目录
前言
粉丝及官方意见说明
第十七章一些学习笔记
第十七章一些操作方法
聚类分析
均值聚类法(快速聚类法)
假设数据
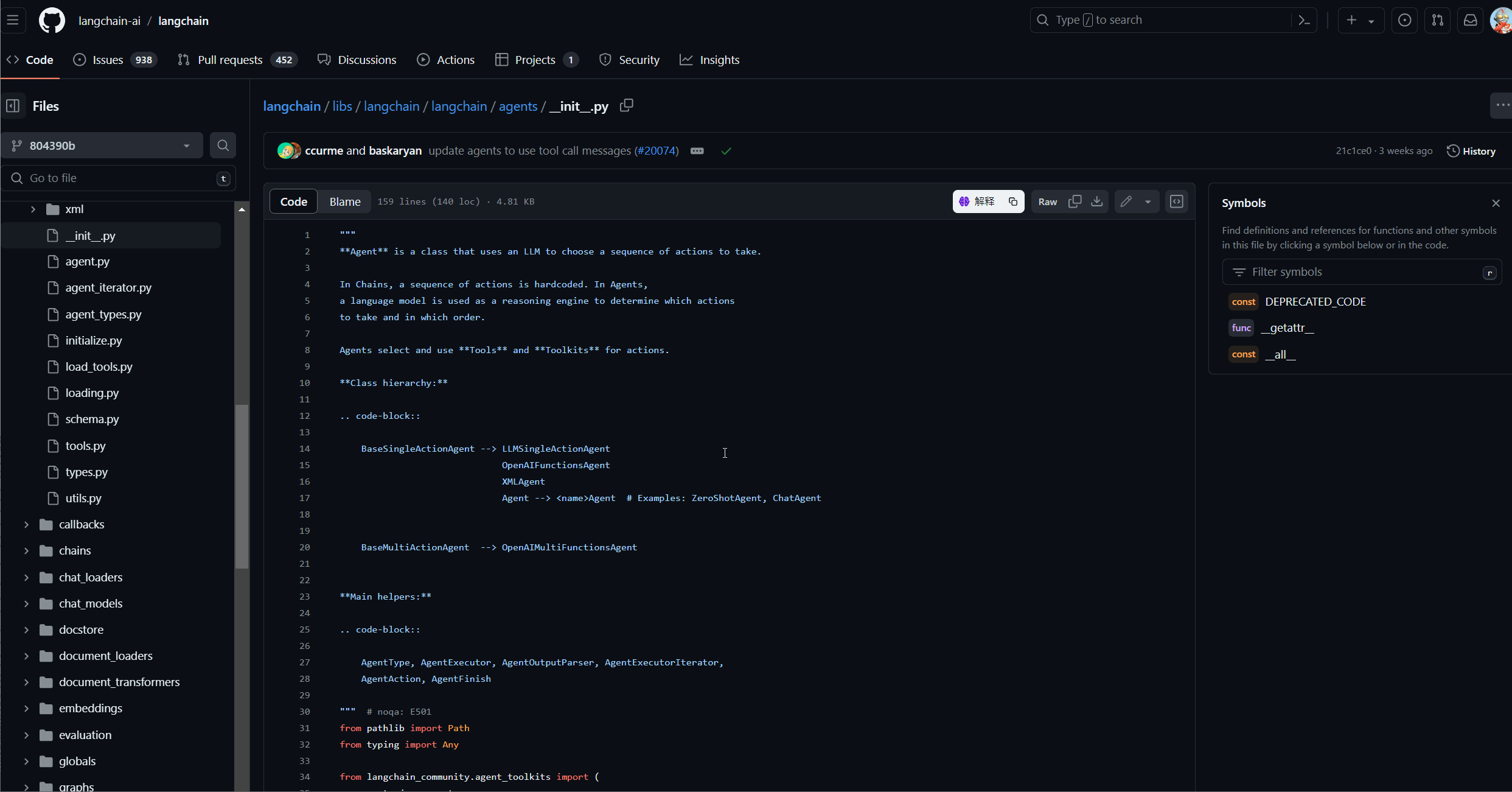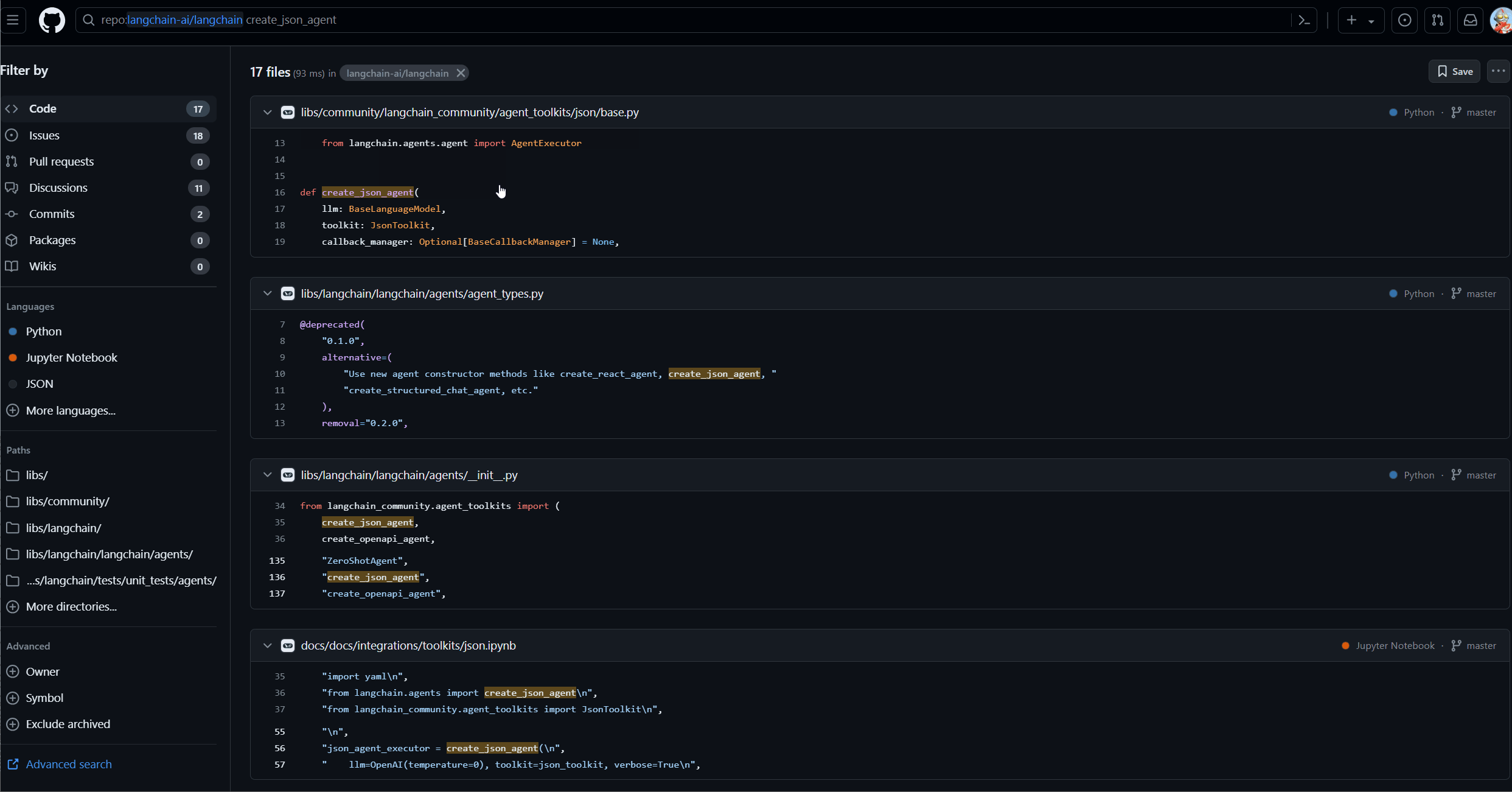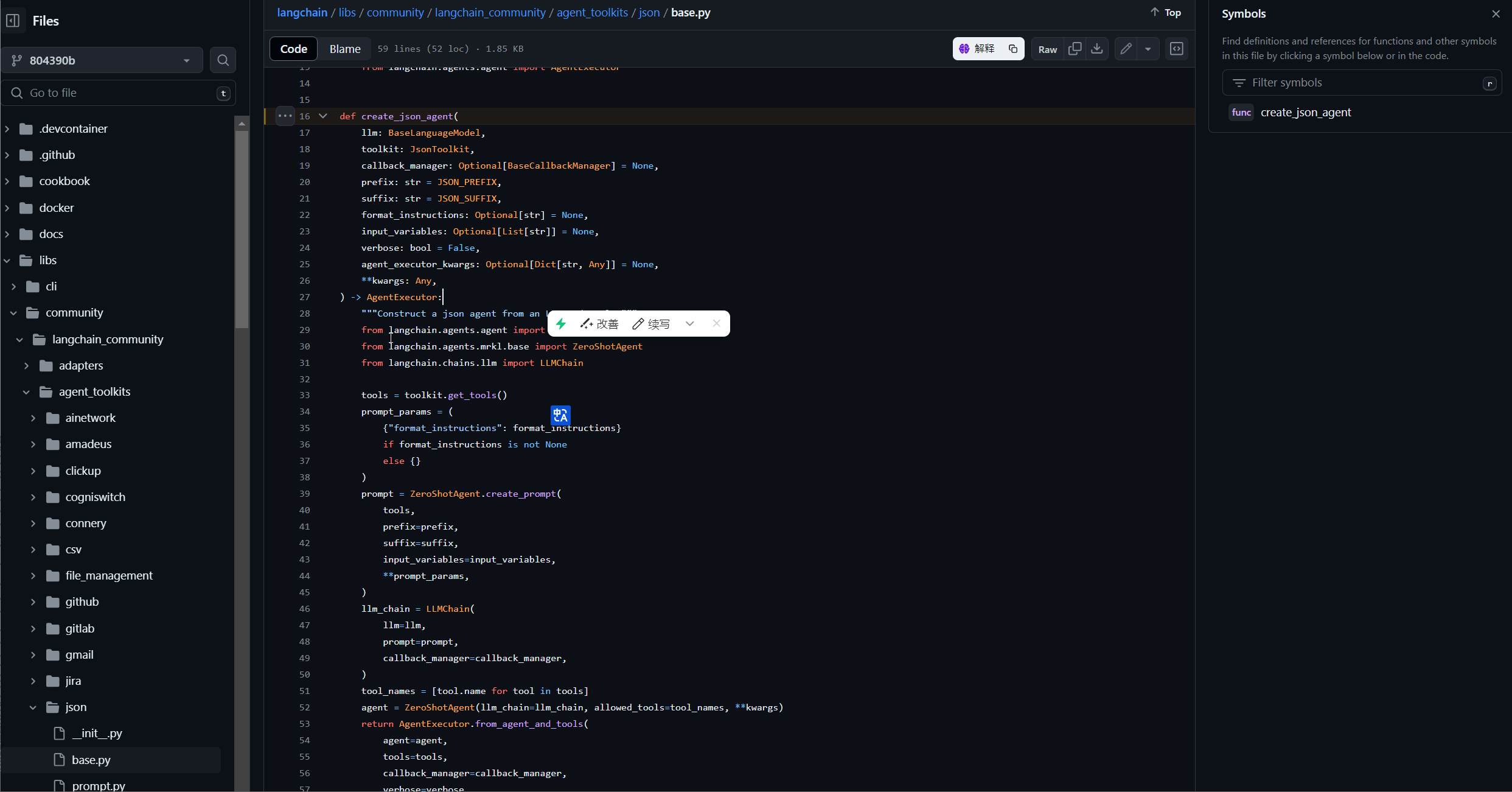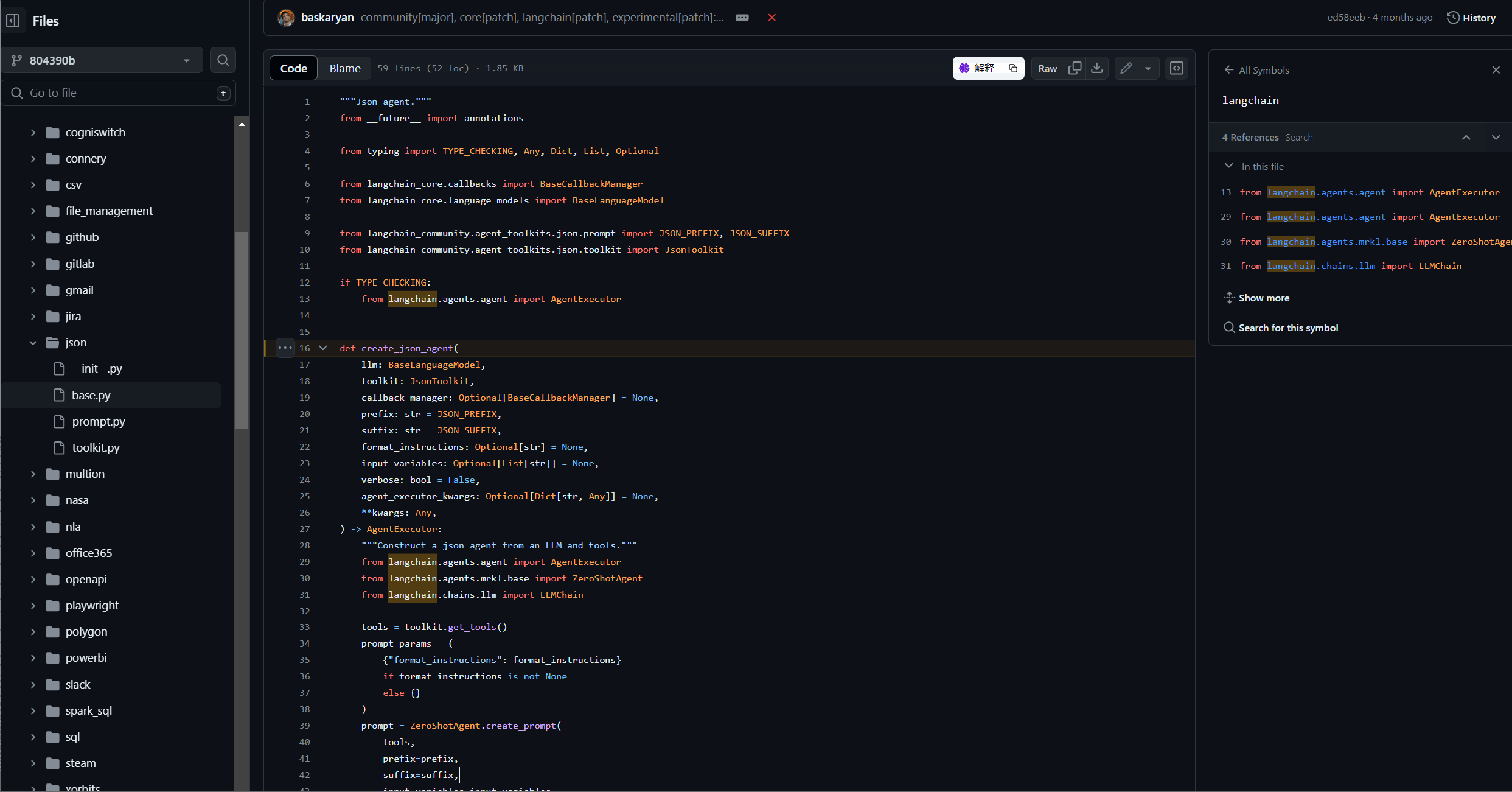
预分析(描述统计)
先将除了ID变量的每个变量除以其最大值进行标准化操作
具体操作
结果解释
聚类结果的验证与自动优化
利用ANOVA复选框比较类别间的结果
结果解释
聚类结果的自动优化
层次聚类法
假设数据
具体操作
结果解释
改进聚类结果
结果分析
两步聚类法
数据假设
具体操作
结束语
前言
#心静方能学习
#本期内容:聚类分析
