文章目录
- 一、关于 Ragas
- 二、安装🛡️
- 三、快速使用 🔥
- Open Analytics 🔍
- 四、References
- 五、生成综合测试集
- 文档
- 数据生成
- 六、使用您的测试集进行评估
- 数据
- Metrics 指标
- 评估
- 七、监控生产中的 RAG
- 需要监控的方面
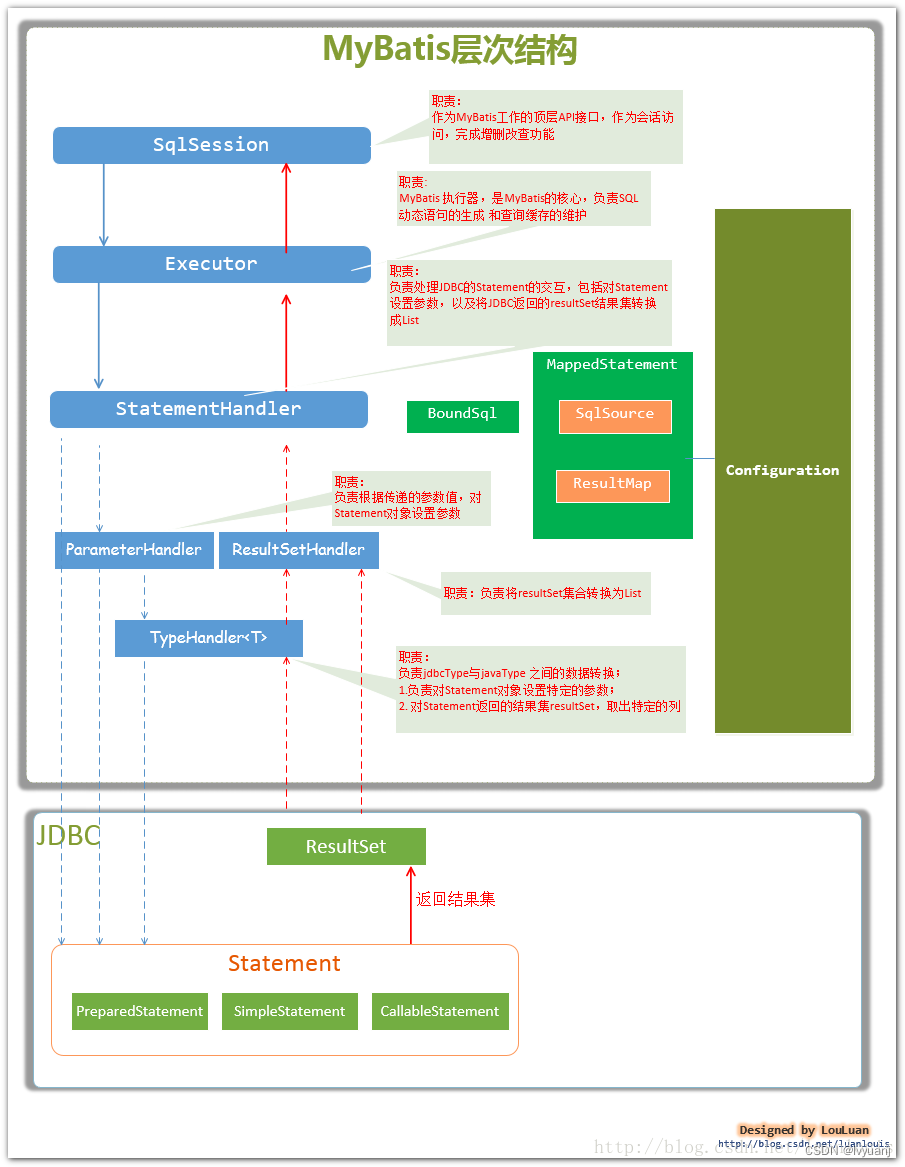
一、关于 Ragas
Ragas 是 RAG pipelines 的评估框架。
用于评估、监控和提高 LLM和RAG 在生产中的应用性能的专用解决方案,包括用于生产质量监控的自定义模型。
- 官网:https://docs.ragas.io
- 文档:https://docs.ragas.io/en/latest/
- github : https://github.com/explodinggradients/ragas
- 论文:RAGAS: Automated Evaluation of Retrieval Augmented Generation
https://arxiv.org/abs/2309.15217 - discord : https://discord.gg/5djav8GGNZ
Ragas是一个帮助您评估检索增强生成(RAG)管道的框架。
RAG表示一类LLM应用程序,它们使用外部数据来增强LLM的上下文。
现有的工具和框架可以帮助您构建这些管道,但评估和量化管道性能可能很困难。这就是 Ragas(RAG评估)的用武之地。
Ragas为您提供了基于最新研究的工具,用于评估LLM生成的文本,让您深入了解您的RAG管道。
Ragas可以与您的CI/CD集成,以提供连续检查以确保性能。
你可以和创始人约定会议交谈:https://cal.com/shahul-ragas/30min
二、安装🛡️
pip install ragas
从源码安装
git clone https://github.com/explodinggradients/ragas && cd ragas
pip install -e .
三、快速使用 🔥
This is a small example program you can run to see ragas in action!
from datasets import Dataset
import os
from ragas import evaluate
from ragas.metrics import faithfulness, answer_correctness
os.environ["OPENAI_API_KEY"] = "your-openai-key"
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[faithfulness,answer_correctness])
score.to_pandas()
