode Map)这两类编码信息图,结合基于注意力的双流残差网络和长短期记忆网络(LSTM, Long Short-term Memory)来识别重定位的I帧,实验证明该方案对几类位置编码设置具有较好的泛化能力。Kang等人[25]提出了一种新颖的HEVC视频双重压缩检测方法,该方法从滤波模块中提取并构建特征图,并结合轻量级神经网络,以捕捉重定位I帧的痕迹。(这个子方向应该算是重压缩检测最多最新,也是比较有价值的方向了,感兴趣的可以多研究研究)
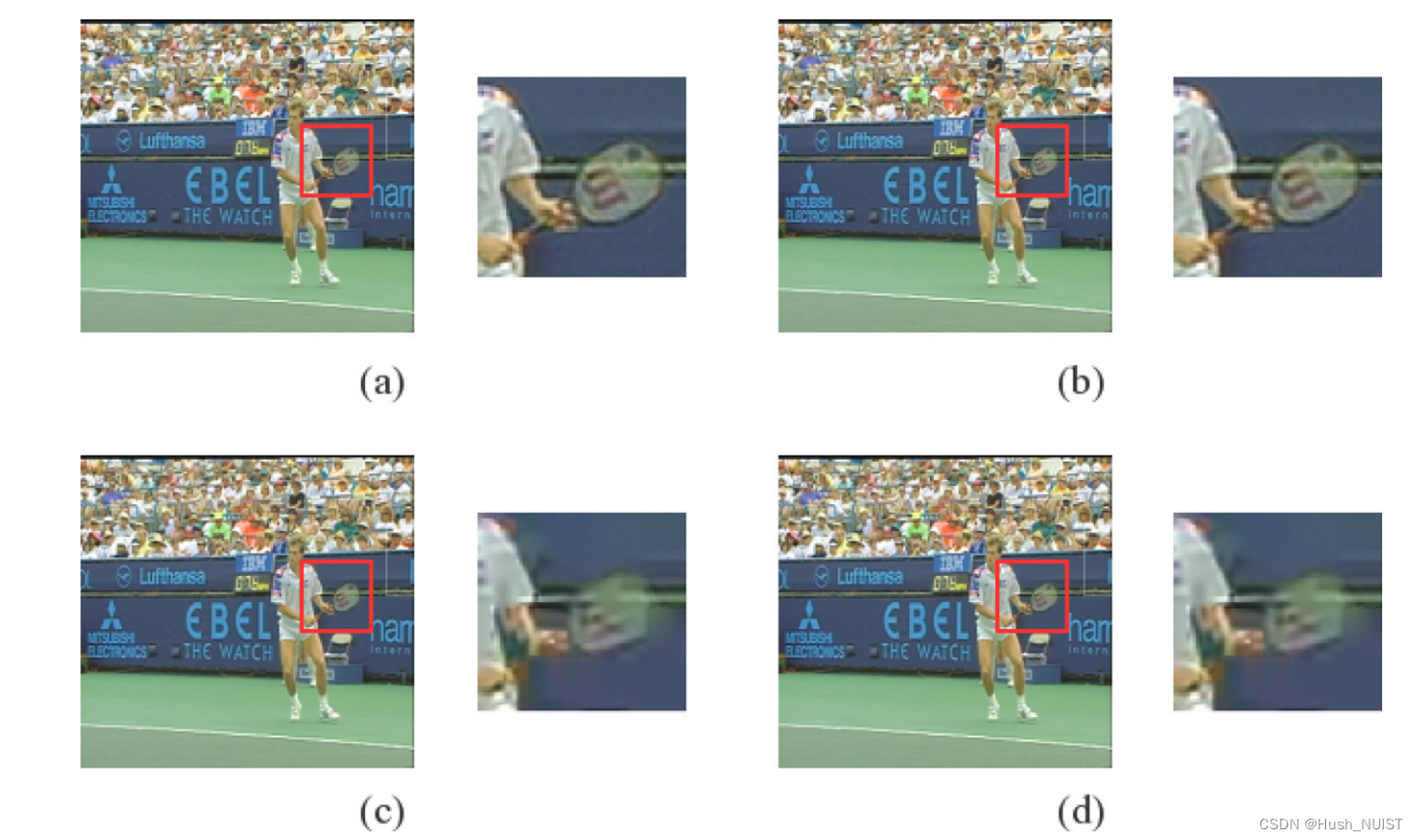
除了该场景外,当篡改者的目的在于伪造虚假质量视频时,通常会通过修改视频的比特率、量化参数和帧率将视频伪造成假高清视频来骗取更多的点击量和非法占用更多网络带宽。
Yu等人[26]针对这一类虚假高清视频,提出了一种基于预测模式特征(PMF, Prediction Mode Feature)的假高清视频检测方案,作者从帧内和帧间预测模式中提取了共10维的特征,结合支持向量机(SVM, Support Vector Machine)来检测并进一步估计它们原始的量化参数和比特率,实验证明该方案在不同的比特率和量化参数组合下都取得了较好的结果。He等人[27]提出了进一步压缩的操作以提取特征重新压缩误差,然后将其通过裁剪策略将一帧图像分解成补丁,将其输入混合的异构深度学习网络以获得补丁级别的分类结果,通过投票策略,该方案得到视频级的分类结果。
相同编码参数下的视频重压缩检测,指篡改者在解码视频的过程中,利用第三方码流分析工具获取原始编码时的参数。在对视频内容进行帧内或帧间内容篡改之后,篡改者会使用这些相同的编码参数重新对视频进行编码。在这种情况下,视频的重压缩迹象通常较为微弱,使得检测工作变得更加困难。
Jiang等人[28]分析了HEVC编码格式的帧内质量退化机制,并依此提出了内预测单元预测模式(IPUPM, Intra Prediction Unit Prediction Mode)特征,实验证明该方案在不同速率控制模式和较高分辨率(720p和1080p)中都取得了较好的实验结果。Kutub Uddin等人[29]通过分析不同编码单元的划分信息来生成深度图,并从中提取基于帧内预测模式了统计特征和深度特征,用于检测在相同编码信息下HEVC的双重压缩,实验结果表明,该方法在多种编码模式和分辨率设置下均显示出了高效的检测能力。Xu等人[30]针对具有高位移强度的视频内容,提出了一种的运动自适应的同参数视频重压缩检测算法,在多次解压过程中提取正常I帧的帧内预测模式的波动强度和不稳定的预测单元以及自适应I帧中的光流特征,最终送入支持向量机分类器得到分类结果,实验证明该方案对不同的运动位移强度和各种编码参数设置具有鲁棒性。Li等人[31]针对视频双重压缩检测提出了一种半监督学习方法,旨在解决传统监督学习因需对大量数据进行详尽标注而导致的效率低下问题。该方案首次将单类分类器(OCC, One-class Classifier)应用于此领域,仅利用原始视频帧中提取的特征进行检测。通过分析视频帧特征的高斯分布,提出了一个简单而有效的基于高斯分布的OCC。为提高模型在不同视频源情境下的鲁棒性和检测性能,该方案采用了集成策略。