#由于导师最近布置了学习SPSS这款软件的任务,因此想来平台和大家一起交流下学习经验,这期推送内容接上一次高级教程第十六章的学习笔记,希望能得到一些指正和帮助~
粉丝及官方意见说明
#针对官方爸爸的意见说的推送缺乏操作过程的数据案例文件澄清如下:1、操作演示的数据全部由我本人随意假设输进去的,重在演示操作;2、本人也只是在学习阶段,希望友友们能谅解哈,手里有数据的宝子当然更好啦,没有咱就自己假设数据练习一下也没多大关系的哈;3、我也会在后续教程中尽量增加一些数据的必要性说明;4、大家有什么好的意见也可以在评论区一起交流吖~
第十七章一些学习笔记
- SPSS中聚类分析的核心在于让类别内的数据“差异”尽可能小,类别间“差异”尽可能大。--统计分析高级教程(第三版)P317
- 聚类的分类方式上有人将对变量的分类称为R型聚类,对案例的分类称为Q型聚类;若按照原理来划分的话,可以分为三种:1、非层次聚类法【non-hierarchical clustering,重新定位法目的是将案例快速分成K个类别,以K-均值聚类法最常用】;2、层次聚类法【hierarchical clustering,这种聚类方法结果间存在这嵌套或者层次关系,常用“谱系图”表示分析结果】;3、智能聚类法【最常见的是两步聚类法、最近邻元素法和神经网络中的自组织图(self-organization map,SOM)】。--统计分析高级教程(第三版)P318-319
- SPSS中若聚类的方法不是很满意,则可以考虑:1、对变量进行标准化;2、聚类用的变量的增删;3、变量变换、合并;4、离群值、缺失值的处理;5、距离测量方法的修改;6、聚类分算法的修改。--统计分析高级教程(第三版)P325
- SPSS中层次聚类法在面对样本量比较大的时候,存在计算速度比较慢的问题,随着计算机技术的发展,当样本量在5000例以下,且用于聚类在10个以内时,其计算速度还是可以接受的。--统计分析高级教程(第三版)P329
