1、API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs
中文标题:API-BLEND: 一个用于训练和评测 API 语言模型的全面语料库
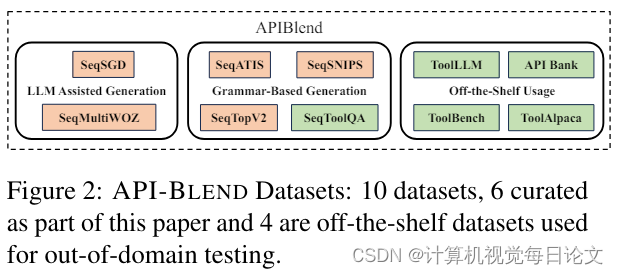

简介:随着大型语言模型(LLM)的发展,它们需要能够有效地利用各种工具和应用程序接口(API)来完成复杂任务。因此,如何获取大量涉及API调用的训练和测试数据成为一个重要的挑战。
解决这一挑战主要有两种研究思路:一是focus on生成合成数据,二是策划包含API相关任务的真实数据集。
本文聚焦于后一种方法,介绍了一个名为API-BLEND的大型语料库。这个语料库模拟了真实场景中涉及API调用的任务,如API检测、参数填充、API排序等。作者展示了这个语料库在训练和评测API增强型LLM方面的实用性。
总的来说,API-BLEND为训练和评测能够有效利用工具和API的LLM提供了一个全面的数据基础。
2、API Pack: A Massive Multilingual Dataset for API Call Generation
中文标题:API Pack: 一个庞大的多语言数据集,用于 API 调用生成
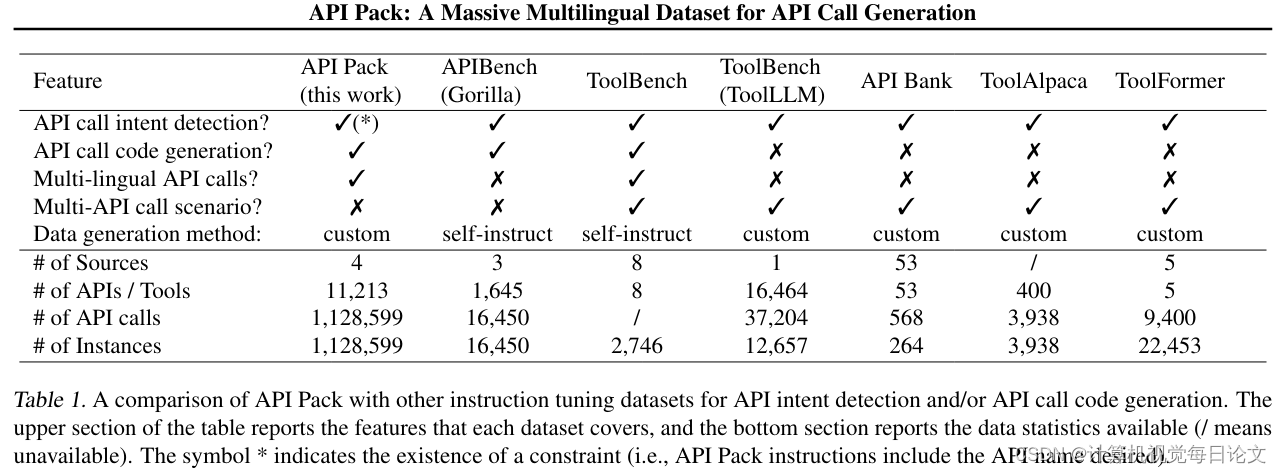
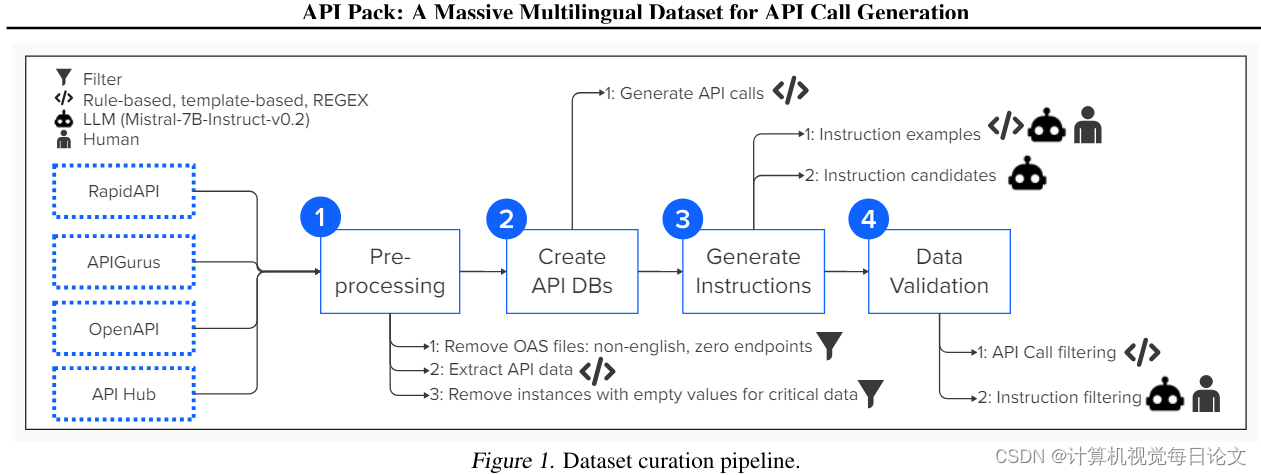
简介:我们开发了一个名为"API Pack"的多语言数据集,包含超过100万个指令-API调用对。该数据集旨在提升大型语言模型生成API调用的能力。通过实验,我们证明使用API Pack对模型进行微调,不仅能增强其专业任务的能力,同时也能保持其在一般编程方面的整体熟练度。
仅在20,000个Python示例上对CodeLlama-13B进行微调,就可以使其生成未见过的API调用的准确率,分别超越GPT-3.5和GPT-4 10%和5%。进一步扩展到100,000个示例,还可以提高模型对新API的泛化能力。
值得一提的是,API Pack支持跨语言的API调用生成,无需大量语言数据即可实现。该数据集、相关的微调模型以及整体代码库都已经开源,可在https://github.com/anonymous_url获取使用。
3、AnyTool: Self-Reflective, Hierarchical Agents for Large-Scale API Calls
中文标题:AnyTool: 面向大规模 API 调用的自我反思型分层代理


