1. 背景
AI爆火了2年有余,但我仍是一个AI小白,最近零星在学,随手记录点内容供自己复习。
上次在Macbook Pro上安装了Stable Diffusion,体验了本地所心所欲地生成各种心仪的图片,完全没有任何限制的惬意。今天想使用Macbook Pro安装一个本地大语言模型体验一下,刚好在2024年4月18日,Meta在官网上宣布公布了旗下最新大模型Llama 3,并开放了80亿(8B)和700亿(70B)两个小参数版本,据说能力显著提升。遂开干。
- 为什么部署本地大模型
-
- 学习方便,私有材料不用发给外网,可以为公司私有化部署积累经验。
- 省钱,不需要单独买云主机,电脑放家里闲着也是闲着。
- 为什么选择llama3
-
- 最新款。科技这东西,用新不用旧。
- Meta出品,大厂品质有保证。
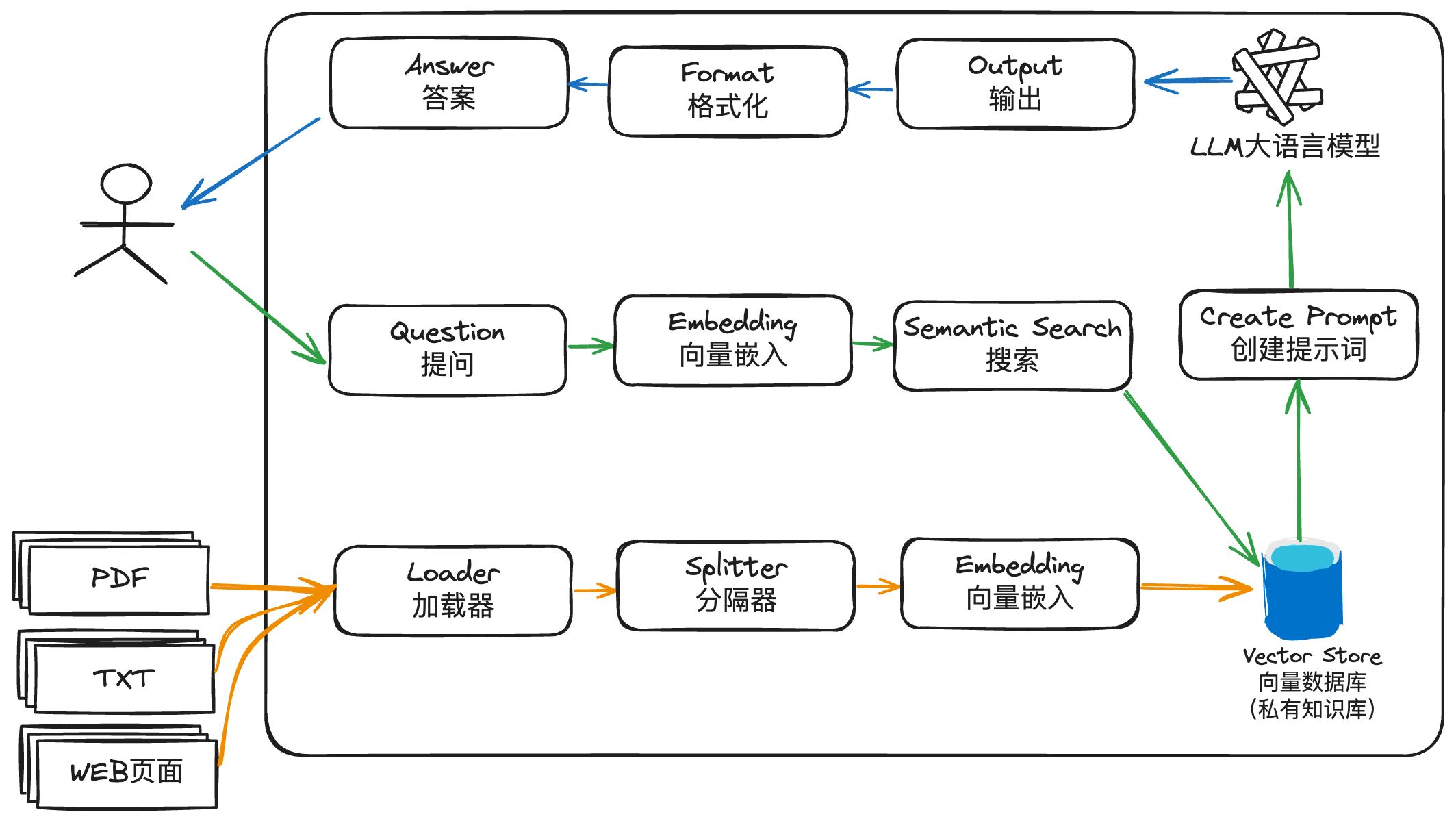
- 这是本次用到的技术框架
2. 环境
硬件:
型号:macbook pro 14寸
CPU:M2 MAX (12+38)
内存:96G
硬盘:8T
操作系统:maxOS 14.3.1
软件:
python 3.11
conda 24.3.0
llama3 8B 和 70B
此外还需要一些额外的特别网络软件,否则可能无法下载。如果想买个便宜的云主机自己部署这类软件,可私信我拿教程。
3. 安装llama3
登录官网:GitHub - ollama/ollama: Get up and running with Llama 3, Mistral, Gemma, and other large language models.
