大家好,我是程序锅。
github上的代码封装程度高,不利于小白学习入门。
常规的大模型RAG框架有langchain等,但是langchain等框架源码理解困难,debug源码上手难度大。
因此,我写了一个人人都能看懂、人人都能修改的大模型RAG框架代码。
整体项目结构如下图所示:手把手教你大模型RAG框架架构
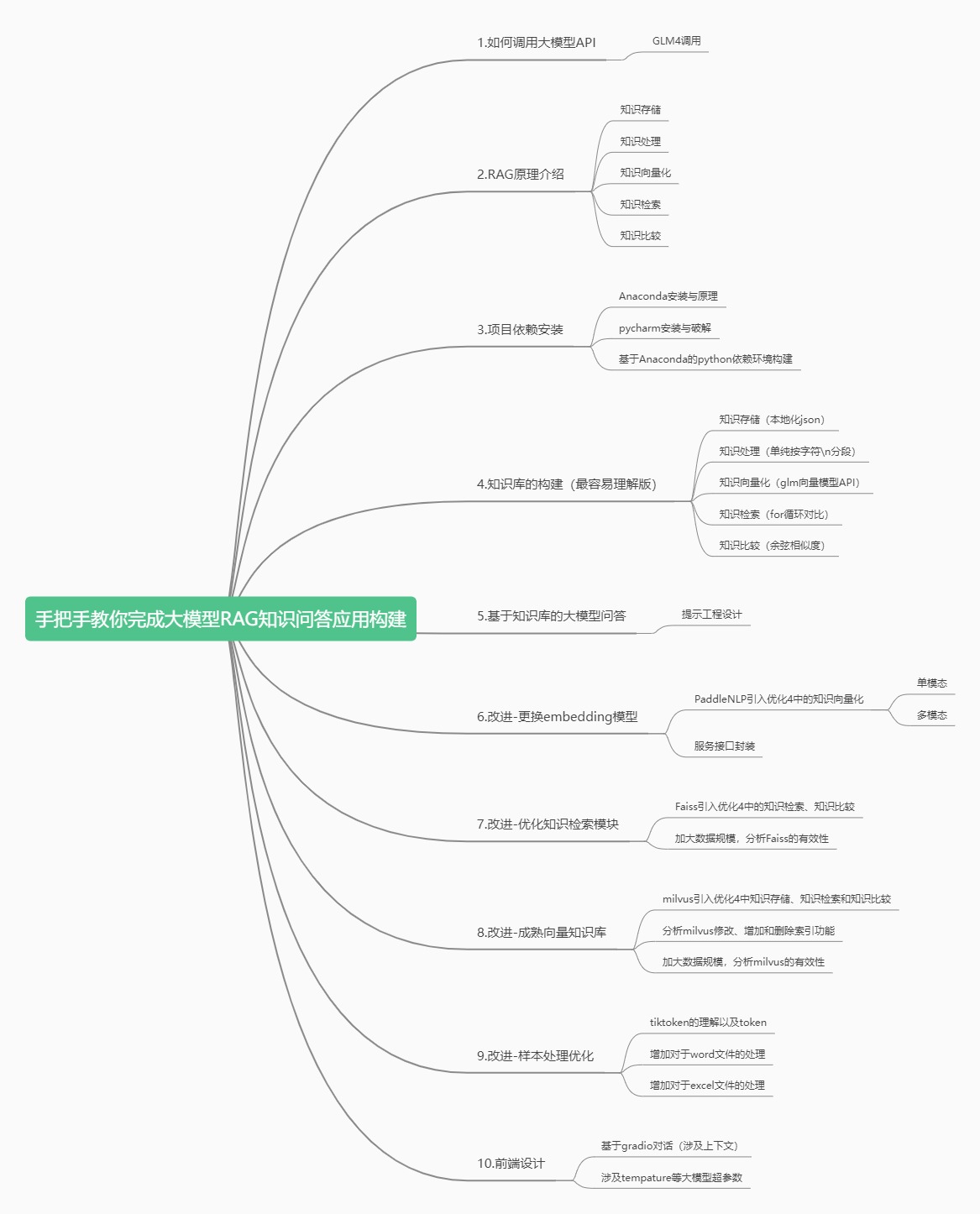
整个小项目分为10个章节,和github高度封装的RAG代码不同,我们将从0到1搭建大模型RAG问答系统。
前序章节:
