文章目录
引言:Mamba
2024年04月29日16:06:08,今天开始记录mamba模块的学习与使用过程。
第一章:环境安装
亲测,根据下文的安装步骤,
即可成功!
使用代码Vision Mamba:https://github.com/hustvl/Vim
git clone https://github.com/hustvl/Vim.git
1.1安装教程
安装教程:下载好vision mamba后,根据下面的教程一步一步安装即可成功。
vision mamba 运行训练记录,解决bimamba_type错误
1.2问题总结
问题总结:遇见的问题可以参考这个链接,总结的比较全面。
Mamba 环境安装踩坑问题汇总及解决方法
1.3安装总结
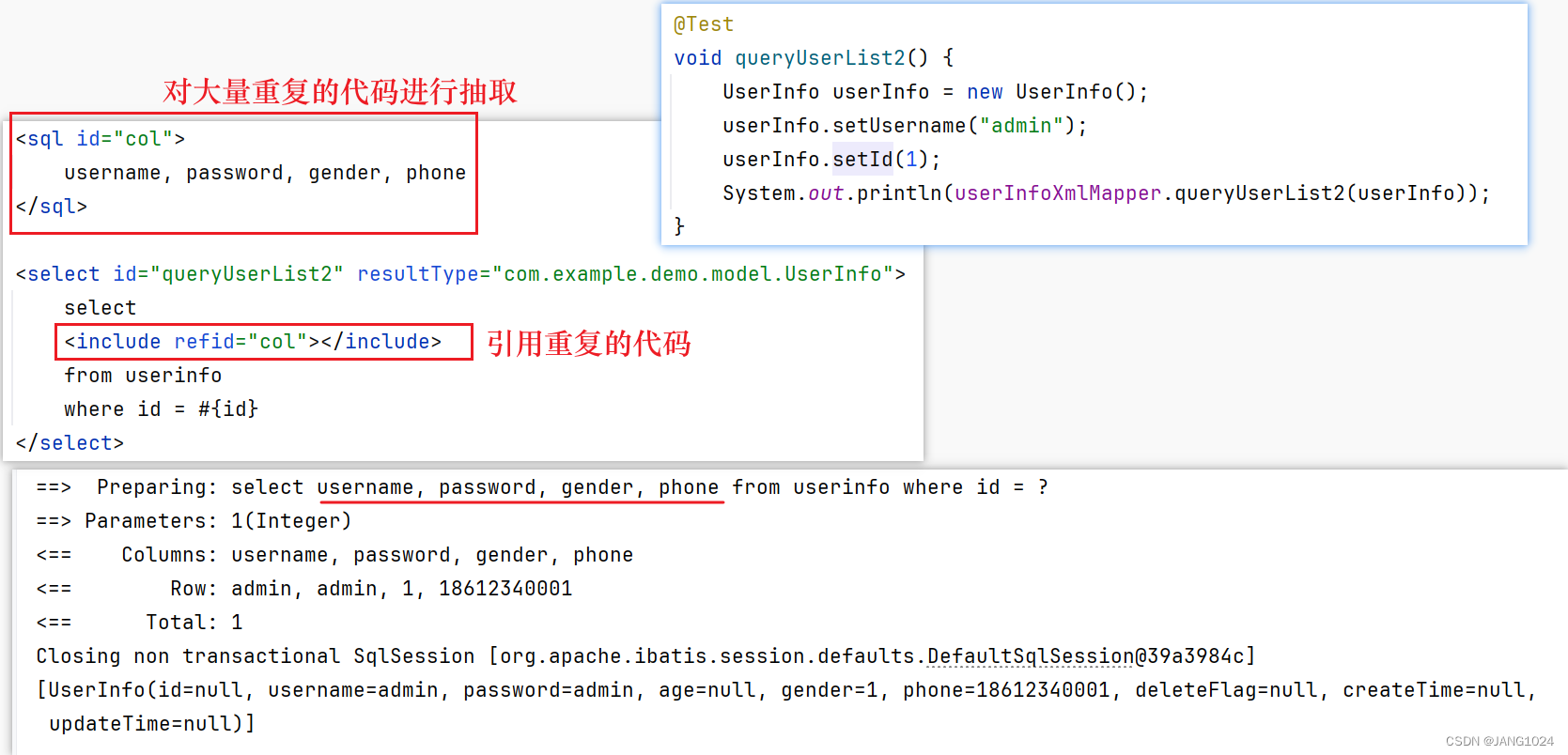
关键就是下载causal_conv1d和mamba_ssm,最好是下载离线的whl文件,然后再用pip进行安装。值得注意的一点就是要用官方项目里的mamba_ssm替换安装在conda环境里的mamba_ssm。
第二章:即插即用模块
2.1模块一:Mamba Vision
Github:https://github.com/hustvl/Vim;
下载代码,配置好环境后,用下面的代码替换Vim/vim/models_mamba.py,即可直接运行;
运行指令
python models_mamba.py
代码:models_mamba.py
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
import torch
import torch.nn as nn
from functools import partial
from torch import Tensor
from typing import Optional
from timm.models.vision_transformer import VisionTransformer, _cfg
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_, lecun_normal_
from timm.models.layers import DropPath, to_2tuple
from timm.models.vision_transformer import _load_weights
import math
from collections import namedtuple
from mamba_ssm.modules.mamba_simple import Mamba
from mamba_ssm.utils.generation import GenerationMixin
from mamba_ssm.utils.hf import load_config_hf, load_state_dict_hf
from rope import *
import random
try:
from mamba_ssm.ops.triton.layernorm import RMSNorm, layer_norm_fn, rms_norm_fn
except ImportError:
RMSNorm, layer_norm_fn, rms_norm_fn = None, None, None
__all__ = [
'vim_tiny_patch16_224', 'vim_small_patch16_224', 'vim_base_patch16_224',
'vim_tiny_patch16_384', 'vim_small_patch16_384', 'vim_base_patch16_384',
]
class PatchEmbed(nn.Module):
""" 2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, stride=16, in_chans=3, embed_dim=768, norm_layer=None, flatten=True):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = ((img_size[0] - patch_size[0]) // stride + 1, (img_size[1] - patch_size[1]) // stride + 1)
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.flatten = flatten
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
x = self.norm(x)
return x
class Block(nn.Module):
def __init__(
self, dim, mixer_cls, norm_cls=nn.LayerNorm, fused_add_norm=False, residual_in_fp32=False,drop_path=0.,
):
"""
Simple block wrapping a mixer class with LayerNorm/RMSNorm and residual connection"
This Block has a slightly different structure compared to a regular
prenorm Transformer block.
