目录
一、KMeans
(一)Kmeans简介
(二)Kmeans作用和优点
(三)Kmeans局限和缺点
(四)Kmeans步骤
(五)如何选取最佳的K值的三种方法
(六)手肘法和目标函数的变化两种确定K值方法的区别
(七)如何选取第一次迭代的K个类中心------KMeans++方法
(八)KMeans的常用参数介绍
二、python实现Kmeans聚类
(一)构建数据集
(二)可视化数据集
(三)使用手肘法确当最优K值
最优K值位置:降后趋于平稳的拐点。
(四)再结合目标函数(聚类内部元素的总平方距离下降程度)确定最优K值得选取
结论:
(五)使用最佳的K值进行K-Means聚类
(六)获取聚类的标签,并重新命名
(七) 获取聚类中心
(八) 获取实际迭代次数
(九) 获取每个样本点到簇中心的距离
(十)获取每类的簇内距离平方和
(十一)获取每个点到聚类中心的距离和(组间平方距离和)
(十二)将聚类结果添加到原始数据中
(十三) 可视化聚类后的结果
(十四)打印每个簇中的样本数量
(十五)对新样本进行预测
问题1:
回答1:
问题2:
回答2:
一、KMeans
(一)Kmeans简介
K均值(KMeans)是一种广泛使用的聚类算法,它的目标是将数据集中的样本划分为预先设定的K个簇。这种算法的核心思想是使得同一簇内的样本尽可能相似,而不同簇之间的样本尽可能不同。
k-means算法特点在于:同一聚类的簇内的对象相似度较高;而不同聚类的簇内的对象相似度较小。
(二)Kmeans作用和优点
作用:
数据聚类:KMeans能够将数据样本划分为不同的簇,这有助于我们发现数据集中的内在结构和模式。
数据预处理:KMeans可以用于数据压缩,通过用簇中心代替样本集合来减少数据维度和存储空间。
异常检测:KMeans也可用于检测异常值,因为异常值通常会被归入与其最近的簇中。优点:
简单:KMeans易于理解和实现。
高效:在大数据集上,KMeans的表现良好。
可扩展:KMeans适用于大规模数据集。
(三)Kmeans局限和缺点
局限和缺点:
需要预先指定K值:我们需要事先知道要划分的簇数量,选择不合适的K值可能导致不理想的聚类效果。
对初始中心点敏感:初始中心点的选择会影响最终的聚类结果。
对非凸形状簇效果不佳:KMeans假设簇为凸形状,对非凸形状的簇聚类效果不佳。
(四)Kmeans步骤
1. 初始化:随机选择K个样本作为初始簇中心点。
2. 样本分配:将每个样本分配给与其最近的簇中心点所在的簇。
3. 更新簇中心:计算每个簇中所有样本的均值,将该均值作为新的簇中心。
4. 重复迭代:重复步骤2和3,直到满足停止条件,如簇中心不再发生变化或达到最大迭代次数。KMeans算法通过不断迭代,将样本划分为K个簇,并尽可能使得同一簇内的样本相似度高,不同簇之间的样本相似度低,以实现聚类的目标。
(五)如何选取最佳的K值的三种方法
K-means算法中,聚类数量K通常需要事先给定。
在实际应用中,确定一个合适的K值是非常困难的,因为通常情况下我们并不知道数据集应该被分为多少个类别才是最合适的。然而,有一些方法可以帮助我们估计一个合理的K值:
1. 手肘法(Elbow Method):这种方法涉及到绘制一个图,图中显示了聚类数量(K值)对聚类误差(如SSE,即簇内平方和)的影响。当K值增加到真实的聚类数量时,SSE的下降幅度会显著减少,形成一个“手肘”形状的曲线,从而帮助我们识别出适当的聚类数。
2. 轮廓系数法(Silhouette Coefficient):这是一种评估聚类效果的方法,通过计算每个数据点的轮廓系数来评估聚类的合理性。轮廓系数的范围在-1到1之间,接近1的值表示聚类效果好。
3. 目标函数的变化:观察目标函数(如SSE)随聚类数K变化的情况,选择目标函数变化较小的点作为合适的K值。例如,如果目标函数在K=4时的变化远小于K=5时的变化,那么可能会选择K=4作为合适的聚类数。尽管有这些方法,但在没有明确的领域知识或先验信息的情况下,确定最佳的K值仍然是一个挑战。因此,实践中可能需要结合多种方法和实验来确定最合适的K值。