更多信息可见文档:https://docs.ragas.io/
Open Analytics 🔍
我们跟踪非常基本的使用指标,以指导我们找出用户想要什么,什么有效,什么无效。作为一家年轻的初创公司,我们必须非常诚实,这就是我们跟踪这些指标的原因。但作为一家开放式初创企业,我们开源 收集到的所有数据。
你可以从这里了解更多:https://github.com/explodinggradients/ragas/issues/49 。
Ragas不会跟踪任何可用于识别您或您的公司的信息。
你可以看看我们记录在代码里的: https://github.com/explodinggradients/ragas/blob/main/src/ragas/_analytics.py
你可以设置 RAGAS_DO_NOT_TRACK flag 为 true 来取消 usage-tracking。
四、References
https://docs.ragas.io/en/latest/references/index.html
- Evaluation
evaluate()Result
- Metrics
AnswerCorrectnessAnswerCorrectness.nameAnswerCorrectness.weightsAnswerCorrectness.answer_similarityAnswerCorrectness.adapt()AnswerCorrectness.init()AnswerCorrectness.save()
AnswerRelevancyAnswerRelevancy.nameAnswerRelevancy.strictnessAnswerRelevancy.embeddingsAnswerRelevancy.adapt()AnswerRelevancy.save()
AnswerSimilarityAnswerSimilarity.nameAnswerSimilarity.model_nameAnswerSimilarity.threshold
AspectCritiqueAspectCritique.nameAspectCritique.definitionAspectCritique.strictnessAspectCritique.llmAspectCritique.adapt()AspectCritique.save()
ContextEntityRecallContextEntityRecall.nameContextEntityRecall.batch_sizeContextEntityRecall.save()
ContextPrecisionContextPrecision.nameContextPrecision.evaluation_modeContextPrecision.context_precision_promptContextPrecision.adapt()ContextPrecision.save()
