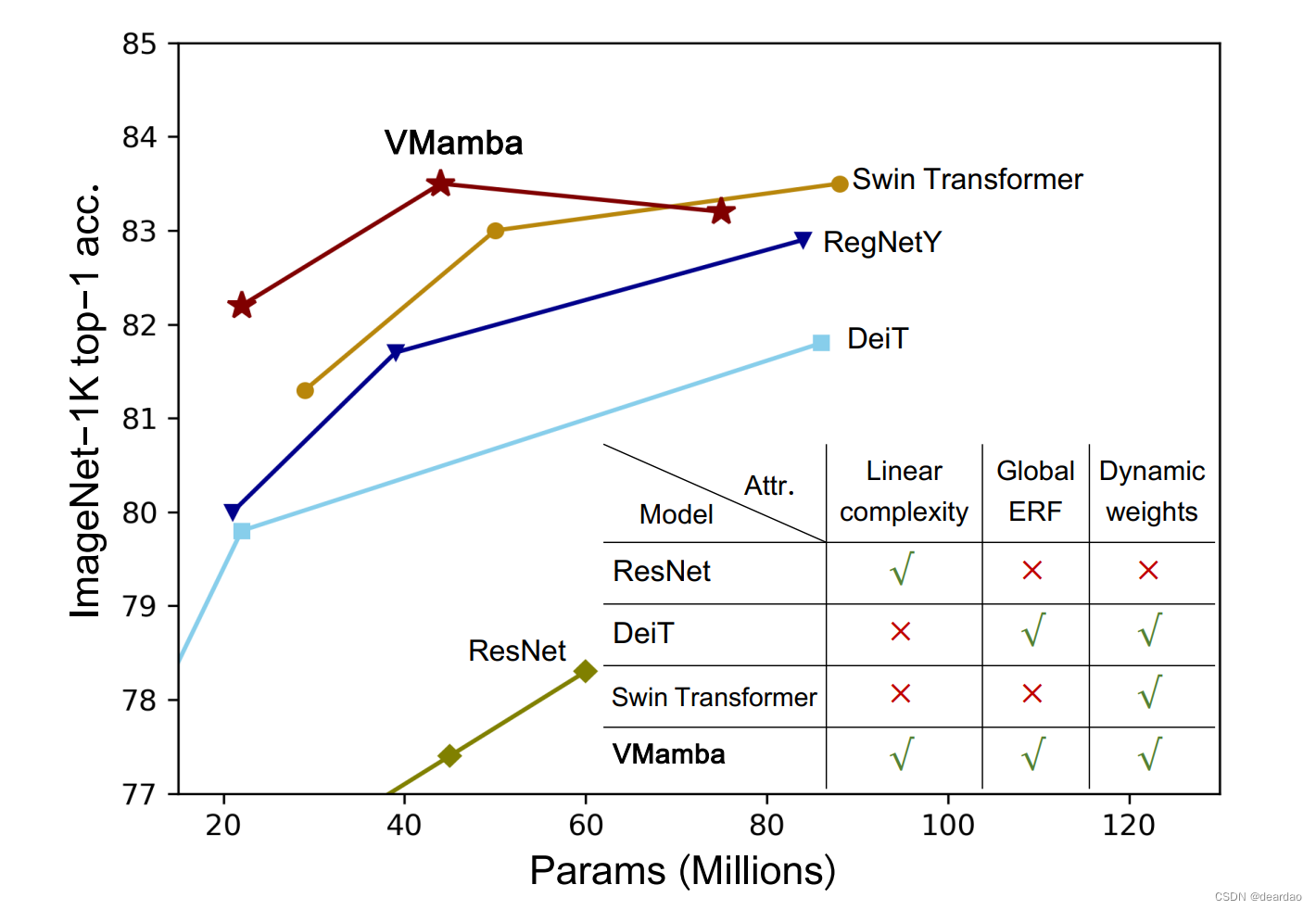
一、库的查看创建删除
库的查看
show databases;库的创建(创建一个test1数据库)
create database test1;同样,我们另起一个root会话,并执行
cd /var/lib/mysql然后发现多了一个test1目录

删除库(删除test1数据库)
drop database test1;删掉之后,对应的目录也就没有了。
小小总结:
1.创建数据库:create database db_name; -----本质上就是在/var/lib/mysql创建一个目录
2.删除数据库:drop database db_name; -------本质上就是删除目录
到这里我们也可以发现mysql是在文件系统之上的。
我们直接在/var/lib/mysql上直接通过mkdir创建一个目录
mkdir hahahaha然后在show一下
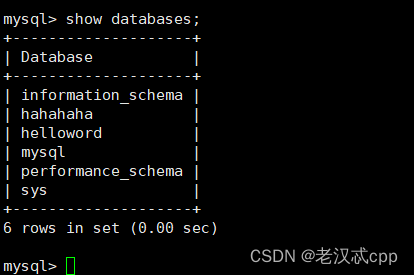
发现就等于创建了一个数据库
但是这样的话,hahahaha内部没有默认的配置文件。所以这里仅是做演示,实际并不推荐这样创建数据库
所以我们把这个库删掉
rm -f hahahaha -r二、认识系统编码
在创建数据库的时候,有两个编码集:
1.数据库编码集 ----未来在向数据库写入数据时,所采用的编码集。
2.数据库校验集 ----支持数据库,进行字段比较的编码,本质也是一种读取数据库中数据所采用的编码格式。
数据库无论对数据进行任何操作,都必须保证操作和校验的编码是相匹配的。
我们可以查看一下mysql默认的字符编码
1.默认的操作编码
show variables like 'character_set_database';
这里是utf8.
2.默认的校验编码
show variables like 'collation_database'; 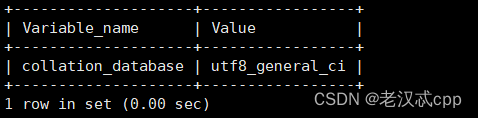
另外还可以查看mysql支持的所有操作字符集
show charset;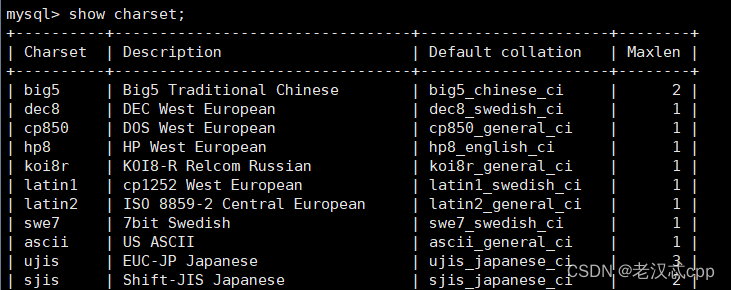
还可以查看mysql所有支持的校验字符集
show collation;三、指定字符集创建数据库
我们之前创建数据库,都是按照默认配置的字符集创建的。在今后我们创建数据库时,一般都是按照默认的来的,但是我们可以熟悉一下按照指定的字符集创建数据库。
还记得我们创建了一个数据库时,在这个目录下有一个默认的配置文件吗
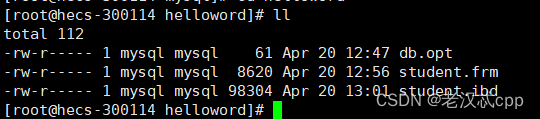