自己手写了一个大模型RAG项目-04.知识库构建
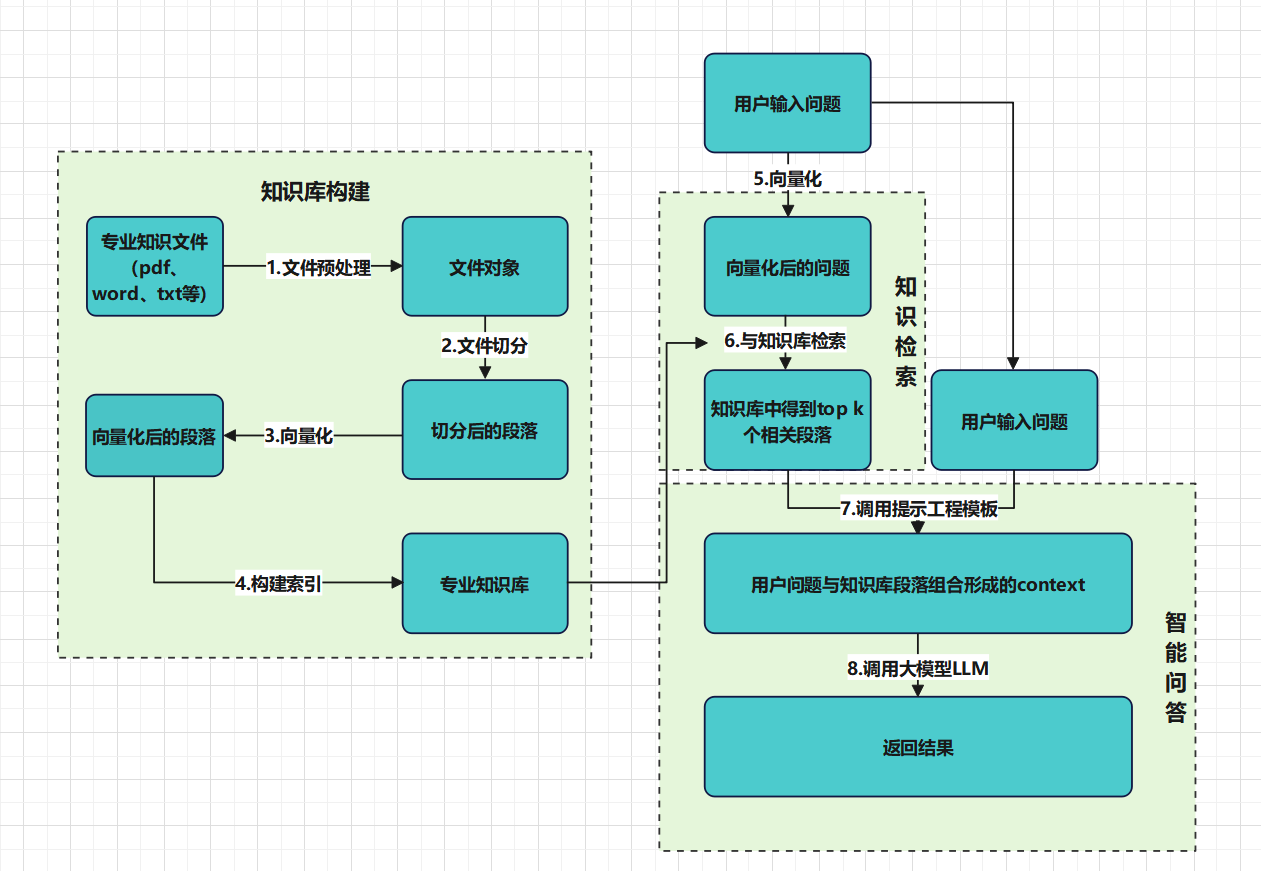
本篇文章将介绍5.基于知识库的大模型问答,知识库构建好之后还需要通过知识检索和智能问答。
一、知识检索
首先第一个问题,为什么要做知识检索
在整个大模型RAG智能问答应用构建过程中,需要将用户的问题向量化,将向量化后的问题与知识库内的向量做匹配。
前面几篇文章已经讲述了如何构建知识库,目前需要从向量库中匹配与问题最相似的k个向量(k是一个超参数,需要根据大模型输入上下文长度来界定)
怎么匹配以及匹配的标准是什么呢?
