这是一篇openSAP中关于SAP生成式AI课程的笔记,原地址https://open.sap.com/courses/genai1/
文章目录
- Unit 1: Approaches to artificial intelligence
- 概念
- 三种范式
- 监督学习
- 非监督学习
- 强化学习
- Unit 2: Introduction to generative AI
- 生成式AI
- 基础模型
- 关系
- 基础模型有哪些能力呢
- Unit 3: Adapting generative AI to business context
- Prompt engineering
- RAG
- Orchestration tools
- Fine-tuning
- 四做四不做
- 零样本学习,少样本学习
- Unit 4: Extending SAP applications with generative AI
- Unit 5: Generative AI business use cases
- 参考
Unit 1: Approaches to artificial intelligence
概念

首先得理清几个概念和这些概念的关系:
最外层是(Intelligence)智能,这是最泛泛的概念,能完成复杂任务的能力就算智能。
AI(Artificial Intelligence)人工智能:可能理解成像人一样有智能的系统或是配备这种系统的机器。
实现AI的方式是ML 机器学习(Machine Learning),机器学习有几种范式,下图中的监督学习(Supervised learning),非监督学习(Unsupervised learning),强化学习(Reinforcement learning)都是范式的一种,除了这些还有半监督学习,自监督学习,迁移学习等。
DL(Deep Learning)深度学习是ML的一种,使用特殊的算法进行计算和分析。
以上都不是本次课程讨论的重点,重点是
基础模型和生成式AI
它的特点是:
- 神经网络,通常使用变压器架构,通过自监督学习目标进行训练
- 展示紧急属性,跨任务进行概括,并可以生成新内容
三种范式
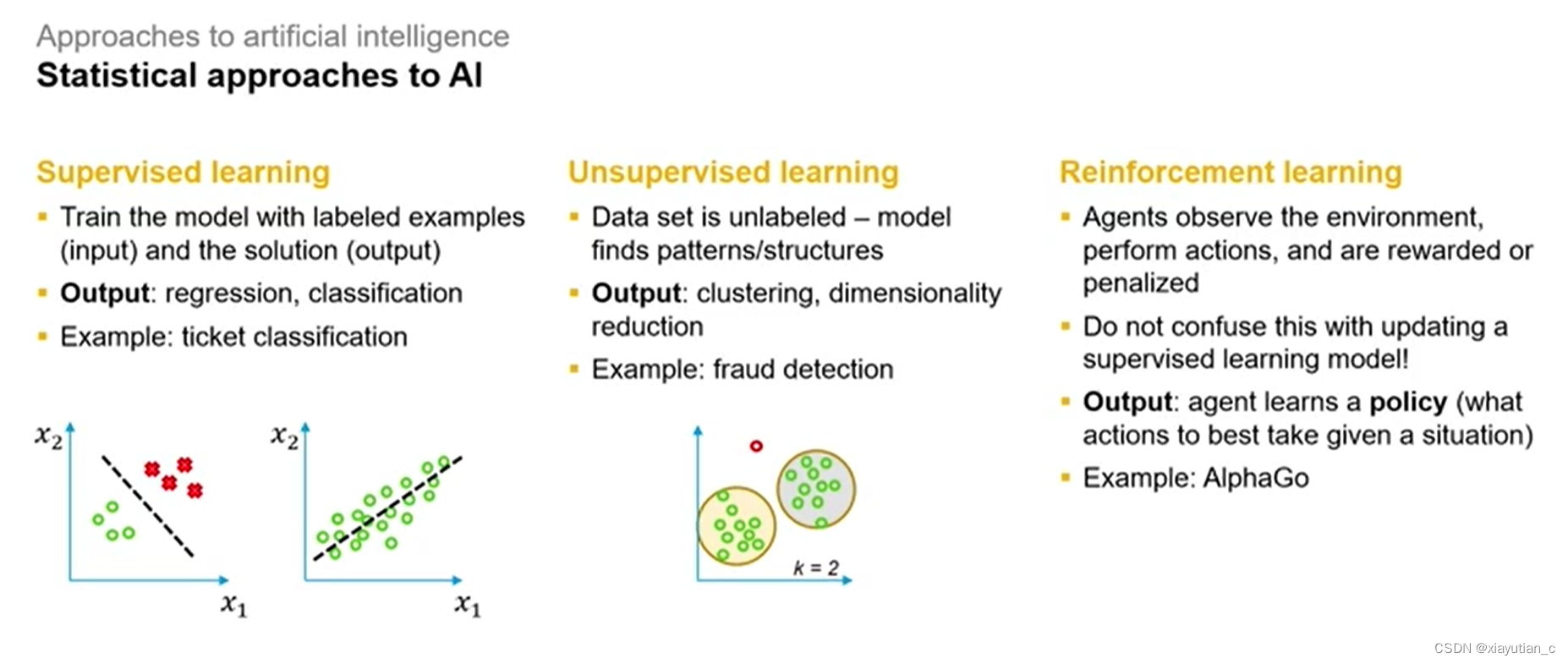
监督学习
训练数据包含有标签的样本,也就是每个输入都与相应的输出相关联。
输出的是回归和分类。
例子:票据分类,手写数字识别,房价预测等。
非监督学习
无监督学习涉及从未标记的数据中学习数据的结构、模式或分布。训练数据不包含目标变量。
输出的是聚类和降维。
例子:欺诈监测,主成分分析(PCA)。
强化学习
强化学习是一种使用Agent通过观察环境、执行动作并从奖励中学习的学习方式。
输出的是规则,智能体(Agent)可以在环境中学会采取一系列动作,以最大化累积奖励。
例子:AlphaGo
Unit 2: Introduction to generative AI
生成式AI

生成式AI已经很NB。BLA BLA BLA
基础模型
Foundation models基础模型是使用自监督学习在大量数据上训练的神经网络,可以应用于许多任务。
一句话,基础模型就是神经网络。
大语言模型就是基础模型中的一类,是用文本和计算机代码训练出来的模型。可以用来预测一句话中的下一个字符,简单讲原理,它是一个阅读了无数文章和代码的机器 ,他所谓的“预测”就是根据模范人类在不同的语境下,不同的context下,预测一个词出现的概率,比如“今天天气真__” 如果是两个人在日常聊天,是不是说“今天天气真好”的可能性要比“今天天气真垃圾”的可能性大,但如果已经是介绍了是一个阴雨密布的早晨,是不是后者就比前者的可能性更大了,理解了这个例子,就理解了大语言模型的基本原理。