(六)手肘法和目标函数的变化两种确定K值方法的区别
二者不完全是一个道理,手肘法和观察目标函数变化的方法确实都是用来估计K-means算法中合适的K值的,但它们的侧重点和分析角度有所不同。
手肘法:这种方法主要是通过观察聚类数目K对手肘法的目标函数(通常是簇内误差平方和SSE)的影响来选择K值。当K值较小时,增加聚类数量会显著降低SSE,因为每个簇可以更紧密地代表其成员。而当K值达到某个点后,SSE的下降速度会明显减慢,这个点就是“手肘点”,通常被认为是数据的真实聚类数量。
目标函数的变化:这种方法更多地关注目标函数随K值增加的变化趋势。我们寻找的是目标函数变化较小的点,因为在这一点之后,增加更多的聚类可能不会带来显著的性能提升,这可能意味着已经达到了数据的内在聚类结构。综上,尽管两者都是通过分析目标函数来确定K值,但手肘法更多是寻找一个明显的拐点,而观察目标函数变化则是寻找变化率减少的点。手肘法主要是通过观察SSE的变化曲线来确定一个合适的K值,而目标函数的变化则是通过观察目标函数本身的变化来确定一个合适的K值。这两种方法都可以帮助我们估计一个合理的K值,但它们的使用场景可能有所不同。
在实际应用中,这两种方法可能会得到不同的K值,我们可以结合使用这两种方法。
(七)如何选取第一次迭代的K个类中心------KMeans++方法
K-means++初始化方法:这种方法是为了解决K-means算法对初始中心点选择敏感的问题。K-means++通过确保初始聚类中心之间的相互距离尽可能远来选择初始聚类中心,从而提高聚类的质量。
这里怎么将距离的大小体现在选择的概率上其实有很多方式,最极端的一种就是,距离最大的概率为1,其余为0。
(八)KMeans的常用参数介绍
1. n_clusters: 这是用户需要指定的最重要的参数之一,它代表期望的聚类数量。
2. max_iter: 这个参数设置了算法的最大迭代次数,即算法在停止前将尝试优化聚类中心的次数。默认值为300,这意味着算法将尝试最多300次迭代来找到最优解。
3. tol: 容忍度参数,用于确定何时停止迭代。当连续两次迭代之间的误差变化小于`tol`时,算法将停止迭代。默认值为1e-4,这个值可以根据实际情况调整,以平衡算法的精度和运行时间。
4. n_init: 这个参数决定了k-means算法将随机初始化并运行的次数。每次运行都会选择最佳的聚类结果作为最终结果。默认值为10,这意味着算法将运行10次,从中选择最佳结果。
每次n_init中的运行都会有max_iter次迭代
5. init: 这个参数用于指定聚类中心的初始化方法。可选的方法包括:
①k-means++: 这是一种改进的初始化方法,它选择初始聚类中心点的方式是使得它们之间的距离尽可能大。
②random: 这是默认的初始化方法,它随机选择数据点作为初始聚类中心。
③一个`ndarray`对象:如果提供了这个参数,它将被用作初始聚类中心。这些参数共同决定了k-means算法的行为和输出。在实际应用中,可能需要根据具体情况调整这些参数,以获得最佳的聚类效果。
二、python实现Kmeans聚类
(一)构建数据集
from sklearn.datasets._samples_generator import make_blobs #生成样本数据
X,Y=make_blobs(n_samples=100,centers=4,random_state=42)这段代码是用 scikit-learn(sklearn)库中的 make_blobs 函数生成一个二维数据集(blobs,即数据点的集合,通常用于聚类问题)。
得到一个100个样本的二维数据集,以及每个样本对应的类别标签。这对于聚类算法的学习和实验非常有用。
(二)可视化数据集
from matplotlib import pyplot as plt #可视化
plt.figure(figsize=(5,3),dpi=144)
plt.scatter(X[:,0],X[:,1],s=50,edgecolors='k')
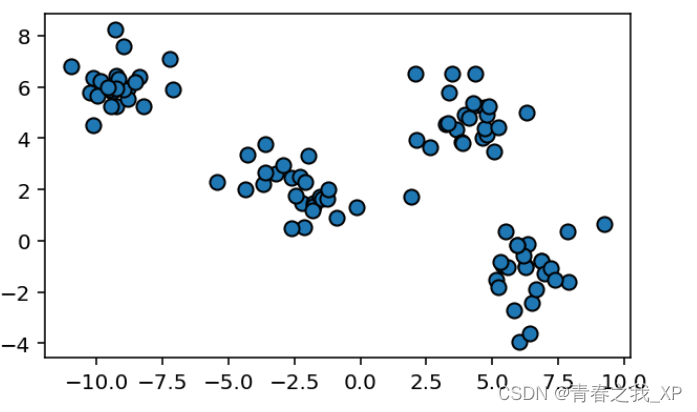