简介:我们介绍了AnyTool,这是一个大型语言模型代理,旨在彻底改变利用各种工具解决用户查询的方式。我们利用来自Rapid API的超过16,000个API,假设其中一部分API可能能够解决查询。
AnyTool主要包括三个关键组件:
1. 具有分层结构的API检索器,能够快速定位可能有助于解决用户查询的 API。
2. 一个求解器,旨在利用选定的API候选集有效地解决用户查询。
3. 一个自我反思机制,在初始解决方案不可行时重新启动AnyTool的工作流程。
AnyTool由GPT-4的函数调用功能驱动,无需训练额外的外部模块。我们还重新审视了先前工作引入的评估协议,发现其存在局限性,导致了人为的高通过率。为了更好地反映实际应用场景,我们引入了一个名为AnyToolBench的新基准。
实验结果表明,我们的AnyTool在各种数据集上优于强基线,如ToolLLM和专为工具利用而定制的GPT-4变体。例如,在ToolBench基准上,AnyTool的平均通过率比ToolLLM高出35.4%。AnyTool的开源代码将在https://github.com/dyabel/AnyTool上提供。
4、ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
中文标题:ToolLLM:帮助大型语言模型掌握16000多种真实世界的API


简介:本论文的目标是解决现有大型语言模型在使用外部工具(API)方面的局限性。为此,论文提出了一种名为ToolLLM的通用工具使用框架,涵盖了数据集构建、模型训练和评估等步骤。此外,为了提高模型的实用性,论文还引入了一个神经API检索器组件,用于为每个指令推荐合适的API接口。总的来说,这个框架旨在帮助大型语言模型更好地掌握和利用多达16000种真实世界的API。
5、Toolformer: Language Models Can Teach Themselves to Use Tools
中文标题:Toolformer:语言模型可以自学使用工具

简介:Toolformer是一个新型的自监督学习语言模型,它在不牺牲核心语言建模能力的情况下,显著提升了在各种下游任务中的零样本性能,与更大型的模型相比也能保持竞争力。
Toolformer的关键特点包括:
(1)提出了一种使用简单API的自监督学习方法,让语言模型能够学会使用各种外部工具。
(2)在多种下游任务中展现出优异的零样本性能,与更大规模的模型相比也不会损失核心的语言理解能力。
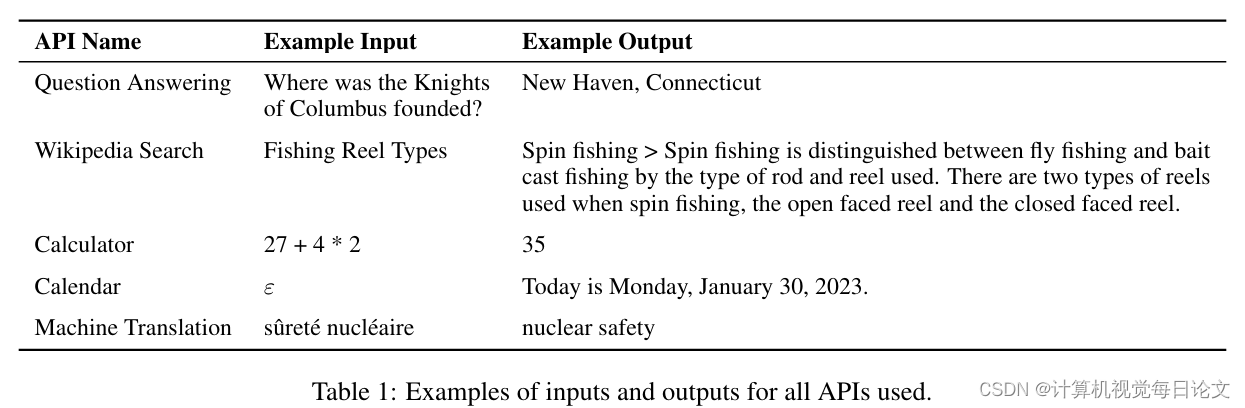
(3)展示了Toolformer可以学会使用各种工具,包括计算器、问答系统、搜索引擎、翻译系统和日历等。
总的来说,Toolformer提供了一种新的自监督模型训练方法,能够在不牺牲语言理解能力的前提下,显著提升语言模型在实际应用中的性能和竞争力。