目录
- 一. 统计文件的总行数
- 二. 获取从第二行开始的内容
- 三. 合并两个文件为一个文件
- 四. 统计指定列唯一值的数量
- 五. 列出文件的绝对路径
- 六. 获取除了空白行和注释之外的部分
一. 统计文件的总行数
⏹非压缩文件
- 统计当前文件夹下csv文件的行数
wc -l ./*.csv
- 统计指定文件夹下csv文件的行数
-maxdepth 2:指定查找的文件夹的层级
find ./ -maxdepth 2 -type f -name *.csv | xargs wc -l
⏹压缩文件
- 使用zact命令,可在不解压的情况下直接查看压缩文件的内容
zcat ./*.csv.zip | nkf -w8 | wc -l
- 若存在多个zip文件,可先将每个zip文件的行数输出到一个文本文件中
- 然后使用awk命令进行合计;或者复制到Excel中进行合计
awk '{sum += $1} END {print "总和:", sum}' ./result.txt
# 获取出当前路径下的zip文件
fengyehong@ubuntu:~/jmw_work_space/20240421$ ls -l *.zip
-rw-rw-r-- 1 fengyehong fengyehong 197454 Apr 21 02:16 CBC_SystemLog.log.zip
-rw-rw-r-- 1 fengyehong fengyehong 484 Apr 21 02:10 file1.txt.zip
-rw-rw-r-- 1 fengyehong fengyehong 464 Apr 21 02:11 file2.txt.zip
# 获取出zip文件的绝对路径
fengyehong@ubuntu:~/jmw_work_space/20240421$ ls *.zip | sed "s:^:`pwd`/:"
/home/fengyehong/jmw_work_space/20240421/CBC_SystemLog.log.zip
/home/fengyehong/jmw_work_space/20240421/file1.txt.zip
/home/fengyehong/jmw_work_space/20240421/file2.txt.zip
# 使用vi编辑脚本文件
fengyehong@ubuntu:~/jmw_work_space/20240421$ vi count.sh
# 查看编辑好的内容
fengyehong@ubuntu:~/jmw_work_space/20240421$ cat count.sh
zcat /home/fengyehong/jmw_work_space/20240421/CBC_SystemLog.log.zip | nkf -w8 | wc -l
zcat /home/fengyehong/jmw_work_space/20240421/file1.txt.zip | nkf -w8 | wc -l
zcat /home/fengyehong/jmw_work_space/20240421/file2.txt.zip | nkf -w8 | wc -l
# 执行脚本,输出结果到新文件中
fengyehong@ubuntu:~/jmw_work_space/20240421$ sh count.sh > result.txt
# 查看统计的结果
fengyehong@ubuntu:~/jmw_work_space/20240421$ cat result.txt
18612
7
7
# 统计全部zip文件的总行数
fengyehong@ubuntu:~/jmw_work_space/20240421$ awk '{sum += $1} END {print "总和:", sum}' ./result.txt
总和: 18626
二. 获取从第二行开始的内容
tail -n +2 file1.txt