关系
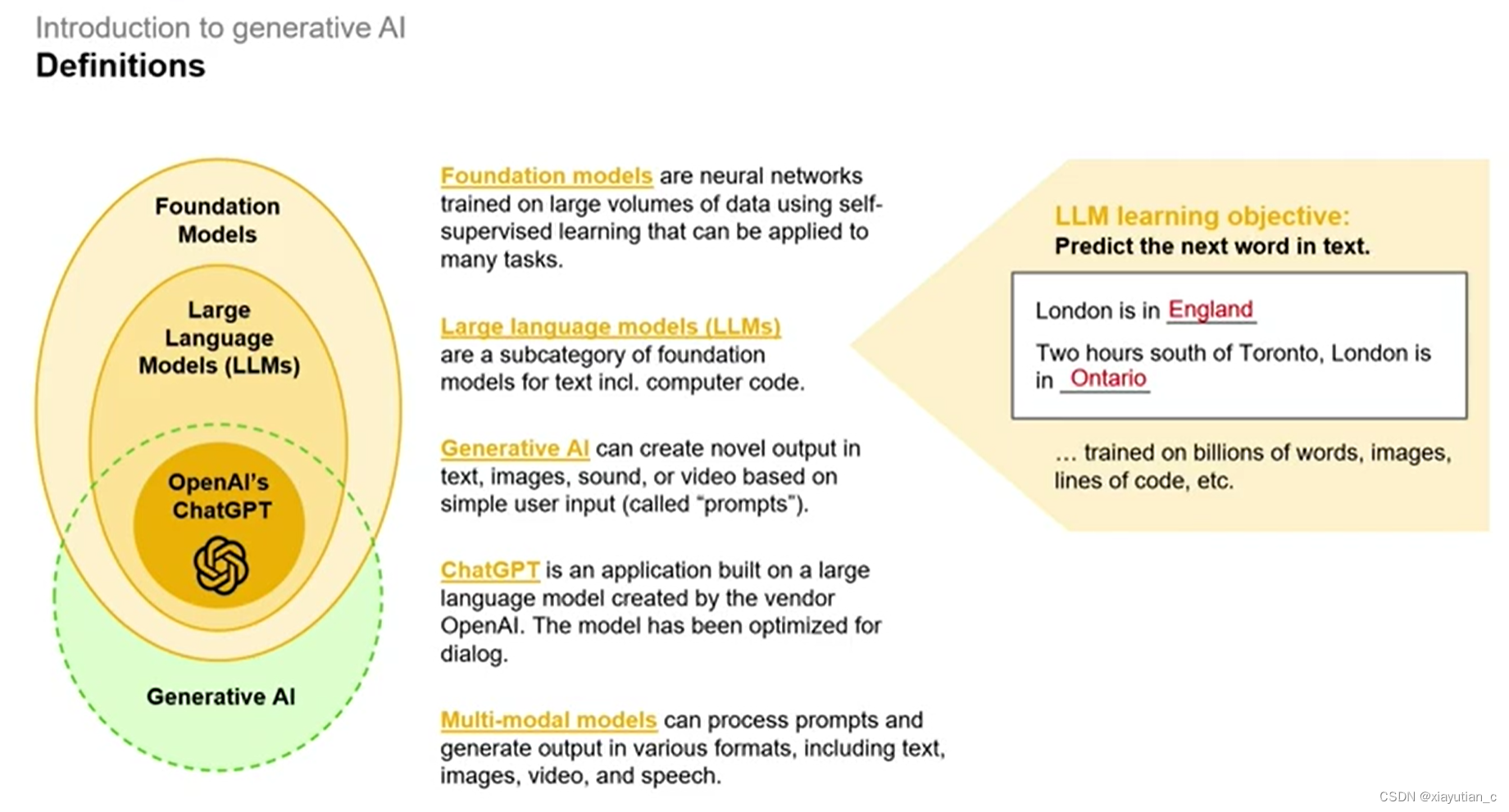
生成式AI是基础模型的一种应用,一种可以根据用户输入“提示词”而生成文本,语言,图像,视频,等类的输出的应用,不是所有的基础模型都是生成式的,也不是所有的生成式AI都是基于基础模型。
我们之所以会混淆就是因为ChatGPT,它是在几个大语言模型基础之上建立的一个应用,它是一个经过优化的并且用一来一回对话的形式的一个应用。它发现的很快,它不多个不同的模型可以处理图片,语音,后面肯定也可以处理视频等不同格式的数据,
基础模型有哪些能力呢
然后是生成式AI能实现的几个功能,没啥意思,不贴了
Unit 3: Adapting generative AI to business context
了解生成式AI的局限性,以及如何适应商业环境。
局限性可以用一句话概括,目前的生成式AI只能回答广泛的,一般性的问题。并且有时候给出的是错误答案,另外它不能提供最新的信息,有时效性,等等,只要记得它有局限性就好。
那怎么在这个局限性的基础上把生成式AI落地并适应商业应用呢
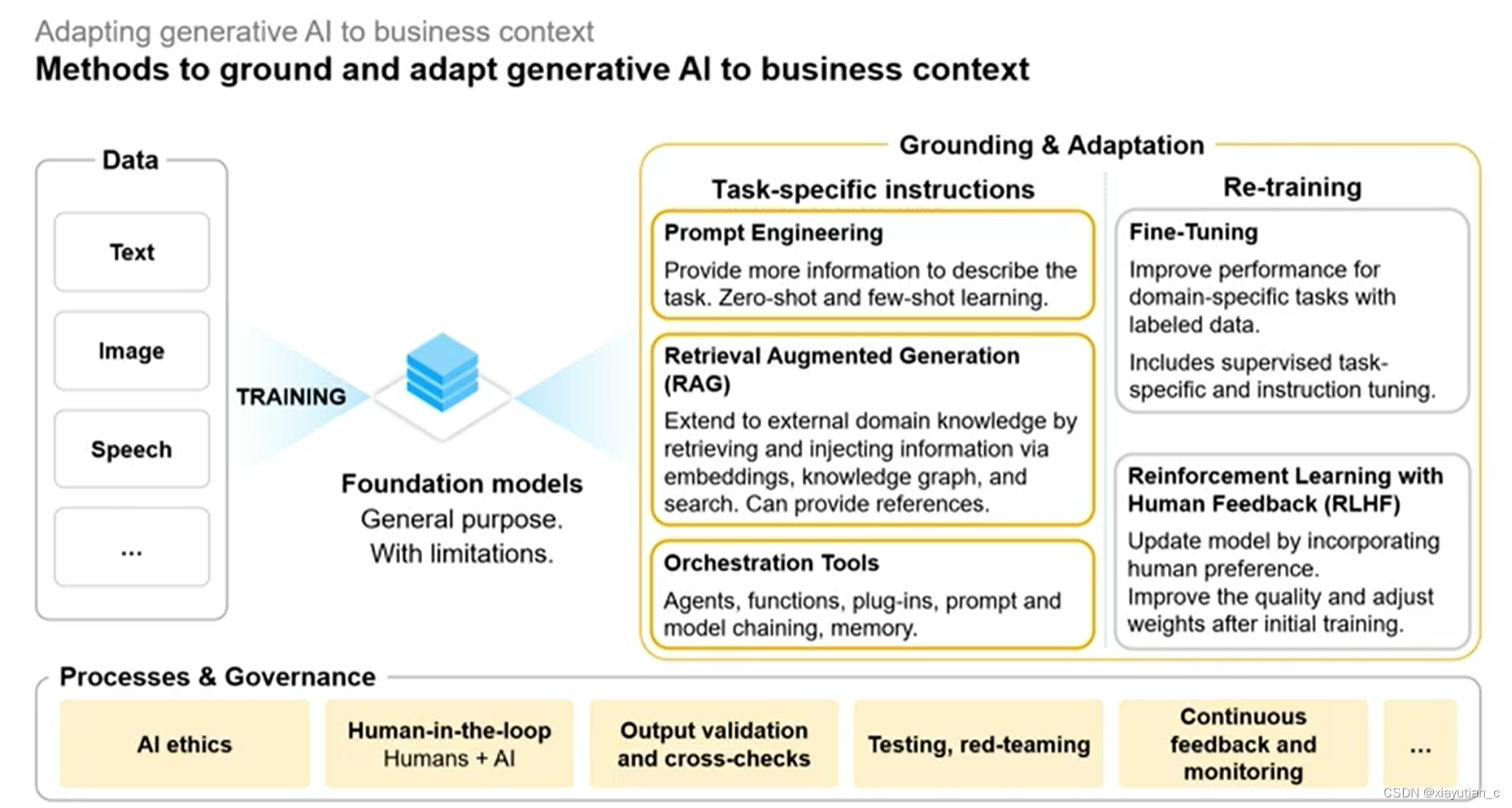
两个方向可以帮助生成式AI落地并适配商业环境:
- 特定于任务的指令:
- 提示工程:给模型提供更多的提示信息来改进其性能,
zero-shot and few-shot learning 零样本学习和少样本学习,它们使得机器学习模型能够在仅有有限数量的示例情况下对对象或模式进行分类和识别。 - RAG检索增强式生成:提供额外的信息。
- 编排工具:利用Agent,插件,提示和模型链等工具,相当于是给原来大模型加一些外挂工具。
- 再训练和调优
- 在已有模型的基础上用标注数据再训练。
- 人类反馈强化学习,就是人为加入一些偏向,改进质量和初次训练后调整权重。比如我们用chatGPT时有时会回馈一下这个答案的好坏,这些数据就可以用来再训练。
上面两类方法虽然很好,但还不足以让生成式AI落地到正式的商业环境,还有一些额外的流程和管理:
- AI道德,这是前提
- 引入人类,当大模型的答案不是很稳定时,需要人类可以介入。
- 对输出进行校验和交叉对比,比如模型推荐了一个采购订单,这时可以加入一些校验,比如检查物料号和供应商主数据是否真实存在,格式是否正确等等。
- 更多的测试
- 持续反馈和监控
Prompt engineering
结合下面的例子再来看是如何利用好的提示工程并且加入了人为的注入更多的信息来使用生成式AI完成一项具体的任务:写一个JD
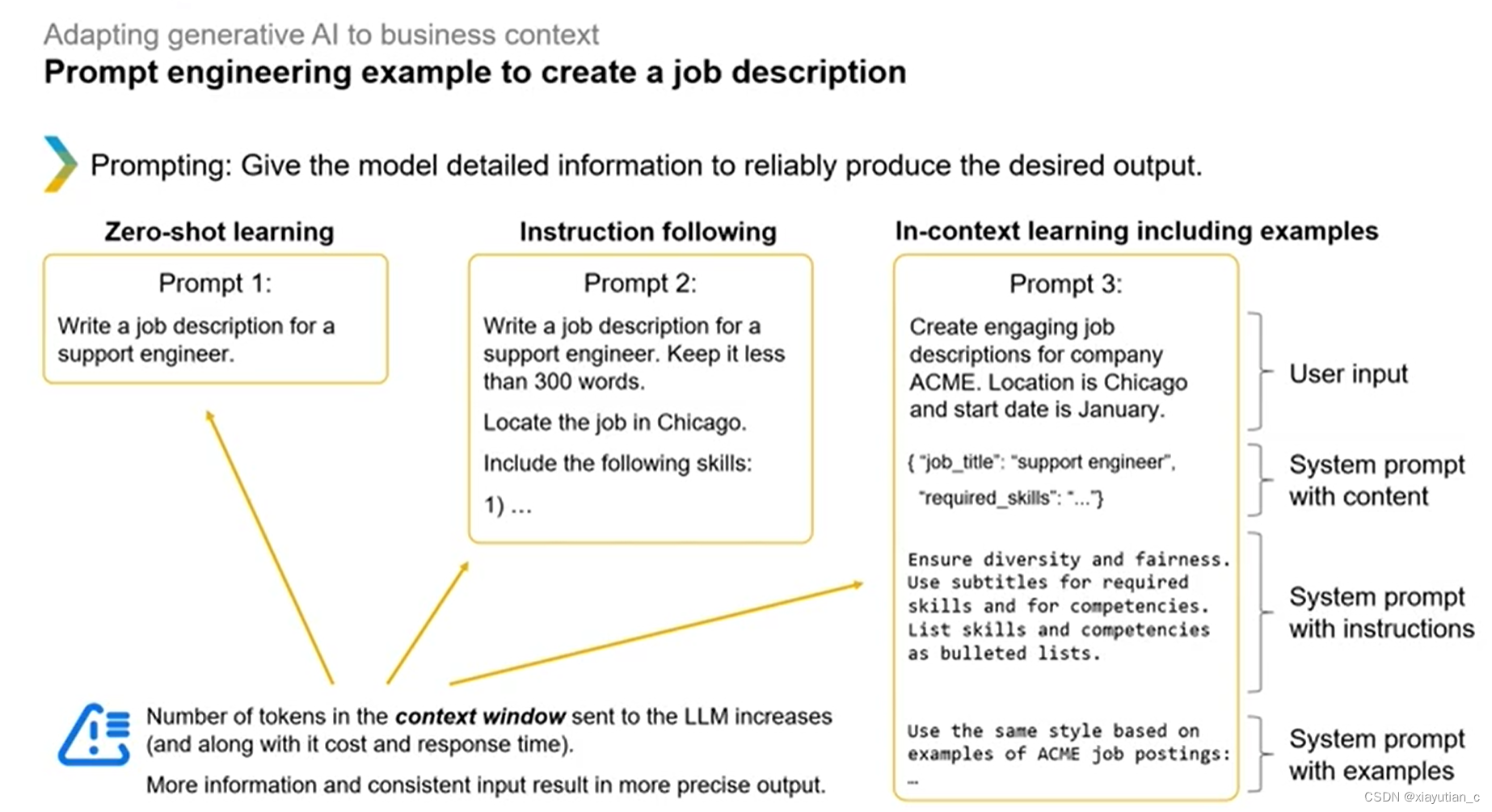
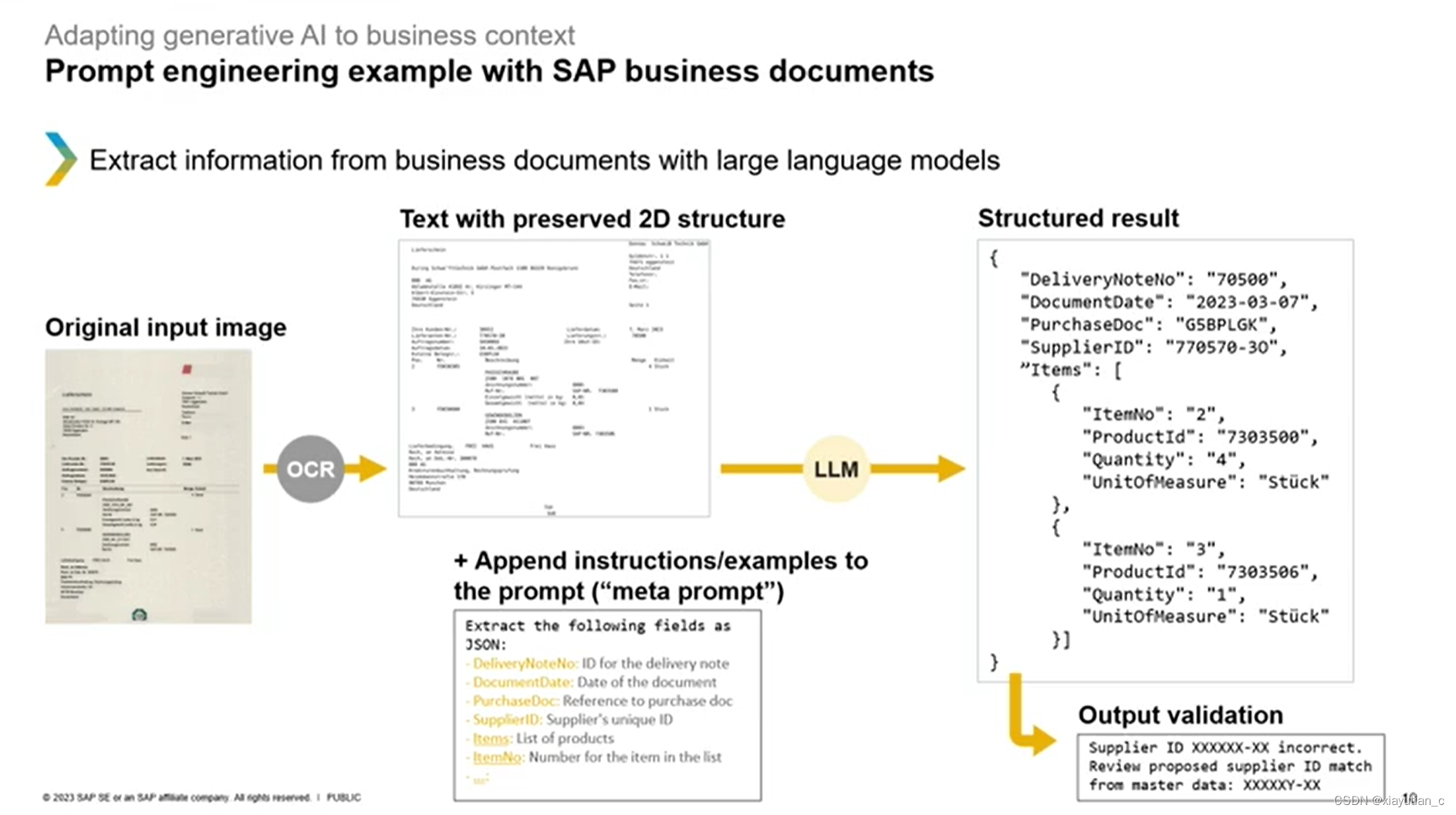
可以看出来,给的信息越多,输出就越准确。
下面的例子就是引入了OCR这个外部工具,再注入了一些结构化的"元提示",一步步得到输出 ,当然输出后还要再加入一些额外的validation和cross check来提高输出的准确度。
RAG
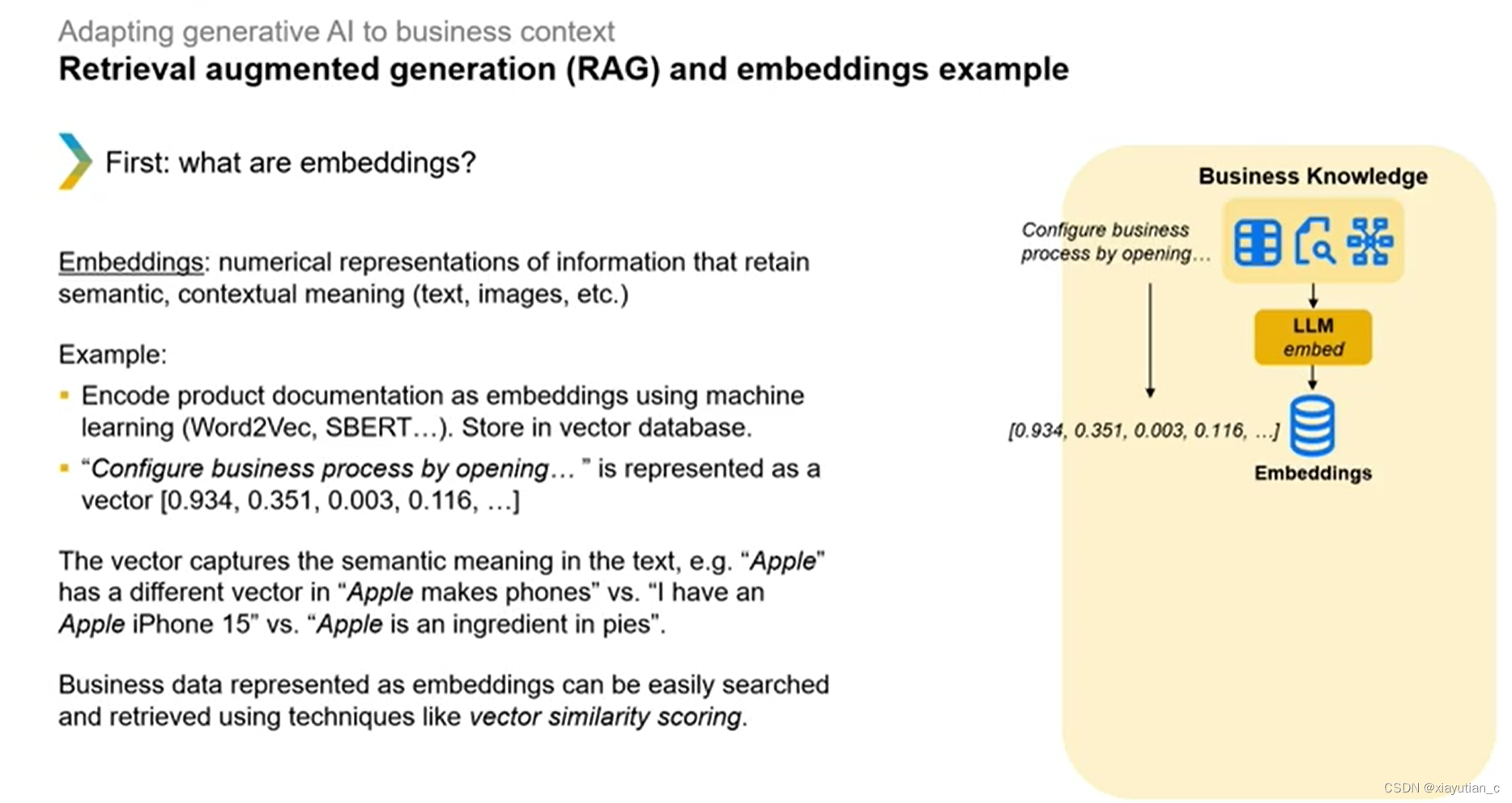
接下来是十分重要的RAG,这里也是很难理解的一部分,首先,什么是embeddings嵌入?