ContextRecallContextRecall.nameContextRecall.adapt()ContextRecall.save()
ContextRelevancyContextRelevancy.nameContextRelevancy.adapt()ContextRelevancy.save()
ContextUtilizationFaithfulnessFaithfulness.adapt()Faithfulness.save()
- Integrations
五、生成综合测试集
本教程将指导您创建用于评估 RAG 管道的综合评估数据集。
为此,我们将利用 OpenAI 模型。确保您的 OpenAI API 密钥可在您的环境中轻松访问。
import os
os.environ["OPENAI_API_KEY"] = "your-openai-key"
文档
最初,需要一组文档来生成合成Question/Context/Ground_Truth样本。为此,我们将使用 LangChain 文档加载器来加载文档。
从目录加载文档
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader("your-directory")
documents = loader.load()
注意:每个 Document 对象都包含一个元数据字典,可用于存储有关可通过Document.metadata。 确保元数据字典包含一个名为 的键filename,因为它将在生成过程中使用。元数据中的属性filename用于标识属于同一文档的块。例如,可以使用文件名来识别属于同一研究出版物的页面。
以下是如何执行此操作的示例:
for document in documents:
document.metadata['filename'] = document.metadata['source']
至此,我们已经有了一组文档,可以用作生成合成 Question/Context/Ground_Truth 样本的基础。
数据生成
现在,我们将导入并使用 Ragas’TestsetGenerator从加载的文档快速生成综合测试集。
使用默认配置 创建 10 个示例
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# generator with openai models
generator_llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
critic_llm = ChatOpenAI(model="gpt-4")
embeddings = OpenAIEmbeddings()
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# generate testset