# cat命令获取文件的全部内容
fengyehong@ubuntu:~/jmw_work_space/20240421$ cat file1.txt
ID,方式1,姓名,组,memberID,电话号码,方式2,消耗时间,结果code
110120,SPLREQUEST,東川雄一,AAA,memberID=1,tel=080-1111-1111,SPLEND,ExecTime=200,ResultCode=200
123456,SPLREQUEST,西村祐二,BBB,memberID=2,tel=080-2222-2222,SPLEND,ExecTime=300,ResultCode=200
123444,SPLREQUEST,南山裕三,CCC,memberID=3,tel=080-3333-3333,SPLEND,ExecTime=200,ResultCode=200
# tail命令获取从第二行开始的内容(相当于去掉表头)
fengyehong@ubuntu:~/jmw_work_space/20240421$ tail -n +2 file1.txt
110120,SPLREQUEST,東川雄一,AAA,memberID=1,tel=080-1111-1111,SPLEND,ExecTime=200,ResultCode=200
123456,SPLREQUEST,西村祐二,BBB,memberID=2,tel=080-2222-2222,SPLEND,ExecTime=300,ResultCode=200
123444,SPLREQUEST,南山裕三,CCC,memberID=3,tel=080-3333-3333,SPLEND,ExecTime=200,ResultCode=200
awk 'NR > 1 {print $0}' ./file1.txt
fengyehong@ubuntu:~/jmw_work_space/20240421$ awk 'NR > 1 {print $0}' ./file1.txt
110120,SPLREQUEST,東川雄一,AAA,memberID=1,tel=080-1111-1111,SPLEND,ExecTime=200,ResultCode=200
123456,SPLREQUEST,西村祐二,BBB,memberID=2,tel=080-2222-2222,SPLEND,ExecTime=300,ResultCode=200
123444,SPLREQUEST,南山裕三,CCC,memberID=3,tel=080-3333-3333,SPLEND,ExecTime=200,ResultCode=200
三. 合并两个文件为一个文件
# 待合并的两个文件14行
fengyehong@ubuntu:~/jmw_work_space/20240421$ wc -l file1.txt file2.txt
7 file1.txt
7 file2.txt
14 total
# 将file1.txt和file2.txt(去除表头)合并到newfile.csv
fengyehong@ubuntu:~/jmw_work_space/20240421$ (cat ./file1.txt;cat ./file2.txt | tail -n +2) > newfile.csv
# 合并之后的文件13行(因为第2个文件去掉了表头)
fengyehong@ubuntu:~/jmw_work_space/20240421$ wc -l newfile.csv
13 newfile.csv
四. 统计指定列唯一值的数量
- 统计指定列唯一值:
awk -F',' '{print $3}' ./newfile.csv | sort -n | uniq -c - 去除行开头的空白部分:
sed 's/^[[:space:]]*//'
# 查看csv文件的内容
fengyehong@ubuntu:~/jmw_work_space/20240421$ cat newfile.csv