就是这个db.opt文件。
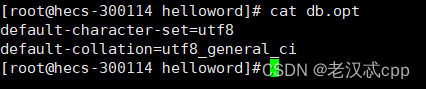
查看就发现它有默认的字符编码集
我们创建一个指定编码集gbk的数据库d2
create database d2 charset=gbk;然后我们查看一下它的配置文件

我们发现, 编码集变成了gbk,并且注意到了一个细节,它的校验编码集我们并没有指定,但是它默认匹配了一个gbk的校验编码集,而不是之前看到的utf8的校验编码集。
再创建一个数据库d3,这次同时指定编码集和校验编码集
create database d3 charset=utf8 collate utf8_general_ci;同样再查看配置文件

如我们指定的一样。
四、验证不同校验编码的影响
1.创建一个数据库,校验规则适用utf8_general_ci。这个是不区分大小写的。
2.校验规则适用utf8_bin。这是区分大小写的。
首先创建一个test1,采用默认的,也就是不区分大小写的。
create database test1;再创建一个test2,校验规则使用utf8_bin,区分大小写
create database test2 collate utf8_bin;看一下test2的配置文件

分别选中两个数据库,并创建相同的表
use test1;
create table person(name varchar(20));
我们可以看一下这个表结构
desc person; 
然后插入一些数据
insert into person (name) values ('a');
insert into person (name) values ('b');
insert into person (name) values ('A');
insert into person (name) values ('B');查看插入的数据
select * from person;
因为我们这个数据库是不区分大小写的
所以我们加上一个查询条件
select * from person where name='a';查询结果
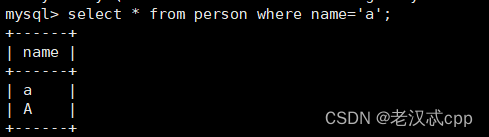
我们发现 A也查出来了。说明不区分大小写。
同样的操作,我们选定test2,并创建一个相同的表,插入相同的数据。

再条件查询'a'。
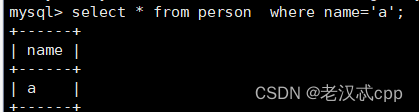
此时就只有'a'了。
我们还可以以名字为排序进行查询
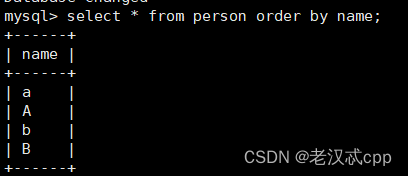