(我只理解到RAG是挂载一些本地内容到大模型,但技术是如何实现的这部分有点过于专业,不深入研究了。涉及向量和各类专业的算法。)
字幕解释,嵌入Embedding就是在保留语义不变的前提下把信息数字化。比如使用机器学习的…算法把生产文档编译成"嵌入"保存到向量数据库里。通过这样的方式把业务内容嵌入到向量数据库
于是,整个使用过程就是下面这样:
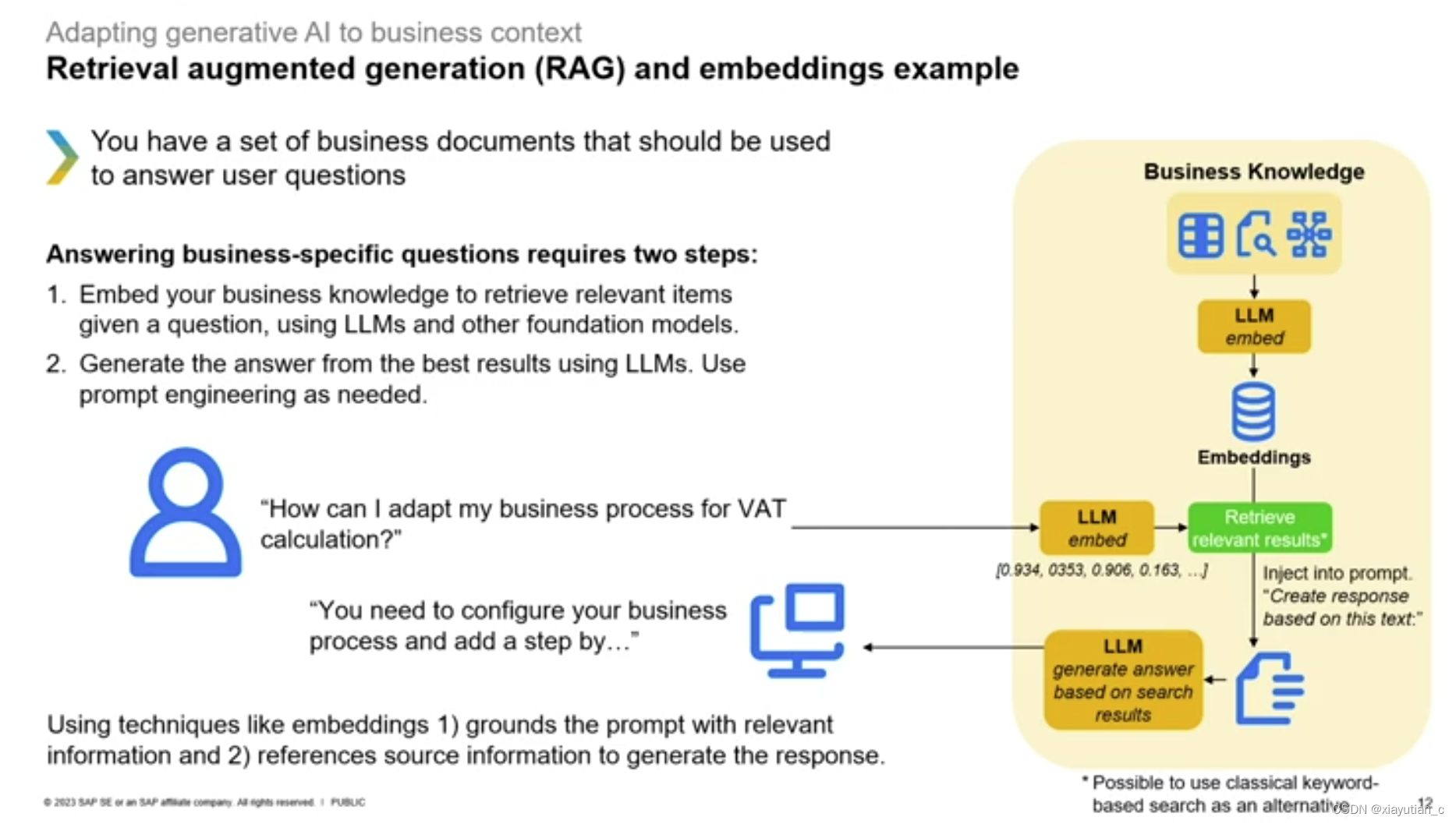
首先有一组业务文档可以帮助回答用户问题,回答具体业务问题就变成了下面两步:
- 使用大语言模型和其他基础模型,嵌入我们的业务知识以检索给定问题的相关项目。
- 使用大语言模型从最好的结果中生成答案。
Orchestration tools
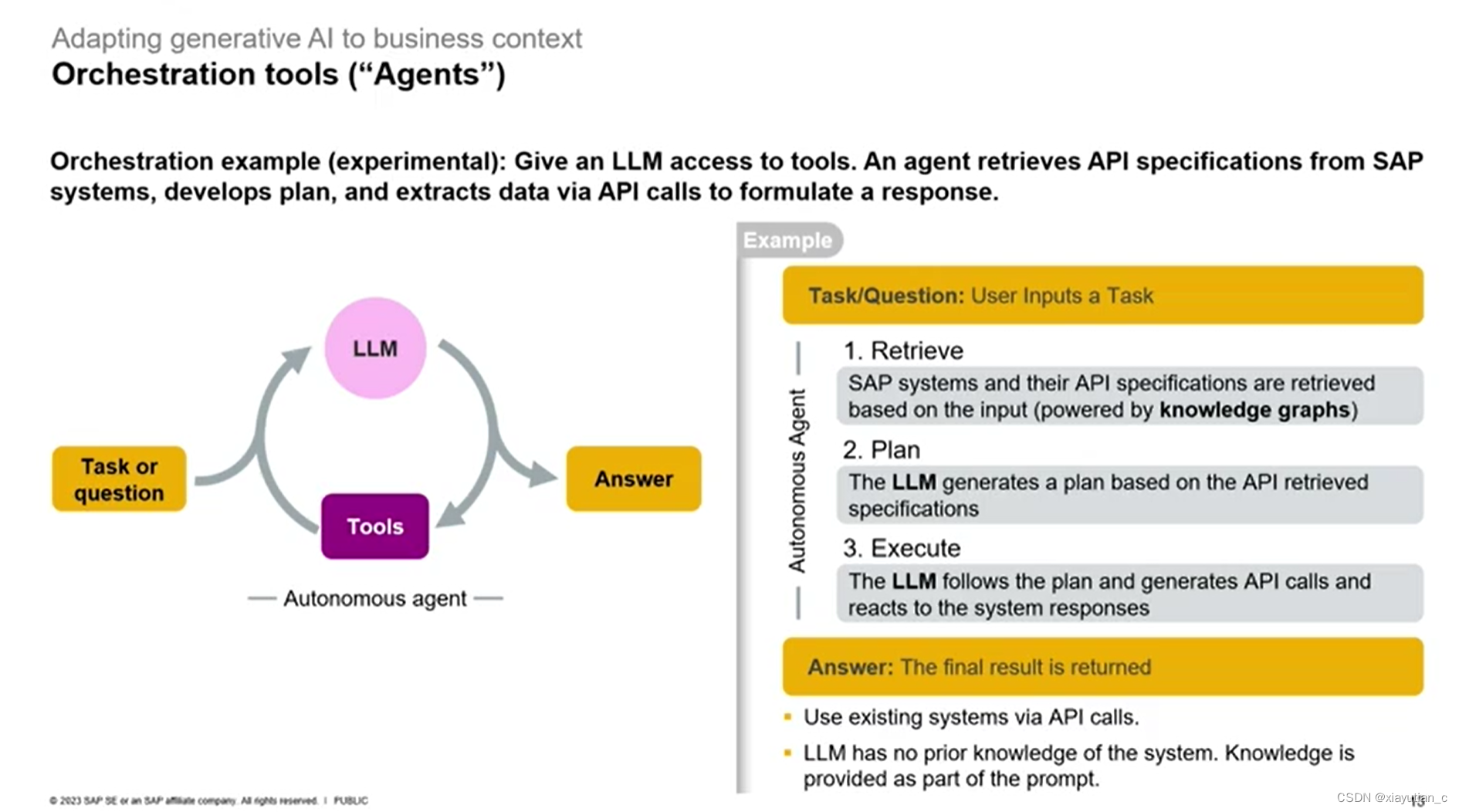
下面这个就厉害了,工具化,Agent化,这个目前看来理是有点理想化,目前应该还没实现,就是搞一个Agent,用户输入一个要完成的任务,Agent具有访问各API的权限,然后Agent先生成一组计划,这组计划组合起来可以完成这个任务,其中可能包括访问某些API,它自己来组织调用API需要的JSON报文,再用LLM分析中间状态,最终产出结果 ,这真的很智能,但实现起来有点理想化。相信未来一定可以。
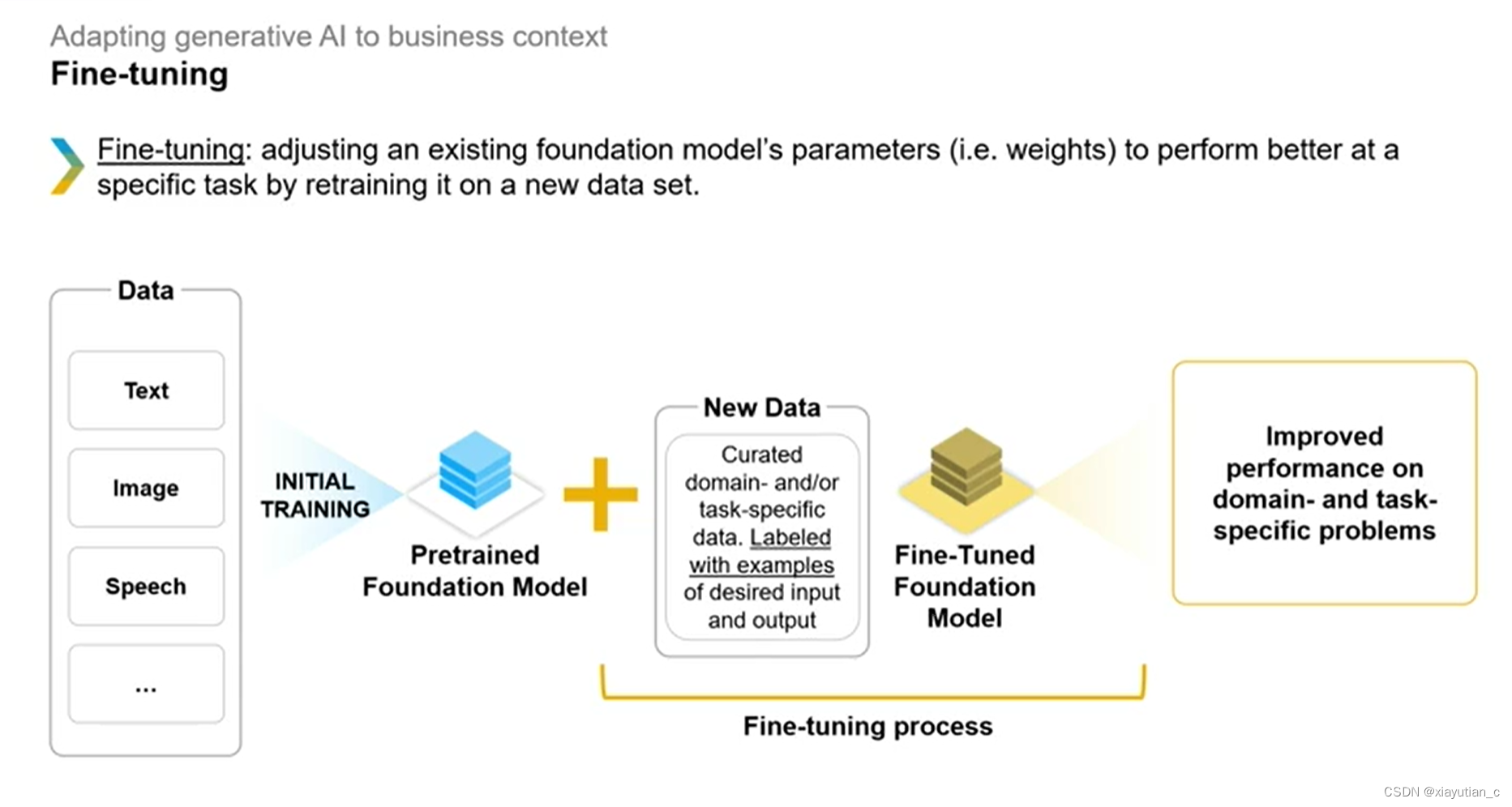
Fine-tuning
最后没办法了再使用调优的方式再次训练现有基础模型,这个费钱费力,尽量别做

四做四不做
总后,总结一下四做四不做,我认为目前来说是非常重要的:
- 不要太相信生成式AI的结果,尤其是应用在真实生产环境中,要谨慎
- 不要上来就要对模型调优,要先试试优化提示词或是考虑下RAG
- 不要上来就用最大的模型,模型不是越大越适合,要测试和适配更有针对性的性价比高的模型
- 不要没有准备好上来就把生成式AI的某一个功能产品化了,要确保有人为监控和及时介入

零样本学习,少样本学习
-
零样本学习(Zero-Shot Learning)是一种能够在没有任何样本的情况下学习新类别的方法。通常情况下,模型只能识别它在训练集中见过的类别。但通过零样本学习,模型能够利用一些辅助信息来进行推理,并推广到从未见过的类别上。这些辅助信息可以是关于类别的语义描述、属性或其他先验知识。