ID,方式1,姓名,组,memberID,电话号码,方式2,消耗时间,结果code
110120,SPLREQUEST,東川雄一,AAA,memberID=1,tel=080-1111-1111,SPLEND,ExecTime=200,ResultCode=200
123456,SPLREQUEST,西村祐二,BBB,memberID=2,tel=080-2222-2222,SPLEND,ExecTime=300,ResultCode=200
123444,SPLREQUEST,南山裕三,CCC,memberID=3,tel=080-3333-3333,SPLEND,ExecTime=200,ResultCode=200
123434,SPLREQUEST,北岡優四,memberID=,tel=080-4444-4444,SPLEND,ExecTime=400,ResultCode=200
345345,SPLREQUEST,田中様,EEE,memberID=5,tel=080-5555-5555,SPLEND,ExecTime=500,ResultCode=200
674545,SPLREQUEST,,FFF,memberID=6,tel=080-6666-6666,SPLEND,ExecTime=400,ResultCode=200
110120,SPLREQUEST,贾飞天,AAA,memberID=1,tel=080-1111-1111,SPLEND,ExecTime=200,ResultCode=200
123456,SPLREQUEST,枫叶红,BBB,memberID=2,tel=080-2222-2222,SPLEND,ExecTime=300,ResultCode=200
123444,SPLREQUEST,枫叶红,CCC,memberID=3,tel=080-3333-3333,SPLEND,ExecTime=200,ResultCode=200
123434,SPLREQUEST,北岡優四,memberID=,tel=080-4444-4444,SPLEND,ExecTime=400,ResultCode=200
345345,SPLREQUEST,田中様,EEE,memberID=5,tel=080-5555-5555,SPLEND,ExecTime=500,ResultCode=200
674545,SPLREQUEST,,FFF,memberID=6,tel=080-6666-6666,SPLEND,ExecTime=400,ResultCode=200
# 第三列是姓名列,列出每个姓名所对应的数量
fengyehong@ubuntu:~/jmw_work_space/20240421$ awk -F',' '{print $3}' ./newfile.csv | sort -n | uniq -c
2
2 北岡優四
1 南山裕三
1 姓名
1 東川雄一
2 枫叶红
2 田中様
1 西村祐二
1 贾飞天
# 使用 uniq -c 后,数量的前面会有空格,此时可通过 sed 's/^[[:space:]]*//' 命令将其去除
fengyehong@ubuntu:~/jmw_work_space/20240421$ awk -F',' '{print $3}' ./newfile.csv | sort -n | uniq -c | sed 's/^[[:space:]]*//'
2
2 北岡優四
1 南山裕三
1 姓名
1 東川雄一
2 枫叶红
2 田中様
1 西村祐二
1 贾飞天
五. 列出文件的绝对路径
⏹不包含隐藏文件
ls *.zip | sed "s:^:`pwd`/:"
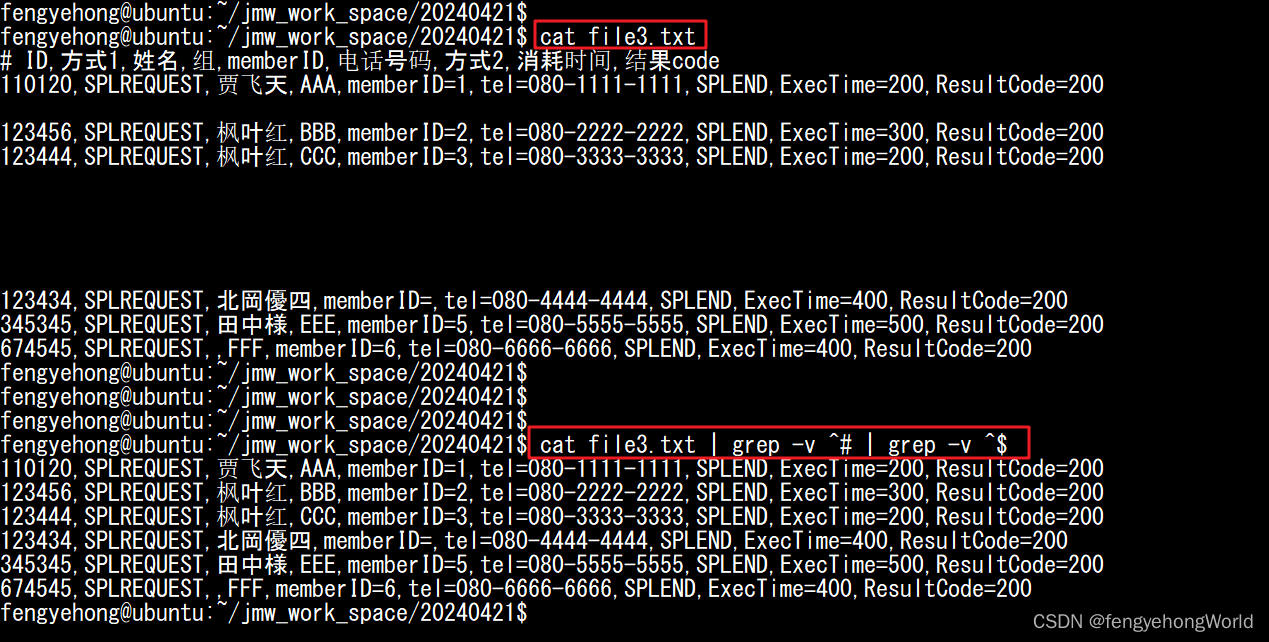
六. 获取除了空白行和注释之外的部分
cat file3.txt | grep -v ^# | grep -v ^$