select * from person order by name; 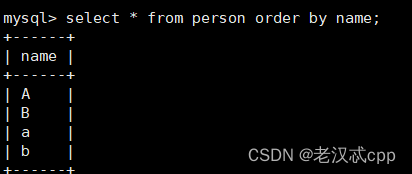
可见test2是以升序排序的。
再看看test1
五、库的删改查
因为刚刚讲的就是增,所以这里只讲删改查了。
库的删除非常简单,比如要删除d2
drop database d2;这样就删掉了,非常简单。
注意,一般非常不推荐删掉数据库,这里仅仅只是为了测试用。
查数据库也非常简单,就是
show databases;不过如果我想要对某个库进行表的操作,要先use选定这个数据。
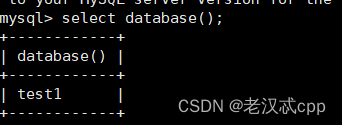
另外,如果我们当前想知道我们选定的是哪个数据库,可以使用
select database();
最后就是修改数据库了,比如我们要修改某个库的字符编码集。
比如我们改一下test2的,将其编码集修改成gbk的
格式如下
alter database test2 charset=gbk collate gbk_chinese_ci;查看一下它的配置文件

已经被修改了。
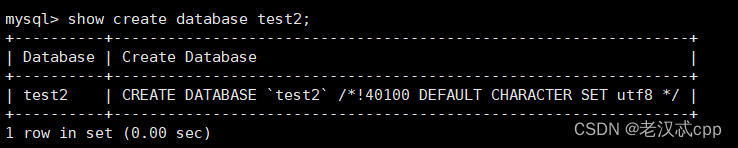
另外,我们还可以看一下某一个数据库,这个数据库当时在被创建时所执行的命令,比如test2
show create database test2;
注意,这个/* */不是注释,它表示的是,如果当前mysql的版本大于4.01的话,就执行这个语句。有点像判断语句。 而它前面的GREATE DATABASE是每个版本都会执行的,只有后面的是要有条件的。
这里我们再将test2的编码集改成utf8的。
alter database test2 charset=utf8 collate utf8_general_ci;再查一下
发现后面的字段跟着变了。
六、库的备份与恢复
以前的数据库对于库的重命名是支持的,现在不支持了。
如果要备份库,我们可以用一个工具,mysqldump,虽然我们之前也了解了数据库其实在linux下就是一个目录,我们可以直接拷贝打包,但是并不推荐这样做。
基本语法
mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径比如我要把备份的文件放在MySQL目录下
cd MySQL/
mysqldump -P3306 -uroot -p -B test1 > test1.sql
简单查看一下这个文件
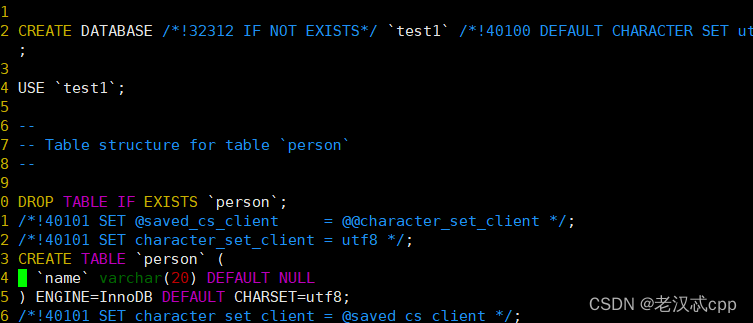 发现其中还保存了我们执行过的指令。
发现其中还保存了我们执行过的指令。