The standard block is: LN -> MHA/MLP -> Add.
[Ref: https://arxiv.org/abs/2002.04745]
Here we have: Add -> LN -> Mixer, returning both
the hidden_states (output of the mixer) and the residual.
This is purely for performance reasons, as we can fuse add and LayerNorm.
The residual needs to be provided (except for the very first block).
"""
super().__init__()
self.residual_in_fp32 = residual_in_fp32
self.fused_add_norm = fused_add_norm
self.mixer = mixer_cls(dim)
self.norm = norm_cls(dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
if self.fused_add_norm:
assert RMSNorm is not None, "RMSNorm import fails"
assert isinstance(
self.norm, (nn.LayerNorm, RMSNorm)
), "Only LayerNorm and RMSNorm are supported for fused_add_norm"
def forward(
self, hidden_states: Tensor, residual: Optional[Tensor] = None, inference_params=None
):
r"""Pass the input through the encoder layer.
Args:
hidden_states: the sequence to the encoder layer (required).
residual: hidden_states = Mixer(LN(residual))
"""
if not self.fused_add_norm:
if residual is None:
residual = hidden_states
else:
residual = residual + self.drop_path(hidden_states)
hidden_states = self.norm(residual.to(dtype=self.norm.weight.dtype))
if self.residual_in_fp32:
residual = residual.to(torch.float32)
else:
fused_add_norm_fn = rms_norm_fn if isinstance(self.norm, RMSNorm) else layer_norm_fn
if residual is None:
hidden_states, residual = fused_add_norm_fn(
hidden_states,
self.norm.weight,
self.norm.bias,
residual=residual,
prenorm=True,
residual_in_fp32=self.residual_in_fp32,
eps=self.norm.eps,
)
else:
hidden_states, residual = fused_add_norm_fn(
self.drop_path(hidden_states),
self.norm.weight,
self.norm.bias,
residual=residual,
prenorm=True,
residual_in_fp32=self.residual_in_fp32,
eps=self.norm.eps,
)
hidden_states = self.mixer(hidden_states, inference_params=inference_params)
return hidden_states, residual
def allocate_inference_cache(self, batch_size, max_seqlen, dtype=None, **kwargs):
return self.mixer.allocate_inference_cache(batch_size, max_seqlen, dtype=dtype, **kwargs)
def create_block(
d_model,
ssm_cfg=None,
norm_epsilon=1e-5,
drop_path=0.,
rms_norm=False,
residual_in_fp32=False,
fused_add_norm=False,
layer_idx=None,
device=None,
dtype=None,
if_bimamba=False,
bimamba_type="none",
if_devide_out=False,
init_layer_scale=None,
):
if if_bimamba:
bimamba_type = "v1"
if ssm_cfg is None:
ssm_cfg = {}
factory_kwargs = {"device": device, "dtype": dtype}
mixer_cls = partial(Mamba, layer_idx=layer_idx, bimamba_type=bimamba_type, if_devide_out=if_devide_out, init_layer_scale=init_layer_scale, **ssm_cfg, **factory_kwargs)
norm_cls = partial(
nn.LayerNorm if not rms_norm else RMSNorm, eps=norm_epsilon, **factory_kwargs
)
block = Block(
d_model,
mixer_cls,
norm_cls=norm_cls,
drop_path=drop_path,
fused_add_norm=fused_add_norm,
residual_in_fp32=residual_in_fp32,
)
block.layer_idx = layer_idx
return block
# https://github.com/huggingface/transformers/blob/c28d04e9e252a1a099944e325685f14d242ecdcd/src/transformers/models/gpt2/modeling_gpt2.py#L454
def _init_weights(
module,
n_layer,
initializer_range=0.02, # Now only used for embedding layer.