- SPSS中各种层次聚类法常用的方法有:1、最短距离法、中位数法和最长距离法;2、重心法【又称为质心聚类法(centroid clustering)】;3、组间连接法和组内连接法;4、瓦尔德法【也称为离差平方和法】。--统计分析高级教程(第三版)P333
- SPSS聚类分析的一些进阶操作:1、利用标准化来调整聚类模式【可以依据位置,也可以依据形状的相似性,即在“方法”的转换值中选择“按个案”或者“按变量”进行聚类】;2、如何选择聚类分析方法【聚类类型(若对个案进行聚类,各种方法都有可以考虑,对变量的话,一般只考虑层次聚类法),数据量(若数据量小于3000,各个方法都可以考虑,优先考虑层次聚类法,若数据量大于5000,且变量数目超过10个,则考虑快速聚类法或智能聚类法),变量类型(若都为连续变量,三种方法都可以考虑使用,若都包含,应使用智能聚类法),是否指定类别数量(快速聚类法需要给出聚类的类别数)】。对案例间距的定义也有分连续变量和二分类变量两组【1、连续变量距离有欧几里得距离(Euclidean distance)、欧几里得平方距离(squared Euclidean distance)、切比雪夫距离(Chebychev)、块(block)、明可夫斯基距离(Minkowski)、定制(customized);2、二分类变量距离欧几里得距离与欧几里得平方距离、大小差(size difference)、模式差(pattern difference)、方差(variance)、方差(variance)、兰斯-威廉姆斯(Lance and Williams)】。--统计分析高级教程(第三版)P340-341
第十七章一些操作方法
聚类分析
连续变量一般使用欧几里得平方距离作为测量指标,分类变量则一般使用卡方作为距离的测量指标。
数据标准化可以让部分极端数据与普通数据在聚类时所产生的贡献相同,但不建议部分场合一律对原始数据进行标准化,应视具体情况而定。