这就是库的备份了。那么我们该如何恢复呢?
只要在mysql客户端下,执行(注意事先得知道备份库所在的文件路径)
source /root/MySQL/test1.sql;即可
注意:如果我们想备份的不是整个数据库,而是其中部分表,格式如下,记得指明库名
mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql还有:如果想同时备份多个数据库,也很简单
mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径其中还原/恢复时都是用source,另外如果我们备份的时候,没有带 -B选项(说明只是想备份部分表),那么还原的时候需要先创建一个空数据库,再使用source来还原。
因为数据库也是网络服务,所以我们可以查看当前有哪些用户正在访问使用数据库
show processlist;
那么库的操作就暂时告一段落了。
七、表的增加
基本格式
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
) character set 字符集 collate 校验规则 engine 存储引擎;在()之间是设置表的字段,其中注意的是,是字段名字在前,类型在后,这跟我们学C/C++变量命名的时候是反过来的。
我们测试创建一个用户表
create table if not exists user1(
-> id int,
-> name varchar(20) comment 'user name',
-> password char(32) comment 'for test',
-> birthday date comment 'for test2'
-> )character set utf8 collate utf8_general_ci engine MyIsam;if not exists:可以加也可以不加。
comment:跟注释的功能是一样的,这里用作测试
character set utf8 collate utf8_general_ci engine MyIsam:这里我们不指明写的话,就会默认采用配置文件里面的,除了编码方式,我们指明了使用的引擎是MyIsam。
注意在设置字段的时候,很像C++构造函数的初始化列表一样,每一个字段之间要用逗号分隔,但是最后一个不要用逗号。
八、表的查询
1.查询我们当前选定的是哪个数据库
select database();2.展示当前库内所有的表名
show tables;
3.查看某个表的详细结构
desc 表名;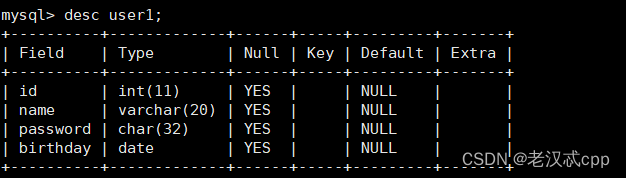