plt.show()从下图可知,生成的100个数据集,很明显分成了三类。
给每类数据按照真实标签加上颜色表示,如下:
# Y = Y.astype(int) # 将Y转换为整数类型
plt.figure(figsize=(5, 3), dpi=144)
plt.scatter(X[:, 0], X[:, 1], s=50, edgecolors='k', c=Y, cmap='viridis') # 使用c参数设置颜色,并使用cmap参数指定颜色映射
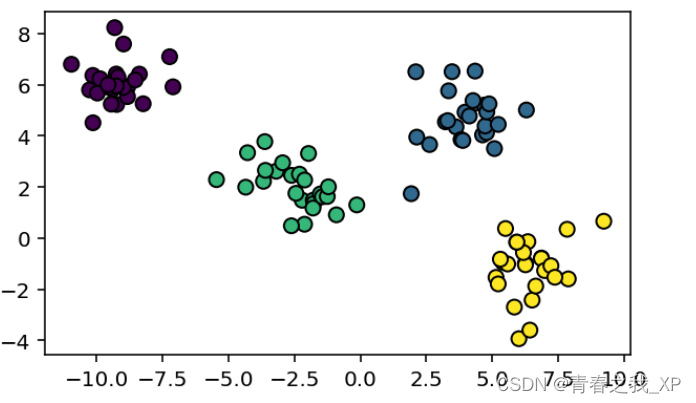
plt.show()通过下图,我们发现,数据集的真实情况是四类,绿色那类和紫色那类距离很接近,说明相似度很高。
(三)使用手肘法确当最优K值
手肘法(Elbow Method):这种方法涉及到绘制一个图,图中显示了聚类数量(K值)对聚类误差(如SSE,即簇内平方和)的影响。当K值增加到真实的聚类数量时,SSE的下降幅度会显著减少,形成一个“手肘”形状的曲线,从而帮助我们识别出适当的聚类数。
from sklearn.cluster import KMeans
# 使用手肘法确定最佳的K值
plt.rcParams['font.sans-serif'] = ['SimHei']
inertia = []
for k in range(1, 11):
kmeans = KMeans(n_clusters=k, random_state=0,init="k-means++")
kmeans.fit(X)
inertia.append(kmeans.inertia_)
# 绘制手肘法图表
plt.figure(figsize=(5, 3),dpi=144)
plt.plot(range(1, 11), inertia, marker='o', linestyle='--')
plt.xlabel('K值')
plt.ylabel('距离平方和')
plt.title('手肘法图表')
plt.savefig('手肘法图.png',dpi=300)
# plt.grid(True)
plt.show()
# 从手肘法图表中选择最佳的K值
# 在这个示例中,根据手肘法,选择K=4
最优K值位置:降后趋于平稳的拐点。
从手肘法图表中选择最佳的K值,从上图中我们可以看出在K=3或者K=4时,距离平方和趋于稳定,所以最优K大概在3和4之间取。
(四)再结合目标函数(聚类内部元素的总平方距离下降程度)确定最优K值得选取
目标函数的变化:观察目标函数(如SSE)随聚类数K变化的情况,选择目标函数变化较小的点作为合适的K值。例如,如果目标函数在K=4时的变化远小于K=5时的变化,那么可能会选择K=4作为合适的聚类数。
import numpy as np
# Find the K value with the smallest inertia change
#距离平方和得差,也就是每次K值距上一次K值所对应得距离平方和下降程度
inertia_diff = np.diff(inertia)结果如下:

我们看到这个差是负值,所以说明K在(1,10) 范围内取值时,距离平方和都是在下降的,后面在画图时,为了更好得呈现结果,会将inertia_diff 取绝对值,来表示下降的程度大小。
plt.figure(figsize=(5, 3),dpi=144)
inertia_diff_abs = np.abs(inertia_diff) # 取绝对值,使所有值变为非负
plt.plot(range(2, 11), inertia_diff_abs, marker='o', linestyle='--')
#inertia_diff_abs:取绝对值
plt.xlabel('K值')
plt.ylabel('距离平方和下降程度')
plt.title('目标函数(聚类内部元素的总平方距离下降程度)表')
# plt.savefig('手肘法图.png',dpi=300)
# plt.grid(True)
plt.show()