-
一次样本学习(One-Shot Learning)是一种只需要一个样本就能学习新类别的方法。这种方法试图通过学习样本之间的相似性来进行分类。例如,当我们只有一张狮子的照片时,一次样本学习可以帮助我们将新的狮子图像正确分类。
-
少样本学习(Few-Shot Learning)是介于零样本学习和一次样本学习之间的方法。它允许模型在有限数量的示例下学习新的类别。相比于零样本学习,少样本学习提供了更多的训练数据,但仍然相对较少。这使得模型能够从少量示例中学习新的类别,并在面对新的输入时进行准确分类。
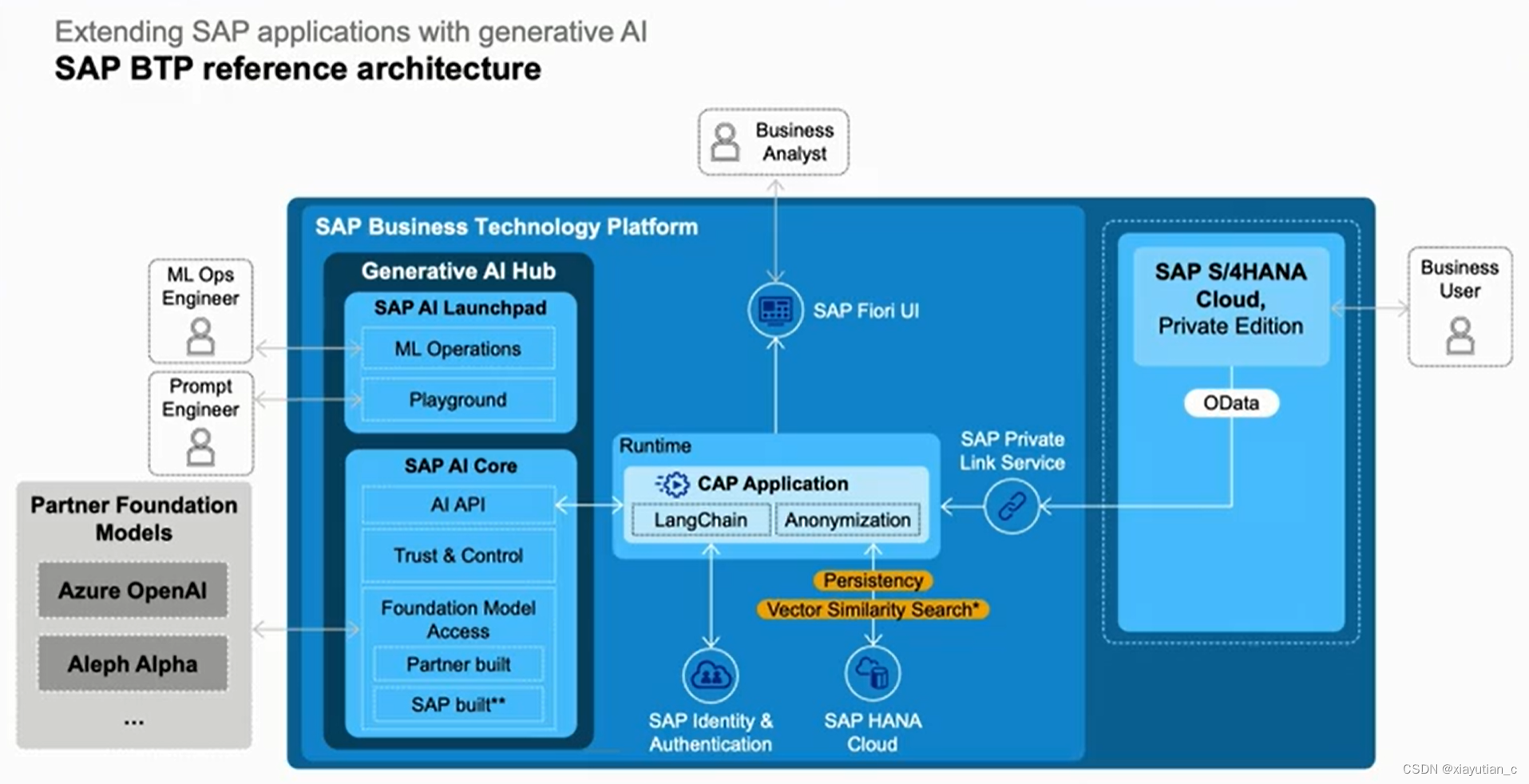
Unit 4: Extending SAP applications with generative AI
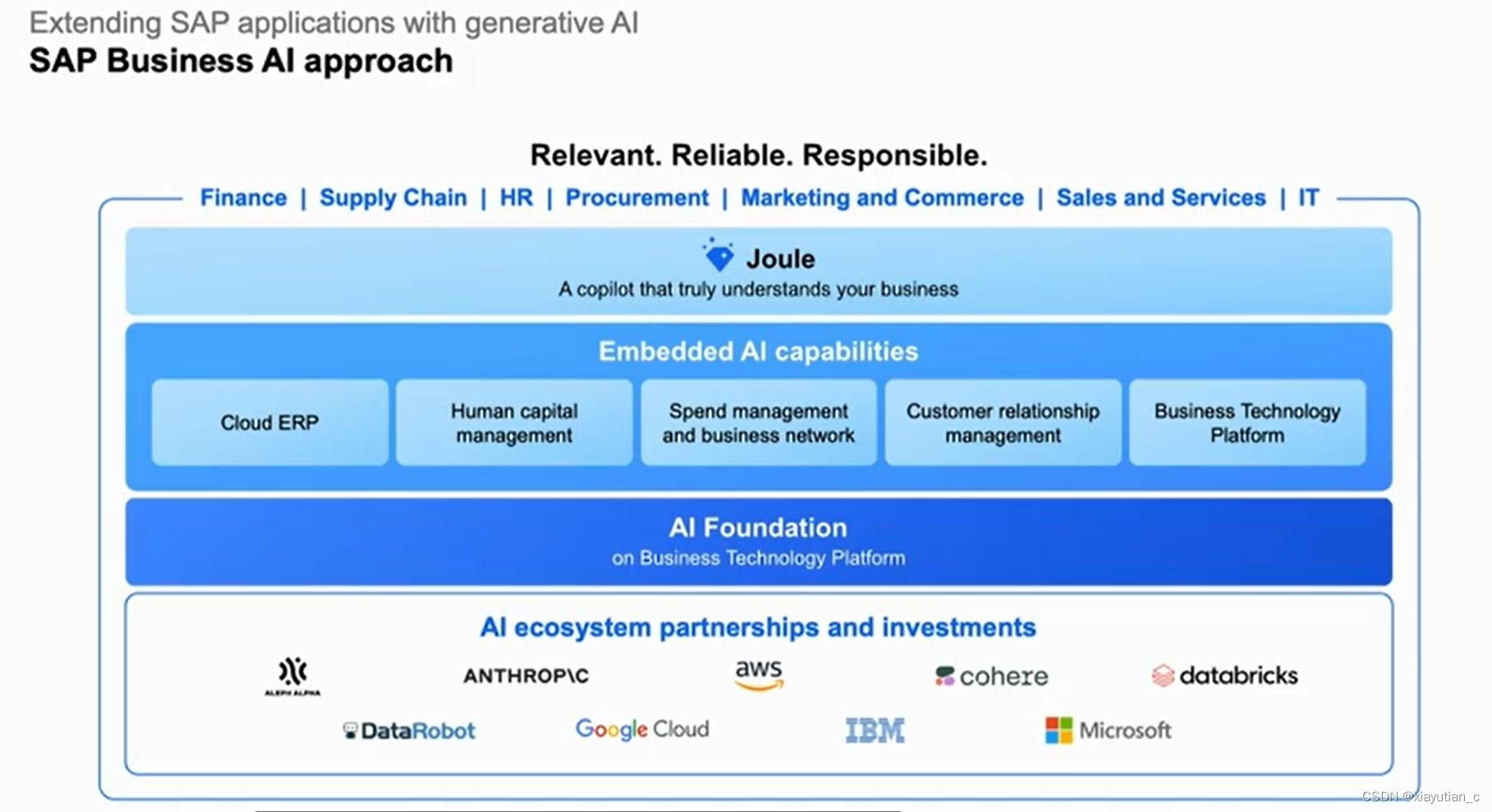
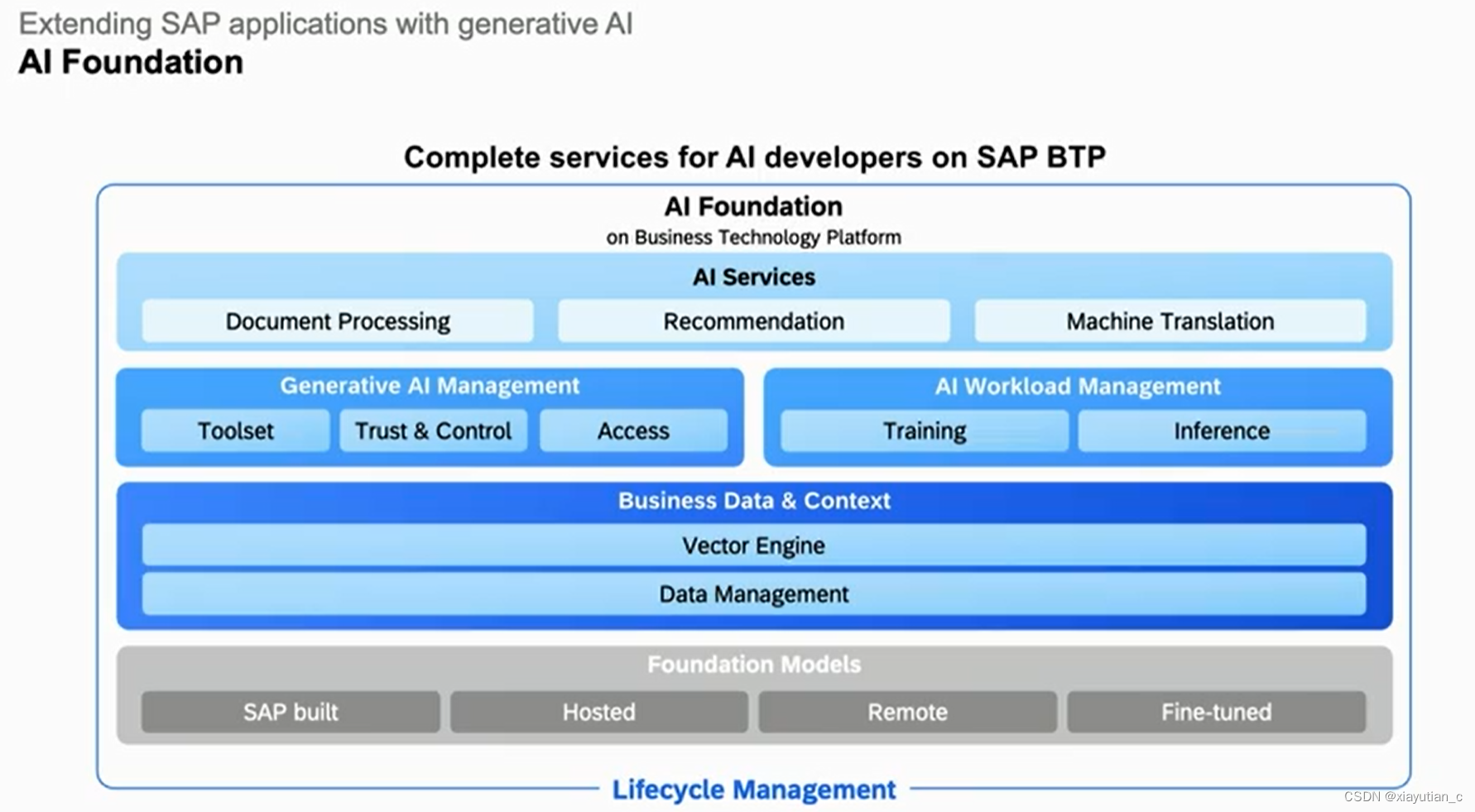