rescale_prenorm_residual=True,
n_residuals_per_layer=1, # Change to 2 if we have MLP
):
if isinstance(module, nn.Linear):
if module.bias is not None:
if not getattr(module.bias, "_no_reinit", False):
nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
nn.init.normal_(module.weight, std=initializer_range)
if rescale_prenorm_residual:
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
#
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
for name, p in module.named_parameters():
if name in ["out_proj.weight", "fc2.weight"]:
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
# We need to reinit p since this code could be called multiple times
# Having just p *= scale would repeatedly scale it down
nn.init.kaiming_uniform_(p, a=math.sqrt(5))
with torch.no_grad():
p /= math.sqrt(n_residuals_per_layer * n_layer)
def segm_init_weights(m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Conv2d):
# NOTE conv was left to pytorch default in my original init
lecun_normal_(m.weight)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.LayerNorm, nn.GroupNorm, nn.BatchNorm2d)):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
class VisionMamba(nn.Module):
def __init__(self,
img_size=224,
patch_size=16,
stride=16,
depth=24,
embed_dim=192,
channels=3,
num_classes=1000,
ssm_cfg=None,
drop_rate=0.,
drop_path_rate=0.1,
norm_epsilon: float = 1e-5,
rms_norm: bool = False,
initializer_cfg=None,
fused_add_norm=False,
residual_in_fp32=False,
device=None,
dtype=None,
ft_seq_len=None,
pt_hw_seq_len=14,
if_bidirectional=False,
final_pool_type='none',
if_abs_pos_embed=False,
if_rope=False,
if_rope_residual=False,
flip_img_sequences_ratio=-1.,
if_bimamba=False,
bimamba_type="none",
if_cls_token=False,
if_devide_out=False,
init_layer_scale=None,
use_double_cls_token=False,
use_middle_cls_token=False,
**kwargs):
factory_kwargs = {"device": device, "dtype": dtype}
# add factory_kwargs into kwargs
kwargs.update(factory_kwargs)
super().__init__()
self.residual_in_fp32 = residual_in_fp32
self.fused_add_norm = fused_add_norm
self.if_bidirectional = if_bidirectional
self.final_pool_type = final_pool_type
self.if_abs_pos_embed = if_abs_pos_embed
self.if_rope = if_rope
self.if_rope_residual = if_rope_residual
self.flip_img_sequences_ratio = flip_img_sequences_ratio
self.if_cls_token = if_cls_token
self.use_double_cls_token = use_double_cls_token
self.use_middle_cls_token = use_middle_cls_token
self.num_tokens = 1 if if_cls_token else 0
# pretrain parameters
self.num_classes = num_classes
self.d_model = self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, stride=stride, in_chans=channels, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
if if_cls_token:
if use_double_cls_token:
self.cls_token_head = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
self.cls_token_tail = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
self.num_tokens = 2
else:
self.cls_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
# self.num_tokens = 1
if if_abs_pos_embed:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, self.embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
if if_rope:
half_head_dim = embed_dim // 2
hw_seq_len = img_size // patch_size
self.rope = VisionRotaryEmbeddingFast(
dim=half_head_dim,
pt_seq_len=pt_hw_seq_len,
ft_seq_len=hw_seq_len
)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
# TODO: release this comment
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
# import ipdb;ipdb.set_trace()
inter_dpr = [0.0] + dpr
self.drop_path = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
# transformer blocks
self.layers = nn.ModuleList(
[
create_block(
embed_dim,
ssm_cfg=ssm_cfg,
norm_epsilon=norm_epsilon,
rms_norm=rms_norm,
residual_in_fp32=residual_in_fp32,
fused_add_norm=fused_add_norm,
layer_idx=i,
if_bimamba=if_bimamba,
bimamba_type=bimamba_type,
drop_path=inter_dpr[i],
if_devide_out=if_devide_out,
init_layer_scale=init_layer_scale,
**factory_kwargs,
)
for i in range(depth)
]
)
# output head
self.norm_f = (nn.LayerNorm if not rms_norm else RMSNorm)(
embed_dim, eps=norm_epsilon, **factory_kwargs
)
# self.pre_logits = nn.Identity()
# original init
self.patch_embed.apply(segm_init_weights)
self.head.apply(segm_init_weights)
if if_abs_pos_embed:
trunc_normal_(self.pos_embed, std=.02)
if if_cls_token:
if use_double_cls_token:
trunc_normal_(self.cls_token_head, std=.02)
trunc_normal_(self.cls_token_tail, std=.02)
else:
trunc_normal_(self.cls_token, std=.02)
# mamba init
self.apply(
partial(
_init_weights,
n_layer=depth,
**(initializer_cfg if initializer_cfg is not None else {}),
)
)
def allocate_inference_cache(self, batch_size, max_seqlen, dtype=None, **kwargs):