#optimal_k = range(1, 11)[np.argmax(inertia_diff)]
#为什么是求差最大的点,因为每次的总平方和距离都是下降的,所以差是负值,要去绝对值最小的那个点,也就是带负号中的数值最大的点
#print(f'Optimal K value is: {optimal_k}')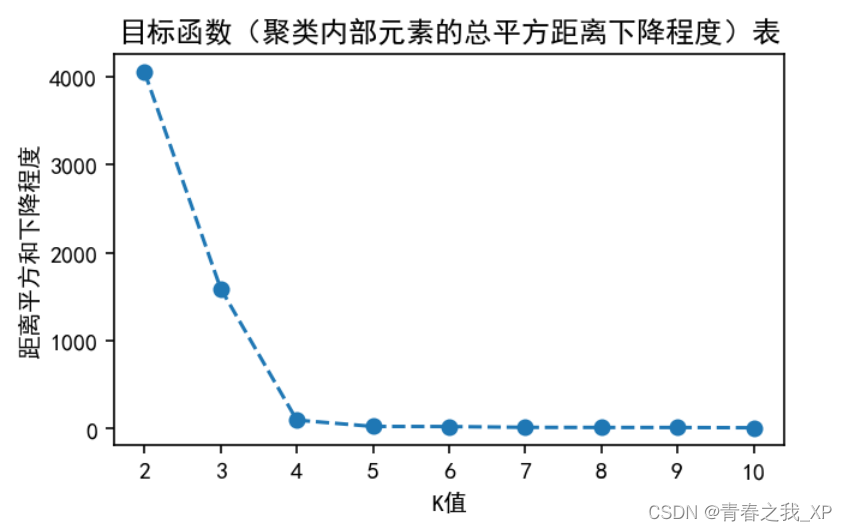
结论:
从图中我们可以看到,当K的3时,与上一阶段的距离平方和下降程度依然很大;当K=4时,与上一阶段的距离平方和下降程度也很大;当K=5及以后,下降程度趋于平稳,几乎不再下降,或者说下降程度相对而言微乎其微;故选择K=4作为最优K值得选取。
综上,根据手肘法的分析结果,再结合目标函数的下降程度这个方法,最终我们选取K=4作为最优的K值。
(五)使用最佳的K值进行K-Means聚类
kmeans = KMeans(n_clusters=4, random_state=0,init="k-means++")
kmeans.fit(X)(六)获取聚类的标签,并重新命名

# 定义一个字典来给标签命名
label_names = {0: "Cluster A", 1: "Cluster B", 2: "Cluster C",3: "Cluster D"}
# 将数字标签转换为有意义的标签名称
name_labels = [label_names[label] for label in kmeans.labels_]
#cluster_names = ['Cluster 1', 'Cluster 2', 'Cluster 3', 'Cluster 4']
#labels_dict = {i: cluster_names[label] for i, label in enumerate(kmeans.labels_)}
(七) 获取聚类中心
print(kmeans.cluster_centers_)#获取聚类中心
(八) 获取实际迭代次数

(九) 获取每个样本点到簇中心的距离
#如果想要获取每个样本点到其所属聚类中心的距离,可以使用 kmeans.transform(X) 方法,然后选择每个样本点所属聚类中心的距离即可。
distances = kmeans.transform(X)
# 输出每个样本点到簇中心的距离
for i in range(len(X)):
print(f"样本点{i}到簇中心的距离:{distances[i]}")
kmeans.transform(X) 方法输出的结果是样本数据 X 中每个样本点到每个聚类中心的距离。具体来说,如果有 n_samples 个样本点和 n_clusters 个聚类中心,那么输出的结果是一个形状为 (n_samples, n_clusters) 的数组,其中每个元素表示对应样本点到对应聚类中心的距离。
(十)获取每类的簇内距离平方和
要实现获取每个类中每个样本点到聚类中心的距离和,并且同时输出每个样本点到簇中心的距离,可以使用KMeans模型的transform方法。该方法可以计算每个样本点到每个聚类中心的距离,并返回一个矩阵,其中每一行表示一个样本点,每一列表示该样本点到对应聚类中心的距离。
下面是一个示例代码,展示如何实现获取每个类中每个样本点到聚类中心的距离和,并输出每个样本点到簇中心的距离:
import numpy as np
# 获取每类的簇间距离和
cluster_distances = []
#for cluster in range(4):
for cluster in range(kmeans.n_clusters):
cluster_indices = np.where(kmeans.labels_ == cluster)
cluster_distances.append(np.sum(distances[cluster_indices, cluster]))
# 输出每类的簇间距离和
for cluster in range(kmeans.n_clusters):