其中Vector Engine和Data Management能力可以帮助落地应用,确保企业的数据以合适的上下文应用在LLM中。
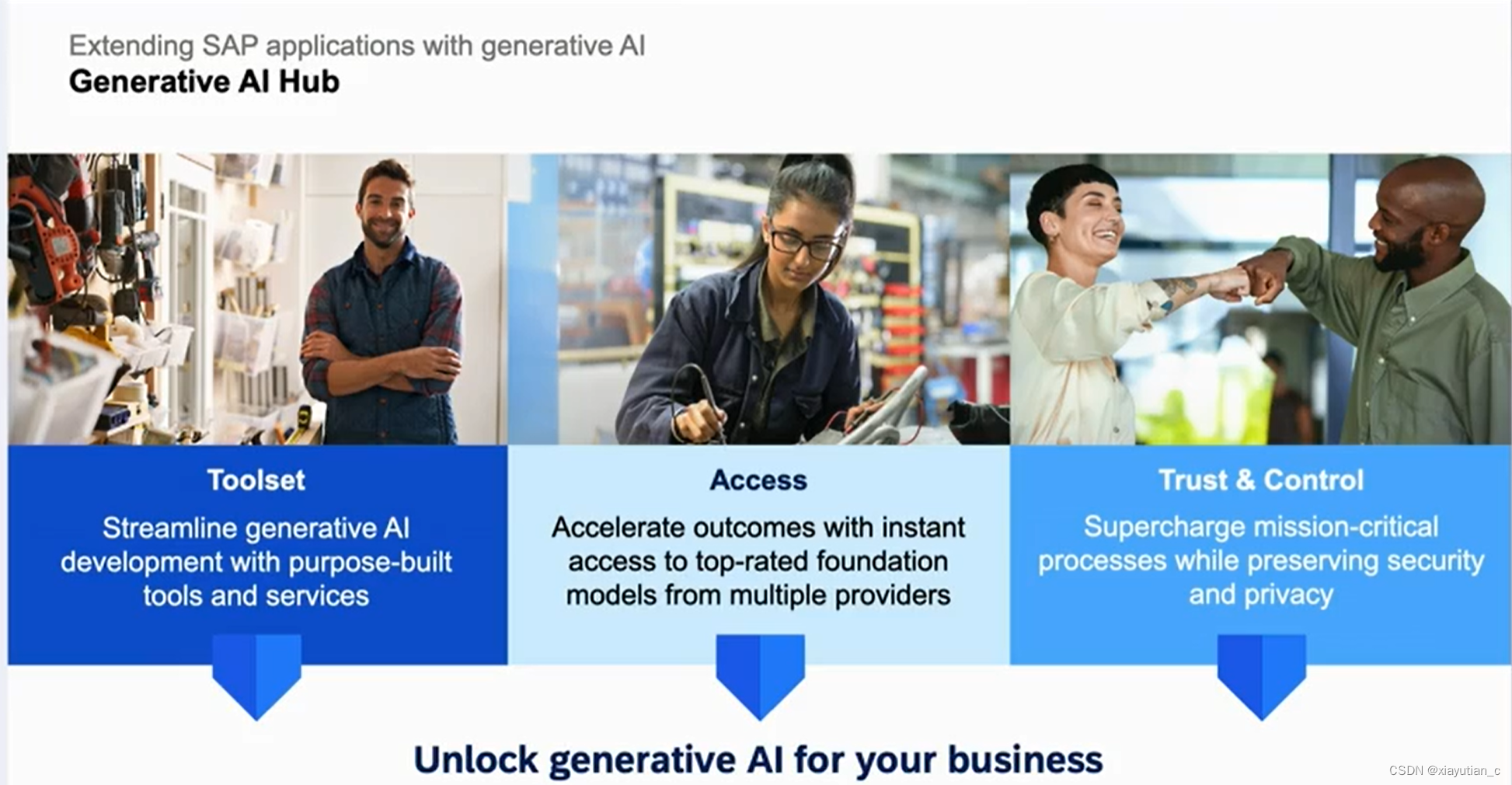
还有像API HUB一样,SAP搞了一个Generative AI HUB,提供工具和市场流行大模型的访问。下面是具体内容,其中带星号是还没有实现的。
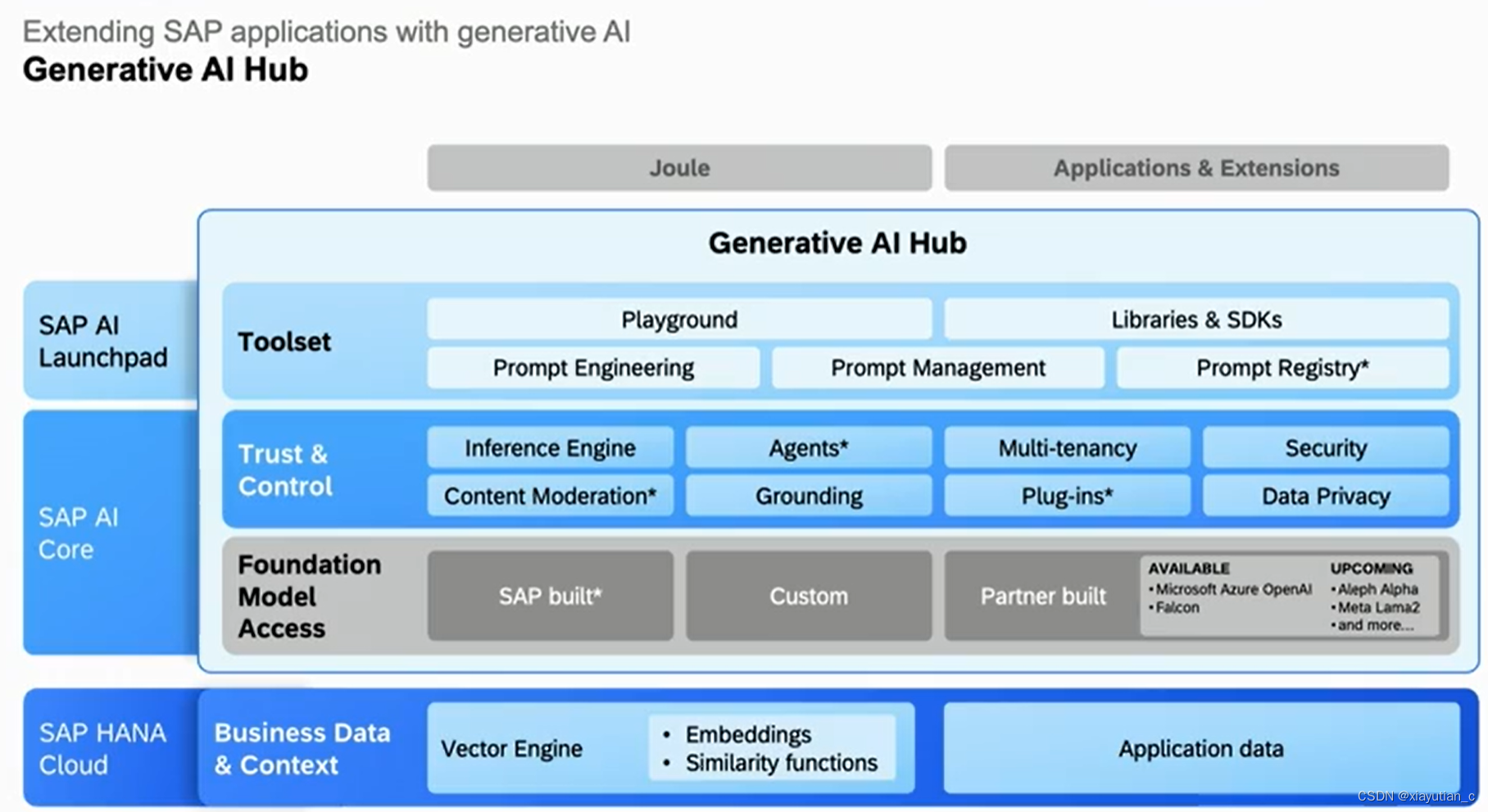
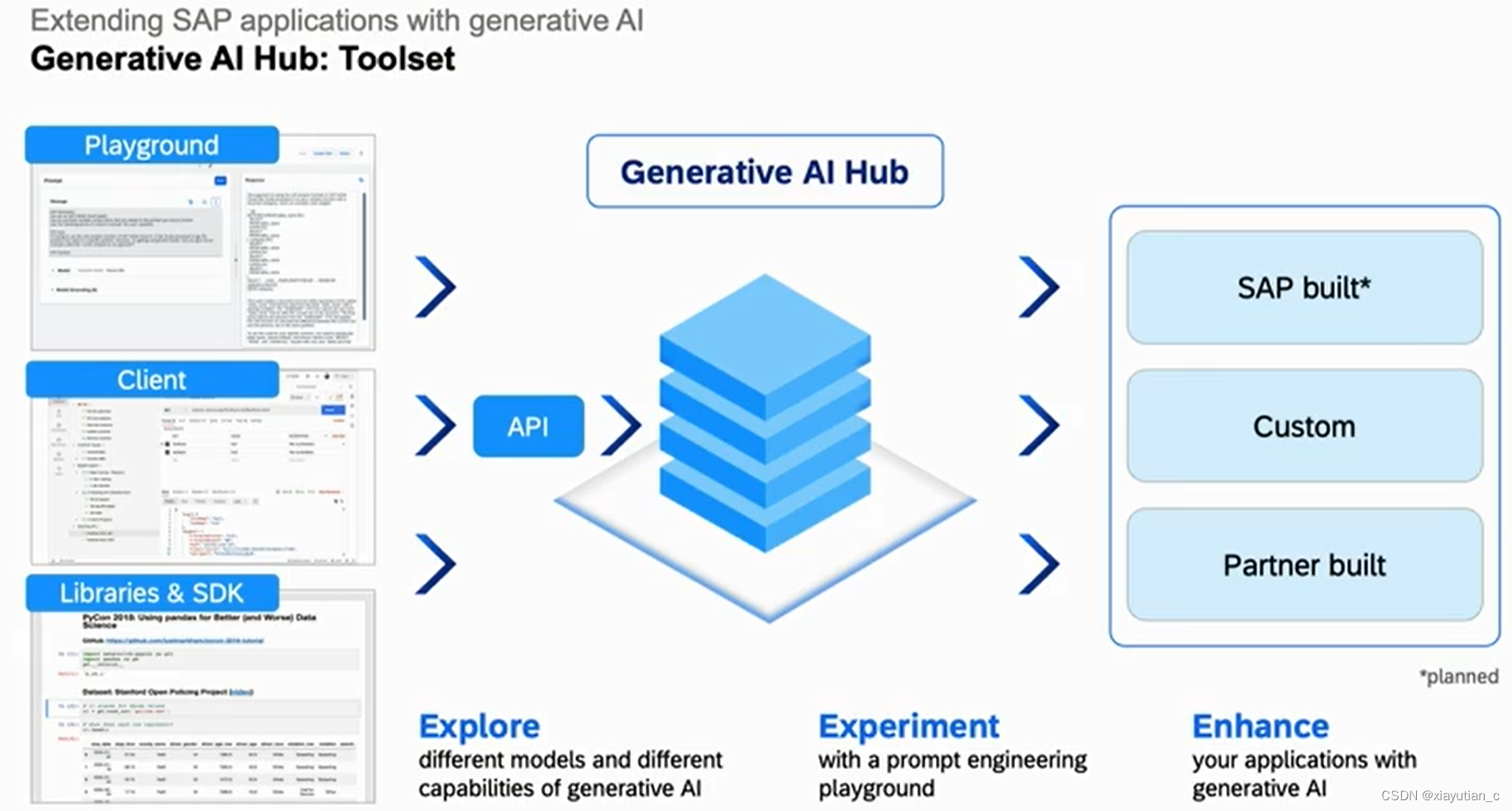
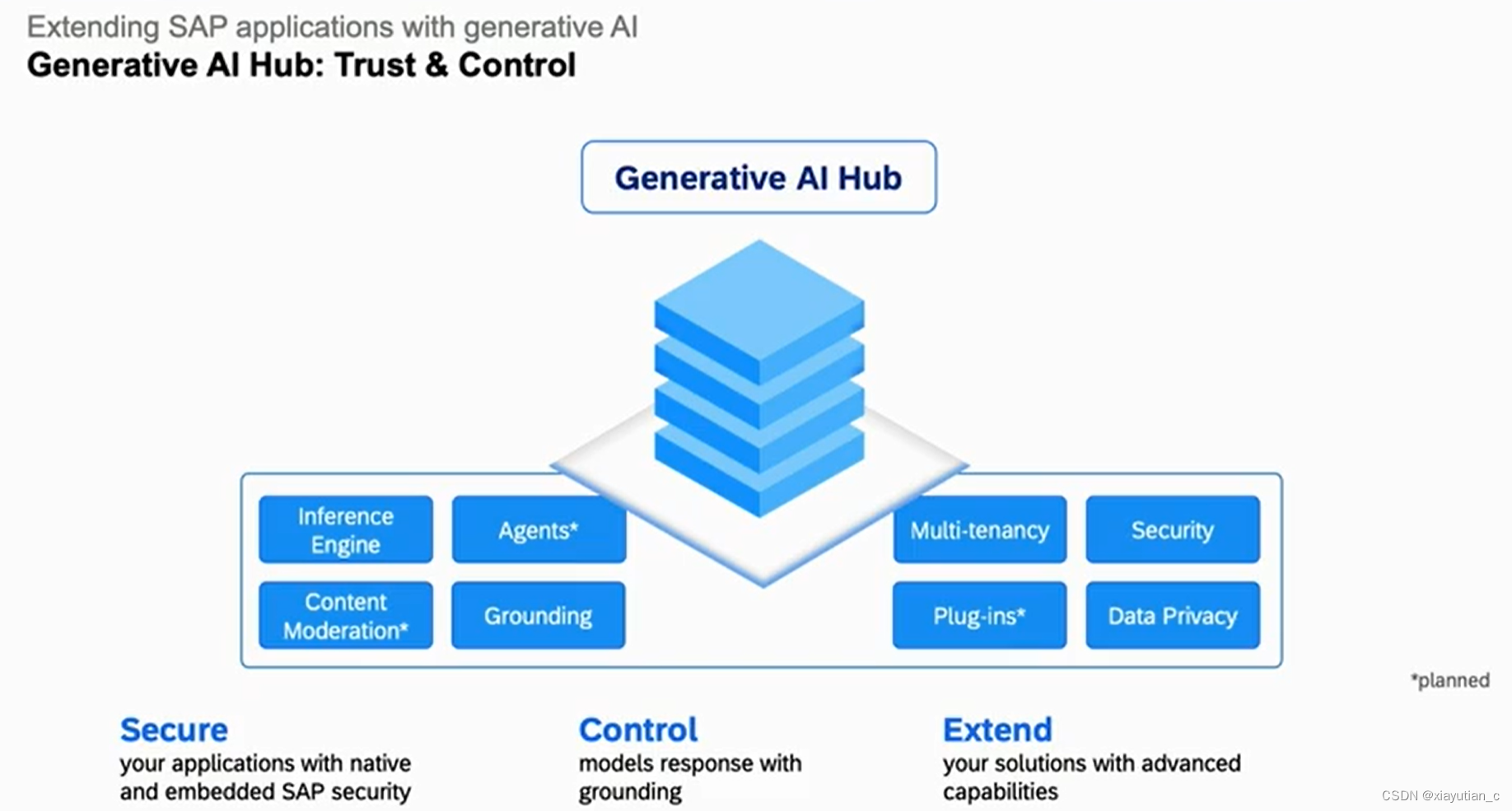
再逐步展开,具体看ToolSet,Trust&Control
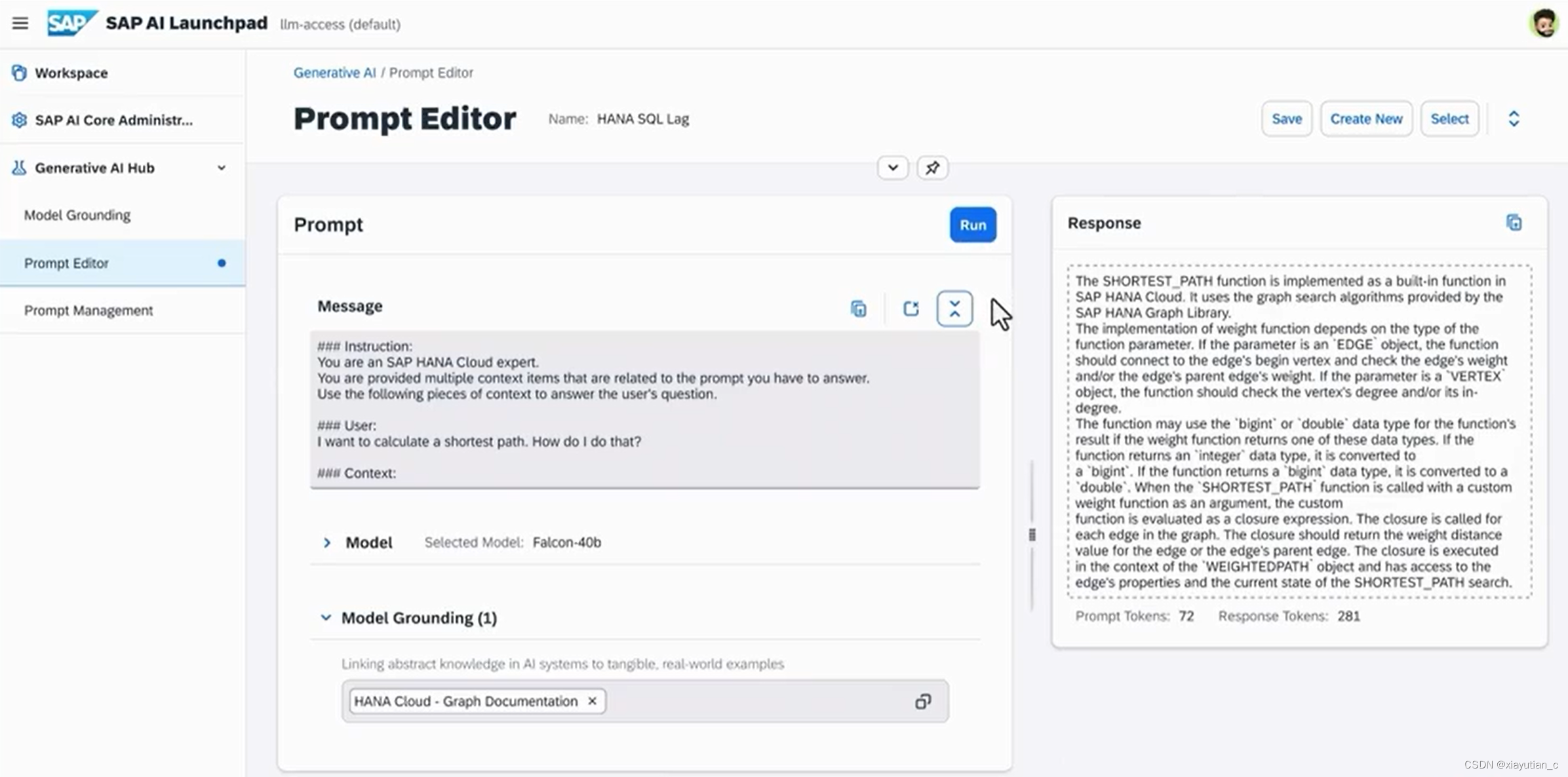
然后演示了其中一个prompt功能
再举一个接近实际应用的例子来说明如何利用各组件和能力,下图实用是一个邮件分析应用,有几个点:
Anonymization是把邮件匿名化,做为安全策略方面的考虑,然后从下面的SAP HANA Cloud里向量检索有没有相似的邮件,右边从PCE里调取需要的数据,最核心的是有区别的SAP AI Core的交互,利用了BTP上这个Generative AI Hub实现应用的功能。
Unit 5: Generative AI business use cases
生成式AI的商业应用
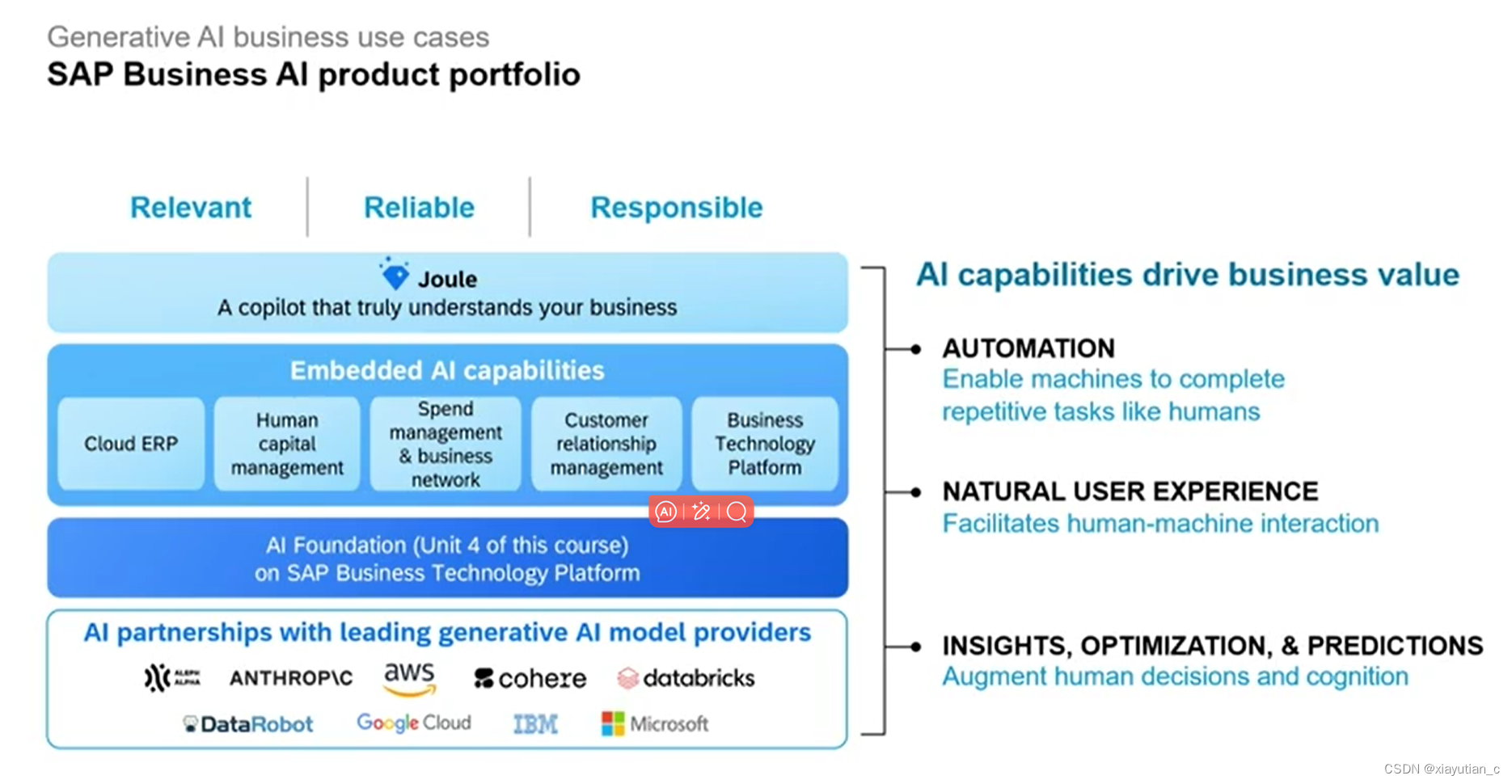
人工智能能力驱动商业价值主要在三个方面:
- 自动化,使机器能够像人类一样完成重复的任务。
- 自然的用户体验,促进人机交互洞察。
- 优化和预测,增强人类的决策和认知。
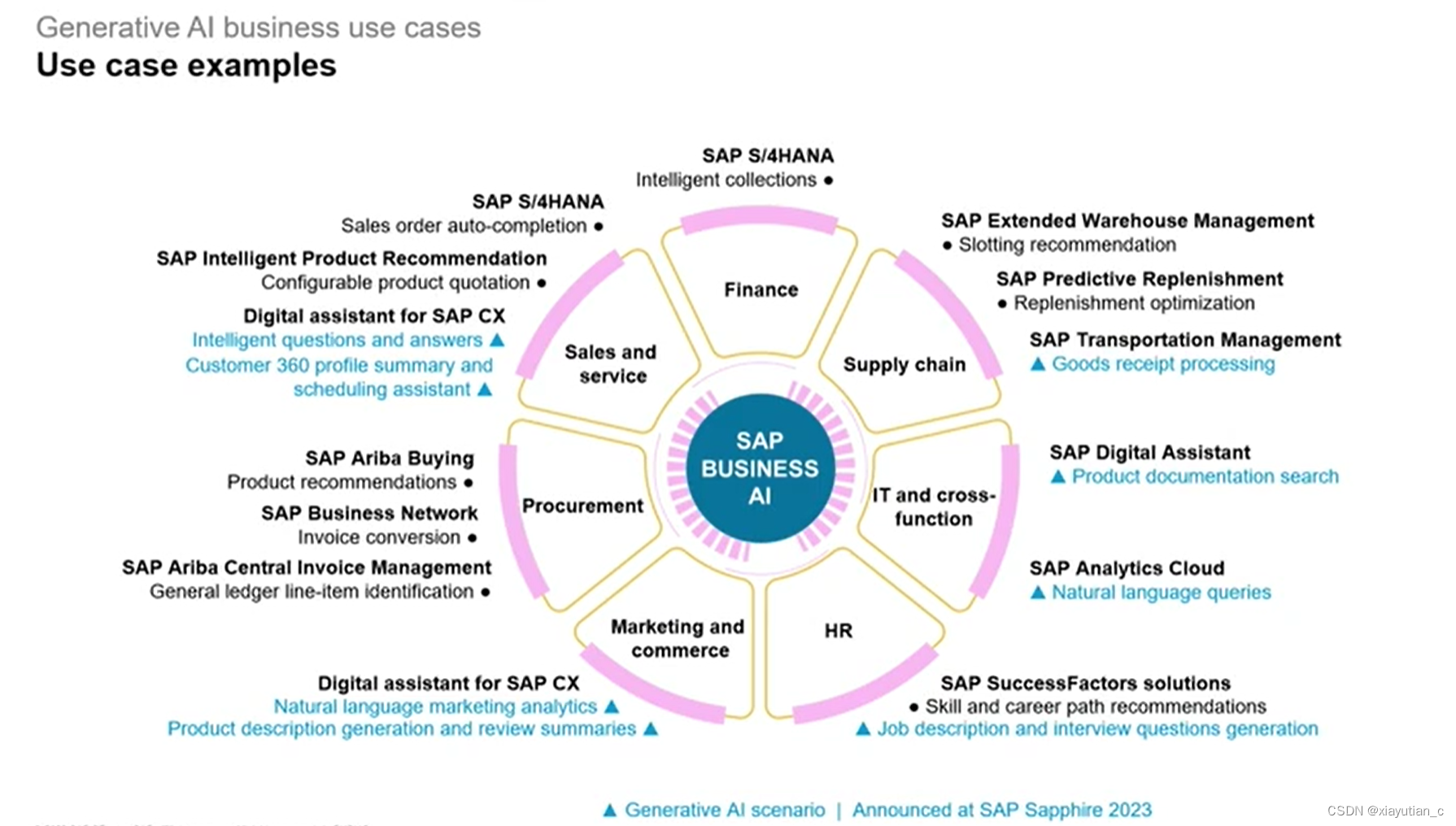
下面是一波SAP已经实现商业应用的说明
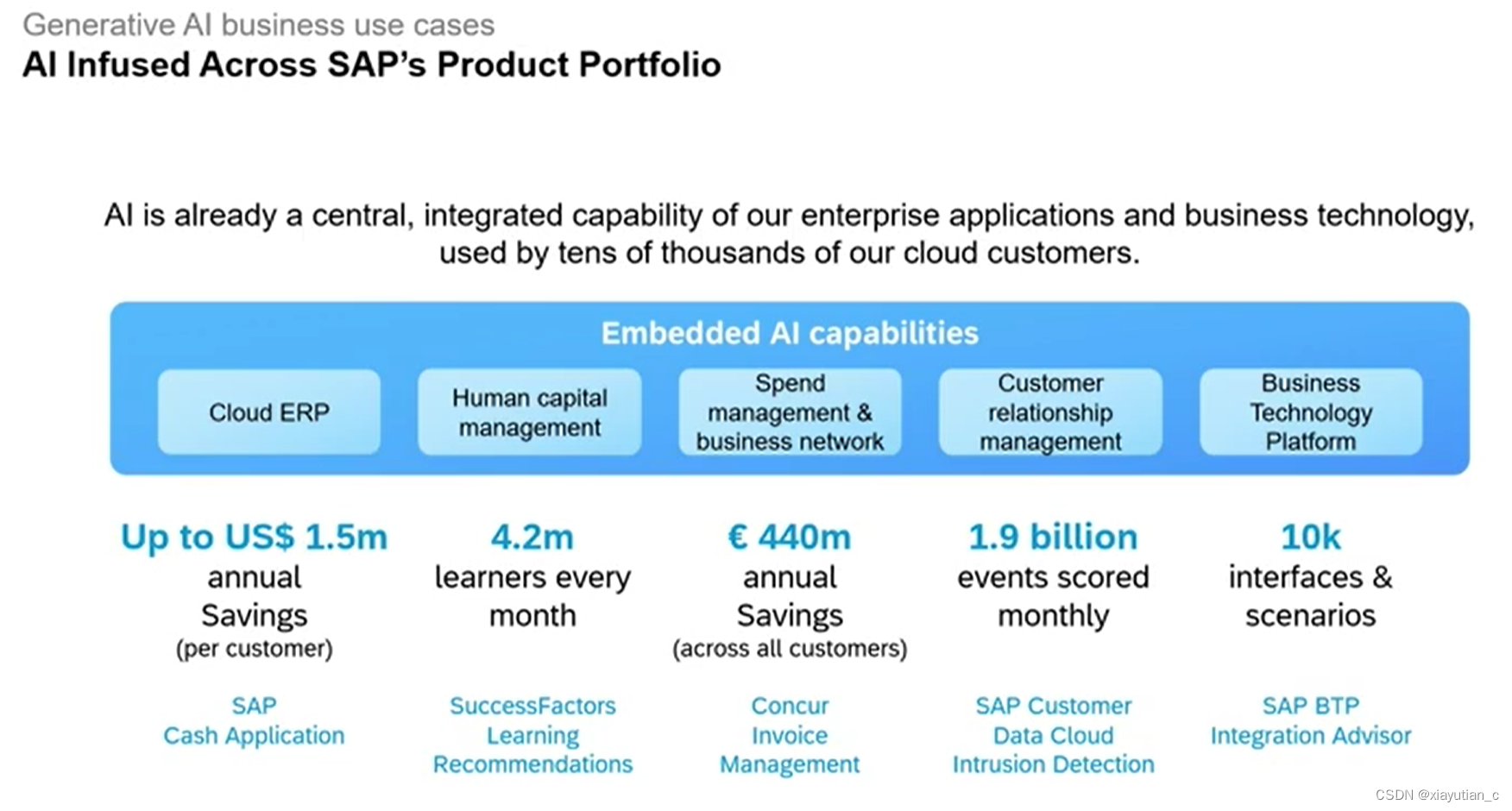
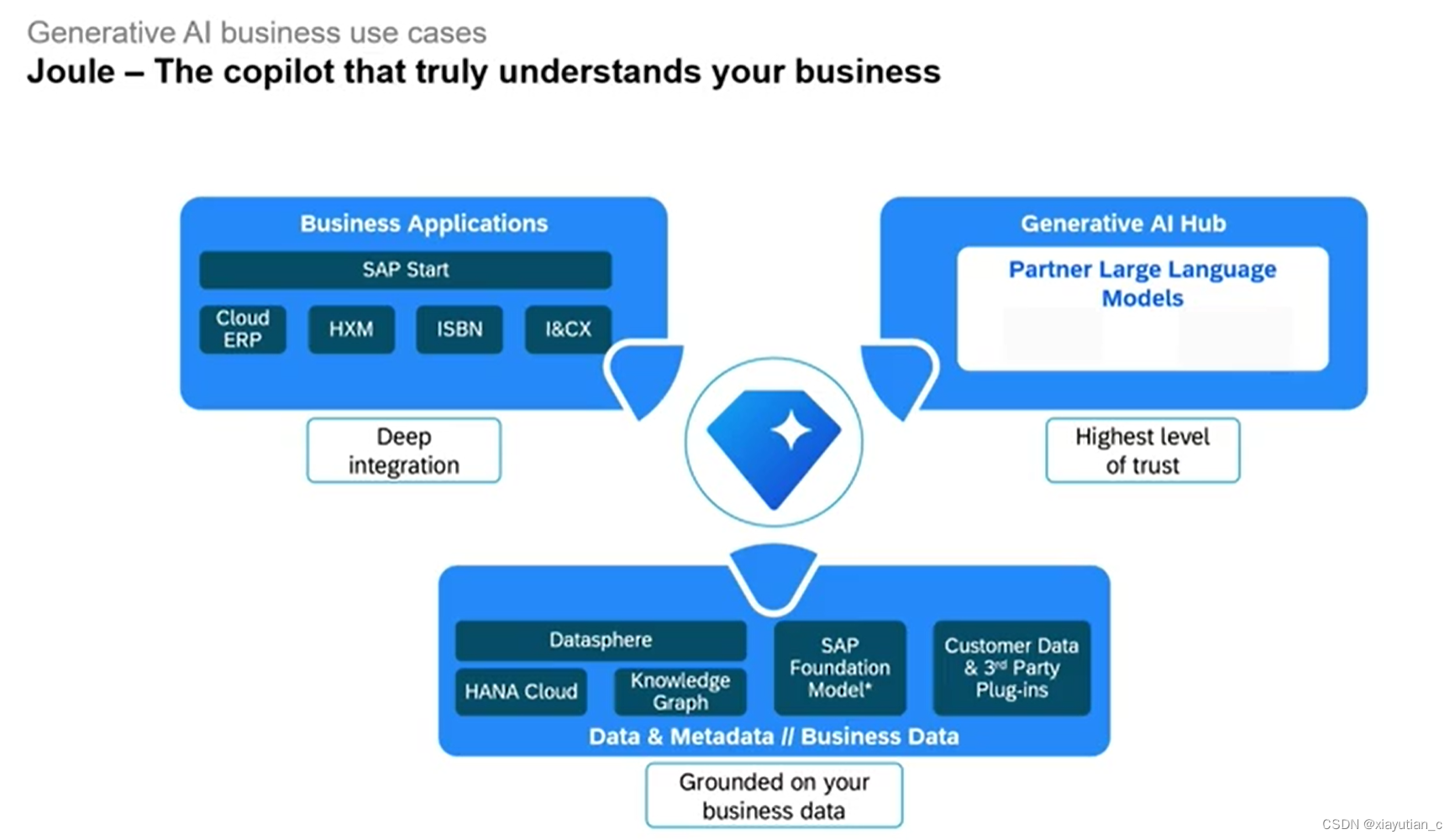
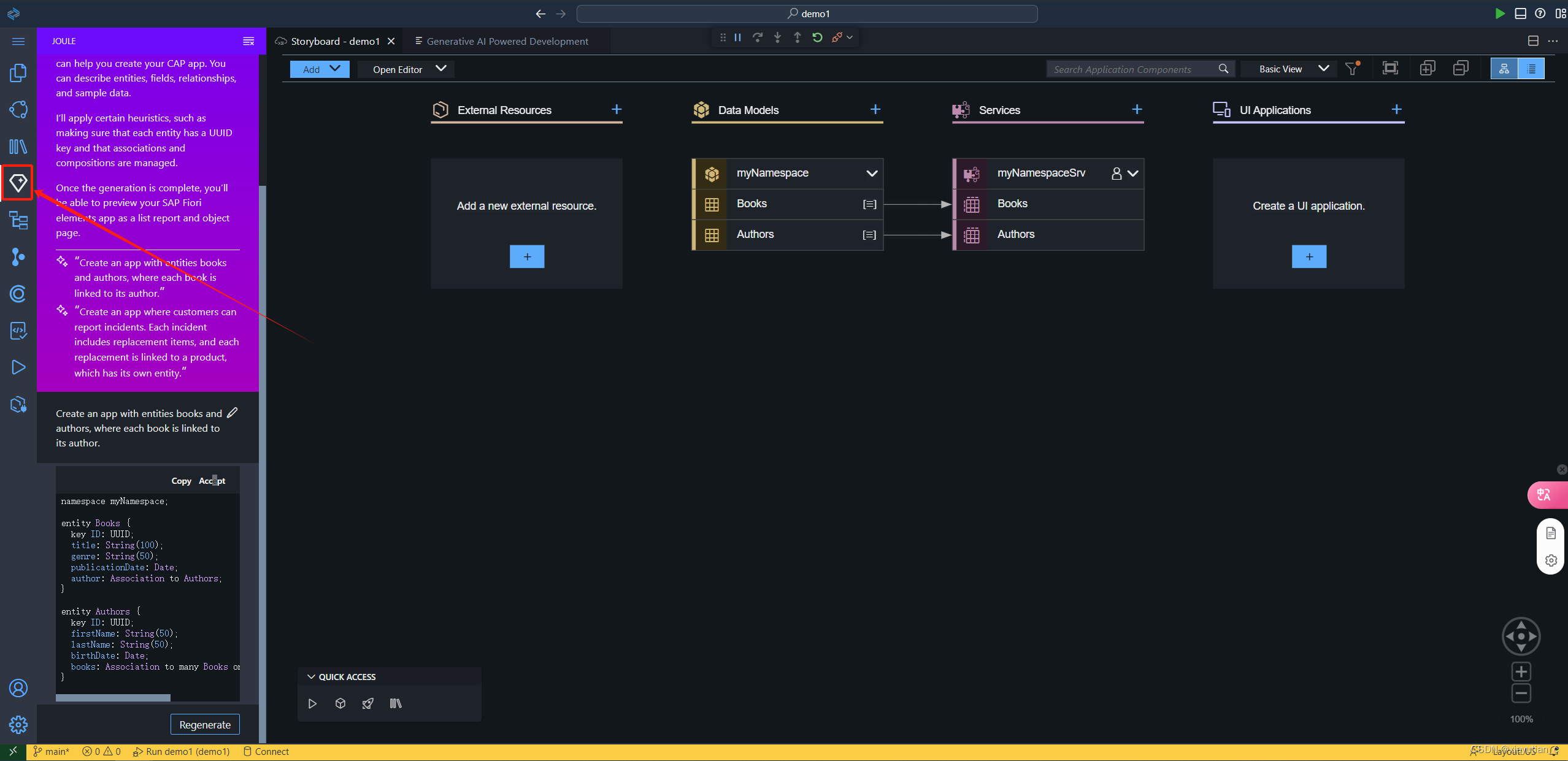