下载安装包:https://ollama.com/download/Ollama-darwin.zip
解压后运行:Ollama,初始化环境。
先体验8B模型,在命令行窗口运行(第一次运行会下载并安装模型):
ollama run llama3安装完成后,输出提示“end a message (/? for help),可以随便输入信息。
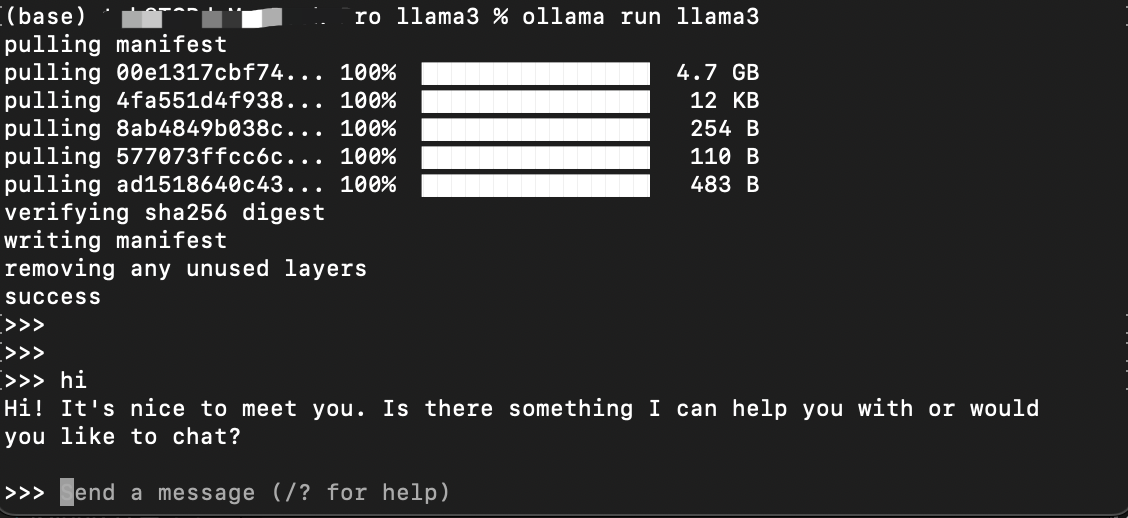

对中文支持还不错。
4. 使用langchain完成简单的RAG
上面对广州的介绍输出非常简单,如果想使用自己语料库来完成,比如公司内部有自己的知识库,需要结合公司的知识库来回答问题,那就可以试试langchain。
简单地说,langchain 是一个帮助在应用程序中使用大型语言模型(LLM)的编程框架,可极大简化对LLM的调用。
详细介绍可参考官方文档:Introduction | 🦜️🔗 LangChain。
快速开始:Quickstart | 🦜️🔗 LangChain。
安装:
conda install langchain -c conda-forge报错:“Verifying transaction: / WARNING conda.core.path_actions:verify(1055): Unable to create environments file. Path not writable.”