实验结果显示该方法在处理HEVC编码格式的视频时,不仅在检测双重压缩方面取得了出色性能,而且相比于其他更复杂的单类分类方法及完全监督学习方法,具有更低的计算复杂度,有效提高了检测效率。Xu等人[32]提出了一种用于检测相同编码参数下H.266/VVC(Versatile Video Coding)重压缩的算法。该方案通过分析H.266/VVC双重压缩痕迹的产生,利用编码单元划分的变化和预测模式的一致性来表征双重压缩痕迹。为了减少四叉树或多类型树分区对模式分析的干扰,提出了最小单元映射(MUM)和子单元预测映射(SPM)来构建特征,形成了60维的检测特征向量,结合SVM得到最终分类结果。广泛的实验显示,该算法性能优越,且在不同编码场景下具有鲁棒性。
视频转码检测指将数字内容从一种质量较低编码格式转换为另一种编码格式,以此来伪装成先进编码格式视频的质量篡改行为,因此有许多工作聚焦于转码检测,旨在识别这类视频质量篡改行为。
Xu等人[33]通过分析帧间编码中的环路滤波和I帧中预测单元划分的变化,构建了一个17维的分类特征,进而使用支持向量机进行分类,实验验证了该方案的优越性和鲁棒性。Yao等人[34]使用解码帧和预测单元映射图作为输入,提出了一个包含特定卷积模块和自适应融合模块的双路径网络,以实现帧级的转码检测及定位。
主动检测(不太了解 不予评价)
主动检测技术要求在视频内容创建或传输过程中嵌入额外信息,以便后续验证视频的真实性和完整性。近几年的视频主动检测主要聚焦于数字水印技术:
视频数字水印技术
视频数字水印技术是一种将特定信息或指纹(即水印)嵌入到视频内容中的方法,旨在保护数字媒体内容的版权和所有权。随着高速网络的发展,视频的传播变得更加便捷,但同时也面临着未经授权的复制和分发的风险。视频数字水印技术能够在不影响原始视频质量的情况下,嵌入隐蔽的信息,以便在版权纠纷或非法分发的情况下识别和追踪视频的来源。
Huan等人[1]提出了一种新颖的双树复小波(DT CWT, Dual Tree-complex Wavelet)视频水印方案,通过探索联合子带上的稳定系数来增强水印的鲁棒性。该方案在DT CWT域执行块奇异值分解(SVD, Singular Value Decomposition),并选取最大奇异值作为候选系数,然后通过模拟水印嵌入过程确定两对联合子带。这些子带在水印嵌入后倾向于提供相似的候选系数,因此能够在某个子带遭受攻击时降低影响,提升整体的鲁棒性。水印的嵌入是通过在视频分辨率自适应选择的层级上修改联合子带的候选系数来进行的。为了鲁棒地检测水印,从两对联合子带中提取一组稳定的候选系数来确认视频的所有权。
He等人[2]提出了一种盲视频水印方案,通过在低阶递归Zernike矩中嵌入水印,提高了对几何变形和视频分享平台处理的鲁棒性。该方案害采用了高效的计算策略,针对视频和矩的特性进行了优化,从而降低了计算复杂度,实验证明该方案在抵御几何变形、长宽比调整等多种攻击的情况下,依然保持了水印的隐蔽性,并且能够在无需原始宿主视频的情况下准确提取水印。
Chen等人[3]提出了一种新型基于Zernike矩的视频水印技术,专为高分辨率视频设计,能够抵抗旋转、缩放和其他常见攻击。该方法通过自适应选择适合嵌入和提取的帧对,使用分块技术和奇异值分解来生成正方形特征矩阵,并将水印嵌入到选定的Zernike矩中,增强了水印的鲁棒性和不可见性,同时,该方案提出了两种策略以增强对特殊情况的抵抗力。