testset = generator.generate_with_langchain_docs(documents, test_size=10, distributions={simple: 0.5, reasoning: 0.25, multi_context: 0.25})
然后,我们可以将结果导出到 Pandas DataFrame 中。
导出到 Pandas
testset.to_pandas()
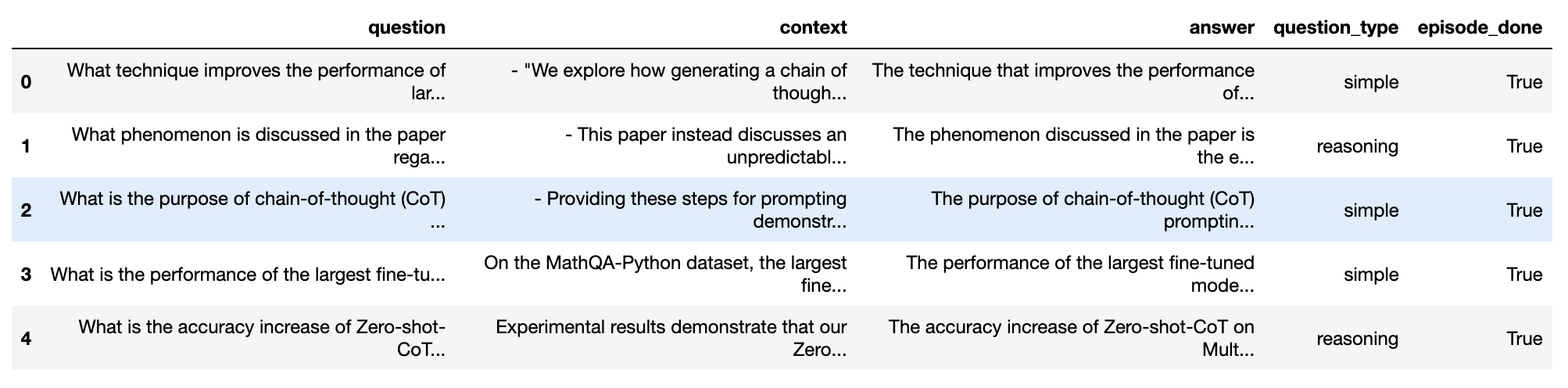
六、使用您的测试集进行评估
一旦您的测试集准备就绪(无论您是创建自己的测试集还是使用综合测试集生成模块),就可以评估您的 RAG 管道了。
本指南可帮助您尽快设置 Ragas,使您能够专注于增强检索增强生成管道,同时该库可确保您的修改改进整个管道。
本指南利用 OpenAI 来运行一些指标,因此请确保您已准备好 OpenAI 密钥并在您的环境中可用。
import os
os.environ["OPENAI_API_KEY"] = "your-openai-key"
注意:默认情况下,这些指标使用 OpenAI 的 API 来计算分数。如果您使用此指标,请确保您已OPENAI_API_KEY使用 API 密钥设置环境密钥。 您还可以尝试其他LLM进行评估,查看自带LLM指南以了解更多信息。
让我们从数据开始。
数据
在本教程中,我们将使用 我们为 Amnesty QA数据集创建的基线之一的示例数据集。数据集包含以下列:
- question:
list[str]- 这些是您的 RAG 管道将被评估的问题。 - context :
list[list[str]]- 传递到LLM以回答问题的上下文。 - ground_truth:
list[str]- 问题的真实答案。
理想的测试数据集应包含与您的实际用例密切相关的样本。
导入样本数据集
from datasets import load_dataset
# loading the V2 dataset
amnesty_qa = load_dataset("explodinggradients/amnesty_qa", "english_v2")
amnesty_qa
也可以看看
请参阅测试集生成,了解如何生成您自己的Question/Context/Ground_Truth三元组以进行评估。请参阅准备您自己的数据集以了解如何准备您自己的数据集以进行评估。
Metrics 指标
Ragas 提供了多个指标来评估 RAG 系统的各个方面:
- 检索器:提供
context_precision并context_recall衡量检索系统的性能。 - 生成器(LLM):提供
faithfulness测量幻觉以及answer_relevancy测量答案与问题的相关程度的方法。
Ragas 中还有许多其他可用的指标,请查看指标指南以了解更多信息。