return {
i: layer.allocate_inference_cache(batch_size, max_seqlen, dtype=dtype, **kwargs)
for i, layer in enumerate(self.layers)
}
@torch.jit.ignore
def no_weight_decay(self):
return {"pos_embed", "cls_token", "dist_token", "cls_token_head", "cls_token_tail"}
@torch.jit.ignore()
def load_pretrained(self, checkpoint_path, prefix=""):
_load_weights(self, checkpoint_path, prefix)
def forward_features(self, x, inference_params=None, if_random_cls_token_position=False, if_random_token_rank=False):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add the dist_token
x = self.patch_embed(x)
B, M, _ = x.shape
if self.if_cls_token:
if self.use_double_cls_token:
cls_token_head = self.cls_token_head.expand(B, -1, -1)
cls_token_tail = self.cls_token_tail.expand(B, -1, -1)
token_position = [0, M + 1]
x = torch.cat((cls_token_head, x, cls_token_tail), dim=1)
M = x.shape[1]
else:
if self.use_middle_cls_token:
cls_token = self.cls_token.expand(B, -1, -1)
token_position = M // 2
# add cls token in the middle
x = torch.cat((x[:, :token_position, :], cls_token, x[:, token_position:, :]), dim=1)
elif if_random_cls_token_position:
cls_token = self.cls_token.expand(B, -1, -1)
token_position = random.randint(0, M)
x = torch.cat((x[:, :token_position, :], cls_token, x[:, token_position:, :]), dim=1)
print("token_position: ", token_position)
else:
cls_token = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
token_position = 0
x = torch.cat((cls_token, x), dim=1)
M = x.shape[1]
if self.if_abs_pos_embed:
# if new_grid_size[0] == self.patch_embed.grid_size[0] and new_grid_size[1] == self.patch_embed.grid_size[1]:
# x = x + self.pos_embed
# else:
# pos_embed = interpolate_pos_embed_online(
# self.pos_embed, self.patch_embed.grid_size, new_grid_size,0
# )
x = x + self.pos_embed
x = self.pos_drop(x)
if if_random_token_rank:
# 生成随机 shuffle 索引
shuffle_indices = torch.randperm(M)
if isinstance(token_position, list):
print("original value: ", x[0, token_position[0], 0], x[0, token_position[1], 0])
else:
print("original value: ", x[0, token_position, 0])
print("original token_position: ", token_position)
# 执行 shuffle
x = x[:, shuffle_indices, :]
if isinstance(token_position, list):
# 找到 cls token 在 shuffle 之后的新位置
new_token_position = [torch.where(shuffle_indices == token_position[i])[0].item() for i in range(len(token_position))]
token_position = new_token_position
else:
# 找到 cls token 在 shuffle 之后的新位置
token_position = torch.where(shuffle_indices == token_position)[0].item()
if isinstance(token_position, list):
print("new value: ", x[0, token_position[0], 0], x[0, token_position[1], 0])
else:
print("new value: ", x[0, token_position, 0])
print("new token_position: ", token_position)
if_flip_img_sequences = False
if self.flip_img_sequences_ratio > 0 and (self.flip_img_sequences_ratio - random.random()) > 1e-5:
x = x.flip([1])
if_flip_img_sequences = True
# mamba impl
residual = None
hidden_states = x
if not self.if_bidirectional:
for layer in self.layers:
if if_flip_img_sequences and self.if_rope:
hidden_states = hidden_states.flip([1])
if residual is not None:
residual = residual.flip([1])
# rope about
if self.if_rope:
hidden_states = self.rope(hidden_states)
if residual is not None and self.if_rope_residual:
residual = self.rope(residual)
if if_flip_img_sequences and self.if_rope:
hidden_states = hidden_states.flip([1])
if residual is not None:
residual = residual.flip([1])
hidden_states, residual = layer(
hidden_states, residual, inference_params=inference_params
)
else:
# get two layers in a single for-loop
for i in range(len(self.layers) // 2):
if self.if_rope:
hidden_states = self.rope(hidden_states)
if residual is not None and self.if_rope_residual:
residual = self.rope(residual)
hidden_states_f, residual_f = self.layers[i * 2](
hidden_states, residual, inference_params=inference_params
)
hidden_states_b, residual_b = self.layers[i * 2 + 1](
hidden_states.flip([1]), None if residual == None else residual.flip([1]), inference_params=inference_params
)
hidden_states = hidden_states_f + hidden_states_b.flip([1])
residual = residual_f + residual_b.flip([1])
if not self.fused_add_norm:
if residual is None:
residual = hidden_states
else:
residual = residual + self.drop_path(hidden_states)
hidden_states = self.norm_f(residual.to(dtype=self.norm_f.weight.dtype))
else:
# Set prenorm=False here since we don't need the residual
fused_add_norm_fn = rms_norm_fn if isinstance(self.norm_f, RMSNorm) else layer_norm_fn
hidden_states = fused_add_norm_fn(
self.drop_path(hidden_states),
self.norm_f.weight,
self.norm_f.bias,
eps=self.norm_f.eps,
residual=residual,
prenorm=False,
residual_in_fp32=self.residual_in_fp32,