均值聚类法(快速聚类法)
这里的K表示所聚类的类别数,即聚类数
假设数据

预分析(描述统计)

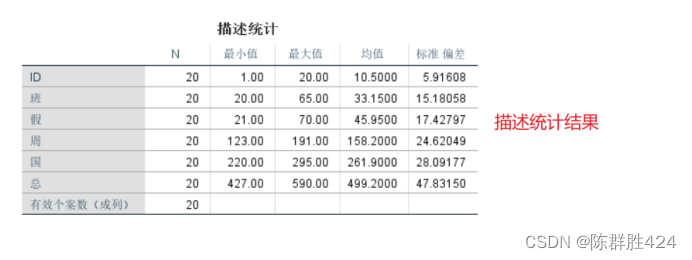
先将除了ID变量的每个变量除以其最大值进行标准化操作

具体操作

结果解释
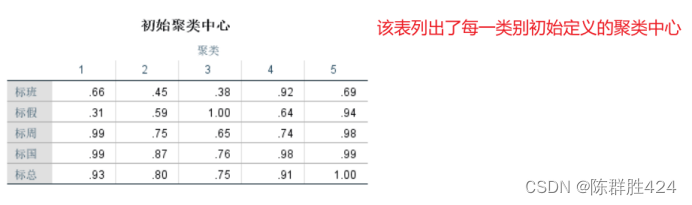
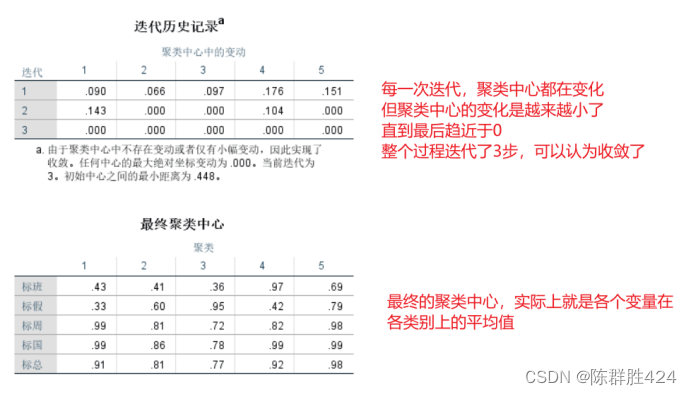

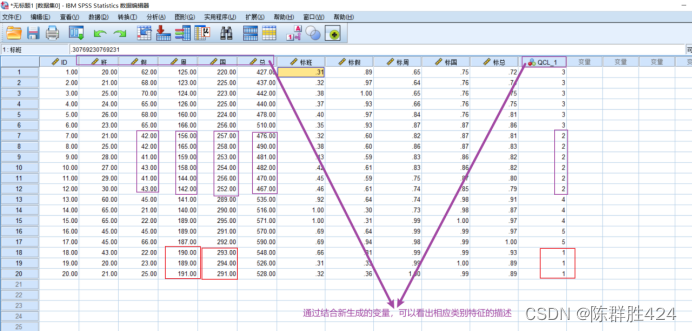
聚类结果的验证与自动优化
利用ANOVA复选框比较类别间的结果
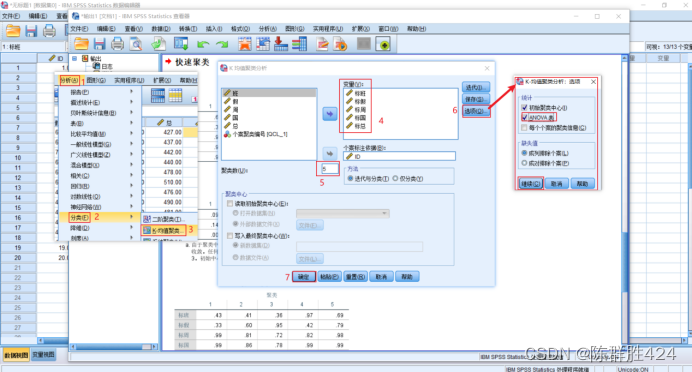
结果解释

聚类结果的自动优化

后续可以考虑使用Python编程来实现
层次聚类法
考虑普通人与裁判的打分差异
假设数据

具体操作