Luo等人[4]提出了一种新型的基于深度学习的视频水印技术(DVMark, Deep Video Watermark),旨在通过不可察觉的方式将信息嵌入视频中,并能在视频经历各种扭曲后仍能检索出这些信息。与传统水印方法和深度图像水印模型相比,DVMark通过其独特的多尺度设计,在处理广泛的视频扭曲方面显示出更高的鲁棒性,同时保持了良好的感知质量。该模型支持端到端训练,易于适应不同的扭曲要求,并通过加入水印探测器,能够在含有未加水印内容的视频中精确定位加水印的视频片段。
值得一提的是,目前DeepFake(深伪)检测方向也出现了许多类似主动取证的方法,比如通过对抗训练给图片(也可以是视频帧)添加一个扰动/噪声,使图片在经历现有的篡改技术后产生严重影响视觉效果的伪影,这也是近几年比较火的方向。
未来发展与挑战
视频数字水印技术:该方向的发展前景与挑战主要围绕以下几个方面展开:
1.不可见性:不可见水印技术的核心挑战在于如何确保水印的存在对人类视觉系统(HVS, Human Visual System)不可感知,以防止降低视频质量。未来的发展需要进一步优化算法,以实现在不影响视频视觉质量的前提下,隐藏更多的信息。
2.有效载荷:如何在保持水印不可感知的同时,增加更多信息的嵌入量(有效载荷),是一个重要的研究方向。这涉及到算法设计中有效载荷与不可感知性之间的平衡,特别是在多比特水印和访问控制应用中。
3.盲检测:盲水印提取技术的发展是应对实际应用场景中原始视频不可用的情况。挑战在于如何提高盲检测的准确性和鲁棒性,使得在没有原始视频参照的情况下,也能可靠地提取出水印信息。
4.对攻击的鲁棒性:随着攻击手段的多样化和复杂化,如何增强水印方案对各种信号处理攻击、几何攻击以及时间去同步等扭曲的鲁棒性,是一个持续的挑战。这要求水印技术能够在视频质量受损的情况下仍然维持其功能。
5.水印的安全性:除了提高水印的鲁棒性外,如何防御那些旨在获得嵌入和/或提取系统知识以移除水印的安全性
攻击,也是一个关键挑战。这包括对抗勾结攻击、仅加水印攻击和多重水印嵌入等策略,以及如何防止非法声称视频内容的所有权。
总的来说,视频水印技术的发展面临着不可见性与有效载荷之间、盲检测准确性与鲁棒性之间以及安全性与防御策略之间的多重平衡挑战。这些因素相互之间存在紧张关系。例如,提高鲁棒性往往以降低视觉质量为代价,增加有效载荷可能对解码准确性以及视觉质量都有一定的影响。未来的研究将需要在这些方面寻找更高效、更智能的解决方案,以实现这些相互冲突目标之间的优化平衡。
深度伪造检测:深度伪造技术的快速发展对检测系统提出了极大的挑战,要求未来的深伪检测方法必须同时具备高度的泛化能力、鲁棒性和可解释性。随着深伪内容生成工具的不断演化,这些系统需要能够跨越不同的生成技术,有效识别各种深伪内容,这要求研究人员开发出更通用的算法,可能通过融合多种检测特征和学习方法来实现。同时,面对现实世界应用中的复杂情境,如低质量媒体内容和精细的篡改技巧,检测模型必须展现出异常的鲁棒性,能够在各种条件下保持高效的识别性能。此外,增加模型的可解释性在法律和取证领域尤为关键,这不仅有助于提升用户对技术的信任,还能为专业分析提供必要的透明度和理解。此外,考虑到现实世界中存在的各种特殊应用场景,如[10]中所提及的红外场景,这些场景在安全监控和夜间监测中有着广泛的应用,这也对深度伪造检测技术提出了新的挑战。