)
# return only cls token if it exists
if self.if_cls_token:
if self.use_double_cls_token:
return (hidden_states[:, token_position[0], :] + hidden_states[:, token_position[1], :]) / 2
else:
if self.use_middle_cls_token:
return hidden_states[:, token_position, :]
elif if_random_cls_token_position:
return hidden_states[:, token_position, :]
else:
return hidden_states[:, token_position, :]
if self.final_pool_type == 'none':
return hidden_states[:, -1, :]
elif self.final_pool_type == 'mean':
return hidden_states.mean(dim=1)
elif self.final_pool_type == 'max':
return hidden_states
elif self.final_pool_type == 'all':
return hidden_states
else:
raise NotImplementedError
def forward(self, x, return_features=False, inference_params=None, if_random_cls_token_position=False, if_random_token_rank=False):
x = self.forward_features(x, inference_params, if_random_cls_token_position=if_random_cls_token_position, if_random_token_rank=if_random_token_rank)
if return_features:
return x
x = self.head(x)
if self.final_pool_type == 'max':
x = x.max(dim=1)[0]
return x
@register_model
def vim_tiny_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False, **kwargs):
model = VisionMamba(
patch_size=16, embed_dim=192, depth=24, rms_norm=True, residual_in_fp32=True, fused_add_norm=True, final_pool_type='mean', if_abs_pos_embed=True, if_rope=False, if_rope_residual=False, bimamba_type="v2", if_cls_token=True, if_devide_out=True, use_middle_cls_token=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="to.do",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def vim_tiny_patch16_stride8_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False, **kwargs):
model = VisionMamba(
patch_size=16, stride=8, embed_dim=192, depth=24, rms_norm=True, residual_in_fp32=True, fused_add_norm=True, final_pool_type='mean', if_abs_pos_embed=True, if_rope=False, if_rope_residual=False, bimamba_type="v2", if_cls_token=True, if_devide_out=True, use_middle_cls_token=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="to.do",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False, **kwargs):
model = VisionMamba(
patch_size=16, embed_dim=384, depth=24, rms_norm=True, residual_in_fp32=True, fused_add_norm=True, final_pool_type='mean', if_abs_pos_embed=True, if_rope=False, if_rope_residual=False, bimamba_type="v2", if_cls_token=True, if_devide_out=True, use_middle_cls_token=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="to.do",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def vim_small_patch16_stride8_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False, **kwargs):
model = VisionMamba(
patch_size=16, stride=8, embed_dim=384, depth=24, rms_norm=True, residual_in_fp32=True, fused_add_norm=True, final_pool_type='mean', if_abs_pos_embed=True, if_rope=False, if_rope_residual=False, bimamba_type="v2", if_cls_token=True, if_devide_out=True, use_middle_cls_token=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="to.do",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
if __name__ == '__main__':
# cuda or cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# 实例化模型得到分类结果
inputs = torch.randn(1, 3, 224, 224).to(device)
model = vim_small_patch16_stride8_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False).to(device)
print(model)
outputs = model(inputs)
print(outputs.shape)
# 实例化mamba模块,输入输出特征维度不变 B C H W
x = torch.rand(10, 16, 64, 128).to(device)
B, C, H, W = x.shape
print("输入特征维度:", x.shape)
x = x.view(B, C, H * W).permute(0, 2, 1)
print("维度变换:", x.shape)
mamba = create_block(d_model=C).to(device)
# mamba模型代码中返回的是一个元组:hidden_states, residual
hidden_states, residual = mamba(x)
x = hidden_states.permute(0, 2, 1).view(B, C, H, W)
print("输出特征维度:", x.shape)
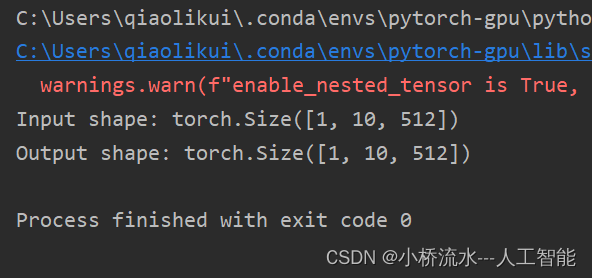
运行结果

2.2模块二:MambaIR
B站UP主:@箫张跋扈
视频地址:Mamba Back!一种来自于Mamba领域的即插即用模块(TimeMachine),用于时间序列任务!
下载好代码后,把下面的代码放到MambaIR.py文件中,然后再运行即可得到结果。
代码:MambaIR
# Code Implementation of the MambaIR Model
import warnings
warnings.filterwarnings("ignore")
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from typing import Optional, Callable
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from mamba_ssm.ops.selective_scan_interface import selective_scan_fn, selective_scan_ref
from einops import rearrange, repeat
"""
最近,选择性结构化状态空间模型,特别是改进版本的Mamba,在线性复杂度的远程依赖建模方面表现出了巨大的潜力。
然而,标准Mamba在低级视觉方面仍然面临一定的挑战,例如局部像素遗忘和通道冗余。在这项工作中,我们引入了局部增强和通道注意力来改进普通 Mamba。
通过这种方式,我们利用了局部像素相似性并减少了通道冗余。大量的实验证明了我们方法的优越性。
"""
NEG_INF = -1000000
class ChannelAttention(nn.Module):
"""Channel attention used in RCAN.
Args:
num_feat (int): Channel number of intermediate features.
squeeze_factor (int): Channel squeeze factor. Default: 16.