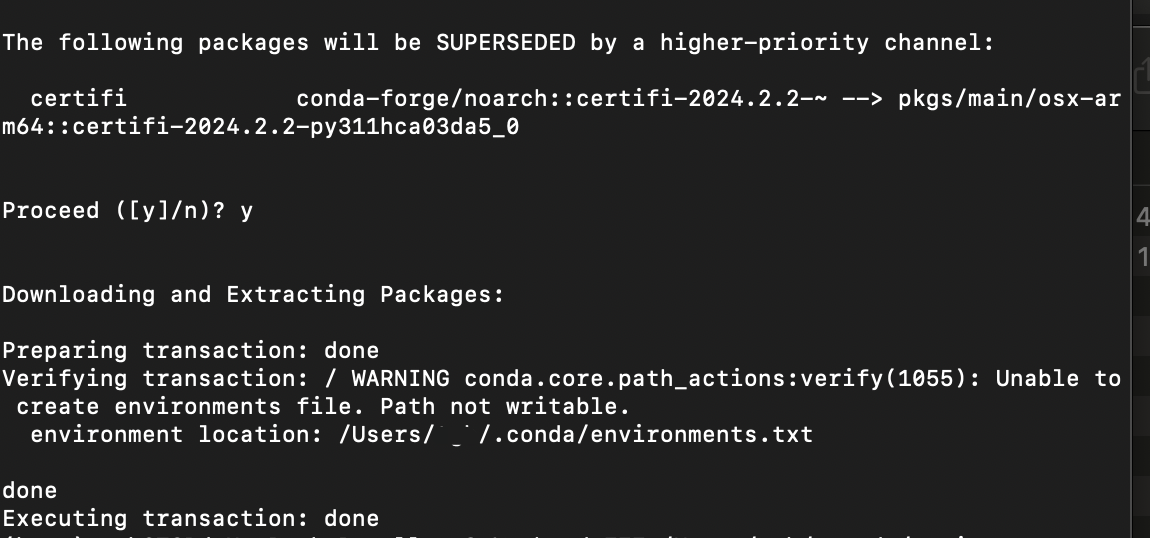
说明没有写权限,把对应文件owner修改为当前登录用户:
sudo chown -R $USER ~/.conda为了方便,使用PyCharm来写测试文件。
上面使用conda安装langchain的环境,所以新建项目的环境选择“Select existing”,再选择conda。
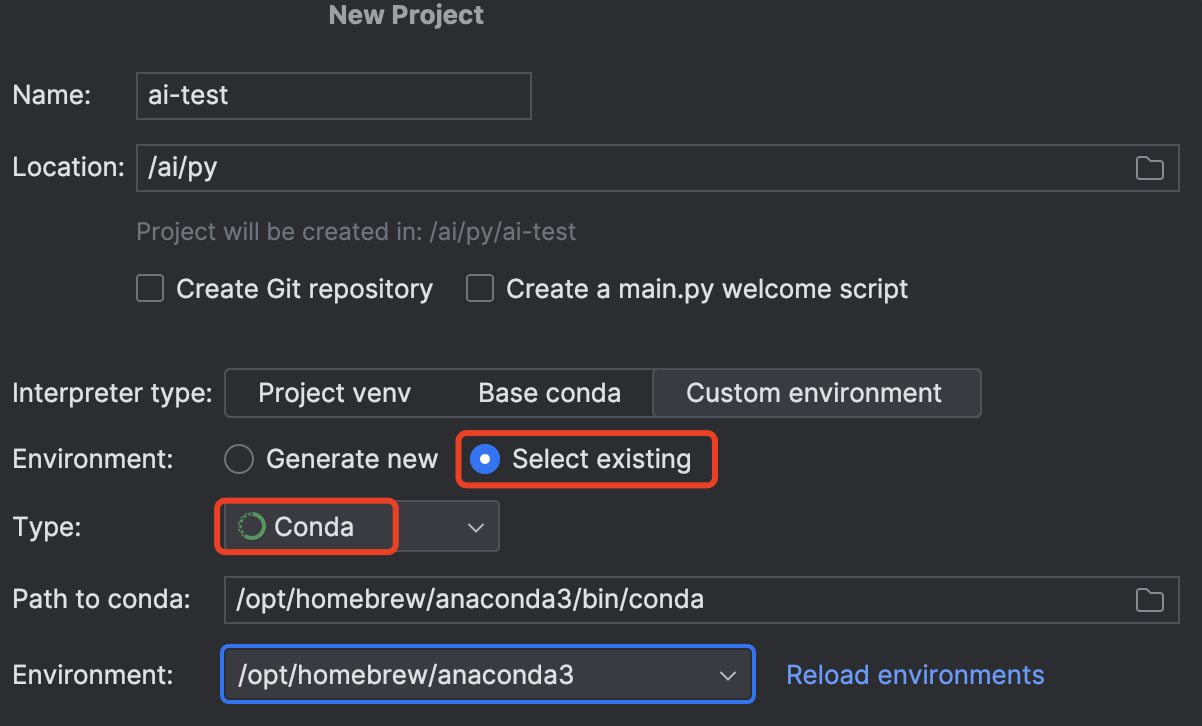
写一个python文件测试:
from langchain_community.llms import Ollama
llm = Ollama(model="llama3")
response = llm.invoke("使用中文介绍一下广州")
print(response)报错,提示要安装llama2,根据提示修改文件“/opt/homebrew/anaconda3/lib/python