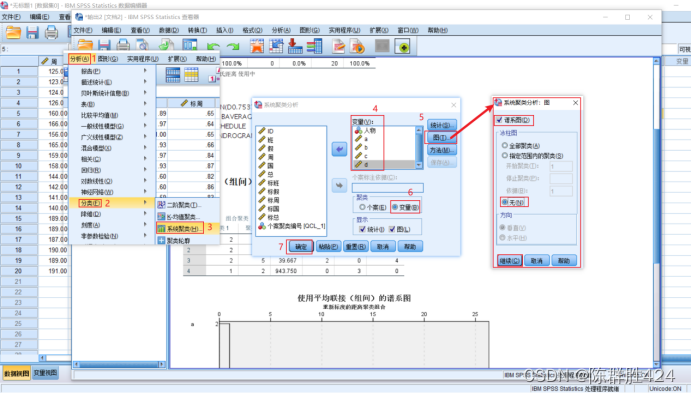
结果解释

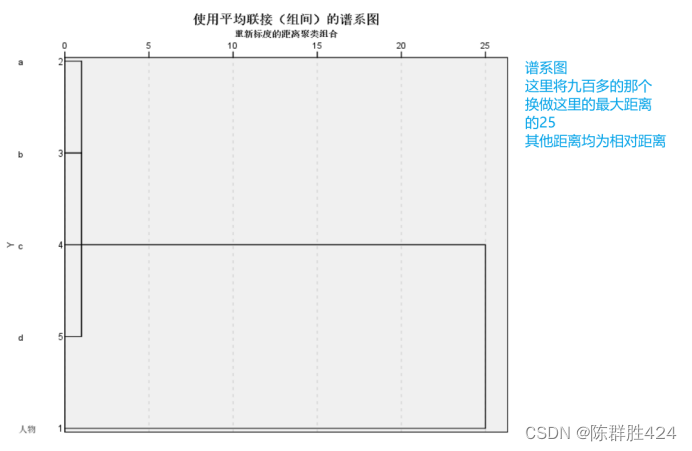
改进聚类结果

这里不采用冰柱图,是因为案例相对较少,当案例较多时,谱系图过大而难于观察,此时可以考虑冰柱图。
结果分析

两步聚类法
数据假设

具体操作
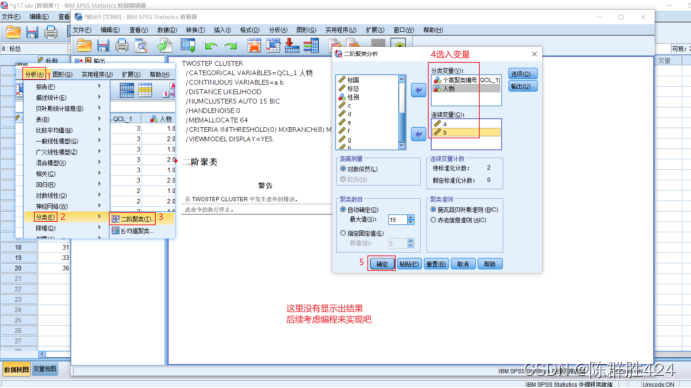
基于密度的聚类分析方法,也是需要R插件来实现的,故后续考虑编程来实现。
结束语
#好啦~,以上就是我SPSS第三十五期学习笔记——高级教程第十七章的学习情况啦~,希望能与大家交流学习经验,共同进步吖~
#考虑高级教程的难度与深度,主要是内容太多辣,后续依然会尽力更新内容~争取日更!
#也非常感谢大家对我的一路陪伴,宝子们的关注、支持和打赏就是up儿不断更新滴动力,我近期也会坚持学习SPSS,更新相应的学习内容及笔记到平台上,咱们下期高级教程不见不散~