"""
def __init__(self, num_feat, squeeze_factor=16):
super(ChannelAttention, self).__init__()
self.attention = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(num_feat, num_feat // squeeze_factor, 1, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(num_feat // squeeze_factor, num_feat, 1, padding=0),
nn.Sigmoid())
def forward(self, x):
y = self.attention(x)
return x * y
class CAB(nn.Module):
def __init__(self, num_feat, is_light_sr= False, compress_ratio=3,squeeze_factor=30):
super(CAB, self).__init__()
if is_light_sr: # we use depth-wise conv for light-SR to achieve more efficient
self.cab = nn.Sequential(
nn.Conv2d(num_feat, num_feat, 3, 1, 1, groups=num_feat),
ChannelAttention(num_feat, squeeze_factor)
)
else: # for classic SR
self.cab = nn.Sequential(
nn.Conv2d(num_feat, num_feat // compress_ratio, 3, 1, 1),
nn.GELU(),
nn.Conv2d(num_feat // compress_ratio, num_feat, 3, 1, 1),
ChannelAttention(num_feat, squeeze_factor)
)
def forward(self, x):
return self.cab(x)
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class DynamicPosBias(nn.Module):
def __init__(self, dim, num_heads):
super().__init__()
self.num_heads = num_heads
self.pos_dim = dim // 4
self.pos_proj = nn.Linear(2, self.pos_dim)
self.pos1 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.pos_dim),
)
self.pos2 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.pos_dim)
)
self.pos3 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.num_heads)
)
def forward(self, biases):
pos = self.pos3(self.pos2(self.pos1(self.pos_proj(biases))))
return pos
def flops(self, N):
flops = N * 2 * self.pos_dim
flops += N * self.pos_dim * self.pos_dim
flops += N * self.pos_dim * self.pos_dim
flops += N * self.pos_dim * self.num_heads
return flops
class Attention(nn.Module):
r""" Multi-head self attention module with dynamic position bias.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.,
position_bias=True):
super().__init__()
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.position_bias = position_bias
if self.position_bias:
self.pos = DynamicPosBias(self.dim // 4, self.num_heads)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, H, W, mask=None):
"""
Args:
x: input features with shape of (num_groups*B, N, C)
mask: (0/-inf) mask with shape of (num_groups, Gh*Gw, Gh*Gw) or None
H: height of each group
W: width of each group
"""
group_size = (H, W)
B_, N, C = x.shape
assert H * W == N
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4).contiguous()
q, k, v = qkv[0], qkv[1], qkv[2]
q = q * self.scale
attn = (q @ k.transpose(-2, -1)) # (B_, self.num_heads, N, N), N = H*W
if self.position_bias:
# generate mother-set
position_bias_h = torch.arange(1 - group_size[0], group_size[0], device=attn.device)
position_bias_w = torch.arange(1 - group_size[1], group_size[1], device=attn.device)
biases = torch.stack(torch.meshgrid([position_bias_h, position_bias_w])) # 2, 2Gh-1, 2W2-1
biases = biases.flatten(1).transpose(0, 1).contiguous().float() # (2h-1)*(2w-1) 2
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(group_size[0], device=attn.device)
coords_w = torch.arange(group_size[1], device=attn.device)
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Gh, Gw
coords_flatten = torch.flatten(coords, 1) # 2, Gh*Gw
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Gh*Gw, Gh*Gw
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Gh*Gw, Gh*Gw, 2
relative_coords[:, :, 0] += group_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += group_size[1] - 1
relative_coords[:, :, 0] *= 2 * group_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Gh*Gw, Gh*Gw
pos = self.pos(biases) # 2Gh-1 * 2Gw-1, heads
# select position bias
relative_position_bias = pos[relative_position_index.view(-1)].view(
group_size[0] * group_size[1], group_size[0] * group_size[1], -1) # Gh*Gw,Gh*Gw,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Gh*Gw, Gh*Gw
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nP = mask.shape[0]