3.11/site-packages/langchain_community/embeddings/ollama.py”,使用llama3替换:
#model: str = "llama2"
model: str = "llama3"再次报错,提示要安装faiss,使用命令行安装:
pip install faiss-cpu终于跑成功,输出如下:
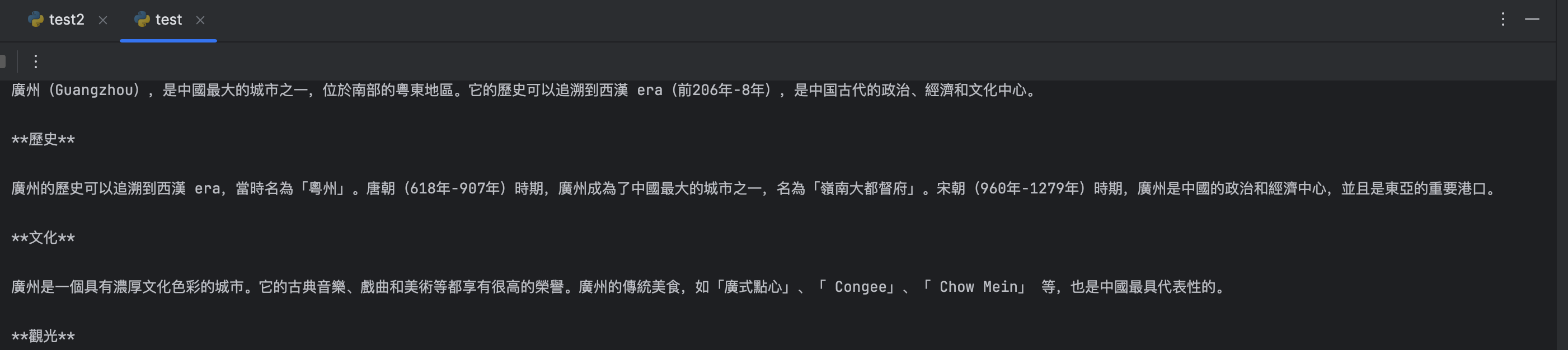
换成百度百科的语料,python文件如下:
from langchain_community.llms import Ollama
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
#加载文件
loader = WebBaseLoader("https://baike.baidu.com/item/%E5%B9%BF%E5%B7%9E%