基于目标的视频篡改检测:该方向面临的挑战和发展方向可综合概括为以下几个关键点:
- 提高通用性:目前的基于目标的视频取证方法多专注于特定类型的篡改操作,缺乏广泛适用性。为适应实际应用中的多样化篡改手段,需要开发能够广泛适应各类视频篡改的通用特征和技术。
- 增强稳健性和实现精确空域定位:现有的视频取证技术在稳健性方面存在不足,难以应对视频质量变化、编码差异和复杂篡改手法。同时,精确的空域定位对于完整理解篡改内容极为重要,因此提升这一能力是未来的重要研究目标。
- 计算效率与准确率的平衡:在提高检测技术的准确性的同时,也需要关注算法的计算效率。视频处理本身就是资源密集型的任务,因此如何在保持高准确率的同时优化算法的计算量,实现快速有效的检测,是一个重要的考虑因素。这需要在算法设计中寻找准确率与计算资源之间的最佳平衡点,可能涉及到算法架构的优化、高效的计算方法、甚至硬件加速等多方面的创新。
总的来说,基于目标的视频篡改检测技术的未来发展需要在提高通用性、稳健性、检测精度、以及计算效率等多方面进行创新和优化,以适应日益复杂的视频篡改手段和实际应用的需求。
视频隐写分析:随着视频隐写术与人工智能等其他技术的结合日益深入,其在视觉质量、嵌入容量和鲁棒性之间实现了良好的平衡,隐写分析面临的挑战也随之增加。尤其是隐写术与视频压缩技术的紧密整合,为隐写分析带来了前所未有的挑战。通过调整压缩过程中的语法元素进行秘密信息嵌入的压缩域视频隐写技术,减少了其对空间域的影响,使得传统基于图像的隐写分析方法难以直接适用于视频。
因此,未来的研究重点将是利用深度学习和卷积神经网络等先进技术,自动学习和提取视频数据中的隐藏特征,从而开发出有效识别压缩域隐写技术的新方法。同时,随着新视频编码标准如VVC的推出,针对这些复杂编码过程的隐写分析和检测技术亦需不断研究和进步,以确保隐写分析技术能够与视频隐写术的最新发展保持同步。
视频重压缩检测:从该方向的整体来说,当前大量研究集中在HEVC编码上,随着最新的VVC编码标准的引入,其带来了众多复杂的新技术,这些都需要进行深入的分析研究。到目前为止,只有[32]探讨了在VVC编码格式下进行同参数重压缩检测的问题。在这一领域的其他子领域中,继续探索现有的HEVC方案在新的VVC标准下的适用性,以及为VVC量身定做的新方案,都是十分有价值和必要的研究方向。
此外,在视频重压缩检测的任何子领域中,寻求一种对不同编码器预设和参数具有鲁棒性的方案,始终是一个亟待深入探索和研究的问题。最后,随着高清视频内容(如2K、4K)的普及,当前对于高清视频的重压缩检测方案尚属空白,这也标志着一个待开发的研究领域。
参考文献
[1]W. Huan, S. Li, Z. Qian and X. Zhang, “Exploring Stable Coefficients on Joint Sub-Bands for Robust Video Watermarking in DT CWT Domain,” in IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 4, pp. 1955-1965, April 2022.