print(f"第{cluster}类的簇间距离和:{cluster_distances[cluster]}")
(十一)获取每个点到聚类中心的距离和(组间平方距离和)

kmeans.inertia_是用来评估聚类模型的性能,它表示了数据点与其所属簇中心的紧密程度。而cluster_distances则是用来计算每个簇内数据点的距离之和,可以用来分析不同簇之间的差异。
(十二)将聚类结果添加到原始数据中
# 将 X 转换为 DataFrame
import pandas as pd
df = pd.DataFrame(X, columns=['Feature1', 'Feature2'])
df["真实标签"]=Y
# 将簇标签添加到原始数据中
df["聚类标签结果"]=name_labels
#name_labels这个变量在(六)获取聚类的标签,并重新命名这一部分定义的
(十三) 可视化聚类后的结果
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
# 簇分布
plt.figure(figsize=(5,3),dpi=144)
#画图时,x轴刻度有负值,负号不显示出来,而是方块,所以尝试了下边的方法可以解决
# 设置刻度值的格式化字符串
formatter = ticker.StrMethodFormatter("{x:.1f}")
plt.gca().xaxis.set_major_formatter(formatter)
plt.gca().yaxis.set_major_formatter(formatter)
plt.scatter(X[:,0],X[:,1],s=50, c=kmeans.labels_, cmap='viridis')
plt.scatter(centers[:,0],centers[:,1],c='r',s=100,marker='*')
plt.xlabel('Features1')
plt.ylabel('Features2')
plt.title('K-Means 结果')
# plt.savefig('K-Means 结果.png',dpi=300)
plt.show()下边一共有两个图,第一个图是聚类后的结果可视图,第二个图是原始数据的类别可视图,通过对比我们发现,聚类后的效果很好,本次聚类结果和原始数据的类别结果相重合。


(十四)打印每个簇中的样本数量
print(df["聚类标签结果"].value_counts()) 
(十五)对新样本进行预测

问题1:
kmeans = KMeans(n_clusters=4, random_state=0) kmeans.fit(X)在这里已经固定随机种子了,为什么每次kmeans.n_iter_或者kmeans.inertia_等的输出结果都会发生变化,为什么不是固定的值 ??
回答1:
在KMeans算法中,即使设置了`random_state`参数来固定随机种子,
`n_iter_`(迭代次数)和`inertia_`(最终的簇内误差平方和)仍然可能会在不同的运行之间发生变化。
这是因为:
1. 随机初始化:虽然`random_state`固定了初始中心点的选择,但在K-means++初始化过程中,第一个中心点是随机选择的,这个随机性是由`random_state`控制的。然而,后续的中心点是基于数据点与已选中心点之间的距离概率分布来选择的,这个过程并不受`random_state`的影响。
2. 数据的处理顺序:K-means算法在每次迭代时会根据距离重新分配数据点到最近的簇。如果数据集很大,数据的处理顺序可能会影响迭代过程,尤其是在有多个处理器核心的情况下。以及一些其他原因
问题2:
如果模型经过n次迭代后,得到最优的聚类结果,那么能不能输出每次迭代的聚类中心?
回答2:
要获取每次迭代的聚类中心,需要使用一个稍微不同的方法,因为KMeans类本身并不提供直接的方法来追踪每次迭代的中心点。不过,可以通过创建一个自定义的K-means类或者修改现有的KMeans类来实现这个功能。