然后稍微说明了一下几个实际应用,我最感兴趣的还是据说可以帮自动完成开发的Joule,实际它能做的工作非常多,像是一个已经实现了的Agent,它可以自己去调用SAP相关的API进行一些action的操作,比如调用BAPI完成订单的创建,提交审批,发布招聘等等。非常期待它的正式版,但从前几节的内容看,AI目前还是不可全信的,要有人工参与才行。
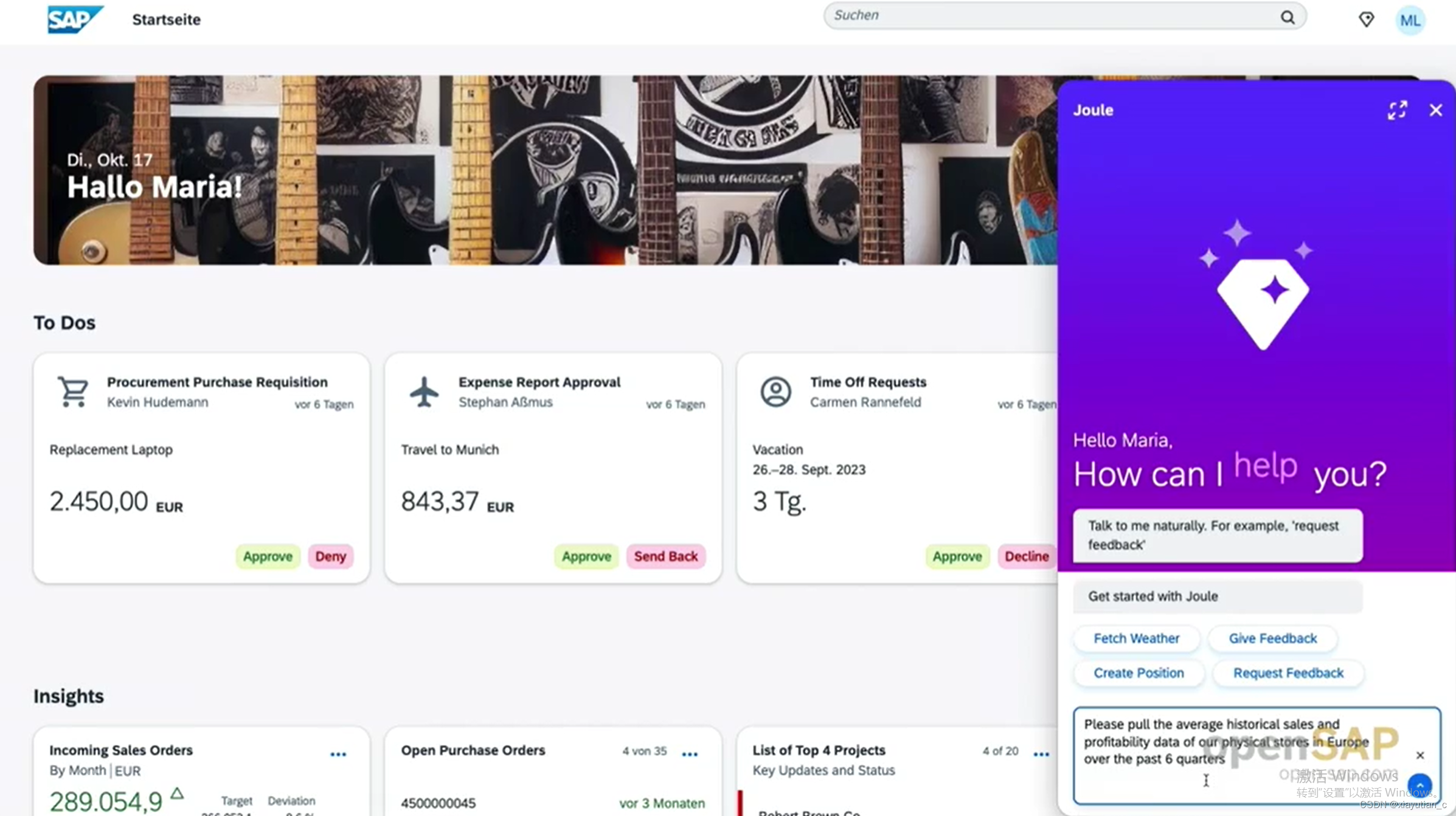
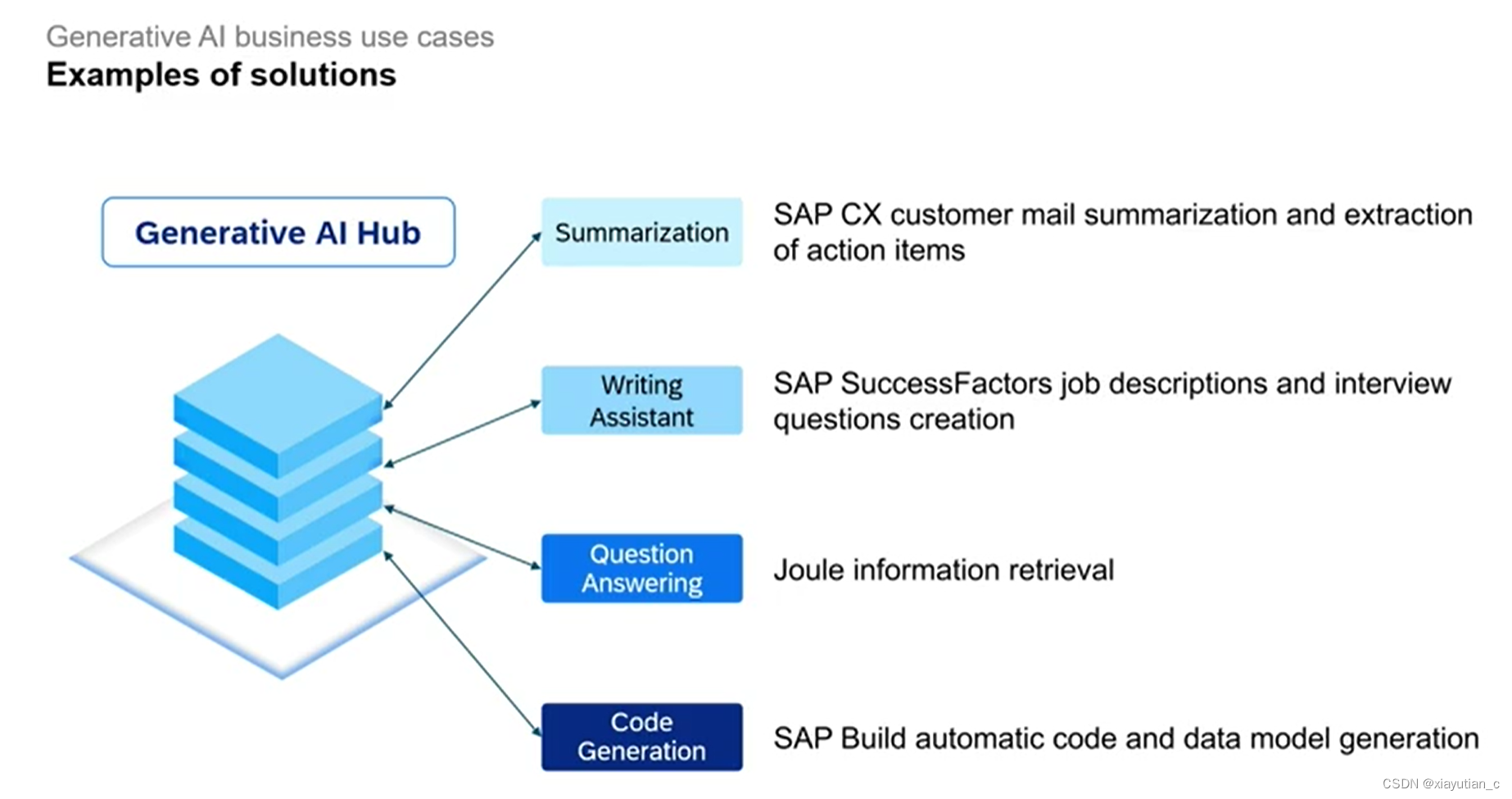
Generated AI可以做的几类工作:
- 汇总
- 写作助手
- 问讯
- 代码生成
再到SAP商业应用中
接下来我准备再花点时间在 Joule。
了解下这颗宝石吧
参考
https://blog.csdn.net/qq_35831906/article/details/134349445
https://blog.csdn.net/weixin_42010722/article/details/131182669