匹配的目的就是一堆向量中找到最相似的几个向量,最简单直白的方式就是去遍历所有向量,计算问题向量与知识库所有向量之间的相似度,然后按照相似度多少,从高到低排序,取最大的几个。
匹配的标准也很简单,我采用了余弦相似度。此外可以用L2范数、内积、曼哈顿距离、p范数等等。
@classmethod
def cosine_similarity(cls, vector1: List[float], vector2: List[float]) -> float:
"""
calculate cosine similarity between two vectors
"""
dot_product = np.dot(vector1, vector2)
magnitude = np.linalg.norm(vector1) * np.linalg.norm(vector2)
if not magnitude:
return 0
return dot_product / magnitude
def query(self, query: str, EmbeddingModel: BaseEmbeddings, k: int = 1) -> List[str]:
query_vector = EmbeddingModel.get_embedding(query)
end_time = time.time()
result = np.array([self.get_similarity(query_vector, vector)
for vector in self.vectors])
print(' 检索 cost %f second' % (time.time() - end_time))
return np.array(self.document)[result.argsort()[-k:][::-1]].tolist()
上面代码用到了最简单的for循环对比。不过for循环对比效率太低,因此有了许多优化方法。主要可以分为索引构建、检索加速、向量数据库等。
1.索引构建
索引一般存储在磁盘的文件中,它是占用物理空间的。一般我们都将存储所有原始向量。
由于原始向量维度比较高,为了减少索引占用的空间,可以采用主成分分析(PCA)对向量降维;也可以通过某些编码方式降低向量维度,比如PQ16使用16个字节编码向量、PQ8+16通过8字节来进行PQ,16个字节对第一级别量化的误差再做PQ等等。
2.检索加速
检索这一块最简单的是基于余弦相似度的暴力全量搜索。如果你只是少量检索,或者要求检索结果非常准确的话这种索引是你的首选。
在数据量大了之后,暴力搜索会很慢,因此也有一些新的搜索算法。
-
倒排暴力检索
具体做法是预先设定好需要把所有向量聚成多少类,每个簇下会选出一个中心向量,在每次search的时候可以找到最近的几个中心向量,然后只在这几个中心向量涉及的簇中进行搜索,这样就大大减小了搜索范围,有利于搜索效率的提升。
-
乘积量化
利用乘积量化的方法,改进了普通检索,将一个向量的维度切成x段,每段分别进行检索,每段向量的检索结果取交集后得出最后的TopK。
-
图检索
图搜索算法是一类用于遍历或搜索图的数据结构和算法,图的节点可能带有关系,这些关系可以是有向的或无向的,加权的或无权的。图检索构建索引极慢,占用内存极大,检索速度极快,10亿级别秒出检索结果,
还有很多检索加速的方法,想快速用起来,推荐使用Faiss向量检索库,一行代码即可实现上述检索功能。比如用Faiss构建倒排暴力检索,代码如下:
import faiss
# 向量维度是128,faiss.METRIC_L2代表相似度采用欧式距离
dim, measure = 128, faiss.METRIC_L2
#代表k-means聚类中心为4096,
description = 'IVF4096,Flat'
index = faiss.index_factory(dim, description, measure)
3.向量数据库
向量数据库是一种专门用于存储和处理向量数据的数据库系统。它以向量为基本数据类型,将向量作为数据的主要组织形式。相比传统的关系型数据库,向量数据库具有高效的相似性搜索和高度可扩展性。
你可以理解向量数据库主要包括数据存储、索引构建和相似性搜索三个过程。并且都根据数据是高维向量这一特性,在存储、索引、检索方面都做了大量的优化。
目前国产向量数据库中,比较厉害的就是Milvus。代码中也会涉及Milvus部署使用以及在没有资源的情况下如何白嫖Zilliz(Milvus的云化版本)
二、智能问答
这一块涉及如何组织语言,将用户的问题与知识库被检索出的文本块结合起来,便于大模型更好理解用户意图,生成用户想要的结果。
业界给了它一个高大上的名字:提示工程。提示工程探讨如何设计出最佳提示词,用于指导语言模型帮助我们高效完成某项任务。
下面给个项目中提示工程的例子:
PROMPT_TEMPLATE = dict(
RAG_PROMPT_TEMPALTE="""使用以上下文来回答用户的问题。如果你不知道答案,就说你不知道。总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
如果给定的上下文无法让你做出回答,请回答数据库中没有这个内容,你不知道。
有用的回答:""",
InternLM_PROMPT_TEMPALTE="""先对上下文进行内容总结,再使用上下文来回答用户的问题。如果你不知道答案,就说你不知道。总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
如果给定的上下文无法让你做出回答,请回答数据库中没有这个内容,你不知道。
有用的回答:"""
)
其中question是我们问的问题,context是知识库检索到的知识。
三、运行
代码目录结构:
├─images
├─RAG #存放RAG核心代码
└─tutorial
├─01.如何调用大模型API
├─02.RAG介绍
├─03.部署环境准备
├─04.知识库构建
├─05.基于知识库的大模型问答
├─06.改进-用自己的embedding模型
├─07.封装镜像对外提供服务
├─08.改进-基于Faiss的大模型知识索引构建
├─09.改进-使用向量数据库
│ └─cloud-vectordb-examples
└─10.前端构建
其中tutorial文件夹中,进入05.基于知识库的大模型问答
执行:python test.py,即可针对知识库开展大模型问答(前提条件:完成04.知识构建)
好了,我们已经做出了一个最简单的基于RAG的大模型问答。下一章将介绍不调用接口,使用自己部署的embedding模型。
最后,我撰写的人工智能应用相关的博客及配套代码均整理放置在Github:ai-app,有需要的朋友自取。