[2]M. He, H. Wang, F. Zhang, S. M. Abdullahi and L. Yang, “Robust Blind Video Watermarking Against Geometric Deformations and Online Video Sharing Platform Processing,” in IEEE Transactions on Dependable and Secure Computing, vol. 20, no. 6, pp. 4702-4718, Nov.-Dec. 2023.
[3]S. Chen, A. Malik, X. Zhang, G. Feng and H. Wu, “A Fast Method for Robust Video Watermarking Based on Zernike Moments,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 12, pp. 7342-7353, Dec. 2023.
[4]X. Luo, Y. Li, H. Chang, C. Liu, P. Milanfar and F. Yang, “DVMark: A Deep Multiscale Framework for Video Watermarking, ” in IEEE Transactions on Image Processing, March 2023.
[5]J. Hu, X. Liao, W. Wang and Z. Qin, “Detecting Compressed Deepfake Videos in Social Networks Using Frame-Temporality Two-Stream Convolutional Network,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 3, pp. 1089-1102, March 2022.
[6]Q. Yin, W. Lu, B. Li and J. Huang, “Dynamic Difference Learning With Spatio–Temporal Correlation for Deepfake Video Detection,” in IEEE Transactions on Information Forensics and Security, vol. 18, pp. 4046-4058, 2023.
[7]H. Wang, Z. Liu and S. Wang, “Exploiting Complementary Dynamic Incoherence for DeepFake Video Detection,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 8, pp. 4027-4040, Aug. 2023.
[8]X. Liao, Y. Wang, T. Wang, J. Hu and X. Wu, “FAMM: Facial Muscle Motions for Detecting Compressed Deepfake Videos Over Social Networks,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 12, pp. 7236-7251, Dec. 2023.
[9]Y. Yu et al., “MSVT: Multiple Spatiotemporal Views Transformer for DeepFake Video Detection,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 9, pp. 4462-4471, Sept. 2023.
[10]Y. Wang, C. Peng, D. Liu, N. Wang and X. Gao, “Spatial-Temporal Frequency Forgery Clue for Video Forgery Detection in VIS and NIR Scenario,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 12, pp. 7943-7956, Dec. 2023.
[11]Z. Guo, Z. Jia, L. Wang, D. Wang, G. Yang and N. Kasabov, “Constructing New Backbone Networks via Space-Frequency Interactive Convolution for Deepfake Detection,” in IEEE Transactions on Information Forensics and Security, vol. 19, pp. 401-413, 2024.
[12]M. Aloraini, M. Sharifzadeh and D. Schonfeld, “Sequential and Patch Analyses for Object Removal Video Forgery Detection and Localization,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 3, pp. 917-930, March 2021.
[13]Q. Yang, D. Yu, Z. Zhang, Y. Yao and L. Chen, “Spatiotemporal Trident Networks: Detection and Localization of Object Removal Tampering in Video Passive Forensics,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 10, pp. 4131-4144, Oct. 2021.
[14]L. Xiong, M. Cao, and Z. Fu, “FoArensic of video object removal tamper based on 3D dual-stream network,” Journal on Communications, vol. 42, no. 12, pp. 202-211, 2021.
[15]Zhong J L, Gan Y F, Vong C M, et al. Effective and efficient pixel-level detection for diverse video copy-move forgery types. Pattern Recognition, 2022, 122: 108286.