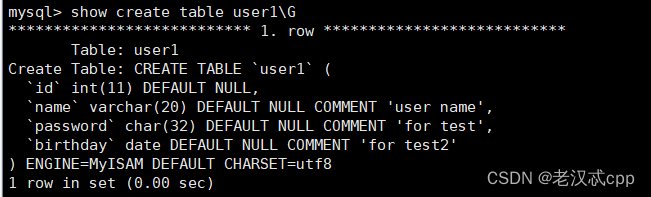
但是如果我们还想查看更加详细的信息,比如使用的引擎,所用的编码方式,或者注释等信息,可以使用
show create table 表名\G其中这个\G是可选选项,它替换了冒号,加了使得查询结果更简洁。
九、修改表
1.首先我们先向表中插入数据
就比如之前的user1表
insert into user1 (id,name,password,birthday) values (1,'张三','12345','2004-2-1');其中,在values前的括号中,指明我们要插入的列,这个括号可以省略,省略就表示我们我们要对每一列都进行插入。
2.接着我们修改表,使其新增一列 ,比如年龄,并加上注释
alter table user1 add age int comment '年龄';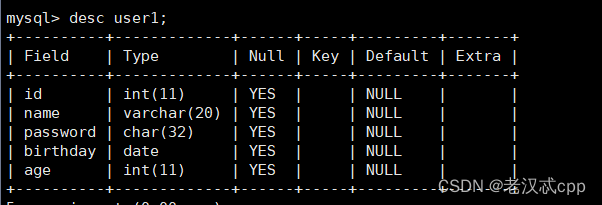
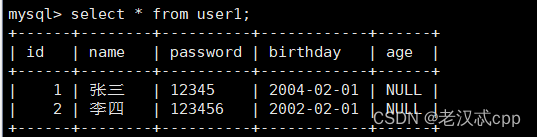
这时我们在看一下更详细的表结构变化
发现年龄和注释也加上来了。
3.修改某一个列的属性
原本user1这个表,name列的类型是varchar(20),我们将其修改成60
alter table user1 modify name varchar(60);注意修改是modify。
再查看一下

大小确实更改了。
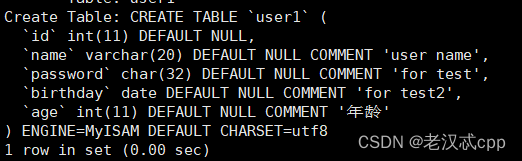
我们再看一下更详细的表结构
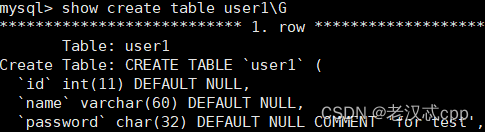
我们发现,name这一列大小确实也变了,但是当时我们是有注释的,我们修改之后,注释没有了。
说明这个修改是覆盖式的修改,它会连同创建时的属性一同修改了。
4.删除某一列
比如我们要删除password列
alter table user1 drop password;结果
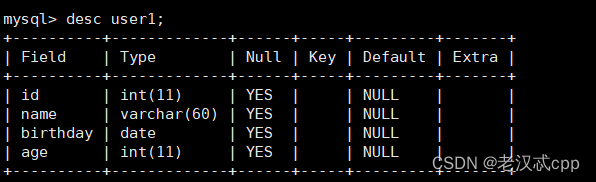
确实删除成功了。并且我们这一列上的数据也跟着删除了,所以删除列的时候也要小心。
5.修改表名
alter table 原表名 rename 新表名;6.修改列名
alter table user change 原列名 新列名 varchar(60) DEFAULT NULL;注意,在修改列名时,还需要设置新列名的类型,以及属性。
十、删除表
非常简单
drop table 目的表;注意 删除表和修改表的操作一定要十分谨慎。在开发前期就最好把表结构商讨清除,防止开发过程中中途修改表结构或者删除表。