E5%B8%82/21808?fromtitle=%E5%B9%BF%E5%B7%9E&fromid=72101&fr=aladdin")
page_context = loader.load()
#分词
text_splitter = RecursiveCharacterTextSplitter()
split_documents = text_splitter.split_documents(page_context)
embeddings = OllamaEmbeddings()
#保存到向量库
vector = FAISS.from_documents(split_documents, embeddings)
retriever = vector.as_retriever()
#提示词模板
prompt = ChatPromptTemplate.from_template("""Answer question based on the provided context:
<context>{context}</context>
Question: {input}""")
#加载模型
llm = Ollama(model="llama3")
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever, document_chain)
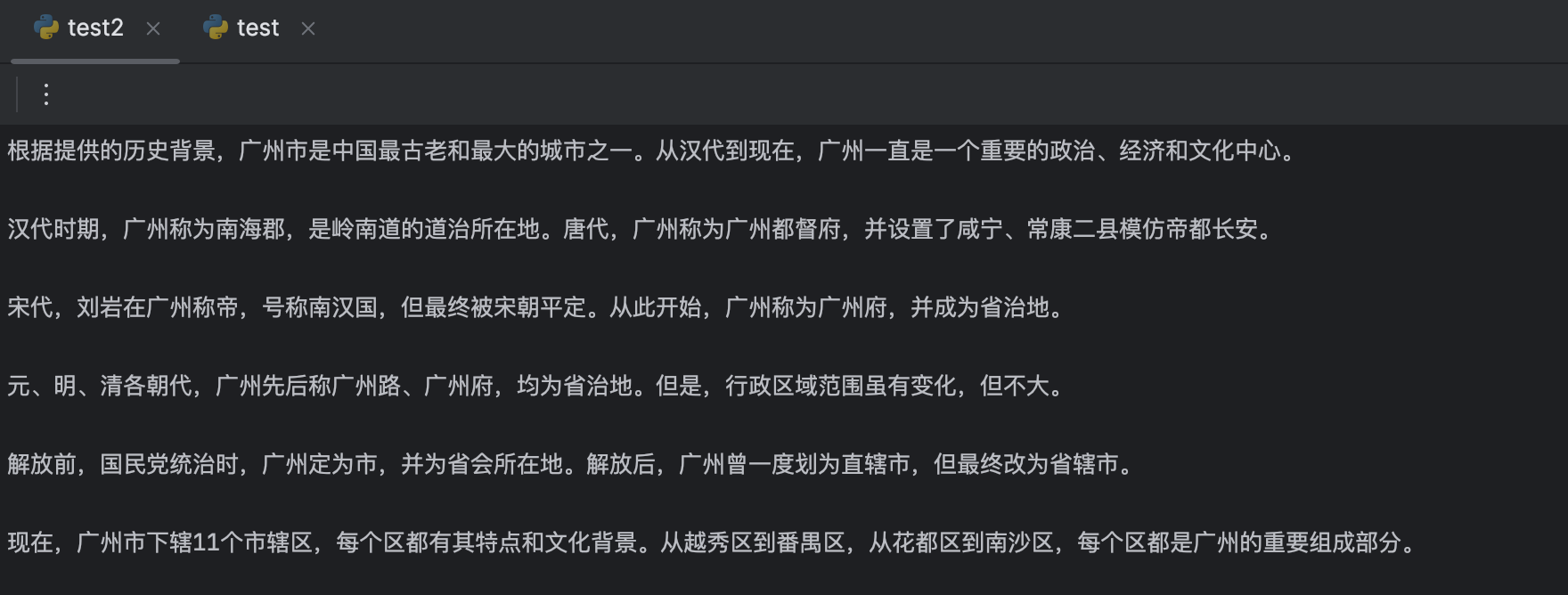
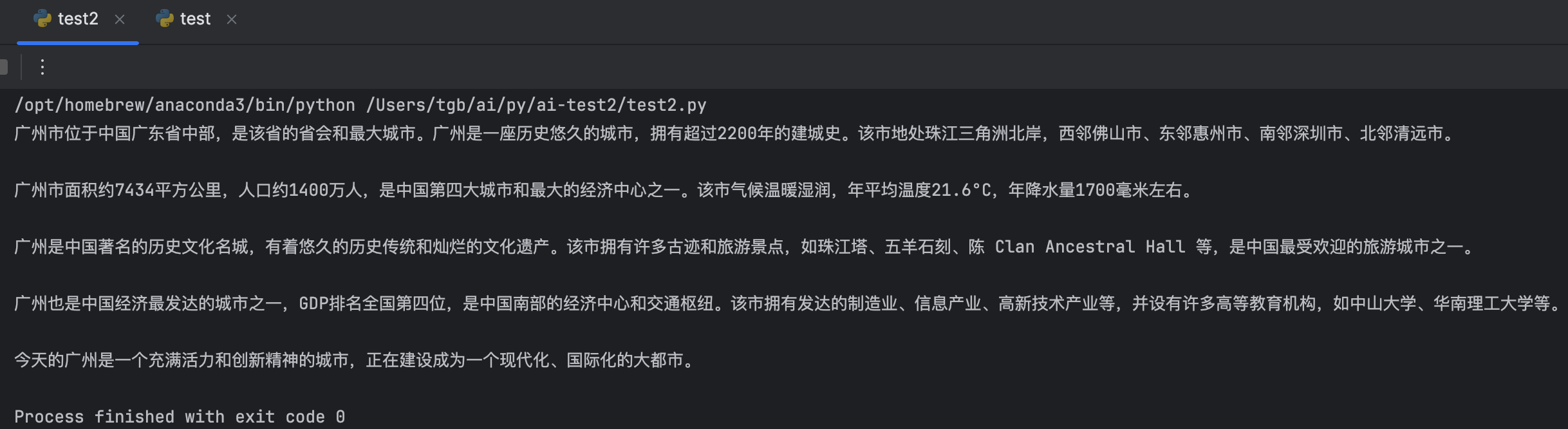
response = retrieval_chain.invoke({"input": "使用中文介绍广州"})
print(response["answer"])输出如下,可以看出输出的内容部分使用了百度百科最新的数据:
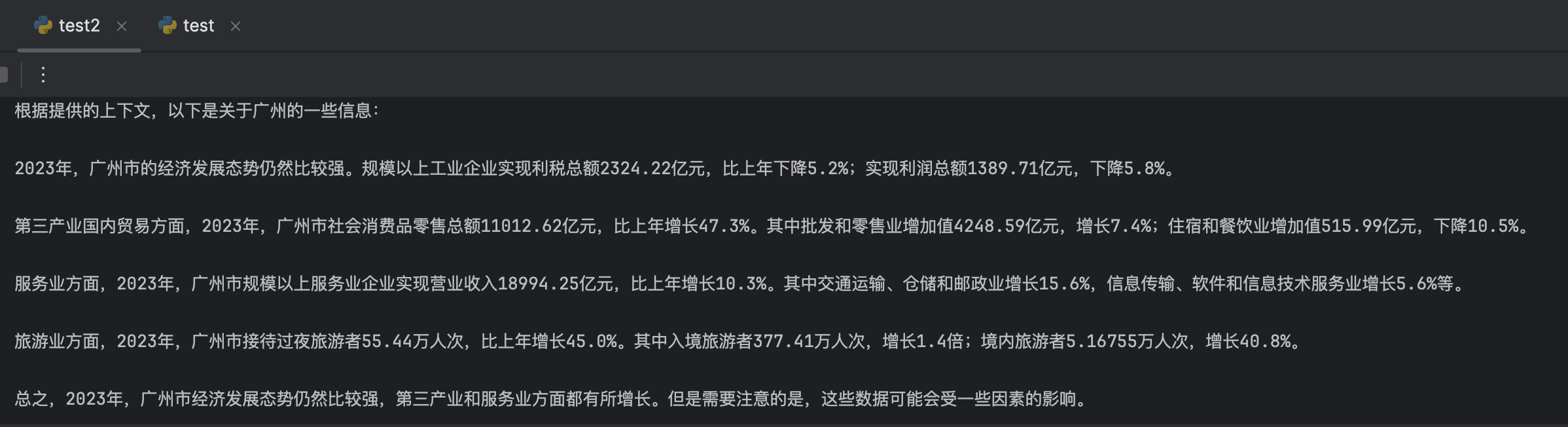