[16]Zhong J L, Pun C M, Gan Y F. Dense moment feature index and best match algorithms for video copy-move forgery detection. Information Sciences, 2020, 537: 184-202.
[17]X. Jin, Z. He, J. Xu, Y. Wang and Y. Su, “Object-Based Video Forgery Detection via Dual-Stream Networks,” 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 2021, pp. 1-6.
[18]Tai D. Nguyen, Shengbang Fang, Matthew C. Stamm; Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024, pp. 8563-8573.
[19]Bingyao Yu, Wanhua Li, Xiu Li, Jiwen Lu, Jie Zhou; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 8188-8197.
[20]L. Zhai, L. Wang and Y. Ren, “Universal Detection of Video Steganography in Multiple Domains Based on the Consistency of Motion Vectors,” in IEEE Transactions on Information Forensics and Security, vol. 15, pp. 1762-1777, 2020.
[21]Y. Cao, H. Zhang, X. Zhao and X. He, “Steganalysis of H.264/AVC Videos Exploiting Subtractive Prediction Error Blocks,” in IEEE Transactions on Information Forensics and Security, vol. 16, pp. 3326-3338, 2021.
[22]H. Dai, R. Wang, D. Xu, S. He and L. Yang, “HEVC Video Steganalysis Based on PU Maps and Multi-Scale Convolutional Residual Network,” in IEEE Transactions on Circuits and Systems for Video Technology.
[23]Q. Xu, X. Jiang, T. Sun, and A. C. Kot, “Detection of HEVC double compression with non-aligned GOP structures via inter-frame quality degradation analysis,” Neurocomputing, vol. 452, pp. 99-113, Sep. 2021.
[24]P. He, H. Li, H. Wang, S. Wang, X. Jiang, and R. Zhang, “Frame-wise detection of double HEVC compression by learning deep spatio-temporal representations in compression domain,” in IEEE Transactions on Multimedia, vol. 23, pp. 3179-3192, 2021.
[25]X. Kang, P. Su, Z. Huang, Y. Chen and J. Wang, “Double Compression Detection Based on the De-Blocking Filtering of HEVC Videos,” in 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023, pp. 1-5.
[26]Y. Yu, H. Yao, R. Ni, and Y. Zhao, “Detection of fake high definition for HEVC videos based on prediction mode feature,” Signal Process, vol. 166, p. 107, Jan. 2020.
[27]P. He, H. Li, B. Li, H. Wang and L. Liu, “Exposing Fake Bitrate Videos Using Hybrid Deep-Learning Network From Recompression Error,” in IEEE Transactions on Circuits and Systems for Video Technology., vol. 30, no. 11, pp. 4034-4049, Nov. 2020.
[28]X. Jiang, Q. Xu, T. Sun, B. Li, and P. He, “Detection of HEVC double compression with the same coding parameters based on analysis of intra coding quality degradation process, ” in IEEE Transactions on Information Forensics and Security, vol. 15, pp. 250-263, 2020.
[29]K. Uddin, Y. Yang, T. O. Byung. “Double compression detection in HEVC-coded video with the same coding parameters using picture partitioning information.” Signal Processing: Image Communication, 2022, 103: 116638.
[30]Q. Xu, X. Jiang, T. Sun, and A. C. Kot, “Motion-adaptive detection of hevc double compression with the same coding parameters,” in IEEE Transactions on Information Forensics and Security, vol. 17, pp. 2015-2029, 2022.
[31]Q. Li, S. Chen, S. Tan, B. Li and J. Huang, “One-Class Double Compression Detection of Advanced Videos Based on Simple Gaussian Distribution Model,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 4, pp. 2496-2500, April 2022.
[32]Xu Q, Xu D, Wang H, et al. “Detecting double H. 266/VVC compression with the same coding parameters”. Neurocomputing, 2022, 514: 231-244.
[33]Xu Q, Jiang X, Sun T, et al. “Detection of transcoded HEVC videos based on in-loop filtering and PU partitioning analyses”. Signal Processing: Image Communication, 2021, 92: 116109.
[34]H. Yao, R. Ni, H. Amirpour, C. Timmerer, and Y. Zhao, “Detection and Localization of Video Transcoding From AVC to HEVC Based on Deep Representations of Decoded Frames and PU Maps,” in IEEE Transactions on Multimedia, vol. 25, pp. 5014-5029, 2023.