现在,让我们导入这些指标并更多地了解它们的含义。
导入指标
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
)
这里我们使用四个指标,但它们代表什么?
- 忠实性 - 衡量基于问题的上下文答案的事实一致性。
- Context_precision - 衡量检索到的上下文与问题的相关程度,传达检索管道的质量。
- Answer_relevancy - 衡量答案与问题的相关程度。
- Context_recall - 衡量检索器检索回答问题所需的所有必要信息的能力。
要探索其他指标,请查看指标指南。
评估
运行评估就像使用您选择的指标调用一样evaluate简单Dataset。
使用样本数据集进行评估
from ragas import evaluate
result = evaluate(
amnesty_qa["eval"],
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
result
这就是你需要的所有分数。
如果您想更深入地研究结果并确定管道表现不佳或异常良好的示例,您可以将其转换为 pandas DataFrame 并使用标准分析工具!
导出结果
df = result.to_pandas()
df.head()
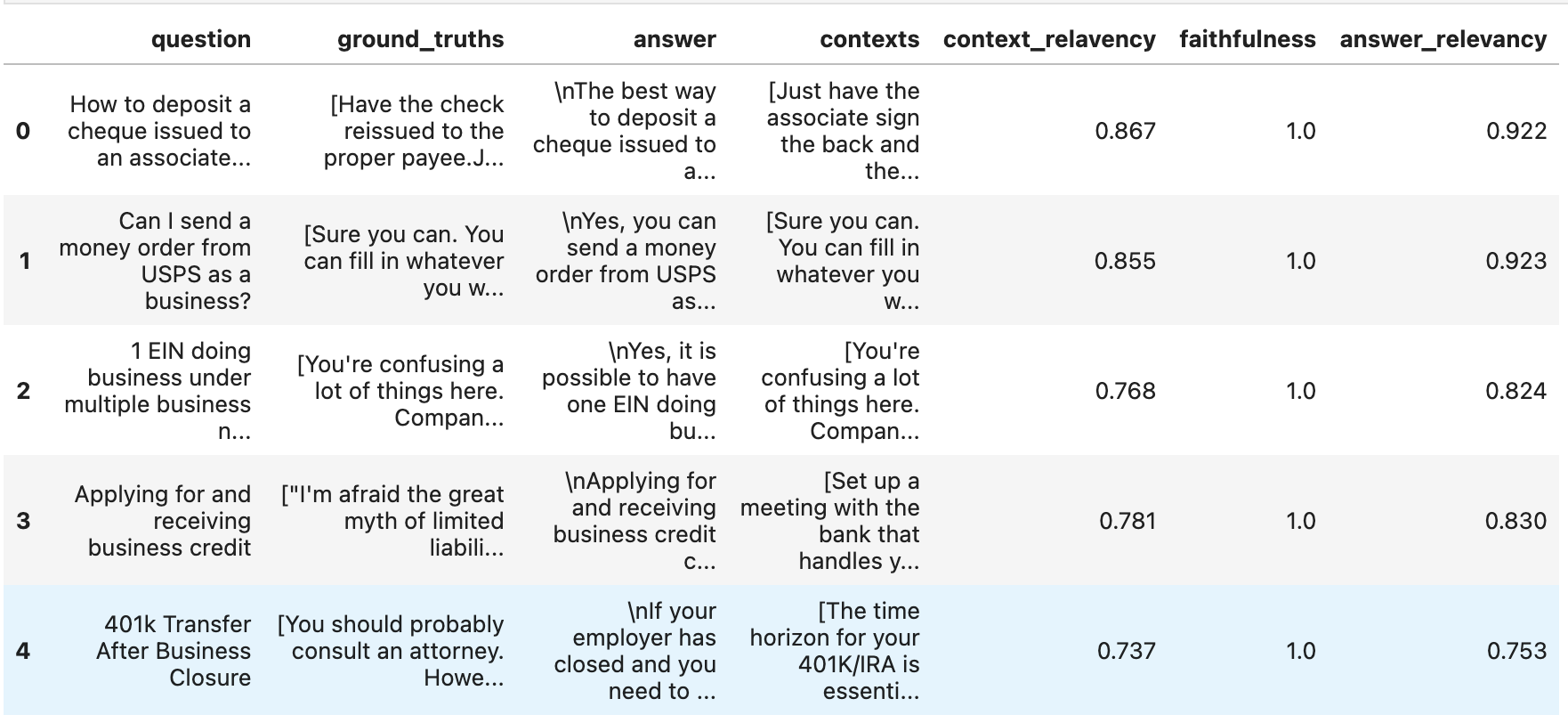
就这样!
七、监控生产中的 RAG
在生产环境中保持 RAG 应用程序的质量和性能具有挑战性。 RAG 目前提供了生产质量监控的基本构建块,为您的应用程序性能提供了宝贵的见解。然而,我们还致力于通过解决三个关键领域来构建更先进的生产监控解决方案:
- 如何确保生产数据集的分布与测试集保持一致。
- 如何有效地从用户提供的显式和隐式信号中提取见解,以推断 RAG 应用程序的质量并确定需要注意的区域。
- 如何构建定制的、更小、更具成本效益且更快的模型来进行评估和高级测试集生成。
注:我们仍在为即将发布的版本开发并收集反馈。您可以请求 提前访问以尝试或分享您在该领域面临的挑战。我们很想听听您的想法和挑战。
此外,您可以将 RAG 指标与其他 LLM 可观察性工具一起使用,例如:
- Langsmith
- Phoenix (Arize)
- Langfuse
- OpenLayer
这些工具可以提供有关应用程序各个方面的基于模型的反馈,例如下面提到的:
需要监控的方面
- Faithfulness 忠实性:此功能有助于识别和量化幻觉实例。
- Bad Retrieval 不良检索:此功能有助于识别和量化不良上下文检索。
- Bad Response 不良响应:此功能有助于识别和量化回避、有害或有毒的响应。
- Bad Format 格式错误:此功能可以检测和量化格式不正确的响应。
- Custom Use-Case 自定义用例:要监控特定于您的用例的其他关键方面,请与创始人交谈。
2024-04-28(日)