如果把提示词修改一下:“Answer question only based on the provided context”,就是里面加上限定词“only”,输出就只有百度百科的内容,如下:
5. 测试llama3 70b
如果内存足够大,可以选择安装70b模型。70b与8b的区别我现在只知道参数一个多一个少,对硬件要求不同,具体能力区别,还得后面去学习验证。
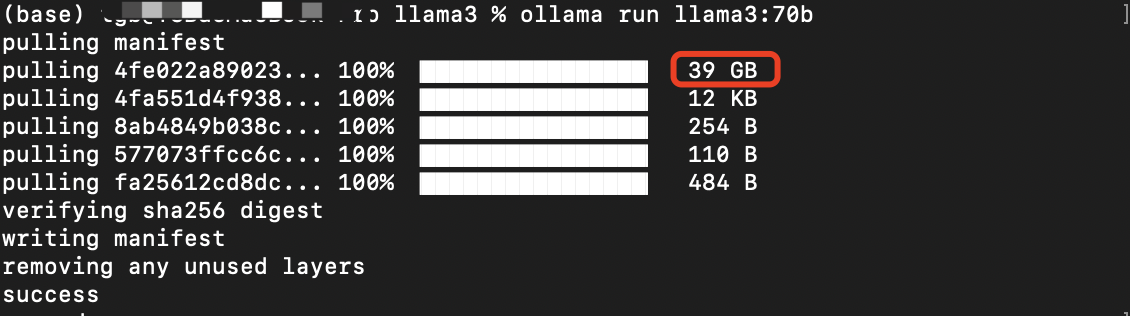
安装:
ollama run llama3:70b70b模型安装文件达到了39G多,而8b模型文件是4.7G。
安装完成后,使用命令行测试,输出:

70b模型通过langchain无专属语料输出:
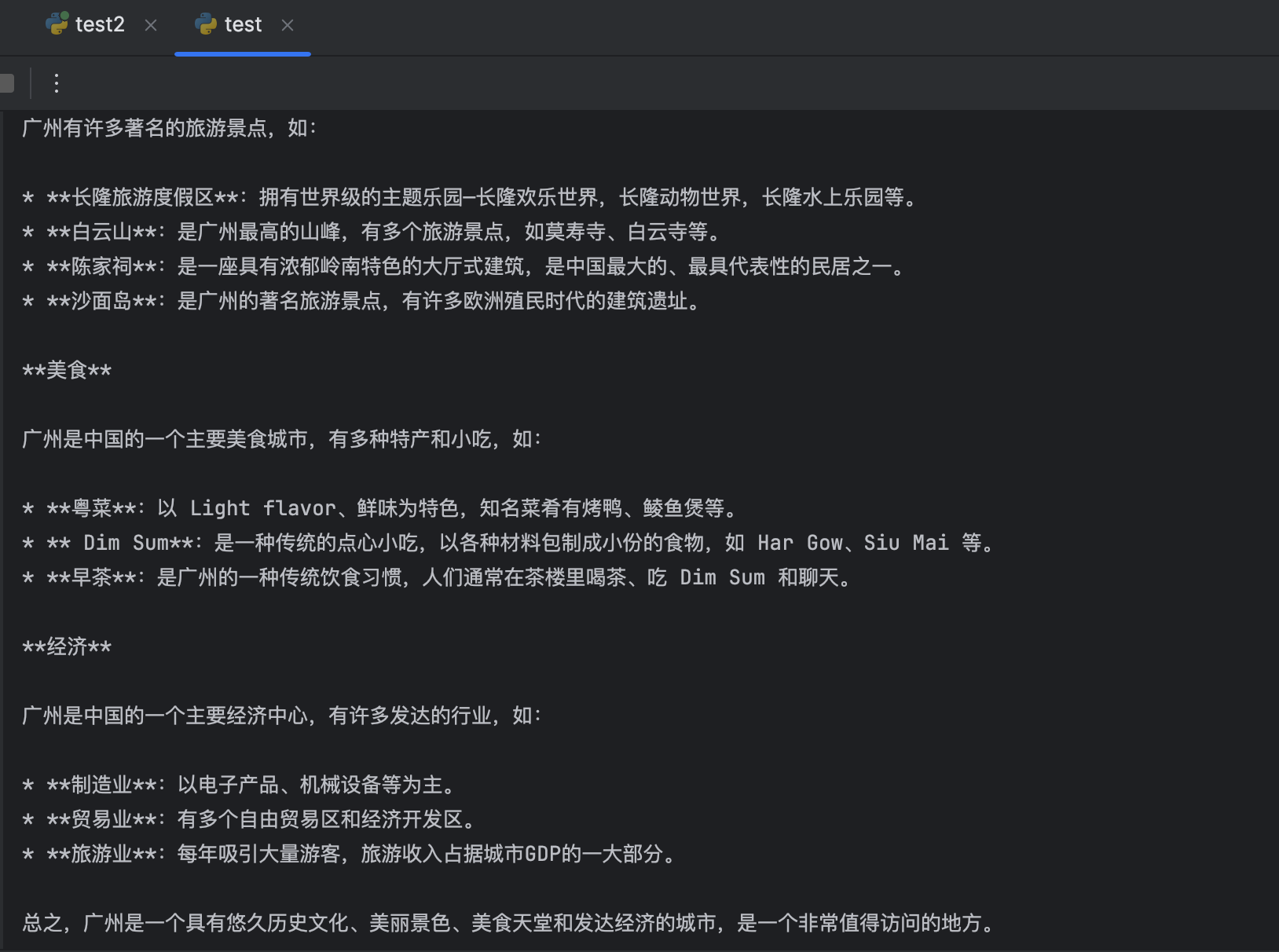
通过对比,在不使用专属语料库的情况下,70b模型比8b模型输出内容更为丰富。