attn = attn.view(B_ // nP, nP, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(
0) # (B, nP, nHead, N, N)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class SS2D(nn.Module):
def __init__(
self,
d_model,
d_state=16,
d_conv=3,
expand=2.,
dt_rank="auto",
dt_min=0.001,
dt_max=0.1,
dt_init="random",
dt_scale=1.0,
dt_init_floor=1e-4,
dropout=0.,
conv_bias=True,
bias=False,
device=None,
dtype=None,
**kwargs,
):
factory_kwargs = {"device": device, "dtype": dtype}
super().__init__()
self.d_model = d_model
self.d_state = d_state
self.d_conv = d_conv
self.expand = expand
self.d_inner = int(self.expand * self.d_model)
self.dt_rank = math.ceil(self.d_model / 16) if dt_rank == "auto" else dt_rank
self.in_proj = nn.Linear(self.d_model, self.d_inner * 2, bias=bias, **factory_kwargs)
self.conv2d = nn.Conv2d(
in_channels=self.d_inner,
out_channels=self.d_inner,
groups=self.d_inner,
bias=conv_bias,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
**factory_kwargs,
)
self.act = nn.SiLU()
self.x_proj = (
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
)
self.x_proj_weight = nn.Parameter(torch.stack([t.weight for t in self.x_proj], dim=0)) # (K=4, N, inner)
del self.x_proj
self.dt_projs = (
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor,
**factory_kwargs),
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor,
**factory_kwargs),
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor,
**factory_kwargs),
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor,
**factory_kwargs),
)
self.dt_projs_weight = nn.Parameter(torch.stack([t.weight for t in self.dt_projs], dim=0)) # (K=4, inner, rank)
self.dt_projs_bias = nn.Parameter(torch.stack([t.bias for t in self.dt_projs], dim=0)) # (K=4, inner)
del self.dt_projs
self.A_logs = self.A_log_init(self.d_state, self.d_inner, copies=4, merge=True) # (K=4, D, N)
self.Ds = self.D_init(self.d_inner, copies=4, merge=True) # (K=4, D, N)
self.selective_scan = selective_scan_fn
self.out_norm = nn.LayerNorm(self.d_inner)
self.out_proj = nn.Linear(self.d_inner, self.d_model, bias=bias, **factory_kwargs)
self.dropout = nn.Dropout(dropout) if dropout > 0. else None
@staticmethod
def dt_init(dt_rank, d_inner, dt_scale=1.0, dt_init="random", dt_min=0.001, dt_max=0.1, dt_init_floor=1e-4,
**factory_kwargs):
dt_proj = nn.Linear(dt_rank, d_inner, bias=True, **factory_kwargs)
# Initialize special dt projection to preserve variance at initialization
dt_init_std = dt_rank ** -0.5 * dt_scale
if dt_init == "constant":
nn.init.constant_(dt_proj.weight, dt_init_std)
elif dt_init == "random":
nn.init.uniform_(dt_proj.weight, -dt_init_std, dt_init_std)
else:
raise NotImplementedError
# Initialize dt bias so that F.softplus(dt_bias) is between dt_min and dt_max
dt = torch.exp(
torch.rand(d_inner, **factory_kwargs) * (math.log(dt_max) - math.log(dt_min))
+ math.log(dt_min)
).clamp(min=dt_init_floor)
# Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759
inv_dt = dt + torch.log(-torch.expm1(-dt))
with torch.no_grad():
dt_proj.bias.copy_(inv_dt)
# Our initialization would set all Linear.bias to zero, need to mark this one as _no_reinit
dt_proj.bias._no_reinit = True
return dt_proj
@staticmethod
def A_log_init(d_state, d_inner, copies=1, device=None, merge=True):
# S4D real initialization
A = repeat(
torch.arange(1, d_state + 1, dtype=torch.float32, device=device),
"n -> d n",
d=d_inner,
).contiguous()
A_log = torch.log(A) # Keep A_log in fp32
if copies > 1:
A_log = repeat(A_log, "d n -> r d n", r=copies)
if merge:
A_log = A_log.flatten(0, 1)
A_log = nn.Parameter(A_log)
A_log._no_weight_decay = True
return A_log
@staticmethod
def D_init(d_inner, copies=1, device=None, merge=True):
# D "skip" parameter
D = torch.ones(d_inner, device=device)
if copies > 1:
D = repeat(D, "n1 -> r n1", r=copies)
if merge:
D = D.flatten(0, 1)
D = nn.Parameter(D) # Keep in fp32
D._no_weight_decay = True
return D
def forward_core(self, x: torch.Tensor):
B, C, H, W = x.shape
L = H * W
K = 4