70b模型通过langchain使用专属语料输出:
通过对比,使用专属语料库的情况下,70b模型和8b模型输出内容看不出明显差异。
6. 机器消耗
跑问题时,CPU基本空转,内存跑到64G,GPU打满,风扇呼呼响。
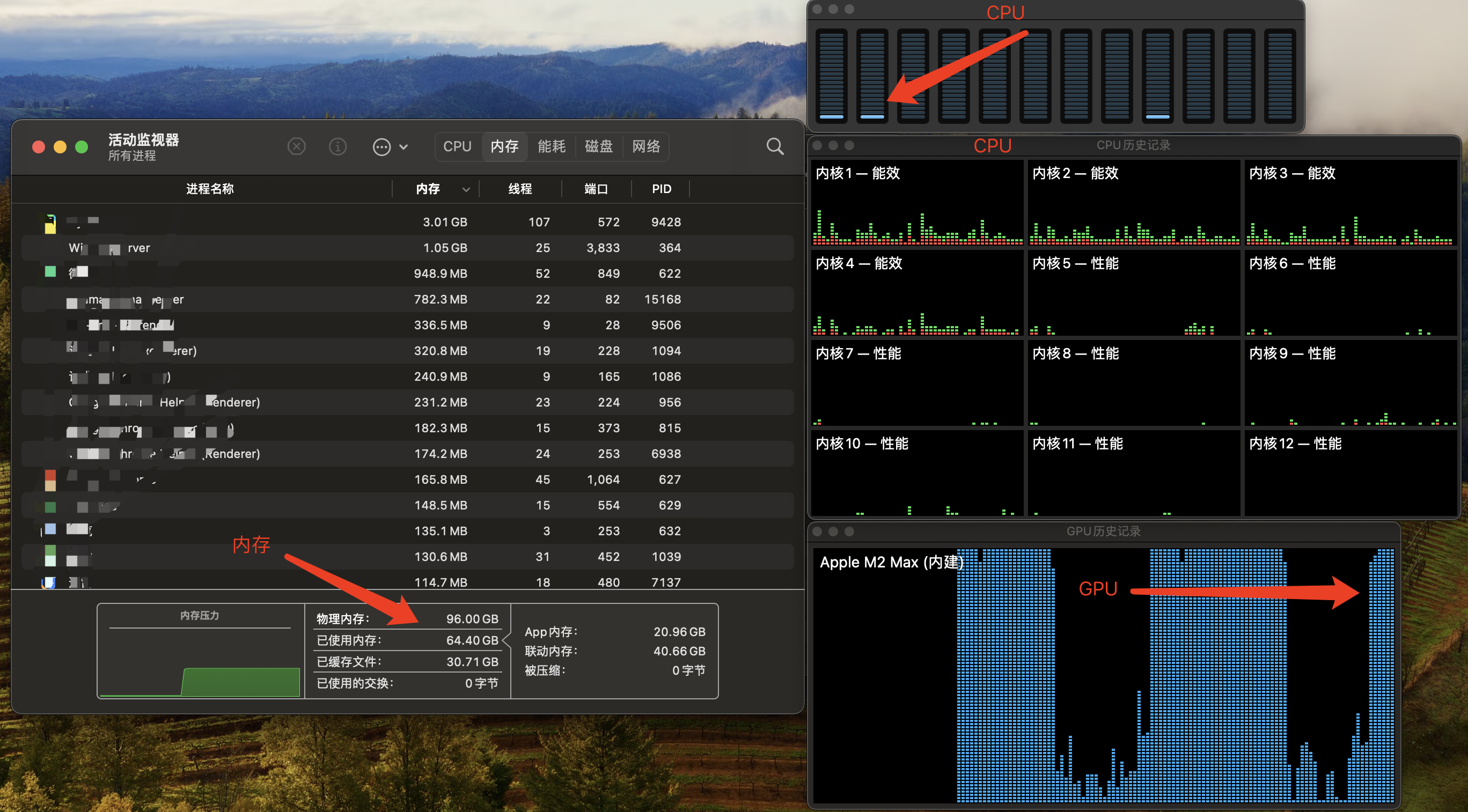
不跑问题时,内存在27G,GPU和CPU负载都很低,风扇不转。

7. 小结
Macbook pro 跑大模型在网上经常被人笑话,不过自己安装玩一玩,学一学,还是不错的,反正我自己用得挺好的。有空的时候再去云平台搞台N卡的机器试试,看到有些云主机平台还有免费试用3个月的带显卡的AI专用虚机供申请,过几天去薅羊毛看看效果。
这也是我第一次写python,果然比java方便。
最后,支付公司都有各种各样的技术文档,可以私有化部署LLM,再结合RAG,私有文档库,做成专有的专家知识库,不仅可以用于外部客户答疑,内部同学值班处理线上问题也是非常方便的。