x_hwwh = torch.stack([x.view(B, -1, L), torch.transpose(x, dim0=2, dim1=3).contiguous().view(B, -1, L)], dim=1).view(B, 2, -1, L)
xs = torch.cat([x_hwwh, torch.flip(x_hwwh, dims=[-1])], dim=1) # (1, 4, 192, 3136)
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs.view(B, K, -1, L), self.x_proj_weight)
dts, Bs, Cs = torch.split(x_dbl, [self.dt_rank, self.d_state, self.d_state], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts.view(B, K, -1, L), self.dt_projs_weight)
xs = xs.float().view(B, -1, L)
dts = dts.contiguous().float().view(B, -1, L) # (b, k * d, l)
Bs = Bs.float().view(B, K, -1, L)
Cs = Cs.float().view(B, K, -1, L) # (b, k, d_state, l)
Ds = self.Ds.float().view(-1)
As = -torch.exp(self.A_logs.float()).view(-1, self.d_state)
dt_projs_bias = self.dt_projs_bias.float().view(-1) # (k * d)
out_y = self.selective_scan(
xs, dts,
As, Bs, Cs, Ds, z=None,
delta_bias=dt_projs_bias,
delta_softplus=True,
return_last_state=False,
).view(B, K, -1, L)
assert out_y.dtype == torch.float
inv_y = torch.flip(out_y[:, 2:4], dims=[-1]).view(B, 2, -1, L)
wh_y = torch.transpose(out_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
invwh_y = torch.transpose(inv_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
return out_y[:, 0], inv_y[:, 0], wh_y, invwh_y
def forward(self, x: torch.Tensor, **kwargs):
B, H, W, C = x.shape
xz = self.in_proj(x)
x, z = xz.chunk(2, dim=-1)
x = x.permute(0, 3, 1, 2).contiguous()
x = self.act(self.conv2d(x))
y1, y2, y3, y4 = self.forward_core(x)
assert y1.dtype == torch.float32
y = y1 + y2 + y3 + y4
y = torch.transpose(y, dim0=1, dim1=2).contiguous().view(B, H, W, -1)
y = self.out_norm(y)
y = y * F.silu(z)
out = self.out_proj(y)
if self.dropout is not None:
out = self.dropout(out)
return out
class VSSBlock(nn.Module):
def __init__(
self,
hidden_dim: int = 0,
drop_path: float = 0,
norm_layer: Callable[..., torch.nn.Module] = partial(nn.LayerNorm, eps=1e-6),
attn_drop_rate: float = 0,
d_state: int = 16,
expand: float = 2.,
is_light_sr: bool = False,
**kwargs,
):
super().__init__()
self.ln_1 = norm_layer(hidden_dim)
self.self_attention = SS2D(d_model=hidden_dim, d_state=d_state,expand=expand,dropout=attn_drop_rate, **kwargs)
self.drop_path = DropPath(drop_path)
self.skip_scale= nn.Parameter(torch.ones(hidden_dim))
self.conv_blk = CAB(hidden_dim,is_light_sr)
self.ln_2 = nn.LayerNorm(hidden_dim)
self.skip_scale2 = nn.Parameter(torch.ones(hidden_dim))
def forward(self, input, x_size):
# x [B,HW,C]
B, L, C = input.shape
input = input.view(B, *x_size, C).contiguous() # [B,H,W,C]
x = self.ln_1(input)
x = input*self.skip_scale + self.drop_path(self.self_attention(x))
x = x*self.skip_scale2 + self.conv_blk(self.ln_2(x).permute(0, 3, 1, 2).contiguous()).permute(0, 2, 3, 1).contiguous()
x = x.view(B, -1, C).contiguous()
return x
if __name__ == '__main__':
# 初始化VSSBlock模块,hidden_dim为128
block = VSSBlock(hidden_dim=128, drop_path=0.1, attn_drop_rate=0.1, d_state=16, expand=2.0, is_light_sr=False)
# 将模块转移到合适的设备上
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
block = block.to(device)
# 生成随机输入张量,尺寸为[B, H*W, C],这里模拟的是批次大小为4,每个图像的尺寸是32x32,通道数为128
B, H, W, C = 4, 32, 32, 128
input_tensor = torch.rand(B, H * W, C).to(device)
# 计算输出
output_tensor = block(input_tensor, (H, W))
# 打印输入和输出张量的尺寸
print("Input tensor size:", input_tensor.size())
print("Output tensor size:", output_tensor.size())
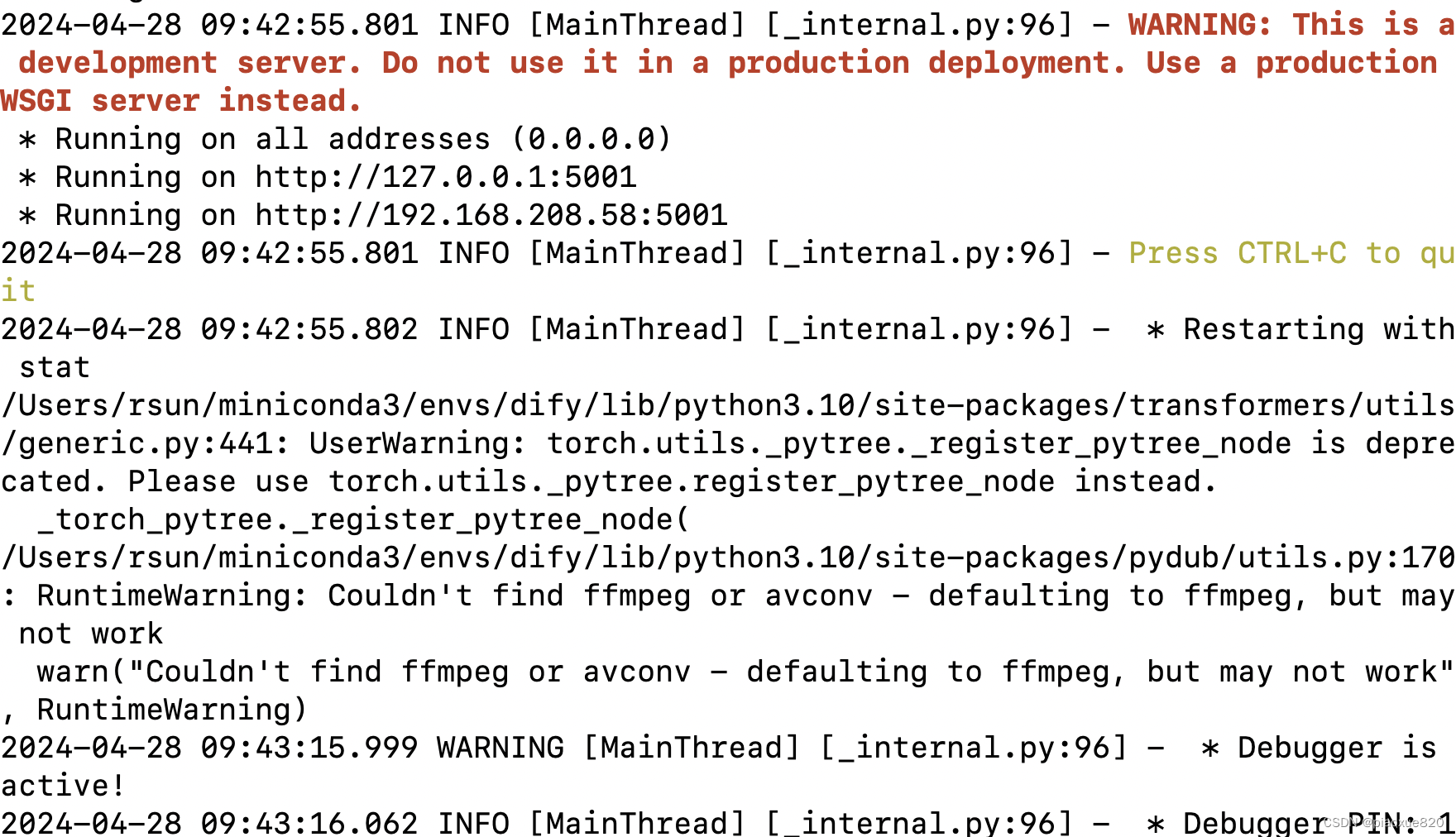
运行结果

第三章:经典文献阅读与追踪
Mamba原文:Mamba: Linear-Time Sequence Modeling with Selective State Spaces
经典论文
- Vision Mamba@Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
- MambaIR@MambaIR: A Simple Baseline for Image Restoration with State-Space Model
- U-Mamba@U-Mamba: Enhancing Long-range Dependency for Biomedical Image Segmentation
Mamba系列论文追踪
该Github链接会分享不同领域基于Mamba结构的论文
Mamba_State_Space_Model_Paper_List Public:https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List
第四章:Mamba理论与分析
未完待续...
第五章:总结和展望
- 2024年04月29日16:57:45,今天已完成环境的安装与即插即用模块实例化和相关论文的分享;在近期会充分学习Mamba后对其理论进行分享,帮助快速简要理解原文Mamba相关理论。